
Abstract
This paper proposes a better semi-supervised semantic segmentation network using an improved generative adversarial network. It is important for the discriminator on the pixel level to know whether it correctly distinguishes the predicted probability map. However, currently there is no correlation between the actual credibility and the confidence map generated by the pixel-level discriminator. We study this problem and a new network is proposed, which includes one generator and two discriminators. One of the discriminators can output more reliable confidence maps on the pixel level and the other is trained to generate the probability on the image level, which is used as the dynamic threshold in the semi-supervised module instead of being set manually. In addition, the trusted region shared by the two discriminators is used to provide the semi-supervised reference. Through experiments on the PASCAL VOC 2012 and Cityscapes datasets, the proposed network brings better gains, proving the effectiveness of the network.
Introduction
Semantic segmentation has developed rapidly with the development of various studies and is widely used in autonomous driving, biomedical and other fields [1–4]. Although the convolutional neural network proposed based on fully convolutional neural network (FCN) [6] greatly improves the performance of semantic segmentation, it requires accurate per-pixel annotations for each training image, which will consume a lot of cost and time. In order to simplify the work of obtaining high-quality data, semi-supervised and weakly-supervised methods have been applied to semantic segmentation tasks. These methods usually assume additional annotations on the image level [7–11], box level [12, 13] or pixel level [14–17].
For semi-supervised semantic segmentation, some work uses generative adversarial network (GAN) [18, 19] which includes a generator network and a discriminator network. The generator network uses a semantic segmentation network to generate the probability maps of the semantic labels. The discriminator network generates the confidence map by distinguishing generated samples from target ones. For unlabeled data, the ground truth is obtained according to the manually set threshold and the confidence map generated by the discriminator network [20].
In this article, we focus on the discriminator network and the confidence map it generates, which supervise the generator to produce more accurate semantic segmentation results. Our work proposes a method for generating more reliable confidence maps, which is extremely important to improve the performance of semi-supervised semantic segmentation. First, for the generator network, an effective discriminator network is required to generate the reliable confidence maps, so as to further improve the performance of the generator. Secondly, for unlabeled data, it is necessary to generate the reliable pseudo label masks based on the confidence maps, which can be used to infer sufficiently close areas from the ground truth distribution. If the confidence maps are unreliable, it may generate unreliable pseudo label masks, which will affect the results of the generator.
For the image-level discriminator, its propose is to distinguish whether the generated sample is real and its output can represent the probability that the input is real. It regards generator samples as negative samples and target samples as positive samples. In most pixel-level discriminator network [20, 21], its propose should be to distinguish whether the pixels in the generated sample are real. However, regardless of whether the pixels are real or not, it is unreasonable to regard all pixels in the generated samples as negative samples. As a consequence, the pixels in the generator sample cannot be distinguished and the generated confidence map does not reflect the correct probability of the segmentation result. As shown in Fig. 1, the heat map is generated based on the overlay of the image and the confidence map. About the color of heat map, blue means low reliability and red means high reliability. According to the heat map, we can see that the value of this confidence map is generally lower and unreliable. The heat map of the second and the third columns are generated by [20] and our network respectively. Our method aims to generate the more reliable confidence maps. The probability of the confidence map is low regardless of whether the prediction is correct, which illustrates the inconsistency between the confidence map generated by the previous discriminator and the actual confidence probability. Obviously, reliable confidence maps can improve the semantic segmentation results.

Practical examples that have lower confidence in labeled pixels.
To improve the performance of semi-supervised semantic segmentation, our method focuses on the discriminator network and generates a reliable confidence map. In order to achieve this goal, we design a new discriminator network to generate confidence map, including network inputs, network structure, ground truth of confidence map and loss function. We improve the network structure of the previous discriminator to which we add the encoder-decoder structure [22, 23] on the basis of the previous network. The ground truth of the confidence map is generated based on the consistency between the generator sample and the target sample. The cross-entropy loss is used as the discriminator’s loss function. At the same time, in the semi-supervised module, the credibility threshold is determined according to another discriminator network. Finally, based on the results of the two discriminators, a common trusted region will be generated as the ground truth of unlabeled data.
In summary, the contributions of this work are the following: We propose a semi-supervised semantic segmentation network, which is the first network to solve the problem of confidence map and ground truth of unlabeled data. It explores a new direction for semi-supervised semantic segmentation by GAN. By considering the credibility of the confidence map, the semi-supervised semantic segmentation result on mIOU is 2.1% higher than [20]. For the discriminator network, we improve the structure of the discriminator, which uses the encoder-decoder structure and the proposed new loss function to generate a more reliable confidence map. The experimental results show that the results after using the discriminator branch are positively correlated with the true confidence. For the generator network, we use deeplabv3 + [24] network instead of deeplabv2 [25] as the semantic segmentation network to further improve the performance of the generator network. For the semi-supervised module, we use the other discriminator to generate the total probability as threshold on the image level. Based on the confidence map and the probability as threshold generated by the two discriminators, a common region is used to obtain more reliable ground truth for unlabeled data. Experimental results on the PASCAL VOC 2012 [26] and Cityscapes [39] datasets validate the effectiveness of the proposed semi-supervised semantic segmentation network using GAN.
However, for segmentation ground truth, labeling pixel-level images is very difficult. In order to reduce labeling costs, many studies on weak supervision and semi-supervision have been proposed in recent years. The method in [5] proposed a decoupled deep neural network to solve this problem.[23] defined revisiting dilated convolution to apply to semi-supervised semantic segmentation. The method in [29] explores the relationship between image label and segmentation. [30] refines the segmentation by fusing object localization. Moreover, in order to make up for the loss of detailed boundary information caused by less marking information, some researches raise semi-supervision. [31] and [32] get semantic segmentation by using generative adversarial network with a few fully-annotated images.
Method
Motivation
When using GAN for segmentation tasks, the discriminator needs to supervise the generator to generate more realistic data through the output confidence map. For unlabeled data in semi-supervised learning, the pseudo label mask is generated based on the confidence map generated by the discriminator, so the reliability of the generated confidence map is very important. However, the value of confidence map generated by the current discriminator does not reflect the probability of whether the pixels are real. To quantify this problem, we compare the confidence probability of the discriminator output in [20] with the true confidence probability. Specifically, we conduct experiments using the network [20] with 1/8 images as labeled data on the PASCAL VOC 2012 validation dataset. The distribution of the predicted probability for each pixel in the confidence map output by the discriminator and the distribution of true confidence probability is shown in Fig. 2(a). Probability represents the value for each pixel on each confidence map. Proportion indicates the percentage of pixels that actually predicted correctly or incorrectly. TPred denotes that the pixel on the predicted label map is true, which is the same as the one on the ground truth label map, otherwise expressed by FPred. We can see that the actual number of correct pixels is relatively high when the predicted value is low. This indicates that the score of the confidence map generated by the discriminator is inconsistent with the true confidence probability.

Relationship between the probability distribution of the confidence map and the true probability proportion in [20].
In applying GAN to segmentation and semi-supervised learning, if an unreasonable reference probability map is used to train the discriminator, the confidence map generated by the discriminator cannot represent the prediction probability on the pixel level probability. This motivates us to generate more realistic confidence maps based on reliable reference. Thus, we propose a new network which improves the structure of the discriminator network and learns a more reliable confidence map. The distribution of the pixels’ probabilities in the confidence map generated by our framework is shown in Fig. 2(b), which is proportional to the proportion of actual correct predictions.
Based on the semi-supervised semantic segmentation network [20], the overall structure after adding the new discriminator network is shown in Fig. 3. Assume that the above discriminator network is known as D1 and the other discriminator network is called as D2. We will present the details of our framework in the following sections.
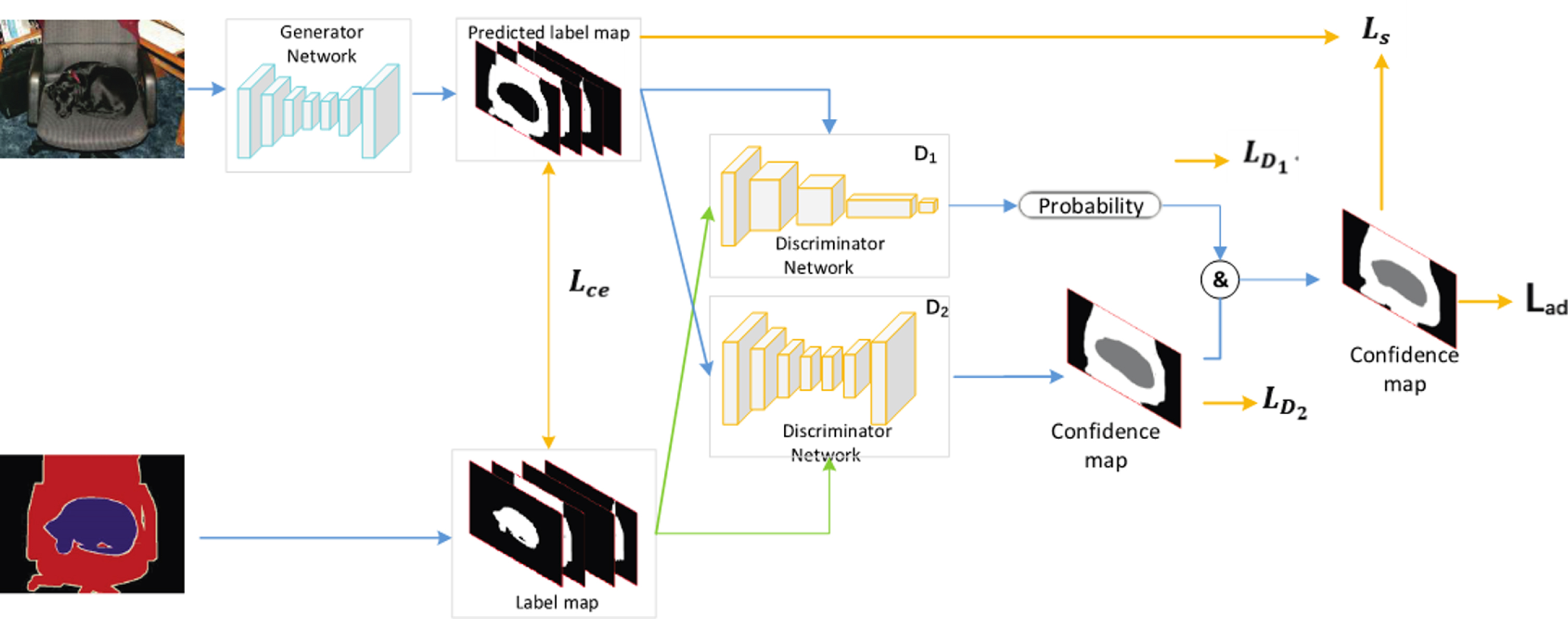
Network architecture of the proposed semi-supervised semantic segmentation.
Define the size of the input RGB image X n as H × W × 3 and we use G (X n ) to denote the class probability map over C classes of size H × W × C that the generator network produces, with the input given X n . We denote one discriminator network as D1 (·) that outputs 0 or 1 and the other discriminator network as D2 (·) that outputs the confidence map of size H × W × 1. L n is the ground truth label map of X n , of which the size is H × W × 1 and the pixel values represent the categories they belong to. Y n of size H × W × C is the ground truth of L n after one-hot encoding.
a) Referenced confidence map: We define C map as the confidence probability of the generator output G (X n ). The discriminator is used to judge the credibility of the predicted label map generated by the generator, thus the output of the discriminator is represented by a confidence map. The output of the generator is selected to the category corresponding to the maximum probability, then a pixel-level prediction label map can be obtained. The resulting predicted label map is defined as:
That is, the confidence map is based on whether the predicted label map is consistent with the ground truth, so that each pixel is binarized.
b) Loss function: When using GAN for classification tasks, the discriminator network acts as a classifier by using the 0-1 distribution as the overall distribution just like D1. The discriminator maximizes the probability of real images and minimizes the probability of generated images, so the probability represents the similarity between the generated image and the ground truth distribution. Nevertheless when GAN is used in semantic segmentation, the discriminator D′ in [20] used it on the pixel level, and the loss function of the discriminator is:
y n = 0 if the sample is drawn from the generator network and $y n = 1 if the sample is from the ground truth label. But semantic segmentation is aimed at single pixel, it needs to get the confidence probability of each point. The overall distribution does not reflect the distribution of individual pixels. Take generator samples for example, some works like [20] use 0 as the reference value to calculate the loss function no matter the prediction is truth or false. As a result, the probabilities of the pixels cannot be regressed correctly, so the confidence map output by the discriminator is inaccurate. Therefore, in this paper, C map is used as ground truth and the cross-entropy loss is used to regress the pixel-level probability. The loss function is:
In the discriminator module, we use the above two discriminators. One is to classify input images as true or false on the image level. The other is to infer the correct probability on the pixel level. Combining the two discriminators above, we give the adversarial loss:
Assume G″ (Xn) (h,w,c) is the one-hot encoded label map of G′ (Xn) (h,w), then G″ (Xn) (h,w,c) = 1 if c = G′ (Xn) (h,w). The ground truth of unlabeled data
For the generator’s loss, we apply a wghted hybrid loss function which includes the multi-class cross entropy loss L ce ., adversarial loss provided by discriminator L ad and semi-supervised loss L s . λ ad and λ s are two weights for minimizing the proposed multi-task loss function. The minimized objective function to be trained is:
We conduct experiments on PASCAL VOC 2012 and Cityscapes segmentation datasets, and we use the mean intersection-over-union (mean IOU) as the evaluation metric. We follow the PASCAL VOC 2012 settings, using the 10,582 images train split for training, and the 1449 images validation split for validation. For Cityscapes dataset, the number of annotated images for training, validation and testing are 2975, 500, 1525 respectively. Besides, the number of classes in PASCAL VOC 2012 and Cityscapes are 20 and 19 respectively.
Implementation details
We complete experiments based on the [20]. For PASCAL VOC 2012 dataset, during the training, input images are resized to 321 × 321 by random scaling and cropping and we train all the networks for 20k iterations with batch size 10. For Cityscapes dataset, the size of input images is 512 × 1024 and we set the number of iterations to 40k and the batch size is 2 during training.
For the generator network, we use ResNet-101 as the backbone and set the initial learning rate as 0.001. Stochastic Gradient Descent (SGD) [37] with momentum 0.9 and weight decay 10-4 is used as the optimizer. For the discriminator training which include two discriminators D1 and D2, the learning rates are both 10-4 using Adam optimizer [38]. For training semi-supervised module, we randomly divide the training dataset into labeled data and unlabeled data. Train the generator and the discriminator when using labeled data and train only the generator network when using unlabeled data. About hyper-parameters, we set λ ad as 0.01 and λ s as 0.1.
For the training process, we first train the generator and discriminators with the labeled images for 5000 iterations. Then we fix the parameters of discriminators and train the generator with the unlabeled images. As described in Section 3, the pseudo label masks are generated from the outputs of the two discriminators.
Experimental results
For semi-supervised validating, we randomly take 1/8, 1/4, and 1/2 amount of pictures as labeled data and the other as unlabeled data. We use our proposed generator network as baseline. We compare the results between [20] and our baseline to prove that our baseline model has better performance.
As shown in Table 1, it shows the results on PASCAL VOC 2012 dataset. Our baseline gets stable improvement (about 1.5%) in mean IOU. Besides, we experiment the discriminator D′ in the [20] and the discriminator D2 we proposed on different baselines. The highlighted results shown that our discriminator D2 can achieve stable improvement on distinct baselines and can improve the baseline from 1.3% to 3.1%. Furthermore, for the combination of baseline and discriminator, the mIOU of our proposed network is about 1.5% higher than that of [20].
Comparison of the baseline and discriminator on pascal voc 2012 validation results
Comparison of the baseline and discriminator on pascal voc 2012 validation results
Table 2 shows the results on Cityscape dataset. Both our baseline and discriminator have consistent performance with these on PASCAL VOC 2012. The baseline has about 1% increase over the baseline in [20]. The proposed discriminator D2 improve 0.8% to 1.9% gain over the baseline and the network achieves about 1% gain in mIOU over [20].
Comparison of the baseline and discriminator on Cityscapes validation results
Table 3 reports the effects of different modules on performance on PASCAL VOC 2012. For the discriminator D1, it has small improvement like most image-level discriminators [32]. About the semi-supervised module, we first manually set the threshold to 0.9 when the discriminator module D1 is not used in experiments. The proposed semi-supervised learning module brings overall 0.8% to 2.1% gain. As the experimental results show, using the output probability of discriminator D1 as the dynamic threshold, the performance is better than the static threshold which is set manually and the segmentation results achieve about 0.5% gain. Table 4 shows the performance of each modules. Both the discriminator D1 and semi-supervised method have positive improvement on performance. They both achieve the performance gain from 0.3% to 0.5%.
Comparison of the different combinations we proposed on PASCAL VOC 2012 validation results
Comparison of the different combinations we proposed on Cityscapes validation results
Figure 4 shows the results of different combinations generated by the proposed method. We can find that the combination of D1, D2 and semi-supervised module gives the most accurate and detailed results. Moreover, as shown in the Table 5, compared with [20], our network improves the overall performance by 2% in semi-supervised semantic segmentation.

Visual results on the PASCAL VOC 2012 dataset using 1/8 labeled data.
Performance comparison of semi-supervised semantic segmentation with [20] on the PASCAL VOC 2012 validation set
C classes prediction maps. C classes prediction maps concatenate RGB images: All the C classes prediction maps are concatenated with RGB images. Label map concatenates RGB images: The label map of the target class is taken and concatenated with the RGB images. C classes prediction maps multiply RGB images: All the C classes prediction maps are multiplied with the RGB images.
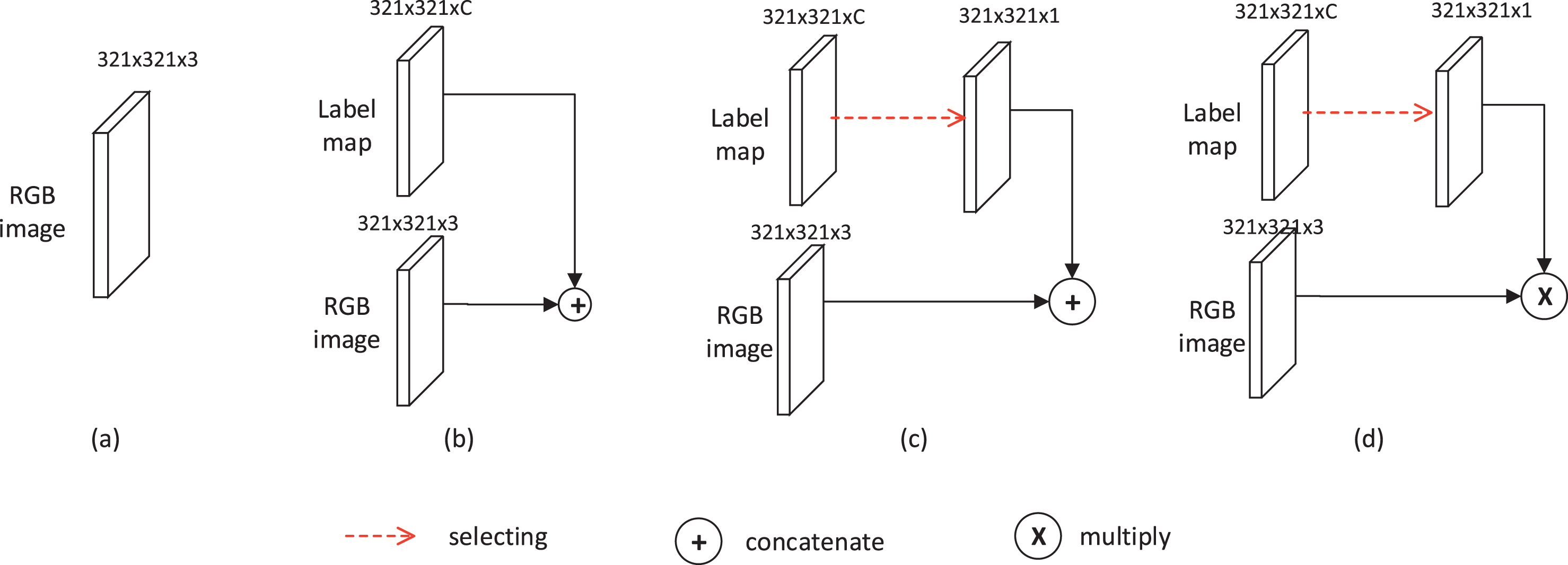
Designs for input of discriminator.
The results are shown in Table 6. We observe that the performance of various designs is improved compared to the baseline and the four designs have little effect on performance. In conclusion, we use the choices of C classes prediction maps because of its best results.
Results of designs for the discriminator D2 input
output stride is 16 and up-sampling factor is 16. output stride is 4 and up-sampling factor is 4. output stride is 16 and up-sampling factor is 2. output stride is 16 and the up-sampling factor is 4.

Designs for structure of discriminator.
Table 7 shows the results for the above discriminator network. By comparing the results, we can find that the third and the fourth network structures are better than the first two. At the same time, using the third network with the output stride = 16, the performance can be improved by the third one but the computational complexity will be increased. Thus, the last decoder structure is used as our default choice.
Results of structures for the discriminator D2
Results on hyper parameter
In this paper, we propose an improved network structure for semi-supervised semantic segmentation which focuses on the confidence map of discriminator output and the ground truth of unlabeled data. By adding a new discriminator network branch, a more reliable confidence graph is generated and the performance of semi-supervised semantic segmentation is superior to the compared one. For the semi-supervised module, we replace the manual threshold setting method with the output probability of the other discriminator output, which further improves the performance. A large number of experiments on the PASCAL VOC 2012 dataset confirm the effectiveness of the network.