
Abstract
Breast cancer is a severe disease for women health, however, with expensive diagnostic cost or obsolete medical technique, many patients are hard to obtain prompt medical treatment. Thus, efficient detection result of breast cancer while lower medical cost may be a promising way to protect women health. Breast cancer detection using all features will take a lot of time and computational resources. Thus, in this paper, we proposed a novel framework with surrogate-assisted firefly algorithm (FA) for breast cancer detection (SFA-BCD). As an advanced evolutionary algorithm (EA), FA is adopted to make feature selection, and the machine learning as classifier identify the breast cancer. Moreover, the surrogate model is utilized to decrease computation cost and expensive computation, which is the approximation function built by offline data to the real object function. The comprehensive experiments have been conducted under several breast cancer dataset derived from UCI. Experimental results verified that the proposed framework with surrogate-assisted FA significantly reduced the computation cost.
Introduction
The breast cancer seriously affected the normal functions of human organs and destroyed the normal tissue structure, which is a serious threat to women health and life. Such as chest pain, shortness of breath and difficulty in breathing. If the cancer metastasizes to the spine, there can be bone pain, and in severe cases, paralysis. The death rate is very high at the advanced stage of breast cancer. However, the reason of breast cancer is uncertain yet, thus it is hard to accurately detect the disease by the current medical technology at early stage. Many patients suffer much pains and even die because not obtained accurate result in detection early. In fact, the breast cancer can be detected by analyzing its influence factors, such as human living habits, genetic factors, environmental pollution and others. But, when analyze these influence factors, the doctor’s decision may diverse. The final decision may get a false-negative result or false-positive results caused by fatigue and inexperience doctor. Therefore, it is a good way to use the intelligent identification technology to deal with the complex analysis work and get useful information for doctor.
In the past decades, machine learning attracted a lot of attention, it obtained great effect in different fields for solving problems with unknown rules, including cancer detection. For example, Wu et al. [34] proposed a novel neural-network based algorithm, which refers to as entropy degradation method (EDM), to detect small cell lung cancer (SCLC) from computed tomography (CT) images. This research could facilitate early detection of lung cancers. Deng et al. [6] developed a novel weighted hierarchical adaptive voting ensemble (WHAVE) machine learning (ML) method for breast cancer detection, the result is more accurate than the individual ML methods. Abdar et al. [1] proposed a method to predict heart disease, which through finding a better decision tree to extract these most influence factors. Rajesh et al. [23] utilized support vector machine (SVM) to obtain higher sensitivity in classification of ECG heartbeats. Besides, data mining is also a widely used technique for information processing, which utilizes available data to find hidden but useful information that may not be directly recognizable.
Evolutionary algorithm [28, 29] has good performance in disease diagnose, which can be used to extract more essential feature information. Such as, Hassoon et al. [13] used the genetic algorithm (GA) to optimize boosted C5.0 algorithm to find rules for liver disease by considering a dataset, which can find the effective attributes in the liver disease diagnosis. The particle swarm optimization (PSO) [30] is also used to generate rules for heart disease in [3]. In addition, surrogate model method is a good way for optimizing the evolutionary algorithm, which developed along with the extensively employed for expensive black-box design optimization. Meanwhile, surrogate model method can efficiently assist the evolutionary algorithm to optimize the real-world problems with lower cost. Such as, Gong et al. [11] used surrogate model to select the best one among the multiple candidate offspring, which improve the performance of single operator-based methods in the majority of the functions. Moreover, Regis et al. [24] develops a surrogate-assisted evolutionary programming (EP) algorithm for constrained expensive black-box optimization that can be used for high-dimensional problems with many black-box inequality constraints. This proposed method is much better than a traditional EP.
In fact, breast cancer detection is a complex process, although costing long time and great money, it still may get a false results possibly. Based on these observations, we proposed a novel framework with surrogate-assisted FA, which provides a more accurate and efficient result in breast cancer detection. In this framework, the efficient FA is used to extract important feature information and dig out their hidden relation. Then the machine learning built a classifier by these extracted feature information. The classify performance is remarkable of machine learning technology, but it has expensive computation cost. Thus, we adopted the surrogate model fitting the real classification problem. The framework with surrogate-assisted FA significantly decrease the computation cost. We have conducted experiment on three breast cancer datasets derived from UCI.
The main contributions of this paper can be summarized as follows: Using surrogate model assist the FA to extract feature of breast cancer. Design a framework with surrogate-assisted FA for breast cancer detection (SFA-BCD) in which the FA can be replaced with other advanced FA variants, the machine learning method and surrogate model also can be replaced with else.
The rest of this paper is organized as follows. Section 2 briefly reviews the related works, including the machine learning techniques, evolutionary algorithm and surrogate model. Section 3 introduced the design method and implement procedure about our proposed disease detection framework. On the basis of different experiment results and analysis, verifying that the performance of our proposed framework is good in section 4. Finally, the conclusion of this paper has presented in section 5.
Preliminary works
In this section, we first briefly reviewed the contribution of the machine learning in medicine field, then introduced some application with FA in feature selection, followed by a brief explain of the effect using surrogate model to assist evolutionary algorithm.
Machine learning in cancer detection
With the increasing medicine technique, we can know that the cause of one disease always relate with many factors. For that, doctor need to deal with and analysis large patient data record before making decision. The classification is a kind of supervised data analysis technique, which is important for dealing with lager-scale data. Plenty of classification algorithms such as support vector machine (SVM), neural networks (NN), K-nearest neighbor (KNN) and etc, them have been widely used in various research fields. For example, Zheng et al. [40] adopted the K-means algorithm to identify the hidden patterns of the benign and malignant tumors respectively, then distinguish the incoming tumors using the new classifier built by the SVM, the accuracy is improved obviously. Bazazeh et al. [4] used SVM, random forest (RF) and bayesian networks (BN) to develop tools for physicians that can be used as an effective mechanism for early detection and diagnosis of breast cancer which will greatly enhance the survival rate of patients. Osareh et al. [18] utilized SVM, KNN and probabilistic neural networks (PNN) classifiers combined with signal-to-noise ratio feature ranking, sequential forward selection-based feature selection and principal component analysis feature extraction to distinguish between the benign and malignant tumours of breast. Valentini et al. [27] utilized bagged ensembles method of SVM to identify cancer disease, which can efficiently deal with the variance and the curse of dimensionality. In addition, Kong et al. [15] increase the accuracy in diagnosis and prediction of breast cancer, by using the novel jointly sparse discriminant analysis to explore and extract the key features. More detailed review about machine learning algorithm in breast cancer recognition can be found in [39]. However, using individual machine learning to identify cancer need great time because the number of cancer feature is vast frequently.
Feature selection method
At present, a real-world problems can be solved by many solutions, but requires much complex computation in most cases. For reducing the computation time and avoiding curse of dimensionality, feature selection method has obtained a lot of attention. The primary propose is that select a subset of variables from the input data, which can efficiently represent the information of input data. This technique is widely applied in many fields, such as increasing the prediction accurate in machine learning, the better understanding by extracting the more important information from data in pattern recognition. Gao et al. [10] designed a new feature redundancy term that considers the relevancy between a candidate feature and the class given each already-selected feature, which can deal with large redundant information meanwhile offering large new classification information problem. Evolutionary algorithm is a kind of efficient approach used in feature selection. Niu et al. [16] used the brain storm optimization algorithm (BSO) to identify the more important features and utilized reinforcement-behaved strategy to make feature selection. Alfarraj et al. [2] proposed a firefly gravitational ant colony optimization approach, which can successfully select the optimized feature that consists of the particular predictive analytics, the result show that it is better in sensitivity, specificity and accuracy. In addition, Emary et al. [7] introduced a system for feature selection, in which the novel FA is able to quickly find the optimal or near-optimal feature subset, therefore, the system can enhance validly the classification accuracy and reduce the attribute size. Peng et al. [21] proposed a novel composite FA (CoFA) to tackle the breast cancer recognition problem. Furthermore, there have more detailed survey about feature selection problems by evolutionary algorithm in [35].
Surrogate model technique
In order to solve real-word optimization problems, expensive function evaluations is a severe challenge, it requires great computational cost frequently. For that, the evolutionary algorithm with surrogate model has obtained a lot of attention from academia and industry. Surrogate model technique not only enhances the evolutionary algorithm but also reduce the resource consuming. For example, Yu et al. [38] introduced a surrogate-assisted hierarchical particle swarm optimizer in which the RBF model built by online data choose the best solution so that reduce expensive computation. Sun et al. [25] proposed a two-layer surrogate-assisted PSO (TLSAPSO) algorithm, in which a global and a number of local surrogate models are employed for fitness approximation. This method can reduce the number of fitness evaluations, especially computationally expensive problems. Because of useing GA and PSO to solve inverse heat conduction problem required higher computational costs than their gradient based alternatives, Vakili et al. [26] construct an approximation to the direct problem using a set of available data and the underlying physics of the problem, which can achieve low cost. Pan et al. [19] used neural network to predict the dominance relationship, which is not separately approximating the objective value of candidate solution and reference solution. In addition, Wang et al. [31] proposed a novel offline data-drive evolutionary algorithm, the bootstrap sampling technique is used to extract the train dataset, one RBF surrogate model pool is built by these train dataset, finally reduce the computational complexity through utilizing the RBF model to calculate the fitness value.
Classical FA
From the above mentioned, it is distinct that evolutionary algorithm is a good way for feature selection. FA is a simple but efficient algorithm for solving complex optimization problems in continuous search space. The flash and attractiveness is the core feature for firefly to evolve in nature, therefore, three rules are used to simplify the structure of FA from Yang et al. [36]. First, there is no gender difference for all fireflies. Second, the brighter firefly will attract the less brightness one. Third, the brightness of each firefly is depend on the fitness of objective function.
On the basis of FA, the attractiveness of each firefly is depend on its light intensity, thus the attractiveness β applied in [36] is shown as follows:
Any firefly
1: Randomly generate Np fireflies (solutions) as an initial population {X i |i = 1, 2, . . . , Np};
2: Calculate the fitness value f of each firefly;
3: FEs = Np;
4:
5:
6:
7:
8: Move firefly X i towards X j according to (3);
9: Calculate the fitness value of the new solution;
10:
11:
12:
13: FEs = FEs + Np;
14:
To assume the overall procedure of original FA, Algorithm 1 briefly described the main procedure of FA. f (.) represents fitness evaluation function, Np is population size, FEs is the current fitness evaluations, MaxFEs is the maximum fitness evaluations, and f (X
i
) < f (X
j
) indicates that firefly
We have observed three key points as follows: The machine learning is widely applied in cancer detection, but still need to solve uncertainly influence factor and high dimension challenge when the data is huge. FA is efficient for feature selection. Surrogate model can reduce the expensive computation.
Thus, consideration of combining these approaches may be helpful for getting the better result of breast cancer detection while reducing the expensive computation time and cost. A framework with surrogate-assisted FA for cancer detection is proposed in this paper, using surrogate model assists the FA and reduce the expensive computation.
Although combining machine learning and FA can improve the accuracy of the classifier, the computational time still is enormous. For this challenge, surrogate model is a good way to reduce the expensive computation time, which have obtained remarkable results for solving expensive and complexity optimization problems in various fields. Based on these considerations, we proposed a novel framework with surrogate-assisted FA for breast cancer detection.
Breast cancer detection framework
In this section, we proposed a novel framework with surrogate-assisted FA for breast cancer detection (SFA-BCD). The breast cancer detection framework is simple but effective, in which the machine learning is a classifier used to identify the breast cancer, the FA is used in feature selection, and the surrogate model efficiently assists FA to optimize problem.
As shown in Fig. 1, the proposed SFA-BCD framework can be divided into three main parts, i.e., breast cancer dataset collection, feature selection with FA and classification. First, the breast cancer datasets are collected, after making pre-processed, all features within dataset are ready to process. Then, FA generates offline data by obtained feature set and machine learning algorithm.
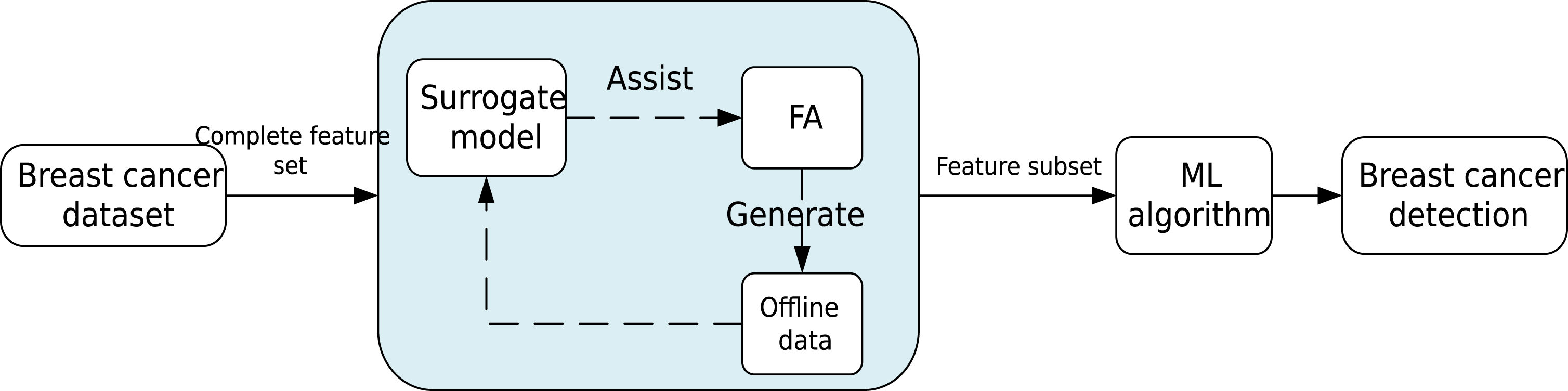
Illustration of SFA-BCD framework
1: Randomly generate Np fireflies (solutions) as an initial population {X i |i = 1, 2, . . . , Np};
2: Calculate the fitness value f of each firefly;
3: FEs = Np;
4:
5:
6: ...
7: The procedure can be replaced with any individual selection strategies;
8: ...
9:
10: ...
11: The procedure can be replaced with any FA variants;
12: Such as move firefly X i towards X j according to (3) in the original FA;
13: ...
14: Calculate the fitness value of the new solution according to (5);
15:
16:
17: FEs = FEs + Np;
18:
In order to built suitable surrogate model, the optimization problem needs to be properly formulated, including the specification of the fitness has been approximated by the surrogate model. In this paper, the surrogate model is built by the offline data, which can assist the FA feature selection. Finally, machine learning algorithm conducts breast cancer detection. In addition, for getting the reasonable feature subset from the complete feature set, during the feature selection process of FA, the dimension size is used as same as the number of attributes in the given dataset. All dimension variable are limited in the range [0, 1], if random value is smaller than surrogate probability, and when the variable value approach to 1, its corresponding feature is candidate to be selected in classification, the process of feature selection is formulated in (4), more detailed information can be known in Algorithm 2. If calculated by the surrogate model, there is no any process about the variable value.
In order to overcome the challenge that the false positive or true negative results from breast cancer detection, we employed three machine learning methods to analyse record data and output detection result, they are support vector machine (SVM), K-nearest neighbor (KNN) and Random forset (RF). For these methods, SVM kernel type is set to RBF, the number of neighbors are selected as 5 in KNN, otherwise, the number of trees in RF are set to 30. The theory of SVM is mainly inspired from statistical learning theory. Compare with other machine learning models, the major advantages of the SVM are that there is no local minima during learning and the generalization error does not depend on the dimension of the space. More information about SVM can refer [17]. The equation of the evaluation coefficients is follows:
1: Dataset pre-processing;
2: Collect offline data;
3: Build the surrogate function RBF and PRS according to offline data;
4: Randomly generate Np fireflies (solutions) as an initial population {X i |i = 1, 2, . . . , Np};
5: Calculate the fitness value f of each firefly;
6: FEs = Np;
7:
8:
9: ...
10: The procedure can be replaced with any individual selection strategies;
11: ...
12:
13: ...
14: The procedure can be replaced with any FA variants;
15: Such as move firefly X i towards X j according to (3) in the original FA;
16: ...
17:
18: Calculate the fitness value of the new solution according to (5);
19:
20: Calculate the fitness value of the new solution according to (8);
21:
22:
23:
24: FEs = FEs + Np;
25:
Combining the machine learning method and FA, the accuracy of cancer detection result has significantly enhanced. However, the time cost is still enormous, that not only increases expensive computation but also boosts the waiting time for patient. Surrogate model is a good way to reduce computational time while decrease cost, thus, we utilized two state-of-the-art surrogate models, polynomial response surfaces (PRS) and radial basis function (RBF). Box and Draper originally proposed PRS in [5], which can be simply built and its smoothing capability allows fast convergence of noisy functions during the search process, the second order polynomial model is formulated in (6). RBF is firstly proposed by Hardy in [12], which is a linear combinations of a radially symmetric function rely on the Euclidean distance between the sample point and predicted point, the RBF model is formulated as (7). More discussions and application on PRS and RBF can be known in the researches [8, 37]. We used offline data to build the corresponding PRS and RBF surrogate model, the offline data comes from the evaluation records derived from the result of classifier with FA for cancer detection, that includes the individual dimension value and the final accuracy calculated by classifier. For that, an approximate function of the expensive fitness function is constructed. It can be described as:
In the SFA-BCD framework, SP is the surrogate probability, using the classifier to calculate the fitness when the random value is smaller than the surrogate probability. Otherwise, choosing surrogate model assists the feature selection in FA by approximate function.
In order to verify the performance of the proposed breast cancer detection framework with surrogate-assisted FA (SFA-BCD), comprehensive experiments have conducted on real patient dataset, including three different breast cancer datasets. Three advanced firefly variants are also used in feature selection, which include LiFA [20], RaFA [32] and NaFA [33], all of them have obtained good performance under the benchmark function. For fairly comparing the experimental results, all classifier with FA variants independently run 10 times at each dataset, the mean accuracy are retained. The MaxFEs is set to 5E3 in the mentioned FA variants. Besides, other parameters are designed as same as its original structure. For all experiments in this paper, the 10-fold cross validation method is used to ensure the reliability of the result.
Test datasets
Three breast cancer datasets derived from UCI repository, which include breast cancer wisconsin datasets in original (BCWO) and breast cancer wisconsin dataset in diagnostic (BCWD), the other is breast cancer coimbra (COI). These datasets cover static information of participants, various habits, medical records and other characteristics. Table 1 introduces some basic information about these mentioned datasets, they are the number of instances and attributes, completeness, positive and negative. When the completeness is No, some value have lost in the dataset, the Negative indicates the number of malignant breast cancer, Positive means that the number of benign or absence breast cancer. More information can be found in Appendix.
Breast cancer datasets
Breast cancer datasets
In this section, the experimental results with computation cost as well as the accuracy are presented to verify the proposed framework for breast cancer detection. For the purpose of having statistically sound conclusions, the Wilcoxon’s rank sum test results at a 0.05 significance level between proposed SFA-BCD and others are summarized, in which the symbol “-”, “+”, and “≈” represent that the performance of proposed SFA-BCD is worse than, better than and similar to that of related algorithm, respectively. Ratio coefficient is used to measure the time cost difference between the classifier with FA and proposed SFA-BCD, it is formulated as followings:
In Table 2, 3 and 4, the results of accuracy and time are calculated using classifier directly, the classifier with FA and the proposed SFA-BCD. The ratio represents the difference of time cost between FA and surrogate assisted FA, lower is better. For example, in Table 2, the accuracy of LiFA+SVM+RBF on BCWO dataset is 0.9748 (+,-), in which (+,-) means that LiFA+SVM+RBF better than SVM and worse than LiFA+SVM. At Table 2, we used LiFA as the feature selection method, RBF and PRS are also employed to assist the LiFA, three classifiers such as SVM, RF and KNN are adopted to classify the condition of breast cancer. From these results, the performance of proposed breast cancer detection framework is significantly better than using classifier directly. Such as the SVM classifier, the accuracy of used classifier is 0.9698, 0.7125 and 0.9787 at three datasets, but the accuracy rise to 0.9748, 0.8579 and 0.9824 in the proposed framework with RBF surrogate model, the PRS surrogate model also increases the accuracy to 0.9744, 0.859 and 0.9821. For the SVM algorithm with LiFA, the statistic results in accuracy has not remarkable difference compared with the proposed breast cancer detection framework, which means its effect in accuracy is similar with proposed SFA-BCD.
Result obtained by LiFA for breast cancer detection at different datasets
Result obtained by RaFA for cancer detection at different datasets
Result obtained by NaFA for breast cancer detection at different dataset
However, it is noticeable that computation cost of proposed breast cancer detection framework is sharply decreased, value of ratio can describe clearly the time difference, smaller is better. We still used the SVM classifier as a sample to demonstrate, the time of SVM with LiFA is 493.97, 484.47 and 503.10 obtained from these three datasets. But the time of proposed framework with RBF model is 146.18, 194.91 and 221.30, respectively, the proposed framework with PRS model costs time is 149.13, 198.78 and 220.08. Obviously, the computation cost is highly decreased, the ratio is 0.30, 0.40 and 0.44 between SVM with LiFA and the proposed framework with RBF model, meanwhile, the ratio compared with the proposed framework with PRS model is 0.30, 0.41 and 0.44. These results show that surrogate-assisted LiFA reduced more than half computation cost to SVM with LiFA.
To comprehensively verify the performance of proposed SFA-BCD, we also used RF and KNN classifier to conduct breast cancer recognise. Moreover, employing RaFA and NaFA to prove that the framework is flexible, other advanced optimization algorithm could be used in this framework. Fig. 2 shows the computation cost of NaFA, NaFA+RBF, and NaFA+PRS on SVM, RF, and KNN classifier, in which the mean cost of algorithm on all three datasets is used to compete. By carefully reviewing Fig. 2, one can note that using surrogate model to assist the NaFA reduced more than half cost. From these results in Table 2, 3 and 4, we can conclude that the proposed SFA-BCD can combine with different optimization algorithms and machine learning algorithms to obtain good result, which not only enhanced the accuracy but also decreased the computation cost.
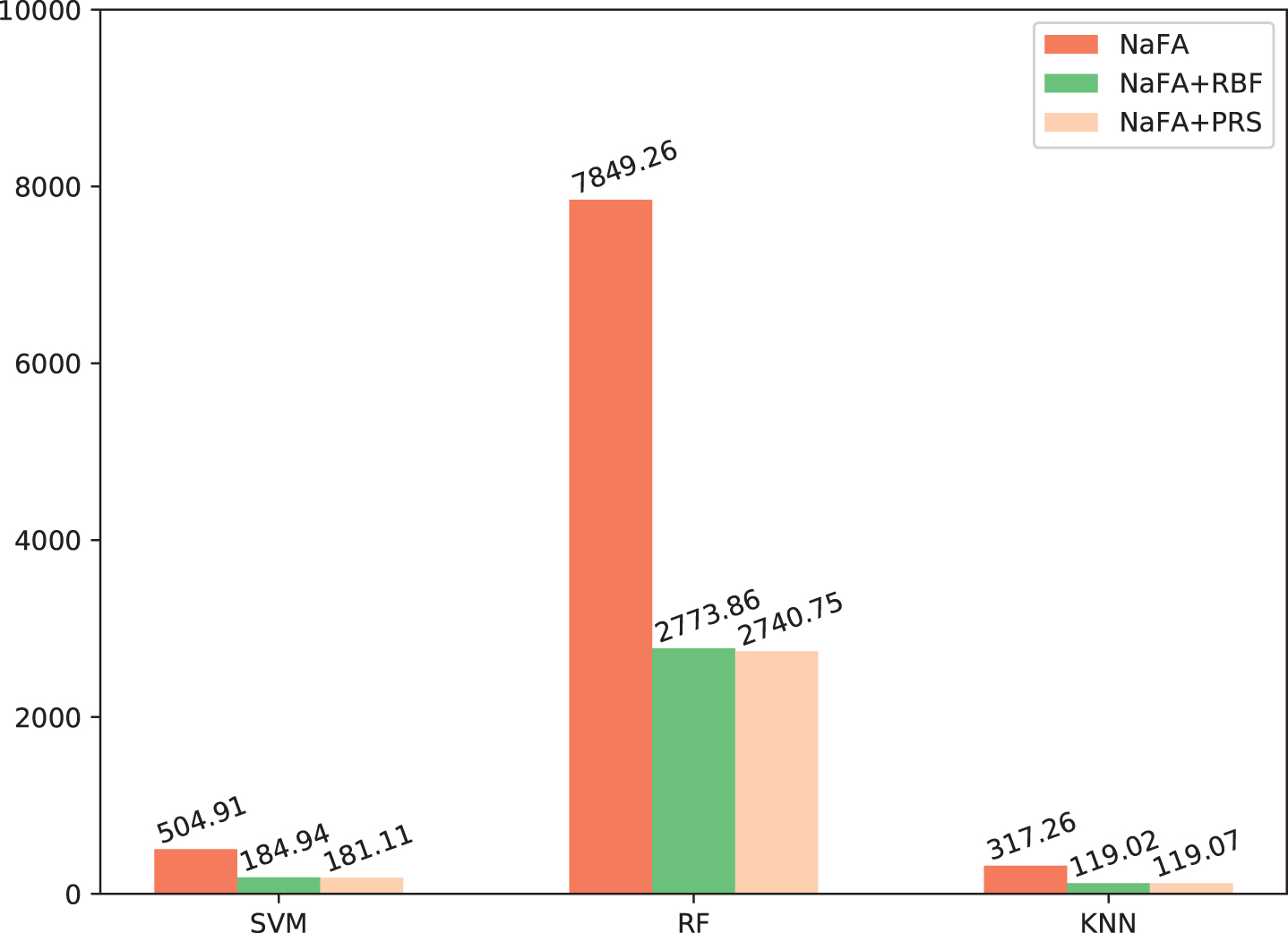
Computation cost of NaFA, NaFA+RBF, and NaFA+PRS on SVM, RF, and KNN classifier.
Because the value of surrogate probability decided the times using surrogate function to calculate, we primarily analyzed the effect under different SP in this section. In this experiment, the classifier just utilized KNN, other structure is as well as above mentioned, the value of SP is set to 0.3, 0.4 and 0.5, respectively. From Table 5, the ratio is gradually rise when the SP increase, such as, from 0.30 to 0.30, then to 0.52 at the KNN with LiFA in feature selection based RBF surrogate model. However, with the time cost increasing, the accuracy is rise, from 0.9794 to 0.9795 and then to 0.9801 when SP is 0.3, 0.4 and 0.5. Because the SP is bigger, the times using KNN to calculate the accuracy is rise, the time cost also will increase.
Result obtained by algorithms for breast cancer detection at different SP
Result obtained by algorithms for breast cancer detection at different SP
This paper proposed a breast cancer detection framework with surrogate-assisted FA (SFA-BCD) using classifier to calculate the accuracy, in which the FA variants is used to feature selection, besides, using surrogate model technique assists the FA variants while reduce the computation cost. On the basis of experiment analysis, the proposed breast cancer detection framework with surrogate-assisted FA has significantly reduce the computation cost and obtained good performance.
The computation cost of the proposed framework is sharply decreased. The time of SVM with LiFA is 493.97, 484.47 and 503.10 obtained from three test datasets. But the time of proposed framework with RBF model is 146.18, 194.91 and 221.30, respectively. The proposed framework with PRS model costs time is 149.13, 198.78 and 220.08. Meanwhile, the ratio compared with the proposed framework with PRS model is 0.30, 0.41 and 0.44. These results show that using surrogate model to assist the FA variant reduced more than half computation cost to SVM with FA variant.
In addition, the framework can integrate different evaluation algorithms, machine learning algorithm and surrogate model techniques, the procedure is easy to complete. So, it can be applied in other disease detection. In the future, we will do more work in the structure design of surrogate function according to offline data.
The Matlab source code of SFA-BCD can be downloaded from H. Peng’s homepage: https://whuph.github.io/index.html.
Footnotes
Appendix
Details of the three breast cancer datasets can be found by the following links:
Acknowledgments
This work is supported by the National Natural Science Foundation of China (61763019, 62041603), the Jiangxi Provincial Natural Science Foundation (20202BABL202019), and the Science and Technology Plan Projects of Jiangxi Provincial Education Department (GJJ180891).