
Abstract
The TransR model solves the problem that TransE and TransH models are not sufficient for modeling in public spaces, and is considered a highly potential knowledge representation model. However, TransR still adopts the translation principles based on the TransE model, and the constraints are too strict, which makes the model’s ability to distinguish between very similar entities low. Therefore, we propose a representation learning model TransR* based on flexible translation and relational matrix projection. Firstly, we separate entities and relationships in different vector spaces; secondly, we combine our flexible translation strategy to make translation strategies more flexible. During model training, the quality of generating negative triples is improved by replacing semantically similar entities, and the prior probability of the relationship is used to distinguish the relationship of similar coding. Finally, we conducted link prediction experiments on the public data sets FB15K and WN18, and conducted triple classification experiments on the WN11, FB13, and FB15K data sets to analyze and verify the effectiveness of the proposed model. The evaluation results show that our method has a better improvement effect than TransR on Mean Rank, Hits@10 and ACC indicators.
Keywords
Introduction
Knowledge graph is a structured semantic knowledge base, which describes entities and their relationships in the physical world in symbolic form. Its basic components are “entity-relation-entity” triples and value pairs of entities and related attributes. Entities are connected with each other through relationships, forming a networked knowledge structure [20, 24]. The main research goal in the field of knowledge graphs is to obtain structured knowledge from unstructured Internet information, automatically integrate and construct knowledge bases, service knowledge inferences and other related applications. Among them, knowledge representation is the foundation of knowledge acquisition and application, and a key issue throughout the entire process of knowledge base construction and application. The most direct way to represent knowledge graphs is to use graph databases, but the application of this representation method to large-scale knowledge graphs has problems such as high computational complexity, low reasoning efficiency and data sparseness [21, 25]. In other words, under this kind of representation, the knowledge graph is symbolic and logical. Therefore, numerical machine learning methods and techniques cannot be applied to the knowledge graph.
In recent years, with the continuous deepening of big data research and application, the representation learning technology in artificial intelligence has emerged, aiming to represent the semantic information of the research object as dense low-dimensional real-valued vectors [22]. As a new method to support the calculation and reasoning of knowledge graph, the knowledge graph is mapped into a continuous low dimensional vector space while retaining the specific attributes of the original graph, which makes a large number of efficient numerical calculation and reasoning methods applicable. For example, TransE [5], TransH [6], TransR [13], DistMult [10], DT model [8] and so on. Among these models, TransR is considered a model with great potential. However, TransR still adopts the translation principles based on TransE, and the constraints are too strict, which makes the model’s ability to distinguish between very similar different entities low, and the model’s expressive ability is limited.
For this reason, we propose a representation learning model TransR* based on flexible translation and relational matrix projection. First, the relationship matrix projection is introduced; secondly, based on it, combined with the principle of flexible translation proposed by us to make the translation more flexible and reduce the interference of irrelevant information. At the same time, during model training, the sampling strategy of negative triples is improved, using 1-to-N and N-to-1 mapping relationships to select replacement entities, so that as many entities as possible are trained, and the prior probability of the relationship is used to solve the problem of similar coding relations. Finally, two tasks of link prediction and triple classification were performed on the sub-data sets of WordNet and Freebase, and the performance of the model was judged by Mean Rank, Hits@10, and ACC.
The contributions of this paper are as follows: (1) We propose a new knowledge representation learning model TransR*; (2) We propose a new flexible translation principle for the first time, which reduces translation constraints; (3) During model training, the quality of generating negative triples is improved by replacing semantically similar entities, and the prior probability of relationship is used to solve the problem of encoding similar relationships that are difficult to distinguish; (4) In experiments, our method outperforms the classic TransR model in link prediction and triple classification tasks.
Related work
In this section, we introduce the current typical knowledge representation learning model, and analyze its algorithm ideas, scoring function, and time complexity. In Table 1, we use N c to represent the time complexity, a lowercase letter i to represent the dimensionality of the entity embedding, a lowercase letter j to represent the dimensionality of the relationship embedding, a lowercase letter q to represent the number of nodes of the neural network, and a lowercase letter s to represent the number of tensors. A lowercase x represents the number of times to adjust the hyperparameter. A lowercase v represents the rank of the matrix. W r represents the three-dimensional tensor. M represents the matrix. A lowercase letter u means hyperparameter and a lowercase letter g represents the function.
The score function and time complexity of the knowledge representation learning model
The score function and time complexity of the knowledge representation learning model
Other models
The NTransGH model [14] combines a transformation mechanism that models a relationship as a transformation operation of a generalized hyperplane, and a neural network that captures more complex interactions between entities and relationships. The SProje model [15] introduces an adaptive measurement method to reduce the influence of noise information. On this basis, by further optimizing the loss function to increase the loss weight of the complex relationship triples. The TransGraph model [16] is based on the ability of TransE to learn the characteristics of the triplet and the knowledge graph network structure simultaneously, which enhances the representation effect of the knowledge graph effectively; in order to achieve the deep integration of network structure information and triplet information, a cross-training mechanism for vector sharing is presented. The STransH model [17] is modeled in the entity space and the relationship space, and uses the nonlinear operation of a single-layer neural network to strengthen the semantic connection between entities and relationships. At the same time, inspired by the TransH model, the mechanism of projecting to a specific relationship hyperplane is introduced, so that entities have different roles in different relationships. The SME model [3] proposes more complex operations to portray the internal connections between entities and relationships. The SE model [2] introduce a new method for automatically learning the embedding of a structured distributed knowledge base. The NTN model [6] uses bilinear vectors to replace the linear transformation layer in traditional neural networks. The Unstructured model [1] is a specific framework for performing semantic analysis on free text. The RESCAL model [9] is the representative of the matrix factorization model, which uses the matrix factorization method for knowledge representation learning. The DistMult model [10] uses embedding without explicit logical constraints to mine logical rules directly from the knowledge base. HolE model [11] proposes using holographic embedding to learn the combined vector space representation of the entire knowledge graph. The ComPlEX model [12] discusses the application of complex embeddings in low-rank matrix factorization.
Our model
In this section, we define M r as the relationship matrix, f r (h, t) represents the score function, h r and t r represent the projection vector of the head entity and the tail entity, and u represents the hyperparameter.
Our motivation
TransR model projects the head entity and tail entity of each triple (h, r, t) in the knowledge base into the relational space through a mapping matrix, so that h r + r ≈ t r (Fig. 1(a) represents the entity space, Fig. 1(b) represents the relationship space); and construct a corresponding vector space for each relationship, and separate entities and relationships in different vector spaces [13]. The TransR model solves the problem that the TransE model and TransH model may not be sufficient for modeling in public spaces. It is a very potential knowledge representation learning model. However, the TransR model still uses the translation principle of h r + r ≈ t based on the TransE model, and this constraint is still too strict. When different entities are very similar, the TransR model’s ability to distinguish between different entities is still low, which makes it less effective when dealing with complex types of relationships.
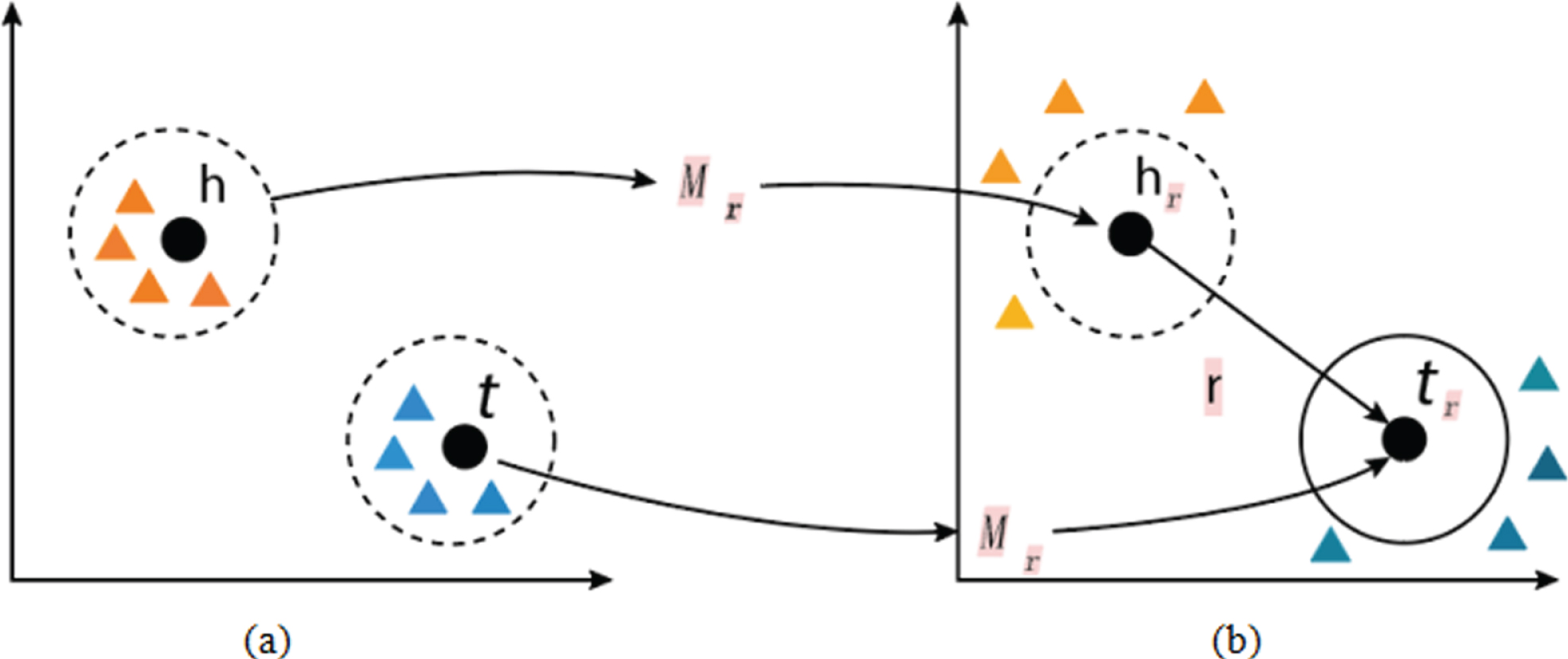
Algorithm idea of TransR model.
Where circles represent specific relational projections, and triangles represent entities that do not have h r + r ≈ t r relations. The dots refer to entities that satisfy the h r + r ≈ t r relationship.
In order to solve the problem that the TransR model has low distinguishing ability for different entities that are very similar, we propose the relational matrix projection model TransR* based on the principle of flexible translation. We put forward the principle of flexible translation for the first time, and its translation principles is: For each triplet (h, r, t), assuming that r and t are given, then we allow h to have the same direction but different sizes, and ϕ is adjusted as a hyperparameter (e.g. Fig. 2(a)); Similarly, assuming that h and t are given, we allow r to have the same direction and different sizes, and β as a hyperparameter to adjust (e.g. Fig. 2(b)); h and r are given, we allow t to have the same direction but different sizes, and λ is adjusted as a hyperparameter (e.g. Fig. 2(c)).
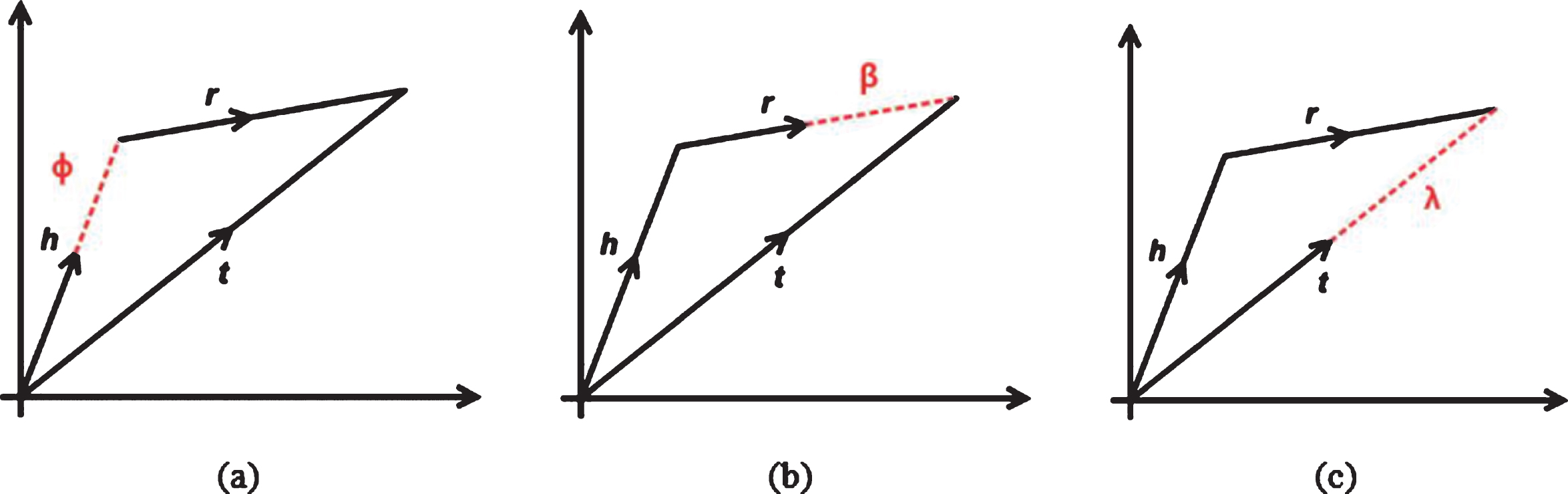
Principles of flexible translation.
Considering the problem of random errors in the experiment, it is possible that h +ϕ+ r is not enough to equal t, h + r +β is not enough to equal t, and h + r is not enough to equal t +λ. Therefore, we set three random numbers j1, j2, j3 as error adjustment. The situation after setting the random number is shown in Fig. 3(a-c):
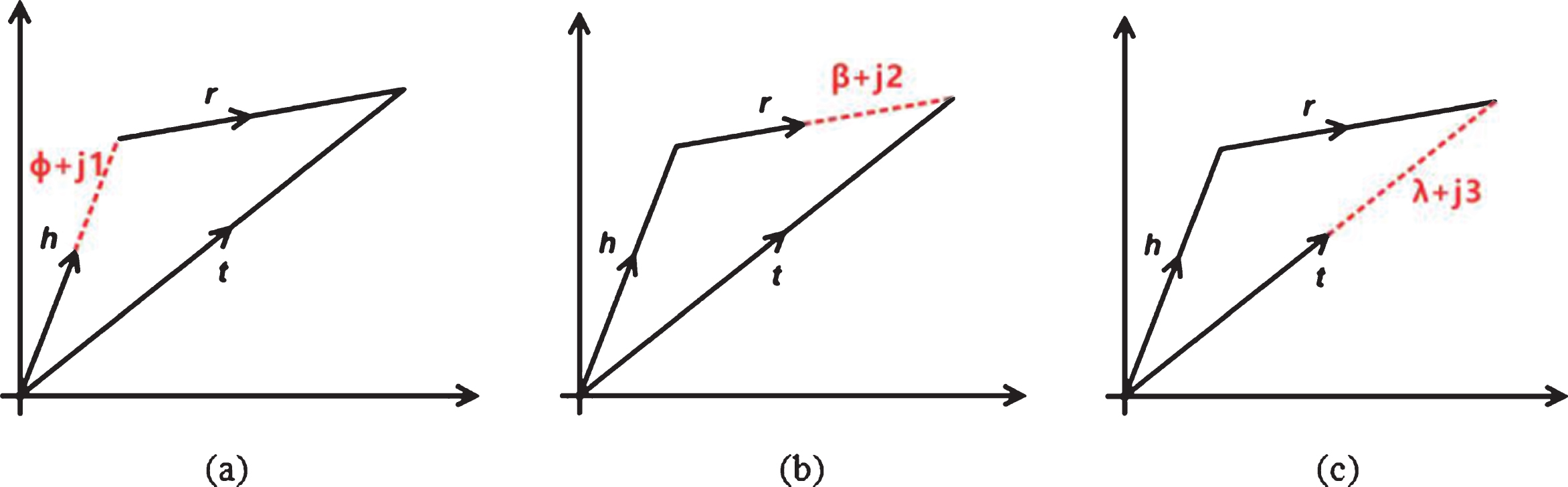
The principle of flexible translation after setting a specific range of random numbers.
In translation, the embedding of entities and relationships are in the same space. The translation principle is defined as:
Among them, ϕ, β, λ, j1, j2, j3 ɛ Rm×n. Correspondingly, the scoring function is:
On the basis of TransR model relation matrix projection, we added the principle of flexible translation proposed by us. In the relational representation space of r, for a given r and t r , the head entity is represented by h r + ϕ + j1 (e.g. Fig. 4(a)); for a given h r and t r , the relation is represented by r +β+j2 (e.g. Fig. 4(b)); for a given h r and r, the tail entity is represented by t r +λ+j3 (e.g. Fig. 4(c)). The score function of TransR* is:
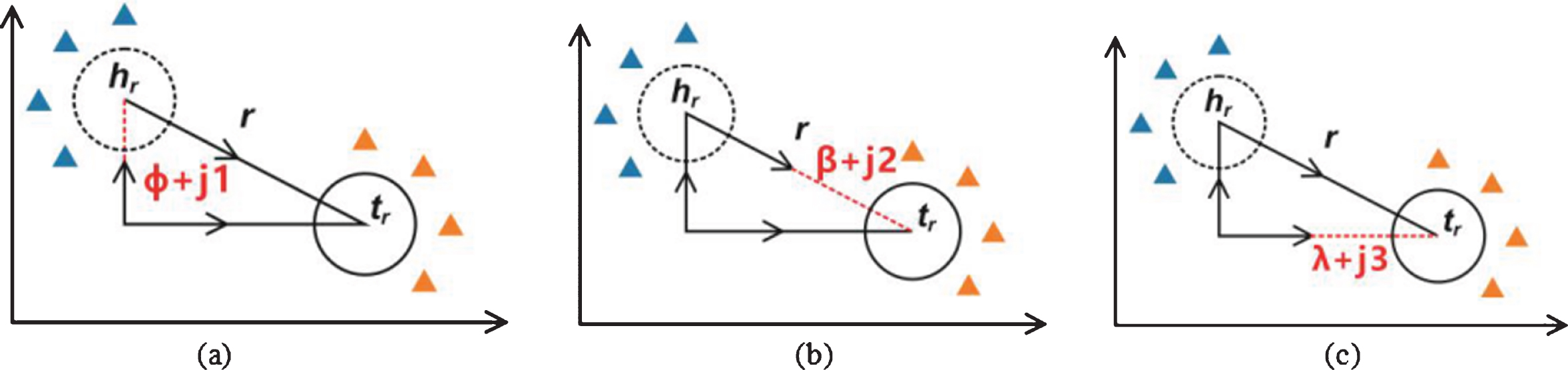
Algorithm idea of TransR* model.
In model training, constructing negative triples is an important task. The method we use is the probability method, which replaces the head and tail entities with different probabilities. When generating negative triples, the selected strategy is to replace entities for different relationship types. Specifically, for a N-to-1 relationship, choose a higher probability to replace the tail entity; for a 1-to-N relationship, choose a higher probability to replace the head entity. Since an entity contains multiple attributes, when dealing with N-to-1 relationships, replacing the tail entity can fully train multiple attributes of the tail entity; when dealing with 1-to-N relationships, replacing the head entity can also make the head entity’s multiple attributes are fully trained [17].
(1) Probability method replaces head and tail entities
During model training, we can get the following data: first, the average number of tail entities corresponding to each head entity tqh; second, the average number of head entities corresponding to each tail entity hqt. When we use the probability method, we sample according to the Bernoulli distribution of q = tqh / (tqh + hqt). When we use positive triples to construct negative triples, we replace the head entity with probability q, and replace the tail entity with probability 1-q, so that the total probability is 1, and the sampling method conforms to Bernoulli distribution. The Bernoulli distribution is chosen, because this method can bring two benefits: first, it can increase the probability of getting a positive triplet, and second, it can reduce the computational complexity.
We stipulate that when tqh < 1.5 and hqt < 1.5, then the relationship r is 1-to-1; when tqh > 1.5 and hqt > 1.5, then the relationship r is N-to-N; when tqh≥1.5 and hqt < 1.5, Then it means that the relation r is 1-to-N; when tqh < 1.5 and hqt≥1.5, it means that the relation r is N-to-1 [26].
(2) The prior probability of the relationship
We use the prior probability of the relationship to solve the problem of encoding similar relationships. That is, the more times a relationship appears, the greater the probability that the entity pair (h, t) has the relationship. Given the candidate triples (h, r, t), we determine the prior probability of the relation r by comparing the most similar relation r’ to the given relation r. The specific formula is as follows:
Where Nr is the number of times the relationship r appears in the training set, and Nr’ is the relationship most similar to the relationship r. In the model training process, in order to distinguish between positive triples and negative triples, the following margin-based loss function is used as the optimization objective function of the training model:
Where S represents the set of positive triples, the relational matrix projection S’ represents the set of negative triples, and max (x, y) refers to the larger value between x and y, γ represents the distance between the score of the loss function of the positive triple and the score of the loss of the negative triple. Therefore, the optimization goal of this objective function is to separate the positive triples from the negative triples to the greatest extent.
The running platform of this experiment is pycharm, the operating system is Linux, the development language is python, and the cpu is i7-6700HQ. On the framework, pytorch version 1.5 is selected. In addition, in order to improve the training speed of the model, this experiment chose a GTX1080 GPU with 6 G memory.
Data set
When selecting the data set, consider the need to compare the data with the classic TransE, TransH, TransR, Unstructured, SE, SME, LFM, NTN and other models. Therefore, we chose the common datasets for these models: two subsets WN18 and WN11 in WordNet [23, 27], and two subsets FB15K and FB13 in Freebase [18]. Among them, FB15K is considered to be a large data set due to the relatively large number of relations. The specific number of entities and relations are shown in Table 2.
Data set statistics
Data set statistics
Given an entity and relationship in the triplet, the purpose of the link prediction task is to predict the correct other entity [19, 28]. For example, given the head entity “United States” and the relationship “capital”, it is predicted that the tail entity should be “Washington”. Link prediction can find the missing knowledge in the knowledge graph and is an important means of knowledge completion.
When constructing the negative example triples, one entity in the original correct triples is replaced with any other entity in the knowledge graph. There is a situation: the new triples generated by the replacement originally exist in the knowledge graph. In this case, the newly generated triples may rank higher than the original correct triples, which will interfere with the prediction results. Therefore, it is necessary to remove the existing part in the newly generated triplet. This filtered experiment is called “Filter", and the experiment without removal is called “Raw".
Experimental realization. We chose some representative models as the basis for comparison, such as Unstructured, RESCAL, SE, SME, LFM, NTN, TransE, TransH, TransR etc. In the process of reproducing experiments, due to parameter settings, random initialization of parameters, and differences in the experimental environment, we did not get the best results in the references. However, considering that the same data set is used and the same indicators are selected, we directly use the best experimental data in the references. In addition, in order to reduce the impact of accidental experimental data on the experimental results, we repeated each task 10 times; then, the average of the 10 results was taken as the final result. When training TransR*, the learning rate α among {0.0001, 0.001, 0.005, 0.01}, the margin γ among {1, 1.5, 2, 3, 3.5, 4}, the embedding dimension k among {50, 100, 150, 200}, the hyperparameter μ among {0, 0.1, 0.5, 1, 2}, the random numbers j1, j2, j3 between (0.0001, 0.001), and the batch size B among {20, 50, 75, 120, 4800, 9600}. The best parameters are determined by the validation set.
Under the “unif” setting, the best configuration is: on WN18, μ= 0.1, α= 0.0001, γ= 3.5, k = 50, B = 75; on FB15K, μ= 0.1, α= 0.001, γ= 3, k = 50, B = 50. Under the “bern” setting, the best configuration is: on WN18, μ= 0.1, α= 0.0001, γ= 3.5, k = 50, B = 75; on FB15K, μ= 0.1, α= 0.001, γ= 3, k = 50, B = 50. For these two data sets, this experiment will iterate all training triples 500 times.
Link prediction experiment results
Link prediction experiment results
In order to prove that TransR* has better expressive ability and can better handle complex relationships. We conducted an in-depth analysis of the FB15K data set and found that the number of 1-to-1 relationships in FB15K reached 323, the number of 1-to-N relationships reached 309, the number of N-to-1 relationships reached 390, and the number of N-to-N relationships reached 323. Thus, FB15K can be used as a large data set. We used the optimal configuration parameters of the TransR* model on FB15K, and tested the scores of the model under the relationship of 1-to-1, 1-to-N, N-to-1, and N-to-N. From the experimental results in Table 4, it can be seen that the TransR* model achieves the best results on Predicting Left and Predicting Right, which is better than other models. Among them, TransR* reached 92.8% on the 1-to-N relationship of Predicting Left and 93.2% on the N-to-1 relationship of Predicting Right.
Hits@10 values of various relationships in FB15K(%)
Triple classification is used to determine whether a given triple (h, r, t) is correct, and its main task is to classify a triple as “correct” or “wrong” [29]. In the triple classification test, firstly, perform a classification test on the verification set, and maximize the classification accuracy for each relationship r to obtain the classification threshold σ r ; secondly, when testing the triple (h, r, t), the classification greater than the threshold σ r is positive, otherwise it is negative; in the training process, the verification set is used to test the model effect, and then the accuracy of triple classification is given on the test set.
Where T p represents the number of positive triples that are predicted correctly; T n represents the number of negative triples that are predicted correctly; N pos and N neg represent the number of positive triples and negative triples in the training set, respectively.
Classification accuracy of triples of different models (%)
We propose a representation learning model TransR* based on flexible translation and relational matrix projection, which mainly solves the problem that the TransR model has low distinguishing ability for different entities that are very similar. First, we separate entities and relationships in different vector spaces; second, we put forward the principle of flexible translation to make translation strategies more flexible. During model training, the quality of generating negative examples is improved by replacing semantically similar entities, and the prior probability of the relationship is used to distinguish the relationship that encodes similarity. Experimental results show that compared with the classic TransR model, TransR* has a significant improvement in Mean Rank, Hits@10 and ACC indicators.
Since our model does not perform well on data sets with sparse relationships, we plan to improve the TransR* model in future research. From the literature, we noticed that in dealing with data sets with sparse relationships, it is better to use similarity negative sampling methods to improve the quality of negative triples. Therefore, we can optimize the method of generating negative triples on the basis of the original model. In addition, we are not satisfied with only doing experiments on link prediction and triple classification. In the next step, we will also study the task of extracting relational facts from text and entity alignment by knowledge representation methods.
Footnotes
Acknowledgments
This research was funded by the National Natural Science Foundation of China (61966035), the Xinjiang Autonomous Region Department of Science and Technology International Cooperation Project (2020E01023), the Xinjiang Uygur Autonomous Region Postgraduate Innovation Project (XJ2019G072), and the Network Resource Management and Trust Evaluation Key Laboratory of Hunan, China (2016TP003). We thank all anonymous reviewers for their constructive comments.