
Abstract
This paper introduces a new approach to build the rule-base on Neo-Fuzzy-Neuron (NFN) Networks. The NFN is a Neuro-Fuzzy network composed by a set of n decoupled zero-order Takagi-Sugeno models, one for each input variable, each one containing m rules. Employing Multi-Gene Genetic Programming (MG-GP) to create and adjust Gaussian membership functions and a Gradient-based method to update the network parameters, the proposed model is dubbed NFN-MG-GP. In the proposed model, each individual of MG-GP represents a complete rule-base of NFN. The rule-base is adjusted by genetic operators (Crossover, Reproduction, Mutation), and the consequent parameters are updated by a predetermined number of Gradient method epochs, every generation. The algorithm uses Elitism to ensure that the best rule-base is not lost between generations. The performance of the NFN-MG-GP is evaluated using instances of time series forecasting and non-linear system identification problems. Computational experiments and comparisons against state-of-the-art alternative models show that the proposed algorithms are efficient and competitive. Furthermore, experimental results show that it is possible to obtain models with good accuracy applying Multi-Gene Genetic Programming to construct the rule-base on NFN Networks.
Keywords
Introduction
Neuro-Fuzzy networks are Computational Intelligence techniques that combine characteristics of the Fuzzy Systems and Neural Networks. These systems stand out for integrating the treatment of uncertainty and the interpretability of Fuzzy Systems and the learning ability provided by Neural Networks [40]. Neuro-Fuzzy networks present benefits over other Artificial Intelligence (AI) techniques since they have high learning and generalization capacity and can be explainable - meaning that it is possible to explain why the training method reaches a determined solution [3, 34]. On the other hand, Fuzzy Systems lack learning and generalization capabilities, and Neural Networks are not explainable [34].
From the 90s, many works have improved Neuro-Fuzzy Systems and achieved great results. Neuro-Fuzzy systems have become highly efficient due to its fast learning, on-line adaptability, self-adjusting, the capability of obtaining the small global error possible, and small computational complexity [47]. Furthermore, the capacity of obtaining good results is one of the responsible for them to be considered universal approximators [27, 57].
Neuro-Fuzzy networks have been applied in different domains such as forecasting [2], non-linear systems identification [15], classification [7, 29], control systems [42], among others. Some works have already made a comparison between Neuro-Fuzzy networks and other AI techniques. For example, [16] compares Multi-Gene Genetic Programming (MGGP) and a dynamic evolving neural-fuzzy inference system (DENFIS) to modeling pan evaporation, showing some advantages of DENFIS to prediction and MGGP to regression in data. In [44] Neuro-Fuzzy and Neuro-Bee models for predicting the safety factor of eco-protection slopes are evaluated, obtaining a high prediction capacity in the Neuro-Fuzzy model. Some AI tools, including Genetic Programming (GP) and Adaptive Neuro-Fuzzy Inference System (ANFIS), are evolved to determinate relationships between groundwater quality parameters in [4]. ANFIS has demonstrated efficiency to estimate these parameters and GP to model the relationships.
There is a growing interest in developing new learning algorithms that enable the autonomous construction of the rule-base and parameters’ update in Neuro-Fuzzy networks using Machine Learning techniques [47]. Among the approaches used for learning in Neuro-Fuzzy networks are Evolutionary Computation techniques that stand out for their ability to adapt and learn, based on a global search [20].
Evolutionary Computation algorithms can be used to extract knowledge to the construction of the rule-base [26] and to parameters’ update [24]. There are two main approaches to creating rules with Evolutionary Computation techniques, that of Michigan [21] and that of Pittsburg [50]. Michigan’s approach defines that each individual represents one rule, and the rule-base is a set of individuals. In this case, the individual’s modeling is simpler, but its evaluation becomes harder due to the need to define a rule’s quality. In the Pittsburg approach, each individual encodes a set of rules, thus facilitating their assessment, since a single individual represents the entire rule-base. On the other hand, computational cost and training time become higher when compared to the other approach.
Evolutionary methods, population-based algorithms inspired by biological evolution principles, distinguish from other heuristic methods mainly by their ability to avoid local optimal [17]. Being populational methods, they can converge in fewer steps than others. Specifically, Genetic Programming (GP) has already been demonstrated to be efficient when applied to regression problems due to its high capability of representing complete functions [6, 38]. Such as discussed in [47], a single supervised learning technique, such as gradient-based technique, suffers from local minima and overfitting problems. Furthermore, a single technique can be exhaustive and present weak firing strength when the network structure and parameters become large [33, 46]. Instead, population-based algorithms are derivative-free algorithms and do not require the differentiability assumption. Those algorithms require only the availability of objective function values but no derivative information. It is particularly useful when the derivative of the function is difficult to obtain or does not exist.
This work introduces an evolutionary Neuro-Fuzzy system that hybridizes the neurocomputing approach with the searching ability of the evolutionary techniques. Here, an algorithm based on Multi-Gene Genetic Programming (MG-GP) to build the rule-base of a Neo-Fuzzy-Neuron (NFN) network [55] using the Pittsburg approach is proposed. Since in the Pittsburgh approach, an entire fuzzy rule base is encoded as a chromosome, when applying the Genetic Programming, an individual of the population represents a complete rule-base. The MG-GP creates and adjusts the membership functions, and a Gradient-based method adjusts the network’s parameters. Although much explored in Fuzzy and Neuro-Fuzzy Systems and shown to be efficient methods to learning in these systems, Evolutionary Algorithms, in particular Genetic Programming, are still unexplored in NFN networks. The novelties and the main contributions presented in this work are: Integration of Multi-Gene-Genetic-Programming and Gradient-based Method to automatic generation and adjustment of rules and parameters in Neo-Fuzzy-Neuron networks; The Neo-Fuzzy-Neuron models are evolved in the evolutionary learning processes; A new learning algorithm to Neo-Fuzzy-Neuron Networks focused on solving general regression problems; Obtaining a Neuro-Fuzzy System based on data with good accuracy.
Genetic Programming, a class of evolutionary approaches, encodes data in the genetic individuals, and the search is performed on this coding instead of raw data. This feature allows GP to be independent of the continuity of the data [47]. The rationale behind the choice of hybrid algorithm, coupling Multi-Gene Genetic Programming and Pittsburg approach, is based on the following: Genetic Programming can be seen as an extension of popular Genetic Algorithms combining their global search ability and their renowned efficiency. In Genetic Programming, one individual is modeled as a complete rule base in a tree-like arranged nodes. Since the fuzzy sets are encoded into the genotype, it facilitates evaluating solutions and fuzzy rules. It allows the generation of more suited fuzzy sets to describe membership functions via the intersection and/or union of the existing fuzzy sets. Every component of the resulting rule-base is relevant in some way for the problem’s solution. Therefore, the GP does not encode null operations that will expend computational resources at runtime. The proposed approach does not scale up with the problem size, differently from other approaches that work poorly when the problem grows in size. This would be the case when using a Genetic Algorithm to encode an N × N matrix. It is important to notice that, using Genetic Programming, any restriction on the structure of solutions is imposed. Besides, nor the complexity neither the number of rules of the solution is bounded.
The aspects discussed above give significant advantages to Genetic Programming in Neuro-Fuzzy Systems’ learning processes [5] over other heuristic and populational methods such as ACO [43], PSO [37], ABC [14], among others.
After this brief introduction, the remainder of this paper is organized as follows. Section 2 presents a short review of works that used evolutionary computation techniques to learning in Neuro-Fuzzy networks and other techniques used to learning in NFN. Section 3 describes the Neo-Fuzzy-Neuron (NFN) network and addresses its learning algorithm. Section 4 presents the proposed approach, the Neo-Fuzzy-Neuron with the Multi-Gene Genetic Programming (NFN-MG-GP). Section 5 details the computational experiments and discusses the results. Finally, Section 6 concludes the paper with a summary of its contributions and suggestions for further studies.
Related works
The synergy of Fuzzy Systems and Evolutionary Computation has been extensively explored since the 90s, aiming to integrate the management of uncertainty and the interpretability of Fuzzy Systems with the learning and adaptability of Evolutionary Computation [17]. Several works explored Evolutionary Computation for learning in Fuzzy Systems and Neuro-Fuzzy networks. Most of these works applied Genetic Algorithms (GA), but there are also approaches utilizing other techniques like Genetic Programming (GP).
Using GP, [26] presents a Fuzzy System for classification. The work uses Multi-Gene Genetic Programming to create and adjust the rule-base of a Pittsburg Genetic Fuzzy System. In [35], a multi-tree GP model is used to improve the accuracy of a Takagi-Sugeno Fuzzy System for dynamic portfolio mapping.
A Genetic Neuro-Fuzzy Inference Method (GENFIS) for diagnosis of Tuberculosis is presented in [39]. The GA was used to select the ideal network input parameters, which are used for diagnosis. The work of [5] presents an approach that uses Neuro-Fuzzy models to identify the main factors responsible for depression. In addition to optimizing weights, the AG, fleeing from great locations, also made it possible to identify redundant and inexpressive rules, thus obtaining a cleaner and more optimized rule-base. In [51], a Neuro-Fuzzy Hybrid System called ANFIS-GA (Adaptive Neuro-Fuzzy Inference System with Genetic Algorithm) is introduced. In ANFIS-GA, the GA is used to adapt the parameters of an ANFIS network. In this work, the antecedent and consequent of the fuzzy rules are modeled as GA variables.
The work of [19] presents a Genetic Neuro-Fuzzy Systems to detect faulty bearings. GA determines the adequate values to parameters to achieve a reduced number of nodes on the hidden layer. Each individual represents one structure of hidden nodes. [1] proposed an Adaptative Neuro-Fuzzy Inference System (ANFIS) trained by GA to Forecasting crude oil price. The ANFIS parameters are adjusted by GA, defining the best weights between layers 4 and 5 are optimized by GA.
However, the use of evolutionary techniques in NFN-type networks is still underexplored. In Neo-Fuzzy-Neuron networks, most works use methods based on Gradient and least-squares. In [13], an extended NFN network is proposed with adaptive learning by Backpropagation to adjust the network parameters. In this approach, the universe of discourse is uniformly partitioned by triangular and complementary functions. In [22], the authors use the same structure and present an architecture and methods for deep NFN networks with online parameters update using the weighted recurring least squares method with adaptive and cascading learning. The membership functions are triangular and complementary, created from uniform partitions.
A simple and automatic approach to design Neo-Fuzzy-Neuron networks for non-linear system identification is proposed by [32]. The network is composed of triangular and complementary functions created with the uniform partitioning of the universe of discourse. A least-squares with Backfitting obtains the network parameters. In [45], a convex cascade NFN network is proposed. The cascade architecture allows training each neuron cell independently and updates network parameters using a Gradient-based method. The membership functions used are complementary triangular and uniformly spaced.
An extended Neo-Fuzzy-Neuron structure is used in the work of [9], with unified pertinence functions of the type B-Spline [54]. A Gradient-based algorithm is used to adapt the network parameters. In [10], an NFN network powered by multidimensional non-linear weights is proposed. Weights are adjusted by a method based on Gradient with Backpropagation, and the learning rate is given by an optimal method of recurring least-squares (only one step). In [12] authors present a new algorithm to adaptive training rule for a hybrid cascade neural network based on an application of a specific type of NFN elements. The suggested model has a hybrid cascade structure, following the hybrid cascade neural network’s topology on the grounds of an optimized pool in each cascade, proposed by the same authors in previous works, combining elementary Rosenblatt perceptrons with neo-fuzzy neurons on a structural block. Besides that is presented a modified procedure by Kaczmarz–Widrow–Hoff [23] for training the system. Were used a combination of different membership function for each node, as triangular and B-splines.
[56] presents and investigates a hybrid self-organized model called GMDH-neo-fuzzy Neural Network with deep learning. The GMDH method is a self-organization method and allows the optimal structure to be built to a neo-fuzzy system and adjust the weights of the neural network in just one procedure. A hybrid model was suggested where a Neo-Fuzzy Network with a small number of adjustable parameters was utilized as a node of the GMDH-System. The NFN model utilized was the original model proposed by Yamakawa in [55]. The same structure was used in [11] applied to Forecasting Problems in Finacial Sphere. A difference to the previous model is that each node of the GMDH-system, representing by one Neo-Fuzzy Network, uses only two inputs. The approach aims to prevent deep learning drawbacks, such as vanishing or exploding of the gradient method. An accelerated backpropagation algorithm to a deep Neo-fuzzy Neural Network is described in [8]. The proposed network consists of a traditional multilayer feedforward architecture with a layer to information processing and a neo-fuzzy neuron network as a node. It was used triangular membership functions with non-linear synapses. The learning method presented to the model is based on an error backpropagation algorithm. The learning process is performed through the search of synaptic weight coefficients by minimization of the chosen loss function and uses a standard squared function as a learning criterion.
After this brief review is possible to see that evolutionary algorithms demonstrated an efficient and interesting method to perform the learning tasks in Fuzzy and Neuro-Fuzzy Systems. Despite its popularity in other contexts, they are still unexplored in the NFN networks domain.
Neo-Fuzzy-Neuron
This section reviews the Neo-Fuzzy-Neuron (NFN) network [55] used to implement the proposed algorithm presented in Section 4. Neo-Fuzzy-Neuron is a Neuro-Fuzzy network composed of a set of n zero-order Takagi-Sugeno (TS) models [52], one for each input variable. The NFN can be summarized in 4 steps. Initially, the firing degree of the membership functions μ
A
ij
is calculated for each i input variable, in which j indexes the membership functions and i the input variables. In the second step, for each input variable, the degree of activation of the membership functions is multiplied by its respective weight q
ij
, thus obtaining an output for each rule. After each rule output, the output of each TS model (y
ti
) can be obtained just by aggregation of all rules. The way to perform the aggregation of all rules is detailed later on. Finally, the network output is obtained by the aggregation of the output of each TS model. Figure 1 illustrates the basic structure of the NFN network, and each step is detailed as follows. In this figure, x
ti
is the input variable i at time t, y
ti
the zero-order TS model output,
In NFN, each membership function with its respective weight q ij represents one rule. The domain of each input variable x ti is partitioned into m i membership functions [49]. Thus, with the partition of the input variable domain i, we have the following m i TS rules:
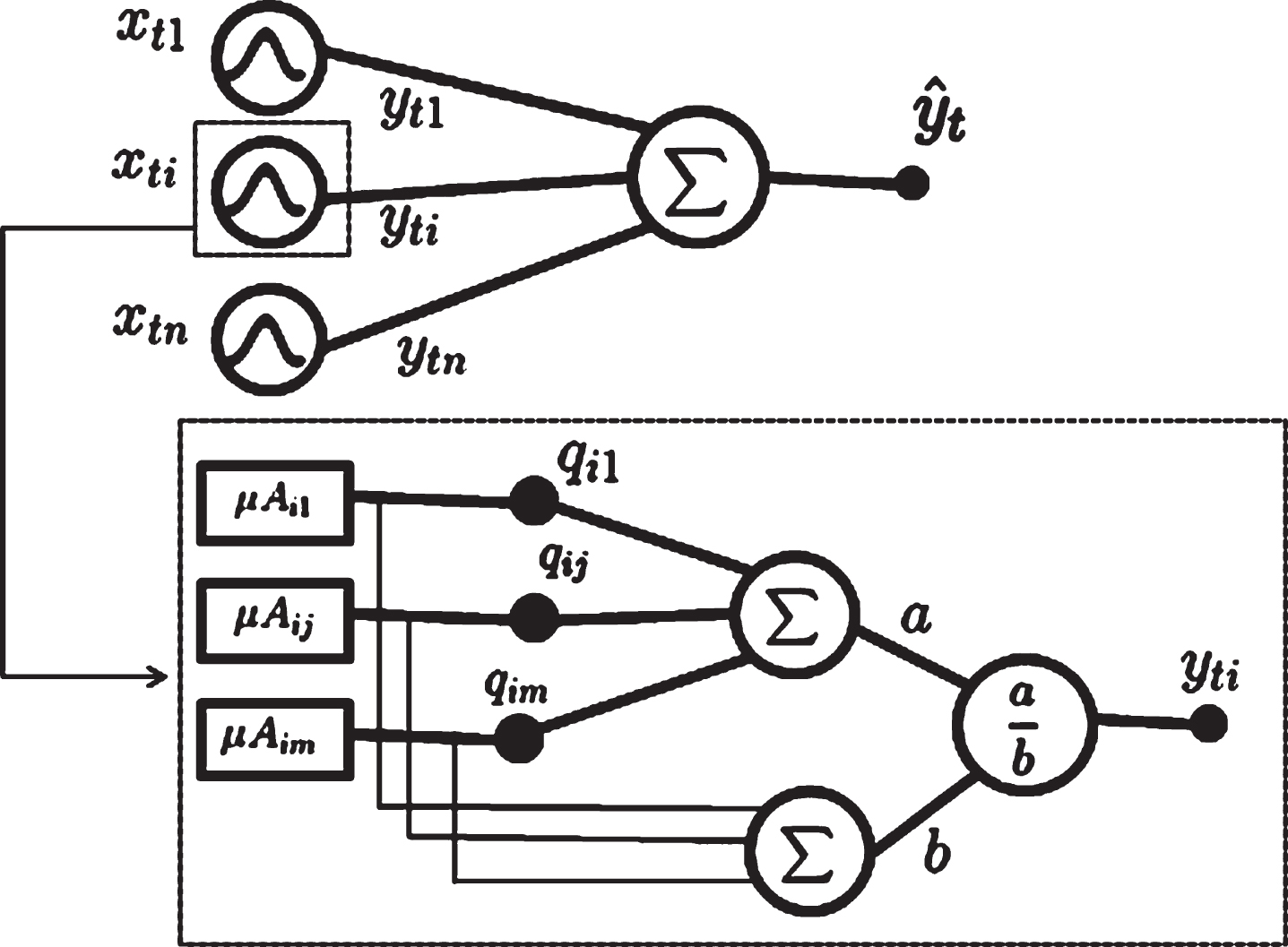
Neo-Fuzzy-Neuron network basic structure.
The models are decoupled, and the zero-order TS models output y ti is obtained by Equation (1). In this way, the output y ti is computed by the sum of the activation degree of each rule μ A ij (x i ) multiplied by its respective parameter q ij (a), weighted by the sum of the activation degree of all rules (b).
in which i indexes the input variables, j the membership functions, and t denotes the current step.
The NFN output in t (
Although the membership functions used in the NFN proposed by [55] are Triangular, other membership functions can also be used, such as Gaussian or Spline [12, 56]. In this work, we use Gaussian functions because it is an adequate function to represent uncertain data [28]. A Gaussian membership function is represented by its center (c) and spread (s). The activation degree μ
A
ij
(x
ti
) of a Gaussian membership function for a variable x
ti
is given by Equation (3). Figure 2 ilustrates the structure of a Gaussian membership function.
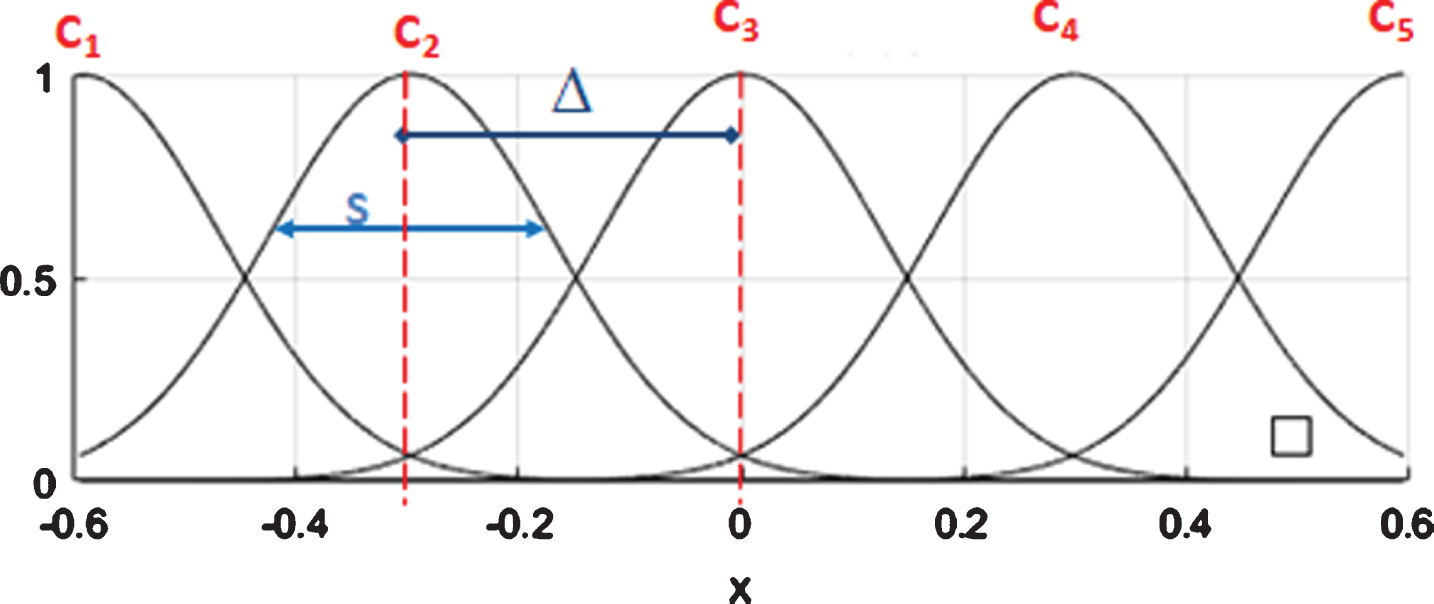
Uniformly Gaussian membership functions.
Gaussian membership functions can granulate the domain of input variable in two ways: uniformly spaced or non-uniformly spaced. Uniformly spaced membership functions consider that all rules cover the same range of values in the input variable’s domain. Figure 2 shows an example, in which the domain of the input variable is granulated into five uniformly spaced Gaussian membership functions. Note that the distance between the center of the functions (Δ) and the spread (s) are the same for all functions. Δ is given by Equation (4) and c is computed using Equation (5):
in which i indexes the input variable, m
i
is the number of membership functions for the variable i, j indexes the membership function,
In non-uniformly spaced Gaussian membership functions, there is no definition of a single value for c or s. Thus, membership functions can be freely distributed throughout the universe of discourse, as shown in Fig. 3. Note that, in this case, there is no need to calculate Δ. Non-uniformly spaced functions can be considered generalized functions as they are more adaptable to the context of the problem to be solved [25]. Having that in mind, we opted to use non-uniformly spaced functions in this work.

Non-uniformly Gaussian membership functions.
The procedure to update the network parameters is carried out using a Gradient-based method. The learning is supervised and aims updating q ij [49]. The parameters q ij are updated only for the active membership function according to Equation (6):
in which α is the learning rate, y
t
is the desired output,
The NFN parameters q ij can be initialized randomly between 0 and 1. Algorithm 3.2 summarizes how to compute the output and update the parameters of the NFN network. In this algorithm, we use the number of epochs (l) as a stopping criterion for the training, but error measures such as RMSE and MSE can also be used.

This section introduces the proposed approach to building up the Neo-Fuzzy Neuron network rule-base. The Pittsburg method [50], in which one individual represents a complete rule-base, is used with Multi-Gene Genetic Programming (MG-GP) [18] to create the NFN network rule-base and a Gradient-based method to adjust the parameters.
MG-GP is a variation of Genetic Programming (GP) considers that one individual has several trees connected by a linear structure of genes. The output of each individual is the aggregation of the trees linked to each superior gene. In NFN-MG-GP, each superior gene represents a zero-order TS model, and each one is associated with an arity tree m, in which m is the number of membership functions. A sub-tree linked to the central node represents a membership function, and the root node is composed of an aggregation function that returns the result of the membership functions associated with that model, as discussed in Section 3 and shown in Fig. 1. One individual of NFN-MG-GP is shown in Fig. 4.

Example of individual on NFN-MG-GP.
The NFN-MG-GP seeks to find the best rule-base for NFN network using Multi-Gene Genetic Programming (MG-GP), which models possible rule-bases as individuals and adjusts its evolutionary process. Thus, each individual of MG-GP represents one rule-base to NFN. To ensure that the best rule-base is not lost between generations, the Elitism operator replicates the best individual to the next generation. The consequent parameters are created in the NFN module and updated by the Gradient Method. The set of parameters is the same for all individuals of Genetic Programming. Summarizing, the rule-base is adjusted by genetic operators (Crossover, Reproduction, Mutation, Elitism) at each GP generation. The consequent parameters are updated by the Gradient learning method. Figure 5 illustrates this process, highlighting the steps performed by the GP module and by the NFN module. Section 4.1 details the steps of the algorithm.
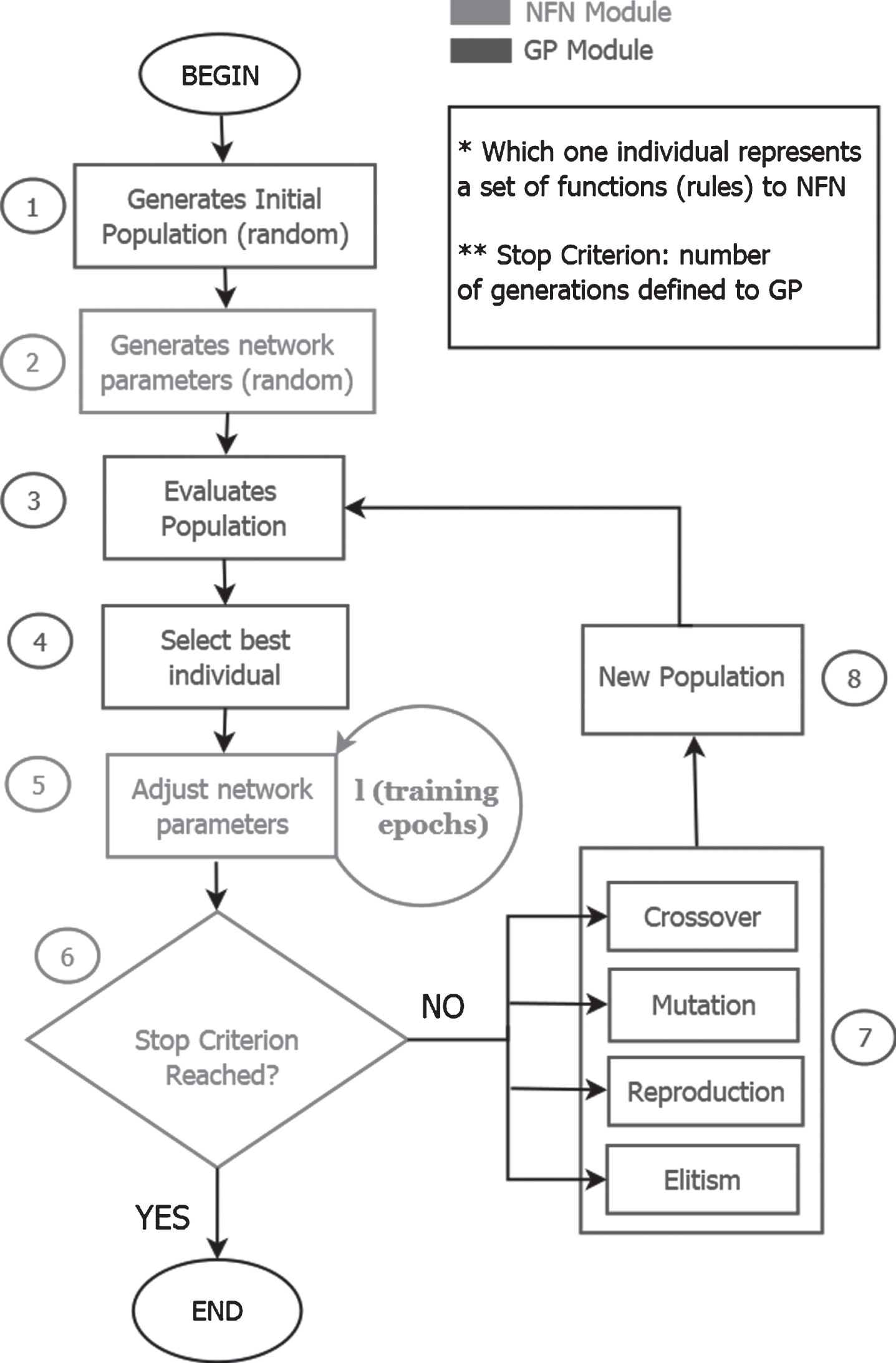
NFN-MG-GP algorithm flowchart.
This section details the proposed procedure to create the rule-base and update the network parameters of NFN-MG-GP, shown in Fig. 5. The procedure can be divided into the following 8 steps.
The first step is the generation of the initial population. Each individual of the population represents a complete structure of the NFN network. The initial population of NFN-MG-GP is created with randomly generated individuals. The Gaussian functions are defined drawing, for each function, a random value of c (center of the function) between the lower bound and the upper bound of the input variable domain, and a random value for the parameter s (spread). The initial number of membership functions to each input variable m _ ini is a user-defined parameter.
The parameters q ij are initialized with random values between 0 and 1. The created parameters in this step will be the same for all individuals of the MG-GP.
In the third step, we run the NFN network with the individuals and obtain the network output (
in which y
t
is the desired output at time t,
After evaluating the population, the best individual (the individual with the least MSE value) is selected.
This step consists of updating the parameters q ij of the best individual defined by Step 4. This update is performed by l learning epochs using a Gradient-based method, mutatis mutandis, the same described in Section 3.
Then, it is necessary to check if the stop criterion has been reached. If so, the training ends. If not, the algorithm continues by going to Step 7. The stop criterion can be an established number of generations or an error measure such as MSE (Equation (8)) or RMSE (Equation (9)), for example.
If the stop criterion is not reached in Step 6, the best individual, selected in Step 4, will pass through the next generation by Elitism. The rest of the new population is obtained, applying Crossover, Mutation, and Reproduction.
The Crossover in MG-GP can be performed at a high or low-level. High-level Crossover occurs when one parent’s superior gene is exchanged with another parent’s superior genes. When the Crossover occurs in the sub-trees associated with the superior gene, it is called a low-level Crossover. In this work, we use a low-level Crossover that allows performing smaller steps in search space, combining only the sub-trees representing the membership functions and not the entire zero-order TS model. Complementary information on the high and low-level Crossover is detailed in [26]. The Crossover operator is responsible for modifying the number of membership functions from parent to child individuals. If the same Crossover point is selected for both parents, the children generated will have the same number of functions as the parents. On the other hand, if we use different Crossover points in the parents, the children produced may have different numbers of functions.
Reproduction is carried out by generating offspring exactly like the parent (clone). The Mutation changes only one function (sub-tree) of a chosen gene, exchanging it for a new random function. The parent selection method is the tournament method [41], which selects a subset of individuals and chooses the best among them. If the parents are not selected to Crossover (due to Crossover probability), they will be selected for Reproduction. The generation of the new population is performed by replacing the entire current population with the new population generated. The best individual is always copied to the new population by Elitism.
In this step, the current population is replaced by the population generated in Step 7 and Steps
Algorithm 2 details the process to create and adjust the rule-base and update the network parameters.

This section details the parameters used in the NFN-MG-GP. The learning algorithm of the NFN-MG-GP has nine parameters: g: number of generations. Experimental practice suggests g ∈ [300, 500]. Using g > 500, relevant improvements on the final solution have not been observed in the literature. l: number of gradient epochs. In NFN-MG-GP, l is executed to each generation of MG-GP and can be set between 1 and 10. Better results have been achieved setting l = 5. Although, in this case, MG-GP has a slower convergence, it gets a lower error. α: learning rate used to update the network parameters q
ij
. The value of α is usually set to a small value, e.g., 0.5. pop _ size: size of the population. Generally, the pop _ size is chosen between 50 and 200 to ensure diversity of solutions in the population. Large population size may not be useful, leading to high computational overhead to find a solution. tx _ c: Crossover rate. The value of of the crossover rate lies in [0, 1] and the literature recommends higher values, usually tx _ c ≥ 0.7. tx _ m: Mutation rate. It’s a value between 0 and 1. The literature recommends tx _ m ≤ 0.3. Trn: tournament size. The number of individuals used on each parent selection. Preferably do not use more then 10% of pop _ size. m _ ini: initial number of membership functions to each input variable. Experimental results suggest a value between 2 and 5. m _ max: maximum number of membership functions to each input variable. Initial experiments suggest m _ max ≤ 10.
Computational experiments
In this section, the performance assessment of NFN-MG-GP is evaluated on different problems: forecasting of the weekly flow of a large hydroelectric plant; non-linear process identification; and temperature prediction of locations. Three alternative models are used in the comparison: (i) ANFIS - Adaptive Neuro-Fuzzy Inference System with Least Squares and Gradient Descent with Backpropagation; (ii) MLP - Multilayer Perceptron Neural Network with Gradient Descent method with Backpropagation; and (iii) NFN - Neo-Fuzzy-Neuron with Gradient Descent.
All computational experiments follow the same protocol as described next. For each addressed problem, the data set is split into three subsets, one for training with 60% of samples, one for validation with 20%, and another for testing with 20% of samples. The performance indicator used, the Root Mean Squared Error (RMSE), is given by:
in which k is the sample number of the test set,
The mean and the standard deviation help describe, show, or summarize the results in a meaningful way. However, a statistical test is needed to prove whether one model is statistically superior to another or not. Aiming to visualize the difference, a Boxplot Diagram is used to show the difference among models. The boxplot shows data distribution based on a five number summary (minimum, first quartile, median, third quartile, and maximum). If two boxes do not overlap with one another, then there is a statistical difference between the two groups. In the case of overlapping, a hypotheses test must be carried out to verify if there is a difference. In this work, the all versus one pairwise comparison is applied since the goal is to evaluate the performance of the proposed approach compared to others. Furthermore, a one-tailed T-test is employed.
In the one-tailed T-test, the statistical analysis is carried out using Mean (NFN - MG - GP) - Mean (m) = 0 as null hypothesis, Mean (NFN - MG - GP) - Mean (m) < 0 as alternative hypothesis, and m is the alternative model employed in the pairwise comparison. The null hypothesis will be rejected when the p-value is less than the adopted significance level. In this case, the alternative hypothesis favors NFN-MG-GP over the alternative model.
For the T-test application, the assumptions of randomness and normality of sample sets need to be tested for each problem. It is important to notice that the ANFIS model is a deterministic model always returning the same RMSE value for a given initial configuration. Due to the absence of variance in ANFIS, it is necessary to evaluate this model’s output in relation to the mean values of the others. The p-value is also presented, and the significance value used is 0.05.
The parameters used in the alternative models have been extracted from the literature and are defined as follow: ANFIS: training epochs = 500; initial membership functions = 2; type of membership functions = Gaussian; α = 0.01. NFN-MG-GP: population size = 50; generations = 300; training epochs = 5; Crossover rate = 0.9; Mutation rate = 0.08; α = 0.01; initial membership functions for each individual = 5; type of membership functions = Gaussian. NFN: training epochs= 500; α = 0.01; membership functions = 5; type of membership functions = Gaussian. MLP: hidden layers = 2; neurons per layer = 10; training epochs= 500; α = 0.01; activation function = hyperbolic tangent
It is important to highlight that the parameters have not been fine-tuned for any models applied. The values used have been chosen as the best ones reported in the literature.
In this section, models are evaluated to forecast the average weekly flow of a large hydroelectric plant located in northeastern Brazil. The goal is to predict the flow of the subsequent week based on the previous weeks [31, 39], according to Equation (10):
According to [31, 49], the non-stationary nature of data, due to periods of flood and drought throughout the year, imposes difficulty in the forecast.
The dataset, covering the period between 1931 and 2000, consists of 3,707 samples with 3 input variables and 1 output. Of these, 2,224 have been used to train, 741 to validate, and 742 to evaluate the models’ performance. As in [31, 49], the data provided is normalized between 0 and 1 to maintain privacy.
Figure 6 shows the final membership functions to the streamflow forecasting, and Fig. 7 demonstrates the output of NFN-MG-GP and the desired output. Visually analyzing Fig. 7, it is possible to see the fast convergence of the NFN-MG-GP.

Final membership functions to streamflow forecasting by NFN-MG-GP.
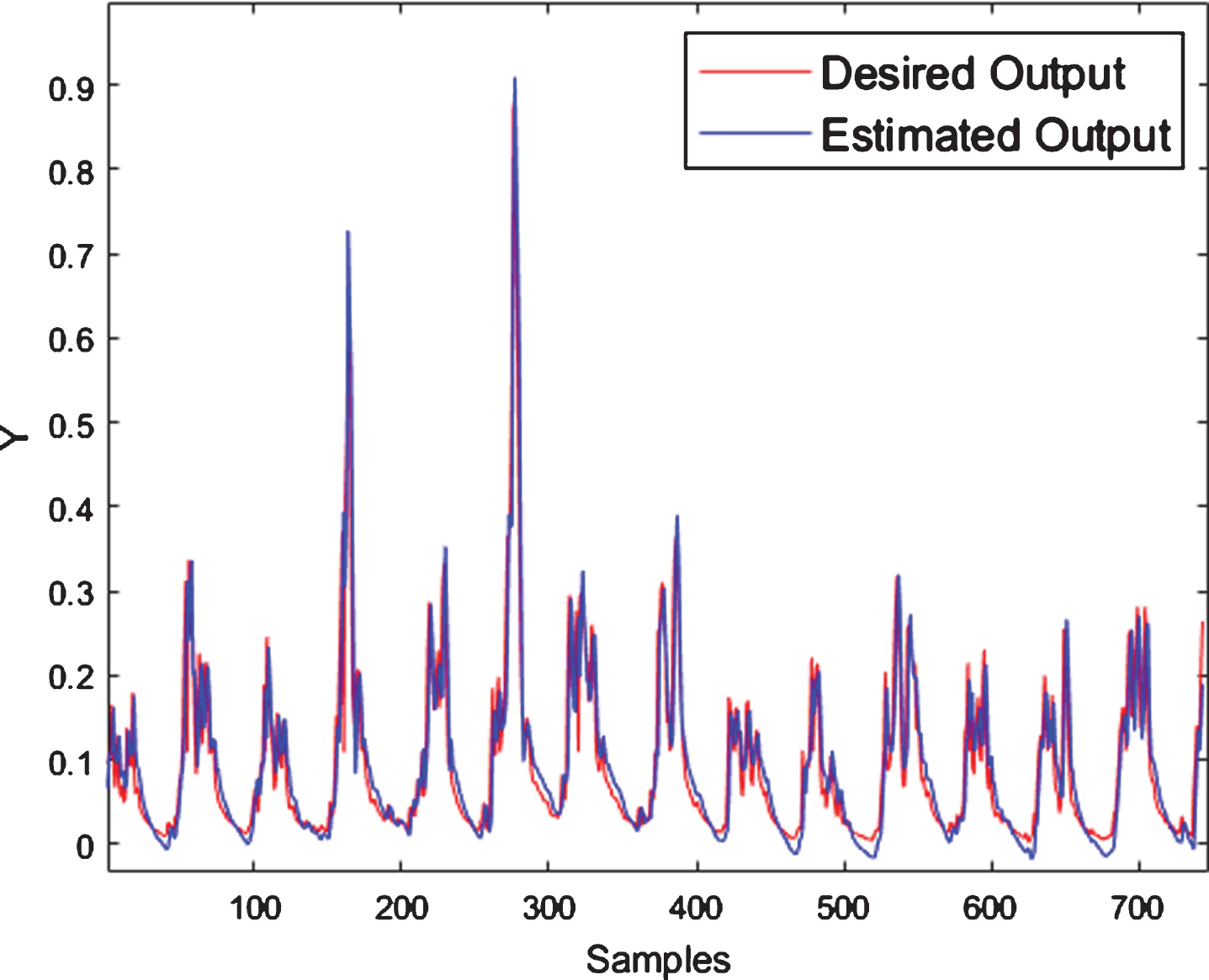
Streamflow forecasting by NFN-MG-GP.
Table 1 shows the RMSE and the standard deviation after all simulation runs. The best performance is achieved by NFN-MG-GP, followed by NFN, ANFIS, and MLP. The results achieved by the NFN-MG-GP and NFN are comparable and outperform those of the other models.
Performance of the streamflow forecast models
Figure 8 shows the boxplot for Streamflow forecasting. It is possible to say NFN-MG-GP’s is statistically superior to MLP and ANFIS since there is no overlap between the corresponding boxes. However, the boxes for NFN-MG-GP and NFN do overlap. So, a pairwise T-test has been executed, obtaining a p-value of 0.01. Since the p-value (0.01) is less than the significance level (0.05), the null hypothesis is rejected, indicating that NFN-MG-GP is statistically better than NFN to this dataset.
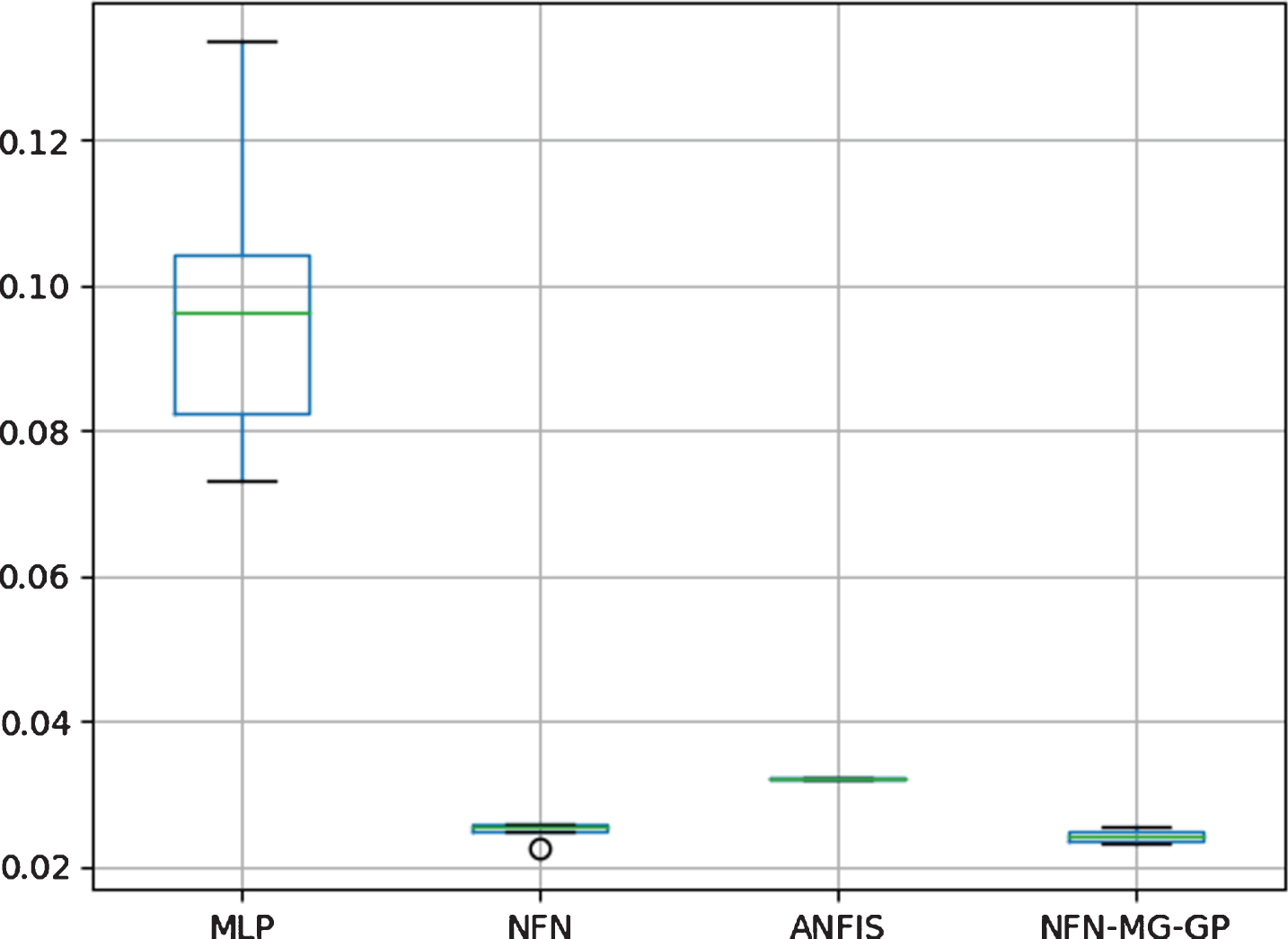
Boxplot to Streamflow forecasting.
This experiment aims to analyze the behavior of the proposed algorithms in the non-linear process identification described by:
in which y
t
= 0 and u
t
= 0 for t ≤ 3, u
t
is defined by Equation (12) for 3 < t ≤ 500 and by Equation (13) for t > 500:
The goal is to predict the current output using the delayed input and the outputs. The model for this data set is defined by:

Final membership functions for non-linear system identification by NFN-MG-GP.
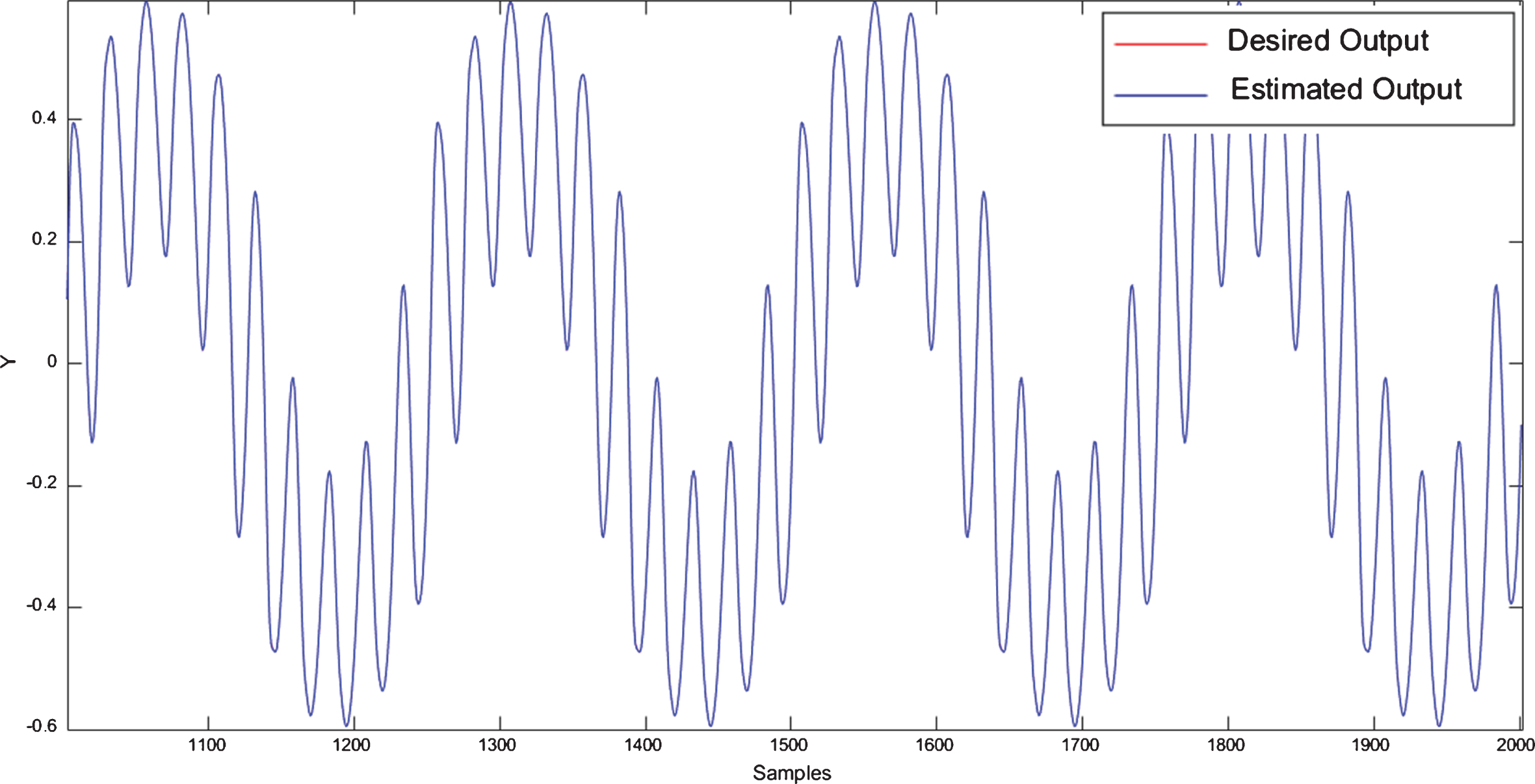
Non-Linear System Identification by NFN-MG-GP.
The RMSE performance of the modeling approaches is summarized in Table 2. They suggest that ANFIS obtains the best performance, followed by NFN-MG-GP and MLP. The results achieved by ANFIS, NFN-MG-GP, and NFN are comparable and are better than the MLP in an order of magnitude.
Non-Linear system identification performance
Figure 11 shows the boxplot to Non-Linear System Identification. It is possible to say NFN-MG-GP is statistically superior to NFN and MLP since there is no overlapping between the boxes. Using a different scale, a boxplot presenting the values for NFN-MG-GP and ANFIS are shown in Fig. 12. Since there is no overlapping between the boxes, there is a statistical difference between the two models, being ANFIS superior to NFN-MG-GP.
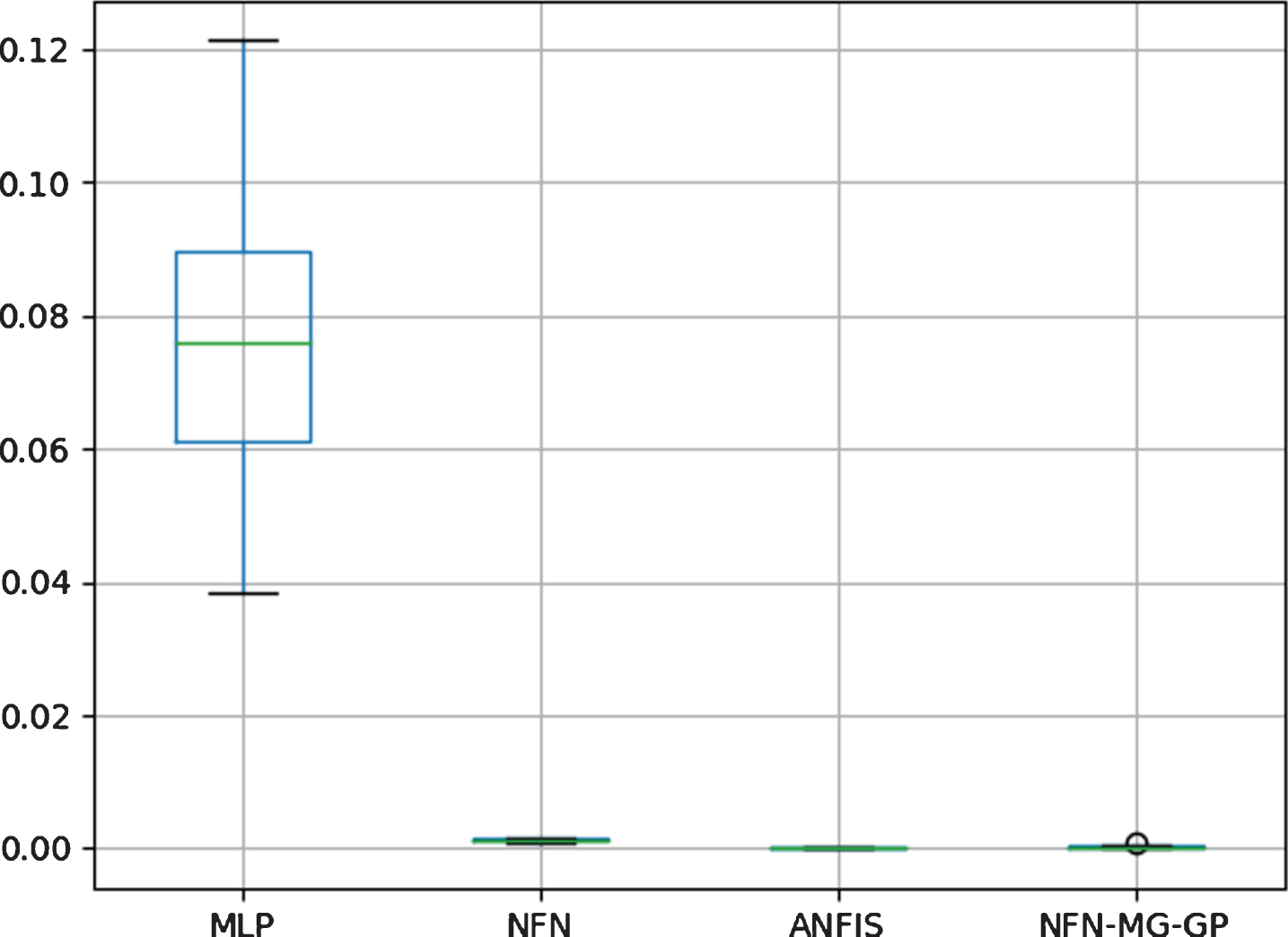
Boxplot to Non-Linear System Identification for all models.
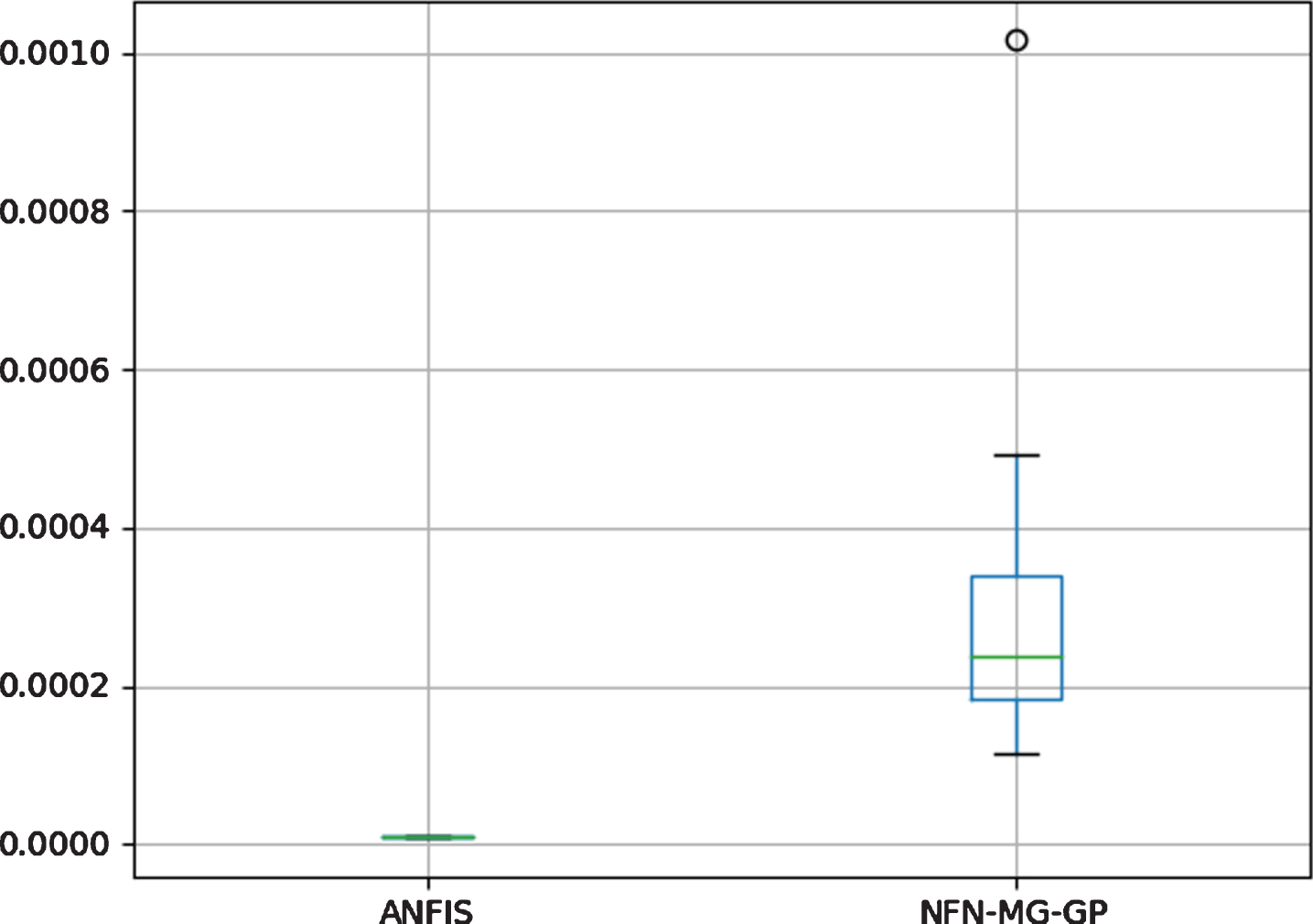
Boxplot for ANFIS and NFN-MG-GP to Non-Linear System Identification using a different scale.
This section evaluates the models to predict the temperature in Lisbon, Portugal, a region with a very varied climate throughout the year, ranging from a very cold winter with snow to a hot summer. The goal is to predict the average monthly temperature one step ahead. Previous work suggests using the first five lagged values of the series as an input [30, 48]. In this way, the model can be described by:
Data refers to the average monthly temperature from January 1910 to December 2009. The data set consists of 1,194 samples, 716 used to train the models, 239 for validation, and 239 for evaluating their performance. Figure 13 shows the membership functions generated by the NFN-MG-GP algorithm, and Fig. 14 depicts the actual value and the forecasted output by NFN-MG-GP.
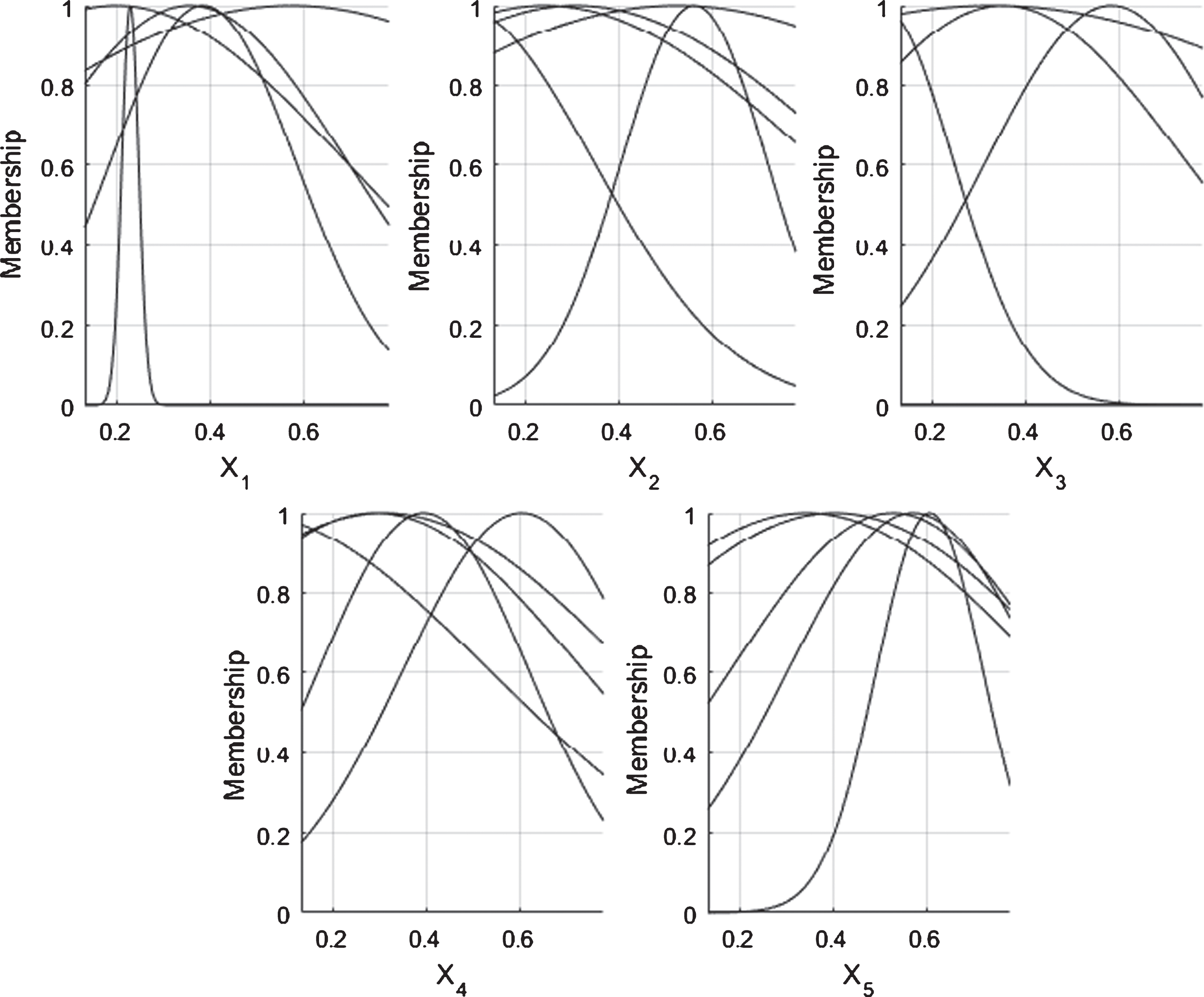
Final membership functions to temperature prediction in Lisbon by NFN-MG-GP.
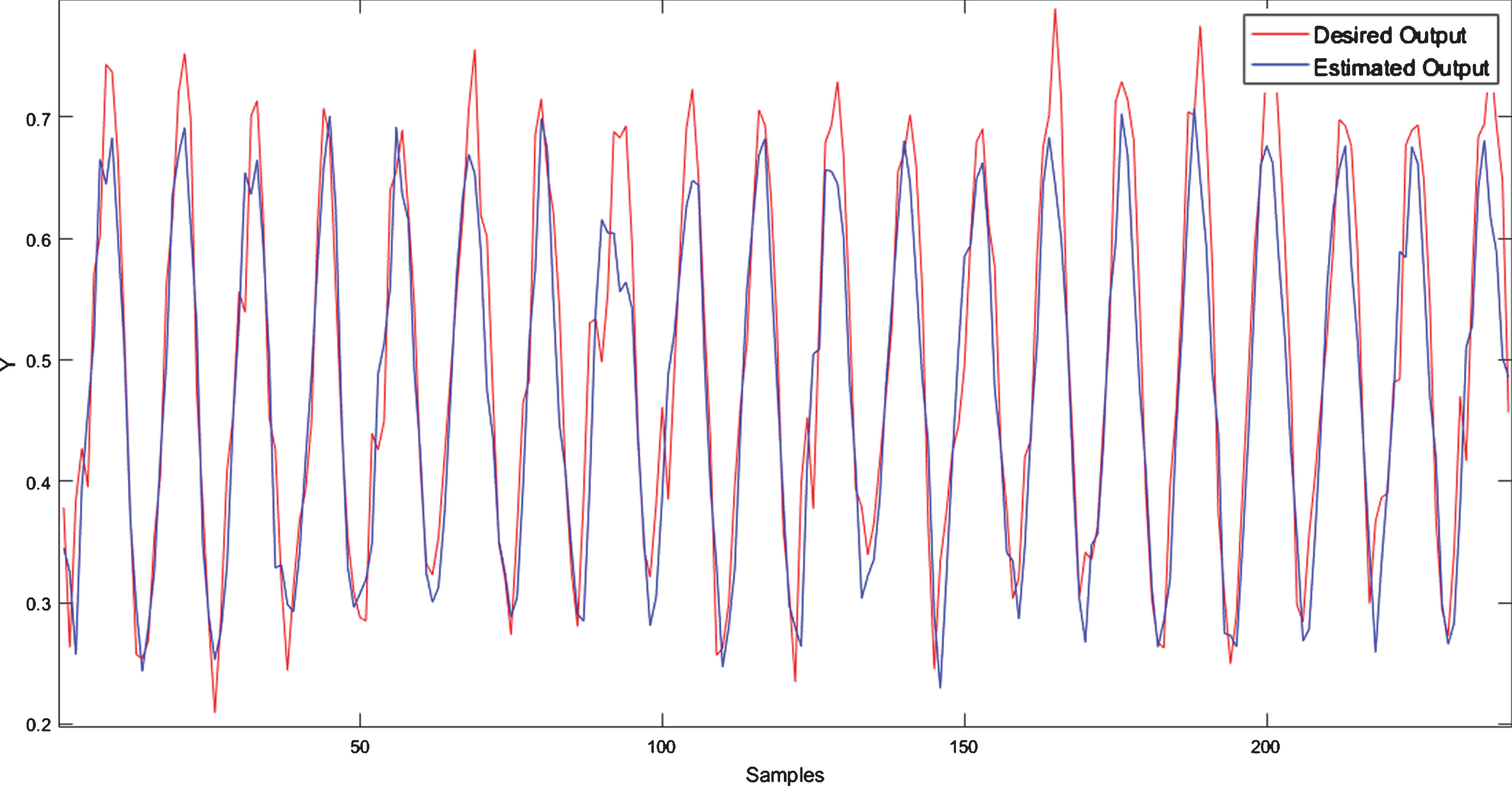
Temperature prediction in Lisbon by NFN-MG-GP.
Table 3 shows the mean and the Standart Deviation of RMSE in temperature prediction in Lisbon. The best performance is obtained by NFN-MG-GP, followed by NFN, ANFIS, and MLP.
Temperature prediction in lisbon performance
Figure 15 shows the boxplot of RMSE values for a temperature prediction in Lisbon. We can see NFN-MG-GP is better than MLP and ANFIS since any overlapping can be observed between the boxes. The one-tailed T-test between the NFN-MG-GP and NFN has been carried out. With a p-value of 0.17, the null hypothesis cannot be rejected. It indicates that there is no evidence to say NFN-MG-GP is better than NFN.
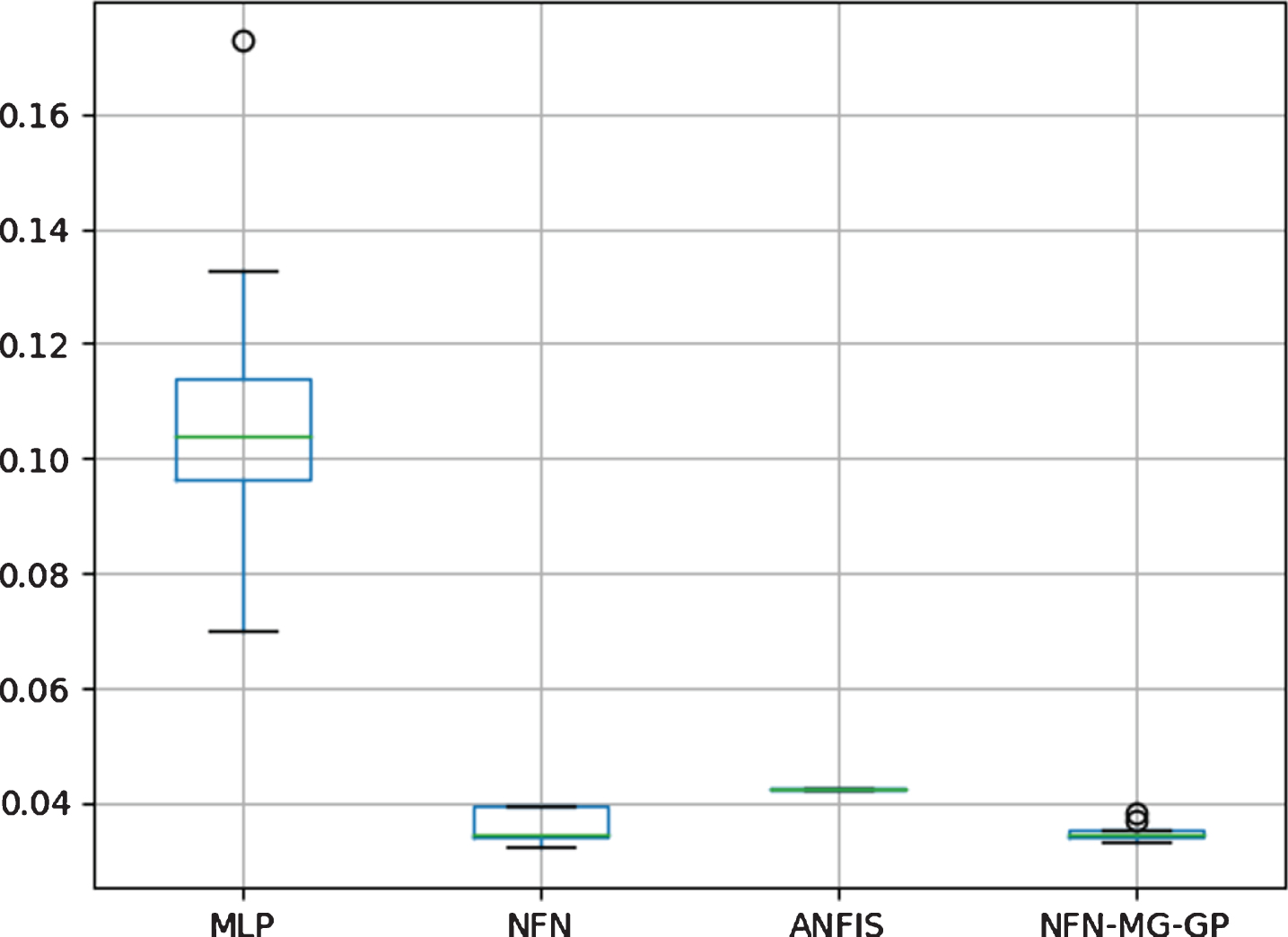
Boxplot to Temperature Prediction in Lisbon
In this experiment, the models are analyzed in temperature prediction in Death Valley, a region with an extremely dry climate and high temperatures. Such as the previous section, the goal is to predict the average monthly temperature one step ahead, according to Equation (15).
The average monthly temperature information for Death Valley spans from January 1901 to December 2009. The data set contains 1,302 samples, of which 781 are used to train the models, 260 to validate, and 261 to evaluate your performance. The final membership functions obtained by the NFN-MG-GP algorithm are illustrated in Fig. 16. Figure 17 presents the desired values and those estimated by the NFN-MG-GP for the evaluation data.
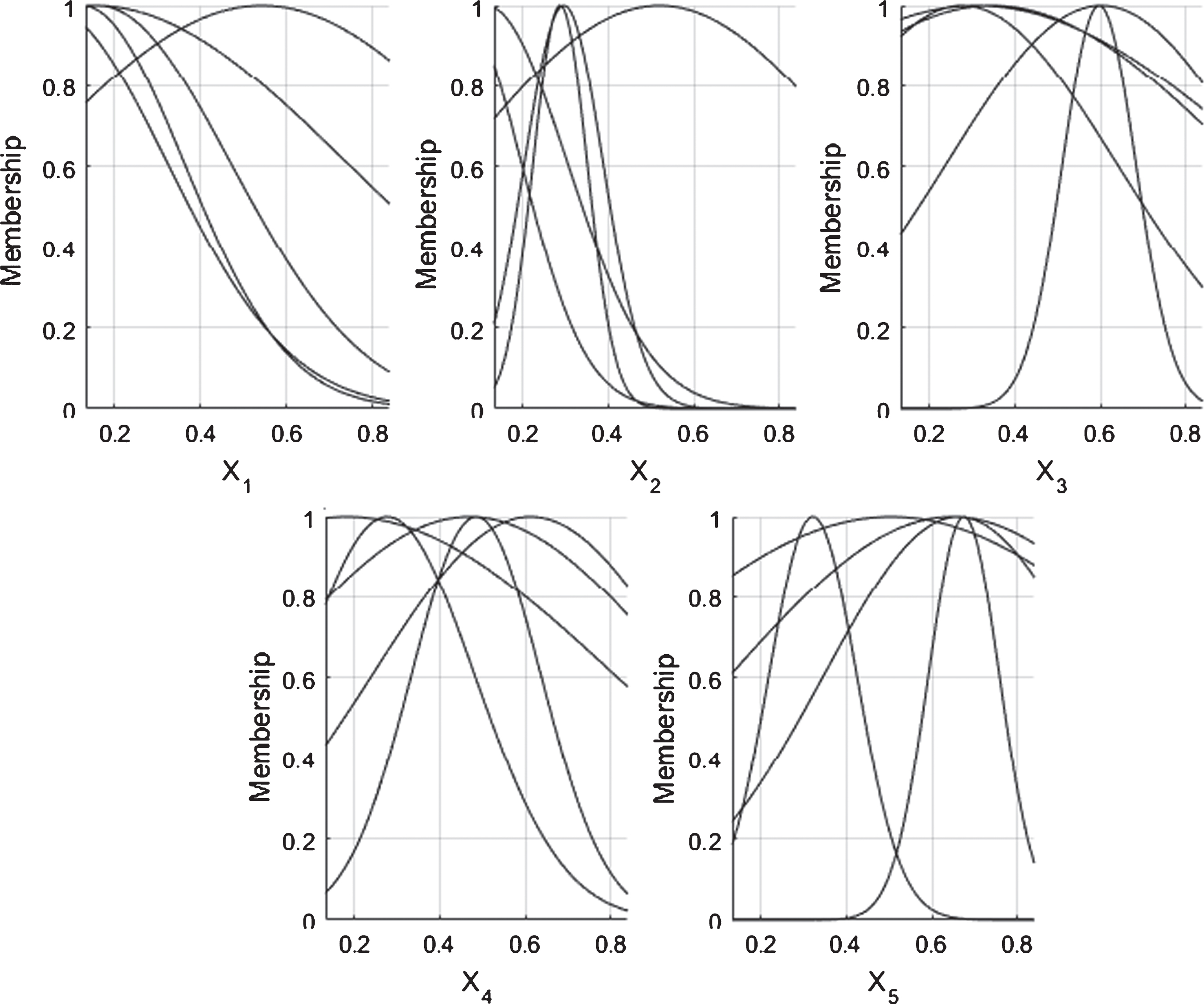
Final membership functions to temperature prediction in Death Valley by NFN-MG-GP.
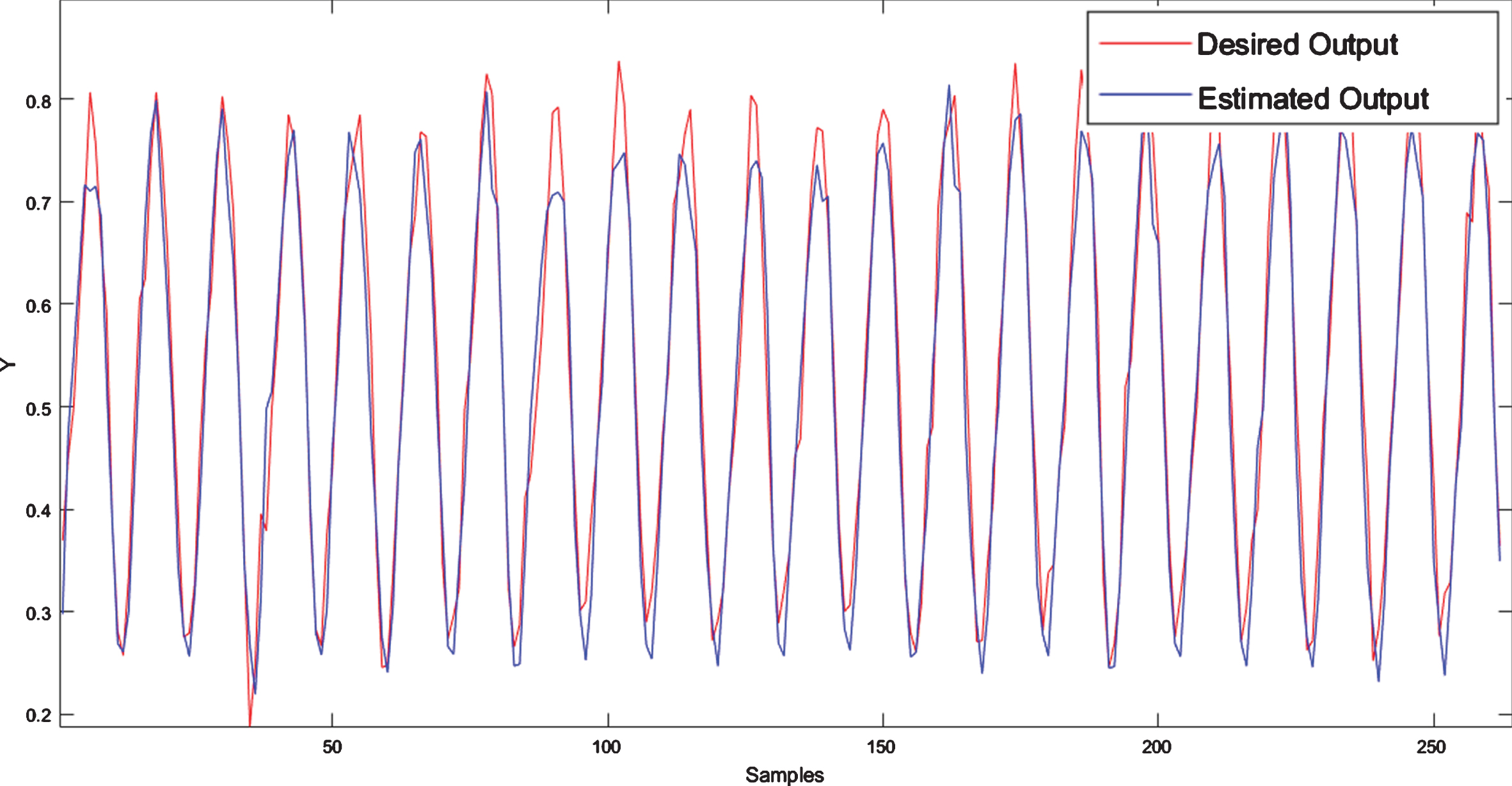
Temperature prediction in Death Valley by NFN-MG-GP.
Table 4 shows the RMSE results obtained by the models for temperature prediction in the Death Valley. The NFN-MG-GP has achieved the best results, followed by NFN, ANFIS, and MLP.
Temperature Prediction in Death Valley Performance
Figure 18 shows the boxplot for Temperature Prediction in Death Valley. As in the temperature prediction for Lisbon, we can say NFN-MG-GP is statistically superior to MLP and ANFIS. The pairwise comparison between NFN-MG-GP and NFN has been done and, since p - value = 0.0545, the null hypothesis cannot be rejected, indicating that there is no evidence to say NFN-MG-GP and NFN are statistically different.
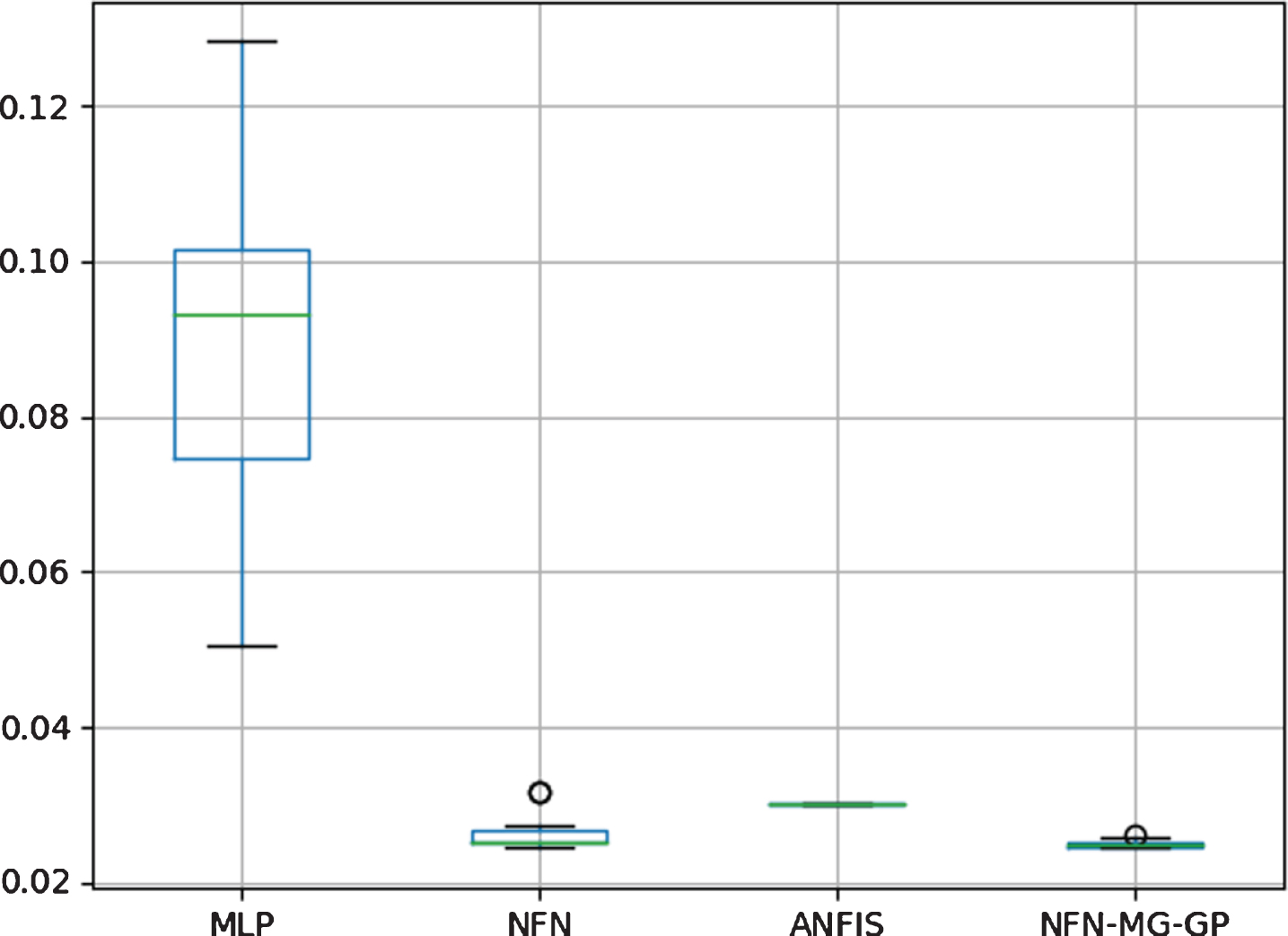
Boxplot to Temperature Prediction in Death Valley.
The results presented in this section demonstrate that NFN-MG-GP is able to reach similar or better results than alternative models. In all experiments, NFN-MG-GP showed a better performance than conventional NFN. Thus, the proposed model is efficient for forecasting and non-linear systems identification and competitive with other models. It can be observed that in some cases, some membership functions cover a similar space in the universe of discourse of the input variable. These functions can generate redundancy among rules. It can be seen as a limitation of the proposed algorithm. Despite this limitation, apparently, the performance has not been affected.
Conclusion
This work presented a novel approach to building the rule-base of the Neo-Fuzzy-Neuron network. The proposed approach uses Multi-Gene Genetic Programming to create and adjust the rule-base and a Gradient-based method to update the network parameters. Based on this approach, the algorithm NFN-MG-GP was introduced. Multi-Gene Genetic Programming demonstrated an efficient technique to create and adjust the rule-base in NFN networks. This variation of traditional GP facilities the modeling of rule-base by allowing the representation of many functions in the same individual.
Forecast and non-linear system identification application problems were used to evaluate and compare the NFN-MG-GP against current state-of-the-art modeling approaches. Simulation results suggested the NFN-MG-GP has comparable or better performance than the alternative models. The results also showed that the NFN-MG-GP presented less variance when compared with other stochastic models in most cases, which makes the results more consistent.
Future work can address Genetic Programming in network parameters updating, modeling membership functions, and network parameters as individuals from MG-GP. A strategy to eliminate redundant functions should also be studied. The generalization of the model for problems with multiple outputs is also important for future work. Besides, it is possible to consider using triangular membership functions in the NFN network.
Footnotes
Acknowledgement
The authors acknowledges CAPES, Brazilian Ministry of Education, code 001.