
Abstract
As the scale of software systems continues expanding, software architecture is receiving more and more attention as the blueprint for the complex software system. An outstanding architecture requires a lot of professional experience and expertise. In current practice, architects try to find solutions manually, which is time-consuming and error-prone because of the knowledge barrier between newcomers and experienced architects. The problem can be solved by easing the process of apply experience from prominent architects. To this end, this paper proposes a novel graph-embedding-based method, AI-CTO, to automatically suggest software stack solutions according to the knowledge and experience of prominent architects. Firstly, AI-CTO converts existing industry experience to knowledge, i.e., knowledge graph. Secondly, the knowledge graph is embedded in a low-dimensional vector space. Then, the entity vectors are used to predict valuable software stack solutions by an SVM model. We evaluate AI-CTO with two case studies and compare its solutions with the software stacks of large companies. The experiment results show that AI-CTO can find effective and correct stack solutions and it outperforms other baseline methods.
Introduction
As the scale of software systems continues expanding, software architecture is receiving more and more attention as the blueprint for the complex software system. Software architecture establishes the link between requirements and implementation [1] and allows designers to infer the ability to meet requirements at the design phase. This field has been developing for more than 30 years and plays an important and ubiquitous role in contemporary industrial practice [2]. The quality of the system depends heavily on its design, i.e. architecture. According to a research report from the National Institute of Standards and Technology (NIST), more than 70% of errors found in software testing are caused by requirement acquisition or architecture design [3]. The longer the errors exist in the system, the harder it will be to find them, and the higher the cost of solving them. In summary, a good architecture makes the software system more robust and reliable. Software architecture can be divided into two levels: architecture and design, but it is difficult to clearly distinguish the boundary of them [4]. Therefore, in this paper, the “architecture” is considered to be elements of architectural styles. For example, there are two basic elements of client-server architectural style, the “client” and “server”. Common architectural styles include pipes and filters, data abstraction and object-oriented organisation, event-based implicit invocation, abstract data types or objects, layered system, business cycle, client-server model, etc [5]. The “design” is considered to be the process of choosing a development software for each element of architectural styles. For example, MySQL is software for the database element of an architectural style. However, due to the complex relationship between architectural style and software performance, it is difficult for architects to choose an appropriate style and design each component manually.
Motived by the above problem and challenge, this paper proposes a novel method, AI-CTO, to suggest software stack solutions. AI-CTO consists of three stages: Establishment of software knowledge graph; Embedding of the knowledge graph; Deriving of software stack solutions. The basic idea is extracting knowledge from a well-designed software graph to facilitate architecture tasks. As the relations among software entities can be reasonably represented by the knowledge graph, we firstly build the five-layer software graph: (1)Software system layer; (2) Software stack layer; (3) Software category layer; (4) Software label layer; (5) Software framework layer. These layers represent the different type of entities in the graph, such as software and requirement labels. In addition, the company entities are not in these layers, because they are not elements of software stacks.
For automated analysis of the architectural problem, we intend to embed the entities in the software graph into a low-dimensional vector space. However, most of the previous researches about graph embedding just learned from structural triples [6–8], while there is rich semantic information that reflects features of the software, such as descriptions and names. Therefore, we propose a novel embedding method to combine the two kinds of information in the graph, i.e., structure information and description information. Our method takes the results of node2vec [8] as structure information and the embedding of software description text as description information.
To derive the software stack solutions according to the requirements of architects, we propose a requirement-based-walk method to select a set of stack solutions, which satisfy the requirements. These preliminary stack solutions are further filtered by a Support Vector Machine (SVM) model. The feature vector of each stack is calculated by the embedding results. The SVM model is trained by the stack solutions of large companies.
According to the above ideas, we build the prototype of AI-CTO. The software graph contains 11876 entities and 43269 relations, including 3175 software entities and 350 company entities. We set four baselines on two experiments to evaluate the correctness and usage of AI-CTO. For the correctness experiment, the results of AI-CTO are verified by real software stacks. For the usage experiment, this experiment counts the companies using the same stacks as AI-CTO results. The results show that AI-CTO outperforms other baselines and can suggest satisfactory software stacks.
In summary, we make the following contributions in this paper: We introduce the concept of knowledge graph to formally represent software entities and requirements of architects, which converts development experience to knowledge and narrows the knowledge barrier between newcomers and experienced architects. We implement the prototype of AI-CTO to extract effective software stack solutions from the software knowledge graph. The method makes full use of both the semantic information of software descriptions and graph structure information. The software stack solutions are further filtered by an SVM model. We present an extensive evaluation of AI-CTO. The experiment results show that AI-CTO outperforms other baseline methods.
The rest of this paper is organised as follows. In Section 2, we discuss the background information needed to have a primary impression of the technologies used in our method. Section 3 details the software stack solution method. The method is analysed and evaluated in Section 4. Section 5 reports factors that may affect experiment results. Section 6 discusses the related work of our work. Finally, we summary this paper in Section 7.
Background
This section discusses motivation, formalisation of the problem in the selection space and notions about knowledge graph.
Motivation
There is a phenomenon of inadequate utilisation of existing knowledge and experience. Newcomers possess limited knowledge and experience [9, 10]. It is difficult for them to choose an appropriate style and design each component manually. In fact, according to the experience of our industrial partners, develops tend to choose the technologies they are familiar with, which makes it harder for them to learn from experienced architects.
In addition, the knowledge and experience of architects are full of entities and relations, such as software, companies and dependencies among them, which is very similar to the concept of the knowledge graph. To facilitate the analysis in form of vectors, the graph is embedded into a continuous low-dimensional vector space.
The embedding process takes account of two kinds of features. The graph structure features reflect the space characteristic while the description features reflect the semantic information. Therefore, an SVM model is used to find the boundary of that.
Problem definition
This problem can be explain by defining a selection space. Let a be a vector having elements a
i
in an architectural style, and a
i
corresponds to the design selections. The architectural vector a has n dimension. Let d be a Boolean vector having elements d
j
as each design selection, i.e., a
i
= {d}. The design vector d has m dimension. A design element d
j
can be defined as either d
j
= 0 (do not choose it), or d
j
= 1 (choose it):
The task for architects is choosing an option from the selection space. For example, the architecture of a simple web application usually consists of web server, client and database, i.e., the a has three elements. According to a technology stack website1, the number of common development tools for web server, client and database are 25, 40 and 58, i.e., m1 = 25, m2 = 40, m3 = 58. There is a total selection space of m1 * m2 * m3 (58000) options to select among, which is a large number for human developers. As the full-stack tools, such as NodeJS, are not included in the example, the upper-bound of selection space is much higher in real-world situations.
The knowledge graph efficiently stores objective knowledge in form of triples. Each triple contains two entities and the relation between them. For example, triple (h, r, t) contains a head node h, a relation r and a tail node t. This kind of knowledge representation can preferably reflect the relation information between entities and it is useful for various domains [11]. With the advancement of knowledge graph technologies in recent years, some changes have taken place in this field. One of them is that more and more researches have shifted from a general-purpose knowledge graph (GKG) to domain-specific knowledge graph (DKG). GKG is built with general objective knowledge and on a large scale, such as Google’s Knowledge Graph [12], NELL [13] and WikiData [14]. As one of the most important features of GKG is the large scale, automatic Information Acquisition technologies become a widely research topic [15–17].
DKG refers to knowledge graphs that are focused on a specific field, such as software engineering. Software knowledge graph contains not only software but also related entities such as developers, logs and documentation. For example, IntelliDE [18]implement the function of software text semantic search based on a software knowledge graph, which consists of information from source code files, version control systems, mailing lists, issue tracking systems, Microsoft Office and PDF documents, HTML-format tutorials, API documentation, user forum posts, blogs and online social question-answering pairs.
The software knowledge graph can be used to solve different issues in software engineering, such as design and analysis of functional requirements [19], maintenance and testing of software [20] and documentation for coding support [21].
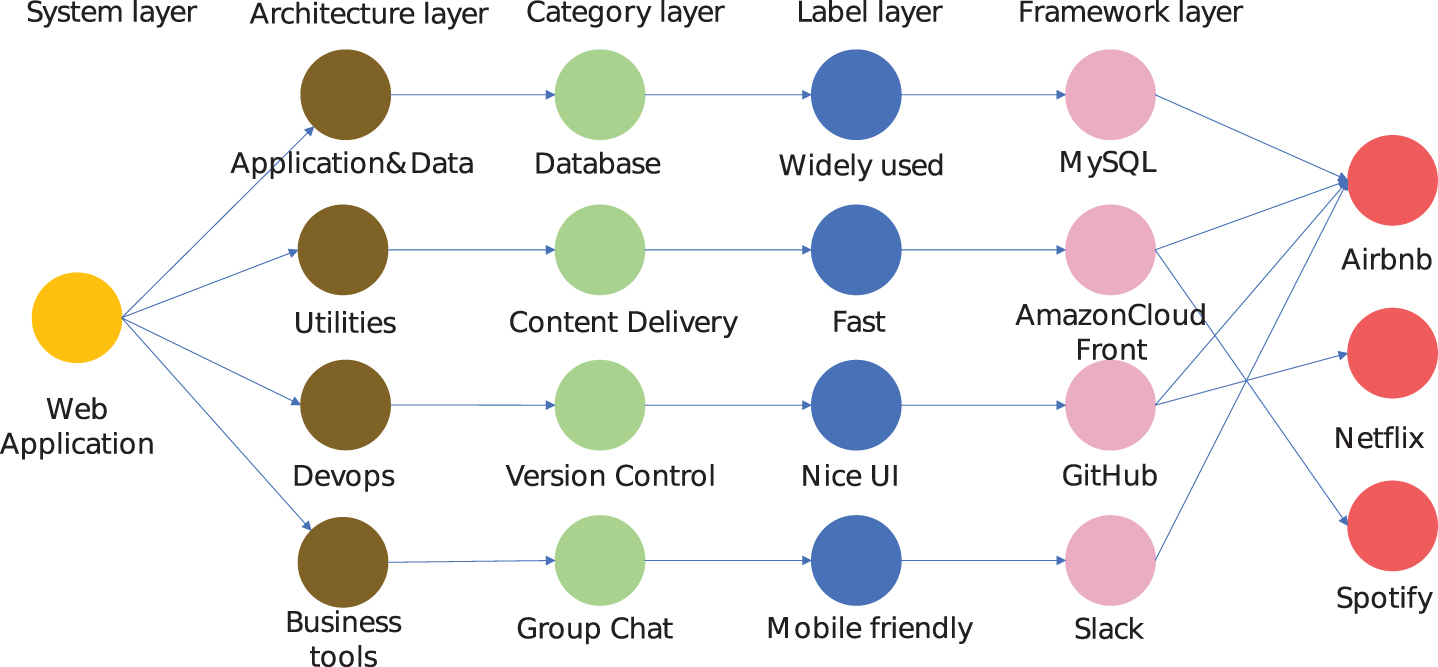
The layout example of the software knowledge graph.
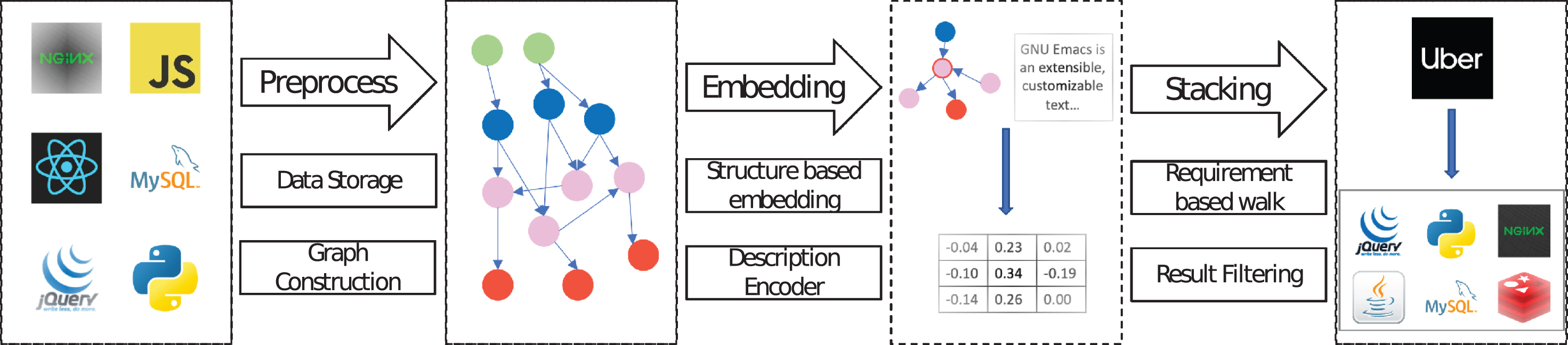
The overview architecture of Our method: (1) The preprocessing stage consists of two processes, graph construction, and data storage; (2) The Embedding stage consists of two processes, structural based embedding, and description encoder; (3) The stacking stage consists of two processes, requirement based walk, and result filtering.
Fig. 2 demonstrates the overview architecture of the proposed approach, which contains three main stages.
The preprocessing stage converts raw data to the knowledge graph. The graph construction process extracts entities and relations from raw data to build a structured software knowledge graph. The raw data comes from online sources and consists of software tools, companies, software labels, etc, which is massive and disordered. Therefore, the data needs to be cleaned in the data storage process. In addition, the output of the graph construction process is stored into the graph database in this process.
In the embedding stage, the software knowledge graph is projected into a continuous low-dimensional vector space. There are two kinds of information that can be used to realise the embedding, graph structure information and auxiliary information of entities. The structure based embedding process projects entities into vector space based on graph structure information. The description encoder process encodes the description of entities to vectors with the same dimension based on auxiliary information. The two kinds of the vector are combined to represent the entity in the software knowledge graph.
The stacking stage constructs software stack solutions. The requirement based walk process walks in the graph to select a primary stack according to user requirements. The result filtering process improves the primary stack according to entity vectors.
Preprocessing
Graph construction
One of our central hypotheses is that the technology stacks used by famous companies are efficient and adaptable. Therefore, we crawl technology stack data as elementary knowledge from stackshare2. The problem is that the raw data consists of many pieces of separate data. The software knowledge graph of this paper extracts structured software knowledge from raw data according to the following rules: (1) A node in the graph represents a software knowledge entity; (2) A directed edge represents a relation; (3) Each software entity corresponds to a unique identifies.
Although the graph data is generated by the relation between entities, it still needs a cleverly designed structure to be represented. The extracted entities and relations are constructed into five layers, as shown in Fig. 1. Each layer is created for a kind of entities. In particular, the label layer reflects the requirements of users, so a stack walks through the label can be thought as that the stack satisfy the requirement.
The software system layer contains the target system or application which we want to build stack for, such as a Web application. Following paragraphs describe the structure and features of the rest of the layers.
The software stack layer consists of four entities, “Application&Data”, “Utility”, “Devops” and “Business tools”. The four architecture items are used to organise a large number of software categories.
The software category layer consists of various categories of basic software items, such as databases, cloud hosting and full-stack frameworks. The software stack is built according to different categories in this layer. For example, a Web application basically contains front-end framework, Web server and database. The stack for a Web application chooses one element from each of these three categories.
The software label layer consists of the function and performance labels, which are used to reflect the characteristic of elementary software items. Those labels are used to represent the requirements of users. For example, developers tend to use high-performance tools, such as NodeJS. The “high-performance” is a performance label of NodeJS, and it represents the requirement of developers on performance. As the category layer and software framework layer is connected with the label layer, it is able to select a software that satisfies the multiple requirements by walking in the graph.
The software framework layer consists of elementary software items, such as NodeJS, JavaScript and Python. In particular, software items used by famous companies connect to the corresponding company entities. This makes the stack used by famous companies different from others in embedded data so that our method can learn the technology features of famous companies.
Data storage
The output data of the graph construction process is imported into the graph database for succeeding tasks. According to features of the graph, we first build entities in the graph database and then associate them with relations. However, there are too many query operations with this method and it is inefficient. We optimised the operation of importing. When building entities, a part of the entities that have known relations are directly constructed into triples, thus reducing the query operations when building relations later. In addition, the software label data from stackshare is submitted by tool users, i.e. it is crowdsourcing data. Not all labels in the data are valid, some of them are lack of support by developers. The top 60% of the labels are reserved.
Embedding
The basic idea of our method is analysing software in a continuous low-dimensional space instead of doing that with the symbolic representation of triples. As shown in Equation 2, we proposed a new embedding method by combining two methods to embed entities into the vector space, i.e. structure based embedding (E
s
) and description encoder (E
d
). The two methods simultaneously project entities into the same vector space, i.e., the dimensions of output are the same.
Due to the classical triple structure, the knowledge graph can efficiently provide graph structure information. According to the Skip-gram model [22], words with similar meanings tend to appear in a similar context. Similarly, an embedding vector of a node is decided by its neighbourhoods. The embedding normally consists of two steps, graph information sampling and vector learning. The first step samples the adjacent nodes by a biased random walk algorithm. The second step learns the feature vectors of nodes by the Skip-gram model. This process is implemented based on node2vec [8]. The biased random walk is to select representative nodes according to different search strategies, such as the breadth-first search (BFS) and the depth-first search (DFS). BFS focuses on neighbouring nodes and characterises a relatively local network representation. DFS reflects the homogeneity between nodes at a higher level. BFS can explore the structural properties of the graph, while DFS can explore the similarity in content (similarity between connected nodes). Nodes with similar structures do not have to be connected, and may even be far apart.
The problem is that node2vec does not distinguish the categories of different nodes in the graph, we avoid this problem by embedding the “category” in the vector space as well.
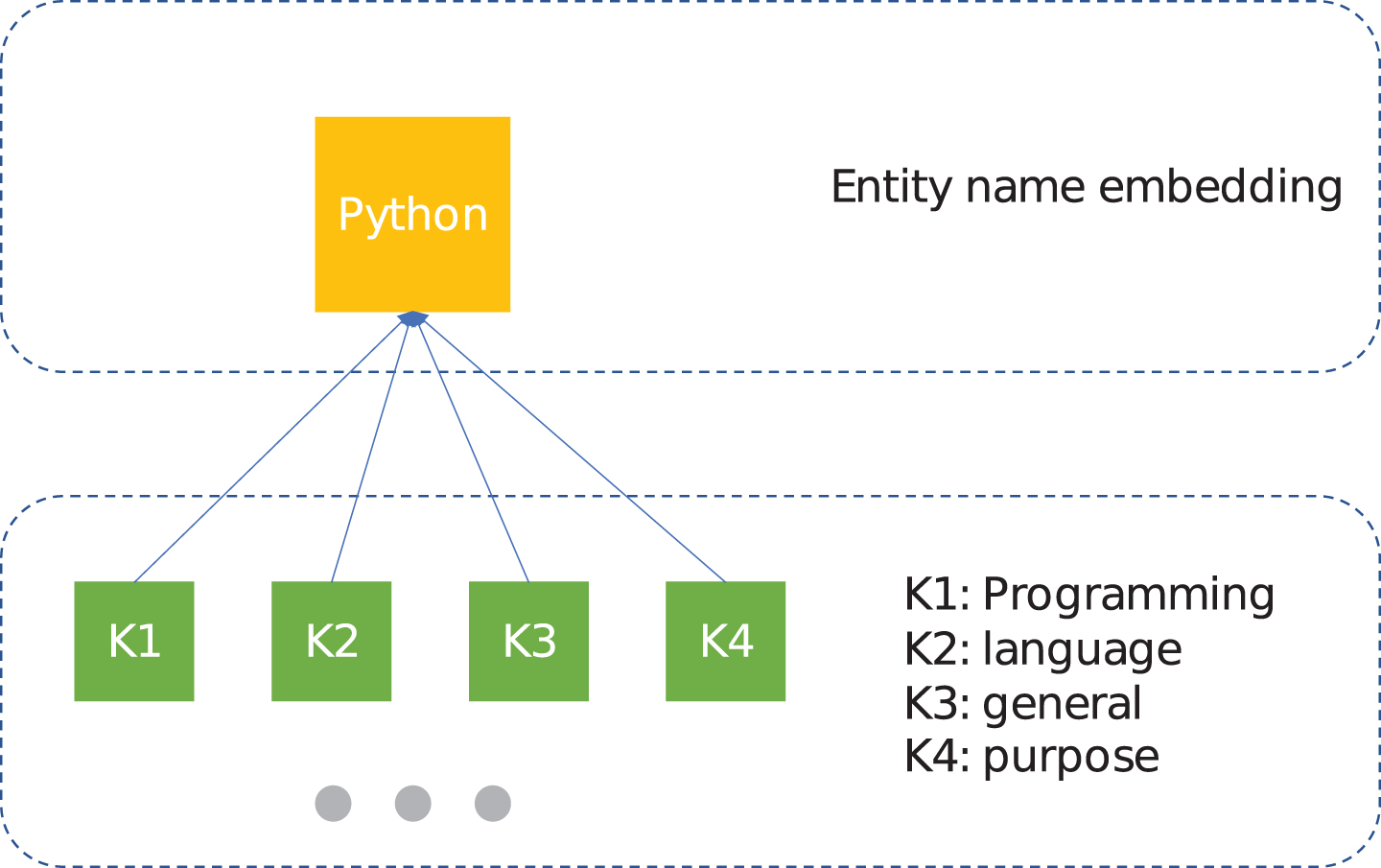
The keywords of a short description for an entity. The different distance between keywords and entity name will result in different weights for each keywords.
For each software entity, there is a short description that reflects the features and functions of the entity. For example, Fig. 4 is the description of NodeJS. The description encoder is built based on the hypothesis that the keywords in the description are able to summarise the main features of an entity. The embedding of each keyword is calculated by word2vec [22] model, which is trained on Wikipedia and all of the software descriptions. However, the keywords in a description should not be treated equally. Some keywords, such as the category of the entity, preferably represents the meaning of a description. For example, in the description of “Python is a general-purpose programming language created by Guido Van Rossum.”, the word “programming” is more important than “purpose”. Fig. 3 shows the relation between the entity and the keywords. The keywords are ranked by distances.

The description of NodeJs.
To capture this feature, we take the embedding of entity name as an anchor point. The words closer to entity name have more weight. The description embedding of a entity is calculated by following equations:
Inspired by the work of [23], this paper calculates the weights of keywords by Gauss Function, i.e., the weights increase with the decreasing distances between keywords and entity. As shown in Fig. 5, the results of Gauss Function are smooth and the range can be adjusted by the three parameters. Equation 6 shows the definition of Gauss Function, where a, b and c denote some real constants and decide the range of the weight. The x is the distance between a keyword and an entity, f (x) is the weight of the keyword corresponding to the entity. In this paper, the a value is always set to 1, so that the weight is ranged from 0 to 1. There is a maximum value when |x - b|=0. The b value is always set to 0 so that the distance equals 0 when the maximum weight is obtained (distance is positive). The c value is the standard deviation and controls the “width” of the function. It is adjusted according to the maximum of distances for each entity.
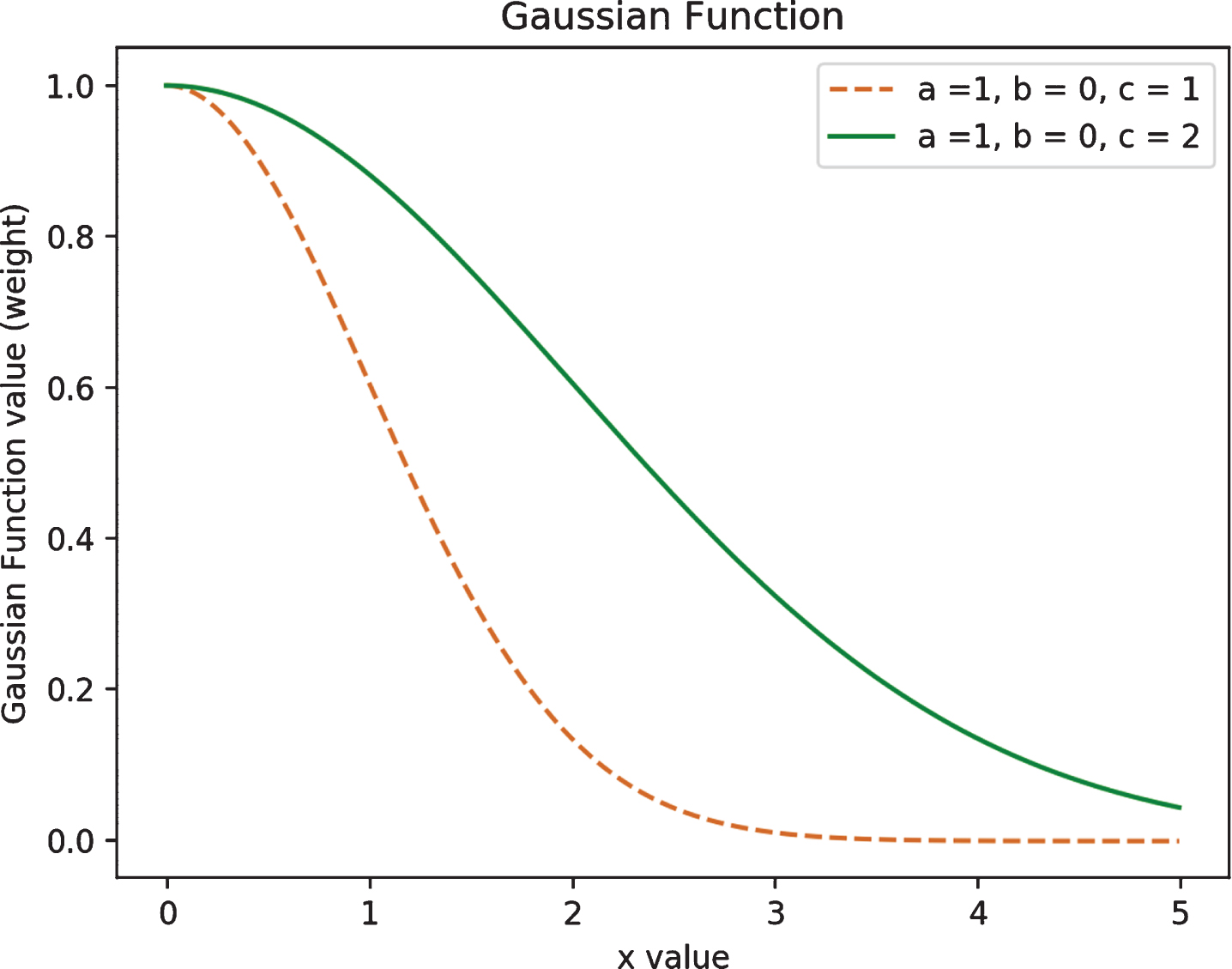
Gaussian Function.
Requirement based walk
The requirement based walk is proposed to find out which category of software is needed by the architecture. The basic idea is that popular categories are what develops need. For example, the “Web Servers” category is used by 3442 companies in our data and the “Graphic Design” category is used by 31 companies. Therefore, the “Web Servers” is considered as a category in the stack, while the “Graphic Design” may not.
Another key is to reflect the requirements of developers. As mentioned in section Graph Construction, there is a software label layer in the knowledge graph, which consists of the function and performance labels. In this paper, those labels are considered as software requirements. However, there are too many labels in the graph, i.e. 7800 labels. It is meaningless to integrate all of the labels in the method. We set a threshold to filter out unimportant labels according to their weights. The weight of a label is calculated according to the number of people who agree it on the stackshare website. Software tools that satisfy the labels are selected to be the preliminary software stack. However, the number of tools in the preliminary data is too large, which will be further filtered by a result filtering process. It is not better to directly select popular software or combination of popular software, but popular is just an important factor. It is also necessary to consider the relationship between software and company, software and software. The knowledge graph is to better reflect this relevance.
Result filtering
The results of requirement based walk process is selected by requirement labels, but it can be further filtered according to relevance among software, companies, labels etc. According to the idea of embedding method, the vectors of popular software and less used software will be located in different areas in the vector space. In addition, the software in a stack used by companies will be further closer. Therefore, considering the small amount of data and improving generalisation performance, we implement an SVM classifier to find the boundary between good stacks and useless stacks. SVM does not need to rely on the whole data, it is important to find the support vector.
The classifier finds a hyperplane W that separates two kinds of “points” with maximum margin. In this paper, the “points” are software stacks, which are classified valuable stack and worthless stacks. However, a software stack consists of multiple entities, each entity is represented as a vector. We simply use the average vector of all the entities in the stack to train the SVM classifier. The loss function is:
The s i is the score of corresponding sample x i . The W is a weight matrix which represent the hyperplane.
The AI-CTO method is evaluated with real data from a famous technology exchange community3 to answer the following research questions (RQs):
RQ 1 and RQ 2 examine the effectiveness of AI-CTO.
Dataset
We evaluate our method on real-world data from stackshare. Stackshare provides data about how famous companies build a software system. For example, there are 35 tools used by Facebook. Table 2 lists 10 of them. The problem is that the items in the data are discrete. Therefore, the data is converted to a software knowledge graph, which contains 11876 entities and 43269 relations. In particular, the statistics of the knowledge graph are listed in Table 1, and each item corresponds to the five layers of the graph.
A graph database is used to facilitate the query and storage in this experiment. The top five databases of DB-Engines Ranking4 are Neo4j, Microsoft Azure Cosmos DB, ArangoDB, OrientDB and Virtuoso. Considering the storage model, query language and other factors, Neo4j is chosen as a data storage tool in our method. Neo4j natively supports the Property Graph Model and has full ACID (Atomicity, Consistency, Isolation and Durability) properties.
The statistics of the software knowledge graph
The statistics of the software knowledge graph
Technology Stack of Facebook
To have an intuitive analysis of embedding results, Principal component analysis (PCA) algorithm is used to project vectors to 2-D, so that the embedding can be visualised. Fig. 6 is the 2-D projections of 128-D embeddings of the “python” and related nodes. The pink start is the “python” node. PCA was invented by Karl Pearson [24] in 1901, which is used to analyse the problem about how to retain more information while reducing the dimension of data. The method is mainly used to decompose the covariance matrix to obtain the principal components (i.e., eigenvectors) of the data and their weights (i.e., eigenvalue). The largest eigenvalue means that the largest variance is in the direction of corresponding eigenvector.
The baselines are implemented to compare with AI-CTO from two points of view. One is the feature used in AI-CTO, i.e., the graph structure feature and the description feature. Another is the method used to form a stack. It is clear from Fig. 6 that nodes with high correlation will be closer to each other. Therefore, the basic idea for baselines to form a stack is calculating the distance between software in a stack.
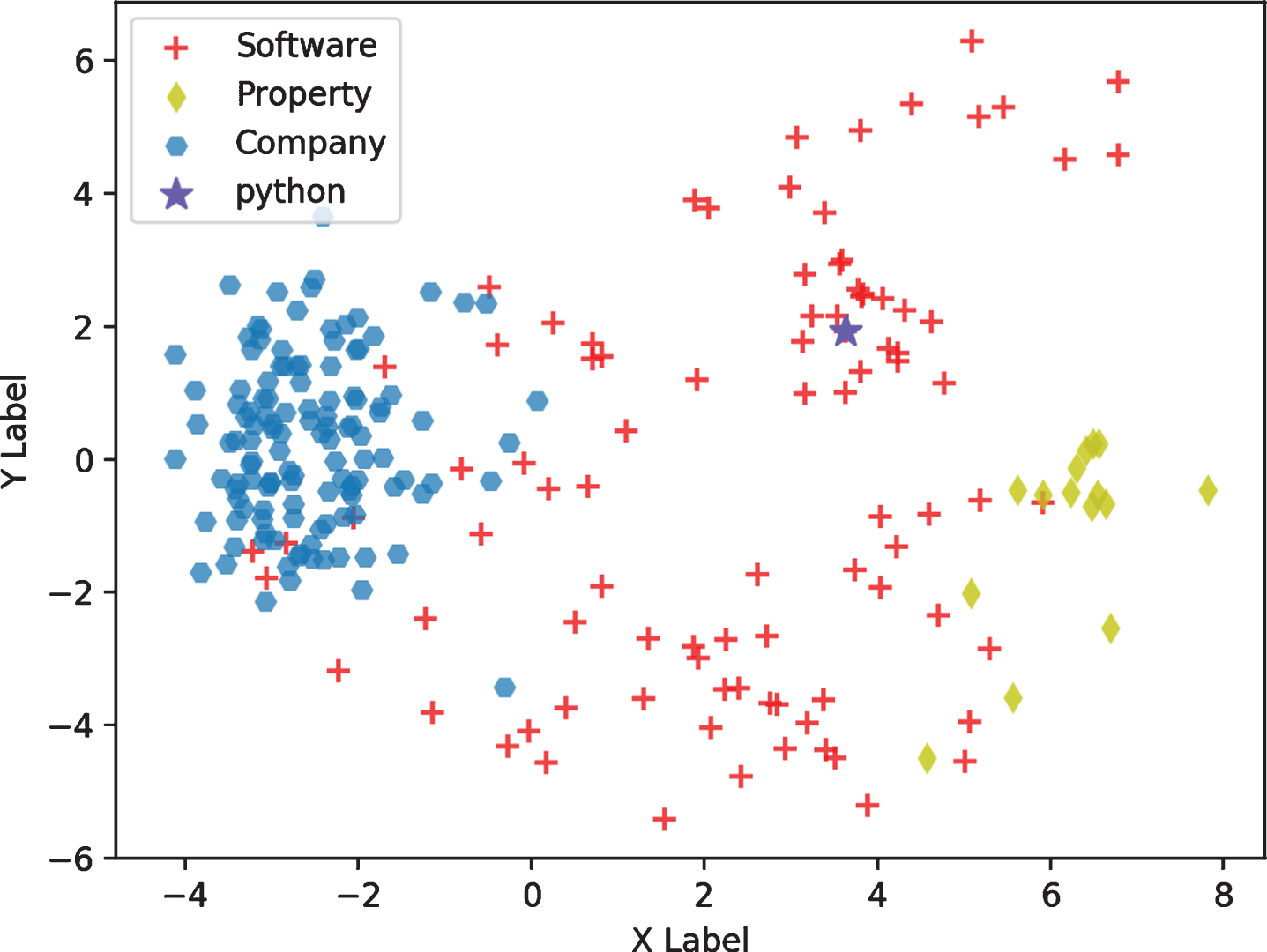
The embedding results of “python” and related nodes, which are projected to 2d by PCA algorithm. The pink start is the “python” node.
The baseline one extracts graph structure information to represent nodes in the software knowledge graph. The basic idea of this model is that the closer the two nodes are, the more relevant they are. Relevant nodes are considered as good combination for software development.
The baseline one model takes embedding results of node2vec as representations of nodes in the graph. The requirement based walk process selects all possible software stacks from the graph to give a preliminary software stack. However, there are too many groups in the preliminary data. The model calculates the Euclidean distances between node vectors to filter irrelevant results out. Fig. 7 illustrates the architecture of baseline one model.

Baseline One: the node2vec results and distance calculation.
The baseline two extracts semantic information to represent nodes in the software knowledge graph. The training data consists of Wikipedia texts and description texts from stackshare. The basic idea of this model is as same as that in baseline one model, but the representations of nodes are different. This model also takes Euclidean distance as a metric to filter irrelevant results out. Fig. 8 illustrates the architecture of the baseline two model.

Baseline Two: the word2vec results and distance calculation.
The categories used in the evaluation for AI-CTO
The baseline three combines both graph structure information and semantic information to represent nodes. In other words, the baseline three model is the combination of baseline one and baseline two. This model also uses the same method to filter irrelevant results out. Fig. 9 illustrates the architecture of the baseline three model.
Baseline Three: the graph structure + description text results and distance calculation.
Our method combines both graph structure information and semantic information to represent nodes, which is the same as that in baseline three. However, while baseline three just takes Euclidean distance as a metric to filter irrelevant results out, our method implements an SVM model to predict whether a software stack is valuable or not.
Single software. As a stack is a set of software, single software will not be a positive sample. Stacks with unpopular software. Normally, the developer tends to use popular software. Therefore, stacks with unpopular software are thought as negative samples.
In addition, software in a stack is represented as vectors, so the stack is represented as the average of the sum of all software vectors.
The categories used in this experiment
To build a software stack, it is important to select appropriate categories. This problem solved by AI-CTO in two aspects. One is the number of companies using the category, which reflects the practicality. Another is the labels related to the category, which reflects the ability to meet user demand. Table 3 shows the categories used in the evaluation of AI-CTO. As the number of labels are too large, the table only records the most weighted label. In fact, the label is for software in the category, the heavier weights mean the more users paying attention to this label, i.e., user demand.
Evaluation with correctness
Evaluation with number of Users
The results of evaluation with correctness. 8 categories used
The results of evaluation with correctness. 8 categories used
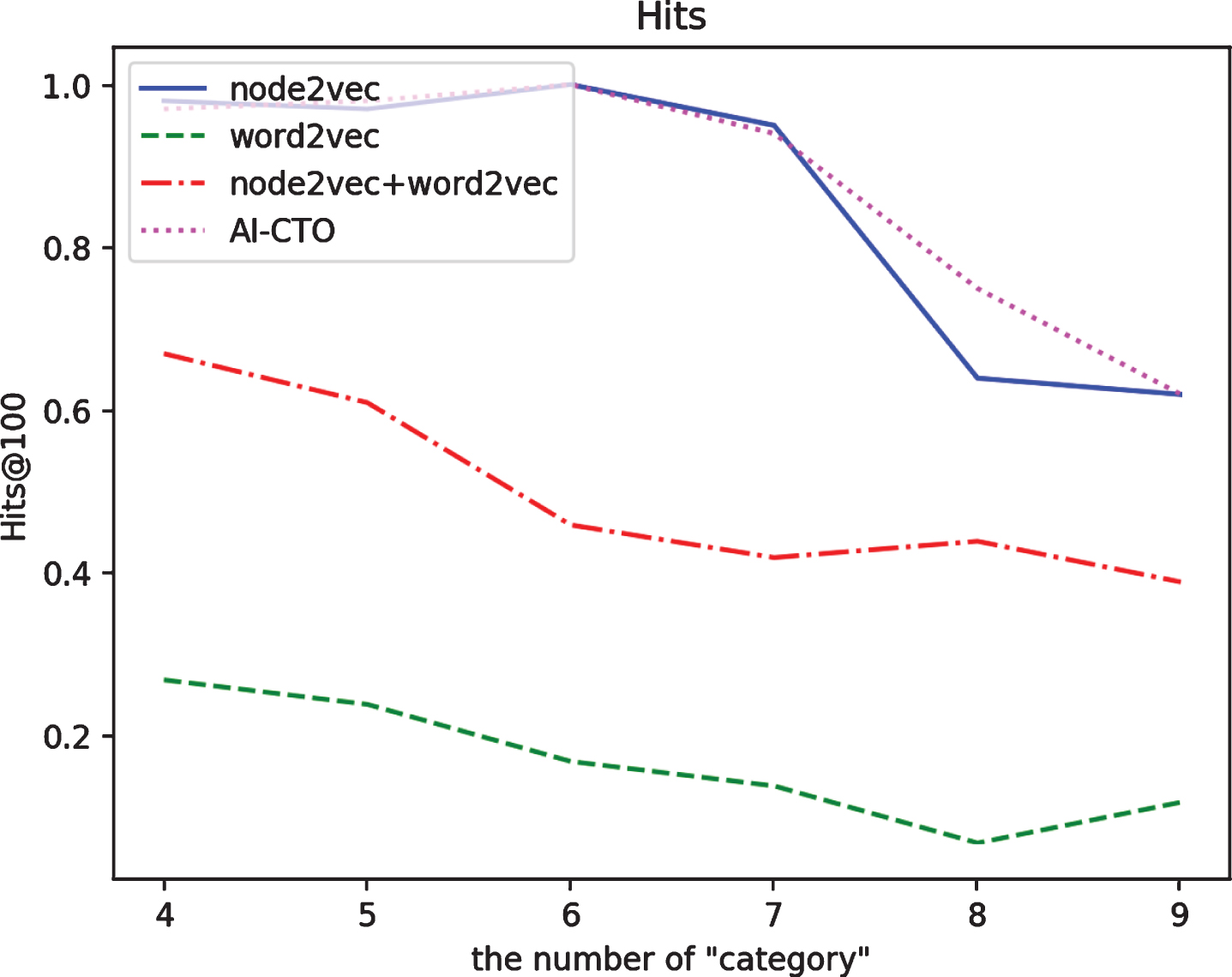
The hits results of different number of “category” in the stack.
The results of evaluation with number of users. 8 categories used
There are defects of AI-CTO, this section discusses the threats to validity and why AI-CTO is still effective.
Treats to software categories
The software stack is built based on the software categories required by developers. For example, a website application may need three kinds of tool, front-end framework, web server and databases. The stacking process selects three tools for the three kinds of tool respectively. Therefore, an important task is determining which categories are needed. Based on the hypothesis that the more companies using this category, the more important it is. AI-CTO choose a category depending on the number of companies using it. Thus, the performance of our method depends on the quality of the technology stack data. In the future, we will try to analyse the characteristics of the software category itself, and then compare it with the results of AI-CTO.
Treats to dataset
As the dataset used in this paper is invariant, the performance of AI-CTO may be affected when new data is generated. However, companies do not adjust their technology stacks frequently. As the idea of AI-CTO is learning from the experience, the “old” data is sufficient to verify the feasibility of AI-CTO. In addition, it is hard to test the integrality of data from stackshare, and it is unable to check whether the technology stack of a company is complete on stackshare.
Treats to software knowledge graph and embedding
Usually, a knowledge graph consists of various entities and relations, i.e., the classification of relations can be different. The different relation can represent more information in a graph. The software knowledge graph in this paper contains only one kind of directed relation with weights. However, the relations in this graph do not include any attributes. As a node is represented by its neighbourhoods, single type of relations is capable to depict the information in the embedding process.
Related work
Software architecture
Software architecture is the blueprint of a system. The architecture reflects the constrained relationships among software components, and those constraints most often come from the system requirements [25]. The modelling of software architecture greatly affects the development performance of practitioners [26]. The research about software architecture gains great attention since the nineties to deal with increasingly software design complexity [27, 28]. To formalise the architectural process, Architecture Description Language (ADL) is used to specify the software architectures precisely, such as Unified Modelling Language (UML) [29, 30], SystemC [31] and Acme5. However, there is not a final conclusion about what extent developers utilise software architecture technologies in software design [27]. In most cases, developers just find a design solution of the software system, but the reason of the solution reflects quality issues for the system [27, 33].
In addition, it is difficult to clearly distinguish the boundary of architecture layer and design layer [4]. In this paper, the “architecture” is considered to be an element of architectural styles. The “design” is considered to be the process of choosing a development tool for each element of architectural styles. The AI-CTO convert the development experience of famous companies to knowledge, i.e., the software knowledge graph. Based on the knowledge, developers choose development tools for each element in the architectural style, which is the software stack solution. It is worth mentioning that the solution derives from the knowledge is interpretable.
Graph embedding
Graphs exist widely in the real world [34], such as social media network, citation graph of research articles, protein molecular structure graph, etc. These graphs contain valuable information that deserves to be analysed. Therefore, this field has received much attention in recent years. A significant number of researches about graph analytics are proposed, such as personalised recommender system [35], entity/node classification [36], relation prediction [37], entity/node clustering [38], etc.
Early technologies are built based on the symbolic representation of graphs, i.e. triples. However, due to the complex structure of graphs, these technologies are computationally inefficient when dealing with large-scale graph [39]. To solve the problem, graph embedding has been presented for embedding entities and relations between them into a continuous low-dimensional vector space [40]. In fact, graph embedding overlaps in graph analytics [41] and representation learning [42]. The purpose of graph analytics is to extract valuable information from graph data. Representation learning transforms raw data into a form that can be effectively developed by machine learning technologies. A common idea is extracting normalised data from graphs by graph analytics and applying representation learning to the normalised data. For example, DeepWalk [43] generates sequence data (paths in the graph) which is similar to text by limited random walk from input graph and then uses the node id as a “word” to learn the node vector with Skip-gram model. On the basis of DeepWalk, node2vec [8] defines a bias random walk and still uses Skip-gram to train. The walk mode can be changed by adjusting the bias weights, thus retaining different graph structure information, such as walk modes of BFS and DFS.
There are also graph embedding technologies using predefined graph structure as features. The embedding work in TransE [6] is done by adjusting the relation in a triple. For example, a triple (h, r, t) holds means Vector h + Vector r ≈ Vector t . This provides insights into how to build the energy function, i.e. ||h + r - t||l1. Obviously, transE works ineffectively on one-to-many and many-to-one relation problems. TransH [44] embeds h and t to a vector space while embedding r to a hyperplane, i.e. (h → h′), (t → t′). The triple (h, r, t) holds means Vectorh′ + Vector r ≈ Vectort′. Moreover, TransR [45], TranSparse [46], TransAt [47], Adversarial Graph Embeddings [48], DELN [49], JANE [50], MTNE [51], etc also presented efficient methods to solve problems in this field.
Auxiliary information
The input data of graph embedding is diverse, such as the whole graph, nodes, and edges. There can be certain auxiliary information for nodes and edges, such as text descriptions, attributes, labels, and etc, which can be used to enhance the performance of graph embedding. The challenge is how to incorporate the auxiliary information in graph embedding model and how to combine it with graph structure information.
Xie et al. [39] propose two encoder, i.e. continuous bag-of-words and deep convolutional neural models, to transform semantics of entity description into vectors. They then define an energy function, i.e. E = E S + E D , to combine description-based representation and structure-based representation. E S is the energy function of TransE to represent the structure information. E D is the energy function of description-based representation and defined as: E D = E DD + E DS + E SD , where E DD = ||Vector h d + r - Vector t d ||. Vector h d is the description-based representation of head node in the triple. E DS and E SD are analogous to that.
Wang and Li [52] use rich context information in an external text corpus to assist in representation learning of the knowledge graph. Similar to distance supervision, they first annotate the entity back to the text corpus to obtain a co-occurrence network consisted of entity words and other important words. The network can be regarded as the link between the knowledge graph and the text information. The context of entities and relations is defined based on the network and integrated into the knowledge graph. Finally, the representation of entities and relations is learned by a translation model. Other auxiliary information is also used to improve the performance of graph embedding, such as relation [53], attribute [54], etc.
Conclusion and future work
This paper proposes AI-CTO, a novel method to automatically suggest software stack solutions. The basic idea of AI-CTO is converting the development experience of famous companies to knowledge, i.e., software knowledge graph. The software stack solutions are derived from the knowledge. To reach this end, we embed the software knowledge graph to a low-dimensional vector space. In addition, we combine embedding of software descriptions to make the graph embedding more precisely. The evaluation of AI-CTO consists of two research question to analyse its effectiveness. The results show that AI-CTO can suggest effective solutions and outperform other baselines. We will explore the following research directions in future: (1) It is possible to include more features for software, such as the code features of open-source software. (2) The description encoder only considers software descriptions and name for embedding, while there are various information, which is possible to be utilised in future. (3) There are no attributes for relations in the software knowledge graph. It is able to include more information for relations between entities in future.
Acknowledgment
This work is supported by National Key R&D Program of China (No. 2018YFB0803600) and National Natural Science Foundation of China (No. 61772507).