
Abstract
Detecting communities is an important multidisciplinary research discipline and is considered vital to understand the structure of complex networks. Deep autoencoders have been successfully proposed to solve the problem of community detection. However, existing models in the literature are trained based on gradient descent optimization with the backpropagation algorithm, which is known to converge to local minima and prove inefficient, especially in big data scenarios. To tackle these drawbacks, this work proposed a novel deep autoencoder with Particle Swarm Optimization (PSO) and continuation algorithms to reveal community structures in complex networks. The PSO and continuation algorithms were utilized to avoid the local minimum and premature convergence, and to reduce overall training execution time. Two objective functions were also employed in the proposed model: minimizing the cost function of the autoencoder, and maximizing the modularity function, which refers to the quality of the detected communities. This work also proposed other methods to work in the absence of continuation, and to enable premature convergence. Extensive empirical experiments on 11 publically-available real-world datasets demonstrated that the proposed method is effective and promising for deriving communities in complex networks, as well as outperforming state-of-the-art deep learning community detection algorithms.
Keywords
Introduction
In recent years, the research community has made great efforts to attempt to solve the problem of community recognition in complex networks (hereafter referred to as CNs). Community detection is an important multi-disciplinary research area, and is considered vital to understand the structure of networks [1]. It splits a CN member into several communities, whereby nodes within the same community are very similar, and less similar to nodes in other communities. Community detection is applied in many applications, including advertising and recommendation activities, link inference and influence analysis, biological and criminological processes, etc. [2, 3]. In reality, several real networks can be represented as CN, e.g. social networks, citation networks, biochemical networks, computer networks, protein-protein interaction networks, etc. All these types of networks can potentially detect and analyse useful information using a community detection task. [4–6].
Encouraged by the considerable success achieved with Deep Learning (DL) in many areas, the problem of community recognition was successfully solved with DL models. The similarity between Deep Autoencoder (hereinafter referred to as DAE) and spectral clustering in terms of feature learning and matrix reconstruction inspired the research community to propose several methods for solving the community detection problem with DAE models [7–9]. These methods are based on the unsupervised DL models (i.e., DAE) [10], which can transform the information from CNs into a low-dimensional space containing useful information that points out the similarity between CN members. The communities are identified by applying clustering algorithms on the obtained low-dimensional space. The following are examples of these models: Sparse Autoencoder (SPAE) [11], Stack Autoencoder (SAE)-based modularity [12], DAE-based modularity [13], and DAE-based nonnegative matrix factorization [14].
DL model training is an NP-heavy optimization problem, typically involving thousands and millions of parameters, which play a key role in increasing the number of local minima [15]. The most popular method for training DL models is the Gradient Descent (GD) with Back-Propagation (BP) algorithm. However, this method has three shortcomings: the slow training process, especially with large amounts of data; sensitivity towards parameter initiation; convergence to local minima [16, 17]. The existing DAE-based community detection methods were built with GD-based BP algorithm. As a result, the limitations of the GD-based BP reduce the effectiveness and efficiency in solving community detection problem. Therefore, it is an interesting subject to find an effective optimization method for the DAE-based community detection in order to overcome the limitations mentioned above.
Metaheuristic algorithms have a good track record in optimizing machine learning models, and are known as efficient methods for solving complex problems and finding optimal or near-optimal solutions in a reasonable time. They can also avoid local minima and increase the likelihood of global convergence [16, 18]. In optimization, however, metaheuristic methods are rarely used in DL models [19]. Therefore, the combination of metaheuristic algorithms for optimizing DL models is an interesting research topic.
Particle Swarm Optimization Algorithm (PSO) is one of the popular global search metaheuristic algorithms, which is a population-based optimization algorithm [20]. In PSO algorithm, the fitness function plays an important role in finding optimal solutions, and it consists of a single objective function; however, it is not effective especially for complex problems such as DAE-based community detection. Thus, it is interesting to establish a fitness function that consists of multi-objective functions, allowing optimization of DL models becomes more effective [21], although the computational complexity will be increased. A continuation method is an iterative method that starts with solving problem in a simple form, and gradually extends to the actual problem. Therefore, it is of great interest to integrate the continuation method with PSO algorithm. The integration will reduce the execution time in optimization and the probability of local minima and premature convergence [22].
In this paper, we present a new DAE model based on PSO and continuation optimization algorithms for community detection in CNs, called (DACDHC). The contributions of this work are summarized as follows: (1) DACDHC method uses PSO algorithm to learn parameters of DAE model. This allows the method to take the advantage of PSO optimization, e.g. avoid local minima and increase the probability of global convergence. Consequently, a useful latent representation of a CN is extracted, which helps in community detection task. (2) Continuation optimization method is combined with PSO algorithm to reduce execution time in optimization, and avoid the probability of local minima and premature convergence. (3) Multi-objective optimization is suggested for DACDHC method since the method includes a DAE model and a clustering algorithm, the two different objective functions used to further improve performance; the first concerns DAE training, i.e. the Mean Square Error (MSE) function, and the second is the modularity Q function, which is related to the quality of communities discovered. In addition, the paper presents the method without the continuation algorithm called DACDH and another method allowing premature convergence called DACDHE.
The paper is organized as follows: section 2 presents an overview of related works; section 3 introduces the preliminaries of autoencoder, PSO and continuation algorithms; section 4 elaborates the proposed method DACDHC in detail. section 5 presents experimental results and analysis of the proposed method; the conclusion is drawn in section 6.
Related works
Community detection with deep learning models
Several studies have proposed using DL models for community detection in the field of CNs. Most of the suggested models were built based on Autoencoder (AE) architecture, which are unsupervised learning models. The main aim of the models is to learn the latent representation of CNs, in which the network structure is preserved and similarity between network members is shown so they can easily be placed into communities. A SAE is proposed for learning the graph embedding [11]. The design was inspired by the similarity between AE model and spectral clustering algorithm. SAE also consists of several encoding and decoding layers. In addition, it uses the loss reconstruction and KL divergence functions. On the other hand, Yang et al. developed a SAE model based on modularity method [12]. The layers of the SAE are trained to create a useful latent representation of the graph. The model is extended to a semi-supervised model by including pairwise constraints. The BP algorithm and greedy layer-wise training process are adopted in the mentioned models.
Recently, Dhilber et al. proposed a SAE-based modularity model [13] as a new way to train the entire model in one training process, in contrast to [12] that adopted a separate training for each layer. In addition, the model is trained to reduce training time by sharing weights across the layers. Similarly, Fanghua et al. integrated the concept of nonnegative matrix factorization into the layer of AE model [14]. The encoder and decoder components are also integrated into the traditional nonnegative matrix factorization to form a uniform loss function. Another type of DL model has been applied in this field of study. For example, a deep sparse filtering model was established to discover communities in CNs [7]. On the other hand, Cao et al. proposed an AE that can integrate network topology and network content [23], whereby Laplace and modularity matrices are fed to the AE model. The experimental results of all the above-mentioned methods demonstrate that these methods have outperformed the traditional methods in the field of community detection. However, most of the existing models encounter the problem of inefficiency and local optimal solutions due to the use of GD with BP algorithm for optimization process.
Deep learning-based metaheuristic optimization
The success of metaheuristic method in optimization tasks has prompted the research community to solve large and difficult problems using metaheuristic algorithms. Recently, several studies have proposed the use of these algorithms for optimizing DL models to create effective and efficient models. In the field of deep neural networks, the GD is replaced by iterative metaheuristic methods to tune the parameters and overcome limitations in GD with BP. The limitations include the slow training process, sensitivity to parameter initiation and the risk of falling into local minima [16, 18]. In this subsection, we outline the recent and important studies which have used metaheuristic algorithms for training and optimizing DL models.
A PSO-based population algorithm was developed to train neural networks in [24]. The fitness function of particles is the cost function of the model, which is evaluated by the current position and corresponds to the weight matrix. The authors presented a comparative study between PSO-based heuristic method and BP methods. Similarly, Zhang et al. integrated both PSO and BP in a model for neural network training [25]. This integration aims to take advantage of both algorithms. PSO performs a global search at initializing phase of the weights followed by a local search around the global optimum by BP algorithm. On the other hand, ACO algorithm is used to feedforward neural network model [26]. Two optimization algorithms are suggested: to train the model based on the stand-alone ACO optimization algorithm; to use BP and ACO. A bat algorithm was employed to optimize both the structure of artificial neural network and the parameters (i.e., weights) In [27]. The work suggested two modifications to the bat algorithm, which named MBatDNN and MeanBatDNN.
Metaheuristic methods have also been used to optimize DAE model. Parameters optimization (i.e., weights) was achieved using GA-assisted AE model [28]. The proposed method overcomes the problem of tied weights in encoder and decoder models to enhance the accuracy in classifications. On the other hand, PSO algorithm was integrated with AE by incorporating PSO into marginalized Stacked Denoising AE to tune the parameters [29]. PSO can hold the best configuration of the marginalized AE. Despite the good results achieved using these methods, most of them still lack in efficiency or effectiveness, or both.
Optimization by continuation refers to the solving of a problem starting with the easy form and gradually expanding to the actual problem through iterations [30]. The purpose is to reduce optimization time and maintain the performance. A continuation method was proposed for training and optimizing neural network models using metaheuristic algorithms [22]. The experimental results demonstrate that continuation method of the three studied metaheuristic algorithms have improved the efficiency of the training and reduces the execution time by 5–30 % compared to the standard metaheuristics. Similarly, incremental learning is suggested for such task, which means the learning of streaming data that arrive over time [31]. In this method, the models are train based on a new batch of data and an earlier model. This method requires limited memory resources without sacrificing the model accuracy.
Community detection and PSO algorithm
In this section, we provide an overview of some important works that have been proposed for community detection-based metaheuristic algorithm, solely (i.e., without DL models). Single-objective metaheuristic algorithms, especially PSO, have been suggested for community detection in CNs field. In [32], a method was proposed to solve the problem of community detection using PSO algorithm. The method utilizes network modularity and eigenvectors for optimization process. The method can automatically detect the number of communities and the particles required in a low-dimensional structure. Similarly, the work in [33] proposed the use of PSO to find communities in CNs based on the modularity function. The method aims to maximize the modularity function that meets a fitness function. The method was evaluated in a small network and achieved acceptable results. However, a single objective optimization does not work well and may fall into a local optimum trapping.
Multi-objective optimization algorithms was proposed to overcome the disadvantage in the single objective optimization. For example, a method using multi-objective PSO in [34]. The two objective functions are Kernel k-mean and ratio cut. This work was further extended in [35] through modifications of the two objective functions to solve the problem of low efficiency and large search space. Similarly, an anti-colony multi-objective algorithm was developed for community detection in CNs in [3]. The algorithm optimizes two objective functions: the community score that measures the cluster density; the fitness function of the community that minimizes the external links. Despite their effectiveness, they have only been used for simple and small datasets, in addition to the high computational complexity. These methods too may fall into local optimum solution.
In this work, a DACDHC was developed based on a DAE model to solve the problem of community detection in CNs. PSO and continuation algorithms have effectively and efficiently trained and optimized the model. Two different objective functions were used to further improve the performance; the first concerns AE training, i.e. the Mean Square Error (MSE) function, and the second is the modularity Q function, which is related to the quality of communities discovered. The advantage of PSO optimization includes the ability to avoid local minima and increase the probability of global convergence, while the continuation method reduces execution time and the probability of local minima and premature convergence. In short, the proposed method was designed to benefit from the merits of existing methods to solve the community detection problem.
Preliminaries
Graph concepts
A graph G consists of nodes V and edges E as G (V, E), where the number of nodes and edges is n and m, respectively. A CN is a graph in context theory, and most graph theories can be employed in complex networks. The adjacency matrix
In this phase, each node has a vector of features corresponding to the number of nodes n in the graph, but these features are sparse (i.e. zero, indicating that there is no relationship between the nodes and no common neighbours between them). In addition, the number of features is huge, especially for large networks, and this has a negative effect on the efficiency and effectiveness of the working model. Therefore, a reasonable number of features should be used; it can be achieved by calculating the average of a set of neighbouring features by reducing them to one feature [36]. The number of features that averaged to one is determined by a hyper-parameter called F, to which F belongs (1 > F > n). For example, if we have a simple network with 100 nodes, each node has a vector feature of size 100 according to the Jaccard similarity calculation. When F = 2, this means that two features are reduced to one (i.e., 1, 2=>1, 3, 4=>2,...99, 100=>50. The size of the new features is therefore 50, and in case of F = 4, the new features will be 25, and so on. The new feature size is based on the following:
This method was chosen because it is easy and efficient to create a new version of the data that reflects the original data. In terms of the effect and efficient latent representation in relation to the clustering process, it is derived from the DAE model proposed in this paper.
The autoencoder model is a feedforward neural network that reconstructs the output data so that it is similar to the input data [10]. It has two phases: (1) The first phase is called encoding, where the hidden layer
Community detection aims to divide the network into dense groups, which typically correspond to entities that are closely related, and may belong to a single community. This is based on the similarity between spectral clustering and unsupervised DL models (i.e. AE model). AE model has proven its ability to solve the community detection problem, which works as follows: AE model receives the CN representation; then, after the model training process, the latent representation with low-dimensional feature spaces of a CN is extracted, showing the similarity between the CN members and ignoring the dissimilarity; finally, a clustering algorithm is applied to the latent representation to assign the nodes to communities [7, 39].
Several metaheuristic algorithms were successfully utilized for the deep neural networks training. Metaheuristic algorithms can avoid local minima and increase the likelihood of global convergence [22]. PSO is a population-based optimization algorithm [20]. Since PSO algorithm is a population-based metaheuristic optimization, it has proven to be a good global optimization algorithm for various optimizations. It generates good knowledge that is learned through local experience of each particle. In addition, the algorithm supports constructive collaboration and information sharing between all particles, thereby improving the search performance for a global optimal solution.
PSO uses a stochastic optimization technique and mimics the behaviour of swarms of birds to find the solution for the optimization problem. Many particles are generated stochastically across the search space to construct a swarm. Each particle is generated to represent a solution candidate for the optimization problem, and each particle is defined by a D-dimensional vector containing trainable parameters. Then, an evaluation process based on the fitness function f (X i ) is carried out with a certain number of generations. The particle moves in the search space with a certain velocity. The particle can return to the best previous position based on memory, which is determined by the best previous performance of the individual particle (pbest) and the best previous performance of all particles (gbest) [20].
The current position is expressed as X
i
= Xi1, Xi2, Xi3, . . . X
iD
). The following equations represent the basic of PSO:
As for updating the best positions:
Continuation optimization refers to a general approach that is not dealing with the whole problem from the beginning of the optimization, i.e. it starts to solve the problem from simple to difficult, from simple to complex or from small to large. This change occurs progressively through iterations of the optimization [30].
This subsection presents the details of the proposed method DACDHC, which was used to identify communities with DAE model-based metaheuristic PSO and continuation optimization algorithms. In the DACDHC method, AE model is trained and its parameters are tuned using PSO metaheuristic and continuation optimization algorithms instead of GD-based optimization. PSO proposes several solutions corresponding to the number of particles, each solution involving its own tuning of the model parameters and the assignment of nodes to communities. Figure 1 and Algorithm 1 show the steps and structure of the method (DACDHC). DACDH is a method without continuation algorithm, while DACDHE is similar to DACDH but enables early stopping when premature convergence occurs.
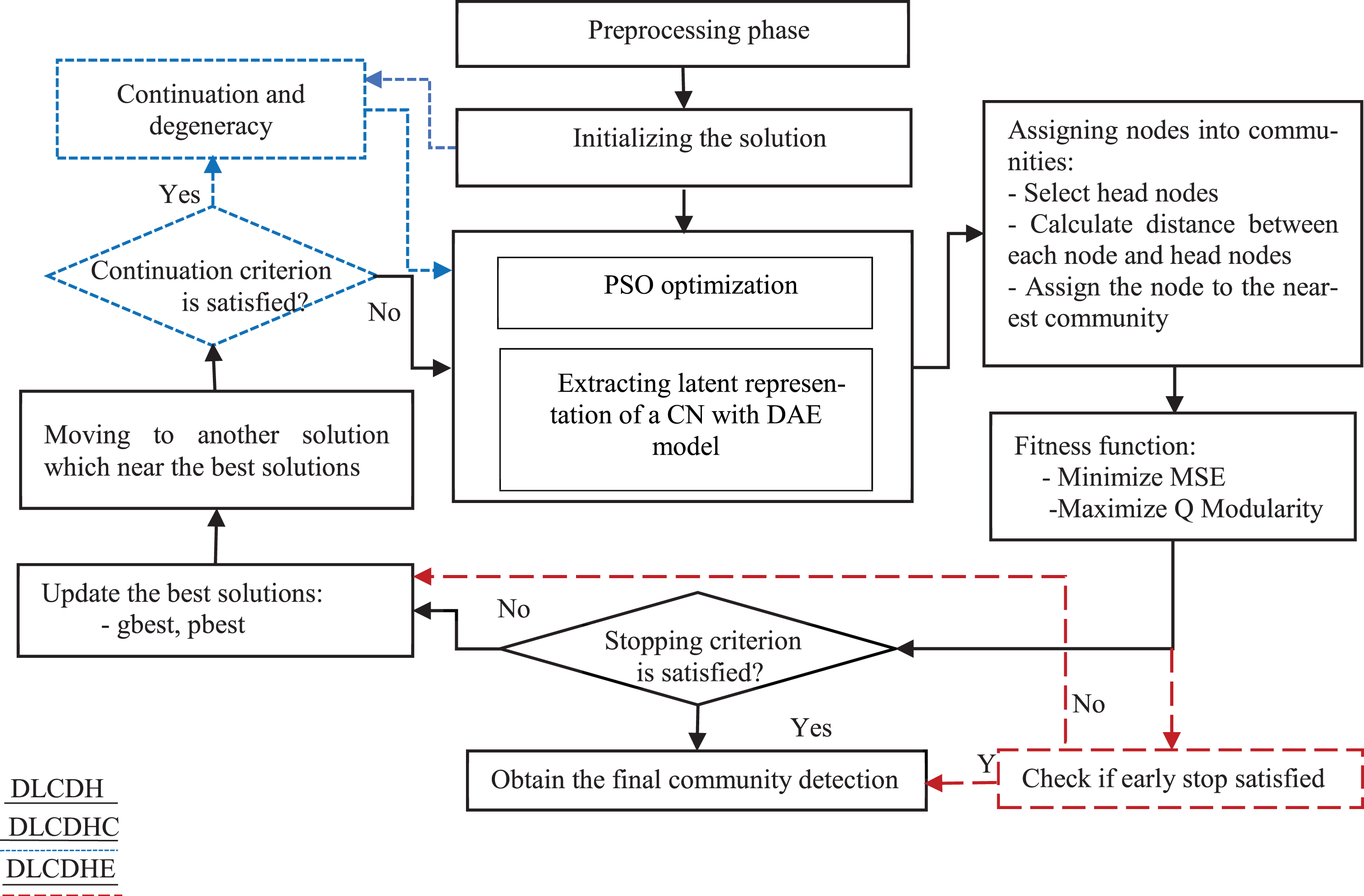
The steps and structure of proposed methods.
The proposed methods start with the preprocessing phase. The phase receives the graph nodes n and edges e, then finds the similarity representation of the graph based on the Jaccard similarity using Equation (1).
The features are also reduced to a certain number of features by Equation (2). At this stage the data is ready to be sent to DAE model for the training process. The data is then subjected to the DACDHC, DACDH or DACDHE method. The methods are explained in detail in the following subsections.
In DACDHC method, the output of preprocessing step is sent to the continuation algorithm based on the degeneration or k-core method. Then, the initialization of the particles produces first solutions. The initial solutions are sent to the continuation algorithm based on the degeneration or k-core method. The continuation algorithm sends the CN data and initial solutions to DAE model for a training process in several phases. The early phases send small size sub-CNs with nodes that have a high degree (d), and gradually, the subgraph size is increased based on the degree until the entire CN is reached over iterations. The evaluation of the solution is performed on a single batch because the second fitness function (i.e. the modularity function) requires all CN or sub-CN nodes that are in the training process. Therefore, the continuation starts sending the important nodes to the model and the CN size is gradually increased over the iterations.
K-core refers to the maximum subgraph generated, whereby all vertices have a degree of at least k. Increasing a subgraph based on node degree makes it possible to create a new subgraph with new nodes based on k degrees (i.e. a k-degenerated graph is an undirected graph in which each subgraph has a vertex with a degree of at least k). In this work, the degree was based on the original graph, not on the degree of the generated subgraph. The basic continuation process includes the following steps: k degrees are initialized to guarantee that around 5 % of the total size of the graph is generated; next, the change from the previous k-degenerate phase to the next phase is determined, which allows the addition of another subgraph with new nodes alongside the nodes in the current subgraph, where the change is based on the kd value. The subgraphs are generated as follows:
Consequently, the local solutions for all particles are expressed as follows:
On the other hand, the global solutions are expressed as follows:
For clarifications, this is an example of how the process continuation works, which details are shown in Fig. 2 (a-e). In Fig. 2 (a), the original graph, where red nodes have the highest degree, followed by green, orange, and pink nodes. The graph has 20 nodes, the maximum degree is max_d = 9 and the difference between the phases is kd = 3, which indicate the increasing graph size from the current generation to the next generation. The beginning allows for creation of at least 5 % of the original graph by adding nodes with degree of max_d or max_d - kd. The subgraph is progressively extended in phases over iterations up to z + 1 = 4 phases, where k = 9, 6, 3, 0, as shown in Fig. 2 (b), (c), (d) and (e). In Fig. 2 (b), a subgraph that has nodes with a degree greater than or equal to 9 is selected, and (c) a subgraph with nodes having a degree of at least 6, until the final phase, in which the entire graph nodes with degree k = max _ d -- (z × kd) = 0, is added. The continuation optimization process feeds the subgraphs into DAE model and PSO optimization, progressively by iterations.
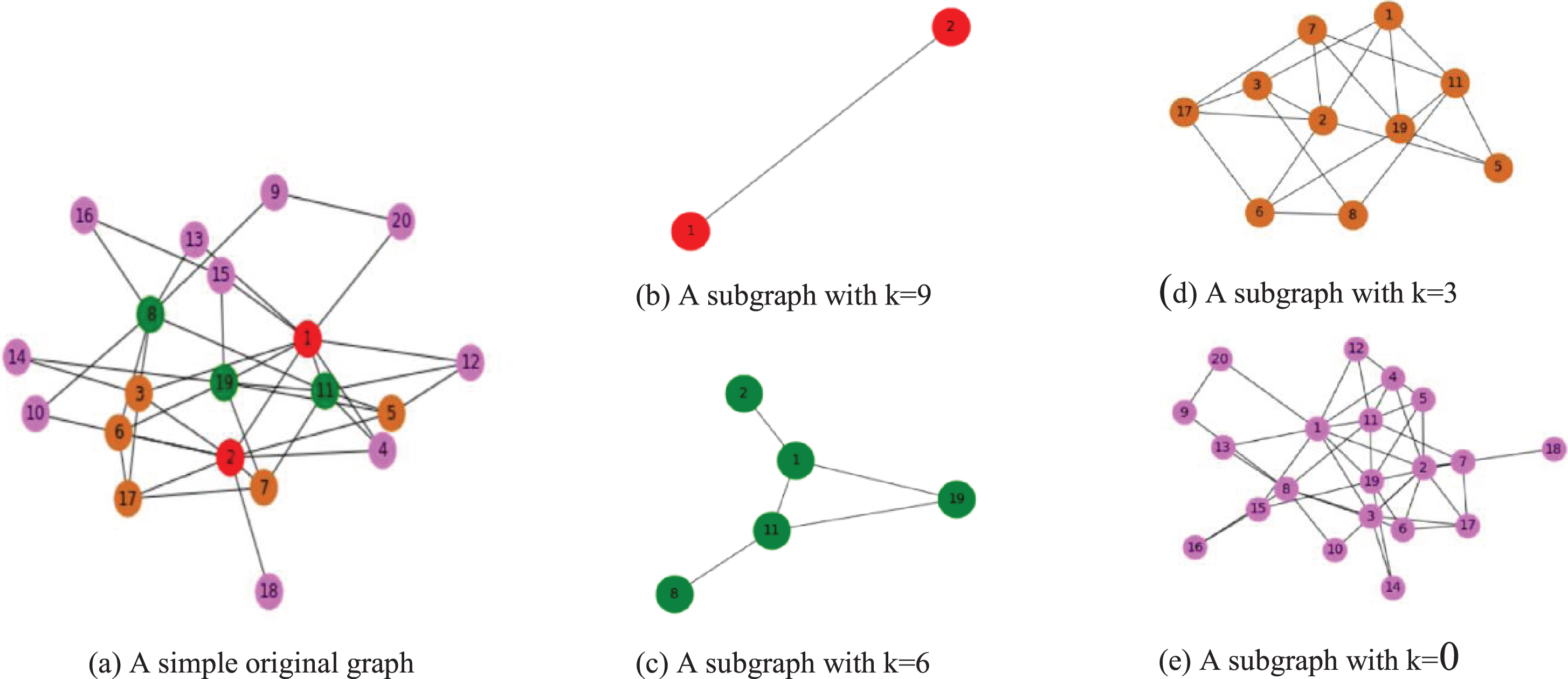
A simple graph to illustrate the continuation-based k-degenerate method.
In the k generation of subgraphs, all operations of the PSO and AE are performed for all generations. In addition, fitness function is calculated as MSE-AE and Q-modularity functions in each phase and generation. The MSE-AE is calculated based on Equation (3) while the Q- modularity is calculated based on (8). The Q-modularity function requires the assignment of nodes to clusters. Consequently, the trainable parameters and fitness values are updated iteratively.
After the continuation process selects the subgraph (i.e. sub-CN), the initial solutions and the selected subgraph are sent to the PSO algorithm to train AE model, which extracts the latent representation for the nodes in the subgraph; the latent representation is then sent to the clustering process. Next, based on the extracted latent representation, the nodes are assigned to the appropriate communities. This phase begins with the selection of the head nodes having the highest degree, where the number of head nodes corresponds to the number of communities, identified as cluster centres. Then, the distance between each node and the head nodes is calculated using Euclidean distance, and the nodes are assigned to the nearest head node to form the communities. The assignment of nodes and model parameters are sent to the evaluation phase.
In evaluation phase, the fitness function includes two objective functions: the first is the minimization of MSE using Equation (3); the second is the maximization of the modularity Q using Equation (8), but generally added to MSE as minimization (1-Q), to be employed for the same goal of community detection and MSE. The fitness function starts with receiving AE parameters and calculates the MSE based on Equation (3). In the first few iterations of the optimization process, the fitness function continues to calculate only the MSE. After the MSE value has improved and reached a certain value known as the MSE improvement value (MSEI), which is less than one, the second objective function is added and used alongside the MSE, which is a Q-modularity function based on the following equation:
Based on the fitness function, the globally best solution is selected from all proposed solutions represented by the particles; the locally best solution is also selected in the same manner. At this point, the first iteration of the optimization is already completed, moving to the next iteration, which starts with creation of a new solution based on the selected local and global solutions using Equations (4) and (5). The new solutions are close to the best local and global solutions. The solutions refer to AE parameters, q, including weights,
This method follows the same steps as in the DACDHC method, except that the continuation method is excluded. And the model deals with the whole CN from the beginning of the training to the end. The method starts with the PSO to initialize the particles, which are the solutions for tuning parameters of AE model (i.e. weights and biases) and the assignment of nodes to communities. Then, the latent representation is extracted and the nodes are assigned to the communities. This is followed by the evaluation phase, during which the two objective functions MSE and Q are calculated. Based on the evaluation, PSO updates the local and global solutions and create new solutions that are close to the best global and local solutions using Equations (4) and (5). All of the above operations are repeated until the convergence is reached by the end of iterations. The steps are listed down in black in Fig. 1 and in Algorithm 1, where continuation parameter is False.
DACDHE
This method is similar to DACDH, which starts with feeding the entire graph to the model. However, it allows for premature convergence when the model gets stuck at a certain point of optimization, which is when the discrimination threshold is E = 0.1e-10. If the threshold is reached with 5 consecutive iterations, the method aborts processing to save computational costs. The additional steps in the method are shown in red alongside the existing steps in black in Fig. 1 and in Algorithm 1, where the early stop parameter is True.
Experiments
In this section, extensive experiments carried out to evaluate the proposed methods with respect to their efficiency and effectiveness are described. First, the experimental setting, datasets, evaluation metrics and comparison models are presented followed by the four available models in this area. Finally, the experimental results and meaningful analyses of the selected results are described in detail.
Experimental setting
The proposed method was evaluated on the benchmark dataset using a single machine that has Core i7 processor, 8 GB RAM and NVIDIA GeForce (GT 840) with 4 GB memory. The Python programing language and Pyswarm package [41] were utilized.
The suggested methods were evaluated and analysed on 11th common real CNs. The datasets were selected because they are commonly used by the researchers working in the area of community detection. Furthermore, the diversity of these datasets in terms of content, size and sources, allows an accurate evaluation of the proposed methods. Six datasets of small networks contain the truth labels (i.e., each node was assigned to real community) namely Karate, School6, School7, Dolphns, Football, and Pol-books. Another five datasets ranged from medium to large networks, namely Political-blogs, Citeser, Cora, Facebook 1, and Facebook 2. The details of these networks are listed in Table 1.
Dataset information
Dataset information
The preprocessing phase included a hyperparameter F, which averages several adjacent features to a single feature, where it is defined depending on the size of the dataset as follows: F = 2 for Karate Football and Pol-books networks, and F = 20, 30, 35, 40, and 200 for Political-blogs, Cora, Citeser, Facebook 1, and Facebook 2 networks, respectively. The F value was set based on the best value obtained from the experiments.
DAE was set up as follows: Sigmoid and Relu-wise elements were used for the proposed method, where Relu was used for the hidden layer and Sigmoid for the encoding and decoding layers. DL architecture includes 3 encoding layers as well as decoding layers. PSO was set up as follows: Particles p = 20, c1 = 0.5, c2 = 0.3, and inertia weight w = 0.9. The settings for the continuation method were determined as described above. The hyperparameter MSEI was set to 0.9. The number of iterations for the optimization was set to 100.
Two accurate metrics are presented here to validate the effectiveness of community detection methods: the first is Modularity Q, and the second is Normalized Mutual Information (NMI) [51]. The modularity Q metric was applied to evaluate the quality of community detection on real CNs since the truth label was unknown in most real CNs; it is defined by Equation (8). As for NMI, it was used for CNs with the known basic truth; it is defined as follows:
On the other hand, in regard to the method efficiency evaluation, the time consumption and the speedup metric were adopted [52]. Speed up of Method A over Method B can generally be defined as follows:
Four recently available DAE-based methods for community detection are presented in this section. These methods were used to validate DACDHC, DACDH, DACDHE methods as they have been used for GD-based BP optimization, and procedures are available online. SPAE [11]. It is one of the earliest methods proposed with DL for community detection. SAE based Modularity (SAEM) [12]. It maximizes modularity with DL for community detection. DAE based Nonnegative Matrix Factorization (DANMF) [14]. It combines DAE and nonnegative matrix factorization principles for community detection. DAE based Modularity (DAEM) [13]. It uses the sharing of weights across the layers to reduce the memory and time complexity of the method. The implementation of these methods is available online at GitHub’s pages namely SPAE
1
, SAEM
2
, DANMF
3
and DAEM
4
.
Results and discussions
Effectiveness evaluation
In this section we evaluate the effectiveness of the proposed methods (DACDHC, DACDH, and DACDHE). The suggested methods were applied to six different real datasets, which are presented in Table 1. The mean value of the NMI and Q modularity metrics over ten runs were reported. The performance of the four state-of-the-art algorithms mentioned above was also evaluated using the same datasets. Tables 2 and 3 show the experimental results obtained using the state-of-art and the proposed methods to solve the problem of community detection with DAE model.
Performance evaluation based on NMI
Performance evaluation based on NMI
Performance evaluation based on Q
Based on Table 2, the results demonstrate that the DACDH method provides comparable and competitive results compared to other methods. In the Karate network, we found that the extracted communities matched the ground-truth communities and reported the NMI value of 1.0. For most of the remaining datasets, we found that DACDH achieved a higher NMI value than the state-of-the art methods (i.e., SPAE, SAEM, DANMF, and DAEM). The results also demonstrate the reduced performance using DCCDHE method as compared to that of the state-of-the-art methods, as the former focuses on reducing the running time. Table 2 shows that the best NMI was reported from using DACDHC on most datasets, with a value of 1.0, 1.0, 0.90, 0.88, 0.96, 0.68, and 0.56 for Karate, School6, School7, Dolphins, Football, Polbooks, and Polblogs networks, respectively. DACDHC outperformed other methods by exploiting the advantages in DL and PSO algorithm optimization, which allows for an escape from the local optimal solutions. Furthermore, the continuation method helps in avoiding local minima and premature convergence by preventing the procedures from getting stuck at a particular optimization point through progressive addition of new data to the model. As a result, the performance improved significantly, as shown in Table 2.
The quality of community detection was taken into account in this work, which was evaluated using the modularity Q metric. The evaluation demonstrates that there is a denser relationship within communities than the relationship between communities. Table 3 compares the result of modularity Q obtained using the suggested methods applied to the seven real CNs. The method DACDH performed slightly better than other methods (i.e., SPAE, SAEM, DANMF, and DAEM) when applied to most of the CNs. The gain is due to the optimization-based PSO, which can overcome the local optimization; the traditional models are often carried out using gradient optimization by BP algorithms (Note: GD optimization has been adopted in all of the state-of-the-art methods). Overall, DACDHC outperformed other methods proposed in this study when applied to most of the datasets. The outperformance can also be interpreted using NMI values in the same manner as discussed above. On the other hand, the weakest performance was observed in the use of DCCDHE due to the early stop; the method improves efficiency by allowing termination of optimization process when the model is stuck at one point.
The performance of DACDHC was also evaluated in medium and large networks namely Cora, Citeser, Facebook and Facebook 2, solely based on with Q-metric due to the unknown ground truth of some datasets such as Facebok as shown in Table 4. The results in Table 4 show that DACDHC records the best Q metric values for most datasets compared to other proposed methods. There is also a significant drop in performance observed in the use of DCCDHE method. The performance of DACDH was slightly lower than DACDHC. In general, the results obtained from the performance analysis in medium and large networks do not differ that of small networks (i.e., Karate, Dolphins, School6, School7, Football, Polbooks and Polblogs).
Performance evaluation based on Q with large networks
The results presented in Tables 2–4 show the outperformance of the proposed methods compared to the four state-of-the-art methods. This is due to the newly proposed fitness function that combines two objective functions (i.e. MSE and Q). The cost function of AE (MSE) is designed to extract a latent representation for each node of a CN with low-dimensional feature space and to preserve the original structure of the CN representation. Modularity function (Q) directs the extracted latent representation towards the task of community detection as the function binds each node to the appropriate cluster and performs a fast evaluation based on the Q. In other words, the new representation of CN nodes is similar for nodes with the same structure. As a result, the clustering algorithm assigns similar nodes to the same community, enabling the separation of different communities.
A) Running time: this paper also takes the efficiency of the proposed methods into account. This subsection presents the running time rendered by the proposed methods. As discussed in the previous section, the DCCDHC method is identified as the best in terms of effectiveness, followed by DACDH and DCCDHE; worst performance was rendered by DCCDHE as the method focuses solely on efficiency that it compromises the accuracy.
The efficiency is determined by the running time required to operate the method. Figure 3(a-e) shows the running time rendered by DACDH, DACDHC and DACDHE when applied to the 11th real CNs presented in Table 1. In Fig. 3(a), it is clearly observed that the running time of DACDHC is longer than DACDHE but shorter than DACDH when applied to Karate and Dolphins dataset, signifying the highest efficiency rendered by DACDHE and the lowest by DACDH. Similar results are observed in Fig. 3(b-e) for all of the remaining real CNs, namely School6, School7, Football, Polbooks and Polblos, Cora, Citeser, Facebook, and Facebook 2. It is important to note that the results also demonstrate that the difference in the running time of the proposed methods becomes larger as the CN grows larger.; Fig. 3(a) presents the CNs with the smallest size (i.e., 34 and 62 nodes) while Fig. 2(e) presents the CNs with the largest size (i.e., 4039 and 22470 nodes). In general, the efficiency of DACDHC and DACDHE is improved as the size of the CN grows in comparison to DACDH.
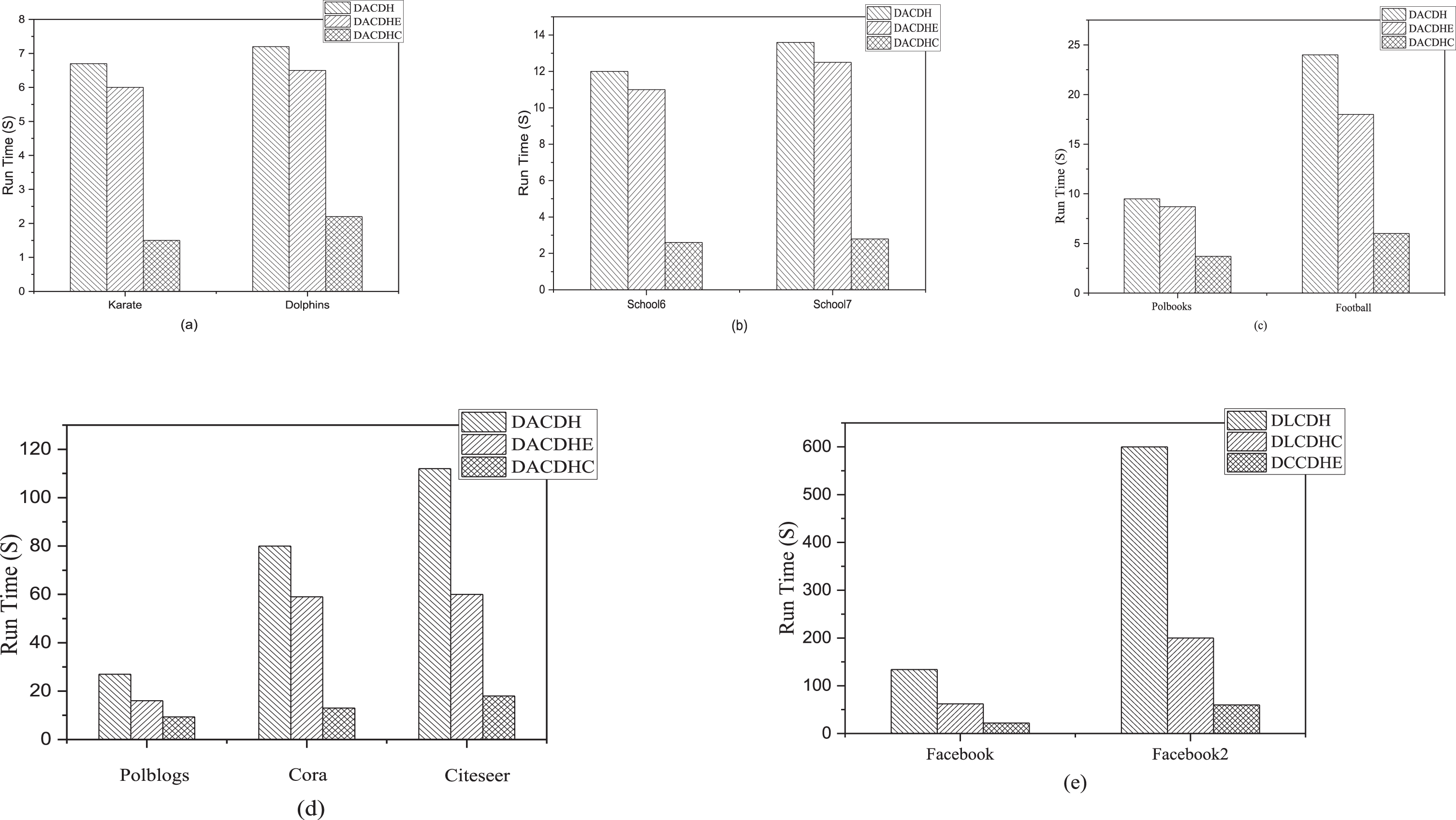
Running time of the proposed methods on different 11th real complex networks.
DACDH is the original design that combines the PSO heuristic algorithm and DAE model to find communities in CNs. From the results in Fig. 3(a-e), it is clear that DACDH requires the longest running time when applied to all real CNs because the method deals with the entire CN from the start of the training until the end. Furthermore, the modularity fitness function requires the assignment of all nodes to all clusters prior to evaluation in each iteration of the optimization. The method also has an optimization threshold, which at some point can be stuck in premature convergence; even after several iterations, only small improvement in the optimization can be achieved. On the other hand, DACDHE method allows for a stop in optimization process at a certain threshold value to avoid wasting time on optimization that does not make sense. Therefore, the results indicate that DACDHE renders the highest efficiency as compared to other suggested methods. Notably, DACDHE sacrifices performance, as observed in the performance evaluation presented in Tables 2, 3, and 4. DACDH does not allow for an escape in the event of being stuck in premature convergence regardless of the number of iterations.
On the other hand, the results demonstrate that the use of DACDHC has not only improved the performance, but also has improved the efficiency in comparison to the original version of the method (i.e., DACDH). The improvement is due to the continuation-based degeneration method, whereby the graph or CN of different sizes (i.e. subgraphs based on degree of node) from small up to the original size of the CN are progressively fed to the model. As a result, the model runs fast during the early iterations on the small subgraphs because the evaluation phase (i.e., the calculation of the Euclidean distance between nodes and centres, the assignment of nodes to clusters, the calculation of MSE and Q objective functions) is performed on small data. The method also benefits from the early optimization performed on small subgraphs during the early iterations. Thus, the performance and efficiency of the are improved.
The number of communities is also considered in evaluating the efficiency of the proposed methods. Figure 4 illustrates the running time of the proposed methods when applied to CNs with communities of different sizes. It is clearly shown that with the increasing number of communities, the running time increases. This is due to the objective function of modularity, which requires the nodes to be assigned to the nearest cluster centre and the Euclidean distance to be calculated, which leads to an increase in overall process optimization.

Running time of the proposed methods on CNs have communities with different sizes.
The largest fraction of time for optimization is spent on fitness function as it consists of two objective functions, namely MSE and Q; Q assigns each node to a suitable cluster and evaluates the detected clusters according to Equation (8). The functions are also influenced by the size of CN and the number of iterations required for the optimization. Thus, according to Fig. 3(a-e), DACDHC outperforms DACDH as the size of CN gradually increases throughout the optimization process in the former. In this case, the DACDHC runs fast during most of optimization iterations, especially during the early iterations. On the other hand, DACDHE surpasses DACDH too as it takes advantage of the premature convergence, which allows for a stop in the optimization process.
B) Speedup gain: the speedup gain of DACDHC and DACDHE methods as compared to DACDH, the original version of the proposed method, was calculated. Firstly, the speedup gain of DACDHC over DACDH was calculated, followed by calculation of the speedup gain of DACDHE over DACDH. Figure 5 demonstrates the greater performance of DACDHC than DACDH with the following speedup: 1.3X speedup reported in small networks, namely Karate, Dolphins, School6, School7, Football, and Polbooks; 1.8X speedup in medium networks, namely Polbooks, Cora, and Cteser; around 2X and 3X speedup in large networks, namely Facebook, and Facebook 2, respectively. Figure 5 illustrates the greater performance of DACDHC than DACDH with the following speedup: 4X speedup reported in small networks, namely Karate, Dolphins, School6, School7, Football, and Polbooks; about 6X speedup in medium networks, namely Polblooks, Cora, and Cteser; about 6X and 10X speedup in large networks, namely Facebook and Facebook 2, respectively.
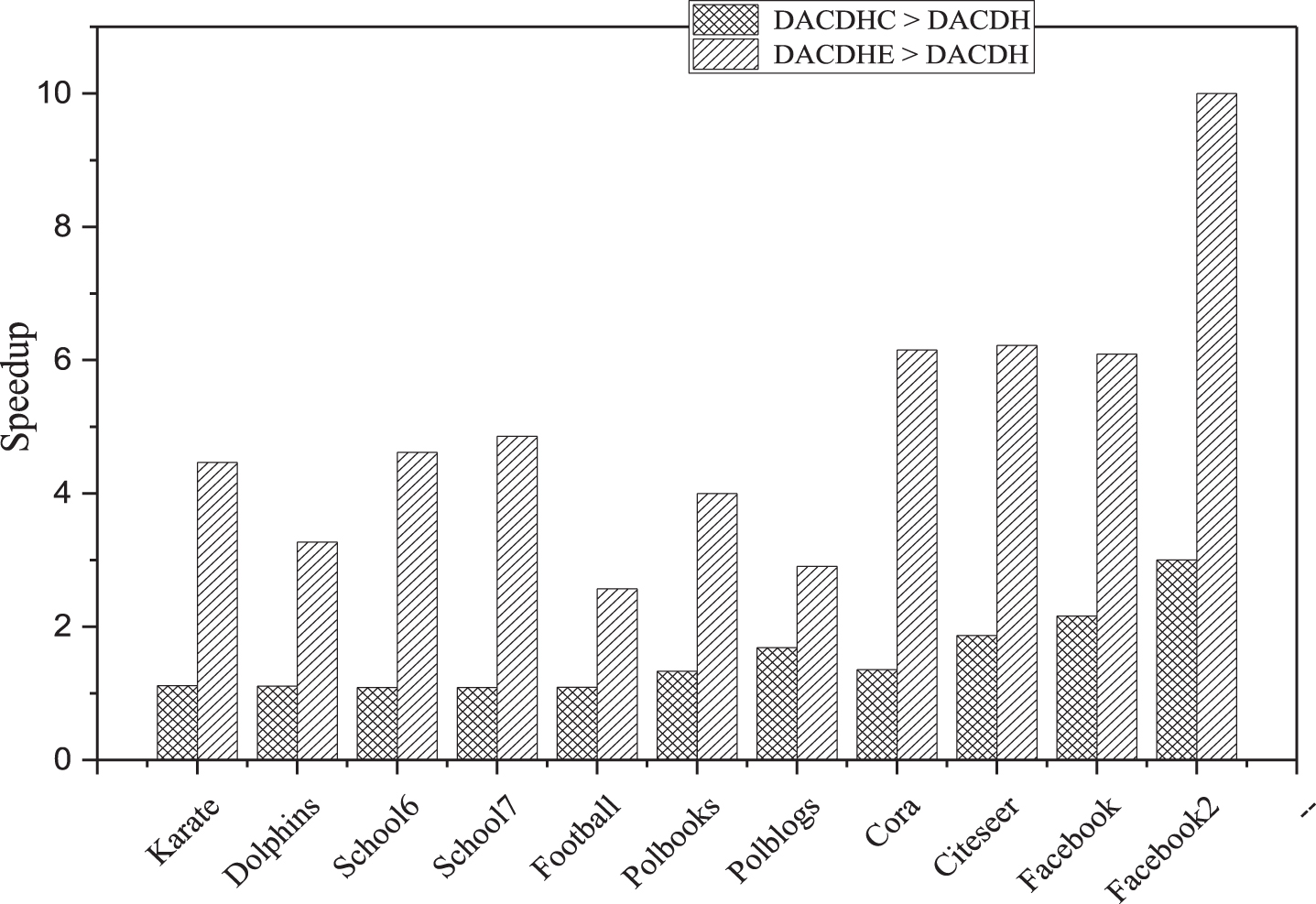
Running time of the proposed methods on CNs have communities with different sizes.
The results demonstrate that the speedup of DACDHE is greater than DACDHC due to the reason discussed above, which is related to premature convergence and its focus in improving the efficiency by compromising effectiveness. DACDHC uses a continuation strategy to improve both the effectiveness and the efficiency of the original method, DACDH. It is also found that the speedup of DACDHC is enhanced with the increase in network size; the continuation strategy allows the model to start the iterations on small network by including the important nodes with high degree and progressively proceed to a lower degree until the original size is reached. Via DACDHE method, it is also found that the speedup increases as the size of the network increases; however, the increment is unstable as it depends on the occurrence of premature convergence.
In summary, we find that the integration of metaheuristic algorithm, exemplified by PSO, to optimize DAE-based community detection method has demonstrated promising performance as compared to the traditional optimization that relies on GD optimization using BP algorithm. The integration overcomes the limitations in traditional optimization, which include the local optimization and the high computational cost of BP. Furthermore, we find that the integration of continuation method to metaheuristic PSO algorithm plays an important role in improving both efficiency and performance as demonstrated by the results obtained from the use of DACDHC method. The integration prevents the process from getting stuck at a particular optimization point by progressively adding new data to the model, in the same way that it improves efficiency. We also find that enabling premature convergence leads to significant performance losses despite the contribution to the efficiency gains, as observed in the results obtained from the application of DACDHE method.
In this paper, DACDHC is presented as a new method for DAE-based community detection using PSO and continuation optimization algorithms. Via this method, PSO trains DAE model to extract the useful latent representation and use it for community detection. PSO was used to overcome the limitations in GD optimization with BP algorithms, which includes the probability of local minima and the inefficiency of BP algorithm. Furthermore, a continuation strategy was employed to reduce the time required for the optimization and avoid the local minima and premature convergence. A continuation algorithm feeds the CN data progressively through iterations based on the k-core method. The proposed method employs two objective functions that include minimizing MSE and maximizing Q modularity function, which refers to the quality of the communities detected. In addition, the paper presents on DACDH method, which operates similarly to DACDHC; the continuation strategy is excluded in DACDH and it deals with the entire CN from the start of processing. On the other hand, the DACDHE method allows for premature convergence to save the unreasonable computational costs of the optimization. Extensive experiments were performed on the 11th real-world CNs to evaluate the performance of the proposed methods. Based on results obtained, we find that the proposed method demonstrated the best performance in comparison to other methods. Furthermore, we find that the integration of the continuation strategy into the PSO algorithm can be considered efficient and beneficial in improving both efficiency and performance of DAE-based community detection in CNs. We also find that enabling premature convergence improves efficiency gains, but compromises the performance. Our future work will focus on combining DAE model with other metaheuristic methods for community detection. Parallel computation should be investigated to further improve the model efficiency in future.
Footnotes
Acknowledgments
This work was supported by the Fundamental Research Grant Scheme (FRGS) from the Ministry of Higher Education and Multimedia University, Malaysia (Project ID: FRGS/1/2018/ICT02/ MMU/02/1).
https/github.com/zepx/graphencoder
yangliang.github.io/code/DC.zip
https/github.com/smartyfh/DANMF
https//github.com/dilberdilu/community-detection-DL