
Abstract
Formation of Gurmukhi character/akshara from the recognized strokes in online handwriting recognition systems is a challenging task. In this paper, the task of character and akshara formation in an unconstrained environment have been addressed. After the recognition of online handwritten strokes the Gurmukhi akshara is formed using a hybrid approach. Two classifiers, namely, Support Vector Machine (SVM) and Recurrent Neural Network (RNN) have been experimented in this study. The classifier, yielded the maximum cross-validation accuracy has been utilized for stroke recognition. A total of 52,500 word samples have been collected from 175 writers in order to train the classifiers. Three post processing algorithms have been proposed in this article for improving the character and akshara recognition accuracy. The proposed methodology when tested on a dataset of 21,500 aksharas, written by 50 new writers, achieved average the accuracy rate of 97.1% and 87.1% for base character and akshara recognition, respectively.
Introduction
Online handwritten character recognition is an emerging area of pattern recognition. Nowadays, online handwritten character recognition assumes a key role in several human-machine interfaces including cell phones, smart pads, digital tablets and computers [5]. It is a highly involved problem because of its complexity, similar shape of characters and variations in handwriting styles. Due to rapid revolution in Information Technology related products, including, touch screen mobiles, digital-tablets, note-pads etc., the demand of online handwritten character recognition based applications is increasing day by day. These products help us in capturing information with the help of digital pen/stylus. The captured information is stored in the form of x, y co-ordinate values with progressive time. The sequence of such co-ordinates, captured between digital pen-down and pen-up event is referred as a stroke in an online handwritten recognition system [10]. Further, a character or akshara can be constructed using a single or multiple strokes.
Gurmukhi script
Gurmukhi is the script used for writing Punjabi language. Punjabi is an Indo-Aryan language spoken by 102 million speakers worldwide. It is 10th most widely spoken language in the world. In 16th century, Shri Guru Angad Dev Ji, second Sikh Guru, standardized Gurmukhi Script. The name of Gurmukhi is derived from the old Punjabi term “Guramukhi”, which means “from the mouth of Guru”. Following are some of the basic characteristics of Gurmukhi script.
The writing structure of Gurmukhi script is cursive and it is written from left to right direction. Fig. 1 illustrates various characters of Gurmukhi script. It has a basic set of 53 characters: 41 Consonants, 9 vowels and 3 nasal symbols. Out of the 9 vowels, 4 vowels (i.e., ,
,  ,
,  and
and  ), are considered as upper matras, appear above the Consonant; 2 vowels (i.e.,
), are considered as upper matras, appear above the Consonant; 2 vowels (i.e., and
and  ), considered as lower matras, appear below () the Consonants and 3 vowels (i.e.,
), considered as lower matras, appear below () the Consonants and 3 vowels (i.e., ,
,  and
and  ) appear adjacent to a consonant. The nasal symbols (i.e.,
) appear adjacent to a consonant. The nasal symbols (i.e.,  ,
,  , and
, and ) are also considered as upper matras and these also reside above Consonants [2].
) are also considered as upper matras and these also reside above Consonants [2].
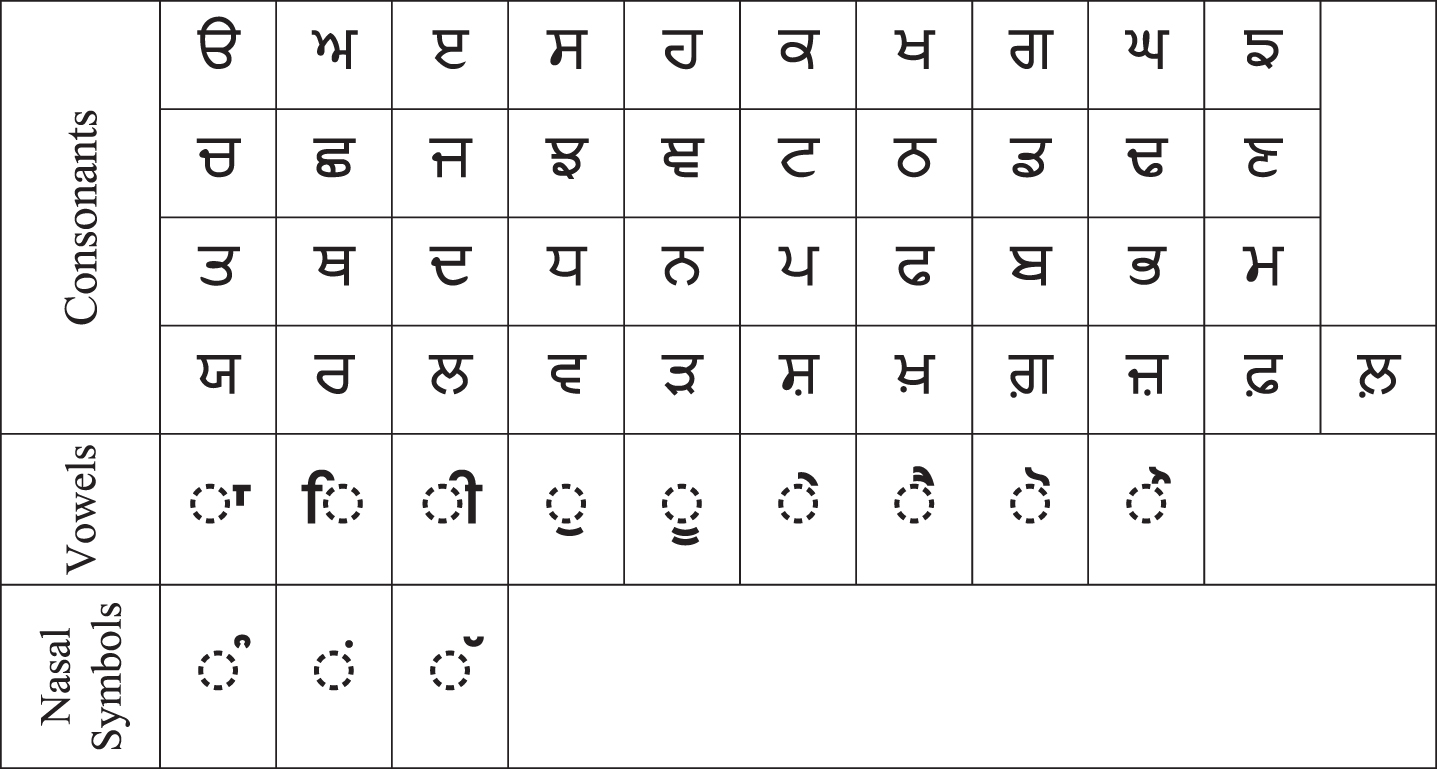
Gurmukhi character set.
In the present work, 35 basic consonants have been considered as Gurmukhi characters. A consonant written with one, two, or three vowel(s) is considered as akshara. Also, the modified consonants; consonant with  (bindi),
(bindi),  (tippi), and
(tippi), and  (adhak); This is worth mentioning here that 35 basic consonants, 6 modified consonants, 9 vowel modifiers, and 3 nasal symbols have been included in the Unicode character set of Gurmukhi script. As such, an akshara is constructed by combining 2 or more Unicodes, there should be one character Unicode in this combination.
(adhak); This is worth mentioning here that 35 basic consonants, 6 modified consonants, 9 vowel modifiers, and 3 nasal symbols have been included in the Unicode character set of Gurmukhi script. As such, an akshara is constructed by combining 2 or more Unicodes, there should be one character Unicode in this combination.
In this paper, Initially, the input strokes are processed for zone identification and pre-processing operations. After this, the identified strokes are recognized in their respective zones (i.e., Upper Zone and Lower Zone) using the trained classifier. Thereafter, the character/ akshara formation mechanism is applied on the recognized strokes in order to form a valid Gurmukhi character/ akshara. This mechanism initially transforms the set of recognized strokes into Gurmukhi characters and then these characters are processed in such a way to form a Gurmukhi akshara.
This paper is organized as follows. Section 2 describes the related work. The various challenges for online handwritten Gurmukhi script have been discussed in Section 3. In Section 4, the overall online handwritten Gurmukhi Akshara recognition system has been illustrated. Section 5, describes the data collection and annotation. The discussion about pre-processing and feature extraction for online handwriting recognition has been done in Section 6. The classification models utilized in the present study have been described in Section 7. The post-processing algorithms have been discussed in Section 8. Experimental results have been illustrated in Section 9 and finally, Section 10 addresses the paper conclusion.
Tappert et al. [18] have described the state of art in online handwritten character and word recognition systems. Shape recognition algorithms, pre-processing techniques and post-processing techniques have extensively been surveyed in this paper. Pal and Chaudhuri [9] presented a survey on character recognition of Indian scripts. The properties of Indian scripts and methodologies used for recognition of these scripts have been described in their paper. They have discussed the character recognition systems for Devanagari, Bangla, Tamil, Gurmukhi, Gujrati, Kashmiri, Malayalam, Oriya, Telugu, Urdu and Kannada scripts. Sharma et al. [13] have implemented an online handwritten Gurmukhi character recognition system using elastic matching technique. They have discussed the process of recognition of strokes and formation of characters from the recognized strokes. In their work, they have also discussed the ways of storing the data for handwritten strokes and characters, and obtained a recognition accuracy of 90.08%. Parui et al. [10] have proposed an online handwritten Bangla character recognition system using Hidden Markov Model (HMM). A dataset of 24,500 online handwritten isolated character samples has been collected in their work. A HMM classifier has been used for recognition of strokes. They achieved a testing accuracy of 84.60%. Sharma et al. [14] proposed rearrangement of predicted strokes in online handwritten Gurmukhi words recognition. In this work, they have classified the input strokes as dependent and major dependent strokes. They have tested their system on a set of 2,576 online cursive handwritten Gurmukhi words, and achieved an overallrecognition accuracy of 81.02%. Arora and Namboodiri [1] have reported a hybrid model for recognition of online handwritten characters for Indian languages. Ambiguities in segmentation and prediction of the strokes have been handled by their system. They have reported an accuracy of 78.00% on a corpus of 60,495 words of two native languages: Malayalam and Telugu, written by 367 writers. Rampalli and Ramakrishnan [11] have proposed an online handwritten character recognition system working in blend with an offline recognition system for Kannada. In their work, online input strokes are converted into an offline image and concurrently recognized by both online and offline strategies. They have reported an improvement of 11.00% in accuracy by combining the online recognition system with an offline one. Belhe et al. [3] have proposed HMM and symbol tree based online handwritten isolated Hindi words recognition system. They convert the online stroke information into an offline image during pre-processing phase. These offline images are further processed for feature extraction. Histogram of Oriented Gradients (HOG) feature vector is extracted for each image. They have reported an accuracy of 89.00% in this work. Gao et al. [4] presented an online handwritten Japanese text recognition system. Their system includes an offline character recognizer and other components for linguistic and geometric contexts. A linear Markov Random Field (MRF) chain model has been used in their work. They have reported an accuracy varying from 91.10% to 95.74% by combined recognizer. However, in the recent literature, deep neural network based approaches have received the much attention over the traditional statistical and structural feature based classifiers [22–24]. Moreover, in [25], the authors explore the various pre-processing and post-processing techniques, feature extraction techniques, and character recognition techniques in detail for indic and non-indic scripts.
A good amount of research work on online handwritten character and word recognition for Gurmukhi script has been carried out by many researchers in recent past [6, 21]. In the present study, unconstrained overlapped handwritten Gurmukhi Aksharas have been considered for their recognition.
Challenges and motivation
In this work, an attempt to recognize the online unconstrained handwritten Gurmukhi aksharas has been addressed. The word formation strategy proposed by Arora and Namboodiri [1] has been explored to form the Gurmukhi Aksharas. As illustrated in Fig. 2, the lowest hierarchy is a handwritten stroke (S i ), the character (C i ) is formed using one or more strokes, representing a valid Unicode. These Unicode characters are further combined to form a valid Akshara, which are further used to form a word. Fig. 4 illustrates the representation of a Gurmukhi akshara in two zones. The region above the virtual-line denotes Upper Zone, where upper matras reside, while the area below the virtual-line represents Lower Zone, where all the Consonants and lower matras reside.

Handwritten word formation hierarchy.
The main challenge in online handwriting Gurmukhi script is to build a system that is able to distinguish between variation in writing the same stroke/character by different writers or same writer at different time, as illustrated in Fig. 3. In addition to this, following are some other challenges that have been faced during the development of online handwriting recognition system for Gurmukhi scripts.

Variations in writing Gurmukhi akshara ‘’; 3(a): the akshara ‘ ’ written in a single stroke, 3(b): written in two strokes, 3(c): written in two strokes but with different shapes, 3(d): written in three strokes and with different shapes, 3(e): written in two strokes and again with different shapes.
’ written in a single stroke, 3(b): written in two strokes, 3(c): written in two strokes but with different shapes, 3(d): written in three strokes and with different shapes, 3(e): written in two strokes and again with different shapes.
Recognition of some confusing characters/aksharas in the Gurmukhi script, such as Writing the Gurmukhi characters/aksharas in different sizes, create the confusion in recognition. Some writers use the same set of stroke to write a character but may write the strokes in different order. Therefore, writing the character with different order of strokes makes the character recognition difficult. Formation of same akshara by multiple combination of different strokes turns out to be very challenging. Most of the Gurmukhi characters include a horizontal-line at its upper part. In a Gurmukhi word, characters are connected with the help of this horizontal-line. However, this horizontal-line is not the part of Gurmukhi character-set but still it’s present is necessary for some characters and akshara formation
Keeping in mind these challenges, the post-processing algorithms have been proposed to over-come the difficulties as discussed above. with
with  ,
,  with
with  etc.
etc.
Fig. 5 contains the flow chart of online handwritten Gurmukhi Akshara recognition system proposed in this work. Strokes are the basic building blocks in all the online handwriting recognition systems. A stroke is represented as sequences of x, y-coordinate points, captured in the real-time environment. We considered the identified strokes as class-label in the present study. The online handwritten strokes are initially processed through pre-processing phase. In the first step of pre-processing phase, zone of each stroke is identified using zone identification algorithm leading to two disjoint sets of strokes: set of strokes in Upper Zone and set of strokes in Lower Zone [20]. These strokes are then processed for removing duplicate points, size normalization, interpolation, and re-sampling to a uniform set of points. After applying the pre-processing operations on the input strokes, the re-sampled strokes are sent to respective classifiers (i.e.,UpperClassifier and LowerClassifier) for recognition. These recognized strokes are then processed further for Unicode character and akshara formation.

Representation of online handwritten Gurmukhi akshara in two zones.

Flow chart of handwritten Gurmukhi Aksharas recognition system.
Data collection is a first step in the character/ akshara handwriting recognition system. For data collection, it is important to identify the set of words, for that handwritten samples would have been collected. Here, we have considered a set of 300 Gurmukhi words for handwriting data collection. Data has been collected from varied classes of writers. A total number of 175 writers, belonging to different age groups, contributed in this data collection process. Touch based device, Tablet-PC (Dell latitude XT-3) has been used for capturing the handwritten samples. After data collection, the collected handwritten data is annotated at stroke level by labeling each stroke with it’s respective strokeID [20]. A total of 336,810 strokes have been annotated in this task.
Pre-processing and feature extraction
The collected handwritten samples are processed through several pre processing steps, namely, size normalization (captured strokes are normalized to 300×300 size window), duplicate points removal, interpolation, and re-sampling of x, y-points. The strokes are re-sampled to a fixed size of 64 points (x, y-coordinates), giving a feature vector of size 128. The recognition performance of an online handwriting recognizer is completely dependent on the trained model. Therefore, a model should be trained using the more suitable feature. In the present work, we have considered pre-processed 64 points (x, y-coordinates) as feature.
Classification models
The extracted 64 points points from a stroke are further used to train the classifier. We have experimented two different classifiers for stroke classification, as described below:
Support Vector Machine (SVM) classifier
The SVM classifier takes the arrangement of features according to its standard input file format. SVM classifier is trained using the feature file, which contains an average of 145-170 samples per stroke class. This process generates a model file, which is further used to classify the test data at stroke level. In general, the SVM classifier has four different types of kernels, namely, Linear, Polynomial, RBF and Sigmoid. It has been experienced that effectiveness of the classifier depends on the kernel used, kernel parameters and soft margin or penalty parameter C. After experimentations, we decided to train the classifier using RBF Kernel. The parameters Cand γ have considerably been varied in order to increase cross-validation accuracy.
RNN classifier
The fundamental feature of a Recurrent Neural Network (RNN) is that the network contains at least one feed-back connection, so the activations can flow round in a loop. This enables the networks to do temporal processing and learn sequences. The RNN is particularly useful for data sequences because each neuron unit uses an internal memory in order to keep information about the previously entered data [8]. The same feature file (i.e., 64 points) has been used to train the RNN classifier.
Post-processing
In the post-processing approach, the misclassified results can be corrected by integrating the linguistic knowledge. Here, all the possible outcomes are studied corresponding to each Gurmukhi character. Usage of language information can improve the accuracy obtained in classification phase. Post-processing plays a crucial role in order to improve the accuracy of recognition system.
After recognizing the pre-processed strokes in their respective zones, the recognized strokes are sent further for character and akshara formation along with their information i.e., (i) StrokeID, (ii) Stroke Sequence Number, and (iii) Stroke Bounding Box Information ((Xmin, Ymin), (Xmax, Ymin), (Xmin, Ymax), (Xmax, Ymax)). However, a character is recognized only on the basis of correct recognition of stroke if it is written using single stroke. But, if a character is written using more than one stroke then to form a valid character from the recognized strokes, post processing is required.
To form a Gurmukhi character/ akshara, the recognized strokes are processed through various operations such as (i) stroke merging, (ii) extraction of lower matras, (iii) akshara list re-ordering, (iv) character/ akshara formation using Rule based file, as illustrated in Fig. 6. In the present study, we have focused on stroke merging operation, which further performed two sub-operation, i.e., vertical-line (‘ |’) and horizontal-line (‘___’) association. The motivation to apply these stroke merging operations has been generated from collected handwritten data verification. While manually verifying the handwritten stroke samples, we observed that two strokes (vertical-line and horizontal-line) are most frequently used to form a character. While writing, these strokes are used at different position/ region with different character. Here, we analyzed the different region based association of vertical-line and horizontal-line strokes with various characters and perform the transformations according to their association.

Flow chart of Gurmukhi character and akshara formation.
While analyzing the handwritten character samples, we found five different regions/ positions of the vertical-line stroke in the character. The Gurmukhi characters, that has association of stroke vertical-line are:  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  , and
, and  . Further, we identify the group of characters, where the position of vertical-line stroke is in the same region. In this way, region-wise different algorithms have been developed for grouping the strokes by associating with a character.
. Further, we identify the group of characters, where the position of vertical-line stroke is in the same region. In this way, region-wise different algorithms have been developed for grouping the strokes by associating with a character.
Fig. 7 illustrating the association of vertical-line strokes for Gurmukhi consonants  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  , and
, and  . While writing these consonants, if a writer use vertical-line stroke explicitly then the region for detecting the vertical-line stroke is projected at extremely right side of the bounding box of partially written stroke as depicted in the figure. These consonants are usually written with one or two strokes along with a vertical-line stroke. This task of associating the vertical-line stroke with the pre-written stroke (partially written stroke) is achieved by the Algorithm 1.
. While writing these consonants, if a writer use vertical-line stroke explicitly then the region for detecting the vertical-line stroke is projected at extremely right side of the bounding box of partially written stroke as depicted in the figure. These consonants are usually written with one or two strokes along with a vertical-line stroke. This task of associating the vertical-line stroke with the pre-written stroke (partially written stroke) is achieved by the Algorithm 1.

Examples of vertical-line association with Gurmukhi Consonants ,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  , and
, and  . (Different color indicates different strokes).
. (Different color indicates different strokes).
struct predictedStrokeList
{ int pos;
int value;
predictedStrokeList *next;
};
1: classLabels []← {145,167,217,151,161,174,202,207}
2: curretStrokeXmin ←
3:
4:
5: baseStrokePos←
6: baseStrokeXmin←
7: baseStrokeXmax←
8: baseXDiff ← baseStrokeXmax - baseStrokeXmin
9: baseXSliceMin ← baseStrokeXmin + (baseXDiff × 0.75)
10: baseXSliceMax ← baseStrokeXmax + (baseXDiff × 0.10)
11: break
12:
13:
14:
15:
16:
17: associate currentStroke with baseStroke
18:
The two Gurmukhi characters  and
and  , as depicted in Fig.8(a) are also written using the vertical line stroke. These two characters use the same shapes of strokes, but the length of the vertical-line stroke varies in both the characters. Thus, in this case, the length of stroke is the key factor to classify these two characters. If the length of the vertical-line stroke is greater than a threshold value (i.e., 75% of the length on y-axis of the reference consonant ‘
, as depicted in Fig.8(a) are also written using the vertical line stroke. These two characters use the same shapes of strokes, but the length of the vertical-line stroke varies in both the characters. Thus, in this case, the length of stroke is the key factor to classify these two characters. If the length of the vertical-line stroke is greater than a threshold value (i.e., 75% of the length on y-axis of the reference consonant ‘  ’), then a single Unicode character, ‘
’), then a single Unicode character, ‘  ’ is formed, as shown in Fig. 8(b); otherwise two separate Unicode characters consonant ‘
’ is formed, as shown in Fig. 8(b); otherwise two separate Unicode characters consonant ‘  ’ and vowel ‘
’ and vowel ‘  ’ are formed and when these two Unicode characters are rendered in a sequence, the character ‘
’ are formed and when these two Unicode characters are rendered in a sequence, the character ‘  ’ is formed, as demonstrated in Fig 8(c). The implementation of this process is illustrated in Algorithm 1_b. Moreover, this vertical-line stroke also used as the vowel kanna ’
’ is formed, as demonstrated in Fig 8(c). The implementation of this process is illustrated in Algorithm 1_b. Moreover, this vertical-line stroke also used as the vowel kanna ’ ’, usually written after the consonant (e.g.,
’, usually written after the consonant (e.g.,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  etc). Here also this vertical-line stroke is associated with the pre-written consonant on the basis of it’s length and position.
etc). Here also this vertical-line stroke is associated with the pre-written consonant on the basis of it’s length and position.

Decision of vertical line in formation of two different Gurmukhi characters, and  : (a) length of the vertical-line stroke is greater than the threshold, (b) length of the vertical-line stroke is less than the threshold (Different color indicates different strokes).
: (a) length of the vertical-line stroke is greater than the threshold, (b) length of the vertical-line stroke is less than the threshold (Different color indicates different strokes).
Similarly, the vertical-line can also appear above the bounding box of the partially written consonant’s stroke as shown in Fig. 9. Gurmukhi character involved in this case are:  and
and  . Apart from this, there are two more cases where the vertical-line stroke is appeared within the bounding box of partially written consonant. In first case, it is appeared at upper-left corner of this bounding box of the partially written consonant, as illustrated in Fig. 10 and Gurmukhi characters involved in this case are:
. Apart from this, there are two more cases where the vertical-line stroke is appeared within the bounding box of partially written consonant. In first case, it is appeared at upper-left corner of this bounding box of the partially written consonant, as illustrated in Fig. 10 and Gurmukhi characters involved in this case are:  and
and  ). In second case, the vertical-line appeared at lower right corner of the bounding box of the Gurmukhi consonants
). In second case, the vertical-line appeared at lower right corner of the bounding box of the Gurmukhi consonants  and
and  , represented in Fig.11. The position of the vertical-line stroke is detected in the specified regions (highlighted with red color box, in Fig. 9 and with green color in Fig. 10 and Fig. 11) only.
, represented in Fig.11. The position of the vertical-line stroke is detected in the specified regions (highlighted with red color box, in Fig. 9 and with green color in Fig. 10 and Fig. 11) only.

Examples of vertical-line association with Gurmukhi Consonants and  . (Different color indicates different stroke).
. (Different color indicates different stroke).

Examples of vertical-line association with Gurmukhi Consonants and  . (Different color indicates differentstroke)
. (Different color indicates differentstroke)

Examples of vertical-line association with Gurmukhi Consonants and  . (Different color indicates different stroke).
. (Different color indicates different stroke).
Horizontal-line also plays an important role in the recognition of Gurmukhi character and akshara. The Gurmukhi characters involved in the association of horizontal-line stroke are:  ,
,  ,
,  , and
, and  . The decision of associating the horizontal-line stroke with the partially written consonant is done on the basis of its position on x-axis and y-axis as shown in Fig. 12. The consonants
. The decision of associating the horizontal-line stroke with the partially written consonant is done on the basis of its position on x-axis and y-axis as shown in Fig. 12. The consonants  ,
,  , and
, and  are formed, when the horizontal-line stroke is written at upper center (on x-axis) part of the bounding box of the consonants
are formed, when the horizontal-line stroke is written at upper center (on x-axis) part of the bounding box of the consonants  ,
,  , and
, and  respectively, as illustrated in Fig. 12. Moreover, the consonants
respectively, as illustrated in Fig. 12. Moreover, the consonants  and
and  are formed when horizontal-line is written at middle center (on y-axis) of the bounding box of the consonants
are formed when horizontal-line is written at middle center (on y-axis) of the bounding box of the consonants  and
and  , respectively. The association of the horizontal-line stroke for the formation of these consonant is performed by the Algorithm 3.
, respectively. The association of the horizontal-line stroke for the formation of these consonant is performed by the Algorithm 3.

Association of horizontal-line with Gurmukhi consonants ,  ,
,  , and
, and  .
.
1: classLabels []← {164,165,155,156}
2: curretStrokeXmin ←
3:
4:
5: baseStrokePos←
6: baseStrokeXmin←
7: baseStrokeXmax←
8: baseXDiff ← baseStrokeXmax - baseStrokeXmin
9: baseStrokeXlimit ← baseStrokeXmin + (2.5 × baseXDiff)
10: baseYDiff←
11: currentYDiff←
12:
13: Not merged
14:
15:
16: Not merged
17:
18: Merged
19:
20:
21: break
22:
23:
In the stroke merging operation, only vertical-line and horizontal-line strokes are taken care for association with character’s stroke. The next operation (lower matras extraction) checks if any lower matra stroke is present in the list of strokes. Decision of extracting the lower matra stroke is taken on the basis of it’s position on x, y-axis. In this operation, the lower matra stroke(s) are stored in a new list with its stroke rendering (stroke sequence number) information. After completing this operation, we have three lists (i.e. list of upper matra strokes, list of consonant’s strokes, and list of lower matra strokes) for the formation of Gurmukhi character and akshara. In the akshara list re-ordering operation, these lists are re-arranged in such a to form a valid Gurmukhi character/akshara. Thereafter, these lists are processed individually to the Rule Base file for the formation of a valid Gurmukhi character or matra [6]. Eventually, Gurmukhi character/ akshara is formed after processing all these three lists.
1: classLabels []← {146, 151, 152, 157, 158, 159, 160, 161, 206, 217}
2: curretStrokeXmin ←
3:
4:
5: baseStrokePos←
6: baseStrokeXmin←
7: baseStrokeXmax←
8: baseXDiff ← baseStrokeXmax - baseStrokeXmin
9: baseStrokeXlimit ← baseStrokeXmin + (2.5 × baseXDiff)
10: baseYDiff←
11: currentYDiff←
12:
13: Not merged
14:
15:
16: Not merged
17:
18: Merged
19:
20:
21: break
22:
23:
The proposed post processing algorithms, which are discussed deeply in Section 8 have been implemented in Visual Studio C Sharp programming tool and tested with 21,500 online handwritten aksharas samples, written by 50 new writers. Each individual writer was asked to write a list of 430 Gurmukhi akshara. We considered strokeID as the class-label. In this study we found a total of 93 distinct shape of strokes as class-label (12 for Upper zone and 81 for Lower zone) for the recognition of online handwritten Gurmukhi characters. Table 1 illustrates the k-fold cross-validation accuracies obtained by using two different classification techniques (i.e., Support Vector Machine (SVM) classifier and Recurrent Neural Network (RNN) classifier) on different values of k, where the value of k varies from 3 to 9. The results of training accuracy of both the models show that the RNN classifier yields the highest cross-validation accuracy of 99.97% and 98.77% for Upper Zone and Lower Zone, respectively with k = 5 folds. Hence, the RNN model, trained using maximum cross-validation accuracy has been used for stroke recognition.
Values of parameters and stroke level accuracy achieved for two zones
Values of parameters and stroke level accuracy achieved for two zones
However, the performance of post-processing phase is influenced by strokes recognition and efficiency of stroke classifier is highly dependent on zone identification of captured strokes. A total of 73,010 strokes have been collected against 21,500 aksharas. Out of which, zone of 72,857 (i.e., 99.75%) strokes have been identified correctly. The evaluation of zone identification is carried out through manual verification of each strokes. Moreover, the average accuracy rate of 94.0%, 97.1% and 87.2% have been achieved for stroke, base character (without matras) and akshara recognition, respectively. The level-wise recognition performance is depicted in Fig. 13.
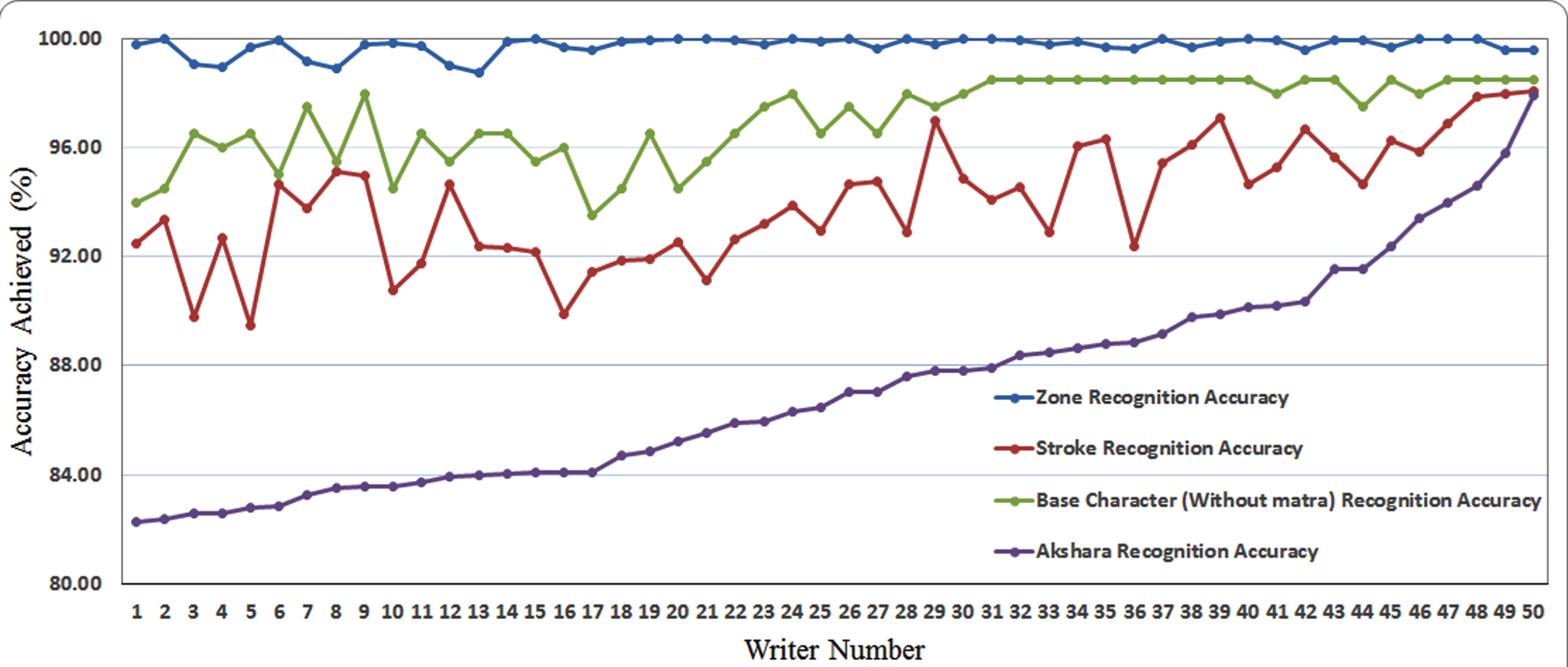
Zone-, stroke-, base character- and akshara-level recognition accuracy for 50 writers (writers are sorted by akshara recognition accuracy).
The overall Gurmukhi character recognition accuracy has been improved after integrating the proposed post-processing algorithms in the online handwritten Gurmukhi character recognition system. Table 2 illustrates the performance comparison of the proposed algorithms with existing state-of-the-art.
Performance comparison with existing state-of-the-art for online handwritten Gurmukhi character recognition.
Performance comparison with existing state-of-the-art for online handwritten Gurmukhi character recognition.
In the online handwriting recognition systems, the post processing is a necessary operation in order to improve the recognition accuracy of the recognizer. This paper presents three post processing algorithms for character and akshara formation. The major motivation to implement these algorithms is: frequently usage of vertical-line stroke and horizontal-line stroke, while writing a Gurmukhi character/akshara in an online handwriting environment. By utilizing these post processing algorithms, these strokes (vertical-line and horizontal-line strokes) are associated or grouped in to a strokes list of unicode character according to their position on the x and y-axis. To evaluation the performance of the proposed algorithms, a handwritten dataset of 21,500 akshara samples, written by 50 new writers is used. Two classification models, namely, SVM and RNN were trained to recognize the strokes. Eventually, the accuracy of 97.1% achieved for base character (without lower/upper matras) recognition and an accuracy rate of 87.2% achieved for akshara formation. Our future attempts will be towards enhancing the recognition performance at akshara- and word-level by incorporating the language model at post processing and development of an android based online handwriting recognition system.