
Abstract
This paper proposes a Hilbert stereo reconstruction algorithm based on depth feature and stereo matching to solve the problem of occlusive region matching errors, namely, the Hilbert stereo network. The traditional stereo network pays more attention to disparity itself, leading to the inaccuracy of disparity estimation. Our design network studies the effective disparity matching and refinement through reconstruction representation of Hilbert’s disparity coefficient. Since the Hilbert coefficient is not affected by the occlusion and texture in the image, stereo disparity matching can conducted effectively. Our network includes three sub-modules, namely, depth feature representation, Hilbert cost volume fusion, and Hilbert refinement reconstruction. Separately, texture features of different depth levels of the image were extracted through Hilbert filtering operation. Next, stereoscopic disparity fusion was performed, and then Hilbert designed to refine the difference regression stereo matching solution was used. Based on the end-to-end design, the structure is refined by combining the depth feature extraction module and Hilbert coefficient disparity. Finally, the Hilbert stereo matching algorithm achieves excellent performance on standard big data set and is compared with other advanced stereo networks. Experiments show that our network has high accuracy and high performance.
Introduction
Stereo vision has always been the focus of research in the field of machine vision, and binocular stereo matching has attracted much attention due to its bionics and other characteristics. The principle is to use two cameras to obtain two digital images of three-dimensional scenes from different time and space. In this way, the cost and disparity matching of two digital images can be calculated. This technology is widely used in UAV, virtual imaging, military, and other fields [3, 21]. Following the development of deep learning, the stereo vision research based on CNN has rapidly progressed. Therefore, CNNs method has become a strong power of computer vision in stereo research. Besides, the method for matching the two disparities based on CNN is also vital to research. An overview of traditional research of stereo matching includes two types: stereo algorithms and methods [2]. The stereo algorithm field has four steps, including computing of matching cost, aggregation of cost, computing and optimization of disparity, and refinement of disparity. Besides, the stereo method research includes global, semi-global, and local methods [1]. Both approaches have their advantages and disadvantages. For example, the research based on the global method generally forms the cost function, and the classical belief propagation and graph segmentation network are relatively [6]. However, this global method has low efficiency due to its inclusion of global image information parameters, and has poor effect in the matching refinement operation of occlusion and shadow regions.
Barry and Sinha designed high-quality cost volume and scan line convolution operation to extract stereo features [7, 8]. However, these CNN-based stereo matching methods need to provide a large number of convolution extraction related features [17]. Because there are a lot of parameter calculations, it has a high requirement for both equipment and experimental equipment. Thus, the algorithm is not very efficient. The semi-global and local research usually aim at the support window method to match the disparity.
Nevertheless, there has a problem with windows choice and position choice. Feature Windows generally utilize the form of sliding of different sizes to extract features through convolution operation, leading to issues such as wrong matching and edge obesity. Inspired by Zhang, Khamis et al. designed a more refined disparity matching method for edge perception [20]. The algorithm adopts the end-to-end adaptive weight matching disparity design. Still, the difference is that the matching value of the edge is increased, which is conducive to a more accurate prediction of the edge. Thus, it has improved the effect of disparity matching, but the output of disparity at the edge of the object with occluded regions is still discontinuous.
Besides, some researchers are also devoted to disparity assessment. Liang et al. improved stereo matching cost prediction by using disparity assessment strategy subsection convolution extraction [22, 23]. However, because the above method uses human markup to calculate and summarize costs, only a small amount of linear characteristics can be learned. Features that cause the loss of a small amount of detail in the texture, and the disparity estimation is inaccurate. Some other scholars are devoted to the study of disparity matching dynamics. For example, Li et al. [30] adopted three-dimensional semantic segmentation to conduct the driving tracking path. Hamzah et al. summarized the results of a large number of researches on stereo vision [29]. They found that most studies on stereo vision are based on the principles of image and optics, and the signal transmission mode of the band can also be used to adapt to the pixel cost of the image. Nonetheless, all the above stereo matching studies have a common problem, that is, CNN-based methods are difficult or even impossible to extract disparity matching on complex or reflective surfaces. This is because they act on the disparity operation itself, resulting in part of the initial disparity is not available, and subsequent stereo matching and thinning operations are not very effective.
To solve the above problems caused by the stereo disparity itself, such as the failure to extract the disparity in the occluded region, and the difficulty in thinning the edge of low-quality disparity, we proposed an innovative Hilbert reconstruction algorithm based on depth feature and stereo matching, which is called Hilbert stereo network for short.
In the first section, we introduce the origin of stereo matching and the relevant progress in recent years (Section 1). The second section presents the proposed Hilbert stereo reconstruction algorithm, which is also the focus of this paper. Here we introduce in detail how to extract the Hilbert coefficient and represent the depth feature (Section 2.1), and the construction of the depth stereoscopic cost volume (Section 2.2). Section 2.3 is about the reconstruction of the disparity method by Hilbert and analysis of the role of the core loss function. Overall analysis, our proposed Hilbert stereo network is a real-time end-to-end architecture design. Our network consists of several predicted Hilbert coefficients, which are applied to disparity maps of different resolutions, and the disparity maps are obtained by multi-resolution Hilbert reconstruction. Low frequency Hilbert prediction learns global gap context information, high frequency Hilbert prediction detailed output disparity. Secondly, we propose a deep cost volume fusion method, which first captures multi-scale context information to represent complex features, and then performs high-precision disparity regression using dense correlation Hilbert reconstruction. In the third section, the experimental method is introduced. Specifically, this includes the introduction of the stereo reference data set (3.1), the evaluation of the establishment of the test (3.2), the details of the experimental training, and the final performance. In our design, not only the computation time and training difficulty are reduced, but also the final performance of the stereo vision algorithm is improved, and better accuracy is obtained. Finally, the Hilbert stereo matching network is used to obtain the best performance in the large-scale stereo vision benchmark test. In the experimental evaluation test, in order to ensure the superiority of the Proposed Hilbert stereo network, we referred to the statistical test operation in the [31, 35] method and designed a large number of comparison experiments for the benchmark evaluation data set of stereo vision. The fourth section discusses and analyzes the research methods and results (Section 4). Finally, in section 5, we summarized the entire Hilbert stereo reconstruction algorithm (Section 5).
To sum up, our main contribution is to propose an innovative network for three-dimensional image feature analysis and reconstruction using multiple layers and different depths of the Hilbert coefficient. We also call it the Hilbert stereo network. First of all, our network is not disturbed by external light and is not affected by occluded areas and blocked areas. Second, the depth feature extraction method uses multi-level feature fusion operation to retain complete image information. Third, end-to-end image disparity reconstruction is adopted to refine the image information of the edge and output a more complete image. Finally, the closely connected fusion network design ensures the output of high-quality image reconstruction disparity and improves the speed of the predicted image.
Hilbert stereo reconstruct algorithm
We are inspired by the design of the pyramid stereo matching network and global deep convolutional network to avoid the influence of disparity itself. We use the Hilbert filter to extract depth information in the image. Then we refine the Hilbert disparity and reconstruct the Hilbert disparity. The overall design adopts the end-to-end design of dense connection and adopts different levels of expansion rate for multi-scale image information feature analysis. The integrity of image information is ensured.
We describe an innovative algorithm to match stereo images, namely Hilbert stereo net. The detailed structure is shown in Fig. 1. First, the depth feature sub-network is used to extract the features of multiple layers of the original images. The advantage of this operation is to get the context information of all the features and refine it layer by layer. All the feature information is retained, while only the most useful feature information is utilized, without excessive parameters. The second part is the Hilbert cost volume module. We design a depth cost volume calculation and aggregation method based on the Hilbert filter. This is very important for our network because, in this step, we convert the difference to the Hilbert coefficient and cascade the output for the next operation. The last part is also essential. It uses different levels of Hilbert coefficients for multi-resolution cost reconstruction. The disparity costs in Hilbert coordinates are refined and matched, and finally, the disparity graph of Hilbert stereo matching is output.
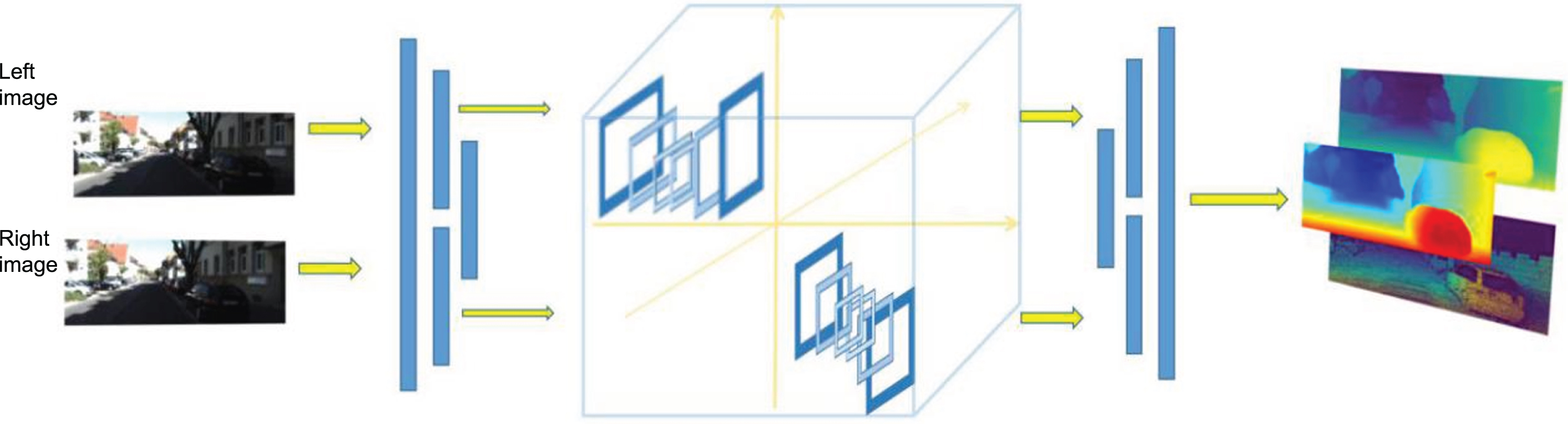
Framework of our algorithm. When we input left and right images with limit correction (from large public data sets), depth image feature acquisition is significant, which determines the accuracy of cost volume composition, and the Hilbert reconstruction method can effectively improve the image refinement disparity. Firstly, the Hilbert coefficient is extracted by multi-depth feature, and then the Hilbert disparity of different frequencies is refined and reconstructed. The overall design uses tight end-to-end connectivity.
In previous studies on feature extraction, the pyramid-pooling model and the ASPP model have been proved to be effective in obtaining feature information. However, both models lose some of the global context information. Besides, the vector extraction method based on multi-scale cannot extract the multi-scale features effectively.
To obtain whole contextual information, we propose a deep feature representation submodule to learn that can form a low-cost volume by extracting features from a pair of stereo images. Inspired by the Siamese network, we design a dense connected spatial pyramid, including two downsampling modules. In detail, our deep feature representation submodule brings the fourth resolution by using convolutions with 3×3×32 filters and a stride of 2. We use convolution operation with 3×3×32 filters in the last layer to realize deep representation, except the output layer, each Conv-layers are followed with a batch norm-operation and relu function. Finally, outputs 1/4 H×1/4 W×32 features for the left and right image. In terms of input resolution, the input resolution of the two-stage detector is generally large. Although more texture information can be obtained in this way, it also leads to a high computing cost. To obtain more texture information and improve the speed, we introduce a multi-level dilated convolution operation to extract information of different resolutions from the images. In detail, the first downsampling operation uses the convolution of four 3×3×4 filters in two inception layers. The expands at rates of 1, 2, 4, and 8. In the second lower sample, four inception layers were used, containing a convolution of3×3×8 filters, and the expansion rates were set to 1 and 2.
Deep dimension cost volume
The calculation concerning the cost matching usually used hand-crafted features [11, 28]. Based on CNN methods, there are three types of calculation process. The first type depends on characteristics and the dot product, such as the Content-CNN and MCCNN [10, 24]. The second type uses a full connection layer and convolution neural network measurement about the disparity [16, 25]. The third type uses the translation of the left and right image features method [26], such as the famous PSMNet [14]. However, this process leads to a larger cost volume. In our work, we design a deep cost volume, including the fourth resolution that can concatenate left and right unary features with shifted disparities. Then it tightly connects the two downsampling operations. The downsampling uses three-dimensional convolution with 3×3×3×32 filters and stride of 2. Finally, the output resolution indicates 4, 8, 16 multiple cost volumes. This depth cost volume structure can resolve the feature information efficiently to lose the problem. Moreover, the output different resolution level feature can also improve the accuracy of Hilbert feature integration.
Hilbert reconstruction
In this section, the Hilbert coefficients disparity map module was designed to obtain different frequency information. In terms of the overall formula design, inspired by the classical stereo matching disparity analysis, we introduce the Hilbert coefficient extraction and fusion refinement operation. In the reverse aspect of loss function design, we use the different weight expansion ratios of different levels to calculate and match the substitution value. This module was designed based on CNNs, and each of the Hilbert coefficients has the same resolution. Respective included the horizontal Hilbert, the vertical Hilbert coefficient, and diagonal high frequency, also have the low- frequency Hilbert approximation. The Hilbert coefficient method is better than the estimation of the disparity itself. In the part of Hilbert coefficient estimation, Soft argmin is used to obtain disparity results at the different sub-pixel level, and also can be used to backward propagate. Nevertheless, due to the effects of multiple modules and the control of four-dimensional regularization volume, the soft argmin is un-robustness. Based on the soft argmin function, we design the Hilbert coefficient estimation. In detail, map the cost from the lowest resolution to the low- frequency Hilbert approximation and the resolution of high- frequency coefficients by using a CNN. And then, combined both frequencies, the high-resolution Hilbert approximation was obtained by using inverse Hilbert transform. Finally, the integrated disparity map resolution is obtained by iterating through all levels. The mathematical formula is designed as Equations 1 and 2.
The low-frequency Hilbert contains rich background information approximately. The high- frequency Hilbert coefficient contains more detailed information, as shown in Fig. 2, including the final estimated Hilbert disparities, the refinement Hilbert error coefficients, and predicted Hilbert error coefficients. Specifically, as shown in Fig. 2, the image in the first column is the final result of three levels of Hilbert regression to refine the differences. The middle column is the result of Hilbert’s regression after three levels of refinement. The last column is the error results used to monitor the refinement of the differences. Figure 3 shows the results of Hilbert reconstruction. To verify the effectiveness of the Hilbert disparity refinement module, we designed relevant comparative effect experiments. The details are shown in Fig. 5, which shows the original input image, the real ground image, the effect of the Hilbert matching module, and the final effect of the Hilbert refining disparity module, respectively. The comparison indicates that our refinement module is more robust to low-texture regions and has a better prediction effect for differences.
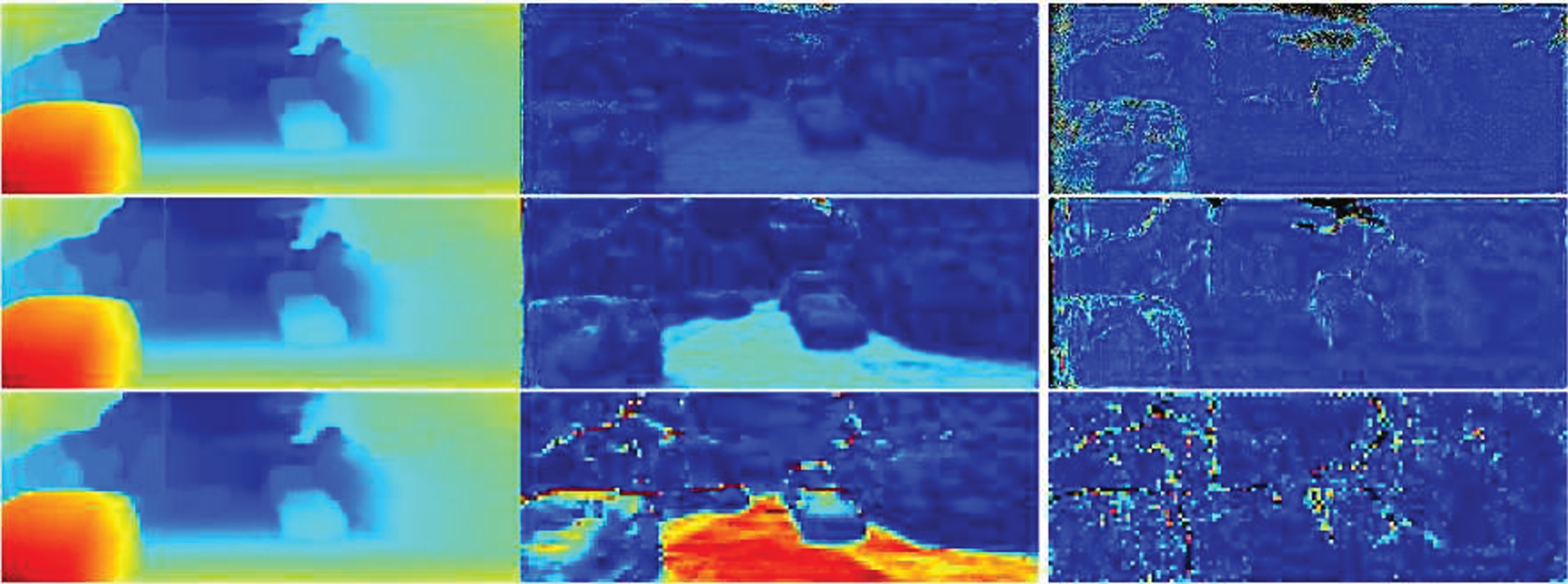
Left column is the final estimated Hilbert disparities, the middle column is the refinement Hilbert coefficients, and the last column is the predicted Hilbert error coefficients.

Disparity reconstruction results shown in this group of images. The left column shown input datasets and the right column shown final-disparity results by Hilbert reconstruction.

Results of Hilbert stereonet. The left column shown error of input datasets and the right column shown the results of different dilated ratio of Hilbert coefficient.

Effective experiment work on Scene flow data set.
And softmax function represents each disparity h weighted by its probability, we denote its as Equation 2:
In this section, we calculated depth hierarchical net refinement disparity, which included approximate smooth loss L1 and three refine loss. The design of the loss function is inspired by the L1 norm loss function. In general, it minimizes the sum of the absolute difference between the target value and the estimated value. It has higher robustness and lower outlier sensitivity.
The refine loss can be defined as Equation 3:
In which the function S was designed mathematical formula as Equation 4:
Moreover, we define the range of higher and lower loss unbalanced smooth loss as Equations 5 and 6:
With 0 < K < 0.5. It should be noted that the higher the predicted value is greater than the ground truth disparity and closer to the ground truth disparity, while the lower the predicted lower limit is closer but less than the ground truth disparity.
Datasets
Scene Flow: This is an extensive composite data set containing 35,454 training images and 4,370 test images, in which the image height H is 540, and the width is 960 [27]. The real ground image of this dataset contains dense and error rate disparity maps. In our experiment, some large disparities pixels, which is larger than the limits set and are excepted in the loss calculation.
KITTI 2012: A data set of driving cars taken from real streets, where the image size is 376 in height and 1240 in width [27]. It contains 194 training stereo image pairs and 195 testing images. The training image pairs have sparse ground truth and are obtained by using LiDAR [13]. We divided the whole training data set into a 16:3 training set and verification set.
KITTI 2015: This dataset has the same image size as KITTI 2012, which image size is H = 376 and W = 1240 [27]. It contains 200 training stereo image pairs and another 200 testing image pairs without ground-truth disparities. In our work, we divided the whole training data into a training set at eighty percent and a validation set at twenty percent.
Evaluation Experiment
In the experimental evaluation, we designed three cross experiments, including the final estimated disparity effect comparison experiment, refined the disparity map comparison experiment, and speed comparison experiment. The performance of the algorithm is tested in the three large open experimental sets mentioned above. The experimental operations and the final results in different experimental sets are described below.
On Scene flow: We adopt metric End-Point-Error to evaluate the performance of our network. For simplicity, we call it EPE. Specifically, EPE represents the average error in pixels, which also defines the average disparity error between predicted disparity and ground truth. In our work, to predict more precise effects, the large disparities were abandoned the pixels.
On KITTI 2012: In this data set mainly used for fine-tuning and pre-trained on Scene flow data set. We set the learning rate is 0.001 for the first 200 epochs and reduced by 10-4 in every 100 epochs. In the last 200 epochs, we also set the learning rate is 0.0001. Through 18.5 hours, the final module was obtained. To verify the performance of the algorithm, we set up a control test and compared it with the advanced stereo network performance. Including DRR [18], GCNet [30], DispNet [8], SGM [1], MC-CNN [9], DESNet [29] and CRL [16]. The comparison results are shown in Table 1. In which, ‘D1-bg’ represents the static elements in background pixels, ‘D1-fg’ represents the dynamic object pixels, and ‘D1-all’ represents all pixels, which consists of ‘fg’ and ‘bg’. By analyzing the error sources of various algorithms, we find that it is easy to generate errors in low texture areas such as occlusion and reflection. However, our Hilbert network is reconstructed by a Hilbert filter, which has not interfered with optics. This effectively eliminates error disparity in low texture areas.
Shown the evaluation test results on KITTI 2012. For the eight stereo algorithms, we performed three index tests on two regional pixels. It is obvious that our stereo network error rate is lower than other advanced networks
Shown the evaluation test results on KITTI 2012. For the eight stereo algorithms, we performed three index tests on two regional pixels. It is obvious that our stereo network error rate is lower than other advanced networks
On KITTI 2015: In this section, we adopt the same strategy as the KITTI 2012 experiment, which mainly to fine-tune operation. We adopt t-pixel error as evaluate index, which means the percentage of bad pixel disparity errors is higher than the threshold. In detail, we utilized two kinds of evaluation experiment indexes work on the network, including the percentage of pixels with a disparity error greater than three pixels and average error to compare index with other algorithms. They are the official assessment indexes. The results of the data are shown in Table 2.
Contrast experiment of network architecture test on the KITTI 2015 evaluation dataset. We respectively used the percentage of error-pixels in non-occluded (out-Noc) and in all areas(out-All). The error rate of our network on the KITTI 2015 data set is also lower than other algorithms, indicating that our Hilbert stereo network has high accuracy. We also run experiments faster
According to our experimental results, to visually prove the real effectiveness and high performance of our Hilbert stereo network, we supplemented the statistical test analysis experiment and compared it with other advanced stereo matching algorithms. Figure 7 shows the results.

Qualitative evaluation results of KITTI 2015 dataset. For each image, the row (a) shows the predicted disparity map about pseudo-color images, and the row (b) shows the error maps.
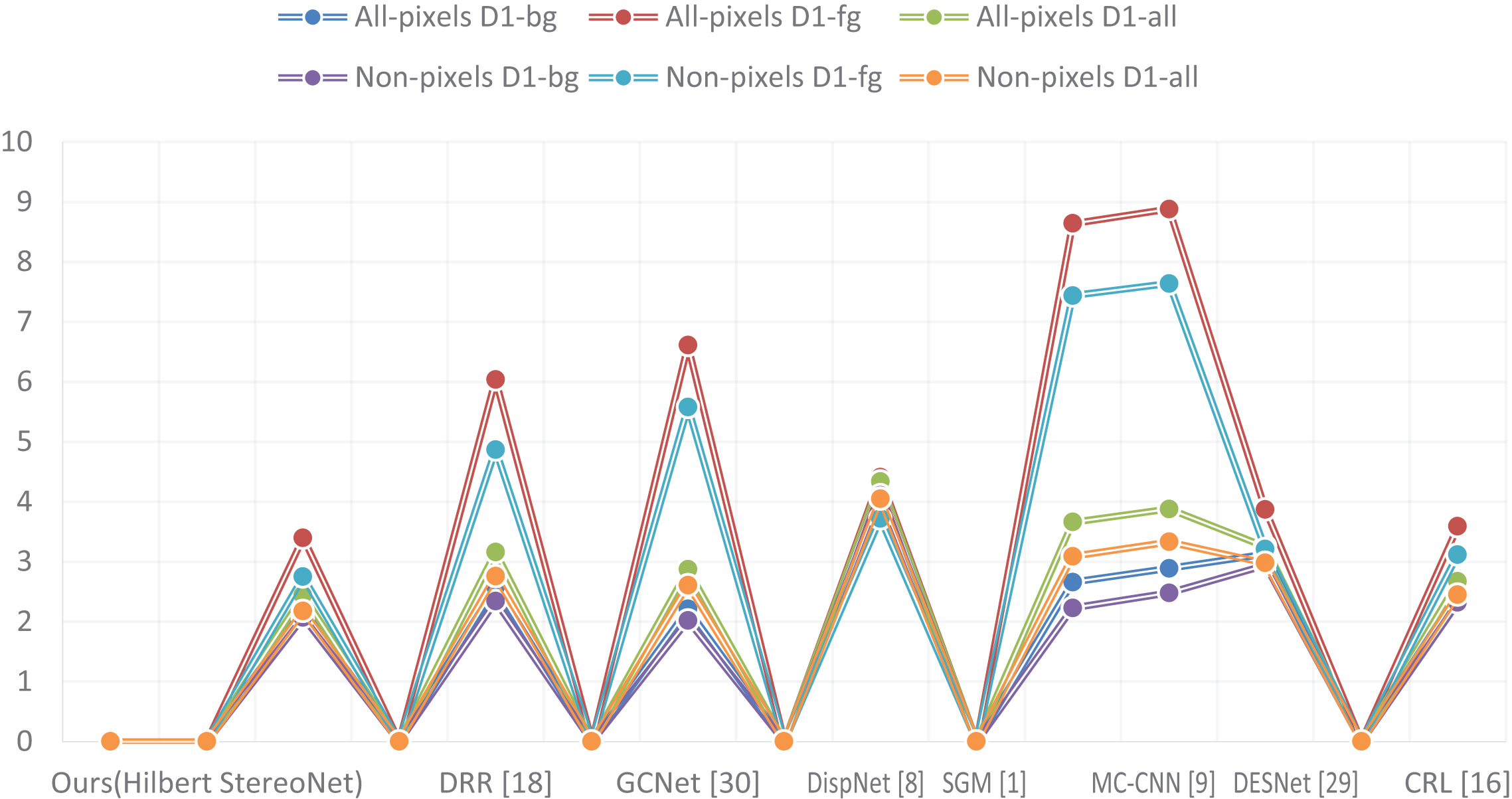
Shows our statistical test results on KITTI 2012, which can be clearly seen. The peak value of the average error on all indexes of Hilbert stereo network is lower than that of other advanced stereo matching algorithms. The validity and high precision of our algorithm are proved.
Training Detail: We using PyTorch to implement our architecture. In our work, we trained network end to end with Adam set β1 = 0.9 and β2 = 0.999. For data pre-processing, we adopted color normalization on the whole dataset. And cropped images randomly to size 256×512, set the max-disparity as 192. During training, we used the Scene Flow dataset with a constant learning rate of 0.001 for 10 epochs. We further tested our model by training it on the scene flow, fine-tuning 300 epochs on the KITTI training set using the scene flow data training model. The fine-tuning learning rate was set at 0.001 for the first 200 epochs and 0.0001 for the remaining 100 epochs. We train the network on Nvidia GeForce Titan RTX GPU of batch size 2, where parameter selection was randomly initialized. And this operation takes 60 hours totally, which takes 18 hours in the fine-tune experiment. In Fig. 4, we visually show the regression experimental results of different Hilbert coefficients. It is not difficult to see that, with the increase of feature extraction of layer number and the refinement of the Hilbert coefficient, Hilbert difference gradually refines and presents a more detailed experimental effect.
Performance: In our work, we consider a pixel to be correct, whether the disparity EPE is less than 3 percentage pixels. Table 2 shows the comparison results. According to Table 1 and Table 2, the depth refinement module improves the performance by a notable margin. In different scenarios, our depth multiple hierarchical models achieve the best disparity estimation performance on both KITTI 2012 and KITTI 2015. The final performance comparison experimental results are shown in Fig. 5. To expand, Fig. 5 shows the results of the depth matching of the Hilbert stereo images and the results of the Hilbert refinement module concerning the ground truth image. The disparity matching result of depth and stereo feature, the texture of roughness can be predicted, but the prediction effect of edge and occlusion area is not good. By refining the results of our Hilbert disparity, it is evident that the prediction effect of disparity is better in detail texture area and occlusion edge. This demonstrates the effectiveness of our Hilbert StereoNet.
In Fig. 6, we show the comparative results of the qualitative assessment experiment, in which (a) is the color prediction result and (b) is the error difference graph result. We compare several advanced stereo matching algorithms, the details of which are highlighted in yellow. The results of our Hilbert stereo refinement module show better predictive performance in both detail and occlusion texture areas.
Discussion
Prior studies that have noted the importance of stereo architecture commonly used an encoder-decoder strategy to obtain global context information. In contrast, we created the Hilbert feature filter module to extract texture features instead of the traditional encoder and decoder architecture.
The first major reason why we do this is, in the unary feature extraction, the stacked deconvolution layers were used to recover high resolution predict results. This operation makes redundant parameters. Besides, the traditional stereo matching algorithm has many problems, such as a large number of wrong matching and a small number of edges that cannot be refined in the occlusion, occlusion, or reflective areas. The encoder and decoder architectures are also convolution operation based on the image texture itself. The source of these problems is that the stereo matching algorithm is based on the study of disparity itself. In other words, the original disparity in areas such as texture distortion is minimal, or the quality itself is not high. Therefore, the cost calculation, matching, and thinning of disparity and other related operations cannot be performed. It affects the stereo algorithm matching and disparity thinning operation. Moreover, the traditional stereo matching algorithm is not good at edge refinement prediction, there is always discontinuous results output. The design of Hilbert’s three-dimensional network is a process of image information collection, matching, fusion calculation, and cost refinement with Hilbert coefficients at different levels, and the final Hilbert refinement is mainly used to refine edge output. The traditional encoder and decoder architectures have a jump connection, which leads to the loss of some image parameter information. However, our Hilbert stereo network adopts end-to-end tight connection design, which increases the utilization rate of all image cost information without losing the original image information.
This design is based on the Hilbert coefficient of the image rather than the disparity itself. It is not affected by occlusion and occlusion light problems, ensuring the accuracy of the original image differences used for analysis. Also, to verify the effectiveness of the Hilbert difference refinement module, we set up comparative performance experiments, namely stereo matching network with Hilbert difference refinement added and depth stereo matching network with refinement module added. To verify the effectiveness of the Hilbert reconstruction module, we designed another comparative experiment. The edge of disparity becomes more and more evident through the iterative refinement operation of the Hilbert coefficient. This operation is proved to be sufficient for the output of stereo matching results. Our Hilbert stereo matching algorithm breaks through the traditional image matching method and provides a new solution to the stereo matching problem of images. Later, we will try to apply it to unmanned driving or other fields.
Conclusion
Most of the previous stereo matching algorithms are based on disparity matching cost itself. This type of method is feasible for global disparity prediction. However, the prediction effect of non-textured or occluded regions is not good. To solve the above problems, we propose an innovative Hilbert stereo net, aim at obtaining high-precision disparity and outputting disparity in real-time. Our work solves the stereo by learning the Hilbert coefficients of the disparity map, rather than directly learning the disparity. Firstly, we designed an end-to-end stereo matching network based on depth characteristics and Hilbert reconstruction. Different from other network models, we refine the differences in predicted costs at different levels utilizing the Hilbert coefficient. The purpose of this operation is to avoid the influence of occluded areas and light disturbances and to enhance the effect of disparity prediction through the cost prediction module with the Hilbert coefficient acting on the sub-pixel level. At the same time, because Hilbert is a design algorithm similar to filter, it is not affected by light and image surface, directly acting on the feature difference at the sub-pixel level. The final output stereo disparity effect is superior to other stereo matching algorithms. Through a large number of comparative experiments and evaluation experiments, it is confirmed that our Hilbert structure improves the stereo matching performance as well as the speed of network disparity prediction.