
Abstract
The evolution of technology has brought new challenges and opportunities for the different dimensions of feature space. The higher dimension of the feature space is one of the most critical issues in e-mail classification problems due to accuracy considerations. The problem of finding the subset features that significantly influence the performance of e-mail spam classification has become one of the important challenges. This paper proposes to overcome such a problem, an intelligent approach to Binary Differential Evolution Support Vector Machine (BDE-SVM). The proposed approach enhances the Binary Differential Evolution (BDE) algorithm based on the correlation coefficient as a fitness function to select the significant subset feature evaluated by an SVM classifier. To our best of knowledge, the correlation coefficient as the fitness function has not been used in the differential evolution algorithm before. The selected subset feature is used to assess the most features that contribute to the reliability of the email spam classification. The finding of the enhanced BDE is to present a powerful accuracy. The tests were conducted using “Spambase” and “SpamAssassin.” Identified benchmark datasets are to assess the feasibility of the proposed solution. The result with full-feature accuracy was 93.55 percent compared to the proposed BDE-SVM approach, which is 93.99 percent. Empirical findings also show that our method is capable of effectively increasing the number of features required to enhance the reliability of the email spam classification.
Keywords
Introduction
Since e-mails are widely used as a platform for sharing information, most problems arise due to unwanted and unsolicited large e-mail messages known as spam e-mails [1,2, 1,2]. While problem scales continue to increase with the rapid growth of e-mail users worldwide, meaningful work in the identification of e-mail spam is needed to improve classification reliability [3]. e-mail spam classification is a supervised learning issue, and classification is critical to solving the spam problem. The high dimension of the feature space is a significant issue that can affect email spam classification [4, 5]. Furthermore, a reduction in the size of the data by removing the irrelevant features leads to a reduction in the hypotheses space’s size, allowing algorithms to run better and more efficiently [6]. On the other hand, feature selection (FS) techniques are essential in reducing the feature space’s size when a subset of features has been selected from the full original features [7]. Using FS is to reduce the size of the feature space by eliminating unnecessary and irrelevant features [8]. Typically, the feature selection algorithms’ performance is assessed by comparing the performance of the classification algorithms before and after the selection of the subset features. A search algorithm is also required to exploit space features such as binary differential evolution (BDE). In this paper, the suggested method (BDE-SVM) using enhanced BDE with correlation coefficients as the fitness function for the selection of features and the SVM classifier is tested. This is to improve the classification of e-mail spam by reducing the size of the spam. The proposed DE-SVM approach is designed in term of reducing the high dimension of the feature space and increase the quality of accuracy for e-mail spam classification based on the SVM algorithm. One of the contributions of this work, to our best knowledge, the correlation coefficient as a fitness function has not been used in the DE algorithm, and then the combination is used as a feature selection approach. In addition, a comparative study is carried out among our proposed method and the many common approaches such as the support vector machine (SVM), the particle swarm intelligence (PSO) and the genetic algorithm (GA). The experimental results show that the use of BDE with coefficient of correlation as a fitness function for the selection of features and SVM as a classifier has higher classification accuracy compared to the use of SVM only as a classifier. This paper is organized into seven sections: section 1 introduced the subject, section 2 discusses the related work, the proposed improved solution and its structure is discussed in section 3, the proposed Differential Evolution (DE) with a Correlation Coefficient was introduced, the implementation, results and discussion of the proposed method is discussed in section 4, section 5 discusses the experimental results, section 6 compares our results with other methods with in-depth discussions, and the conclusions and recommendations are presented in section 7.
Related work
This section presents the previous studies related to supervised machine learning techniques to extract features from an email. Various security applications, such as email anti-spam, may be offered as cloud services. Many intelligent solutions have already been created to reduce the miss classification percentages of the e-mail classifier [9]. They can protect either the virtual infrastructure or the customer’s physical infrastructure and are designed as transparent services using the overlay network or as well-known endpoint services. The internet is an essential part of today’s life, and we spend much of our time on the internet. e-mail is a well-established technology used worldwide in many fields of education and industry for enterprise and private communication through the internet [10]. Email features along with other features are used in numerous research studies for spam email detection [11, 12]. For classification of spam email, a number of machine learning-based methods, such as content-based supervised learning, rule-based learning, semi-supervised learning and unsupervised learning, have been proposed [11]. This is in terms of the low cost of transmission, the quick delivery of a message, and the enhancement of efficient communication [13, 14]. Researchers examined different methods and technologies for improving accurate spam classification and filtering systems [15, 16]. Fortunately, different methods make it possible to automatically detect or classify and remove many of these spam emails, and one of the best-known classifier techniques for binary classification is the SVM algorithm [17, 18]. Email spam classification is a supervised learning problem, and classification is an essential method of eliminating spam e-mails [19]. Recent research shows that e-mail classification is usually based on statistical theory and machine learning (ML) algorithms to distinguish between non-spam e-mail and spam e-mail [20, 21]. Classification issues have been extensively studied in Machine Learning (ML), data mining, and information retrieval with a variety of domains, such as e-mail spam classification [22, 23]. ML is considered to be a branch of artificial intelligence methods and is concerned with the improvement of techniques and methods that allow the computer to learn [24]. ML methods can extract knowledge from a group of e-mails provided [9, 25]. The goal of ML is to improve the effectiveness of the e-mail classifier through experience in creating better decisions and solving problems in an intelligent way through the use of illustrative data [9, 26]. Therefore, Fixing the problem of a high dimension of feature space is one of the most important things in the identification of e-mail spam. Despite many methods of related work, the selection of features is still an emerging area of research [27]. Then, many researchers are looking for new methods to select subset features, enhance classification accuracy, and decreasing execution time [1]. Furthermore, e-mail spam detection is becoming very important when dealing with high-dimensional data [28]. Then, the main problem with the classification of e-mail spam is the high dimension of feature space [29]. One of the fundamental reasons for the selection of features is to solve the high dimensional feature space (curse dimensional) problem. Another motivation for selecting features is to identify unimportant or redundant features and select an optimum subset of features that minimizes the predictive error of the classifiers [30]. In order to address the problem of e-mail spam classification, several scientists have worked to improve the accuracy of classification by decreasing features or eliminating irrelevant and redundant features or by selecting the appropriate features [1, 20]. Several search techniques applied to the selection of features; most of them usually suffer from local enhancement and/or high computational complexity problems. Therefore, a computationally cheap global search technique is required to create a good feature selection algorithm [31]. The Differential Evolution (DE) is a masses-based algorithm that can be seen as like Genetic Algorithm (GA) since it uses operators such as: crossover, mutation and selection [32].
The proposed improved solution and its structure
Advanced solutions have had considerable success in several real-world complex issues solving in modern times. The value of an integrated system is not negotiable, depending on the weakness of the individual system, and the enhanced system is designed to balance the deficiency of these individual intelligent systems. After extracting the email features set, an optimization method based on DE that uses these features to identify the centroids for classification of email spam is proposed. According to the email spam problem, the formulation of the objective function requires maximizing the accuracy that means the number of messages that are correctly detected as SMS spam (TP) and the number of messages are correctly classified as not spam (TN) should be maximized. In this paper, the Binary Differential Evolution (BDE) algorithm was proposed as a feature subset selection to select subset features while at the same time increasing the accuracy of the e-mail spam classification based on the SVM learning algorithm. The binary differential evolution (BDE-SVM) approach consists of two sub-approaches: the binary differential evolution (BDE) approach based on the correlation coefficient as a fitness function for feature selection and the SVM algorithm for e-mail spam classification. The term “Binary” refers to the chromosome configuration that should be modulating into binary dimension space. Each sub approach in the BDE-SVM approaches acts as a separate approach and runs independently from the others. The BDE is trained to select the optimal (or near-optimal) subset features. The outputs of the BDE are then directly applied to the second approach using the SVM learning algorithm as an e-mail spam classifier. The BDE-SVM methodology was designed to test the outcome of a trained method. Due to the high number of specimens associated with the datasets, the dataset was split into 70 percent for learning and 30 percent for research. Figure 1 shows the general phase of our suggested approach.

Framework of our approach.
Evolutionary Computations (ECs) are a type of optimization methodology based on the processes of evolution and behavior of living organisms. In literature, evolutionary algorithms (EAs) are often treated in the same way as ECs. Evolutionary saves sufficient data on functionality, storage space, and population information during the iterative search process. Intelligence algorithms are known as EAs or ECs algorithms. ML is a data-driven learner, aiming to achieve higher accuracy in predictions, and can be used for knowledge extraction [31]. ML techniques can be combined with different EC algorithms in a variety of ways, and they also impact ECs in a variety of ways. Accordingly, ML techniques can help the ECs algorithms search more effectively and efficiently and are employed for analyzing and evaluating data to improve EAs search efficiency as opposed to classical versions. In addition, improvement of population initialization for ECs by ML techniques is found to have played an important role in the literature. In addition, ML was introduced for ECs to enhance fitness evaluation and selection. Furthermore, ML can use for population reproduction and variation. The author can refer to the recent survey presented by [33] for more information about using ML in ECs. In this study, the SVM is used as classifiers; while the BDE technique is used to pick the optimum subset features, it is used in terms of the high performance achieved. Differential Evolution (DE) is one of the EAs that can be used to select the optimum subset features and can increase efficiency to improve classification accuracy. DE is used as a search technique due to its rapid convergence rate compared to other approaches. The control parameters of the DE are: F = rand (0,2), which is called the mutation-scaling factor, and CR = rand (0,1) is called the crossover constant, both of which are chosen by the practitioner along with the population size (NP) ≥4 (must be at least 4). The choice of DE control parameters F, CR, and NP can have a major impact on performance optimization. The large value of the F parameter leads to a higher diversity of population generation, while the lower value causes faster convergence [4]. The fitness function, evaluating the performance of each chromosome, must be designed before the optimal value searches begin. Therefore, we must use heuristic methods to search for a subset of space in a reasonable time. In this article, we use the correlation coefficient as a new fitness method to achieve the best chromosome that helps to choose a subset variable. The values of F=0.5, CR=0.9, and population size (NP)=100 would also be used for this article. In addition, the different number of iterations and the different number of runs will be used to produce different results. More details of the parameter value are illustrated in Table 1 [34, 35]. Individuals are assessed on a generation-by-generation basis to determine their performance, and the best participant is selected to track evolutionary progress. The DE process steps are as follows:
IDE control parameter values
IDE control parameter values
A society of generation G (denoted by Xi,G) comprises a collection of d-dimensional vector parameters where each society vector corresponds to a potential solution to the problem (target vector). Initially, all individuals are randomly generated by the uniform probability distribution. Think we would like to optimize the function and choose the size of the population (number of vectors in the population) NP. The parameter vectors have the form:
Xi,G where i = 1, 2, . . . NP, and G is the generation number.
Identify an appropriate population of target vectors. Each goal vector includes different design parameters. The lower and upper limits are defined for each parameter
Mutation
There are five different learning methods in DE that can be used as mutations. We will adopt the DE / Rand/1/bin formula, which is widely used in many DE literature, and generally, this equation gives better diversity [36]. During the mutation point, the DE algorithm generates new vectors by applying the weighted difference between the two vectors to the third vector. For each target vector Xi,G where i = 1, 2, . . . NP, the G + 1 generation mutant vector (denoted by, Vi,G+1) is generated as follows.
Where r1, r2, r3 are random indices r1, r2, r3 ∈ 1, 2, . . . NP; r1 ≠ r2 ≠ r3 ≠ i and F ∈ [0, 2] is a scale factor that controls the amplification of the differential variation Xr2,G - Xr3,G.
Researches apply in the area of modifications to enhance the equation of mutation to obtain the best member of the population; this may lead to a faster convergence and performance improvement. Therefore, the main aim of the mutation operator is to present some diversity in the population, to extend the effective area of the search space that the algorithm considers.
Crossover
DE uses a uniform convergence technique to increase the diversity of disrupted vector parameters. The trial vector Ui,G+1 is developed from the elements of the mutant vector Vi,G+1 and the target vector Xi,G.
Ui,G+1 = (U1i,G+1, U2i,G+1, . . . , UDi,G+1)
Where:
j = 1, 2, . . . , D
From above, rand (j) is the j th evaluation of a uniform random number generator with the outcome of rand (j) ∈ [0, 1]. CR is crossover probability CR ∈ [0, 1]. Crossover probability controls the fraction of parameter values that are copied from the mutant vector. A randomly chosen index rn (I) ∈ (1, 2, . . . , D) which ensures that Ui,G+1 gets at least one parameter from Vi,G+1. Therefore, the main goal of the crossover is to increase diversity in the population.
Selection
In selection operation, the trial vector at generation G + 1 (Ui,G+1) is compared to the target vector at generation G (Xi,G). If the trial vector at generation G + 1 (Ui,G+1) produces more cost value than the target vector at generation G (Xi,G), then the trial vector replaces the target vector in the next generation (generation G + 1) for a maximization problem. Otherwise, the old value Xi,G is retain and Xi,G+1 is determined as follows:
Where f (.) denotes the objective function of the given vector.
Due to the large number of samples associated with the two datasets used for this analysis, the dataset was split into 70 percent for learning and 30 percent for testing during experiments. Since the acceptable size of the most reliable feature subset is unclear, the suggested method has been used for different feature set sizes. The method is used for the twentieth run when searching for each subset size function. The fitness function is an important measurement step in evolutionary computations (ECs) techniques. The use of the objective function is to decide which individuals are fit to get an optimum solution. These techniques use these functions to determine which chromosome achieves the best solution and is considered to be the most appropriate. Each chromosome has the chance to run again (survive) at the next generation of a new population, and the correlation coefficient function as a fitness factor has been used for each chromosome. Then, each chromosome (individuals) has its own fitness, and the top chromosomes with lower objective function value mean that the chromosome is very important for problem-solving. The contribution of this paper is the use of correlation coefficient functions as a fitness function of the BDE algorithm to select the sub-set features and to help the SVM learning algorithm as a classifier to increase the accuracy. We have improved the traditional DE algorithm from its classical form to enhance its convergence characteristics. In contrast, we used a representation method for search variables to evaluate the near-optimal number of features. The first step is using a correlation coefficient (r) as a fitness function of BDE:
Where x
i
features are values and y
i
are the target value (output value),
From the above equation FS i refers to the corresponding binary of the real value gene |x i |, rand () is a function that generates a real random number between 0 and 1, and - (|x i |) is an exponential value of the correspondent gene |x i |. If rand () is greater or equal to exp (- |x i | then FS i = 1 else FS i = 0.
On the other hand, after transforming the value of gene |x i |, using the modulation into binary code and if the value of FS i = 1, then the corresponding feature is selected as an optimal feature. Otherwise, if the bit contains 0 then the corresponding feature is not selected and is not considered as an optimal feature. In the chromosome structure, the first bit refers to the first feature, while the second bit refers to the second feature, and so on. Figure 2 explains the feature representation (chromosome structure).
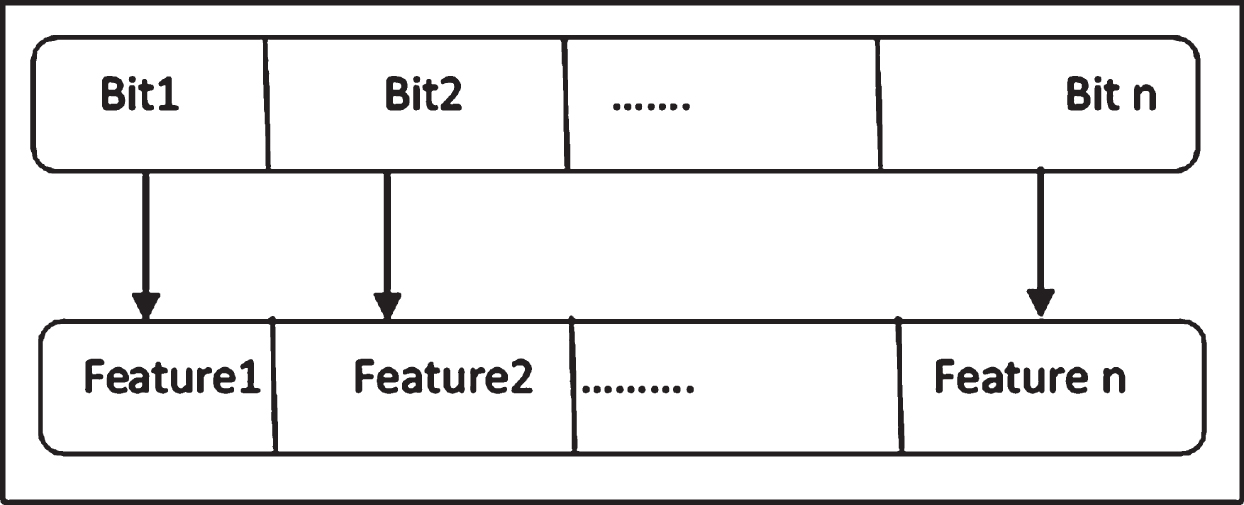
Chromosome structure-feature positions.
A chromosome is a series of genes, and their values are controlled through binaries probability appearance. So all probable solutions will not exceed the limit of 2 n where two refers to binary status [0, 1] and n is the number of features. Within this limited search space, the DE covers all these expected solutions and assigns fitness to each chromosome. Feature selection is performed by selecting relevant features whose scaling factor is one and eliminating irrelevant and redundant features whose scaling factor is zero. Therefore, to extract important features, the DE works at different levels: the iteration level and the run level. Each run level contains a specific number of iterations; for example, in our case, we set iteration = 1000 and run = 20. Then, on every single run, the DE starts to find out the best solution among all the iterations that are represented in binary form. The fitness function is used to decide the best chromosome. Then, our system increases the run by one until the last predefined number of runs. In the end, we will obtain a binary array of n runs. Summing up all these binary values in normal ways will result in extracting the importance of the features.
For better understanding, observe the depiction of a chromosome shown in Fig. 3. Each genome is expected to hold a value between (0, 1), and the example of a chromosome is shown in Fig. 3. It may be considered a difficult task to assign a fitness value to the chromosome in its current format; refer to “Row 1” in Fig. 3. From this point of view, a “modulation layer” is needed to generate the corresponding chromosome. Initial values of Row 1 are real values such as [0.73, 0.92 . . .0.44]. However, these values in their current format and random value are not useful. They are then modulated into a binary string to control feature de/activation as shown at “Row 2” [0, 1 . . .1]. This modulation tells the system to generate a classification only based on the active features and ignores the inactive features. A binary modulation formula is used to modulate the genome’s real value into binary values that were proposed by [38], as shown above.

Chromosome value modulations.
Our experiments looked at the amount of classified e-mail spam before entering the Inbox mails. Our approach was tested according to the group of subset features, and we select the best group obtained and compare it with others. The features were divided into nine groups, and each group had a certain number of e-mails and featured improved for each category with each comparison of tests. We started with three optimal (near-optimal) features in the first group. Then, we added 2 more optimal (or near-optimal) features to the first group and 3, 5, 10, 15, 20,25,30,35, and 57 or 88 respectively. The features are organized in descending order for ease of comparison. Each feature value tells its importance and effect on the e-mail. The purpose of this grouping method is to research the accuracy of the e-mail according to the optimal (near-optimal) features selected and to cancel redundant and irrelevant features. Optimal (near-optimal) features are selected in order to enter the second test comparison phase. On the other hand, we ignored the features that are redundant and irrelevant or have scored close to ’0’. Testing is applied again after feature subset selection. We found that the degree of classification increased with a high dimension relative to the first experiments because the degree of classification relied on the number of features derived from e-mails. Consequently, the reduction of unimportant features led to an increase in the degree of classification and vice-versa. The similarity score was determined, and the datasets are then used for cross-checking.
Experimental results and discussions
The results of this paper indicate two evaluation points of view. The first point is a calculation of the accuracy, and the second is to assess the level of the correlation between the system result and others using a T-test. However, the T-test showed that these results were statistically significant. Figure 4 provides the benefit charts for both SVM training and testing outcomes as classifiers before using the BDE-SVM method. Gains chart with the best line is ($Best-SVM), and the result of SVM before improvement is ($S-SVM).

Training and testing result of SVM before improvement.
This paper is executed two kinds of experiments: BDE and SVM, as mentioned earlier. Figures 6 demonstrate the result of using BDE as feature subset selection to select the optimal subset features based on population size = 50, iteration no = 1000, and a number of run = 20 for “spambase” and “spamassassin” dataset, respectively.

Example results in BDE using spambase dataset.

Example results in BDE using spamassassin dataset.
Tables 3 provide the result of classification using the SVM learning algorithm after reducing the number of features based on the binary differential evolution (BDE) algorithm. This paper produced results by selecting the optimal (near-optimal) subset features using binary differential evolution. The selection of the optimal subset features based on an evolutionary algorithm such as differential evolution, the fitness function is very important. In this paper, a correlation coefficient is used as a fitness function. The approach for the paper reduced the number of features by selecting a subset of all features based on binary differential evolution (BDE). Table 2 demonstrates the result of the classification, testing accuracy, the execution time (computational complexity) based on the SVM algorithm. In addition, Table 3 illustrates the result of a false positive, false negative, precision, recall, and F-measure using the SVM algorithm. The accuracy of classification using the SVM algorithm and the subset of features is 93.99%for testing while the miss-classification is 6.01%for testing of accuracy, the execution-time result is 53.09 seconds, false-negative rate is 0.089, the false positive rate is 0.042, F-measure is 0.94 the precision is 0.94, and the recall is 0.96.
Analysis of the training and testing result based on BDE-SVM
Analysis of the training and testing result based on BDE-SVM
Table 2 shows that the accuracy of e-mails classified was improved for the datasets besides reduce the execution time. This accuracy indicates most of the e-mail is successfully pass to classifiers for recognition with the lowest execution time, 53.09 Sec. This indicates that the proposed approach is improving the accuracy of e-mail spam classification.
Table 3 displays that the false positive, precision, recall, and F-measure of e-mails classified are improving for the datasets. Figure 7 illustrates the gain charts for both training and testing results after selecting the optimal (or near-optimal) subset features based on SVM as a classifier and BDE as feature subset selection. Gains charts with the best line are ($Best-BDESVM), and the result of SVM after using BDE as feature subset selection is ($S- BDESVM).

Training and testing of SVM after use of BDE.
Table 4 demonstrates the result for different methods, accuracy, recall, F-measure, false positive, and execution time to compare with our result. In addition, Table 4 compared two kinds of experiments that are executed in this paper. Feature subset selection based on binary differential evolution (BDE) and classification based on SVM.
The comparisons results in our approach
The former is responsible for obtaining optimal (or near-optimal) subset features from all features, while the latter is responsible for the classification using the selected features for the e-mail spam classification problem. The SVM algorithm was designed to test and evaluate the performance of the BDE method by selecting a feature for e-mail spam classification problems.The results demonstrate that the accuracy using the new approach (BDE-SVM) is better than the following optimization techniques: (SVM and GA). Many authors used GA as an example to improve the accuracy of SVM. The outcome after using the feature subset selection based on binary differential evolution and correlation coefficient as fitness function and using SVM as classifiers gives a better result in terms of accuracy and time of execution as described above. Table 4 compares the result of the classification, accuracy, the execution time based on the SVM algorithm, and different methods as feature selection.
Also, Table 4 illustrates the result of false positives, precision, recall, and F-measure using the SVM algorithm. Based on the generalization of the obtained results, the accuracy of the proposed approach BDE-SVM is 93.99%, which is better than using SVM only. Figures 8 demonstrate the accuracy result comparisons between the previous result and the recent result. Figure 8 indicates the comparison among the accuracy of our methods and the y-axis of the percentages of accuracy for the proposed method relative to other approaches. Figure 8 explains that the new approach based on BDE-SVM has achieved better accuracy than others.

Line comparisons among our results.
Figure 9 shows the comparison between the accuracy and time of execution of our results and the others. From Fig. 9, the x-axis shows the differences between the accuracy and time of execution of each method, and the y-axis shows the proportions of accuracy and time of execution. Figure 9 shows that the new approach has increased reliability and decreased execution time relative to other methods.

The comparisons among our results and other.
From the above figures, this study has proven two hypotheses. The first: studying the importance of e-mail features produces a good classification. The selected features from the trained approach were used to tune the classification accuracy. Second: developing a robust feature selection approach for the selected features.
This section shows the results of the comparison between our proposed approach and the different literature methods used to improve the classification of e-mail spam by reducing the features. The comparison accuracy obtained from our approach was compared with the results from Yilmaz Kaya [39], Vinitha et al. [40], Fagbola et al. [22], Maldonado et al. [41], Alom et al. [42] and Parimala [43]. Alom et al. [42], proposed a deep learning model, which is combining two classifiers (i.e., tweet text classifier and metadata classifier). They run the model on two different real-world datasets. The first dataset achieved an accuracy of 99.32%, while the second one attains an accuracy of 93.38%. We selected these methods of comparison because they used the same datasets as ours. By comparing the outcome of different approaches with our result, we find that our result was better than the different approaches.
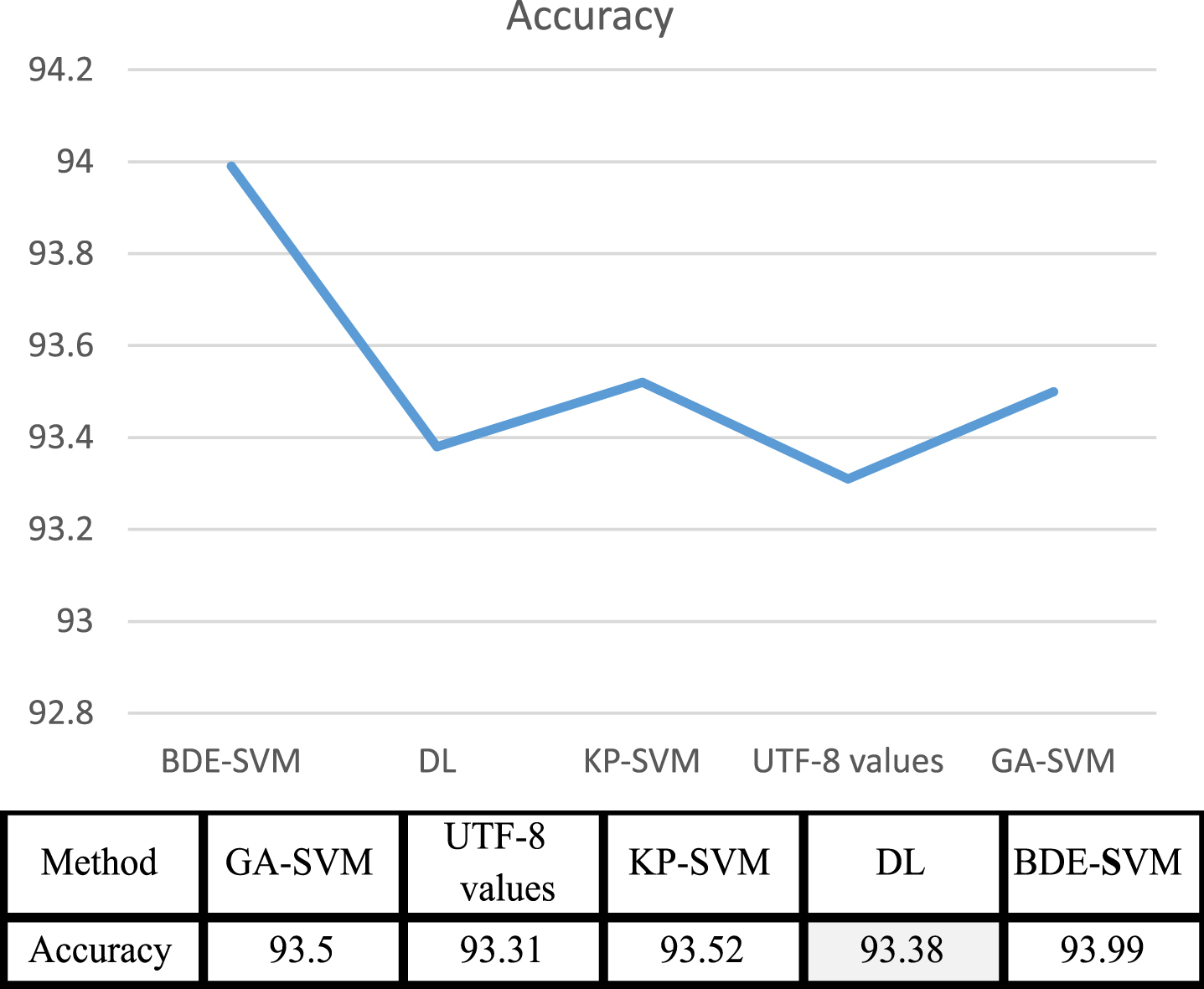
Table 5 shows the comparison between the results of our approach and others for the classification of e-mail spam. We have noted that the proposed approach has achieved better accuracy scores. Figure 10 present the accuracy comparisons between our proposed approach and other methods. From Fig. 10, the x-axis shows the comparisons between the accuracy of our approach and the other, while the y-axis shows the percentages of accuracy for the proposed approach compared to the others using the column chart. Figure 10 explains that the new approach (BDE-SVM) is achieved better accuracy than the other is.
The comparisons of accuracy among our results and others
The comparisons of accuracy among our results and others
Line comparisons among our result and others.
Figure 10, x-axis describes the comparisons between the accuracy of our approach and others while y-axis describes the percentages of accuracy for the proposed approach compared with other using line chart. Figure 10 show that the new approach (BDE-SVM) is more accurate than others. In this article, the T-test is used to demonstrate the importance of our proposed method. Table 6 shows that our approach proposed are statistically significant. The Table 6 shows the result before and after optimization using the binary differential evolution subset selection approach (accuracy of use of SVM, the accuracy of use of BDE-SVM) compared to the paired samples T-test procedure. The Paired Samples T-test test contrasts the results of two variables representing the same class at different times. The mean values of the two variables ((Accracy1, Accracy2) are shown in the Statistic Samples Table 6. Since the T-test Paired Samples compares the means of the two variables, it is useful to know what the mean values are. The low value of the T-test shows that there is a significant difference between the two variables. So consider the null hypothesis that the test statistics will be less than the value of the t-distribution table, and that means that there is a significant difference between the two methods. Compared to the calculated values, the value of the t-distribution table was found to be less than the t-distributed value, which means that there is a significant difference between the two values. The confidence interval for the mean difference does not include zero; it also implies that the difference is significant. In addition, a low significance value for the T-test (usually less than 0.05) indicates that there is a significant difference between the two variables. Table 6 shows the terms (0.0006) that show that our proposed method has achieved significant results in SVM and BDE-SVM. In addition, the significant value in the SVM and BDE-SVM values is high, and the confidence interval of the mean difference does not contain zero. We can therefore conclude that there is a significant difference between the results before and after optimization. We also ran two statistical significance tests (t-tests) to show the improvement of our proposed pre-and post-improvement approach using the binary differential evolution approach. We found that the results of our proposed approach were statistically significant. Results after using feature subset selection based on improved BDE and SVM as classifiers; this can re-duce execution time (computational complexity), improve F-measurement, and improve accuracy and deliver better results than others.
Testing of statistical significance using T-test based on Spambase dataset
The paper focuses on the selection of subset features and, for this reason; the contribution of this paper is to use binary differential evolution (BDE) to select subset features. The challenge is, therefore, to provide an e-mail spam classification method for a subset feature and a classification algorithm such as SVM. Our suggested method is one of the solutions for selecting subset features to reduce the higher dimension and improve accuracy. The results obtained by the proposed approach are considered as one of the significant research solutions for e-mail spam classification. An e-mail spam classification system would be helpful for reducing the number of unsolicited messages. Our implemented approach is to evaluate and compare with some of the current e-mail spam classification techniques. In addition, the suggested solution offers the following advantages: increased detection reliability of the email spam classification. This paper introduces approaches to the choice of features based on the binary differential evolution optimization technique. The quality of the proposed method is contrasted with other population-based selection strategies such as GA and PSO. It is shown that the proposed BDE required smaller memory than other approaches, which results in a reduction in the time of execution. In addition, when testing on an e-mail spam classification problem, the proposed approach managed to outperform both GA and PSO in terms of classification results, yielding an accuracy of 93.99%. Finally, relating to the huge number of e-mails under classification, the difference in accuracy is considering very acceptable.