
Abstract
Based on the granular computing and three-way decisions theory, the sequential three-way decisions (S3WD) model implements the idea of progressive computing. However, almost S3WD models are established based on labeled information system, and there is still a lack of S3WD model for processing unlabeled information system (UIS). In this paper, to solve the issue of given accepted number for UIS, a data-driven sequential three-way decisions (DDS3WD) model is proposed. Firstly, from the perspective of similarity computed by TOPSIS, a general three-way decisions model for UIS based on decision risk is presented and its shortcomings are analyzed. Then, a concept of optimal density difference is defined to establish the DDS3WD model for UIS by updating attributes. Finally, the related experiments show that DDS3WD is feasible and effective for dealing with UIS under the condition of given accepted number of objects.
Keywords
Introduction
Based on both probabilistic rough sets [30, 31] and decision theory, the three-way decisions (3WD) model was proposed by Yao [32, 33] in the view of decision risk. A domain is divided into three disjoint regions (positive region, negative region and boundary region) by considering the minimum decision risk in 3WD model. The rules generated from the positive region represent the action of acceptance; the rules generated from the negative region represent the action of rejection; the rules generated from the boundary region represent the action of deferment. The theory of 3WD extends the semantics of probabilistic rough set and simulates the human thinking mode in solving problems [34]. In recent years, the 3WD model is studied by many scholars in various fields and many achievements have been achieved, such as decision making [12, 13], three-way decisions spaces [4, 8], cognitive concept learning [10, 22] social networks [7], classification [11, 37], clustering [25, 36] and recommendation [38].
As well know, the cognitive mechanism of “large-scale priority” [2] is utilized to solve complex problem by human, that is, a problem is gradually computed by employing coarse-to-fine information granularity, which is called progressive computation [23]. As a typical multi-step approach in granular computing (GrC) theory [1, 34], the sequential three-way decisions (S3WD) model [35] is introduced by Yao based on 3WD theory, which implements the human multi-granularity thinking to solve complex problems. In S3WD model, the problem can be processed in multi-granularity spaces by gradually switching the granularity layer from coarser to finer. In the view of multi-granularity rough sets (MGRS) [17, 18], with the granularity being finer, the information granules will gradually become smaller in S3WD model. Recently, a great deal of research works on S3WD were achieved [3, 41]. Yang [27] established a general framework of S3WD and further proposed a multilevel incremental mechanism for complex problem solving. Zhang [41] constructed the optimistic and pessimistic S3WD models with intuitionistic fuzzy number by considering both cost parameters and attribute values. By considering user requirements, Yang [26] developed an optimization mechanism to select granularity based on S3WD model with rough fuzzy sets. Hu [5, 20] pointed that the existing three-way decisions are the special examples of three-way decisions spaces and further established the multi-granulation three-way decisions space. In the aspect of application, Ju [9] proposed a novel sequential three-way classifier by considering the principle of justifiable granularity. Savchenko [21] presented an algorithm based on S3WD to address the issue of insufficient speed in image recognition when the number of classes is rather large. Zhang [39] introduced a S3WD model by extracting a multi-granularity feature set to balance misclassification cost and time cost in autoencoder. However, the threshold pairs of each granularity space in the almost S3WD models mentioned above are acquired by approximating a target concept of information system. That is, these models are established for processing labeled information system. However, to date, for unlabeled information systems (UIS), few existing models for making sequential three-way decisions are proposed in the research filed.
As shown in Fig. 1, in the process of selecting excellent employees from 10 employees, a company plans to use 2 opportunities to improve the ability of employees by training course. According to the final skill score from high to low, the top 5 employees need to be selected from 10 employees as the excellent employees. Herein, Skill1, Skill2 and Skill3 denote the scores of three skills of employees, and the blue, gray and green region denotes the accepted, deferred and rejected decisions in Fig. 1. In Fig. 1, each skill score would be updated 2 times according to each examination, and the classification results (the employees are divided into three pair-wise disjoint regions as accepted, deferred and rejected region) need to be obtained. In order to decrease the cost of examinations and training course, the company only further trains and tests the employees in deferred region, that is, the skill score of employees in accepted and rejected region will not be updated. Suppose the accepted employees are {x1, x2} → {x1, x2, x3} → {x1, x2, x3, x4, x5} with respect to each selection, finally, 5 excellent employees are selected. However, in the above process, how to obtain the threshold pairs to divide the universe into three regions and achieve the progressive selection until the top 5 are selected is still an issue. By considering dynamic decision making with updating attribute values, the aim of this paper is to establish a sequential three-way decisions model for UIS when the accepted number of objects is given. There are two assumptions in this paper as follows:(1) The higher (lower) attribute value of an object, the higher (lower) chance to be an excellent object;(2) The attribute value of an object is improved after each update. Obviously, the above assumptions are in accord with practical application.
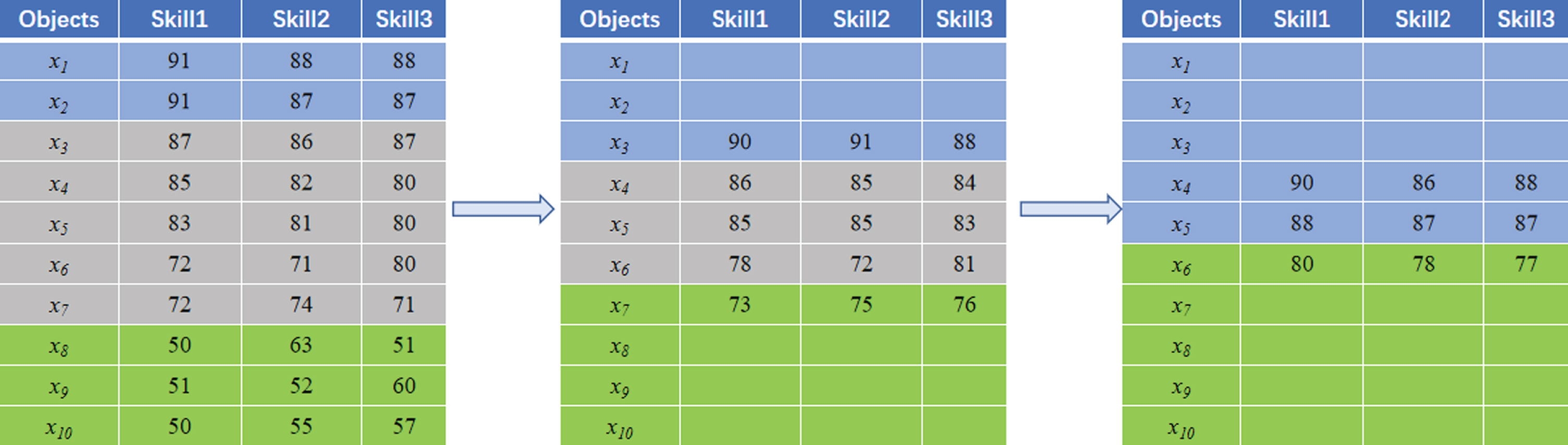
Progressive selection for excellent employees.
As well known, technique for order preference by similarity to an ideal solution (TOPSIS) [4] is one of the multi-attributes decision-making methods, which make use of original data to accurately evaluate objects in an information system. In this paper, to satisfy the above assumptions, the unlabeled information system is preprocessed by TOPSIS. Based on our previous works [26, 40], a data-driven sequential three-way decision model for UIS is proposed. The two main contributions of this paper are as follows: (1) From the perspective of similarity computed by TOPSIS, a general three-way decisions model based on decision risk for UIS is presented, which provide a new way for processing UIS by 3WD theory. (2) For solving the case of given accepted number of objects, based on the concept of optimal density difference, a data-driven sequential three-way decisions (DDS3WD) model for UIS is further proposed, which is adaptive to the updating attribute values.
The remainder of this paper is organized as follows. Related preliminary concepts are introduced in Section 2. In Section 3, a general three-way decisions model for UIS based on decision risk is presented. In Section 4, a concept of optimal density difference is defined and a data-driven sequential three-way decisions (DDS3WD) model for UIS by updating attribute is further proposed. In Section 5, related experiments are provided to verify the effectiveness of DD-S3WD model. Finally, conclusions are drawn in Section 6.
As well known, an information system with label data is also called a decision system. In this paper, we denote a decision system by IS = (U, A = C ∪ D, V, f), where U is a non-empty finite domain, V is the set of all attribute values, C is the set of condition attributes, D is the decision attribute and f : U × A → V is an information function. Similarly, we can define an unlabeled information system as follows,
Rough sets theory [14] is an effective mathematical tool for handling uncertain concept by using the given information granulation. For an uncertain concept, it can be described by a pair of lower and upper approximation sets.
If
Take the excellent employees selection for example, the objects in the positive region are all collections of “excellent” objects, and the objects in negative region are all collections of “inferior” objects, while the objects in boundary region are needed to further observation. Based on the definition of positive region, boundary region and negative in region Definition 3, we have the following definition,
If μ ([x]) ≥ α,decide [x] ∈ POS(α,β); If β ≤ μ ([x]) < α, decide [x] ∈ BND(α,β); If μ ([x]) < β, decide [x] ∈ NEG(α,β).
From Definition 4, when the threshold pair are determined, objects can then be divided into positive, boundary, or negative regions.
A general sequential three-way decisions model for UIS
According to the discussion in Section 1, there is still a lack of 3WD model for UIS under the condition of given accepted number. As well known, for labeled information system, in order to obtain α and β, the classical three-way decisions model [32, 33] is proposed based on the decisions-theoretic rough sets theory according to the minimum expected overall decision risk. 3WD model brings new insight into the problem of parameter setting for the probabilistic rough sets [30]. Similarly, based on the idea of 3WD model [32], a general three-way decisions mode for unlabeled information system is defined in this section. Firstly, TOPSIS [4] is adopted to preprocess the UIS and acquire the membership degree of objects in UIS. The details of TOPSIS is shown in Algorithm 1.
1:
2:
3:
4: X ij = M - f (x i , a j );
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19: Obtain U d = {x1, x2, …, x n } by sorting U0 according to s (x oi ) in descend order;
20:
In this paper, Algorithm 1 is used as data preprocess, which aim to achieve the score set of all objects and the final ranking by this score set. In essence, the score acquired by TOPSIS reflect the similarity between the object and the idealized object, which can be understood as the membership degree to the idealized target. Obviously, for an unlabeled information system, the larger the score of an object is, the more likely an object is to be ideal; inversely, the smaller the score of an object is, the less likely an object is to be ideal. In essence, the score of an object reflects the membership degree that belong to idealized target. Based on the decision risk in 3WD model proposed by Yao, from the perspective of the score, we proposed a three-way decisions model for UIS as follows,
Suppose the action set A = {a
P
, a
B
, a
N
} represents three kinds of actions which are acceptation, rejection and deferred decisions. λ
PP
, λ
BP
, λ
NP
denote the losses incurred for taking actions a
P
, a
B
, a
N
when an object belongs to the accepted objects, respectively. λ
PN
, λ
BN
, λ
NN
denote the losses incurred for taking these actions when an object does not belong to the accepted objects, respectively. Thus, the expected losses associated with taking different actions with object can be expressed as follows,
According to the Bayesian decision rule, the minimum-risk decision rules can be obtained as follows,
(P) If
(B) If
(N) If
Obviously, the above rules are only related to the loss functions and s (x). Furthermore, similar to the traditional 3WD model, 0 ≤ λ PP ≤ λ BP ≤ λ NP ≤ 1 and 0 ≤ λ NN ≤ λ BN ≤ λ PN ≤ 1 are two reasonable assumptions for constructing our 3WD model. The decision rules can be re-expressed as follows,
(P1)
(B1)
(N1)
Combining with the above rules (P1),(B1) and (N1), we can obtain the three parameters α, β, γ respectively,
For rule(P1)
From rule (B1), we have β < α; then
(P2) If s (x) ≥ α,decide x ∈ POS;
(B2) If β ≤ s (x) < α, decide x ∈ BND;
(N2) If s (x) < β, decide x ∈ NEG.
For simplify, suppose λ
PP
= λ
NN
= 0, that is, the correct classification cost is equal to 0, and we have
The decision cost DC(α,β) comes from three regions: positive region, boundary region and negative region. The semantic of DC (POS(α,β)) is the decision cost when we obtain (P2) rule. Similar semantic could be applied to DC (BND(α,β)) and DC (NEG(α,β)).
From Definition 6, for an unlabeled information system, the threshold pairs can be obtained from the perspective of similarity. Similar to the classical 3WD model [32], the decision risk is acquired in Definition 5 by computing the the score of objects, in an unlabeled information system. However, for the case of the given accepted number of objects, the acquired threshold pairs will not change with the different UIS as the threshold pairs depend on the loss parameters λ PP , λ BP , λ NP , λ PN , λ BN , λ NN , that is, the threshold pairs are not adaptive, which is not suitable to make sequential three-way decisions model for UIS. Therefore, to solve this problem, from the perspective of similarity, we proposed a novel three-way decision model for UIS based on data-driven in next section.
An information table of student performance
An information table of student performance
From Table 1, U0 = {xo1, xo2, …, x
on
}. According to Algorithm 1, we have the score set of Table 1 in descending order as follows,
When α = 0.8, β = 0.2, we have
When α = 0.6, β = 0.3, we have
From the above example, it exists some problems, for example, when α = 0.9, β = 0.1, the score of x7 and x8 is too low to be placed in boundary region, because their potential for improvement is very low. When α = 0.6, β = 0.3, the score of x3 is not suitable to be placed in positive region directly. Therefore, various decision regions can be obtained according to the different threshold pairs, which is not objective. Furthermore, for the issue of given accepted number, it is not suitable to make two-way decisions by selecting the top k.
According to the discussion in Section 3, the 3WD model for UIS based on decision risk is not suitable to handle the case of the given accepted number of objects. Moreover, the given threshold is not objective to some extent. To solve the above issues, we proposed a data-driven sequential three-way decisions (DDS3WD) model for UIS in this section. Firstly, a concept of expected density difference according to the mathematical characteristics of a numerical set is defined as follows:
According to Definition 6, Sn-1 possesses one less element s (x
n
) than S
n
. The expected density may be changed when an element s (x
n
) is added to Sn-1. Therefore, the expected density difference reflects the influence degree when an element s (x
n
) is added to Sn-1. That is, the following conclusions holds: Δ
n
> 0 denotes s (x
n
) has a positive effect; Δ
n
< 0 denotes s (x
n
) has a negative effect; Δ
n
= 0 denotes s (x
n
) has no effect.
Based on Algorithm 1, we proposed an algorithm for constructing the data-driven three-way decision model (DD3WD) for UIS, which is defined as follows:
1: Δ1 = Δ2 =∅,POS = BND = NEG =∅;
2: Obtain U d = {x1, x2, …, x n } and S = {s (x1) , s (x2) , …, s (x n )}; // According to Algorithm 1
3: Compute Δ i of x i (x i ∈ U d 1 , where U d 1 = {x1, x2, …, x k }) by formula (1), Δ1 = Δ1 ∪ {Δ i };
4:
5: α = s (x t 1 );
6: Compute Δ i of x i (x i ∈ U d 1 , where U d 2 = {xk+1, xk+2, …, x n }) by formula (1),Δ2 = Δ2 ∪ {Δ i };
7:
8: α = s (x t 2 )
9:
10: If s (x i ) ≥ α,POS = POS ∪ {x i };
11: If α > s (x i ) ≥ β,BND = BND ∪ {x i };
12: If s (x i ) < β,NEG = NEG ∪ {x i }.
13:
14: Return POS, BND, NEG.
In Algorithm 2, U d = {x1, x2, …, x n } and S = {s (x1) , s (x2) , …, s (x n )} are the output of Algorithm 1. Figure 2 describes the algorithm intuitively. s (x k ) is considered as the classification point of U. Obviously, this classification point ensures that the number of objects in the accepted region is less than k, that is α ≥ s (x k ) ≥ β.

Data-driven three-way decisions model.
(continued)
According to k = 4, the object set S8 = {s (x1) , s (x2) , ⋯ , s (x8)} is divided into two subsets {s (x1) , s (x2) ,
s (x3) , s (x4)} and {s (x5) , s (x6) , s (x7) , s (x8)}.
The expected density and expected density difference of each object in Table 1 obtained using Algorithm 2 is shown in Table 2.
Result of Table 1 by Algorithm 2
Therefore, α = 0.877, β = 0.286. Then, we have
As well known, almost the three-way decisions will eventually degenerate to two-way decisions in real applications. Therefore, it is necessary to further establish the sequential three-way decisions model to classify the objects in boundary region constantly until the number in the positive region is equal to the given accepted number k. With respect to a series of unlabeled information system UIS i = (U i , C, V i , f i ) with a pair of threshold α i , β i (0 ≤ β i ≤ α i ≤ 1), i = 1, 2, …, M, a sequential three-way decisions can be established based on Algorithm 2. Therefore, based on Algorithm 2, we proposed an algorithm for constructing the data-driven sequential three-way decisions model (DDS3WD) for UIS by considering dynamic decision making with updating attribute values.
In Algorithm 3, UIS i denotes the ith update unlabeled information system. According to Algorithm 3, the thresholds α and β need to be recalculated with the update of the scores. Figure 3 describes the algorithm intuitively. Obviously, BND1 ≥ BND2 ≥ ⋯ ≥ BND M holds.
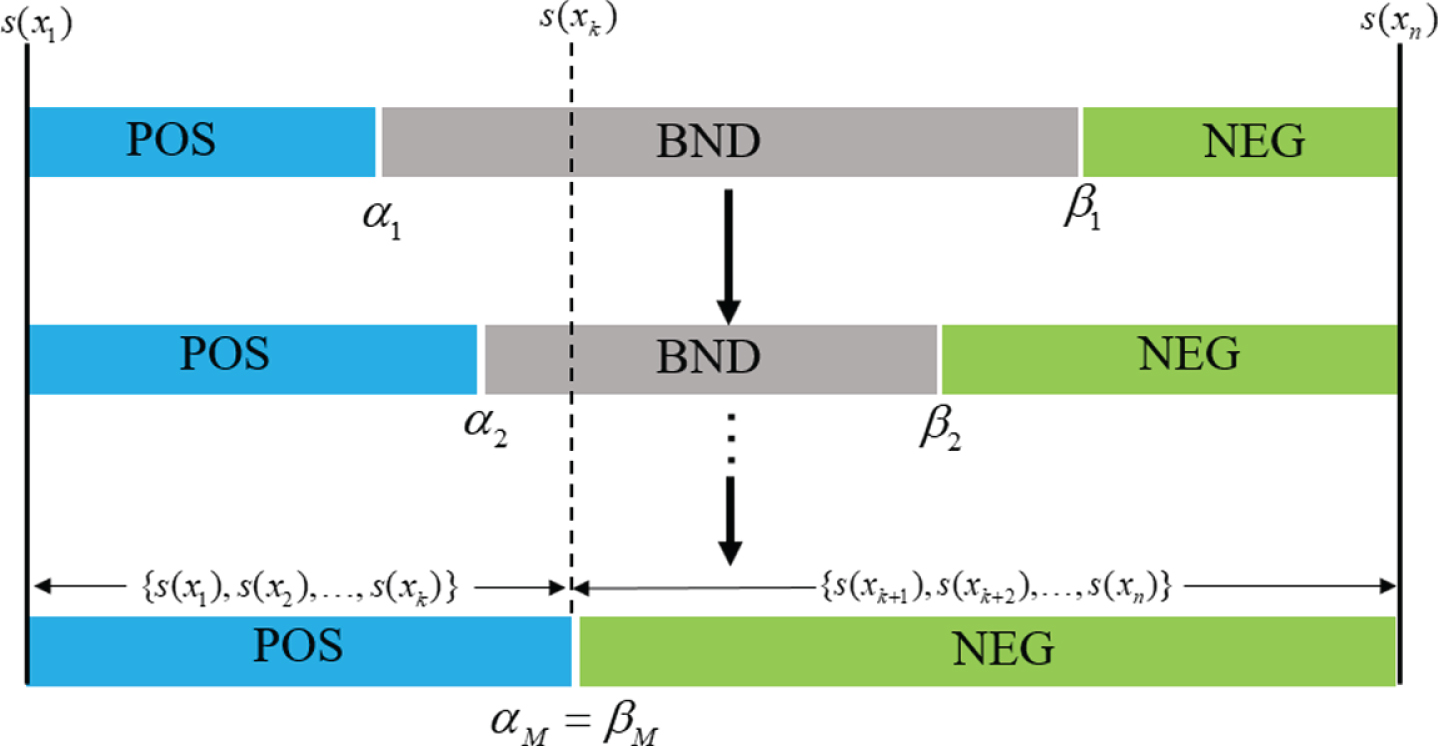
Data-driven sequential three-way decisions model.
1: UIS _ temp ← UIS0 = (U0, C, V0, f0) and POS0← ∅;
2: i = 1;
3:
4: Obtain POS i ,BND i ,NEG i by Algorithm 2 // Take UIS _ temp as the input of Algorithm 2;
5: POS seq = POS seq ∪ {POS i },BND seq = BND seq ∪ {BND i } and NEG seq = NEG seq ∪ {NEG i };
6: k = k - |POS seq |, U i = BND i ;
7: UIS _ temp ← UIS i = (U i , C, V i , f i );// UIS i denotes the ith update information system
8: i++.
9:
10: Return POS seq , BND seq , NEG seq .
In Section 4, we have discussed the data-driven sequential three-way decisions (DDS3WD) model for UIS by updating attributes from the perspective of similarity. In this section, related experiments are carried out to verify the effectiveness of DDS3WD. The experimental environments are Windows 7, Intel Core (TM) I5-4590 CPU (3.30 GHz) and 8GB RAM. The experimental platform is Matlab 2015b. Nine regression datasets from UCI [5] are listed in Table 3. The label of each dataset is used as the real score, and the final result of selection is ranked by descending order. Firstly, the three evaluation functions: Recall, UCR and UM are defined as follows:
The descriptions of datasets
In formula (2),
For the total update times T of each dataset, suppose that the ratio of update times is
In formula (3), UCR reflects the total update cost to some extent.
In formula (4), UM denotes the uncertainty measure of each granularity layer.
In our experiments, for simplicity, we focus on comparing the three methods based on three models (two-way decisions model, DDS3WD and DDS3WD with updating all attribute values) are denoted by Method1, Method2 and Method3, respectively. As shown in Fig. 4, we compute the changing trend of Recall of three methods with the changing

The Recall with the changing
Figure 5 shows the changing trend of UCR of Method2 with the different γ and τ. Obviously, the update time increases with the increasing k in the case of the total number n unchanged, therefore, the UCR of Method2 will be decrease with the increasing γ.

The UCR versus with the changing
Figure 6 shows the UM versus with the changing

The UM versus with the changing
Based on the granular computing and three-way decisions theory, the sequential three-way decisions (S3WD) model implements the idea of progressive computing. In essence, S3WD solves problems by gradually switching the granularity layer from coarser to finer, which means that the same problem can be processed in a hierarchical granular structure. However, almost S3WD models are established based on labeled information system, and there is still a lack of S3WD model for processing unlabeled information system (UIS). To solve the issue of given accepted number for UIS, a concept of optimal density difference is defined to establish the data-driven sequential three-way decisions (DDS3WD) model for UIS by updating attributes in this paper. Three evaluation functions are designed to verify that DDS3WD is feasible and effective for dealing with UIS under the condition of given accepted number of objects. In the next step, we will further study sequential three branch decision-making from the perspective of granularity optimization and attribute reduction.In the next step, we will further study sequential three branch decision-making from the perspective of granularity optimization and attribute reduction.
Footnotes
Acknowledgment
This work is supported by the National Science Foundation of China (No. 62066049), Innovation and exploration project of Guizhou Province (QKHPTRC [2017] 572706), Open fund of Chongqing Key Laboratory of Computational Intelligence (2020FF05), PHD Training Program of Chongqing University of Posts and Telecommunication (No. BYJS201902).