
Abstract
Recent researches indicate that pairwise learning to rank methods could achieve high performance in dealing with data sparsity and long tail distribution in item recommendation, although suffering from problems such as high computational complexity and insufficient samples, which may cause low convergence and inaccuracy. To further improve the performance in computational capability and recommendation accuracy, in this article, a novel deep neural network based recommender architecture referred to as PDLR is proposed, in which the item corpus will be partitioned into two collections of positive instances and negative items respectively, and pairwise comparison will be performed between the positive instances and negative samples to learn the preference degree for each user. With the powerful capability of neural network, PDLR could capture rich interactions between each user and items as well as the intricate relations between items. As a result, PDLR could minimize the ranking loss, and achieve significant improvement in ranking accuracy. In practice, experimental results over four real world datasets also demonstrate the superiority of PDLR in contrast to state-of-the-art recommender approaches, in terms of Rec@N, Prec@N, AUC and NDCG@N.
Introduction
Currently, Recommender Systems (RS) have been ubiquitously applied in various types of applications, and achieved tremendous success [1], such as online business, social network and so on. According to statistics, RS could affect as much as 35% sales on Amazon and 80% movie watching in Netflix [2]. In general, RS is effective and efficient in information retrieval and filtering, which aim to help users to discover the most valuable information from a large number of choices. Moreover, it’s promising to introduce deep learning methods into recommender systems, although still suffering from such limited samples and computational sources, which could lead to low performance.
As we know, the well-known Probabilistic Matrix Factorization (PMF) only involve the observed numerical ratings assigned by users over items for low-rank feature vectors learning [3]. More precisely, PMF just focuses on rating prediction with the products of the learned vectors, finally, PMF return top-N recommendation list to the user according to the ranked predicted ratings. However, there’s no consideration for some additional auxiliary information in traditional PMF, moreover, in practice, it’s always infeasible to collect the explicit feedback, such as numerical ratings. In practice, it’s already demonstrated that accurate rating prediction couldn’t guarantee high performance in top-N recommendation. Fortunately, the Learning to Rank (LtR) method could provide an alternative solution to address these problems, which could overcome the data sparsity, learn each user’s interests and preference, and provide high performance recommendation with implicit feedback.
In general, there are three types of learning to rank algorithms: pointwise, pairwise [4, 5] and listwise [6]. Actually, the rating based collaborative filtering is just belong to the pointwise learning to rank method, in which the predicted ratings will be regarded as the preference degree for the user to the items [3, 8]; Listwise method will outperform pointwise method and pairwise method, but it needs heavy computational cost. Bayesian personalized ranking (BPR) is the famous pairwise learning to rank method [9], which splits the item corpus into positive instances with explicit feedback and negative items with implicit feedback, and then performs pairwise comparison between positive instances and negative samples. In contrast to previous researches, BPR could directly optimize for ranking with the implicit feedback, which could be available in most applications. Moreover, the extensive versions of pairwise learning to rank could achieve significant improvement in item recommendation. However, in real life, insufficient negative samples couldn’t solve the long tail distribution over items, and even lead to low performance recommendation. In addition, a serious problem that the learning to rank method need to address is the high computational complexity, especially in large-scale datasets [10, 11].
In recent years, deep neural networks (DNN) [12] have developed remarkably in information processing due to its powerful capability in information processing [13], and DNN has been ubiquitously applied in various domains, such as computer vision, audio recognition, recommender systems and natural language processing. In contrast to traditional recommender approaches, it’s promising to introduce deep neural networks into RS, furthermore, DNN based RS have achieved tremendous success [14, 15], such as multilayer perceptron (MLP) [1, 16], convolutional neural network (CNN) [17], autoencoder (AE) [18, 19] and so on. In practice, with the powerful capability in computation, DNN based recommender systems could be prone to learn much more expensive feature representations automatically, furthermore, it’s already verified that DNN based RS could work well over unbalanced datasets, and yield significant improvement in contrast to conventional recommender approaches. However, DNN based RS still need improvements, such as model explicable and interactions exploitation between users and items, which could be the bottlenecks in recommendation accuracy.
In this article, a novel Pairwise Deep Learning to Rank recommendation architecture referred to as PDLR is proposed, which is an integration of pairwise learning to rank method and deep neural network, which aims to overcome the drawbacks in computational capability and recommendation accuracy. The corresponding graphical illustration of PDLR is presented in Fig. 1, from which we can see that PDLR generally contains embedding layer, pairwise interaction layer, ranking-aware attention layer and output layer. More specifically, in the architecture of PDLR, the embedding layer could learn expensive feature representations for users and items through average pooling operation, and the ranking-aware attention layer could specify the importance of each item to the user. In contrast to previous researches, it’s also reasonable and interpretable for PDLR to perform full pairwise comparison for the positive instances with each negative sample, which could learn each user’s preference to the negative item in the sense of accuracy. Furthermore, the experimental analysis over real world datasets also shows that it’s promising to introduce the deep neural network into recommender algorithm. The contributions of this article are as follows: A generic deep neural network based pairwise comparison learning to rank framework referred to as PDLR is proposed, which could provide high performance top-N recommendation with the powerful computational capability of neural network. PDLR could deep exploit the interactions among items as well as the relationship between the user and items through the pairwise interaction layer, and accurately calculate user’s preference degree towards each item, accordingly, PDLR could achieve significant improvement in personalized recommendation. Empirical experiments over four real world datasets indicate the superiority of PDLR, which could outperform state-of-the-art recommender algorithms significantly, especially in top-N personalized recommendation.
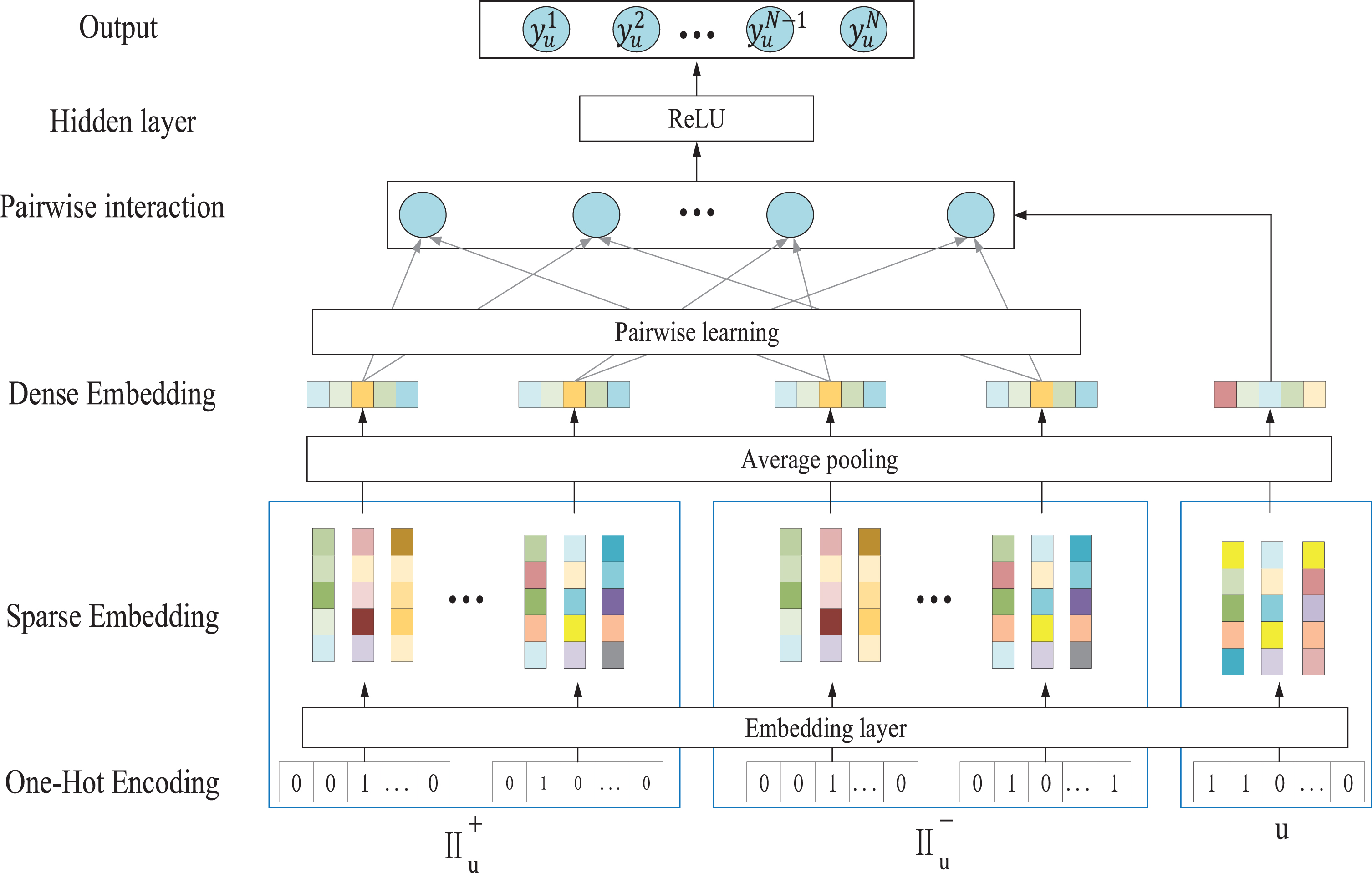
Deep neural architecture for pairwise learning to rank for top-N recommendation. In general, PDLR includes the embedding layer, pairwise interaction layer, hidden layer, ranking-aware attention layer and the output layer.
In this section, we will present some related work about PDLR in detail, including learning to rank recommendation and deep neural network based recommendation.
Learning to rank recommendation
Learning to rank (LtR) recommendation approaches could utilize the implicit feedback for recommendation, such as clicks, purchases, view history and so on, which are available in most information systems, moreover, LtR methods could provide top-N recommendation via minimizing the ranking loss, instead of rating prediction loss. Rendle et al. propose Bayesian personalized ranking from implicit feedback (BPR) [9], which provides a generic optimization solution for personalized ranking. To accelerate the model training for BPR, there are several sampling strategies proposed for negative items, such as random sampling, static sampling and adaptive sampling [5, 20], but in practice, the high performance of each sampling solution may be not consistent over real life datasets. To further improve the performance of BPR, Liu et al. propose a method called CPLR in the sense of collaborative filtering, which partitions the negative items into collaborative set and negative set, and could obtain much better recommendation results [4]. By contrast, Qiu et al. partition the negative items according to the auxiliary action, such as view and like, which could also achieve high performance in top-N recommendation [21].
Deep neural network based recommendation
Previous researches have confirmed that Deep Neural Network (DNN) based Recommender Systems (RS) own powerful capability in computation and information processing, which could deal with various kinds of user’s feedback and other auxiliary information. Zhang et al. provide a comprehensive survey on DNN based RS recently [13], such as Restricted Boltzmann Machines (RBM) [22], Multilayer Perceptron (MLP) [1], Convolutional Neural Network (CNN) [17, 23], Autoencoder [24, 25] and so on. In practice, DNN based RS could effectively and efficiently capture intricate relationship within user’s social network, as well as interactions between users and items, therefore, DNN based RS could capture user’s preference and achieve significant improvements in contrast traditional recommender approaches. Autoencoders and denoising autoencoders [24, 25] try to reconstruct user’s explicit ratings. RecNet could minimize the pairwise ranking loss with implicit feedback with the neural network [26], which could also perform preference exploitation and presentation learning for each user with implicit feedback. MIND [27] tries to deep exploit user’s diverse interests, which could achieve high performance in practice. DeepICF [28] is a combination framework of nonlinear neural network and item-based collaborative filtering, which could capture the intricate interactions within item corpus in practice.
Pairwise deep learning to rank
In this section, we will concretely present the neural architecture for pairwise deep learning to rank, which generally including embedding layer, pairwise interaction layer, hidden layers, ranking-aware attention layer and output layer. In this article,
Neural architecture
In this article we will illustrate the proposed neural architecture for pairwise learning to rank, which generally including embedding layer, pairwise interaction layer, hidden layer and output layer. In PDLR, for user
Here, let variables
In the following, we could get the dense representation vectors for each item through average pooling operation, which can retain useful information and reduce computational complexity. Here, suppose the i-th d-dimensional representation vector for s items with explicit feedback is
Identically, with the one-hot encoded vector for user
To this end, for pairwise comparison layer, let
As mentioned before, the generated
Specifically, here, we design a ranking-aware attention layer Att (l
j
), with softmax function, to learn the weight for each item, which could specify the importance of each item to the user. Accordingly, we can obtain the probability for user u to take behavior over item v
j
as follows:
With the ranked
As stated before, PDLR could directly optimize for top-N recommendation with the implicit feedback. With the learned probability distribution for items, here, cross-entropy is employed in model training to minimize the ranking loss:
In practice, pairwise comparison between a large number of items in
The well-known stochastic gradient descent (SGD) is employed for parameter learning for the neural network, with back-propagation algorithm to compute the error gradients. The deep neural network is capable of exploiting the pairwise relations between items, and the output could indicate the probability distribution for the candidate items. In practice, this neural network could achieve convergence with only part of the explicit items and implicit items, which could be random subset from the items with explicit feedback and implicit feedback respectively. The generated vectors propagate from the embedding layer to the output layer, by contrast, the errors are back-propagated through the network. The detail of the network learning is presented in Algorithm 1.
In this section, to evaluate the performance of PDLR, a series of experiments are performed over Movielens, Amazon Movie (Amazon-m), Douban Movie (Douban-m) and Lastfm respectively, and we will compare the performance of PDLR with other benchmark recommendation methods. In addition, we will also investigate the impacts of parameters over the recommendation performance.
Datasets
The Movielens dataset contains 881,563 observed ratings assigned by 5,748 users over 3,811 movies 1 . The subset of original Amazon-m dataset contains 116,342 observed ratings assigned by 6,562 users over 4,569 movies 2 . The Douban-m dataset contains 122,508 observed ratings assigned by 2,872 users over 12,416 movies 3 . The Lastfm dataset contains 88,104 explicit user-listened artist relations assigned by 1,753 users to 16,428 artists 4 . With the outlier and users and items with less than 10 records being removed, the statistic of each dataset are reported in Table 1, which indicates that the datasets are rather sparse. Moreover, 5-fold cross validation is employed in each experiment, and each dataset will be split randomly into a training set (80%) and a testing set (20%).
Statistic of each dataset
Statistic of each dataset
In addition, the observed ratings in Movielens, Amazon-m and Douban-m will be regarded as the explicit feedback for items in experimental settings, and the rest will be regarded as implicit feedback.
Due to the essential goal of the proposed PDLR is to provide accurate top-N recommendation to each user, here, the popular Rec@N, Prec@N, AUC and NDCG@N are employed as the evaluation metrics for PDLR, and Rec@N and Prec@N are defined as follows:
We will compare the performance of PDLR with the following recommender approaches:
For PDLR, grid search method is employed for parameter tuning over each real world dataset, and the learning rate is set to η = {0.01, 0.001, 0.0001}. The parameter for regularization term is set to: λ = {0.05, 0.01, 0.005, 0.001}, and the embedding size for each user and items is set to: d = {8, 16, 32, 64}.
Performance comparison
In this section, a series of experiments are carried out over each real life dataset to evaluate the effectiveness and practicability of PDLR, moreover, we will further compare the performance of PDLR with the benchmark recommender approaches, in terms of Rec@N and Prec@N, NDCG@N and AUC.
The corresponding experimental results of the performance comparison for BPR, RankNet, DeepICF, RecNet, NCR and PDLR are reported in Table 2, in terms of Rec@N, Prec@N, NDCG@N and AUC. Here, note that the embedding size is set to d = 32 over each dataset for comparison. From Table 2 we can see that: Overall, the proposed PDLR could achieve high performance over Movielens, Amazon-m, Douban-m and Lastfm, in contrast to BPR, RankNet, DeepICF, RecNet and NCR. Take Movielens for example, the values of Rec@5, Rec@10, Prec@5, Prec@10, NDCG@5, NDCG@10 and AUC are 0.1104, 0.1373, 0.2932, 0.3208, 0.3901, 0.4233 and 0.8208 respectively, which are much better than that of other compared approaches. The performance of BPR is a little inferior to that of other methods. Actually, RankNet, DeepICF, RecNet, NCR and PDLR are extensive methods of BPR, and in practice these methods could overcome some drawbacks of BPR, and achieve better performance. The values of Rec@10, Prec@10 and NDCG@10 are a little better than that of Rec@5, Prec@5 and NDCG@5 respectively.
Performance comparison for each algorithm (d = 32)
Performance comparison for each algorithm (d = 32)
From the neural architecture of PDLR, we can see that PDLR could perform pairwise comparison with the pairwise interaction layer. More precisely, items with implicit feedback will be equally regarded as the potential candidates for each user, and PDLR will perform pairwise comparison for each item with implicit feedback to the items with explicit feedback, afterwards, the corresponding results could indicate the user’s preference degree towards the item, which could also be regarded as the probability for the user to take behavior over the item in future. In this regard, PDLR could deep capture the intricate relations between items, and perform pairwise comparison for personalized ranking.
Essentially, PDLR owns the merits of computational capability and recommendation accuracy, since it’s an integration of deep neural network and pairwise comparison. Therefore, with the deep neural network, PDLR could deal with tasks with high computational cost, moreover, PDLR could perform representation vectors learning for each user and items via interaction exploitation. Accordingly, PDLR could overcome the drawbacks of other methods, such as BPR, RankNet, DeepICF, RecNet and NCR, and achieve significant improvement in item recommendation tasks, which is also verified in the experimental results.
In summary, from the experimental analysis over Movielens, Amazon-m, Douban-m and Lastfm, we could conclude that the performance of PDLR is stable and effective over real life datasets, which could provide much more effective and accurate top-N recommendation in contrast to state-of-the-art recommender approaches.
In this section, we will investigate the impacts of embedding size over the performance, and perform convergence analysis of model training. Below, we will do research on top-N performance for PDLR.
Impact of embedding size
The embedding size of the users and items could affect the performance of PDLR. Note here, for sake of simplicity, the user and items are with the same embedding size d. In this section, we do research on the impact of embedding size over the performance of PDLR, and the corresponding results are reported in Fig. 2, from which we could see that: (1) The values of Rec@5, Rec@10 and Rec@20 increase with the increasing embedding size over each dataset; (2) We could obtain the optimal value of Rec@N while the embedding size is around d = 32 for Movielens, Amazon-m, Douban-m and Lastfm. While d > 32, the values of Rec@N vary slightly with the increasing d.
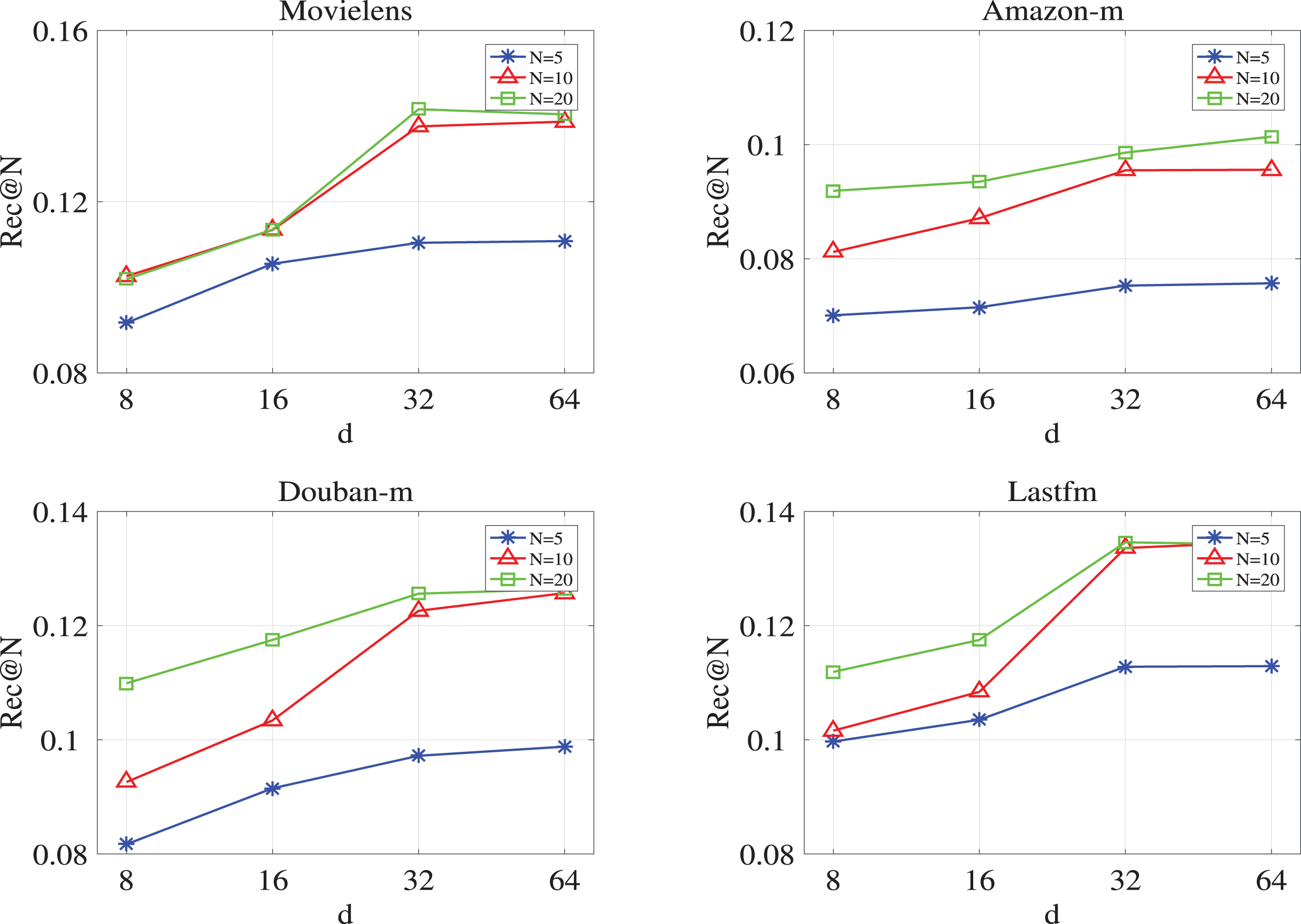
Investigation of embedding size for PDLR in terms of Rec@N over Movielens, Amazon-b, Douban-m and Lastfm.
In practice, the large value of embedding size may lead to heavy computational cost, therefore, we also need to balance the recommendation performance and computational cost. Figure 2 indicates that the embedding size could be set to d = 32 for PDLR in real applications.
In this section, we will focus on convergence analysis for the model training, furthermore, to investigate the functionality of ranking-aware attention layer, we will do performance comparison between the ranking-aware attention layer (Here, referred to as PDLR_ATT) and the network without ranking-aware attention layer (referred to as PDLR_HI) over each real life dataset, and the corresponding results are reported in Fig. 3.
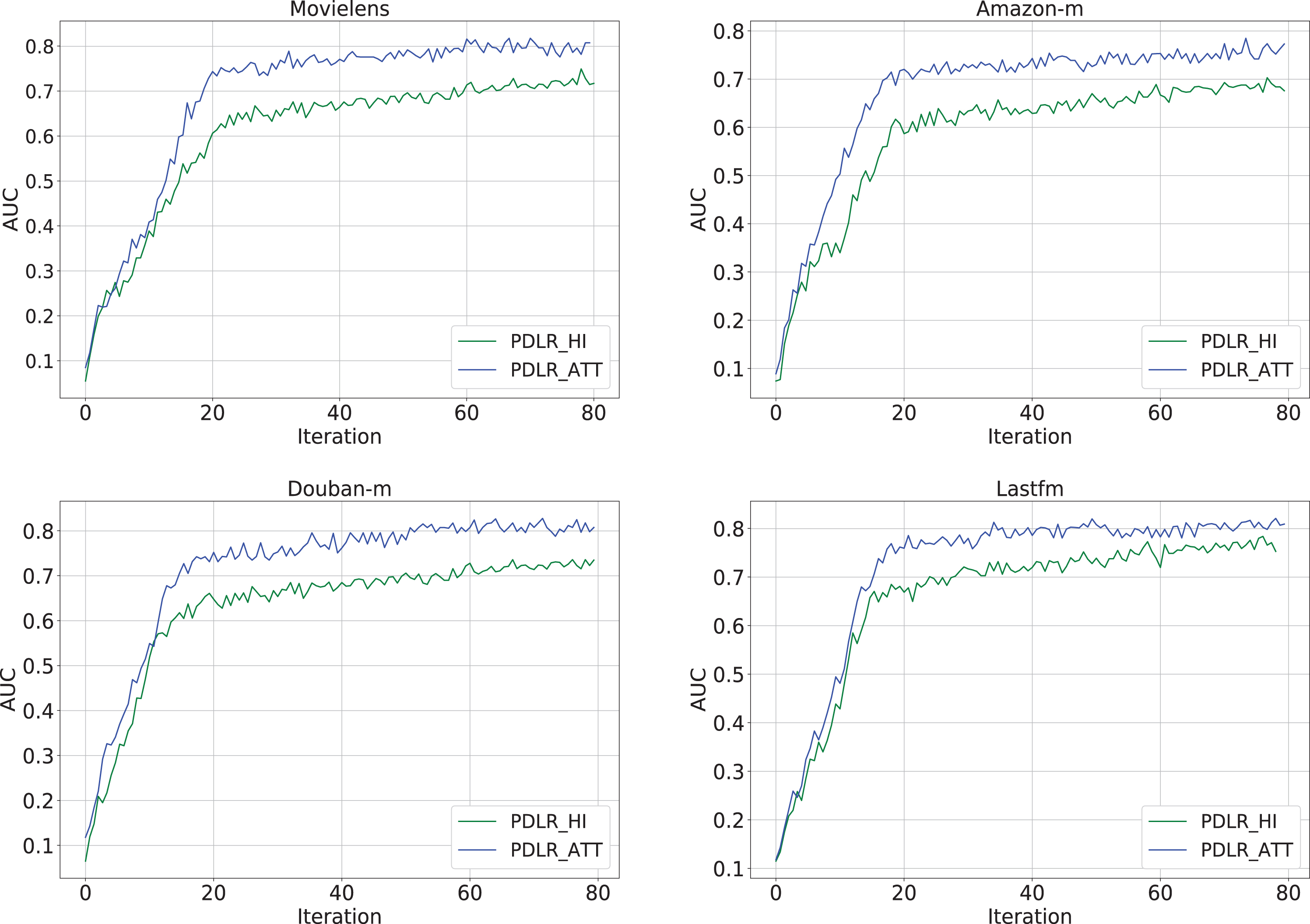
Convergence analysis for PDLR in terms of AUC over Movielens, Amazon-b, Douban-m and Lastfm.
From Fig. 3 we could see that (1)After several (around 20), both of PDLR_HI and PDLR_ATT could quickly achieve convergence training iterations over each dataset; (2) While achieving convergence, PDLR_ATT could obtain a little bigger AUC values than PDLR_HI over each dataset; (3) Values of AUC of PDLR_HI and PDLR_ATT are stable and reliable over each dataset. Take Lastfm for example, the value of AUC for PDLR_ATT is about 0.832, the improvement of which could reach 5.65% in contrast to PDLR_HI, which indicates that PDLR_ATT slightly outperforms PDLR_HI.
Note that during the model training phase, we find that the proposed recommender engine could also achieve convergence just with part of items with explicit feedback and implicit feedback as input, however, in this settings, insufficient samples may lead to low performance in real world applications, although this could decrease the computational cost significantly.
In summary, the experimental results in Fig. 3 demonstrate the significant superiority of PDLR_ATT with ranking-aware attention layer. In practice, the proposed PDLR_ATT could deal with large volume of datasets with the neural architecture effectively and efficiently, and the ranking-aware attention layer of PDLR_ATT could indicate user’s preference to each item, as a result, PDLR_ATT could further improve the recommendation performance, by contrast, PDLR_HI is without the ranking-aware attention layer.
Due to the final goal of the proposed PDLR is to provide top-N recommendation, in this section, we conduct top-N performance comparison (N = {10, 20, 30, 40, 50}) for PDLR and other compared methods in terms of NDCG@N over each dataset, and the corresponding experimental results are shown in Fig. 4, from which we can find that the results share the similar trends over Movielens, Amazon-m, Douban-m and Lastfm: The top-N performance of PDLR is stable w.r.t. N, and PDLR outperforms BPR, RankNet, DeepICF and RecNet significantly. Take Lastfm for example, the NDCG@20 are 0.321, 0.358, 0.362, 0.383 and 0.418 for BPR, RankNet, DeepICF, RecNet and PDLR respectively, and the improvement for PDLR could even reach 8.1% on average while compared to other methods. In practice, a small number of pairwise comparison between the positive instance and the negative samples may lead to inaccurate parameter setting, such as DeepICF and NCR, therefore, to overcome this drawback, PDLR could learn a much more accurate preference degree for each negative sample via the pairwise interaction layer, which could improve the recommendation performance significantly, and the experimental results in Fig. 4 also certificate the superiority of PDLR.
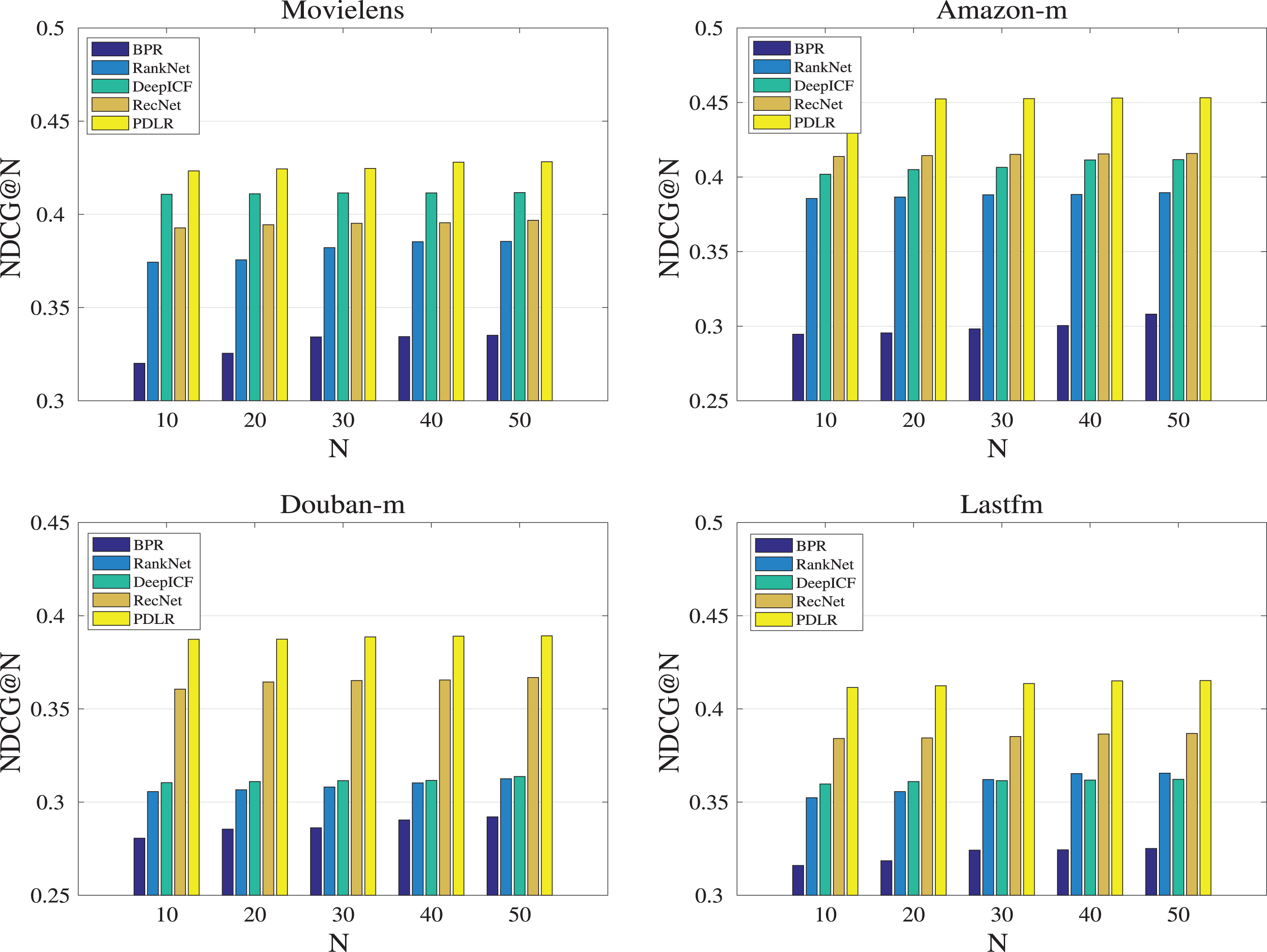
Top-N performance comparison for BPR, RankNet, DeepICF, RecNet and PDLR in terms of NDCG@N over Movielens, Amazon-b, Douban-m and Lastfm.
Recommender systems are effective and efficient in dealing with such data sparsity and cold start problems, and have been ubiquitously applied in various information systems. Currently recommender systems have become the crucial role to address information overload in various information systems. To overcome the data sparsity and provide accurate recommendation for users, in this article, a novel neural network based pairwise comparison method referred to as PDLR is proposed, which could overcome the drawbacks of previous recommender approaches, and perform pairwise learning to rank through comparison between positive instances and negative samples. In practice, PDLR could learn expensive feature representations for each user and item through the embedding layer, and further enhance the recommendation performance with the ranking-aware attention layer. With the powerful computational capability of neural network, PDLR is capable of deep exploiting the interactions among items, as well as the relations between each user and items, which are greatly helpful to accurate top-N recommendation in theory. Experimental analysis over four real world datasets confirms the superiority of PDLR, which could outperform state-of-the-art recommender approaches significantly, especially in recommendation accuracy.
As future work, we intend to investigate the performance of neural network based recommender systems over datasets with large volume, including some online applications. We will also try to leverage some available auxiliary information, such as the item attributes and social network, to further boost the recommendation performance for PDLR.