
Abstract
The analysis of user trajectory information and social relationships in social media, combined with the personalization of travel needs, allows users to better plan their travel routes. However, existing methods take only local factors into account, which results in a lack of pertinence and accuracy for the recommended route. In this study, we propose a method by which user clustering, improved genetic, and rectangular region path planning algorithms are combined to design personalized travel routes for users. First, the social relationships of users are analyzed, and close friends are clustered into categories to obtain several friend clusters. Next, the historical trajectory data of users in the cluster are analyzed to obtain joint points in the trajectory map, these are matched according to the keywords entered by users. Finally, the search area is narrowed and the recommended travel route is obtained through improved genetic and rectangular region path planning algorithms. Theoretical analyses and experimental evaluations show that the proposed method is more accurate at path prediction and regional coverage than other methods. In particular, the average area coverage rate of the proposed method is better than that of the existing algorithm, with a maximum increasement ratio of 31.80%.
Introduction
With the rapid development of Internet applications, the field of location-based social networks has garnered considerable interest. Increasingly, more users are willing to share their travel routes and check-in data on social media, resulting in significant amounts of information on paths and trajectories. This information plays an important role in tourist hotspot detection, urban traffic control, and tourist route recommendation [1–4]. However, there are still many challenges in the field of tourist route recommendation.
Previously, if a user wanted to travel to an atypical place, they would invariably expend a significant amount of energy to plan the route. By contrast, personalizing the travel route recommendation to the user can reduce the amount of energy expanded.
To overcome the aforementioned problems, in this study, we proposed a method that derives relevant knowledge from the user’s social network and recommends the best travel route according to the user’s expectation and personal preference for a given journey. Figure 1 shows the improved genetic (IG) framework of the proposed route recommendation method. The processing steps of this method are as follows. First, the social relationships of users are analyzed and close friends are clustered on the basis of the historical user dataset. Next, joint points are calculated by a joint point search algorithm. Through the selection, crossover, and compilation operations of an IG algorithm, the inputs produce the trajectories that best match the user’s input keywords. Finally, these trajectories are used as input to the rectangular region path planning algorithm to generate recommended routes to the user. In addition, relevant criteria for judging the quality of the IG system are proposed.
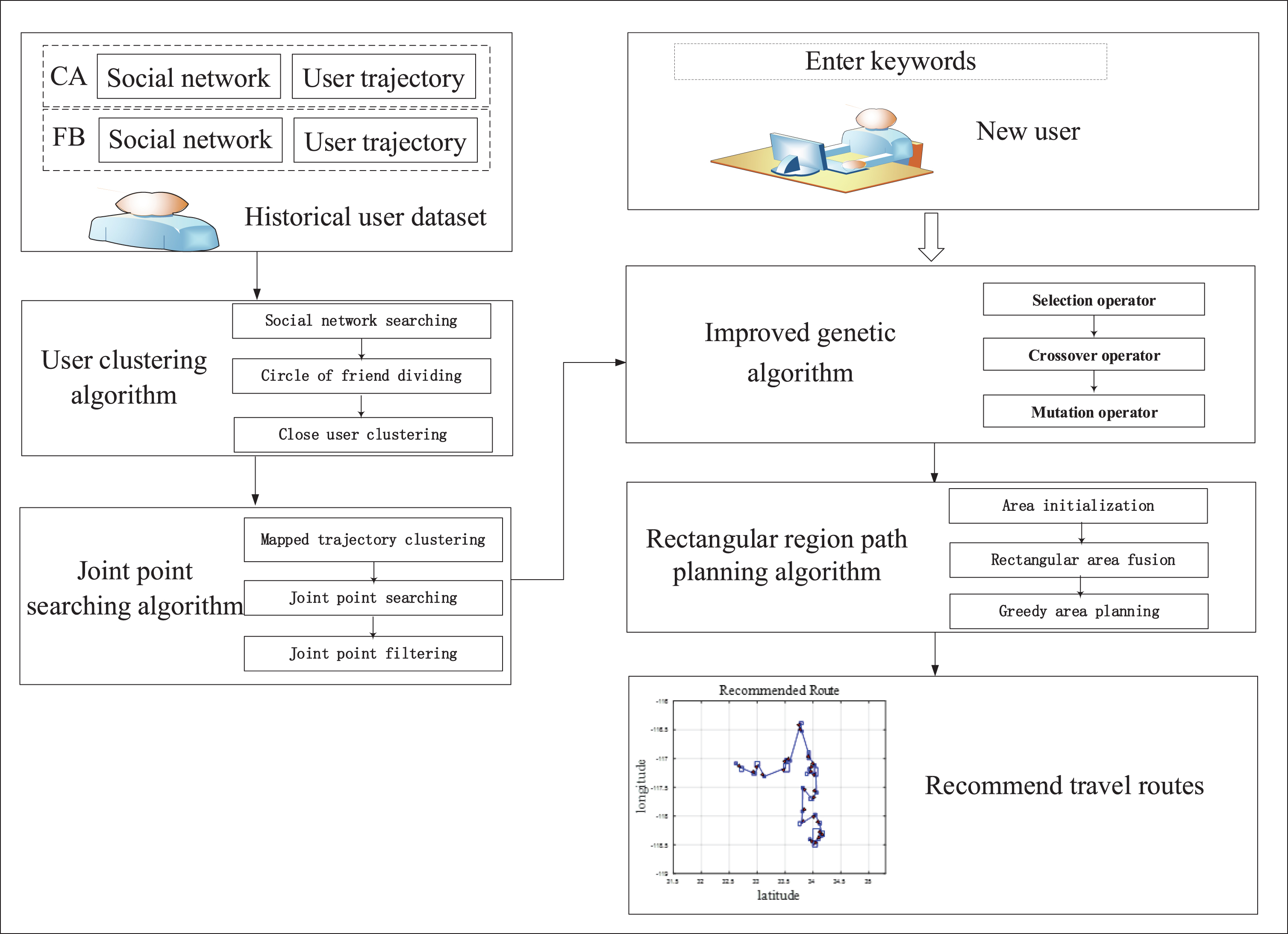
Framework of the proposed route recommendation system.
The contributions of this study are as follows: For convenience while searching for a path, a user clustering algorithm is proposed to class all historical users according to keywords; the clustering results serve to lock the categories quickly. An IG algorithm for trajectory recommendation is proposed. The proposed algorithm is used to filter interest points, select the joint points that meet the user’s preferences, narrow the search scope, and make the route recommendation algorithm more efficient. An efficient route recommendation algorithm based on rectangle area path planning is proposed. The interest points are divided into rectangular areas so that the areas do not overlap with each area has a certain degree of differentiation. An extensive set of experiments are conducted for performance evaluation and comparison. The Davies–Bouldin index (DBI) and Dunn index (DI) evaluating indicators are used to analyze the clustering results, and the average edit distance and average area coverage are used to measure the final recommendation results.
The organizational structure of this paper is as follows. Section 1 gives an overview of route recommendation methods. Section 2 discusses related studies on tourism route recommendation. Section 3 analyzes user social networks and historical trajectories offline modules, including user clustering algorithms, a hierarchical clustering performance evaluation index, and the joint point search of each clustering result path. Section 4 details the online module recommendation system, including the IG algorithm and path recommendation algorithm. Section 5 verifies the prediction accuracy of the proposed method. Finally, Section 6 summarizes the algorithm and problems solved in this paper and outlines future work.
Presently, the research on tourism route recommendation mainly includes the aspects presented in the following subsections.
Personalized demand-based methods
Personalized recommendation according to the different travel needs of users is an important task in travel route recommendation. Malik et al. [5] used a neural network and particle swarm optimization to predict the most effective optimal path by considering distance, road congestion, weather, and other factors. Considering optimal path recommendation of a navigation system, Gregor et al. [6] used a neural network to optimize the “soft” attributes (e.g., the level of tourist interest in scenic spots) to determine a path for the highest tourist satisfaction by improve the routing algorithm. For those tourists who only focus on time, Zhu et al. [7] accounted for which month is suitable for travel and which period of the day is suitable for scenic spots, and recommended a tourist route by expanding the longest path generation algorithm. In some special cases, such as limited travel time and bad weather, tourists tend to choose the path with the shortest travel time to the scenic spot. Li et al. [8] optimized the travel time from an online module and offline module to generate a shorter travel time than the existing travel path.
Real-time demand-based methods
Forecasting the next potential tourist attraction according to current urban traffic, the road network environment, and the real-time needs of tourists is another important task in path recommendation. Zhang et al. [9] used a residual neural network to predict city traffic, while Di et al. [10] and Mehmood et al. [11] utilized the SERM neural network, considering time, distance, attraction, weather, traffic conditions, and other factors to establish a real-time travel route recommendation system, predict the next possible scenic spot for tourists, and recommend a path to tourists for the actual situation. Lin et al. [12] used a hybrid integration algorithm of k-nearest neighbor and Bayesian algorithms to predict information about the next scenic spot.
Multi-scene demand-based methods
The multi-scenario application of path recommendation is also very extensive. Jesús et al. [13] designed a hiking route for tourism, while Zheng et al. [14], Hong et al. [15], and Gan et al. [16] investigated the trajectory patterns of taxis and ships. In addition, Sun et al. [17] and Gong et al. [18] used a tourist route recommendation method to improve the production efficiency in industrial scenarios.
Similarity demand-based methods
The similarity of historical trajectories plays an important reference role for route recommendation. In the research on trajectory similarity, clustering algorithms are the most widely used. Han et al. [19] proposed a new trajectory clustering algorithm from the perspective of complete trajectories. Mao et al. [20] proposed an adaptive acid algorithm for trajectory clustering analysis, and Lv et al. [21] conducted trajectory hierarchical clustering from the perspective of personal semantics. Zhang et al. [22] proposed a new hierarchical clustering method using spatio-temporal periodic pattern mining. From the perspective of local semantics, Dong et al. [23] proposed a mining algorithm with a regional semantic trace pattern, which effectively revealed the pattern of local frequent motions.
Drawbacks of current methods
The aforementioned methods extract trajectory path information from various sources and recommend appropriate routes. However, existing methods fail to achieve a good balance between personalization and diversification. Although Wen et al. [24] proposed a keyword-based framework, which recommends routes from a personalized perspective, the current methods still have low accuracy and lack diversity in their travel route recommendations to users.
Therefore, in this study, we propose an IG method that can achieve personalization while maintaining diversification. The proposed method considers both the attributes of traditional methods and those of path preference. By improving the genetic algorithm to meet the actual scenario, the recommended path is more accurate and diversified.
User clustering based on historical trajectory data
To increase personalization in the route recommendation system, this section analyzes the historical trajectory data in advance to ensure that the recommended route reflects the user’s situation. It consists of three parts. First, a clustering algorithm based on the number of friends the users has is proposed. Next, an evaluation standard for the clustering result based on the depth traversal distance tree is proposed. Finally, the experimental results of the proposed method on the Facebook (FB) and Foursquare (CA) datasets [24] are analyzed.
The FB and CA datasets contain two sub-datasets of social networks and user trajectories, respectively. Each data element of the social network sub-datasets includes two data items: user ID and friend ID. The format is u1, f1, u2, f2, u3, f3, u4, f4, where u represents users and f represents friends. For example, in 1,2, 3,4, 2,5, 5,6, f1 and u3 are the same user, f3 and u4 are the same user, user u1 and f1 within the same brackets are called direct friends, user u1 and f3 are called indirect friends, user u1 and f2 are not friends. Next, the social network dataset is used for user clustering.
User clustering algorithm
To better explain the related algorithms, the following definitions are given.
The circle of friends is a collection of similar users, in which users have direct or indirect contact. Whether online or offline, they will reflect each other’s travel experience. Users with similar hobbies will check the travel of their circle of friends while planning their next trip and the scenic spots to visit.
Different users have different numbers of friends, and users with more friends have stronger social influence than other users. For example, consider users u1, u2, and u3. If u1 has six friends, u2 has four friends, and u1 and u2 have two good friends in common, then u1, u2, and their eight unique friends are clustered into a circle of friends C1. Assuming that u3 has 13 friends, and all of them have no direct relationship to u1 and u2, u3 is regarded as part of circle of friends C2. The social impact between C1 and C2 differs. In this section, all users are clustered into several circles of friends according to their friendships. The user clustering pseudocode is shown in Algorithm 1.
In Algorithm 1, fs_friendship_CA is the input dataset of multiple trajectories. It also takes as inputs the thresholds k and n, and outputs several friend clusters. In Line 3, the Segmentation function sorts all users from high to low according to the number of friends. Then, it selects the top n percent of users as the result of the long matrix according to the threshold value, and the remaining users as the result of the short matrix. Lines 4–8 iterate over all the friend IDs of all the user IDs in the long user matrix. If the friend ID is also used as the user ID in the short matrix, Lines 9–17 judge whether the friend ID and the user ID are strong or weak connections. If they are strong connections, the friend circle of the friend ID is deleted from the short matrix, and if they are weak connections, nothing is deleted. This loop continues until none of the circles of friends have strong connections.
In Algorithm 1, the social core is the center of the circle of friends, and the closely related circle of friends is clustered into several clusters. The users in the cluster generally have similar preferences. At this point, the user’s historical trajectories are not involved. Next, the joint points are searched according to the historical trajectories.
Joint point search algorithm based on depth-first strategy
This section describes how the keywords in the user’s trajectory map in all the circles of friends are matched according to the keywords entered by the user. If the keyword matching score of circle of friends C1 is the highest, then the joint point in the trajectory map of C1 is the result of offline module processing.
Table 1 is a user cluster obtained from Algorithm 1, and it contains paths T1, T2, and T3. These three trajectories cross together to form a digraph, as shown in Fig. 2. This section analyzes these directed trajectory diagrams to find the joint points.
Example of route dataset
Example of route dataset
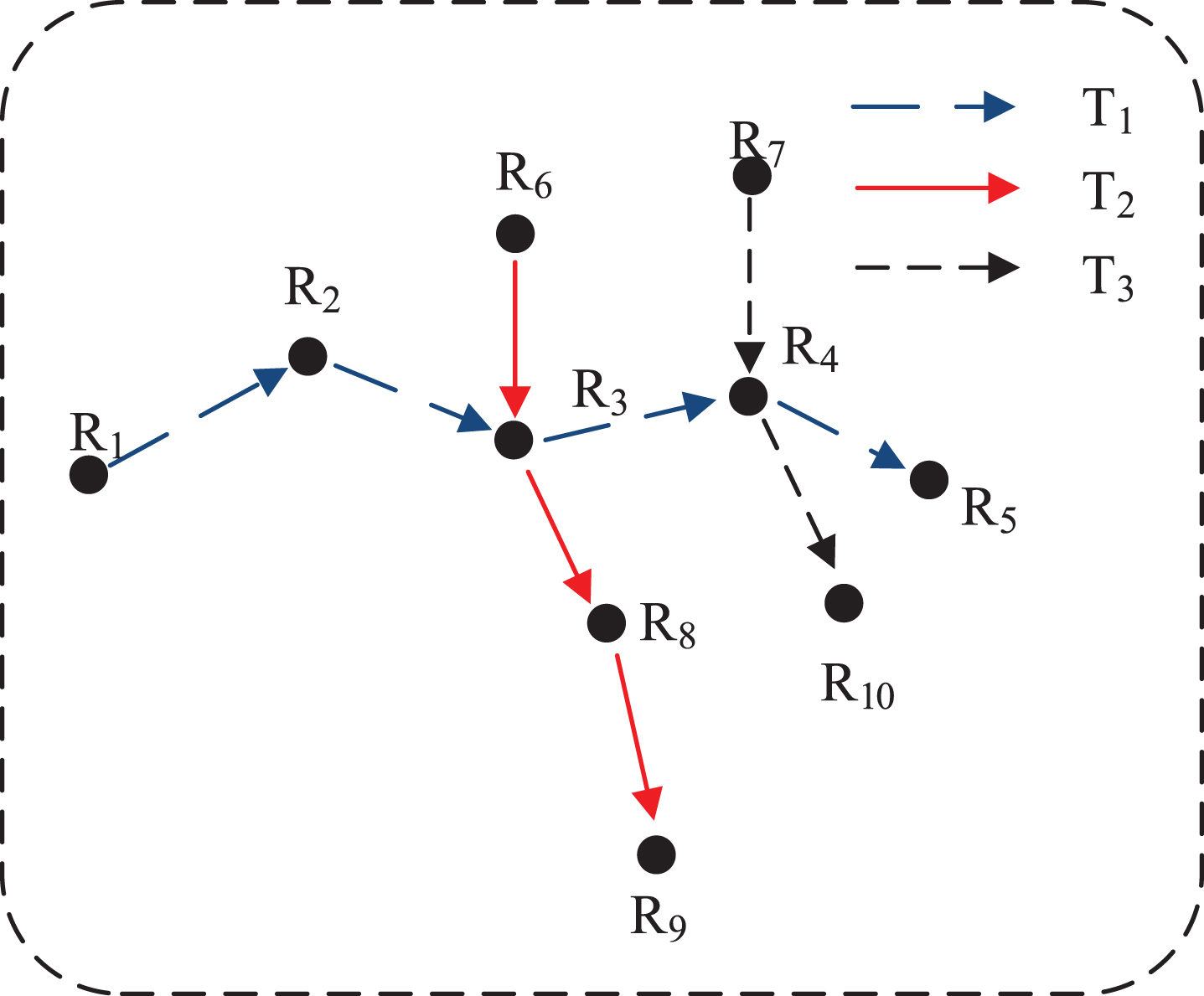
Trajectory of a friendship cluster.
In this study, the traditional depth-first search (DFS) algorithm is improved. Algorithm 2 determines in advance whether the user’s trajectory graph can search for the appropriate joint points. If the user’s trajectory graph is not a connected graph, no joint points can be found. Otherwise, the proposed ImpDFS function will be called.
The ImpDFS function searches for joint points in the connected graph. The joint point searching pseudocode is shown in Algorithm 2.
The input of Algorithm 2 is the path digraph obtained by Algorithm 1. If the digraph is unconnected or doubly connected, all the resulting matrices returned are – 1. If the digraph is simply connected, the joint points of the graph are searched.
In Function 1 (ImpDFS), v and w are nodes, predfn is the depth of the node, and v.id represents the user ID of node v. Lines 2–3 initialize the variables artpoint, count,
The joint points obtained by Algorithm 2 are overlapping interest points in a circle of friends. That is, within a circle of friends, different users appear at the same location, and these particular interest points attract the users. As shown in Fig. 3, the joint points reflect the most interesting places among numerous optional interest points, and are the most visited scenic spots for tourists. The travel route will be recommended according to the joint point below.
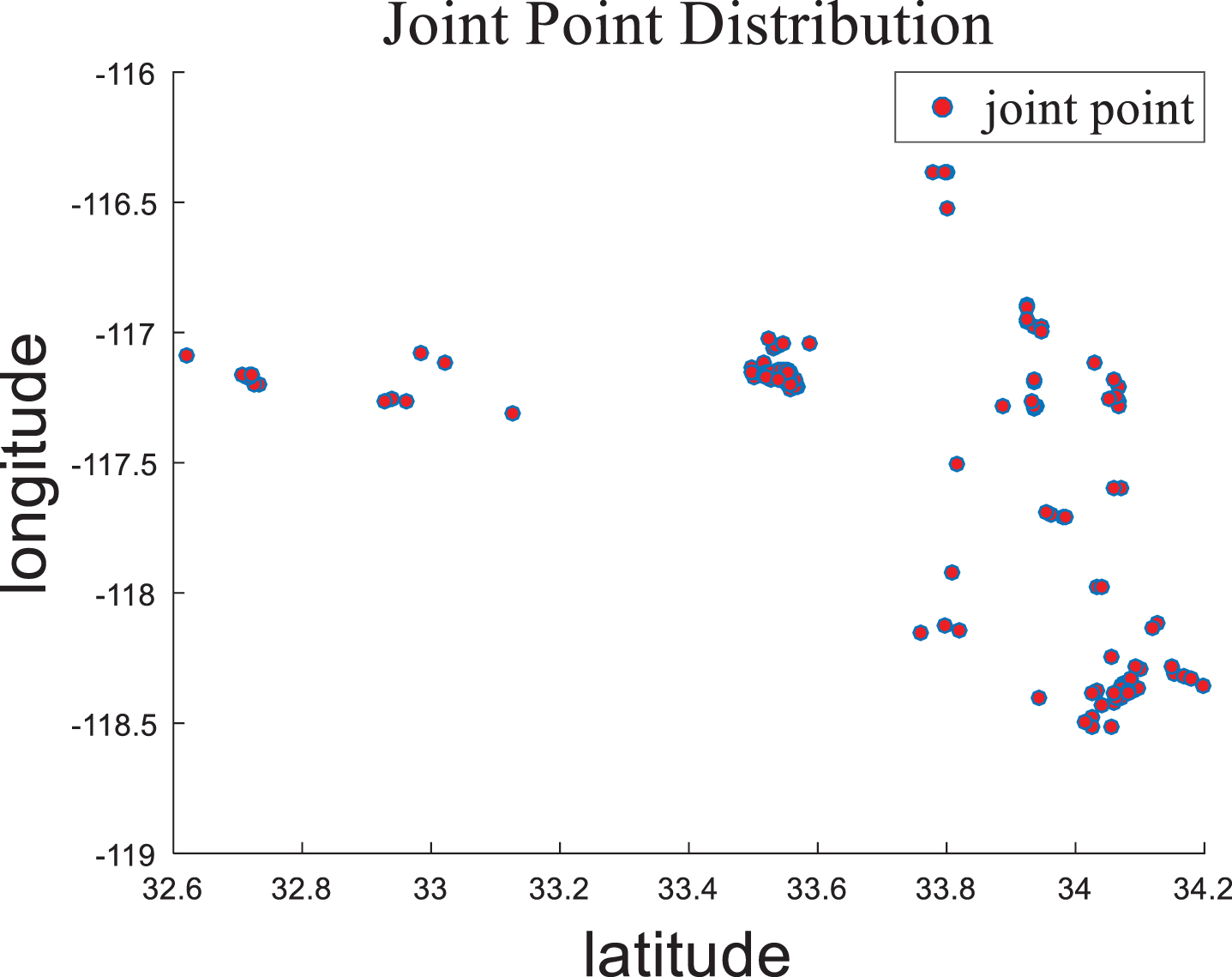
Example of joint point distribution.
The joint points obtained by Algorithm 2 contain the keywords describing the scenic spots. In this section, the keywords entered by the user are used to filter these interest points again, select the joint points that meet the user’s preferences, narrow the search scope, and make the route recommendation algorithm more efficient. Then, the IG algorithm is used to pre-recommend the routes that satisfy the factors of the user’s time, distance, and desired attraction. Finally, the shortest path method for rectangular regions is used to recommend a tourist route to users.
Joint point filtering
To filter out the joint points that meet the user’s requirements in the results of Algorithm 2, this study proposes a method to measure the correlation between the user’s requirements and the joint points. This is represented by
Figure 4 shows the matching friend clusters when K = {“doors,” “travel,” “shop”} and the actual image of the user’s trajectory.
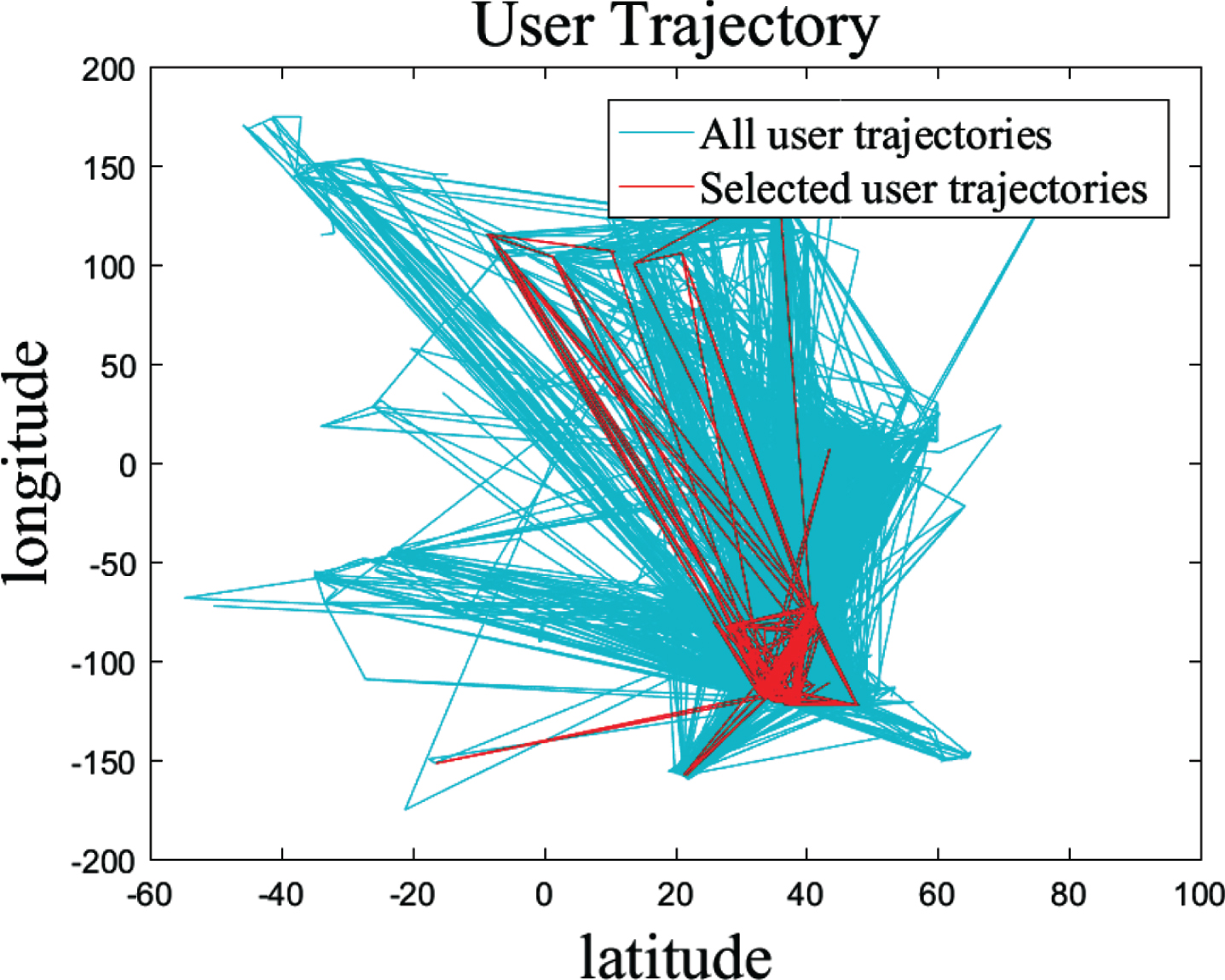
User actual trajectory in a cluster.
The blue area is the trajectory image of all users, involving multiple regions around the world. The red path is the path obtained by friend clustering. This subsection described how the joints to be recommended from the joints in the red area are selected, and the next subsection describes how the recommended route based on these joints is generated.
The advantages of genetic algorithm are that it can handle conditional constraints well, has strong global search ability, and can avoid local optimal solutions while obtaining the global optimal result. The objective of this study is to recommend a global optimal route to the user; hence the genetic algorithm algorithm is the most suitable scheme. In this subsection, the genetic algorithm [25–27] is improved to organize the selected joint points in the previous subsection. First, the interest points on the historical user access path are associated with individuals. Then, the fitness function is determined according to the actual situation, and the appropriate selection operator, crossover operator, and mutation operator are generated. Finally, the recommended tourist path in the region is obtained from the global convergence to a local region. Concurrently, the algorithm can change the search range of the path, run using different granularities, and obtain flexible personalized recommendation results. All points of interest are encoded by floating-point coding, such as 1,2 ... n. Some of the n points are selected for iterative calculation.
Fitness function
This study determines the fitness function via three components: (1) relevance of the user’s input keywords for the individual, (2) Euclidean distance of the pre-recommended path, and (3) access time of the pre-recommended path.
The user relevance factor considers the relationship between the route label and the keyword entered by the user. If the label on the route is similar to the keyword entered by the user, the route is considered to meet the personalized needs of the user. The fitness formula is
The distance factor considers the relationship between the pre-recommended route and the user’s preference. If the distance of the individual decoding route is short, the route is considered to meet the actual needs of the user. The distance factor formula is
Combining the above three factors, the fitness function is as follows:
A random competitive selection method is used as the selection operator. Two individuals are selected according to the roulette algorithm each time, and then the two individuals compete to select the individuals with high fitness as the cross mutation operation. The probability that an individual is selected is directly proportional to the fitness function. If the size of the population is n and the fitness of the individual is Fit
i
, then the probability of its selection is
Crossover operator
This study proposes a novel crossover operator, which can make individual variations meet the requirements of efficiency and high speed. For example, there are two individuals of length n, parent1: 123456789 and parent2: 546923781. First, two unequal numbers between one and n are randomly generated. If the random numbers are, for example, k = 3 and m = 6 (k < m), Fig. 5(a) is used. The gene with a parent1 index that is greater than or equal to k and less than or equal to m is removed, and it is then mapped to the index of parent2. Then the gene in parent2 is reversed to obtain the gene 364925781. Finally, the positions of parent1 and parent2 are interchanged again, and offspring 2196453782 is obtained.
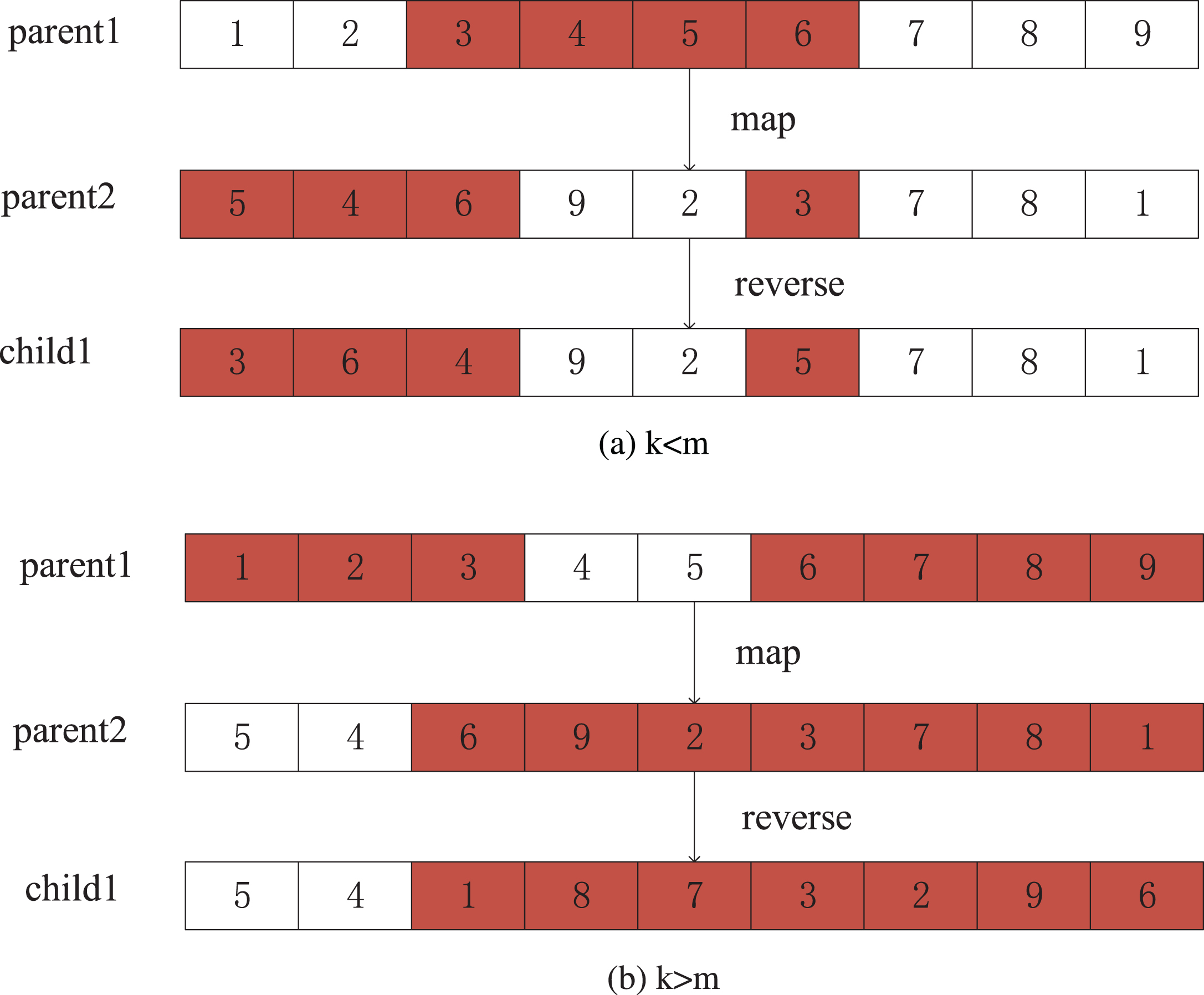
Crossover operator.
In contrast, if k = 6 and m = 3 (i.e., k > m), as shown in Fig. 5(b), then all the indices of gene subscripts of parent1 smaller than m and larger than k are removed. Then the genes are mapped to parent2, and these genes are reversed on parent2 to obtain children1: 541873296. In summary, by changing the positions of parent2 and children1, children2: 827654319 is produced.
The path analysis reveals that the interest points are not evenly distributed. Some points are densely distributed, and others are sparsely distributed. That is, not all the interest points are concentrated in a high-density region, and there are always several interest points far away from the center of the high-density region. The user will generally give up these points; hence, they can be deleted. In this section, the mutation operator is used to delete those points where the possibility of user access is below the threshold.
An interest point in the path is randomly selected assuming that the path length changes less than the distance threshold e after deleting the interest point. The similarity of the interest point to the center of the recommended path is determined, and the interest point is retained. If the threshold is greater than e, the point is redundant, and the interest point is deleted. The number of genes in the population remains stable.
Improved genetic algorithm
The pseudocode of the proposed IG algorithm is presented in Algorithm 3.
In Line 1, the trajectory path is initialized, all the trajectory paths are processed uniformly, and a number is assigned for each longitude and latitude value. In Line 2, the degree of association between each circle of friends and the keyword set K input by the user is calculated via Equation (1), and a relation circle of friends about several users is obtained. In Line 3, the joint points in this circle of friends are found. Line 4 encodes the joint points as several strings. In Line 5, these genes are randomly duplicated to form a population. Line 6 uses Equation (5) to calculate the fitness of each genetic individual. The adaptability is arranged from high to low to obtain a standardized group. Line 7 initializes the recommended population. Lines 8–16 iterate over the individuals in the group and select, cross, and mutate the individuals. Then it chooses two individuals to replace the individuals with low Fit values in the group, iterates several times, and obtains the individuals with the highest Fit values. The experimental results of Algorithm 3 are shown in Fig. 6.

Trajectory image with different iterations of the improved genetic algorithm.
The three distance parameters used in the mutation process of the IG algorithm are 0.001, 0.01, and 0.1, respectively. When the distance parameter is 0.001, the interest points recommended by the genetic algorithm are concentrated at one point, which is not suitable for medium and long distance travel recommendation. If the distance parameter is 0.01, Fig. 6(a), (c), and (e) are obtained. The trajectory image tends to converge in a block. If the distance parameter is 0.1, Fig. 6(b), (d), and (f) can be obtained. The interest points can be located in a large area, and the corresponding recommended interest points can be relatively sparse.
In this study, different distance parameters are used. If the user needs to locate a point that is most suitable for personal interest, the distance parameter can be 0.001, and the system will return a point of interest. If the user wants to travel in the short and medium term, the distance parameter can be set to 0.01, and the system will return the area that is most suitable for the user’s needs and more points of interest will be returned for the user to visit. If the user plans to travel for a long time, the distance parameter can be set to 0.1, and the system will return the interest points that meet the user’s personal preferences in a large area. The following path recommendation algorithm uses short and medium-term travel by default, and the distance parameter is set to 0.01.
Using the genetic algorithm to obtain several historical trajectory points that satisfy the user’s input keywords, users in the region can reach places by using vehicles, ships, and other medium and low-speed vehicles. According to the analysis of these trajectories, there are numerous interest points generated by the different keywords entered by users. According to the average walking speed of human beings, a rectangular moving range can be defined, within which users can walk to the point of interest.
The interest points are divided into rectangular regions so that all regions do not overlap and have a certain degree of differentiation. Route planning is then carried out between regions. Algorithm 4 is listed below.
Line 1 initializes the input data. If different users visit the same place, delete it and renumber the interest points. In Line 2, the variable m refers to the number of matrix region fusions. Lines 3–4 search every point in G’. In Line 5, the minimum matrix block is established with the point of interest as the center. Lines 6–9 expand the matrix range in turn, with each minimum matrix block as the center, where Line 7 merge partially coincident rectangles. Line 12 looks for the most suitable interest point and sends it into the path priority queue. Lines 13–16 use the greedy method to plan the path between points in the matrix blocks. Line 17 returns the path the user needs.
Algorithm 4 recommends the last step based on the pre-recommended route. First, each point of interest in the pre-recommended route is used as the initial rectangular region, and then extended in the final rectangular region. Taking the rectangular area as the recommended scenic spot, the shortest route is recommended. The experimental results of Algorithm 4 are as shown in Fig. 7. The recommended route in this study starts from the matrix area that best meets the user’s requirements. This area contains interest points and is the area that users can walk to within a certain amount of time. The greedy algorithm is then used to select the next matrix region. On the recommended route, users can visit all interest points that meet their personal preferences in the most efficient timeframe.
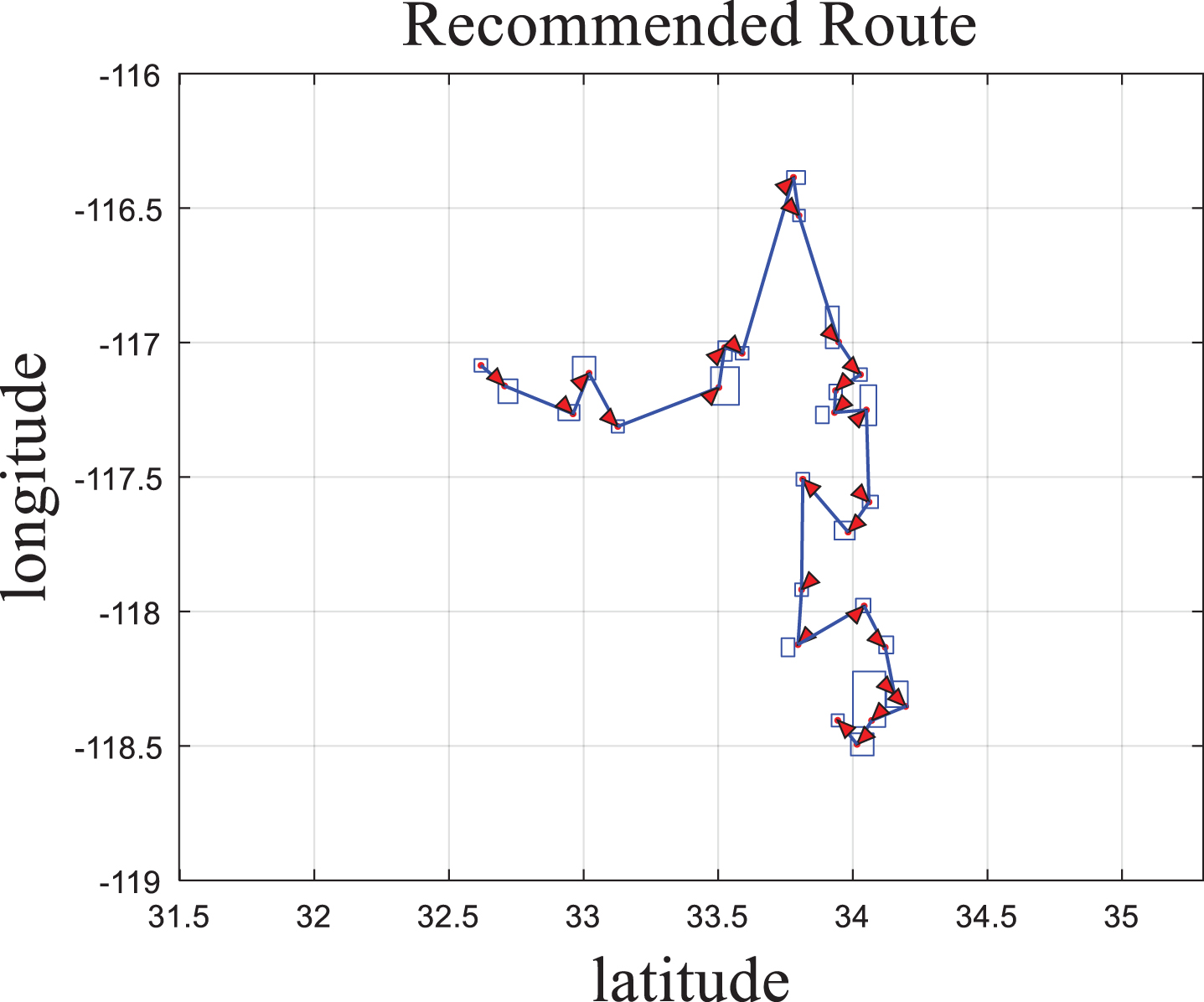
Example of recommended route.
Location-based social networking (LBSN) is a new service that combines time series, behavior trajectories, and geographic location information. This study uses two offline LBSN datasets, as shown in Table 2. The FB dataset contains valid data collected from Facebook, including user social relationships and trajectories. The CA dataset is a dataset of social relationships and trajectories of 96 users and their friends in the Taiwan Province of China. Both datasets are from the literature [24].
Details of the LBSN datasets
Details of the LBSN datasets
The computing equipment used for the experiment included a 3.2 GHz 4 Core (TM) i5-8400 CPU, 16 GB memory, and 64 bit Windows 10 OS. The proposed algorithms were realized in MATLAB 2016a.
The FB and CA datasets have two sub-datasets, respectively. The first sub-dataset is the user’s social network data. The FB dataset has 29,512 users and 39,513 friends of users. The CA dataset has 4,136 users and 32,512 friends of users. The second sub dataset is the trajectory data of all users, including the longitudes and latitudes of the tour sites, times, and keyword descriptions of the points of interest.
Clustering results of evaluation on Algorithm 1
The clustering algorithm proposed in Section 3 uses the first subset of the FB and CA datasets. The result of clustering requires a criterion to determine its advantages and disadvantages. For the evaluation of clustering results, two types of evaluation indices are generally used. One is the external index, which is used to compare the clustering results to a “reference model.” The other is the internal index, which is used to investigate directly the clustering results without using any other reference model [28]. In this paper, the original social relations are clustered into several clusters, which need to satisfy the requirements of low similarity between clusters and high similarity within clusters. Because there is no reference model for the clustering results in this study, internal indicators are used to evaluate directly the clustering results. The cluster division in the clustering results is accounted for by
The DBI, which represents the similarity between different sets, is given by
The smaller the DBI value is, the better. In addition, the DI [28], which represents the similarity between each element in the set, is given by
The larger the DI value, the better.
Because the social relationship of user input in Algorithm 1 does not have a distance, this study proposes a sample distance inference method to evaluate the performance of Algorithm 1. This is done by constructing a distance tree for all users’ social relations. The sample distance is related to the level of the tree. The definition of distance tree is as follows.
According to Definition 4, the root node should be selected to make the n-tree as similar to the user’s social relationships as possible. Thus, the sub-node with the largest number of friends should be selected to make the distance representing the user’s social relationships more accurate. This node is called the initial node. The data structure of each node in the designed distance tree is shown in Table 3.
Node data structure
Node data refers to the index of the user’s personal information, which points to the user’s personal trajectory information. Hierarchy refers to the number of layers of this node’s data in the n-tree, which indicates that this node is closely related to the user’s social contact in the previous layer. The core user point is the circle of friends of the parent node. The child node refers to other user indices of the core user point. The tag is used to record whether or not the node has been accessed (false means it has not, and true means it has).
The process of constructing the social relationship distance tree of users is shown in Algorithm 5.
Line 1 of Algorithm 5 initializes RST as the input. Line 2 finds the initial node in the input data. If the fourth line determines that the node has been visited, the fifth line is processed, and the child nodes of the processing node are traversed. If it is determined that the node has not been accessed, the node data will be processed in Lines 8–11. In Line 8, the function search_parent_data is the parent node found in RST. In Line 9, the level of the node is declared. In Line 10, the function search_child_data is the child node found in RST. In Line 11, the node pdata will be labeled as accessed. In Line 12, the function search_brother finds the next sibling node of the node pdata, and then traverses the sibling node. Line 14 is the stop condition of the algorithm (i.e., it stops when all the input data RST have been accessed). Line 15 returns the generated distance tree. In Algorithm 1, different k values are input to generate different clustering results. In the offline module, the optimal clustering results are required. The appropriate k value is used to ensure that the similarity between each circle of friends is the lowest and the difference is the highest.
Algorithm 6 is used to analyze two parameters n and k. The first parameter, n, is the percentage of the segmentation function parameter in Algorithm 1 required to segment the circle length. The second parameter is the threshold k, which determines the strength of the connection.
In Lines 1–2, the initial n values are 25, 50, and 75, and the initial k values are the integers from 2 to 10. The value of k is temporarily assigned to one of the nine integers from 2 to 10 (k = 1 is not considered here; k = 1 combines all users as a whole). In Line 3, Algorithm 5 is called to generate the distance tree, where the input data are the user’s social relationship data. In Lines 4–9, different k and n values are entered periodically. Line 6 calls Algorithm 1 in Section 3.1. Line 7 calculates the DBI and DI values according to Equations (10) and (11), respectively.
The experimental results of Algorithm 6 are shown in Fig. 8.

DBI and DI values for different k values of FB and CA datasets.
According to Fig. 8(a) and (c), when k = 2, the DBI is at its maximum value, and then decreases with increasing k. When n = 25, the DBI is greater than when n = 50 and n = 75. According to Fig. 8(b) and (d), for the same k value, when n = 25 and n = 50, the minimum DI value is obtained. When k is between 2 and 5, the DI value for n = 25 is significantly less than the DI value for n = 50. To sum up, when n = 25 and k = 2, it can meet the evaluation requirements of a large difference between clusters and achieve better clustering results.
The method proposed in this study is now compared to the following five path recommendation models. Pattern aware trajectory search (PATS) [29]. The PATS model mainly considers the sum of the scores of all points of interest on the recommended route. Then it scores each pre-recommended route. The route with the highest score is the recommended route of the PATS model. Time-sensitive routes (TSR) [30]. The TSR model mainly considers the score of the travel route time factor and calculates the total score of each pre-recommended route. The route with the highest score is the route recommended by the TSR model. Geo-social influenced routes (GSI) [31]. The GSI model considers the social factors and calculates the total score of each pre-recommended route. The highest-scoring route is the recommended route of the GSI model. Keyword-aware skyline travel route (KSTR) [30]. The KSTR method integrates the user’s geographic movements, time, and social network features into the recommended route in the probability score model. Keyword-aware representative travel route (KRTR) [24]. The KRTR method uses the representative skyline concept to weigh the geography, attributes, and time characteristics of points of interest. It can recommend the route that best meets the user’s personal requirements in a short time.
Compared with aforementioned five algorithms, the proposed method is more comprehensive in attribute, as shown in Table 4.
Attribute comparison of different methods
Attribute comparison of different methods
This paper evaluates the experimental results using three different aspects: user edit distance, area coverage [24], and algorithm time complexity.
The calculation results of the edit distance are shown in Fig. 9(a) and (b).
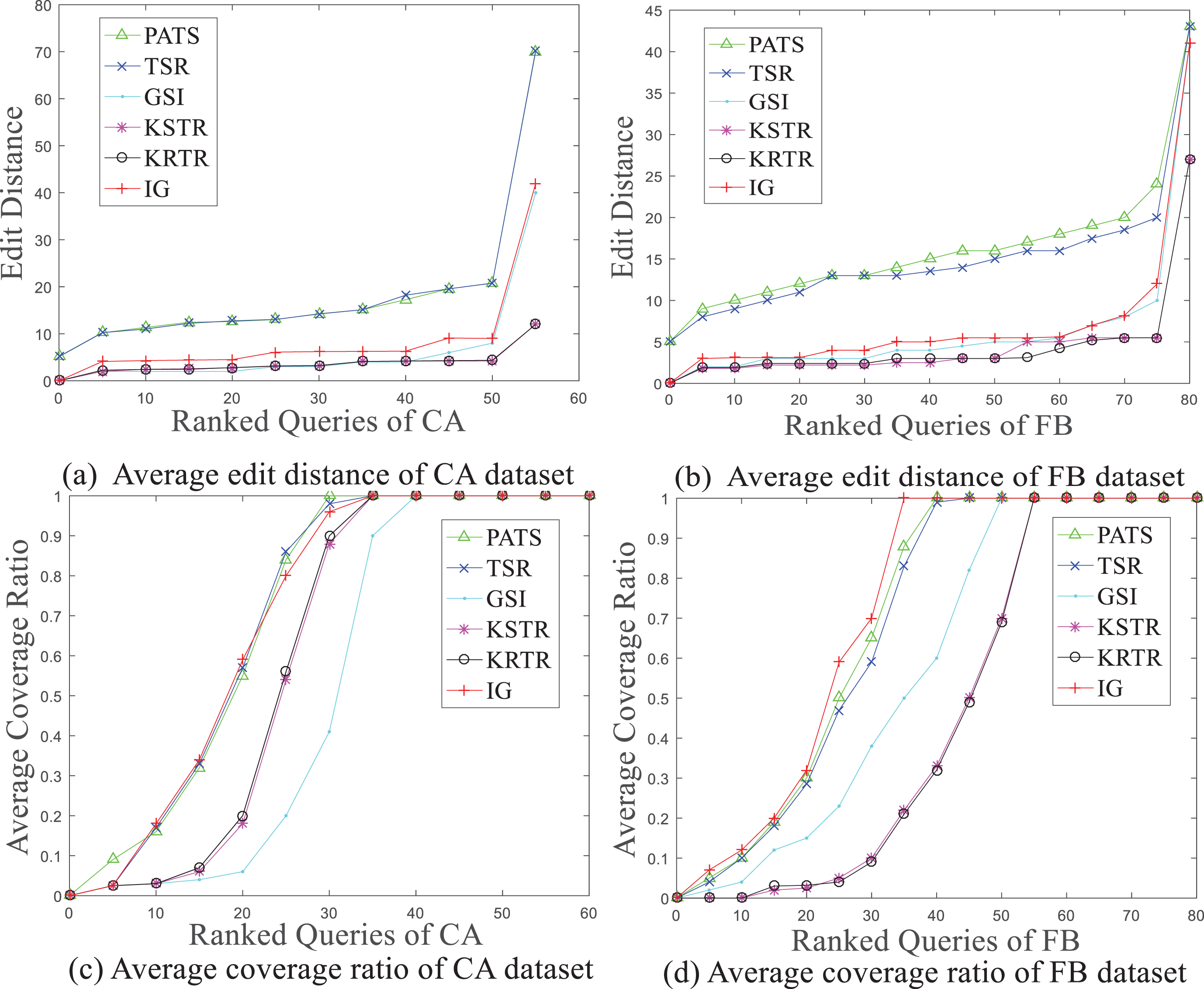
Average edit distance and average coverage ratio versus the recommended travel routes of the CA and FB datasets.
The results of Fig. 9 show that the edit distance of the IG method is greater than that of the GSI, KSTR, and KRTR methods, but less than that of the PATS and TSR methods. In the GSI, KRTR, and KSTR methods, the recommended route is to reconstruct a small number of user trajectory data such that there are more parts overlapped with the sequence of interest points in the test data. However, the PATS and TSR methods only consider the point of interest, and do not consider the user’s entire trajectory. Thus, there is less overlap with the test data. The IG method proposed in this study considers multiple user trajectories. Therefore, its edit distance is larger than that of the GSI, KRTR, and KSTR methods, but smaller than that of the PATS and TSR methods. The statistical results are as shown in Table 5; the average area coverage rate of the proposed method is better than that of the other algorithm, with increasement ratios of 1.04%, 1.96%, 21.39%, 23.68%, and 31.80%, respectively.
Comparison of average edit distance and average coverage ratio
For the FB and CA datasets, the area coverage of the IG method is compared to the above five methods. As shown in Fig. 9(b) and (d), in the CA dataset, the area coverage of the IG method is better than the above five methods combined. Considering the average area coverage, the IG method selects the appropriate interest points from the global trajectory data for path planning. In terms of the global interest points and the user trajectory that meets the requirements, it performs better than the KRTR, KSTR, and GSI methods. In terms of regional coverage, it performs better than the PATS and TSR methods.
Time complexity analysis
Suppose that the number of users in the offline dataset is n, the number of interest points is m, and the average length of each user’s historical trajectories is L. The algorithm of the IG framework in this study mainly consists of four steps: (1) analyze the social relationship of historical users in advance; (2) calculate the joint points in the user group; (3) improve the genetic algorithm to select the region; (4) segment the region and recommend the route. The algorithm of constructing a distance tree by a depth-first traversal and calculating DBI and DI values are not the main time-consuming factors in the path recommendation system, and are therefore ignored in this study.
The social relationships of users are analyzed in advance, and the users with close relationships are grouped into a cluster. The time taken by the segmentation function to divide the number of friends is O(L), and the time taken to traverse the social network of users is O(n2). Thus, the time used in this first part is O(L + n2). The traversal of each user’s interest point in depth takes the most amount of time in the calculation of the joint points in the user group. Therefore, the time of O(n2) is used. In the IG algorithm, the initialization time is a constant, O(1), which can be ignored. The main time-consuming step is the calculation of genetic operators, and that takes O(n2). In the fourth part, the time taken to segment the area and recommend the route is O(m2). In conclusion, the calculation timeframe of the IG algorithm is O(L + c1n2 + c2n2 + c3n2 + c4m2), where c i is a constant parameter. The value of m is much greater than that of L and n, so the algorithm complexity of the IG method is O(m2).
Conclusion
This study focused on the issue of travel route recommendation. The current recommendation model lacks personalization and diversity. This study developed an IG algorithm that mainly considers the influence of friends, the appropriate travel time in the path, and the possibility of meeting the user’s expectations. In the IG model, a series of keywords are first used to describe the path required by users, and the historical data of similar users are analyzed. The proposed method repeatedly screens out the joints that meet user requirements, and uses an IG algorithm to select the appropriate joints from the global region. Then these joint points are divided into matrix blocks, and route planning is carried out between them.
The experimental results showed that the average area coverage is superior to that of the traditional methods. The IG algorithm proposed in this study can be used in social services based on mobile location to provide users with personalized and satisfactory travel route recommendation services. The IG algorithm is suitable for medium and long distance travel, but not for short distance travel, because it is difficult to extract attributes of short-distance travel, which leads to large deviations. In future work, we will improve the diversity of user input and the implementation efficiency of the framework to achieve more accurate recommendations of user paths. Learning from the research method presented in [32], analyzing the movement law of popular routes in scenic spots in recent years and subsequently predicting future travel trends is also a topic worthy of research.
Footnotes
Acknowledgments
The authors would like to thank the reviewers for their useful comments and suggestions for this paper. This work was supported by the National Natural Science Foundation of China (Grant Nos. 61702010, 61972439, 61672039).