
Abstract
Massive digital documents on Internet leading to use e-learning, and it becomes an emerging field of research due to the massive growth of internet users. E-learning requires suitable document ranking method to avoid navigating to the next Search Engine Result Page (SERP) frequently. The existing document ranking methods are lacking to rank the documents independently based on the conceptual contents. This paper proposes a novel method for ranking the documents independently based on the different classification of term it contains. In this approach, the terms are classified into five categories such as (1) direct query term, (2) expanded terms, (3) semantically related term, (4) supporting terms and (5) stop words. The query has been expanded using domain ontology to acquire more semantic terms for better understanding of user query. The semantic weight has been applied independently over different categories of terms in a document for ranking. The document with the highest augmented value in each category of terms has been ranked first. Remaining documents are ranked in the same way and are arranged in the descending order. The WordNet tool is utilized as a knowledge base and Wu and Palmer semantic distance method have applied for measuring semantic distance between the query and document terms for ranking the terms. The experiments show that the performance of the proposed document ranking method for e-learning retrieved better document compared with existing document ranking methods.
Introduction
World Wide Web (WWW) is an omnipresent collection of a massive repository of resources that can be accessed through smart-phones from the Internet anywhere and it becomes an integral part of everyone’s life, and millions of users are interacting as part of their day-to-day activity. The growth of the Internet and the enhancement of search engines make a drastic increase in e-learning users. Students are the highest users of the Internet, and among all their accesses, study-related search occupies a considerable level. Students from a different discipline, specifically from engineering and medical are started to utilize the Internet as their wisdom of knowledge source for learning. Search engines work by ranking the document based on the user query, which is time-consuming besides not providing any adequate content for conceptual understanding. Because the searching engines rank the documents both based on the content of the particular page and also by the search engine’s complete domain ranking parameters.
The classical document ranking methods, like the Boolean model, set model, and many others rank the document by finding the occurrences of query keywords [12]. Query classification and enhancement can also be used to find relevant document ranking [8]. The semantic structure is an emerging document ranking strategy that works on semantic similarity of document terms with query terms. It is mandatory to have strong background knowledge for measuring a semantic distance between two concepts. The knowledge can be a dictionary, a co-occurrence word from multiple documents or several intermediate nodes between classes in ontology. This knowledge can be represented in a translation graph and aids in automatic WordNet construction [15]. The application of WordNet in different languages acts as a key hint for synset detection, which is not applicable in a monolingual setting. The graph theory has been utilized to construct automatic WordNet from ploylingual mappings. The semantic relationship between words can compute from search engine output [11] for measuring semantic similarity between words. In general, a page-count and lexical pattern of word from snippets are collectively used to measure the similarity between words. The arrangement of words (lexical pattern) from multiple documents that are output of a web search engine can also be used to measure the semantic relevance.
The word co-occurrence is highly related to the user’s web search intention [7] and the number of SERP viewed. Reliable lexical-pattern between words from most of the document can be provided with a high semantic score. The document collected as an output from the search engine may have a common structure for two words in a snippet, then assigned with the highest value. The semantic relation between two entities [16], can also be heterogeneous or homogeneous, and it can be ranked based on the semantic association between them. The ontology can also be used for data analysis on documents by providing subordinate and super-subordinate relations among them [2]. The search engine output can also be used for semantic analysis, but the drawback of search engine output-based method is that different search engines provide different SERP and snippets, and the SERP may be changed based on location, user’s history and time to time. The document ranking can vary due to many parameters for every searching [24].
Additionally, this method did not provide adequate changes for measuring semantic similarity between words. The ontology also can be used to measure the performance of the search engine results [2]. The nature of the IR system is to rank the documents and select the best, which has the highest domain similarity or highest probability relation with query terms. The ranking is based on the availability of search terms.
The ontology
Ontology having the provision to keep the concepts in a different dimension which can be used for knowledge representation, sharing, and reuse. This ontology can be developed manually or semi-automatically. A drawback of these ontologies is in the trustworthiness and authorization of knowledge source and the lack of combined global repository to locate and reuse [10]. Ontology is defined in triples such that ‘resource as classes,’ ‘relation as properties’ and ‘object as instances’ and it is often associated with a hierarchy of classes and relationship among the classes via properties to describe knowledge about an entity of the real world. Ontology follows the standard format OWL (Ontology Web Language) as an extension file, which provides a knowledge base in a structured manner globally from computer and information point of view. It is a decentralized, domain-specific knowledge source, used for an autonomous system, intelligence system, and information retrieval. These features are used to increase throughput in a web search. The cognitive of an ontology can be used to share knowledge and reuse in the heterogeneous environment. The ontology is a correct way to represent knowledge to fulfill its design objectives such as clarity, coherence, portability, distribution, minimal encoding complexity, and ontological commitments. Protégé and OntoEdit are globally utilized tools to develop and to deploy ontology. Stanford center for biomedical informatics, Stanford University can be used to create ontology with various additional properties develops the Protégé tool.
WordNet ontology
WordNet Ontology is a lexical analyzer, used in Natural Language Processing (NLP) which contains 150000 “synsets” and its corresponding semantic relations. Similarly, the biggest ontology so far is DBpedia contains around 2.4 million resources, and Cyc ontology contains around 300000 concepts. These in-built ontologies ease in information retrieval, but it is time-consuming when ontology proliferates. WordNet has been utilized for adaptive search using structurally represented data. The wrapper is using ontology [19], to extract and align the data records using lightweight ontology to check the similarity of data at the semantic level. While designing, the authors have incorporated the semantic property into wrapper because, the present automatic wrapper works based on the Data Object Model (DOM) tree that is not suitable for differentiating data regions. This wrapper in WordNet is used to address two problems such as lists the page that are generated from the query and the page where the particular information related to the product/company.
The proposed semantic document ranking includes four functional units, such as (1) query expansion, (2) document term classification, (3) measures semantic relation between query and document terms, and (4) rank the document. To implement our method for document ranking, we have developed two ontologies such that Communication.owl and Computer.owl, - with a set of classes and properties using protégé 4.1 tool. The semantic relation between two terms has been calculated by using Wu-and-Palmer distance measurement method and WordNet as background knowledge.
This paper organized into three segments such as 1. Semantic ranking, which describes detailed methodology for ranking documents 2. Result and discussions which deals with experiments made on the proposed method document ranking, and 3. Performance evaluation, showing the outcome of the proposed method compared with other standard existing ranking models.
Review of literature
The data now become one among the primary property, which can give valuable information for the business process. Data processing can be done on a variety of data types like text, a web of data, image data, multimedia, temporal data, so forth. The data representation can be classified into three category, such as structured, unstructured, and semi-structured data. Structured data retrieval is working on Boolean logic, and all the query languages are working using this principle. Retrieving and validating data from unstructured source like text or web documents is a key challenging issue. Here, web search engines are working on massive repository of unstructured data. Validating unstructured data requires substantial background knowledge. Ontology can provide such a knowledge base, knowledge management and reuse [22], on distributed heterogeneous environment and its widespread applications are machine learning [36], search engine optimization [2], e-learning improvement recommendations [37], document and image retrieval [33], and pattern search on time series [20]. The footprint of document ranking started from the term frequency (TF), inverse document frequency (IDF), improved TF and IDF [40], and ends with semantic ranking [21]. The vector space model [13], latent semantic indexing are notable document ranking methods.
Classifying, clustering, automatic text summarization [39], and hierarchical clustering of documents are also contributed for ranking a document at the significant level. Semantic analysis of clustered data improves the search engine’s performance [31]. Fuzzy logic also contributes its level best to rank the documents, and pattern matching by using a fuzzy logic framework [14], which is capable of evaluating data that have represented as a fuzzy set. The fuzzy ontology can be used for text summarization [29] from the document(s), journal(s), or news, and so forth. Based on the similarity between terms in the existing ontology, the fuzzy ontology can be built by using fuzzy interface mechanism. Query enhancement provides a better understanding of user query by removing ambiguity in search keywords and by appending additional conceptual terms related to the query for better retrieval performance [32]. Query Expanding using concepts is giving a considerable improvement in search engine output compared with direct query terms [28]. Prediction of user intention from queries [6], can be used for automating query enhancement while performing a search. Concept-based retrieval method [30] works on the manually built thesauri from comprehensive human world knowledge to estimate the semantic distance between two words. The advantages of ranking the complicated relationship between the different semantic webs are used to acquire better documents [5]. The concept-oriented retrieval method is working on explicit semantic analysis. It is a keyword-based text representation method with concept-based features and can automatically extract from massive knowledge repositories like Wikipedia. The graph-based techniques providing an alternate solution to estimate the distance between two nodes. Here, the terms in the knowledge base are represented as a graph, and the distance between terms is found by counting the number of intermediate nodes between two terms via the shortest path. Ontology can be used as knowledge base by representing class as ‘vertices’ and property as ‘edge’ in graph, and can easily find the distance between two conceptual terms.
The ontology can be used for knowledge modelling [23] for impelling database search and conceptual level ontology integration by increasing ontological classifications. The performance of ontology-based searching along with database-to-ontology and vice-versa comparison also described in [23]. The solution for measuring distance between two terms can be done by representing the knowledge base as the acyclic graph [17], and the number of nodes between concepts is treated as semantic distance. The use of node distance measure addresses the social network analysis problems for measuring the distance between two semantically similar entities. Estimation of node distances and its corresponding shortest path computation were done using an innovative idea in their work. Semantic measurement is a process of acquiring a similarity score between two terms. The semantic similarity can be done in either distribution of concepts among documents or by comparing similarity with ontology. A functional assessment of distributed semantic similarity measurement found in [27]. The semantic distance can be measured using two different methods (1) structured (2) gloss-based. The “structural” method extracts the similarity score from the structure of the ontology, which is in graphical representation, or it can calculate the property paths that connect concepts in the ontology. For example, the “car” is a “four-wheel motor vehicle, triggered by an internal combustion engine” and a clear relation of type “gloss” is added, then the relations start from “car” and end with “wheel,” “vehicle,” and so forth. Here, the target terms need to be disambiguated before such relation can be added. By augmenting the ontology, the gloss-based process scores the terms by connection-path measures. Although results reported is very promising, the exact process of gloss disambiguation step is not transparent, and hence, unable to reproduce the results when needed. Large scale knowledge base from different sources requires alignment strategy; however, by discovering the candidate key from each source for establishing semantic links between knowledge sources [9].
The similarity measurement using “gloss-based” method calculates overlapping definition of terms. In other words, this method works on the hypothesis that “similar terms have similar definitions”, but most effective way combines these two approaches — an excellent review of the structural method found in [26]. The basic notion in a structural method is connecting path in the ontology that connects two concepts whose similarity is needed to evaluate, and the path is a series of relation-edges concept-nodes. Structural similarity measurement is existing based on the similarity score. Social question-answering system is a static verbal representation of answers for the corresponding question. Correlation of quality answer to the corresponding question [18], has been analysed by mapping user-defined criteria with the data-driven features in the social forum. Alternate methods are also available such as the number of paths, the length of paths, the kinds of relationships existing and kinds of nodes in the path for describing the structural method.
The simple structural approach uses only taxonomic (is-a) relations and calculates similarity by using the length of the path. Assume that “car is-a vehicle” and “bus is-a vehicle.” In this case, a path of length 1 (1 intermediate node) exists among “car-vehicle-bus,” so the score according to this method would be 1/1 = 1. By contrast, the score for “cat” and “mouse” would be 1/4 because “cat is-a feline”, “feline is-a carnivore,” “carnivore is-a placental mammal,” “rodent is-a placental mammal,” “mouse is-a rodent” (4 intermediate nodes). The simplest “gloss based” approach is described in [25]. This method calculates the similarity of two concepts by merely counting the number of common words between the definitions of the concepts. Assign this count as a score. The text categorization on Arabic languages by using multi-label learning algorithm without having any benchmark data set, but with the news articles is presented in Bassam Al et al. (2019). It is a supervised learning algorithm that categorizes the document and gives the synonymic meaning. Text analysis can be used to correlate the social web site text with stock market trends [38].
Ontology is playing a crucial role in increasing the performance of search engine by providing semantic knowledge and also used to design a semantic search [3] engine. IBRI-CASONTO is a one such search engine [13], support Arabic and English languages, and it is deployed with keyword-based search and semantic-based search by using Resource Description Framework (RSF) along with data and Ontology Graph. All the search engines rank the documents by considering the overall content of the domain instead of considering user expectation from a single page. The Hebb Rule-based Feature Selection (HRFS), works on supervised Hebb rule [34], which treats the terms as different classes and the classification of terms are related with neurons to define the semantic and structural relation.
Semantic ranking
IR is the process of mapping between query and documents terms based on various parameters. Let ‘D,’ a set of documents, where D={d1, d2, d3, ... , dn} in a repository and ‘Q’ is a query containing a set of query terms qt={qt1, qt2, qt3, ... , qtm} are generated by the user which are the expecting information from the search engine. Consider each document ‘Di’ contains conceptual terms, Di ={dt1, dt2, dt3, ... ,dtn}. RD is a set of documents highly related to given query.
The model of our proposed method of document ranking shown in Fig. 1. The terms in a document are classified into five categories such as (1) Stop words, (2) Direct query terms, (3) Expanded query terms, (4) Semantically related terms, and (5) Supporting terms (not semantically related).
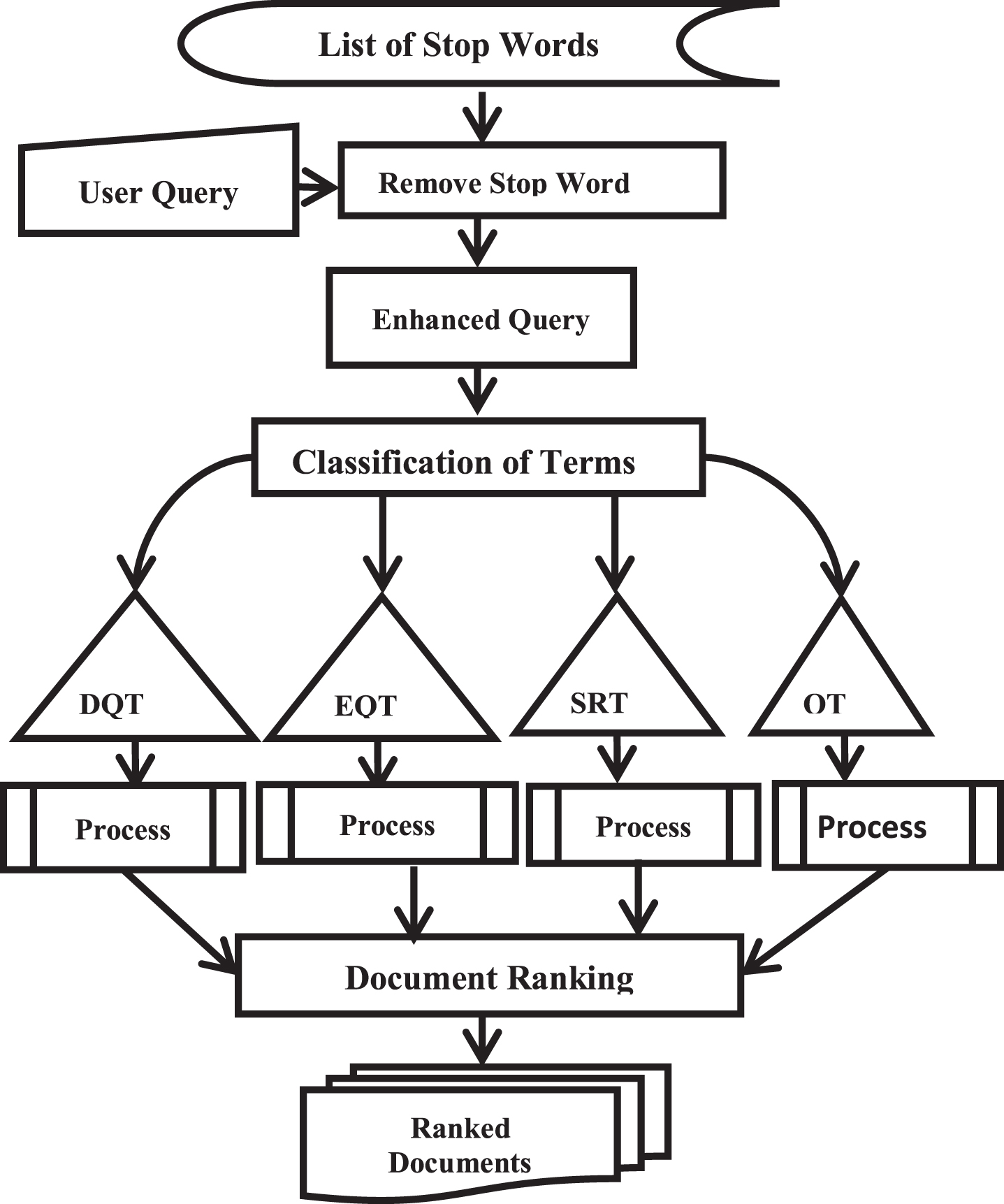
Architecture diagram.
Before start to rank a document, the substance of a document is being divided into lexical tokens such as strings of characters. The primary work of document ranking is to remove the stop-words in it. The total number of stop-words are calculated using Equations (1) and (2).
Algorithm for Document Ranking
Algorithm “docRanking”, developed to rank the document by measuring query-terms, semantic-terms, and other-terms. Here, the ‘
Algorithm “removeStop” has been used to remove stop-words from the document. The conceptual Terms (ct) from Equation 4 contains only conceptual terms of a document once the stop-words are removed.
Algorithm for removing stop words in the document
Direct query terms are the terms that the user query contains. These terms provide the details of the conceptual requirements of information from IR system. The query terms are expanded using ontology to acquire more semantically related terms to enhance the document ranking qualitatively. The query terms along with expanded terms are treated as conceptual keywords that are used for document validation, segregation, and ranking. The first phase of document ranking is to find the query terms in a document and its corresponding term frequency using given in Equation (5).
Such that term tf(i) occurred ‘n’ times in a document. This research work proposes an enhanced weighted term frequency which provides lesser importance to the repeating terms in a document. The enhanced weighted term frequency is measured using following Equation 6.
(The outcome of the enhanced weighted terms frequency is to avoid time and space to calculate inverse document frequency.) Algorithm given below shows how to calculate direct query terms. Here, “ewtf” is the number of times a particular keyword occurred in a document. The inverse document frequency provides lesser weight to terms that present in all the documents in a collection. It is calculated using the Equation (7)
Where, N – is a total number of the document in a collection, ni - number of the document which contains the particular term‘t’, formally called as document frequency. Each direct query terms contribute to measure the weight of the whole document. The contribution of one particular direct query term to rank the document in a collection is calculated using the following Equation (8).
To calculate the overall contribution of all the query terms to rank the document, enhanced term frequency and inverse document frequency for a one particular document has to be calculated. It has been achieved using the Equation (9).
Algorithm for calculate term and inverse document frequency
We used a model document to calculate weight of direct query terms (dqt) and the term frequency of each direct query-term using algorithm “queryTerm” and value tabulated in Table 1.
Term frequency in different documents
The direct query term frequency (tqt), and inverse document frequency (idf) for documents Dc1, Dc2, Dc3,... ... ,Dc10 are calculated and shown in Table 2.
Weight Reduced TF and IDF calculation
As an example, the conceptual term in a document is compared with query terms using WordNet is tabulated in Table 3. The term in a document may have high semantic relation with any of the query terms. The maximum value between document term and any of the query term is considered as the final weight of the relation.
Semantic Relation between query terms and document terms
The semantic terms are the terms that have high semantic relation with any of the query term. The semantic terms ‘st’ is defined as the remaining terms after subtracting the direct query terms from the document as in Equation 10.
Table 3 shows the semantic value between query terms and document terms which are collected for a simple experiment. From the following Equation 11, the ‘st’ defines the semantic relation value between the query term and document term.
The semantic terms in a document are classified into two categories, such that the semantic distance between query term and rest of the term in a document is measured using WordNet, and distance is very closer such that≥0. 7 to nearer to 1. The second category is a semantic distance between the query term and the rest of the term in a document that are > 0 and < 0.7.
The semantic term in a document has the semantic distance value returned by WordNet. The semantic relation between the query term and document term is non-negative and is greater than zero. In this research, the weight of the document is calculated. By the semantic distance between query terms and semantic terms in the document. The term with the highest semantic relation to query terms is considered as a semantic term. Each unique semantic term in a document contributes partially to rank the document. It is measured using the Equation (12).
Term weight (TW) is applied as a metric for each term in a document. The weight is determined based on the total number of query terms in the document and the number of terms that are semantic relation with any of the query term. One particular semantic term in a document may have high semantic relation with more query terms that provides additional weight while measuring the distance with each query term.
The overall semantic distance level calculated for each query term with the rest of terms in a document to compute the semantic distance level. The overall lesser SDL, α, is the maximum number of terms in a document that have semantic relation with query term with values > 0 and < 0.7 in a document. The semantic distance for a single term in a document is calculated using Equation (13) and for all the terms using Equation (14).
Where, j is a semantically related term in a document. The value between qti and dtj is defined as WordNet (qti, dtj)<0.7. This document term dtj is semantically related to query term qti, and if not otherwise. The semantic distance between the query term and rest of terms in a document is carried based on the above condition. Table 4 shows the lower semantic distance and Table 5 shows the higher semantic distance levels. The High Semantic Distance Level (HSDL) with query terms is defined using Equations (15) and (16).
Terms with lower semantic distance level
Terms with higher semantic distance level
Here, the dtj is a term that has high semantic relation with query-term (I), and the overall terms in a document have semantic relation with query-term (i) are calculated using high semantic distance measurement. The Semantic Relation Level (SRL) is evaluated based on high and low semantic distance with query terms using Equation (17)
The ASDL calculated using an average of overall high and low semantic distance between query-term and document term. The overall lower semantic distance, δi, between terms that are semantically related with key-term
i
is computed using the following Equation (19).
Where j is any term semantically related to key-term
i
in a document and N- the total number of terms that are semantically true with key-term i in a document. The higher semantic distance has been calculated by average absolute distance, χ(i), using Equation (20) and same has been tabulated in Table 5.
Where ‘j’ is a term in a document and related to key-term. “M” is a total number of terms that are highly related to the key-term ‘i’. The average of lower semantic distance level and higher semantic distance level are added to evaluate overall average semantic distance level using Equation (21).
ASDL = 0.53 + 0.82 = 1.35 (taken from Tables 4 and 5).
Here, the absolute semantic distance level gives the additional weight to the terms. The documents are arranged in descending order based on SR value given the Equation (22).
Eg., SR = 10.11 + 1.35 = 11.46 (from Equations 15 and 19)
Algorithm for measuring weight of conceptual terms
The given algorithm used to rank the overall document for any given query and it can be retrieved by calculating its semantic relation level with query terms, all the conceptual terms, and average semantic distance level.
In a document, there are some terms neither direct query term nor semantic term. It is a challenging work to measure the contribution of these terms for ranking the document. Consider, for example, the document contains “the car cost exceeds 22 lakhs”, is classified as “luxury car.” The terms ‘classified’ and ‘luxury’ returns null while comparing with query term car using WordNet. This kind of term may spread across the document provide support for human understanding. In this research, these terms are also included for ranking the document using supporting terms.
Eventually, the overall ranking of the document is measured by using the equation dr = dqt+SR+log (supporting terms). In the proposed work, these terms are classified into supporting terms, and its weight is computed using log (total number of supporting terms).
Table 6 shows the document ranking for ten different documents. Figure 2 shows the contribution of a direct query term, semantic term and other terms to provide weight to the documents. The semantic terms in a document provide many contributions to rank the documents, whereas the query terms come to the second level in the observation.
Document ranking
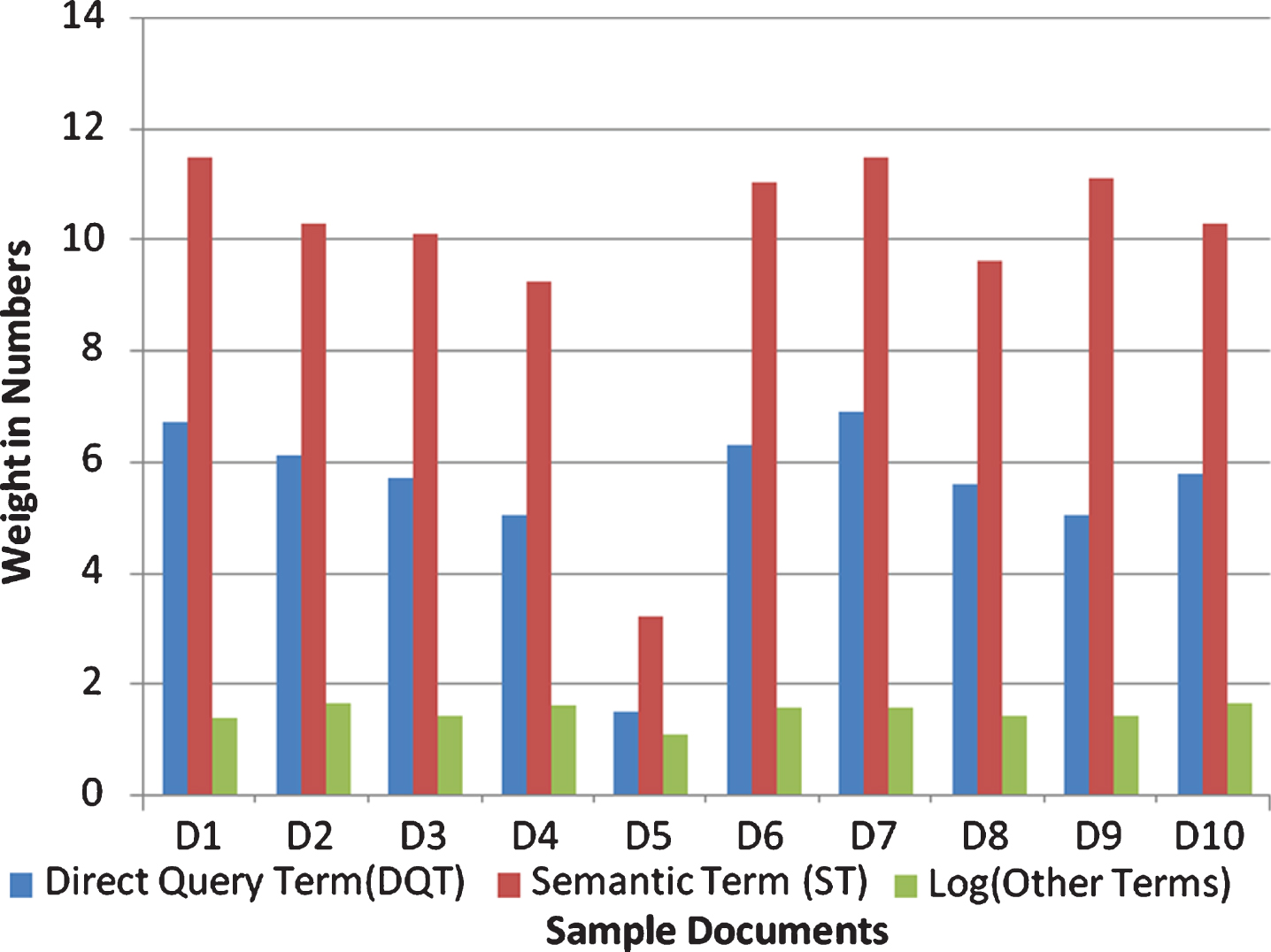
Contribution of ranking parameters.
The value of these terms ‘ot’ is added with a total of ‘dqt’ and ‘SR’ for the overall ranking of a document.
The document which the contains high query terms and semantic terms influence the ranking of the documents. Figure 3 shows that the document ‘d7’ is listed top-ranked document with the highest-ranking value 20.99. Remaining documents are listed in descending order such thatd6, d1, d9, d2, d10, d3, d8, d4, and d5 respectively.
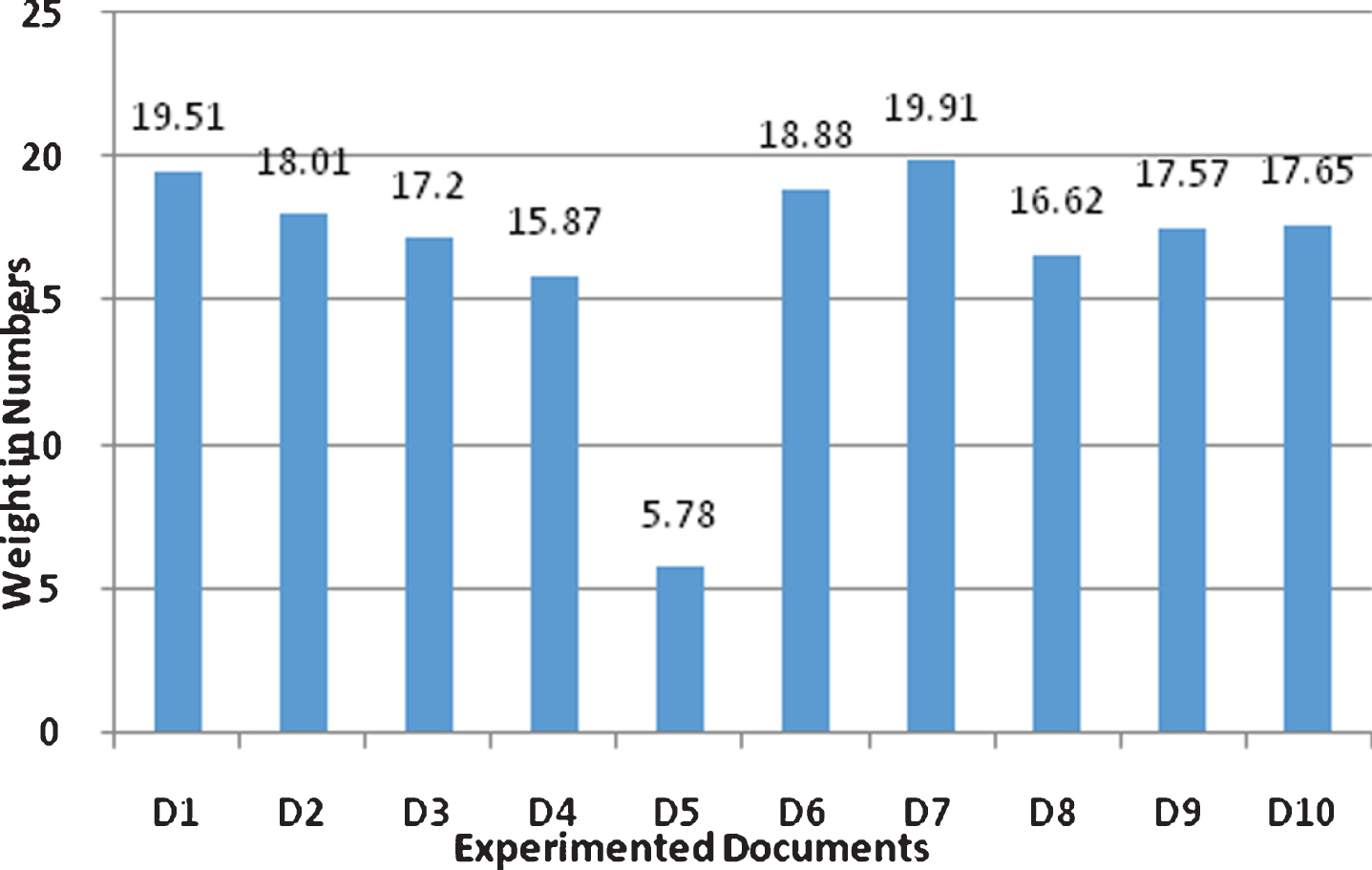
Overall ranking of documents.
The performance of the proposed work evaluated by comparing with SERP of Bing, Google and Yahoo search engine’s top 9 documents in off-line mode with the same query and the result is provided in Table 7 that shows the URL returned by all the three search engines and their corresponding ranks against each other. The performance of the proposed work is compared with Bing, Google and Yahoo search engine’s output.
Ranking of Google, Bing, and Yahoo documents
Ranking of Google, Bing, and Yahoo documents
Table 7 shows the output of the Bing search engine’s top nine documents evaluated using this proposed method. The weight of each document has been measured using STIR and Fig. 4 shows the performance of the proposed method against Bing search engine result.
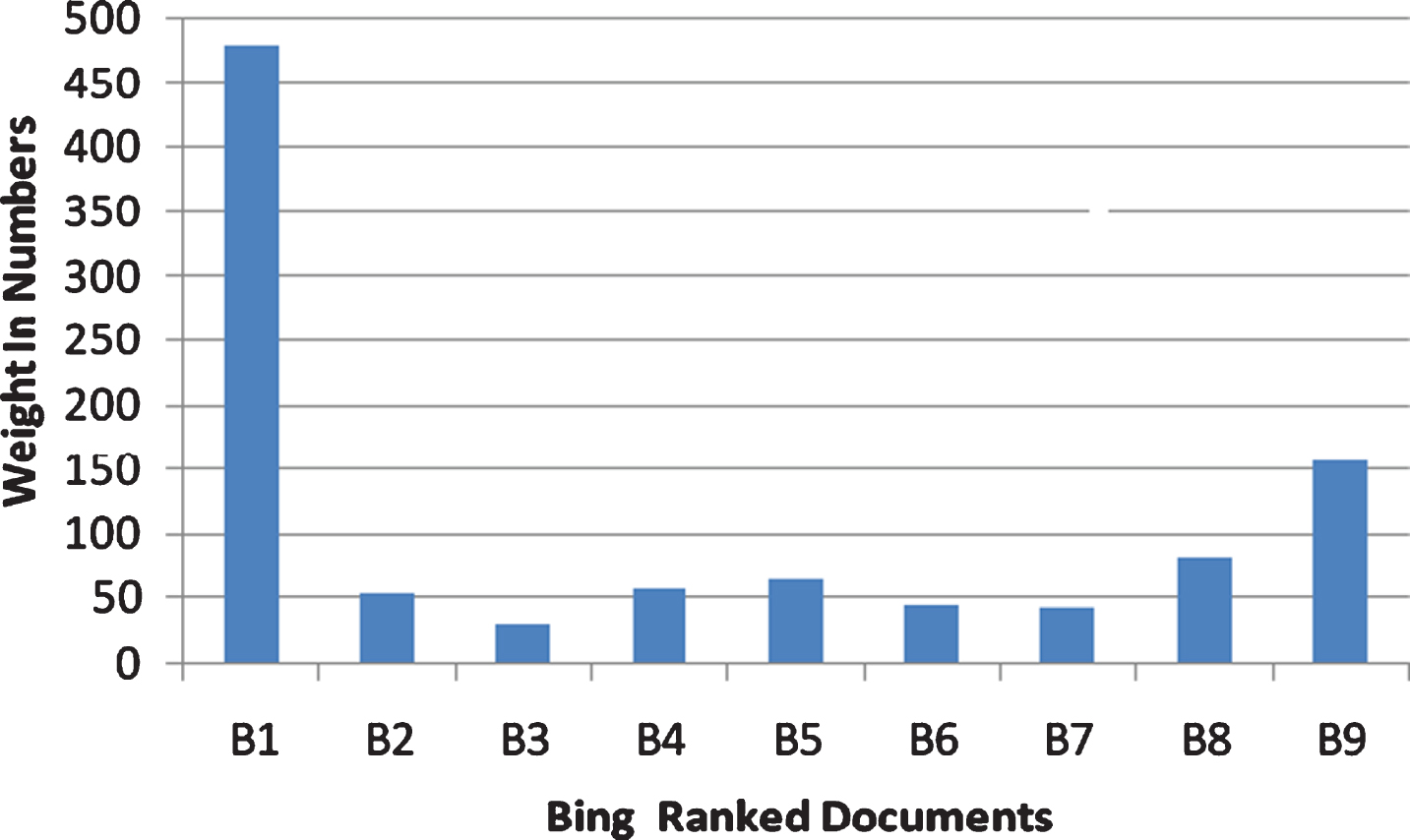
Bing vs STIR.
The document has been listed based on the highest weight into the lowest. Document B1 ranked first and B9, B8, B5, B4, B2, B7, B6, B2 and B3 as last.
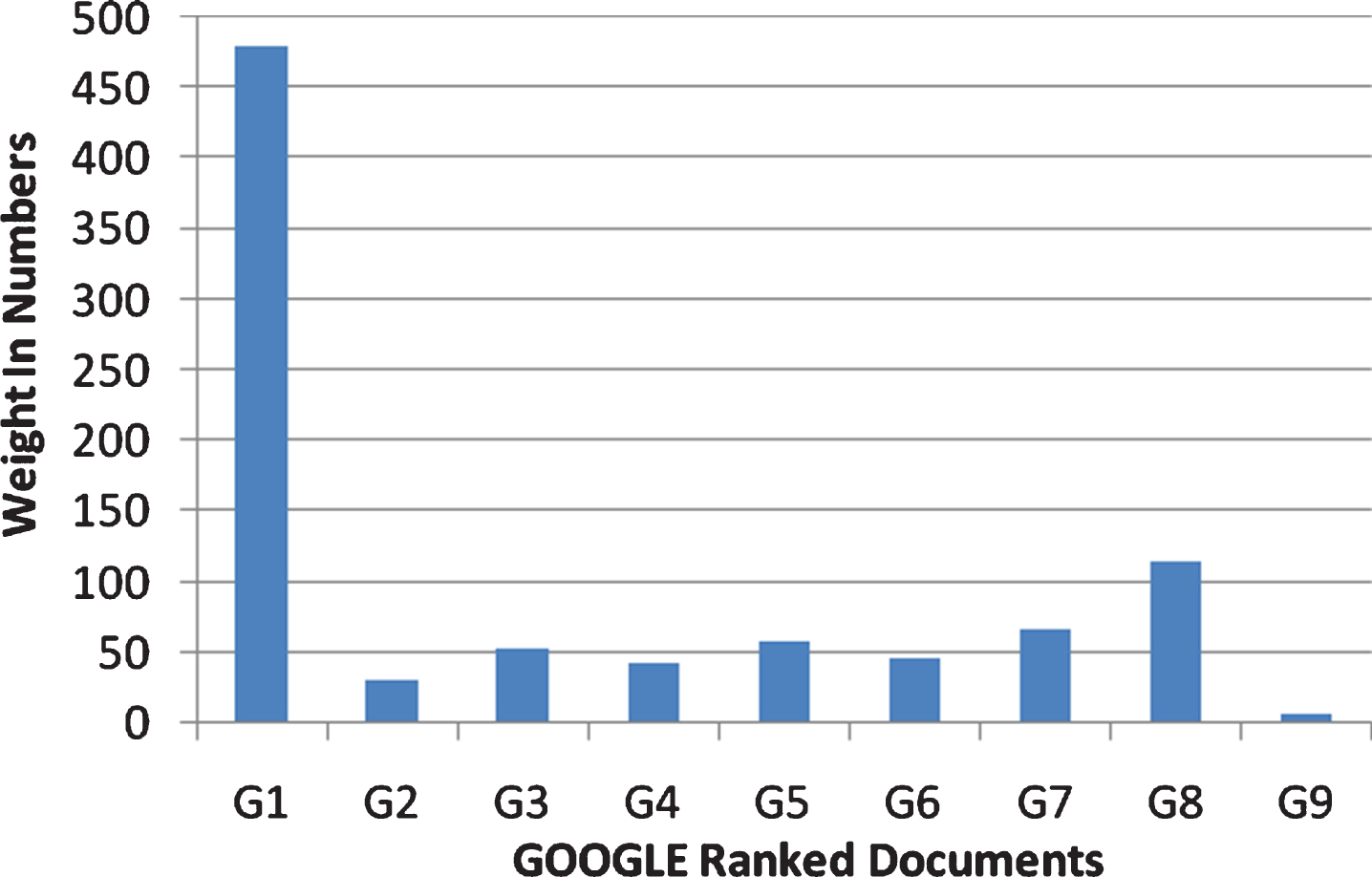
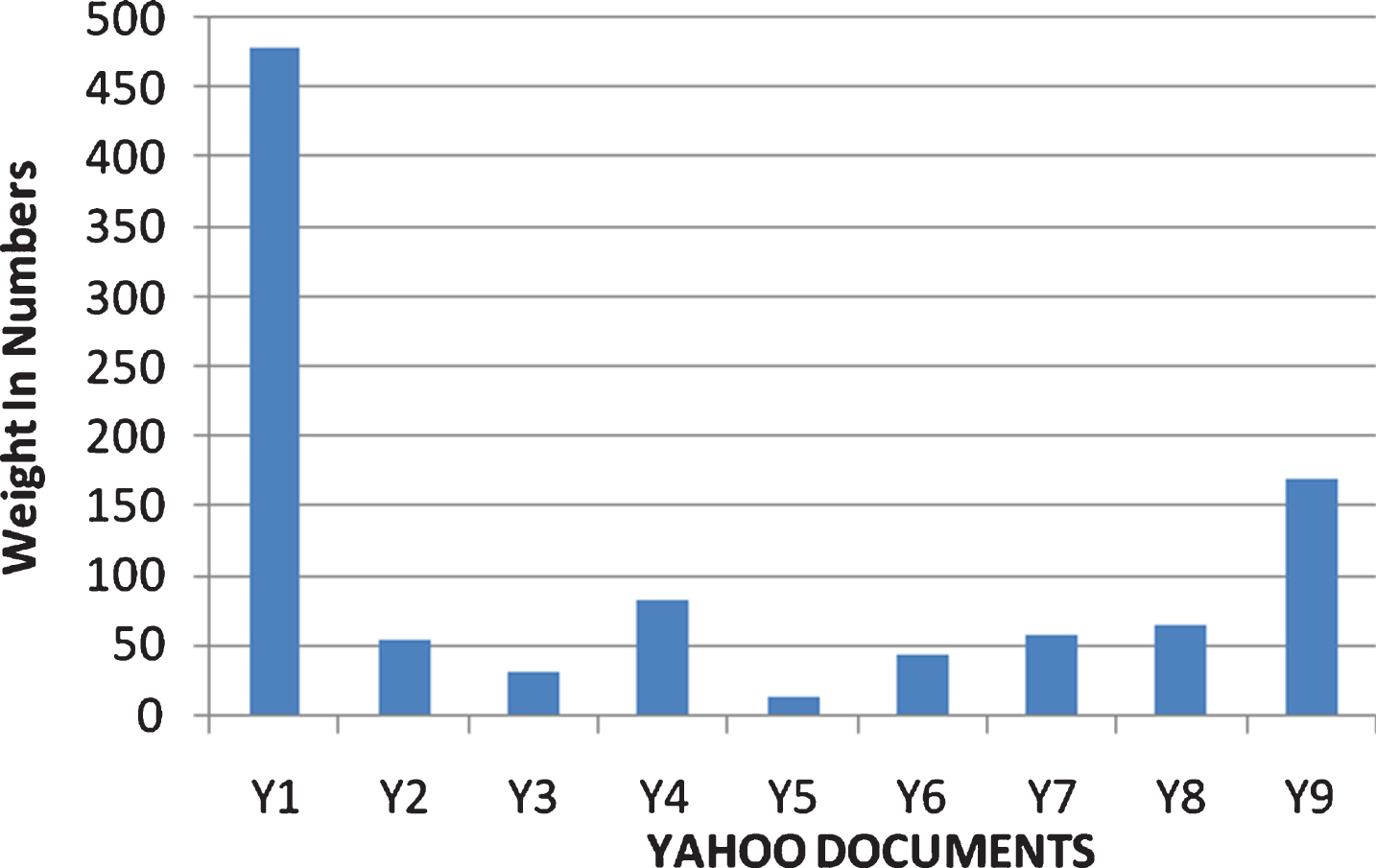
Figure 5 shows the performance of the proposed method against Google search engine result. Document G1 ranked first and G8, G7, G5, G3, G6, G4, G2 and G9 as last. Fig. 6 shows the performance of the proposed method against Yahoo search engine result. The output of the proposed work ranks the document Y1 first and Y9, Y4, Y8, Y7, Y2, Y6, Y3, and Y5 follow respectively.
Google Vs STIR.
Yahoo Vs STIR.
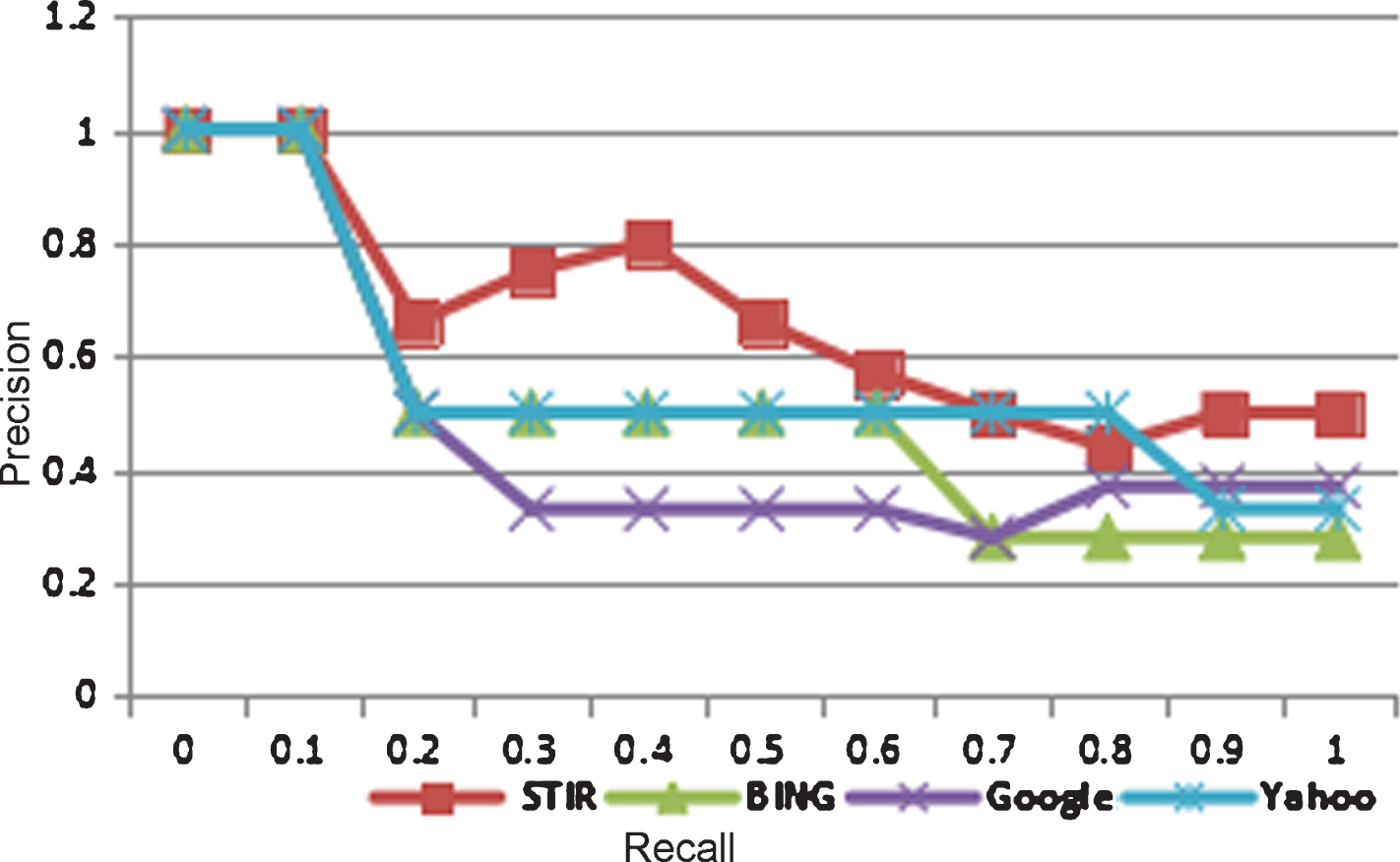
The optimization of the IR system is measured by calculating precision and Recall. Precision is parts of a retrieved document that are relevant whereas the recall is a part of a relevant document that is retrieved successfully. The precision and recall respectively are calculated using the given Equations (23) and (24) respectively. Four basic parameters using to calculate the performance of the IR system are True Positive (TP) that the IR system retrieved relevant documents, False Positive (FP), Relevant Document not retrieved, False Negative (FN), irrelevant documents retrieved by IR system and True Negative (TN) irrelevant document not retrieved by IR system. Table 8 showing performance parameters.
Performance parameter for document ranking
Equation 23 can be written as precision
and Equation 24 can be written as recall
Figure 7 shows the performance of the proposed work. The x-axis defines recall whereas the y-axis defines the precision. The precision and recall for the proposed work have been compared with the outputs of Bing, Google and Yahoo search engines. The proposed method approximates the expert ranking as shown in Table 7. Out of 15 documents ranked by experts, five of them are assessed as valid and the remaining are not valid. As per the human expert judgment for relevance ranking, Bing returns 2 valid documents; Google returns 3 valid documents; Yahoo returns 3 valid documents. Among the top ten documents shown in Table 7, it is observed that the proposed method contains all five valid documents ranked by human experts.
Performance evaluation by precision and recall.
In conclusion, a conceptual document contains terms that are semantically reflecting a domain of interests. To rank the independent document semantically for E-learning, a novel method has presented in this paper “classification of words”, which can provide different importance level to each category of terms and semantic metrics for measuring the relevance of document quantitively, compared to just merely word co-occurrence. The overall weight of each document has been measured by the individual term and its contribution semantically. This document ranking method can also apply for semantic search over cloud documents. This proposed method for document ranking retrieved more relevant documents and the performance has been ensured by multiple test cases each with hundred documents. Here, the query has been expanded using ontology to get more semantic terms corresponding to query term. Our future work moving toward multi-domain ontology mapping for query expansion to handle inter-domain queries.