
Abstract
The main target of this paper is to design a density-based clustering algorithm using the weighted grid and information entropy based on MapReduce, noted as DBWGIE-MR, to deal with the problems of unreasonable division of data gridding, low accuracy of clustering results and low efficiency of parallelization in big data clustering algorithm based on density. This algorithm is implemented in three stages: data partitioning, local clustering, and global clustering. For each stage, we propose several strategies to improve the algorithm. In the first stage, based on the spatial distribution of data points, we propose an adaptive division strategy (ADG) to divide the grid adaptively. In the second stage, we design a weighted grid construction strategy (NE) which can strengthen the relevance between grids to improve the accuracy of clustering. Meanwhile, based on the weighted grid and information entropy, we design a density calculation strategy (WGIE) to calculate the density of the grid. And last, to improve the parallel efficiency, core clusters computing algorithm based on MapReduce (COMCORE-MR) are proposed to parallel compute the core clusters of the clustering algorithm. In the third stage, based on disjoint-set, we propose a core cluster merging algorithm (MECORE) to speed-up ratio the convergence of merged local clusters. Furthermore, based on MapReduce, a core clusters parallel merging algorithm (MECORE-MR) is proposed to get the clustering algorithm results faster, which improves the core clusters merging efficiency of the density-based clustering algorithm. We conduct the experiments on four synthetic clusters. Compared with H-DBSCAN, DBSCAN-MR and MR-VDBSCAN, the experimental results show that the DBWGIE-MR algorithm has higher stability and accuracy, and it takes less time in parallel clustering.
Introduction
In the current era, the need, growth, and expansion of data from different sources create challenges in their collection, processing, management, and analysis. Big data is the next generation of computation which tackles these challenges and obtain useful information from the data [14]. It has brought up a new perception and has been used by many researchers in recent years.
Data mining is a set of techniques to extract potentially useful information and knowledge from a large number of incomplete, noisy, fuzzy and random data. Clustering is one of the most popular tools in data mining, used to group a collection of physical or abstract objects into classes composed of similar objects, which has a substantial usage in statistical learning, artificial intelligence, and pattern recognition [8]. Clustering algorithm groups single and distinct points into clusters such that the members of the same cluster have the highest similarity with each other whilst the points in different clusters are significantly different. In clustering algorithms, density-based clustering algorithms, such as DBSCAN [15] and OPTICS [7], can find clusters of arbitrary shape and are not sensitive to noise, which have attracted a lot of research interest. However, the traditional density-based clustering algorithms cannot be directly used for big data owing to their high time complexity. Improving the existing density-based clustering algorithm and combining it with the distributed computing architecture for a lower computational complexity have become the leading research direction of current density clustering algorithms [3, 17–22].
Many solutions have been proposed to reach this direction, the advent of MapReduce [22], Hadoop, and spark architectures make it possible [5]. Li et al. in the paper [6] first proposed a parallel DBSCAN Algorithm based on MapReduce. After dividing the data, this algorithm uses the MapReduce framework to parallel execute the DBSCAN algorithm to get local clusters. Then the global cluster is obtained by merging the local clusters incrementally. However, this algorithm did not propose an effective method for dividing the data, which leads to high computational complexity. Silva et al. [15] proposed a new efficient distributed strategy of DBSCAN that used MapReduce to detect dense areas according to the input parameters and merge clusters incrementally. It also has high computational complexity and a lower overall parallelization efficiency.
Dividing data effectively and merging local clusters have always been important research of the parallelization of density clustering algorithms [4]. Data gridding can divide spatial data into a finite number of units, and points falling into the same grid can be treated as an object, which can well solve the problem of data gridding [12]. Hence, Mahran et al. proposed the GriDBSCAN (Using Grid for Accelerating Density-Based Clustering) algorithm [13], which uniformly grids data. It uses grids as objects to execute the DBSCAN algorithm in parallel and merge these grid objects to get global clusters. But there are two obvious problems with the algorithm: when dividing the grid evenly, it is difficult to determine the size of the grids, and using regular grids, which may divide up data sets in high-density areas and create a large number of duplicate boundary points, it will seriously affect the clustering results. Besides, the incremental method is adopted to merge local clusters, resulting in low computational efficiency.
Literature [5, 17] proposed an H-DBSCAN algorithm based on Hadoop and an S-DBSCAN algorithm based on Spark. Based on dividing the data equally, they add the extension of the grid boundary to improve the accuracy of clustering results and the efficiency of local clustering. But it was not enough. For better efficiency and effect, Wang et al. in their paper [19] proposed an IP-DBSCAN (an incremental parallelization fast clustering algorithm). Based on the number of data points, the algorithm divided the space grid by dichotomy and combined the greedy algorithm to restructure the partition rationally to reasonably divide the data. It dealt with local clustering to obtain the merged candidate cluster sets. The candidate clusters of R* -tree indexes were merged to be judged and processed. An undirected acyclic graph model of the merged clusters was established, and the data was globally re-labeled. However, the IP-DBSCAN algorithm had two obvious shortcomings. On one hand, it is necessary to input the threshold of grid edge length when the algorithm uses dichotomy to divide data. The different thresholds will affect the accuracy of clustering results, which results in low accuracy. On the other hand, the computational complexity of local clustering is high, and the parallelization strategy is not adopted when combining local clusters, so the overall parallelization efficiency of the algorithm needs to be improved.
Aiming at the problems of unreasonable partition of data and low accuracy of clustering, Dai and Li [2] proposed a method, partition with reduce boundary points (PRBP), to select partition boundaries based on the distribution of data points to reach load balance of each node, meanwhile, they proposed the DBSCAN-MR algorithm with the design of PRBP. Bhardwaj and Dash [9] introduced density level partitioning (DLP) into DBSCAN-MR and proposed the VDMR-DBSCAN algorithm. Use of their merging strategy, which can identify clusters with different densities. Heidari et al. [11] proposed the MR-VDBSCAN algorithm, which improved the accuracy and the speed of local clustering compared with VDMR-DBSCAN. However, all these algorithms do not solve the problem of low efficiency in merging local cluster.
To overcome the above limitations, we take the DBSCAN algorithm as the prototype, propose a density-based clustering algorithm using a weighted grid and information entropy based on MapReduce, noted as DBWGIE-MR. The main contributions of our work include: We propose an ADG (adaptive divide grid) strategy to divide the grid adaptively according to the spatial distribution of data points. For each data partition, we propose NE (Neighboring Expand) strategy to construct its weighted grid to strengthen the relevance between grids to improve the clustering effect. Meanwhile, we propose the WGIE (weighted grid and information entropy) strategy to calculate the grid density, the ɛ-neighborhood, and core objects of the density clustering algorithm, so that the density clustering algorithm is more suitable for the weighted grid. Then, combining with the MapReduce, we propose COMCORE-MR (Computing Core Cluster by using MapReduce) strategy to solve the problem of low computing efficiency for local clusters in the parallel density clustering algorithm. After the local cluster is formed, we propose the disjoint-set merging algorithm MECORE (Merge Core Cluster) based on the disjoint-set to accelerate the convergence rate of the disjoint local cluster. Then combined with the MapReduce, we propose a parallel local cluster merging algorithm MECORE-MR (Merge Core Cluster by using MapReduce) based on MapReduce to realize the parallel merging of local clusters, to improve the overall parallelization efficiency. The global cluster of clustering results can be obtained more quickly when merging local clusters in parallel, which improves the efficiency of the density-based clustering algorithm.
The rest of the paper is organized as follows. Section 2 introduces some basic concepts and the background of MapReduce and DBSCAN. Section 3 introduces the detailed design and implementation of DBWGIE-MR. Section 4 presents the experiment settings and results. Section 5 concludes the paper.
Preliminary
MapReduce
MapReduce [22] is a programming model for parallel computing of large data sets (larger than 1TB). “Map” and “reduce” are its main ideas. MapReduce can automatically divide the big data to be processed into many data blocks, and automatically schedules the computing nodes to process the corresponding data blocks. It greatly facilitates programmers to run their own programs on distributed systems without parallel programming.
In MapReduce, data is represented as (key, value) pairs. A job in MapReduce consists three stages: map, shuffle, and reduce. For each input pair (k1, v1), several output pairs list (k2, v2) are generated based on the (k1, v1) in the map phase, and partitioned and transferred to reducers in the shuffle phase, while in the reduce phase, pairs with the same key are grouped as (k2, list(v2)). At last, the reduce function generates the final output pairs list (k3, v3) for each group.
DBSCAN
DBSCAN [15] is a typical density-based clustering algorithm. It defines a cluster as the largest set of density-connected points, which can find all the dense area of data points and divide them into clusters, it does not need the number of clusters and the process is not affected by noise. DBSCAN has two important parameters: Eps and MinPts. Eps is the neighborhood radius of each object, and MinPts is the minimum points in the neighborhood of each core object. In the DBSCAN algorithm, there are three categories of data points:
Generally, the core point corresponds to the point inside the dense area, the boundary point corresponds to the point at the edge of the dense area, and the noise point corresponds to the point in the sparse area.
Uniform data gridding
Traditional grid-based clustering algorithms, such as the STING, Wave Cluster, and CLIQUE, all use the uniform data gridding [12] method to divide the data space. It can be described as follows: Considering a d-dimensional space, dividing each dimension into n intervals that have the same size and disjoint from each other. Therefore, the whole data space is divided into n d equal grids, as is shown in Fig. 1, when D = 2, n = 3, the two-dimensional data space will be divided into 9 equal grids.

Uniform data gridding.
Weighted grid [10] construction strategy (NE) can strengthen the relevance between grids due to the weights added between the grids, the definition is as follows:
Information entropy
Information entropy [16], proposed by Dr. Shannon in 1948, describes the average uncertainty of a random variable or its probability distribution. For a discrete variable X, the definition of information entropy of which is shown below:
Disjoint-Set [1] is a kind of data structure that can dynamically maintain several non-overlapping sets and support the operations of merge and query. Disjoint-set uses a separate tree to indicate each set, the root node of the tree represents the set, and each leaf node of the tree represents an element in the set. There are three steps to combine the disjoint dynamic sets X = {x1, x2, . . . , x
n
} and Y = {y1, y2, . . . , y
n
} with a disjoint-set, the whole process can be summarized as follows: makeset (X, Y): Creates a new disjoint-set for X and Y separately, which contains n single-element sets. find (x): Returns the representation of the set which element X resides in. unionset (x, y): If the set where element x and y reside in are not intersected, merging them.
Algorithm DBWGIE-MR
DBWGIE-MR consists of three stages: data partitioning, local clustering, and global merging. In stage 1, the grid and ADG strategy were adopted to adaptively divide the whole dataset into smaller partitions according to spatial proximity. After data partitioning, the data was divided into local and border areas, thus providing the conditions for the later cluster-merging procedure. In stage 2, each partition is clustered independently, NE strategy, WGIE strategy, and COMCORE-MR algorithm were adopted to get local clusters. This stage is the dominant part of the whole process in terms of computation time. The slowest local clustering task decides the performance of this stage. In the last stage, the MECORE algorithm and MECORE-MR algorithm were adopted to get global merging. An overview of the DBWGIE-MR algorithm is shown in Fig. 2.
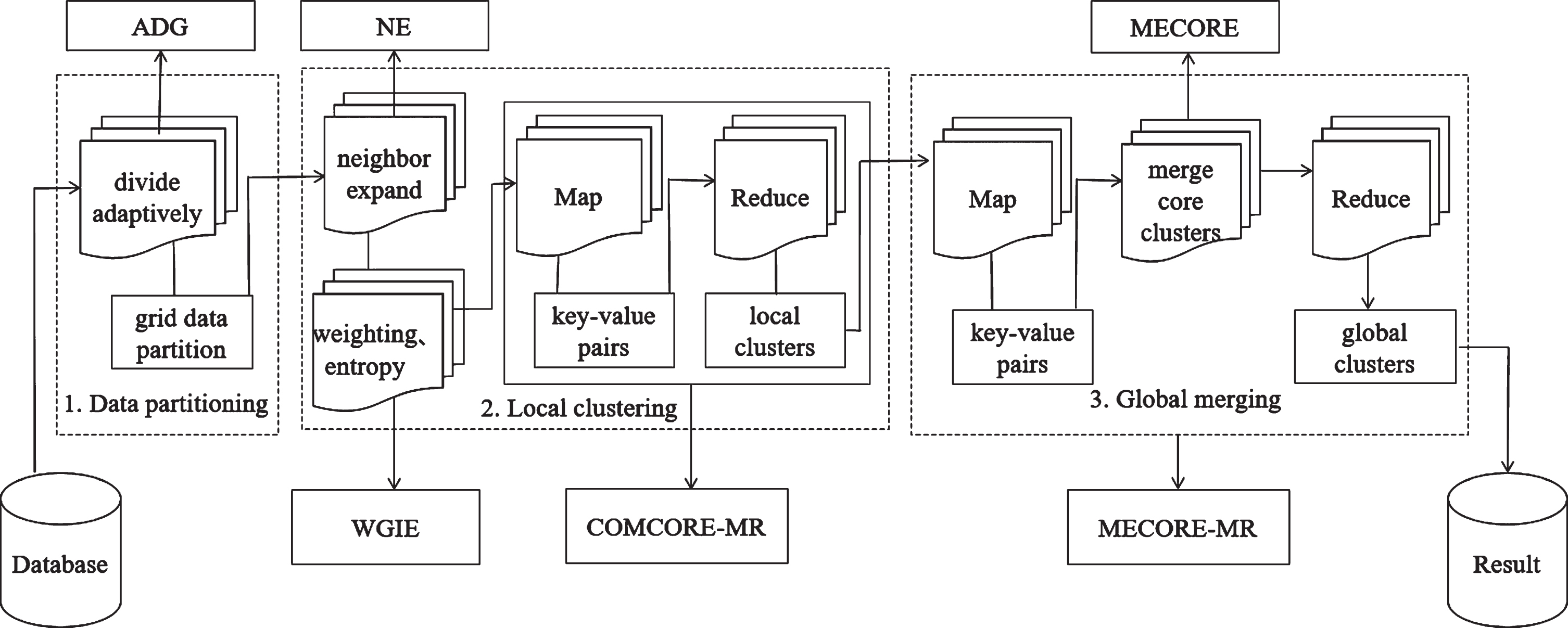
An overview of DBWGIE-MR algorithm.
The purpose of data partitioning is to divide a complete large data set into small pieces that can be processed independently. Most of the existing partition methods focus on evenly dividing the data so that the number of points in each partition is as uniform as possible, such as the methods of grid-based, KD-tree-based, and binary-tree-based and so on. However, they do not work well because the initial side length of the grid is difficult to determine, and the density of grid data is uneven. For these issues, we use the ADG strategy to divide data into grids adaptively. The principle of ADG strategy is as follows:
Firstly, dividing the d-dimensional data space into 2 d initial grids equally, then, we use the minimum average distance between data points in the current grid, and the number of data points in the current grid to calculate the division threshold φ of the edge length of the grid. Keep equally dividing the current non-empty grids, if the current edge length of the current non-empty grid is longer than φ, we stop dividing it. The definition of the threshold φ is shown below:
When φ ⩾ L, i.e.,
When φ < L, i.e.,
As shown in Fig. 3. The density of the grids divided by ADG strategy is very uniform, which is conducive to reach load balance of MapReduce nodes and improves the stability of clustering.
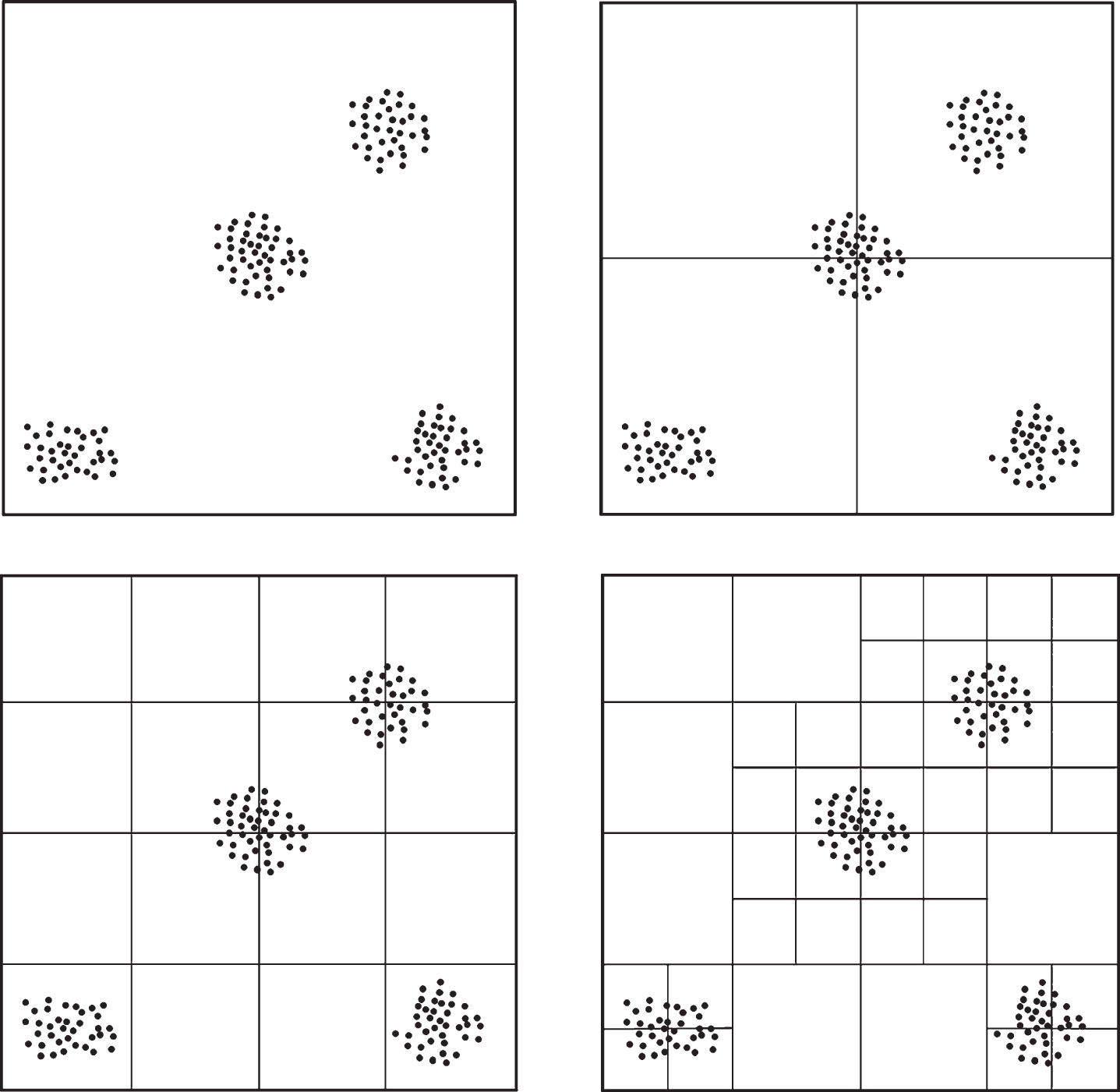
Grid division by using ADG strategy.
The local clustering stage performs the clustering algorithm for each data partition separately and saves the local clusters as intermediate results. In this phase, any data slices split in the last step of the first phase are distributed to the executor through the task scheduler for local DBSCAN cluster calculations. The process is divided into three parts: building weighted grid, calculate grid density, and get local clustering.
Building weighted grid
After gridding data in stage 1, the NE strategy was adopted to build the weighted grid. Before which, several parameters should be determined in advance. The scope of the weighted grid is the parameter that needs to be determined first. And the weight of the weighted grid is the second parameter that needs to be set. The definitions of the parameters are as follows:
Based on the neighbor grid of the Grid Object [20] and the principle of grid boundary expansion [5], respectively, these parameters are defined as follows:
Where N (Gs1,...,s
d
) is the set of grids within the range of the weighted grid, Gs1,...,s
d
is a grid,
When
The following example is based on Definition 7. In Fig. 4, there are 16 grids in the data grid, and the dimension of data is 2. It demonstrates the procedure of building the weighted grid. By Definition 7, the range of action of the weighted grid object is formed within the range of
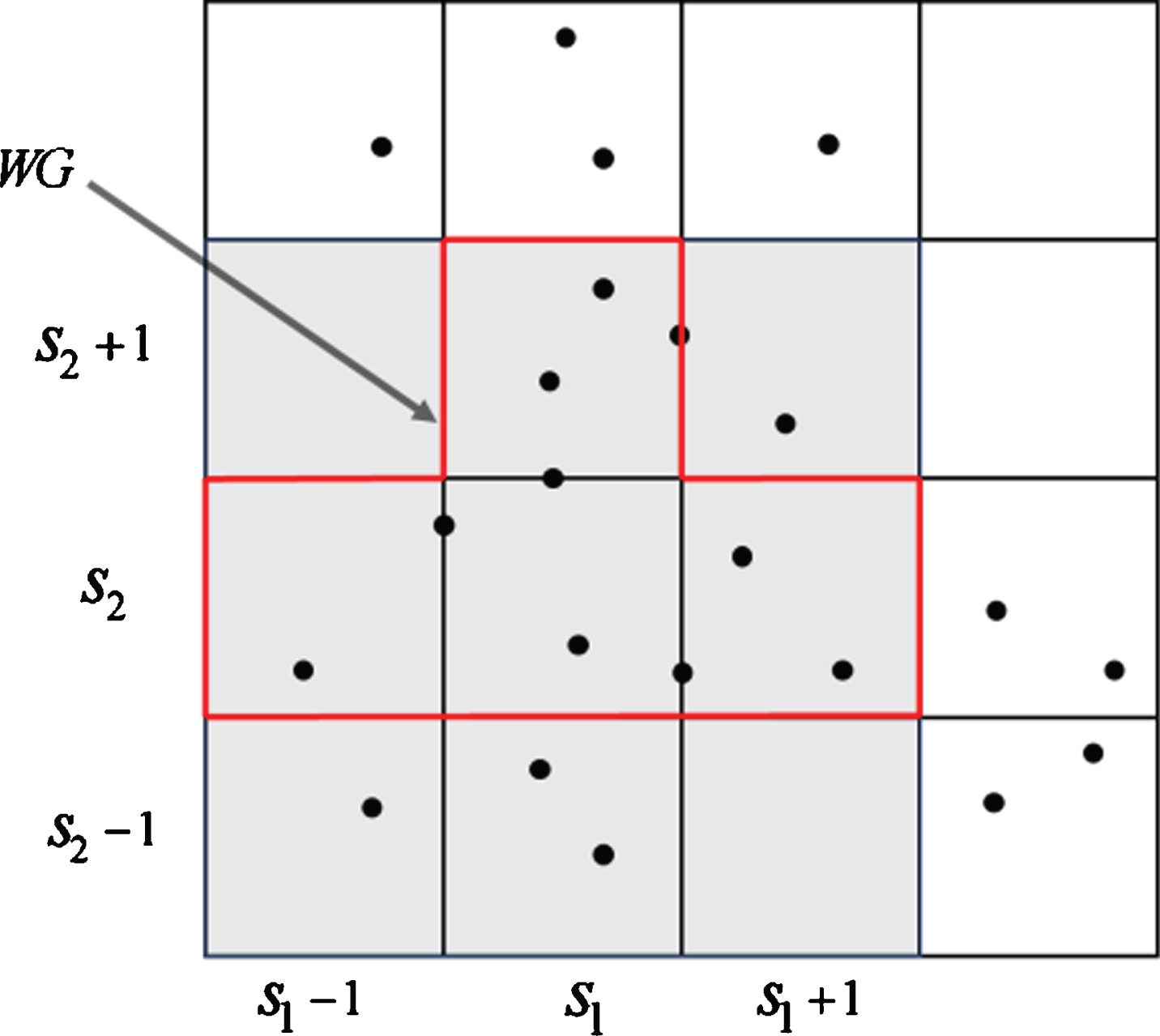
Building the weighted grid.
Consider a certain correlation between grid objects based on the weighted grid. It is unreasonable to use the number of data points in the grid to calculate the grid density. For this, in this section, we propose WGIE (weighted grid and information entropy) strategy to calculate the density of grids, the ɛ-neighborhood and core object of density clustering algorithm are also redefined. The definition of the grid density calculated by WGIE strategy is shown below:
Where x is the number of grids with this density; P (t) is the probability in which the grid density is t; count (t) refers to the number of grids in which the grid density is t; count (n) represents the total number of non-empty grids after partition.
It can be seen from the above that the formula meets the basic conditions of the definition of information entropy, which can be used to evaluate the stability of the system.
According to the scope of the weighted grid and the information entropy, we redefine ɛ-neighborhood and core object. Because the core object is closely related to the density of grids, the weighted grid and information entropy strategy can accurately compute the density value of grid objects. When the density H ’(x) of the grid is smaller than the given density threshold μ, it means that the data in the weighted grid centered on the grid is ordered. It is better to center on the grid, and the grid will also have a large probability of becoming the core object. The ɛ-neighborhood and core object are defined as follows:
The efficiency of local clustering also determines the performance of the algorithm. In this case, we design the COMCORE-MR algorithm for parallel computing local clusters. It contains two steps: Parallel computing grid density and Parallel computing local cluster.
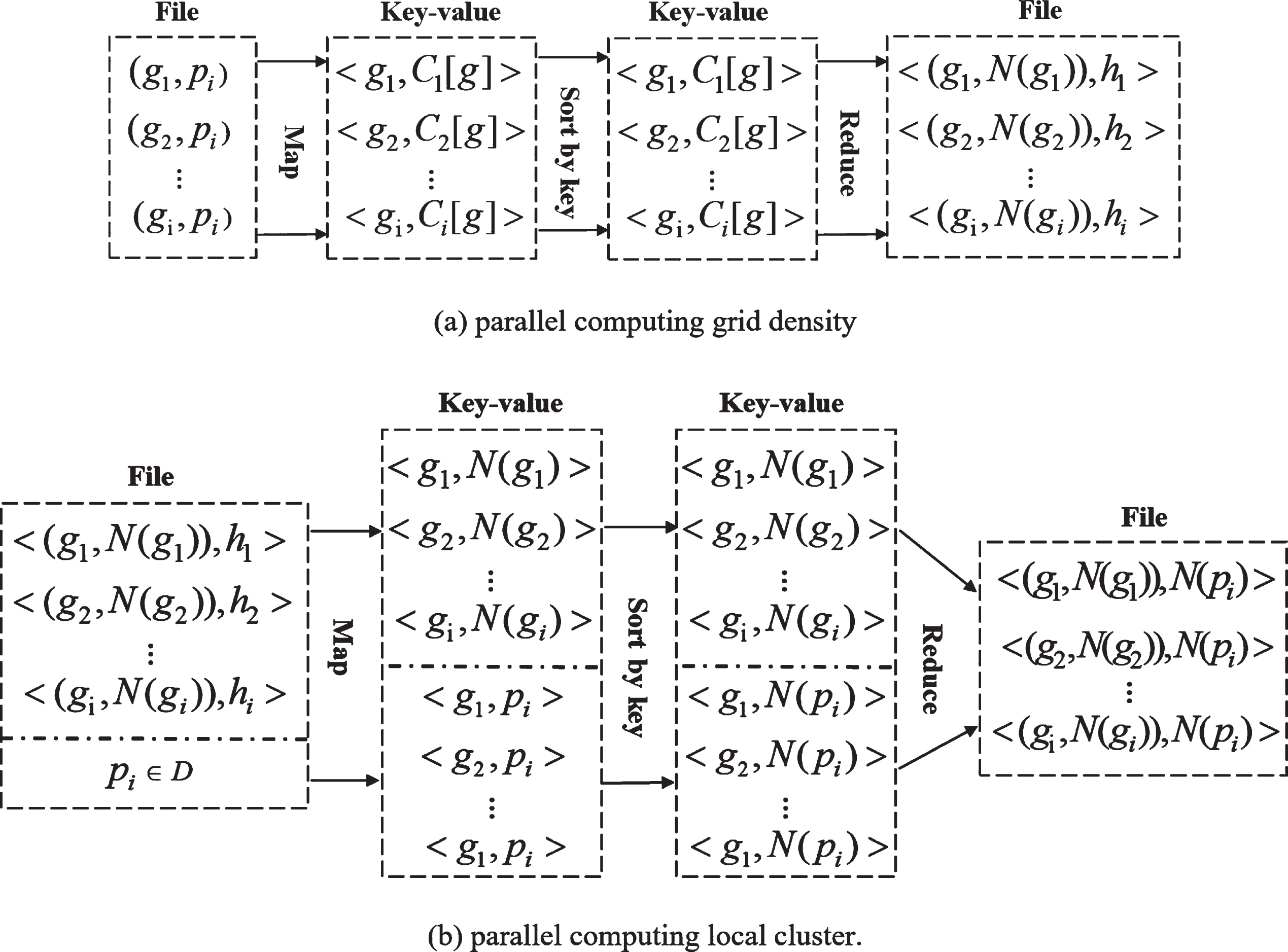
The calculation process of COMCORE-MR algorithm.
In this phase, the generated local cluster are renamed, and each cluster has only one global cluster number. In this way, the final clustering results are generated. The last step of clustering is to merge local clusters into global clusters, which can be divided into two steps: Merging local clusters and parallel merging local clusters. In the first step, we introduce the methods of local cluster merging, and in the second step, some new strategies based on Map-Reduce will be proposed for the parallel merging of local clusters. We will explain them in detail below.
Merging local clusters
According to the merging method of two disjoint sets, MECORE includes three methods of merging different grid objects based on disjoint-set:
Then use these three methods to merge the local clusters. The overall steps of the MECORE algorithm are as follows:
After algorithm execution, according to the corresponding data points and grid ID, we can get the global clustering, and the data points marked as unvisited in the grid objects are outliers. The algorithm merging of local clusters shows in Algorithm 1.
grid object set G after data partition, table R composed of local clusters. global clusters Function Merge (G, R) g.state=unvisited
Make-set (g)
g.state=core
Union-set (g, g
i
) g
i
.state=border
Union-set (g, g
i
)
g.state=Outlier
Parallel merging local clusters
The local cluster merging algorithm based on disjoint-set can merge the local clusters to get global clusters. However, the parallel clustering algorithm based on density does not merge local clusters in parallel. For that, MECORE-MR based on MapReduce is proposed. The steps are as follows:
Grid object-set G after data partition, table R composed of local clusters, dataset D global cluster Function MECORE-MR (G, R, D) k=Count (Machine) G1, G2, . . . , G
k
=Partial (G, k) Result=RunMapReduce (G, R, D, G1, G2, . . . , G
k
) { MapReduce. Map (p
i
, G) g=Grid (p
i
, G) emit (<g, p
i
>) end map
MapReduce. Map (g, G1, G2, . . . , G
k
) { i = Partial_Id (g, G1, G2, . . . , G
k
); R1, R2, . . . , R
k
= Partial (R, i); M
i
= R
i
; emit (<M
i
, (g, N (g
i
))>); end map
MapReduce.Reduce (G
i
,(g, N (g
i
))){ M
i
= MECORE (G
i
, (g, N (g
i
))); end Reduce M = MECORE (M
i
, Mi+1);
Result=Point (M, <g, p
i
>); Return (Result); end Run MapReduce
Procedures of DBWGIE-MR
The specific implementation steps of the DBWGIE-MR algorithm shown in Algorithm 3.
point set D of data space, the dimension d of data space global cluster Initialization parameters: Density threshold μ of grid objects The data space is divided into 2
d
initial grids Execute ADG strategy to get the divided data grid-set G
Execute NE strategy to build the weighted grid, and get the weighted grid of each grid object WG (g
i
, N (g
i
))
Call COMCORE-MR algorithm and output key-value sequence < (g
i
, N (g
i
)) , N (p
i
)> Make the key-value sequence < (g
i
, N (g
i
)) , N (p
i
)> into a table R of the local cluster Return (R)
Call parallel merging local clustering algorithm MECORE-MR (G, R, D) to get Cluster global cluster Result
Return (Result)
Time complexity of the algorithm
Time complexity can measure the performance of the algorithm. The time complexity of DBWGIE-MR depends on the gridding of data, the construction of the weighted grid, the parallel calculation of grid density, the parallel calculation of local clusters, and the parallel combination of local clusters. The time complexity of these steps are as follows: 1) Assuming the number of data points in the space is n, the time complexity of data grid using ADG strategy is O (n2); 2) Assuming the number of non-empty data grids is k, the time complexity of using NE strategy to build weighted grids is O (k2); 3) Under the MapReduce, assuming that the number of distributed machines that executing functions is m, the time complexity of parallel computing of local clusters by using COMCORE-MR algorithm is O ((n + k)/m); 4) The time complexity of parallel merging algorithm for local clusters of COMCORE-MR algorithm is O ((n + k3 + m2)/m).
In summary, the time complexity of the DBWGIE-MR algorithm is O ((n + k3 + m2)/m + n2) because of K < n, m < n, which one is approximate O (n3/m + n2).
Evaluation
Experiment settings
We do the experiments on a Master machine and three Slaver machines. Each machine is equipped with a single quad-core Intel Core i5-9400 H CPU @ 2.9 GHz processor, 16 GB DRAM memory, and 1 TB SATA3 7200RPM hard disk. The operating system is Ubuntu Linux 16.04. The software programming environment is python3.5.2. For the MapReduce platform, we choose the Apache Hadoop3.2.
Data sources
The experimental data of the DBWGIE-MR algorithm are 4 real datasets from UCI [23] public database, which are
Details of the datasets
Details of the datasets
F-measure
Parameter setting and an appropriate evaluating indicator are particularly important. To quantitatively appraise the approach’s outputs, we use the fitness measure (F-measure) to evaluate the results of the clustering algorithm, which is the weighted average of precision and recall.
The definition of F-measure is as shown in Equation (6):
Generally, λ is set to 1, F-Measure comprehensively considers the precision and recall of clustering results, which can evaluate the results of the clustering algorithm more accurately. When the value of F-Measure is higher, it means the results are more accurate and reasonable.
Analysis of variance can be used to determine whether there are significant differences on the observed data or processing results of several groups. We use F-statistics (F) to evaluate the improvement of our algorithm, F-statistics is the ratio of mean squared between (MSB) and mean squared error (MSE), the freedom of which is k - 1 and N - k respectively. The definition of F-statistics is as shown in Equation (7):
As mentioned in the previous section, to apply the DBWGIE-MR algorithm, several parameters must be set. Because these parameters depend on the features of the data set, the accuracy of the resulting clustering is directly dependent on the user’s choice of parameters. For this reason, an empirical study was undertaken on the selected parameter to optimize these parameters for optimal clustering results. In this study, based on the
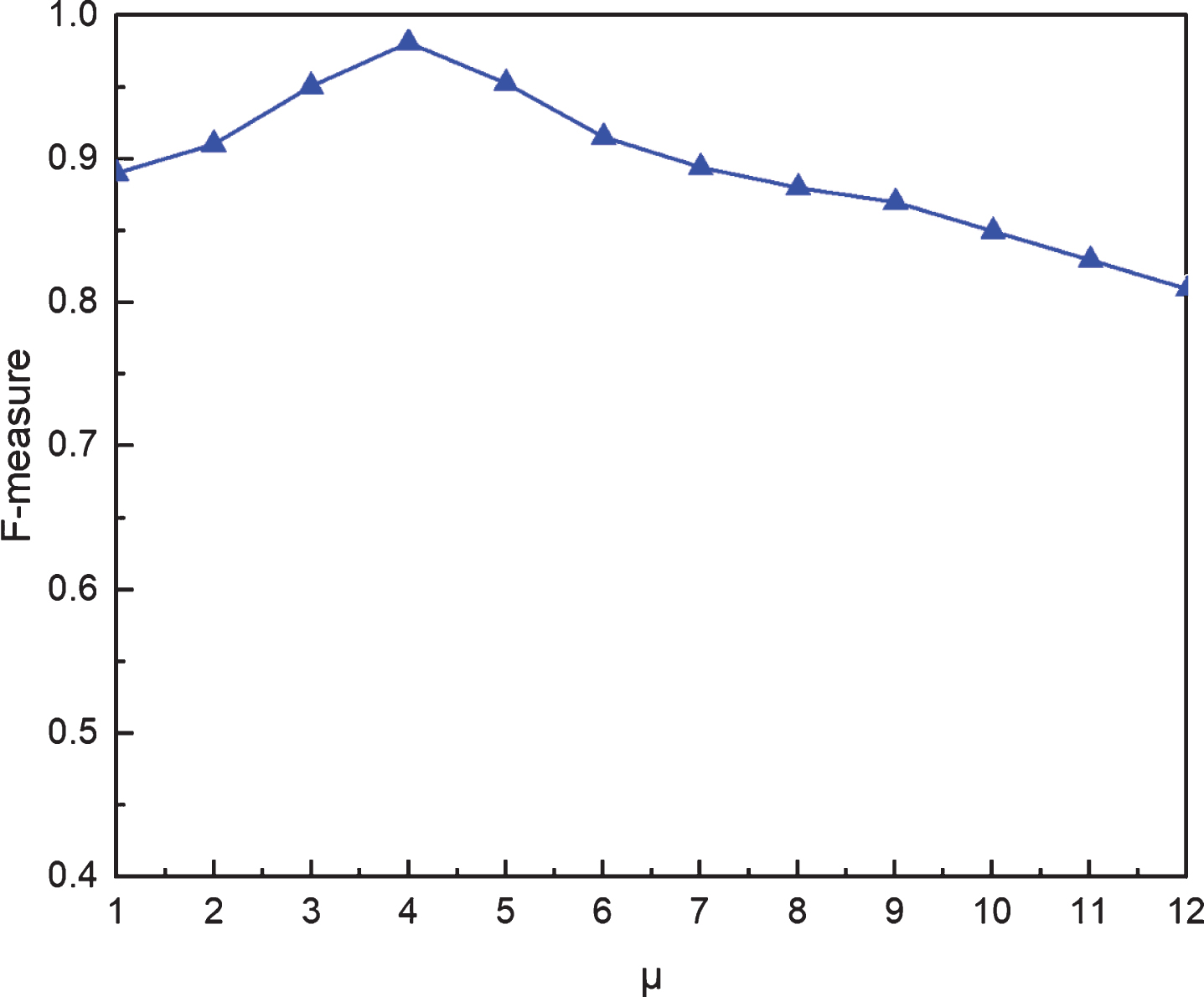
F-measure.
The ability of DBWGIE-MR algorithm should be evaluated from different aspects. We conducted 10 experiments on the datasets based on
Comparative analysis of clustering results of each algorithm
Comparative analysis of clustering results of each algorithm
The accuracy can directly reflect the clustering results of the algorithm, which is, the higher the better. The F-measure was adopted to calculate the accuracy of the algorithm and the mean of 10 experiments was used to compare the accuracy of DBWGIE-MR with that of H-DBSCAN, DBSCAN-MR and MR-VDBSCAN algorithms respectively. The experimental results are shown in Fig. 7.
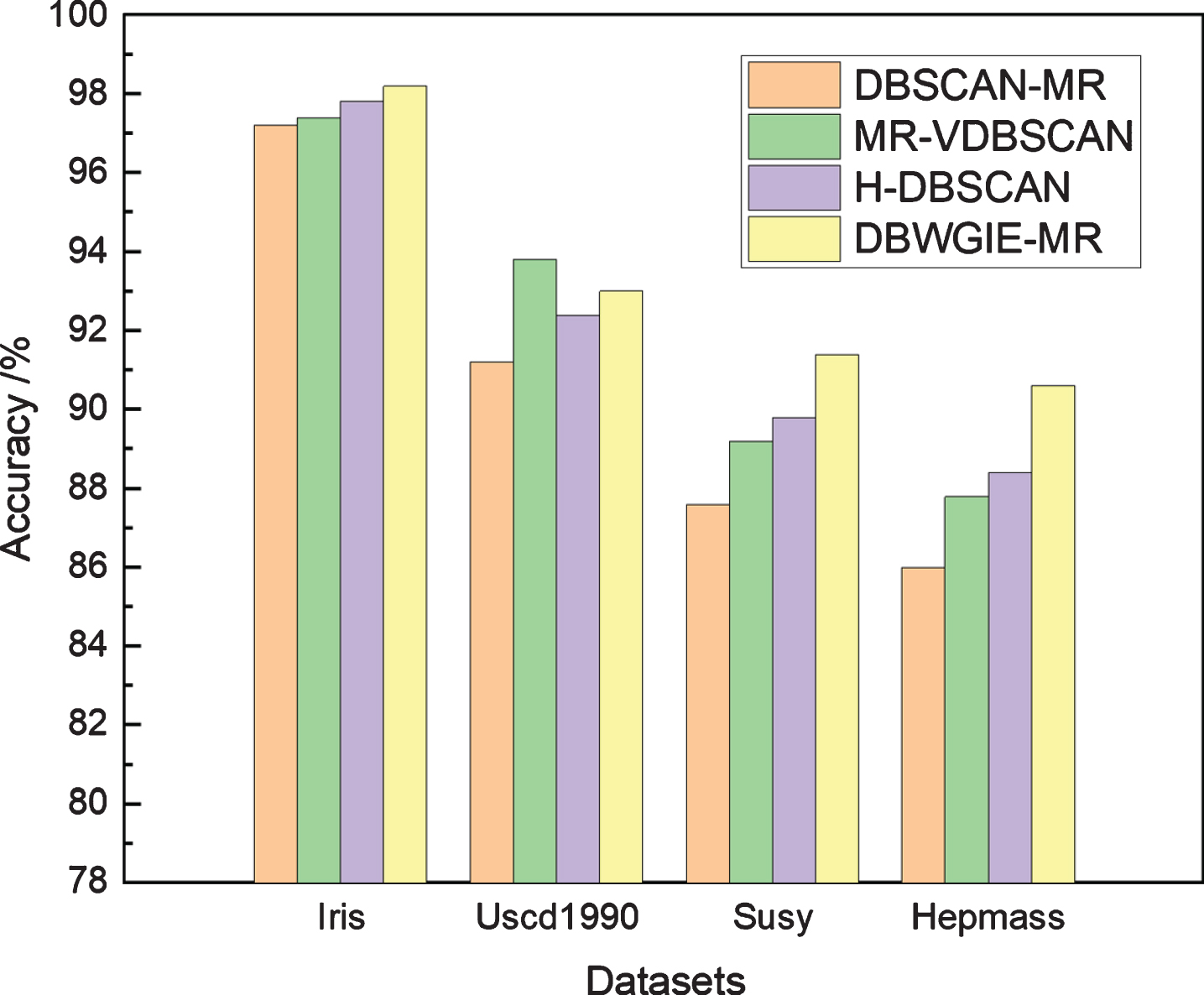
Accuracy of different algorithms in different datasets.
As shown in Fig. 7 that DBWGIE-MR algorithm has a higher accuracy than that of the other algorithms on most datasets. On the
The variance of accuracy can show the stability of the algorithm, the smaller the value, the more stable the algorithm. We recorded the variance of the accuracy of the four algorithms in 10 experiments and take the mean to compare the stability of DBWGIE-MR with that of H-DBSCAN, DBSCAN-MR and MR-VDBSCAN algorithms respectively. The results of the variance are shown in Fig. 8.
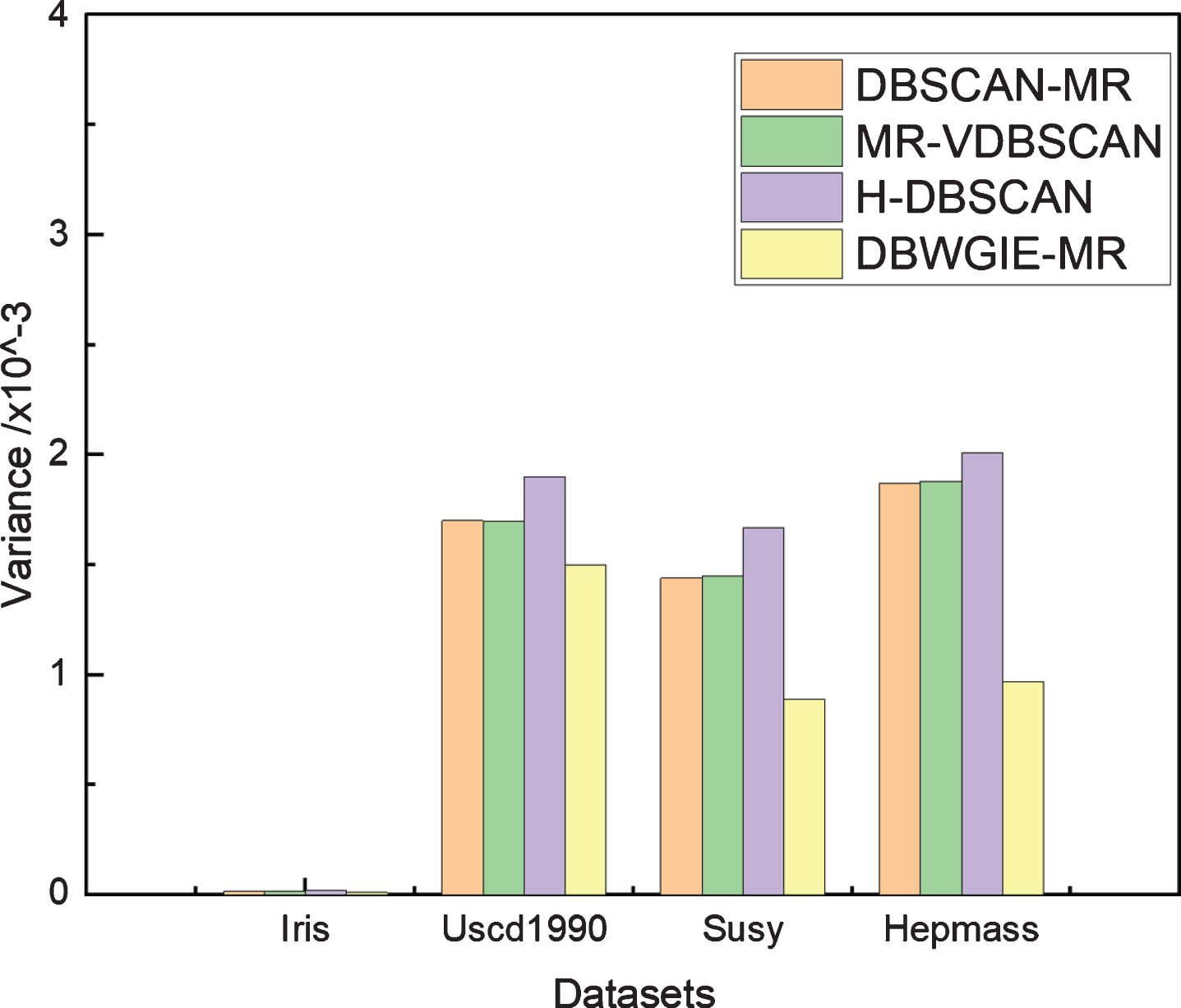
Variance on different datasets.
As shown in Fig. 8 that DBWGIE-MR algorithm has a smaller variance than that of the other algorithms on the 4 datasets and it has a decisive advantage on complex datasets. When clustering on a simple small dataset as the
We made the assumption H0: “the average values of the clustering results of the four algorithms are equal, namely μ
a
= μ
b
= μ
c
= μ
d
”, then calculated the F-statistics of the DBWGIE-MR and the other algorithms on
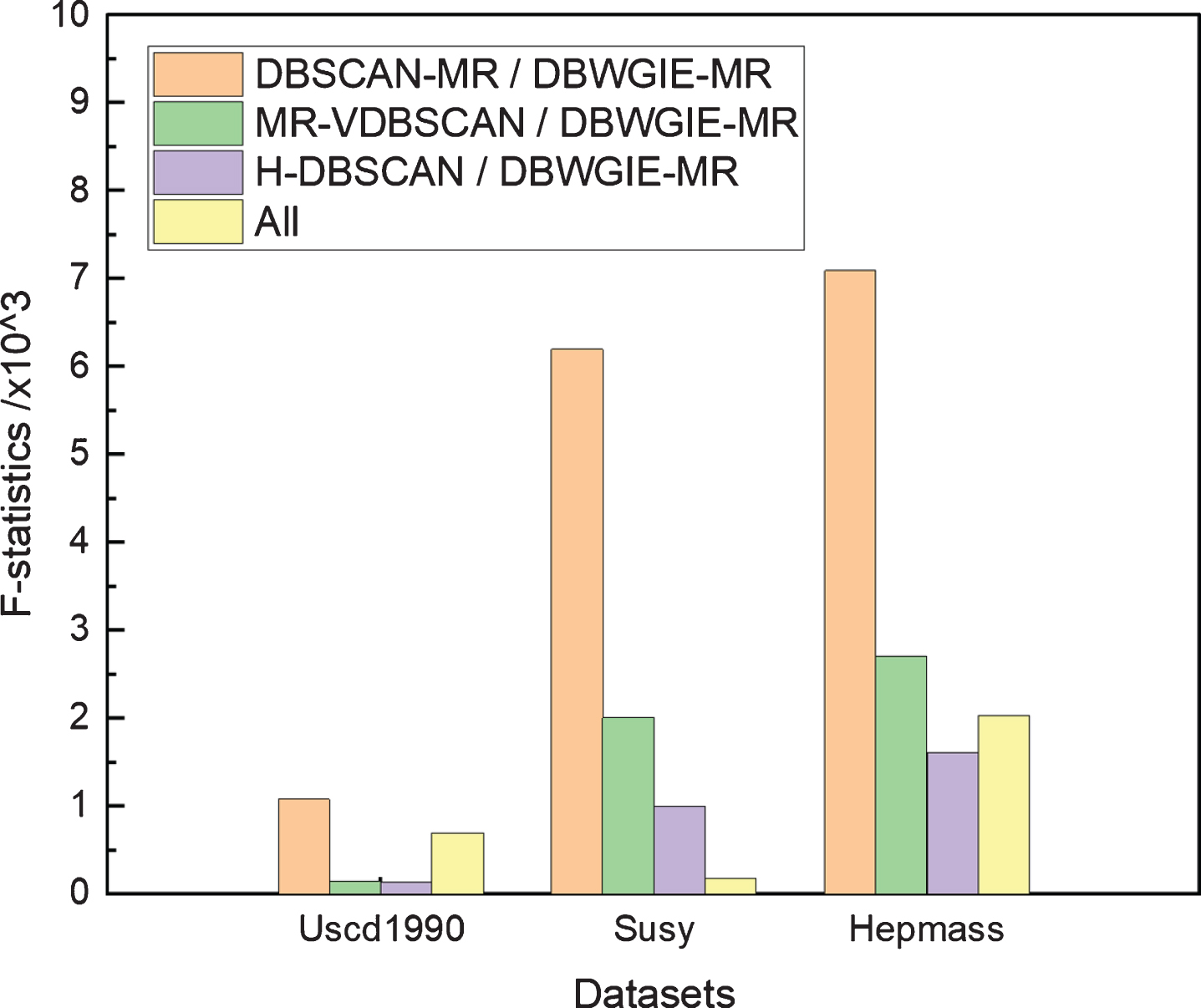
F-statistics.
The “
Analysis of speed-up ratio
The speed-up ratio is the ratio of time consumed by the same task running in a single processor system and parallel processor system, and it is usually used as an important index to test the performance of a parallel algorithm, which is the bigger, the better. In this experiment, we randomly extracted four subsets from the
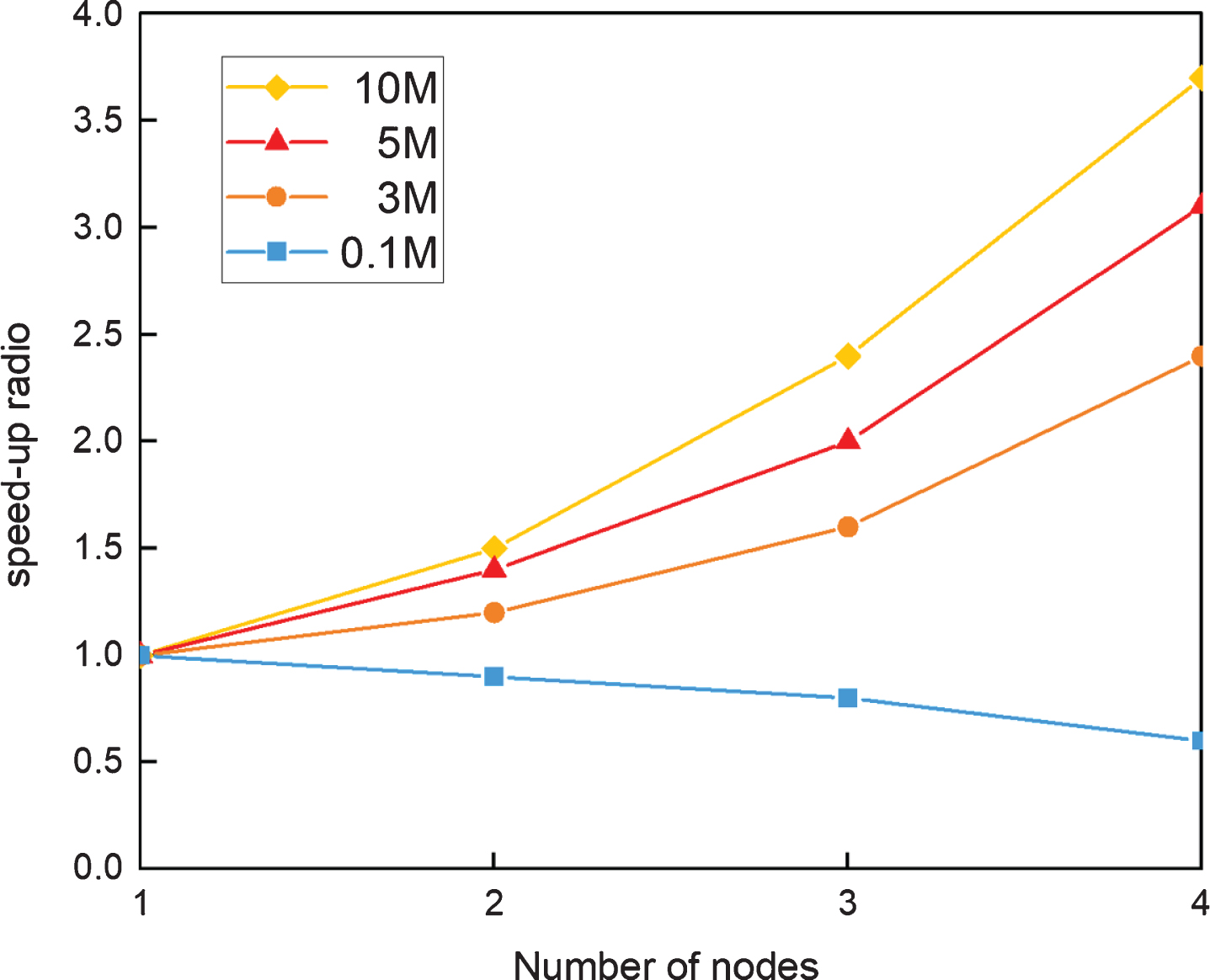
Speed-up ratio.
As shown in Fig. 10, DBWGIE-MR has a big speed-up ratio in processing large datasets. However, when processing the small dataset, the speed-up ratio does not increase but decrease with the increase of nodes. As shown in
The running time is the time taken to get clustering results, which is the shorter, the better. We recorded the running time of the four algorithms on the four subsets of
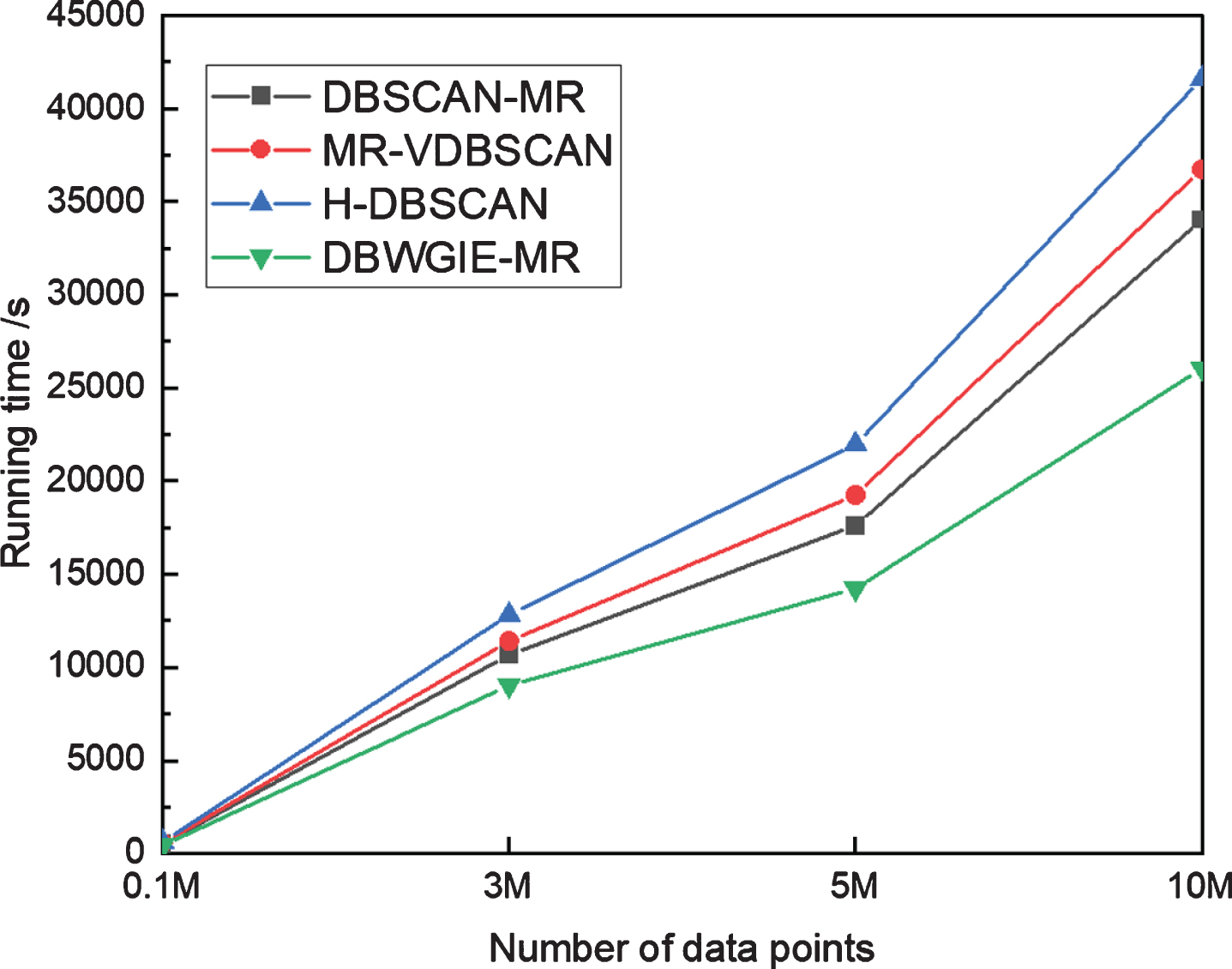
Running time.
As shown in Fig. 11, it is easy to see that the DBWGIE-MR algorithm is more efficient in parallel on large datasets, it takes less time to clustering compared with the other algorithms and the larger the dataset, the clearer is this advantage. When the number of data points is
Clustering algorithms are attractive for the task of class identification in spatial databases. However, the well-known algorithms suffer from severe drawbacks when applied to large spatial databases. In this paper, we design a density-based clustering algorithm using the weighted grid and information entropy based on MapReduce, noted as DBWGIE-MR, to deal with the problems of unreasonable division of data gridding, low accuracy of clustering results and low efficiency of parallelization in big data clustering algorithm based on density. The DBWGIE-MR algorithm consists of three parts: data partitioning, local clustering, and global merging. For each part, we propose several new strategies to improve the algorithm. For data partitioning, we propose an ADG strategy to divide the grid adaptively; For local clustering, we design a NE strategy which can strengthen the relevance between grids to improve the accuracy of clustering, design a WGIE strategy to calculate the density of the grid, and propose an COMCORE-MR algorithm to parallel compute the core clusters; For global merging, we propose an MECORE algorithm to speed up the convergence of merged local clusters, and an MECORE-MR algorithm to get the clustering algorithm results faster. In the experiment, we compared and analyzed with the other algorithms on the four real datasets, the results showed that DBWGIE-MR has significantly improved in accuracy of clustering, running speed, and stability of clustering. Besides, DBWGIE-MR was proved to have a better parallelization effect on large-scale datasets, which also showed that DBWGIE-MR is more efficient than H-DBSCAN, DBSCAN-MR and MR-VDBSCAN. Although the performance of our algorithm is better than other algorithms, this paper does not solve the problem of setting the density threshold of grid and our algorithm cannot identify clusters with different densities, which calls for an improved work in further studies.
Footnotes
Acknowledgments
This study was supported by the National Key Research and Development Program of China (2018YFC1504705) and the National Natural Science Foundation of China (41562019).