
Abstract
Existing fuzzy clustering ensemble approaches do not consider dependability. This causes those methods to be fragile in dealing with unsuitable basic partitions. While many ensemble clustering approaches are recently introduced for improvement of the quality of the partitioning, but lack of a median partition based consensus function that considers more participate reliable clusters, remains unsolved problem. Dealing with the mentioned problem, an innovative weighting fuzzy cluster ensemble framework is proposed according to cluster dependability approximation. For combining the fuzzy clusters, a fuzzy co-association matrix is extracted in a weighted manner out of initial fuzzy clusters according to their dependabilities. The suggested objective function is a constrained nonlinear objective function and we solve it by sparse sequential quadratic programming (SSQP). Experimentations indicate our method can outperform modern clustering ensemble approaches.
Keywords
Introduction
The categorization of the unlabeled data objects into a set of non-predefined collections in such a way that the objects of a group remain as similar to each other as possible and the objects of different groups stay as dissimilar to each other as possible (by minimizing intra-grouping distances simultaneous with maximizing the inter-grouping distances). Clustering can be used in various unsupervised applications such as pattern recognition, image analysis, document retrieval, marketing research, bioinformatics, data mining, and many more multidisciplinary domains.
Generally, these methods are divided into two categories: fuzzy (soft) and hard (crisp) methods. In spite of hard methods, fuzzy methods can assign any object to potentially more than one cluster. They associate a membership degree per each data object-cluster. a membership degree for a data object-cluster indicates the degree to which the data object belongs to the mentioned cluster. This is inspired by the fact that some objects cannot be clustered in a hard manner even by a human. For instance, a satellite image segmentation application can be considered; while a pixel of a satellite image may correspond to a land space, it may belong to different types of lands. Contrarily, a data object certainly belongs to one cluster in hard methods [1]. These methods are considered to be special cases of soft methods. The foundation of the fuzzy clustering analysis is the basic fuzzy c-means (FCM) method that is introduced and completed by Bezdek [2]. Meanwhile, the many soft methods emerged from original FCM in order to adapt it to different datasets with different structures. We can mention Gath-Geva algorithm (GG) [3], kernel-based fuzzy clustering (KFCM) [4], and Gustafson-Kessel algorithm (GK) [5] algorithms as some examples.
Based on different similarity criteria, many methods aroused in data clustering context. Therefore, they turned out to be inherently different. Therefore, applying these methods will produce dissimilar partitions for a given dataset. Even, applying a single method with unlike parameters (or even unlike initializations if the method is unstable) can generate different data partitions for the same dataset. According to “no free lunch”, there is not a dominant algorithm. To sum up, any of them is better under specific conditions. Hence, an alternative solution to deal with many contradictory objective functions can be to combine some of these algorithms. The clustering aggregation or clustering ensemble is the name of this approach [6], which recently has become popular in scientific community [7–14]. It is widely accepted that they can generate more robust, novel, accurate, stable, and innovative results than the simple traditional methods [15]. They can be used in parallel to be scalable. They are able to find out the number of real clusters in a dataset. They are able to cluster the heterogeneous dataset.
Clustering ensemble approaches consist of 2 (usually independent) steps: at the first step, a number of base clusterings are generated, which are as diverse as possible, and at the second step, a module (usually referred to as a consensus function) is applied to them to extract final clustering out of those different base clusterings. The goal of the second phase of the ensemble clustering is to reach the final clustering. This achieved through a consensus function. Since the clustering problem is unsupervised, producing the “final clustering” with maximum similarity to all base clusterings is very difficult and an NP problem [16]. For this purpose, various consensus functions are proposed, each with a specific approach and different information from the base clusterings obtained from phase one, and sometimes by considering the initial characteristics of the data. The current clustering ensemble methods are categorized as: a) intermediate space clustering ensemble methods [10], [17], b) co-association matrix based clustering ensemble methods [6], [18–21], c) hyper-graph based clustering ensemble methods [6, 21] d) expectation maximization clustering ensemble methods [14] and e) mathematical modeling clustering ensemble methods (median partition) [15, 22], f) voting- based approach [23–25], g) Quadratic Mutual Information approach [20]. The fourth category (mathematical modeling clustering ensemble methods) are widely considered to be better than others [26].
While soft clustering methods are widely considered to be better than their counterparts, soft clustering ensembles are not as developed and they are in their early periods. Some current soft clustering ensembles transform soft partitions into hard partitions before any work and after that, extract the consensus partition by application of a traditional hard consensus function. During this conversion much information of basic partitions may be lost. Additionally, most of existing approaches produce crisp final clustering. Consequently, it is safe to say that there is no efficient fuzzy consensus clustering methods.
Any base clustering with low quality highly affects the consensus process in ensemble clustering. The low-quality or even noised basic partitions can badly affect the final partition. Therefore, to handle these type of basic partitions, weighting of basic partitions according to their approximated qualities has been recommended in order to improve the quality of consensus functions [27–29]. However, they assign a weight to each partition, not each cluster [27–29]. But, for obvious reasons, a good cluster may be discovered by a bad partition and be ignored due to its bad weight. Here, we aim at the following targets: (1) considering soft clusters as the base members of our ensemble, (2) defining quality estimator at cluster level, (3) defining cluster weight according to cluster approximated quality, (4) defining a consensus function that, during its process of final partition extraction, participates each soft cluster according its weight, and finally (5) defining a consensus function that generates a
In the median partition based consensus function approach, the problem of consensus partition discovery is formulated into an optimization problem. It searches for a partition that maximizes the average similarity to all partitions in ensemble. Although a great number of clustering ensemble approaches were introduced over the past years, there are relatively few researches in handling fuzzy clustering ensemble based on median partition approach and none of them investigated co-association (Co) ensemble methods simultaneously along with median partition.
We introduce a soft cluster ensemble according to ensemble-driven cluster undependability approximation and cluster-level weighting approach to address the aforementioned challenges. The flowchart of our ensemble structure is depicted by Fig. 1. Considering benefits of the ensemble diversity and fuzzy clustering, we integrate the cluster undependability and validity into our ensemble to enhance the consensus quality. Here, the undependability of each fuzzy cluster is approximated according to its acceptability in relation to a reference set (here whole of the ensemble). Specially, for a given fuzzy cluster, its undependability is approximated by defining a new metric. After that, based on cluster undependability estimation, a Dependability Driven Cluster Indicator (DDCI) can be computed to show any cluster dependability. Here, the point is the fact that a pool of diverse clusters in the ensemble can be used as a guideline to evaluate every single cluster. By assessing and assigning weights to clusters of the ensemble through the DDCI module, weighted Co matrix (WCoM) whose weights are calculated based on dependability are computed. At last, finding the final consensus partition is modeled as an optimization problem, and this problem is solved by sequential quadratic Programming.
Our contribution is to propose a soft cluster ensemble aiming at satisfying the following constraints: (1) considering soft clusters as the base members of our ensemble, (2) defining a consensus function that, during its process of final partition extraction, participates each soft cluster according its weight, and finally (3) defining a consensus function that generates a
Next section is dedicated to the related works. After that, the background will be presented. Our contribution and approach is introduced by Section 4. The experimental study is presented by Section 5. Finally, Section 6 concludes the paper and give guidelines to the future works.
Literature
The researches of Fred and Jain [18] and Strehl and Ghosh [16] are widely considered to be among the initial attempts in clustering ensemble field. In the mentioned researches, aggregators were proposed to extract the final partition out of a pool of base partitions without access to the original dataset features or the base clustering algorithms. Transforming the problem into a constrained optimization objective function, they solved the problem. While a lot of works have been done concerning ensembles of hard clusterings, we only explain those dedicated to soft cluster ensemble, among which the following ones are briefed:
Berikov introduced a probabilistic framework to aggregate the soft cluster ensemble according to the WCoM [30]. He generates each of his basic partitions by applying a different basic soft clusterer. He proposes to compute the variance of the Hellinger distance [31] between any pair of data objects across ensemble. Then, he considers the reverse of this value to be similarity of those two objects in his WCoM. Finaly, he applies a traditional hierarchical clusterer to obtain the consensus partition.
Punera and Ghosh introduced the soft versions of CSPA, MCLA, which had been proposed by Strel and Ghosh [16], and HBGF, which had been proposed by Fred and Brodly [7, 8]. sCSPA, of sMCLA, and sHBGF are the names of the soft mentioned versions [8].
A voting-based consensus clustering is the voting-merging algorithm (VMA) [32]. This is a fuzzy ensemble clustering method that computes the final clustering according to averaging of membership matrices of all basic soft partitions. In this work, all base soft clusters need to be initially relabeled, which is a time-consuming process.
Another related research introduced by Saha et al. is SVMeFC [33]. In this method, some soft clusterers including FCIDE, MoDEFC, GAFC, GAFPSC, and FCM are applied to a given dataset. Some objects of the derived soft partitions are chosen to train a support vector machine (SVM) and the remaining objects of each partition are re-labeled by SVM. At the end of this procedure, to obtained final clusters, CSPA is applied on outputs of SVM. SVMs are very powerful algorithms for data sorting and separating, especially when combined with other methods of machine learning. This procedure best fits the cases where excessive precision is required, as long as we choose mapping functions properly. But it is hugely time-consuming because of high computational complexity of SVMs and also consumes a lot of memory.
Alizadeh et al. converted the soft cluster ensemble problem into a binary bit string problem [34]. They introduced the problem by a constrained non-linear objective function, named fuzzy string objective function (FSOF). Although their output partition is soft, the input basic partitions must be hard.
Sevillano et al. [25] introduced a voting approach to aggregate the base soft clusterings in the ensemble. Their approach has 2 steps: a) relabeling step and b) voting step. In the first step, the relabeling is accomplished by Hungarian algorithm [35, 36] with O (K3) where K is the number clusters. Consensus partition generated by applying sum voting rule or product voting rule [37].
Arlyd and Anna introduced a stable soft cluster ensemble [38] in which a set of basic soft clusterers such as GK, FCM, GG, and KFCM is initially employed to generate ensemble and then use FCM as consensus function to extract final partition out of the CoM of ensemble. There are no weighting mechanisms here.
Szabo and Nunes de Castro [39] offer a method for soft cluster ensemble based on Particle Swarm Optimization (PSO) which can be applied to fuzzy and crisp clusters [39]. Initial clusters in this method are generated using PSO through different parameters. Then a pruning process is accomplished through which a very low fraction of elite partitions are selected. One of internal cluster validity indices like Ball-Hall [40], Calinski-Harabasz [41], Dunn index [42], Silhouette index [43] or Xie-Beni [44] are used to evaluate a partition for selection. Finally, a PSO is employed as consensus function to extract the final partition out of the selected partitions. In this method, each particle represents a cluster, despite the other PSO-based methods which each particle represents a clustering.
Parvin et al. for handling imbalanced clustering proposed a weighted locally adaptive clustering algorithm (FWLAC). Because the performance of FWLAC algorithm is dependent on well-tuning of its two parameters, they proposed an elite soft cluster ensemble. Their proposed procedure first converts soft clusters into crisp clusters and considers each cluster to be a clustering; finally clustering normalized mutual information (NMI) was employed for assessment of each cluster [45].
Background
Before explaining this proposed approach, the general formulation of the data, fuzzy clustering ensemble and entropy definitions should be introduced as follows:
To sum up, the set of all clusters in the ensemble is presented as
Three fuzzy clustering π1, π2 and π3
The ensemble E of three fuzzy clusterings π1, π2 and π3
If and only if these X and Y are independent, then H (X, Y) = H (X) + H (Y) holds. Thus, given n independent random variables X1 ; … ; X
n
, the following term is valid:
In this paper, a new fuzzy clustering ensemble approach based on ensemble-driven cluster undependability estimation and local weighting strategy is proposed. The steps of the proposed approach are shown in Fig. 1 (after green boxes). In the first step, the acceptability of each cluster is computed. In the second step, the undependability of each cluster is approximated in Section (4.2), in the third step, the cluster weight computation is done in Section (4.3). In the fourth step the fuzzy weighted co-association matrix is computed in Section (4.4) and in step 5, the consensus clustering is obtained as described in Section (4.5).
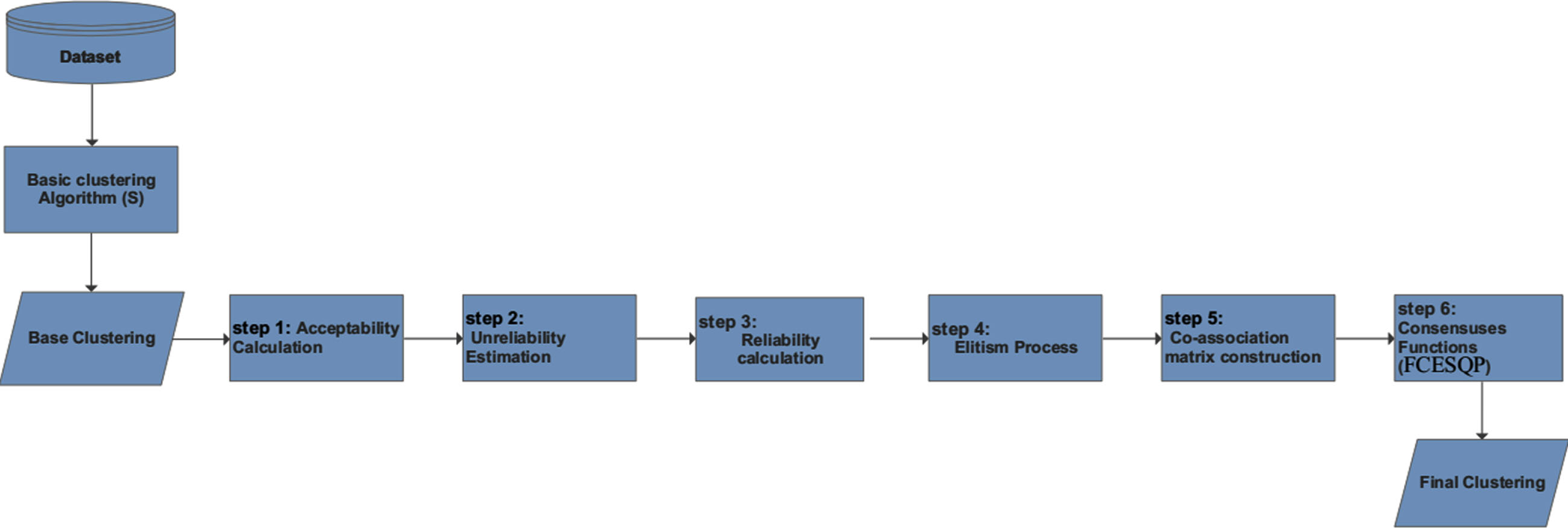
Proposed approach steps.
The first step in Fig. 1 is to compute the acceptability of each cluster in relation to other clusters within different clusterings; i.e. the probability of agreement between two clusters in different clusterings which is obtained according to Definition 7. We measure the cluster acceptability by employing the ‘Similarity between fuzzy sets’ that proposed by Zheng [46], which measures the agreement relationship between two fuzzy sets.
The value of the cluster acceptability (Accp) computed from (10) is in the range [0, 1].
The values of Accp corresponding to fuzzy clusterings presented in Tables 1–3
Because we assume that there is not knowledge about the original data object features, the concept of entropy applying the data object membership degree to the cluster in the entire ensemble is applied for evaluating the Dependability of each cluster. The second step in Fig. 1 is estimating the undependability of clusters based on an entropic criterion in the ensemble. It is obtained without the knowledge of the original data features or making any assumptions on data distribution. Entropy is a measure of cluster undependability associated with a random variable where every cluster consists of a set of data objects. Given a cluster
The values of Accpn corresponding to the Accp values presented in Table 3
The values of UnR corresponding to Accpn values presented in Table 4
We assume that basic partitions of ensemble are mutually independent [47]. So, according to Equation (9) the undependability of C i with respect to the ensemble Π can be obtained by summing up the undependability of C i with respect to the β basic partitions in Π is computed based on Equation (13).
The values of UnR Π corresponding to UnR values presented in Table 5
Third step in Fig. 1 is dedicated to computation of dependabilities of all clusters of the ensemble. Dependability of any cluster can be obtained according to its undependability estimated based on the whole ensemble through a dependability driven cluster indicator (DDCI) after obtaining undependability of each cluster in the ensemble.
Due to UnR Π (C i ) ∈ [0,+ ∞), it holds that DDCI(Ci) ∈ (0, 1] is met for any C i ∈ Π. It is obvious that as the undependability of a cluster C i is minimized (UnR Π (Ci)=0), its DDCI is maximized (DDCI (C i )=1). Additionally, it is obvious that DDCI(C i ) is the Dependability of cluster Ci.
The values of DDCI corresponding to UnR values in Table 6
As can be seen in Fig. 1, the fourth step is computing co-association matrix with regard to the Dependability of each cluster in the ensemble. One of the most common methods used to combine the base clusterings is the co-association matrix-based method. Evidence Accumulation Clustering (EAC), which was first proposed by Fred and Jain [18]. EAC maps the individual data object clusterings in a clustering ensemble into a new pairwise similarity measure.
Unlike in the general crisp evidence accumulation method, because a sample does not belong to any basic soft cluster absolutely, we cannot obtain values of CoM entries by counting how many times a pair of instances are assigned in a shard cluster. In soft clustering, any instance belongs to each cluster with a membership degree. Therefore, we should find a way to evaluate the strength of association between data objects.
As was mentioned in Definition 10, co-association matrix reflects the strength of association between data objects. In order to take the Dependability of each cluster into account in the co-association matrix, DDCI would be considered as a multiplier term (weight) in co-association matrix computation, leading to computation of the weighted fuzzy co-association matrix according to Definition 11.
According to Definition 12,
Substituting the values in the above equation we have,
In a similar way, the other entries of WFCo matrix can be obtained (see Table 8).
The WFCo matrix of fuzzy clustering ensemble presented in Table 1
The final step in Fig. 1 is compute final clustering (consensus clustering). The process of extracting final clustering from the co-association matrix using the EAFC method (Definition 11) is named consensus function. To obtain consensus function at the first we define the objective function to drive final clustering in Section 4.5.1, then we explain its solution in Section 4.5.2.
Objective function
A consensus function is used to derive the final fuzzy clustering π* from Π by solving the Equation (18). Then at first we formalize the problem of finding the final fuzzy clustering π* from the cluster ensemble Π as objective function. Objective function must take into account both fuzzy cluster diversity and fuzzy cluster Dependability of ensemble E summarized in fuzzy co-association clustering ensemble matrix (WFCo). We try to find final fuzzy clustering π* that its co-association matrix is approximately equals to WFCo. According to Equation (16), the co-association of π* is π* × π*′. Hence we try to minimize the square error between WFCo and co-association matrix of π* (minimize the sum of difference square between the final clustering and co-association matrix), as formalize in Equation (18-1). Also π* is fuzzy clustering, each element must be satisfy the constraint (18-2). Additionally because sum of membership of a data object to all clusters in π* must equals to 1 the constraint (18-3) was added to Equation (18). This objective function is defined as Equation (18).
Subject to:
The proposed solver named the FCESQP (Fuzzy Clustering Ensemble by Sequential Quadratic Programming) is introduced in this section. AS mentioned in the previous section, the cluster ensemble is formulated as an optimization problem.
The optimization problem goal is to minimize the soft clustering ensemble objective function. This indirectly results in a clustering where the dependability between basic soft clusters are maximized. To solve the proposed model, any non-linear optimization solver can be applied. Sequential quadratic programming (SQP) method have proved highly effective for solving constrained optimization problems with smooth non-linear functions in the objective and constraints [48, 49]. The objective function is nonlinear with linear constraints. Because the coefficient matrix of constraints is spare, the sparse SQP (SSQP) is applied for solving our optimization problem.
The SSQP algorithm is fully described by Gill, Murray and Saunders [50]. It employs a sparse sequential quadratic programming (SQP) algorithm with limited-memory quasi-Newton approximations to the Hessian of the Lagrangian. It is especially effective for nonlinear problems with functions and gradients that are expensive to evaluate. The functions should be smooth but need not be convex. SSQP is suitable for large-scale for general nonlinear programs of the form
At the first, the transformation of matrix π* into the vector x (containing M × K scalar variables) according to (Equation (20)) is necessary.
After this transformation M × 1 vector x l is set to zero, M × 1 vector x h is set to one, the a M × 1 vector is set to one and the (M) × (M × k) sparse matrix A is defined according to (Eq.(21))
The structurer of final clustering corresponds to base clustering in Table 1
Coefficient matrix A related to example 5
As the proposed algorithm is based on the SQP approach, we provide here a short synopsis of that method. Because the objective function (19) (f0 (x)) is nonlinear, we approximate it to quadratic form with consider 3 first term of Taylor series as Equation (22).
Equation (23) is in the form of quadratic and we can solve it by using a sequence of quadratic programming (QP) sub-problems in each iteration. Since the objective function (i.e. equation 18) consists of equality and inequality constraints, the active-set method of QP is used to solve it as follows:
Start from an arbitrary point x0, then find the next iteration value by setting xk+1 = x k +p k d k , where p k is step-length and d k is search direction at iteration k.
At the current iteration x
k
determine the index set of active the inequality constraints:
Then, we find the direction (d) value by solving Equation (25).
If we expand the Equation (25), and simplify these expressions and drop constants to Equation (26) is obtained.
To obtain the search direction d
k
, solve the Equation (27):
The Karush–Kuhn–Tucker (KKT) optimality conditions [35] lead to the Equation (28):
If d
k
is a solution of QP, then there are λ
k
and
There are two cases: either d k =0 or d k ≠ 0.
Case 1: d
k
=0. the Equation (29) above reduces to Equation (30).
Case 1-a: if
Case 1-b: If some components of
Then the obtained direction is descent direction d k for (QP).
Case 2: (d k ≠ 0): Determine a step-length p k that guarantees x k +p k d k is feasible to QP.
A common p
k
that guarantees the satisfaction of all constraints is
If p
k
<1, then p=
The SQP algorithm is summarized in the Algorithm 1.
The approximate Hessian Matrix Q is updated from iteration to iteration using one of the variable metric updating formulas [51]. Because the matrix of coefficient constraints in our objective function (Equation (20)) is sparse, SQP algorithm must exploits sparsity in the constraint Jacobian and maintains a limited-memory quasi-Newton approximation H k to the Hessian of the Lagrangian [52].
It is worth mentioning that the vector X is transformed to the M × K matrix π* by Equation (33)
To obtain consensus clustering from base clusterings Π according to the local Dependability of each cluster in the ensemble, it is necessary to compute each cluster’s Dependability in the ensemble according to Equation (14). For this purpose, the entropy of each cluster in Π needs to be computed according to Equation (13). To do this, we should compute the undependability of each cluster with respect to clustering π m in ensemble Π, according to Equation (11). For this computation, computing the acceptability of the clusters in ensemble Π according to Equation (10) is necessary. After computing the DDCI, the weighted fuzzy co-association clustering ensemble matrix (WFCo) is obtained according to Equation (17). Then based on WFCo the objective function (Equation (18)) is constructed. Finally, by applying the Consensus_clustering_SQP algorithm as solver over the Equation (18) the final clustering is obtained.
This algorithm is named FCESQP (Fuzzy Clustering Ensemble by SQP) is presented in Algorithm 2 with details. In this algorithm Π is the base clustering ensemble and k is the number of clusters in the final clustering.
Experimental study
Benchmark and evaluation criteria
To evaluate the robustness and quality of the proposed fuzzy clustering ensemble approach, twelve data sets are selected from UCI Machine Learning Data Sets [52], the “Galaxy” dataset described in [53] and a well-known dataset HalfRing as the experimental datasets. The description of these datasets is shown in Table 9.
Two evaluation criteria NMI and Dunn are applied here to assess the quality of clustering.
NMI is normalized mutual information between two clusterings [16], and for two clusterings π1 and π2 is calculated as
The Dunn Index [42] is defined as
To evaluate the consensus quality over various ensembles, base clusterings are constructed through the FCM and K-means clustering algorithms. In order to construct diverse base clusterings, the FCM and K-means are run with different numbers of cluster. The number of clusters for them is randomly chosen from the
The ensemble size for performance evaluation of the methods was assumed as β = 10. Base on empirical results, the best result is obtained when parameter ∅=0.4. To rule out the occasional luck factor and provide a fair comparison, this proposed approach, the state-of-the-art fuzzy clustering ensemble methods were assessed by their quality criteria and AC robustness average over numerous runs (40 runs).
The experimentations have been conducted on a Matlab14a-64.
Comparison with state of the art
The proposed SQP approach were compared with eight clustering ensemble methods, i.e. WEAC [27], GPMGLA [27], SVC [25], PVC [25], BVC [25], ISC [25], Berikov [30] and FSCEOGA1 [34]. The two quality-evaluating criteria, NMI and Dunn were applied to determine the quality of the final clustering resulted from the proposed methods and the baseline methods. The number of clusters in each dataset is the same as the number of pre-defined classes (ground truth) in each dataset.
For comparison purposes, each of the proposed methods and the baseline methods are executed 40 times. The average values of NMI and Dunn criteria of different methods over 40 runs are shown in Tables 12 and 13 respectively. The value in bold in the rows represents the best quality-term of each dataset yield by all the examined algorithms. The last row shows the average quality-term for each algorithm over all the datasets. Because the FSCEOGA1 is computationally expensive, these methods cannot handle large datasets because of large execution time. For this reason, the quality results of FSCEOGA1 method are missing on the Vehicle dataset. Therefore, the quality of FSCEOGA1 the Vehicle dataset denoted as a dash.
The NMI resulted from different algorithms
The NMI resulted from different algorithms
The Dunn index resulted from different algorithms
According to Table 12, FCESQP outperforms other algorithms on ten datasets, while WEAC and ISC outperform other algorithms only in one dataset. It is 2 times that the FCESQP algorithm obtains the third best results. We can see that FCESQP algorithm achieves the best average NMI with the value of 0.3744.
To ensure the results do not happen by chance, and to assess quality of the proposed method running statistical analysis is a must. The Friedman test [54] is applied here to the results of Table 12, subject to null hypothesis, where the mean ranks are equal for all the examined algorithms. The significant level is set to 0.05. The experimental results, subject to Friedman test in Table 12 is shown in Fig. 2. As observed in Fig. 2 and the null hypothesis that the mean rank of the NMI being equal in all algorithms is rejected, because p-value is 7.779E-7, indicating that there exists significant difference. As observed in the mean ranks, FCESQP has the highest NMI score followed by WEAC and then SVC.
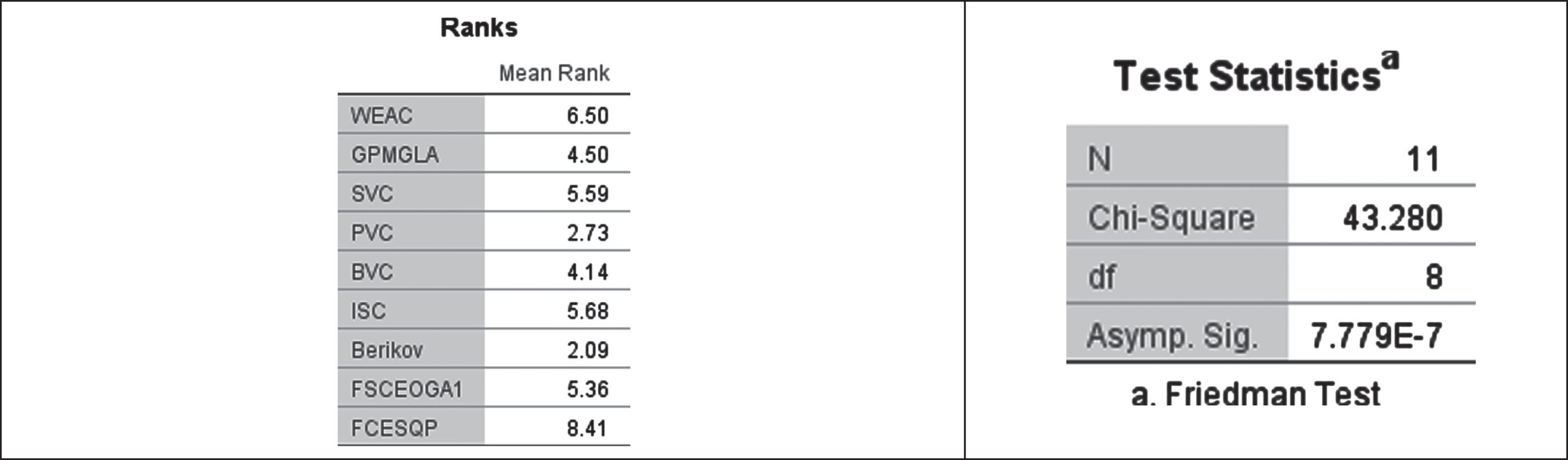
Friedman test result of Table 12.
According to Table 13, it is obvious FCESQP outperforms other algorithms on nine datasets, while WEAC outperforms other algorithms on two datasets. PVC outperforms other algorithms on dataset Glass. With respect to last row (average values on all datasets) it is obvious that FCESQP algorithm achieves the best average Dunn index with the value of 1.90, WEAC has the second score and FSCEOGA1 has the third score.
The experimental results, subject to Friedman test in Table 13 is shown in Fig. 3. As observed in Fig. 3 and the null hypothesis that the mean rank of the NMI being equal in all algorithms is rejected, because p-value is 3.705E-8, indicating that there exists significant difference. As observed in the mean ranks, FCESQP has the highest Dunn score followed by WEAC and then FSCEOGA1.

Friedman test result of Table 13.
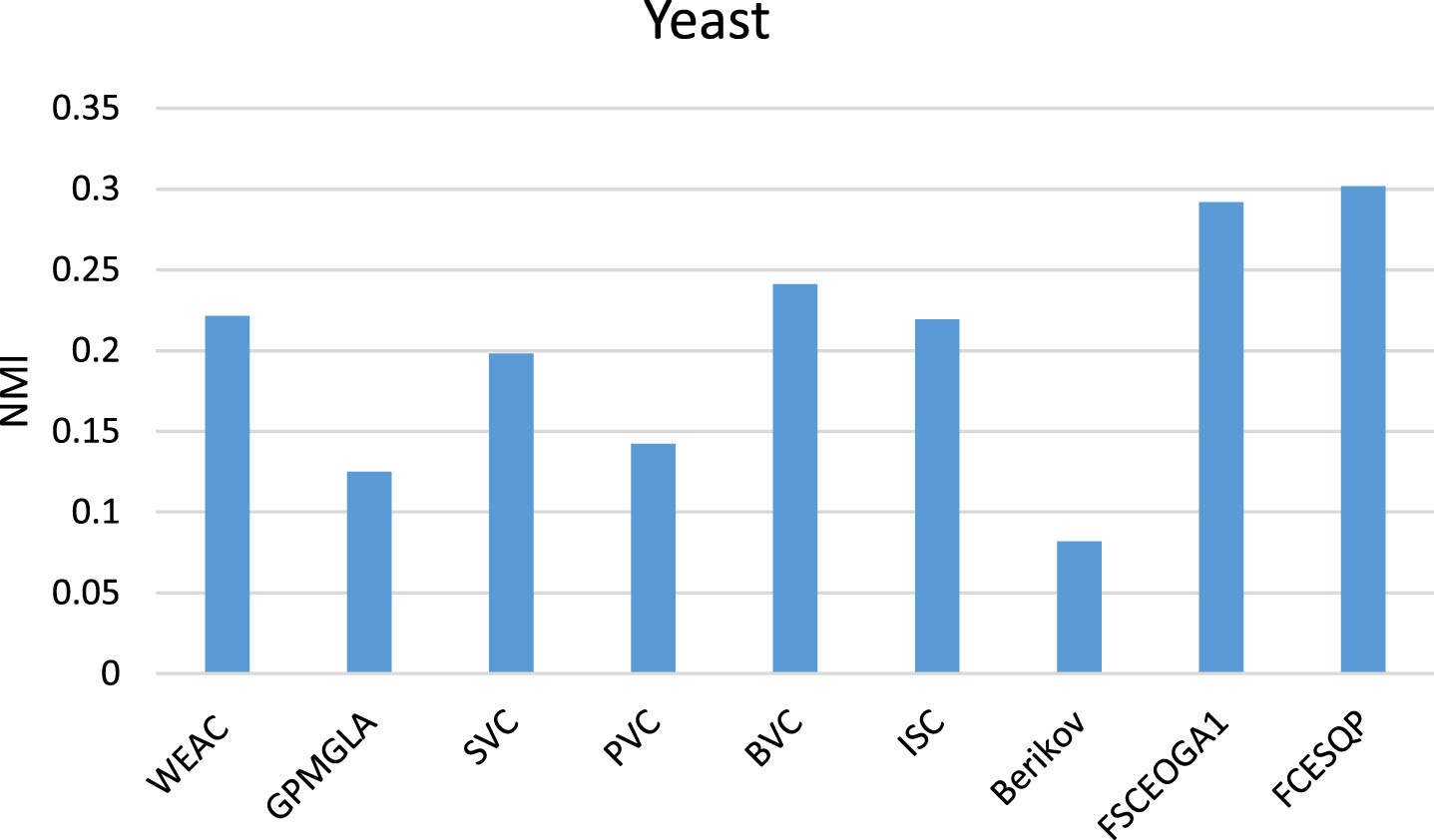
The results of different methods on Yeast dataset.
As the datasets shown in Table 11 are all small, we try a slightly large dataset to show the effectiveness of the proposed method in these conditions. The dataset Yeast with 1484 instances and 8 attributes and 10 classes. The proposed method still outperforms the other methods in terms of NMI.
Description of the datasets
In this paper, a novel fuzzy cluster ensemble approach based on estimation of fuzzy cluster undependability has been proposed. The uncertainty of a fuzzy cluster against a clustering is approximated using an entropic criterion. Then a new Dependability driven cluster indicator termed DDCI based on cluster undependability and local weighting strategy has been introduced. The DDCI measure does not depend on the original data features and has no presumption on data distribution. A local weighting scheme to promote the conventional co-association matrix through the DDCI weigh has been also introduced named WFCo. Instead of participating all clusters in the co-association matrix equally, in this approach each cluster participates in the co-association matrix with respect to its Dependability in the ensemble. In order to extraction final clustering from matrix WFCo a constrained nonlinear optimization problem was formed. We solve this problem by sparse sequential quadratic programming. The experimental results over twelve datasets confirm the quality improve in comparison with other fuzzy cluster ensemble methods.
Propose a parallel solution which obtain the final clustering by the solution of the optimization problem can be considered as in a future work. Solving this nonlinear optimization problem by other methods can be discussed as a future work of this paper. Apply this approach in some real-world applications (specially engineering application) will also be carried out.