
Abstract
Dynamic signature recognition emerges to perfectly solve the hygiene concern due to its no-contact characteristic. Nevertheless, the recognition of dynamic texture is challenging compared with the static signature image due to their unknown spatial and temporal nature. In this work, we present a multi-view spatiotemporal approach based on spectral histogramming for hand gesture signature recognition. A Microsoft Kinect sensor is adopted to capture the motion of signing in a sequence of depth frames. The depth frame sequence is viewed from three directional sights to retrieve rich information, such as temporal changes at each spatial location, the signing motion flow of each vertical and horizontal spatial space in a temporal manner. Furthermore, the proposed approach performs feature description on different levels of locality. This function enables a multi-resolution analysis on this dynamic signature. The robustness of the proposed approach is reflected with the promising result by striking the state-of-the-art performance, as substantiated in the empirical results.
Introduction
For the past 40 years, handwritten signature is le-gally used to represent the identity of a user, and the intention of that user. Its meaning has remained the same in worldwide and has become a tradition. Sig-nature recognition system is widely accepted by society for proof of identity in any kind of legal and financial transaction. It is a behavioural biometrics that encodes measurable patterns of a signature. Signature recognition can be conducted in two ways: (1) static/offline mode, and (2) dynamic/online mode [1]. In static mode, users sign their signatures on a paper and the signatures are digitized through an optical scanner or a camera. The biometric system recognizes the signature by analysing the shape of the signature. In dynamic mode, users sign their signatures by using a special hardware device, i.e. digitizing tablet with stylus pen or smart devices with touchscreen functionality [2, 3]. The biometric system encodes these dynamic characteristics of the signing motion, such as spatial coordinates, pressure, azimuth, inclination etc. Undeniably, dynamic mode is more secure than static mode because it is unlikely for a forger to exactly imitate the dynamic features of the signatures [4].
Recent research community has extended the focus on dynamic signature specifically putting significant efforts in the acquisition of the signature. Research works in [5] and [6] uses wrist-worn devices to acquire the hand written actions. However, users would need to wear the devices such as smart watches or digital fitness trackers on the dominant hand in order to acquire the data. [7, 8] introduced a novel device-free acoustic sensing which requires no contact to any device. It uses inaudible sound from the device’s speaker to capture the pen motion during the signing process. Although it is contactless, it is vulnerable to external voice.
In this paper, we proposed a device-free signature recognition system, which is insensitive to external obstructions, and requires only a low-cost acquisition sensor. This system is termed as hand gesture signature recognition. This recognition system manipulates the spatio-temporal information of the hand gesture that is formed by the positional data and the entire progression of hand movement. The non-contact practice of this system perfectly solves the hygiene concern raised by public, especially those germ conscious users [9]. Microsoft Kinect sensor is the most preferred acquisition tool considering its depth sensing and affordable price [3–7]. The temporal dynamics captured by Kinect are the key features in hand gesture signatures. This dynamic texture embraces the sequences of video frames that manifest certain stationary properties in time [14].
The rich information of hand gesture signature is indispensable to distinguish hand gesture signatures. However, the recognition of dynamic texture in the signatures is challenging due to unknown spatial and temporal nature. Major concerns pertaining to this dynamic texture recognition include: How to effectively combine the motion features with appearance features? How to encode features which are impervious to image transformations such as rotation and translation? How to perform multi-resolution analysis to obtain a description of the dynamic signature on different levels of locality?
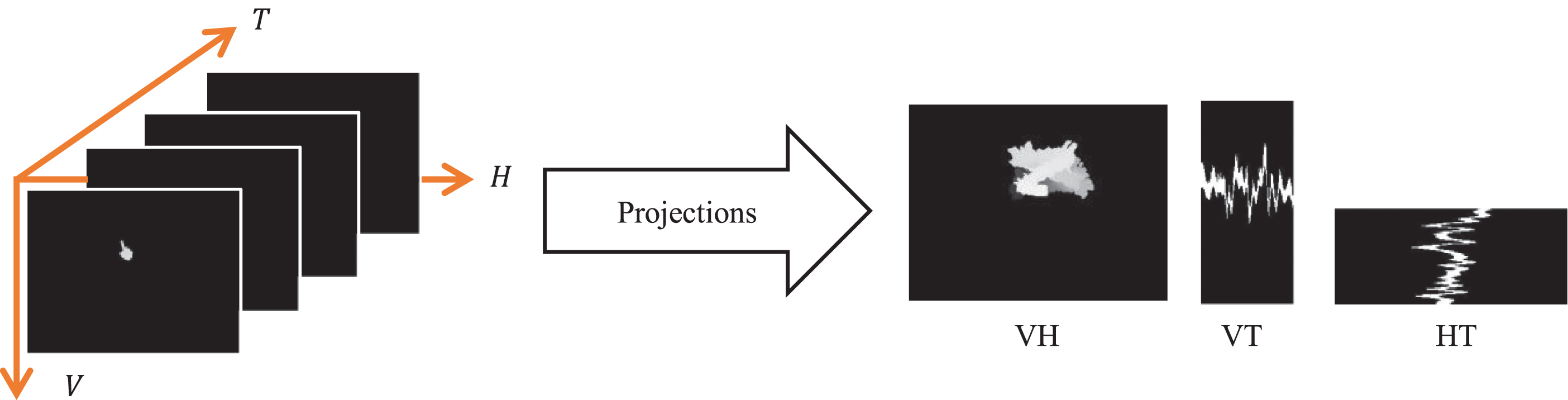
Projection of volume data into three sets of 2-dimensional data image: Vertical-Horizontal (VH) plane, Vertical-Time (VT) plane and Horizontal-Time (HT) plane.
In this proposed system, a Microsoft Kinect sensor is used to capture the signing motion and store them in a sequence of depth images. The unprocessed depth images usually contain abundant unwanted information such as background and unwanted body parts. Hence, palm detection and palm segmentation process is conducted to eliminate these noises.
The depth frame sequence can be viewed from three directional sights to retrieve rich information, such as temporal changes at each spatial location, the signing motion flow of each vertical and horizontal spatial space in a temporal manner. Figure 1 illustrates the three directional views of a signing motion sequence: Vertical-Horizontal (VH) plane, Vertical-Time (VT) plane and Horizontal-Time (HT) planes. From the figure, it is observed that each plane carries different degrees of motion and appearance information. To effectively amalgamate both motion and appearance features of hand gesture signature, a multi-view spatiotemporal approach based on spectral histogramming is proposed.
Local histogramming process is performed on block-wise plane images to extract the texture properties of the image blocks. These texture descriptors not only preserve spatial information, but also provide certain extent of translational and rotational invariance [15–18]. The spectral histogram descriptor of each plane image is a set of marginal distributions of its projected plane. They are formed based on different filter responses, encoding different levels of local structures corresponding to the types of projection panels. Hence, concatenating and analysing the local histogram descriptors of the three orthogonal planes enables feature description on different levels of locality. This function empowers a multi-resolution analysis on this dynamic signature.
The proposed approach is termed, as Dynamic Spatiotemporal Spectral Histogramming (DSSH). The contribution of this paper is threefold: Motion and appearance features are effectively integrated into three projected planes for three directional views: VH plane carries a history of temporal changes of the pixel at each spatial location, VT plane describes the motion of each vertical spatial space in time and HT plane gives expression of the motion flow of each horizontal dimension in a temporal manner. Texture features, which are extracted in a small local neighbourhood (i.e. block), via spectral histogram descriptor are impervious to translation and rotation. A description on different localities (i.e. block-wise histogramming description on the three orthogonal planes) allows multi-resolution analysis on the dynamic signature.
The rest of the paper is organized as follows: a brief discussion of related works in Section 2; Section 3 details the proposed approach including processes of data acquisition, data pre-processing, feature extraction and classification. Experimental analysis and justification are reported in Section 4. Finally, concluding remarks are presented in Section 5.
In the early stage, a traditional colour camera was used to capture a gesture movement in video sequences. Hand detection was accomplished by using the colour and shape information obtained from the camera. In [19], Irteza et al. proposed an approach to perform hand detection based on skin colour from the colour image. Hidden Markov Model (HMM) was applied to the gesture. Nonetheless, methods based on colour images were suffering from the incorrectness of locating the exact region of interest (ROI) [20]. Furthermore, tremendous efforts are required to overcome the lighting variations, the complexity of background colour, as well as the lack of depth information. Wearable technology was recommended to compensate for the drawbacks of poor hand detection accuracy and environmental factors [11, and 13]. However, hygiene issue arises as the main concern since this wearable equipment is to be shared among the public. Radar sensors have been proposed for dynamic hand gesture recognition, for instance in [21–23]. These radar-based approaches utilize micro-Doppler analysis and are independent to various lighting illumination. Therefore, these devices could be a good alternative for traditional colour camera.
The entry of low-cost Microsoft Kinect sensor camera to the market in the year of 2010 [26] stretched the research further by not only providing the colour image data, but also endowing an additional dimension, i.e. depth information. This information is useful in object extraction and detection. Availability of depth property makes hand gesture recognition more robust, reliable and independent to the complexity of background and variability of lighting environment. Some prior works had shown the effectiveness of hand detection and extraction by using depth images. In [20], Vinh et al. proposed a straightforward way in extracting a hand region via thresholding the detected hand point on a depth image. Support Vector Machine (SVM) was adopted to recognize different hand gestures. In addition, [27] presented an approach of hand segmentation based on Kinect sensor depth image. The proposed approach retrieved the gesture track based on the depth image information captured by the Kinect sensor. The provision of depth information has motivated researchers to work in hand gesture signature based on gesture recognition, populating a new research area known as hand gesture signature (HGS) recognition.
In line with this field, a number of studies engaged the usage of Kinect sensor in the context of handwritten password or signature recognition for identity authentication purpose. A handwriting-based authentication system has been proposed by Tian et al. [9] that utilizes Kinect to capture short and easy-to-memorize passwords as the main input to the system. Noted that the input data is not one’s handwritten signature but a simple “password” motion created by the user. Fingertip’s location of each frame was identified and sequentially connected to construct a 3D-signature. Local features were extracted from the raw signature. Dynamic Time Warping (DTW) was applied to quantify the similarity between signatures.
In [28], the authors proposed to integrate in-air signature into a home entertainment system. Similarly, a Kinect sensor was used to capture the signature motion and trace the signature trajectory. Four different validation tests were conducted and Neighbourhood components analysis (NCA) was employed to learn a linear projection of the features. Distance between signatures is measured by normalized Euclidean distance and k-Nearest Neighbours classifier is adopted for classification. A survey reveals that most of the responders show their preferences to use their personal genuine signature rather than a memorable password.
In [10], the authors acquired a real-time hand gesture signature by using Kinect sensor. Several local features were derived from each signature trajectory as hand gesture representation. Finally, DTW was employed for similarity measurement. The similar feature extraction approach was used by Hwang et al. [11] to generate 30 types of 3-dimensional features from a hand gesture signature. All of them were derived from the signature trajectory. The high feature dimension was reduced to 10 principal components through Principal Component Analysis (PCA). Artificial Neural Network (ANN) was adopted as the main classifier to distinguish variants of complex signatures.
Besides, [29] proposed a mobile-based authentication system for HGS system. The hand signature captured by the on-phone accelerometer is used for phone access control. The signature gesture is described in a sequence of accelerometer signals. Signals are preprocessed through a series of signal processing processes before an absolute distance is computed to measure the dissimilarity of HGS.
Recently, a HGS work has been proposed by [30] which employs PoseCNN to locate the fingertip of hand in the 3D volumized data. Both spatial and temporal information are extracted and fused. Lastly, a multi-dimensional Dynamic Time Warping (MD-DTW) is adopted to compute the similarity between the data.
It can be seen that the aforementioned research works utilize signature trajectory or accelerometer signals as the basis of feature derivation, and manifests both positional and temporal information of hand motion. However, the shape, scale and orientation of hand, which are considered as important entities, are not acquired.
In our previous work, we utilized the image sequences captured by a Kinect sensor to generate a set of 3-dimensional data [12]. We postulated that the visual representation of hand gesture could be an important feature to reveal the personality of users. The dimension of input data was reduced to a 2D Motion History Image (MHI). The projection features and Histogram of Oriented Gradient (HOG) features were then extracted from the MHI templates. Accuracy of 90.4% and error rate of 3.22% were attained in both identification and verification systems. The drawback of this approach is temporal information, one of the major characteristics of HGS, might not be explicitly described. This could lead to information loss due to occlusions caused by the overlapping of the active region frames in the condensing process. This degrades the quality of feature and affects the system performance. In viewing of this, a multi-view spatio-temporal representation is proposed to better extract spatiotemporal features from the raw depth image sequences of hand gesture signature.
The proposed system
To the best of our knowledge, there is no literature assessing both motion and appearance features of HGS from different directional sights. Our proposed approach is able to discover temporal changes at each spatial location as well as the signing motion flow in a temporal manner through the projections of three directional sights. Furthermore, the proposed approach is also able to describe features based on different levels of locality. This function enables a multi-resolution analysis on this dynamic signature.
The low cost and the strong capability of providing the depth map of a target make Kinect to be a favoured acquisition sensor in hand gesture signature recognition. Microsoft Kinect is also adopted in this study to extract the depth information from hand gesture signature. Temporal information express is significantly along the axes of V and H, as appeared in the VT and HT planes in Fig. 1. Hence, the flow of hand gesture with respect to time is more discernible because the data is presented explicitly as a flowing path in both planes.
Basically, this proposed system comprises of four stages: (1) data acquisition via Microsoft Kinect sensor, (2) data pre-processing for obtaining region of interest, (3) feature analysis for transforming a 3D volume data into 3 types of data planes, then describing the signing motion on different levels of locality, and (4) accuracy performance based on k-nearest neighbour (k-NN) with different distance metrics. Figure 2 illustrates the overview flowchart of proposed method.

Overview flowchart of proposed method.
A Microsoft Kinect sensor camera v1 (model 1517), as shown in Fig. 3, is used as an acquisition device to collect the handwritten signature video. This model of sensor can support up to a maximum of 30 fps for depth data. Considering the potential delays that may caused by hardware or software limitation, we set the frame rate at a range of 27 to 30 fps. Each captured video frame has a resolution of 640×480 pixels with 16-bit grey level. Participants are required to stay firm within the acquisition platform, as illustrated in Fig. 4, to prevent any potential signing motion is out of camera view.

Data acquisition sensor used in the proposed project.

A subject is signing at the acquisition platform.
Usually, the captured video data contains various noises and unwanted objects. Therefore, a data pre-process is conducted to remove them and extract only the region of interest, i.e. palm region. A signer’s palm is always the nearest object from the sensor and will be treated as foreground in this study. This palm region is detected by calculating a set of non-zero minimum values of the pixels from the depth image. Let Di,j be the depth value of a pixel in the palm region, i and j represent the pixel spatial location. The coordinates of all minimum depth pixels in the palm region are averaged and the computed centroid of a point is treated as the representative point of the palm region. Figure 5 illustrates the representative point of the palm.

Palm location detection in a depth image. The yellow circle is the representative point of the palm region.
Next, the palm region (foreground) is segmented from the background including the unwanted signer’s body parts. A thresholding method is applied to extract the region of interest. A predictive palm segmentation algorithm is adopted. More information of the palm segmentation can refer to our previous paper [12].
The difference between still image data and video data is the later enclosed temporal information. This temporal content is of vital importance to the dynamic texture understanding, especially in the analysis of motion. Hence, in this paper, an efficient spatiotemporal descriptor is proposed. A video is a sequence of frames across the time (T) dimension, and it can be visualized as a stack of Vertical-Horizontal (VH) planes spanned along T dimension. On the other perspective, we also can visualize a video as a set of Vertical-Time (VT) planes straddled across the horizontal (H) axis, as well as a stack of Horizontal-Time (HT) planes in the vertical (V) axis. In short, a video volume is treated from the viewpoint of three different stacks of planes (VH, VT and HT planes).
In this work, we perform projection of the video frames along H axis via the summation of the volume data along H axis to compute VT plane. A similar process is performed on the data frames along V axis for calculating HT plane. These VT and HT planes impart information about the space-time transitions. The process of generating VT and HT planes is illustrated in Fig. 6.
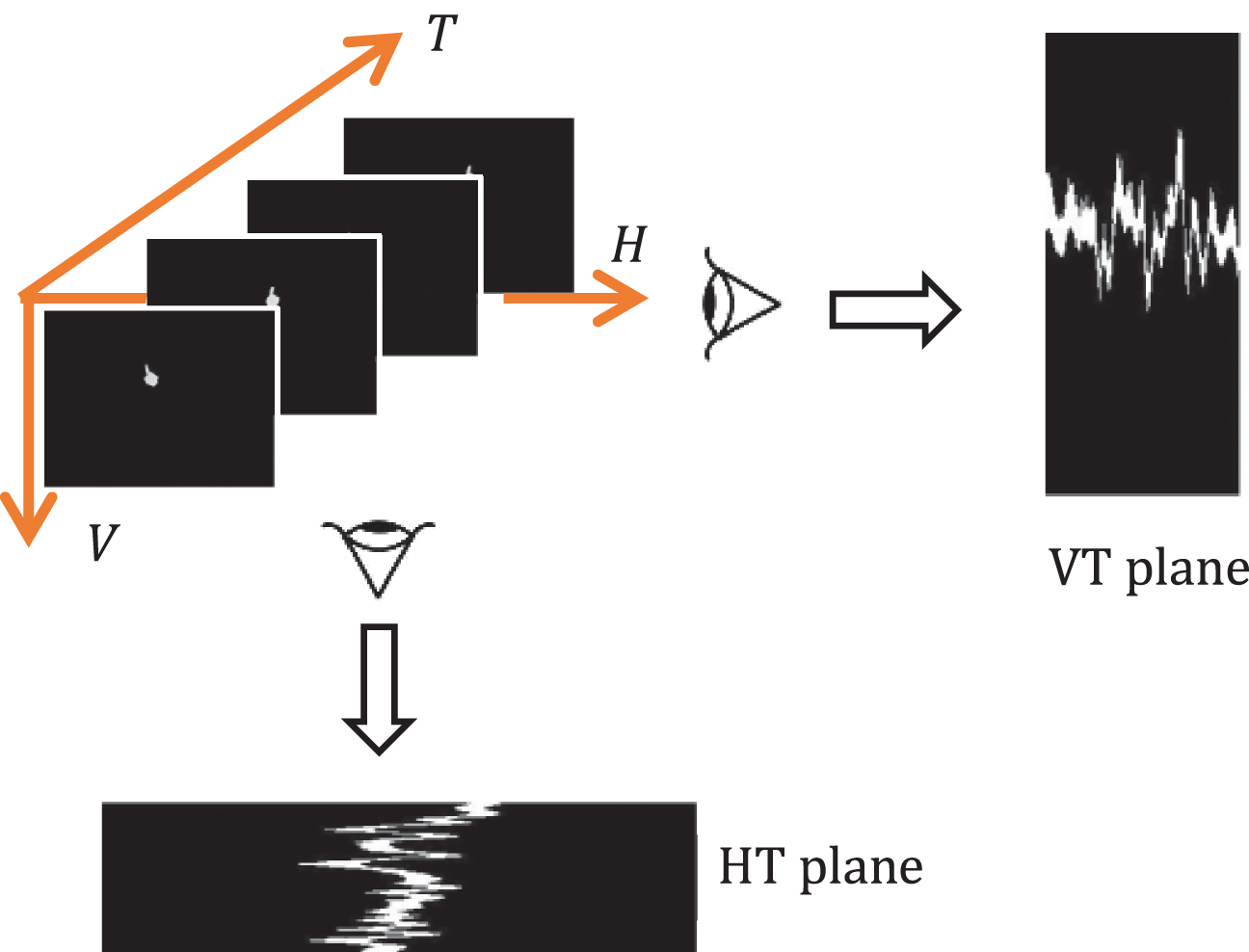
VT and HT planes generation from volume data.
Instead of summating the volume data along the T axis, which the temporal information is neglected, motion history plane (VH) is computed by performing Motion History Image (MHI) [31]. MHI condenses the sequence of frames along the T axis into a grey-scale template and preserve the motion information in a more compact form [32]. MHI is a gradual process function to adjust the recency of motion at each pixel location over a period of time. In other words, the MHI pixel intensity is a function of the motion history at that location, where brighter values correspond to a more recent motion. The update function of MHI at position (x, y) can be defined as,

Samples of VH planes of two different users (each row for one user).
The Binarized Statistical Image Feature (BSIF) code is extracted from the VH, VT and HT planes, in which the statistics of these three planes are obtained and then concatenated into a single histogram to represent the signing motion. The procedure is demonstrated in Fig. 8.
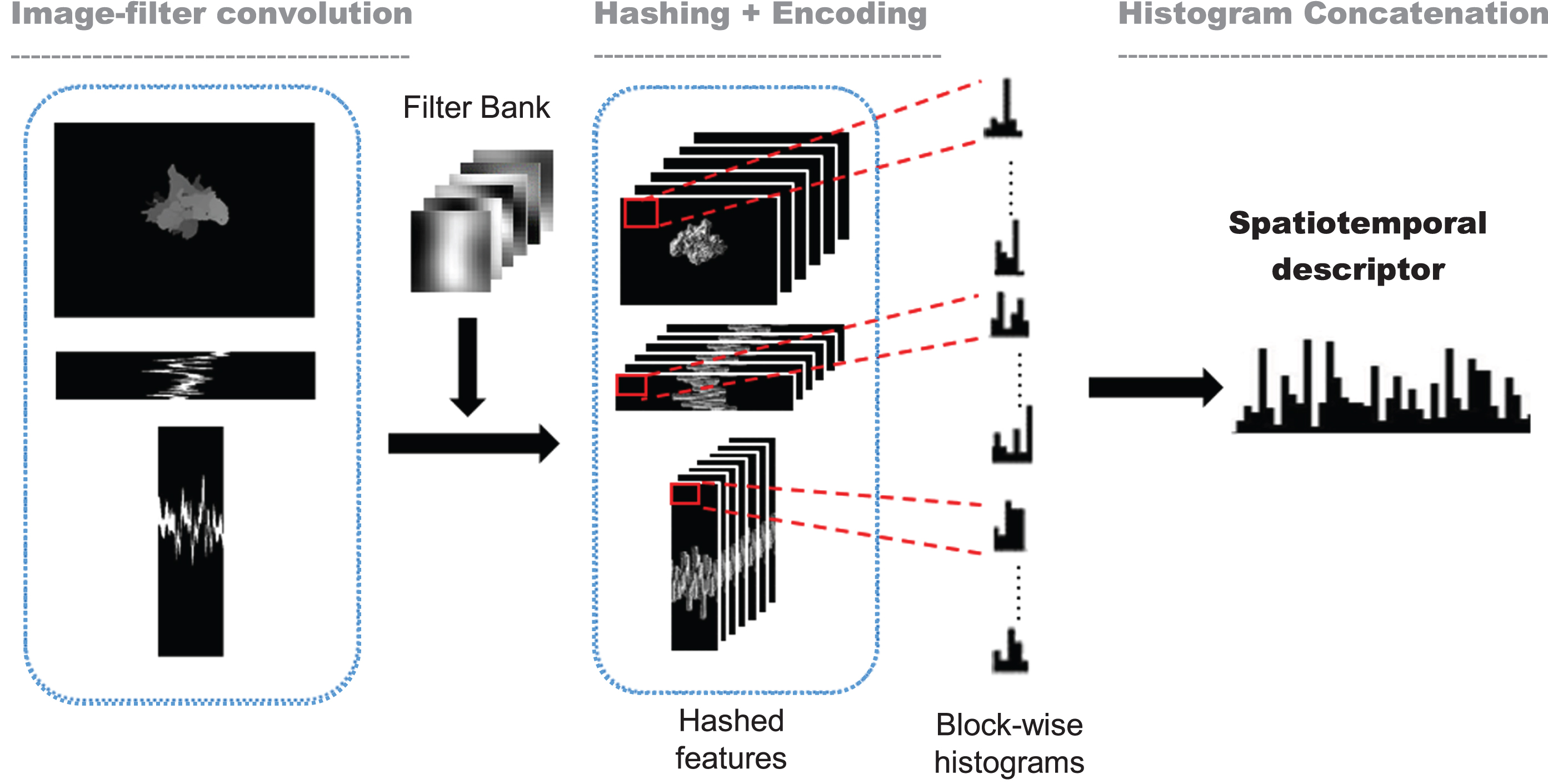
Feature description process on the three orthogonal planes.
Firstly, each plane is convolved with a set of filters learned from natural images by maximizing the statistical independence of the filter responses [15]. This process is to retrieve the most salient micro-structures via local matches. Secondly, each filter response is applied to a nonlinear hashing operator and a bit of “1” is assigned to those positive coefficients and a bit of “0” to otherwise. This binary hashing improves the memory efficiency as well as computation time. In addition, the binary descriptor is also robust to local variation [33]. Next, the binarized responses are decimalized into integers, ranging from 0 to 2 n -1, termed as code map where n is the bit coding of the filter. In what follows, the code map is regionalized into non-overlapping blocks and then recapitulated into block-wise histograms. Lastly, the regional histograms are concatenated into a global histogram representation to estimate the underlying distribution. In such a way, we can effectively obtain a description of the signing motion on three different levels of locality. The bins of the histogram derived from the three projected planes hold motion and appearance information at the pixel level. The bins are summed over each small block to construct information on a regional level expressing the attributes of the spatial and motion in specific locations. All information from the regional level is then concatenated for global description of the signing motion.
For the sake of simplicity, a simple classifier, KNN is employed in this study for classifying the extracted spatio-temporal based features for hand gesture dynamic signature recognition. The implementation is based on one-vs-all (OVA) approach. In other words, it combines multiple binary classifiers to solve for the multiclass problem. OVA involves creating multiple binary classifier models for a single test class against the remaining samples in the dataset which is denoted as the opposite class.
Experiment and evaluation
In this section, we will present the details of the dataset, experimental design as well as the obtained empirical results, followed by some discussions and analysis of the results.
Dataset
A total of 100 participants participated in the data collection. The collection process took four months’ time and was conducted in two sessions with the gap of 2 to 3 weeks. In each session, 10 hand gesture signatures per subject were enrolled. Hence, the whole dataset comprises 2000 hand gesture signatures. The characteristics of the participants are summarized in Table 1. Details of this database were disclosed in our previous paper [12].
Characteristics of the participants in data collection.
Characteristics of the participants in data collection.
In data pre-processing, there are two parameters to determine: (1) threshold value for palm segmentation t hand , (2) range of radius threshold in the predictive palm segmentation r. t hand is determined through inspecting the palm size (i.e. distance from fingertip to wrist). On the other hand, r is the radius of the closest point between two consecutive image frames. For determining the optimal values of these parameters, a heuristic approach was used based on 40 randomly selected sample data. The empirical results show that t hand = 180 and r = 85 demonstrating the optimal performance on the subset database. These values will be adopted in the subsequent experiments.
Accuracy rate of proposed DSSH with different distance metrics.
Accuracy rate of proposed DSSH with different distance metrics.
In data analysis, (1) filter size l and (2) the number of filters b in the filter bank are the user-defined parameters. Various values of these parameters have been tested, i.e. l = [3,5, ... ,17, 3,5, ... ,17] and b = [6,7,...,10, 6,7,...,10]. From the empirical results, l = 11 and b = 8 obtain the optimal performance. Hence, the values are used in the subsequent experiments.
For sake of simplicity, the nearest neighbour classifier is adopted for recognition task. Four different distance metrics are rigorously used to calculate the dissimilarity scores of the matching: Euclidean distance (Eucl), Cosine distance (Cosine), Chi-Squared distance (Chi Sq) and Manhattan distance (L1). In this study, we adopt 5-fold cross-validation. In each fold, samples of the database are randomly divided into two subsets: probe set B and gallery set G. To be specific, at each fold run, 10 samples are randomly selected from the 20 samples that belong to the same subject. These 10 samples are set to be the probe samples, whereas the remaining 10 samples are treated as gallery samples. This process is repetitively held for each subject.
Accuracy metric is presented in our work which can be defined as:
Table 2 records the performance accuracies of the proposed DSSH on different distance metrics, each tested on 5-fold cross-validation. Average, as well as standard deviation of the rates, are also calculated and disclosed in the table. We can observe that the performance of the proposed DSSH is relatively consistent due to the relatively small standard deviations obtains across the five dataset folds. This indicates that the proposed DSSH is relatively stable to deal with different sets of gallery and probe data. For better illustration, the average performance accuracies of the four distance metrics are depicted in Fig. 9. Accuracy performances of the proposed DSSH with distance metrics of Euclidean distance (Eucl), Cosine distance (Cosine), Chi-Squared distance (Chi Sq) and Manhattan distance (L1). Chi-squared distance metric is an effective measure for comparing histogram-based features [34]. Hence, it excels all other distance metrics escalating its usage in histogram matching.
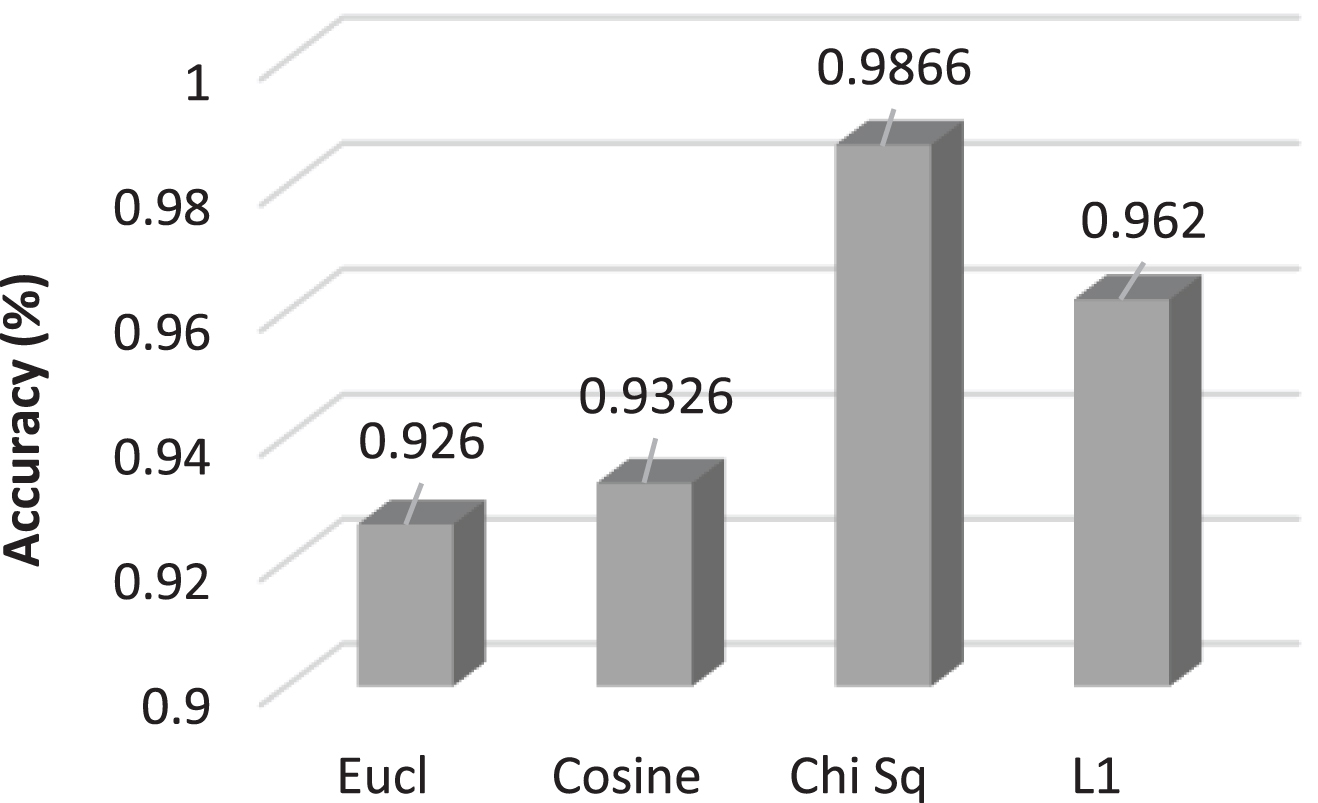
Accuracy performances of the proposed DSSH with distance metrics of Euclidean distance (Eucl), Cosine distance (Cosine), Chi-Squared distance (Chi Sq) and Manhattan distance (L1).
In this section, a thoroughgoing experiment is conducted to divulge further insight into the behaviour of the proposed approach. Firstly, the performances of each orthogonal plane: VH, VT and HT, as well as their combinations, towards the competency of the proposed DSSH system in signature recognition are investigated.
Comparison with different sets of orthogonal templates: Three basic orthogonal planes, i.e. VH, VT and HT, are generated and utilized as the inputs for local feature analysis. In this study, the influences of each single and combinations of orthogonal templates are examined: Vertical-Horizontal (VH) template. Vertical-Time (VT) template. Horizontal-Time (HT) template. Vertical + Horizontal-Time (VT + HT) template. Vertical-Horizontal + Vertical-Time + Horizontal-Time (VH + VT + HT) template.
Fig. 10 illustrates the performance accuracies of the proposed DSSH with different inputs of orthogonal templates. Based on the results illustrated in the figure, the highest accuracy of 98.66% is achieved with the proposed DSSH with the input of VH + VT + HT template. At the same time, its standard deviation score is the lowest among the rest, denoting that their distribution is more centered and precise. Thus, we discern from the experimental results that DSSH with VH + VT + HT template is more generalized to cater any sets of gallery and probe data.
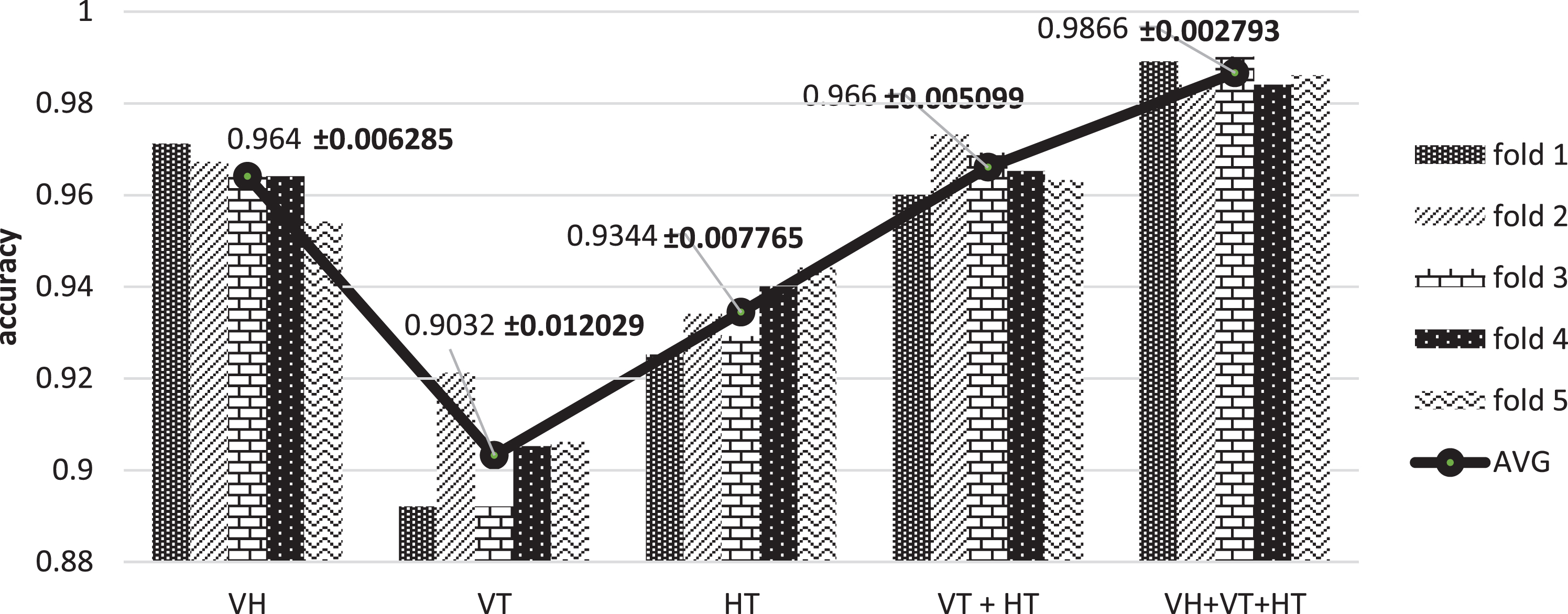
Contributions of each, as well as a combination of, orthogonal template towards the performance of DSSH system. A±B indicates the average value (AVG) and the standard deviation value across the five runs in the cross-validation.
From the figure, we can observe that the proposed DSSH with the input of VT template, as well as HT template, each showing inferior performance, i.e. 90.32% and 93.44% accuracy respectively. However, it does not mean that these two planes contain no significant features in terms of distinguishing between dynamic textures. The information that describes the motion of each row or column in temporal space, appended in the VT or HT template, undoubtedly contains some useful information. The inclusion of these two templates (VT and HT) to VH template (96.4% accuracy) is able to boost up the recognition performance with 2.26%, rising to 98.66% accuracy.
Comparison with different numbers of training samples: Different training sample sizes were conducted in a gradient manner in this study to examine its influence towards the performance of the proposed DSSH. The dataset is partitioned into two subsets: training set and validation set. TM/PN means M video clips are randomly selected for training and the remaining N video clips are used for validation. The reported experimental results are averaged over five runs on a randomly selected training set. Table 3 records the performance accuracies of the proposed DSSH with different TM/PN. From the results, there is a slight performance degradation when a smaller training sample size is employed. When the training sample size is reduced to 40%, i.e. 10/10 to 6/14, a minor performance relapse, i.e. 2.2% accuracy, is observed.
Accuracy Performance with different ratios of the number of training sets and number of validation sets, TM/PN.
DSSH attempts to extract the representative knowledge from the training samples in the training phase. However, it may be hampered by the lack of training samples. The small numbers of training samples are not able to capture all the possible variations resulting from different hand gesture poses and motion speed, varying lighting conditions etc. This exerts a challenge to the proposed system in classifying a probe data. This explains the system performance is deteriorated when smaller training sample size is used.
Influence of training sample size on orthogonal templates: From the above study, we observe that there is a certain degree of effect for different orthogonal templates to the robustness of the proposed DSSH approach. In this study, we will examine how impactful those orthogonal templates are when a small sample size is applied. It could be seen from Fig. 11 that VH + VT + HT yielded the best accuracy performance while input VT performed the worst among them. It is also observed that the 50/50 ratio of training samples and testing samples slightly outperformed those with lesser training samples.

Accuracy performance with different training sample sizes on different orthogonal templates.
Influence of filter size and string bit: Next, the effect of various filter sizes and bits in the code string are examined. Figure 12 illustrates the performance accuracies of different filter sizes, ranging from the size of 3×3 to 17×17 with 8 bits of code string. It is observed that the performances are increasing while the filter size increases; except the size of 11×11 which slightly loses its trait of increasing. The input of VH + VT + HT template into our proposed method shows consistent prominent performance than other planes or combinations of planes. This again reveals the robustness and enlightenment of VH + VT + HT template as feature representation.

Average accuracy performance with different filter size with 8-bit string.
Figure 13 demonstrates the performance with varying string bits, with filter size of 17×17. The empirical results illustrate the steady improvement in performance when inclining to 8 bits string, but the plots are declining from 9 bits string and onwards. This is because higher bit strings are carrying higher frequency information which customarily causes the blurriness to the images. Therefore, the performance is degraded.
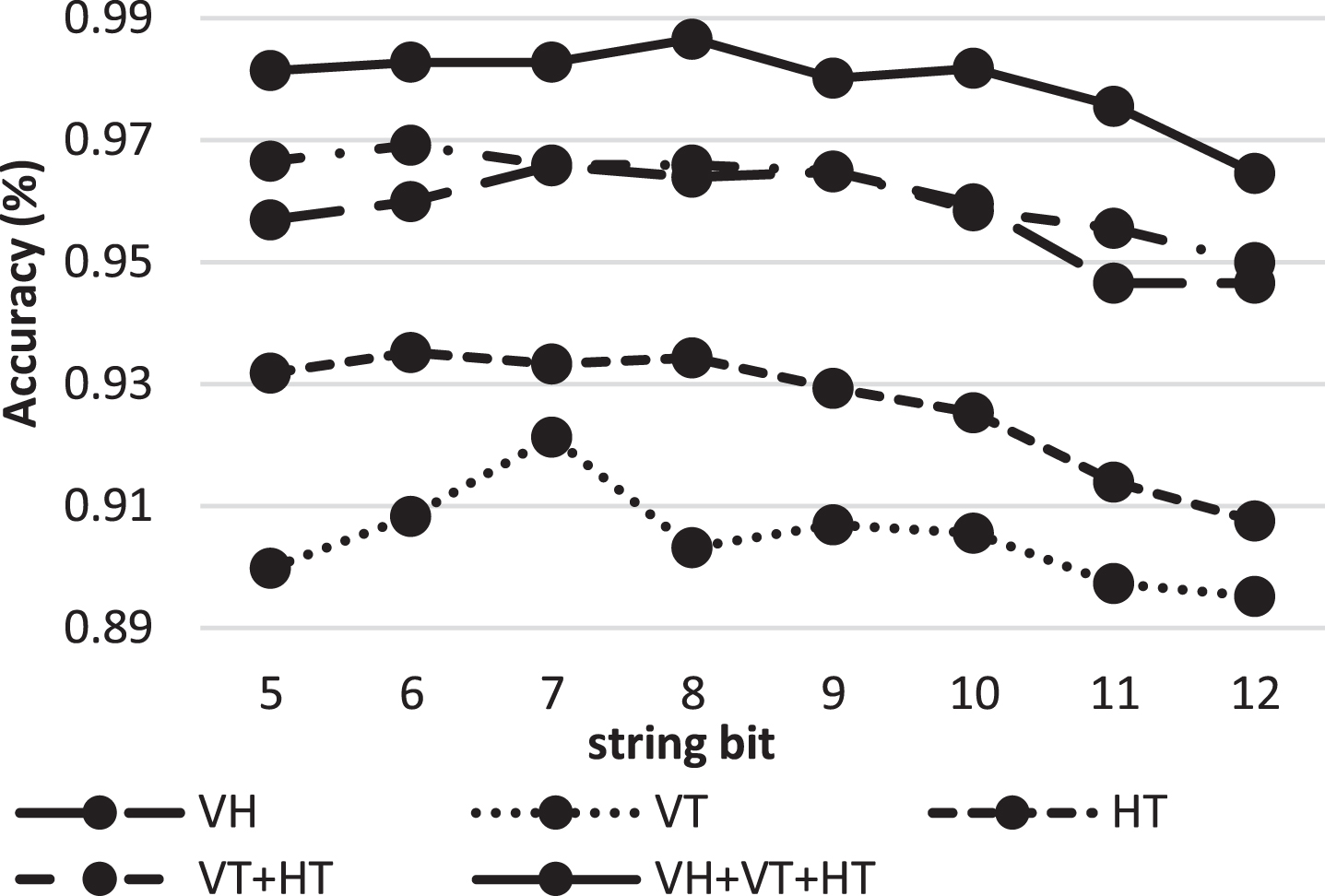
Accuracy performance with different bits.
Comparison with other existing approaches: For a thorough evaluation, some existing hand gesture signature systems are compared. Recognition performances of these techniques are extracted from the original papers. The parameter settings of the techniques are based on the optimal parameters as proposed in the original papers. Both trajectory and imagery approaches take into account the spatial and temporal data. However, the trajectory approach only tracks the path of fingertip or centre of hand during the signing. On the other hand, besides tracing the flow of hand movement, the imagery approach also accounts the hand shape and hand orientation during the signing. From Table 4, we can observe the inferiority of MHI + KNN. This is because the information loss due to occlusions caused by the overlapping of the active region frames degrades the quality of feature. Instead, it is observed that the proposed DSSH is superior to, or on par with, the systems. This validates that the rich and significant feature representation is attained though the multi-view, multi-resolution analysis in DSSH.
Comparison of DSSH with other existing approaches.
In this paper, we present a spatiotemporal approach based on spectral histogramming, namely DSSH that consists (1) palm detection and segmentation, (2) projection of depth data into 3 sets of image data: Vertical-Horizontal (VH) plane, Vertical-Time (VT) plane and Horizontal-Time (HT) plane, (3) data feature learning via filter convolution and (4) nonlinear feature description through a sequence of feature binarization, block-wise histogramming and concatenating histograms to be global descriptor. The robustness of DSSH is reflected with the great result by striking the state-of-the-art performance, as substantiated in the empirical results.