
Abstract
Named entity recognition (NER) is fundamental to natural language processing (NLP). Most state-of-the-art researches on NER are based on pre-trained language models (PLMs) or classic neural models. However, these researches are mainly oriented to high-resource languages such as English. While for Indonesian, related resources (both in dataset and technology) are not yet well-developed. Besides, affix is an important word composition for Indonesian language, indicating the essentiality of character and token features for token-wise Indonesian NLP tasks. However, features extracted by currently top-performance models are insufficient. Aiming at Indonesian NER task, in this paper, we build an Indonesian NER dataset (IDNER) comprising over 50 thousand sentences (over 670 thousand tokens) to alleviate the shortage of labeled resources in Indonesian. Furthermore, we construct a hierarchical structured-attention-based model (HSA) for Indonesian NER to extract sequence features from different perspectives. Specifically, we use an enhanced convolutional structure as well as an enhanced attention structure to extract deeper features from characters and tokens. Experimental results show that HSA establishes competitive performance on IDNER and three benchmark datasets.
Keywords
Introduction
Named entity recognition (NER) plays a basic role in natural language processing (NLP) [1] which is designed to identify the spans of entities and classify them into pre-defined categories. It is fundamental to many advanced NLP tasks such as machine translation and knowledge graph construction [2]. With the rapid development of deep learning, many neural methods are proposed for NER task. However, these methods rely heavily on abundant labeled data, thus most state-of-the-art researches are mainly oriented to high-resource languages such as Chinese [3–5] and English [6–9]. There are few studies on low-resource languages represented by Indonesian [10]. Most current methods for Indonesian NER are still based on rules and machine learning (ML) [11–14].
Some previous studies have presented their efforts on the construction of Indonesian NER datasets [13, 15–17], however, these datasets are not satisfactory both in size and quality. Limited labeled resource leads to limited language technology development in Indonesian. To ease this situation, we build a large Indonesian NER dataset (IDNER) from Indonesian news comprising over 50,000 sentences and explore the impact of corpus size for Indonesian NER model.
Current NER methods can be divided into two categories: (1) fine-tuned pre-trained language models (PLMs) such as deep neural models [7, 25] and transformer-based models [8, 39–42]; (2) classic neural models such as Bi-LSTM-CNNs-CRF [6, 18–22]. Unfortunately, both these two methods have their own shortages on NER task. Fine-tuned PLMs focus more on the acquisition of contextual information, which is crucial for NER task. However, NER is a token-wise task, where token and character features are of great significance and necessity. Especially for Indonesian language, it is an agglutinative language. As such, affix is an important word composition for Indonesian language that new words exist by adding one or several (less than three) affixes to a base word. The affixes can be the host of proclitic, enclitic and particle. Figure 1 shows the morphological structure of an Indonesian word. Therefore, how to fuse fine-tuned PLMs with an efficient token feature extractor as well as character feature extractor are of great essentiality. In classic neural models, convolutional neural network (CNN) is a superior character feature extractor [23], which can effectively solve OOV (Out of Vocabulary) problem. However, CNNs can only extract local optimal features. It is insufficient for global character features extraction such as circumfixes (such as ke...an) in Indonesian. Bidirectional long short-term memory (Bi-LSTM) can obtain global features but lacking of local optimal features. These problems may negatively affect the performance of the NER models. Attention mechanism [31] is proven to be effective in many NLP tasks, but we argue that simple 1-dimensioanal (1-D) attention layer is insufficient for the learning of different tokens and characters in NER task. The deficiency of 1-D attention vector is that it only focuses on one or a few perspectives of the characters and tokens [24], with the result that different semantic aspects of the characters and tokens are missed, leading impaired effect on NER models.
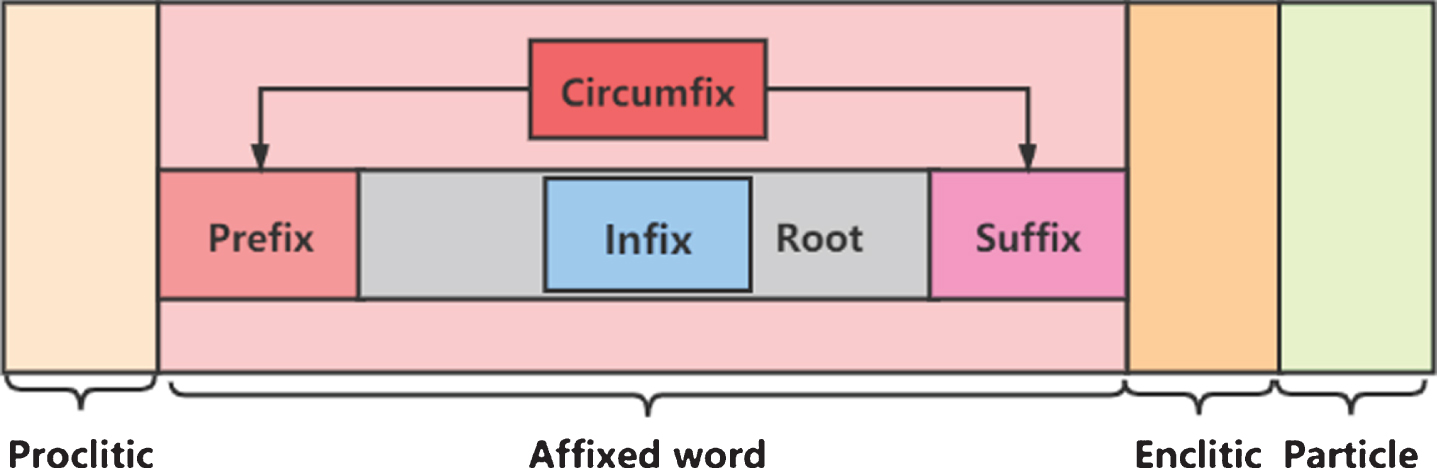
The morphological structure of an Indonesian word.
To this end, we propose a hierarchical structured-attention-based model (HSA) for Indonesian NER, where semantic and syntactic features of a given input sequence can be simultaneously captured from different perspectives. Specifically, we employ an enhanced convolutional structure named residual gated convolution neural network (RGCNN) and an enhanced attention structure (structured-attention) with two pooling strategies (average and max pooling) to extract sequence features. It is worth to note that our model is closely related to AMFF [22], with mainly three improvements: (1) Unlike the work in [22], which directly extracts global word features and local word features from pre-trained word vectors and then feeds them into a Bi-LSTM layer, we argue that these features should be relative to the input sequence, so extracting token features of different levels through the attention mechanism over the hidden states in Bi-LSTM layer is more helpful to the NER task; (2) Using structured-attention with different pooling operations is more efficient and effective than the simple attention mechanism: average pooling can keep more global background knowledge of the input sequence for the tokens, and max pooling can perform feature selection to retain the local optimal features of the input sequence for the tokens; (3) Because Indonesian NER task is more sensitive to character features, we use enhanced convolutional structure and attention structure to extract character features.
In summary, the contributions of this paper are: (1) we construct a large Indonesian NER dataset to alleviate the insufficient labeled resource for Indonesian; (2) we construct a hierarchical structured-attention-based model (HSA) for Indonesian NER to make use of multi-perspective sequence features; (3) HSA establishes comparable performance on three Indonesian benchmark datasets and IDNER.
The remainder of the paper is organized as follows. Section 2 briefly presents some related work to Indonesian NER. In Section 3, the process of building Indonesian NER dataset is described. Next in Section 4, our NER model is introduced. In Section 5, we present the experiment setting and analysis the experimental results. Finally in Section 6, we give some conclusions and remarks.
Top-performance NER
Many researchers are focusing on NER in high-resource language such as English. Current NER methods can be divided into two categories: fine-tuned PLMs [7, 39–42] and classic neural models [6, 18–22]. Fine-tuned PLMs focus more on extracting contextual information that is crucial for NER task. Akbik et al. [9] propose a pooled contextualized embedding approach for NER in FLAIR 1 framework. Matthew et al. [7] apply ELMo that based on a two-layer Bi-LSTM to NER task. Transformer-based PLMs [8, 39–42] are also widely applied for fine-tuned NER models. They all achieve superior performance on CoNLL datasets [25]. Classic NER techniques [6, 18–22] use a combination of pre-trained word embeddings [11, 12] and character embeddings derived from a CNN layer or Bi-LSTM layer. These features are passed to a Bi-LSTM layer, which may be followed by a CRF layer [6, 18–20].
Indonesian NER
Indonesian NER itself has attracted many years of research. It can be devided into three categories: (1) rule-based method; (2) ML method; and (3) neural method.
Dataset construction
As the basis of NLP research, dataset construction is significant. However, existing Indonesian datasets cannot meet the requirements of deep learning technology in terms of size and quality. For the follow-up study, we focus on three entity types
An Indonesian annotation example
An Indonesian annotation example
Statistics of IDNER
Fully human annotated datasets for NER are expensive and time-consuming which are therefore relatively small. Distant supervision [29], a technique which uses existing knowledge bases as the source of weak supervision to automatically annotate datasets, can well reduce the burden of manual annotation. Based on distant supervision, we collect a large number of entity instances from different sources such as DBPedia, and then link these instances into raw text to construct a preliminary NER dataset. However, the dataset labeled with distant supervision method often suffers from low recall and mislabeling errors. For further optimization, we iteratively revise the corpus based on manual audit.
Data source
We use Indonesian news articles to construct the dataset because of its convenient availability and huge amount. To obtain attested Indonesian data, we crawl articles from Indonesian news websites whose content covers various topics including politics, finance, society, military, etc. The websites are shown in Table 3. After separating paragraphs into individual sentences, we randomly select 60,000 sentences as our corpus to be annotated. After iteratively training and audit, we discard some sentences that do not contain entities. Altogether, the dataset has 50,098 sentences.
Indonesian news websites
Indonesian news websites
This section briefly introduces the construction process of our dataset, which contains six steps (shown in Fig. 2).
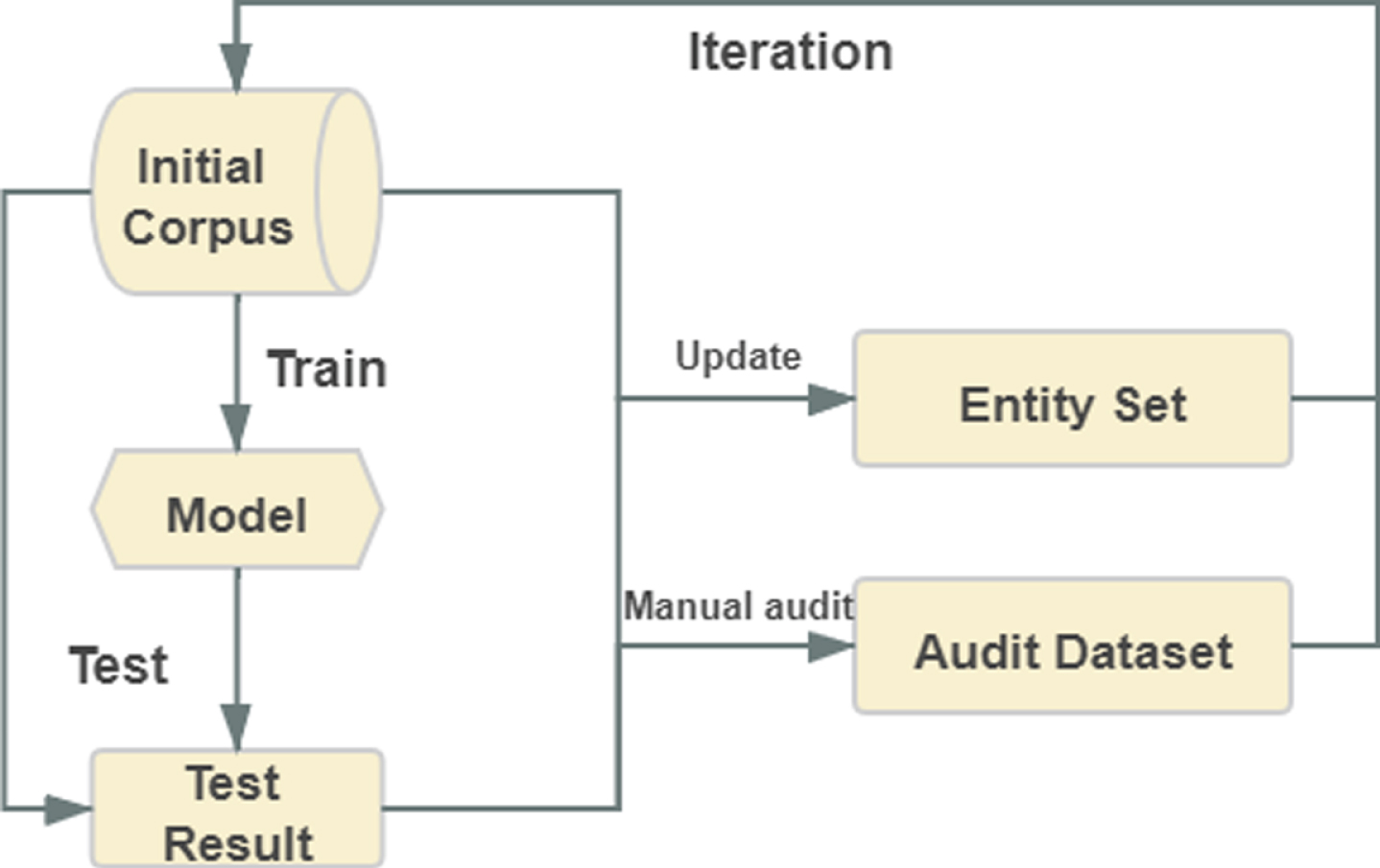
Process of IDNER Construction.
DBPedia Indonesia
3
provides various structured information from Indonesian Wikipedia. DBPedia Indonesian describes 19,567 persons, 57,702 locations and 5,773 organizations. To expand more entity instances, we crawl entities instances from DBPedia as well as other sources (such as travelling websites, Indonesian textbooks, etc.). At last, 20,126 person instances, 57,702 location instances and 6,547 organization instances are collected. Based on the idea of distant supervision, we construct a preliminary NER dataset. In nested entity cases, we take the outermost (with the max length) entity as the label and discard the inner entity labels. The corpus constructed in this way often suffers from mislabeling problems and boundary errors. All picked sentences (60,000 sentences) are used for both model training and testing. Sentences with different labels in training and testing phases are manually audited. For each sentence to be audited, two auditors are engaged in to ensure the quality of the audited sentences. If two audit results conflict, ask another auditor to check the results. The new entities extracted during the audit process are added to the entity set. Then the entity set is used to re-align the whole dataset. The re-aligned dataset is put into the model for an iterative training and testing. Three iterations are processed.
Model
This section will introduce the proposed model for Indonesian NER.
NER can be formulated as a sequence labeling problem. Give an input sentence S which composed of n tokens {w1, w2, w3, … , w n } and its corresponding labels {l1, l2, l3, … , l n }, the proposed model is to infer the entity label l i for each token w i and output a label sequence. Figure 3 gives an overview of our proposed model, consisting of three main components: (1) Character Encoder; (2) Word Encoder; and (3) CRF Decoder.
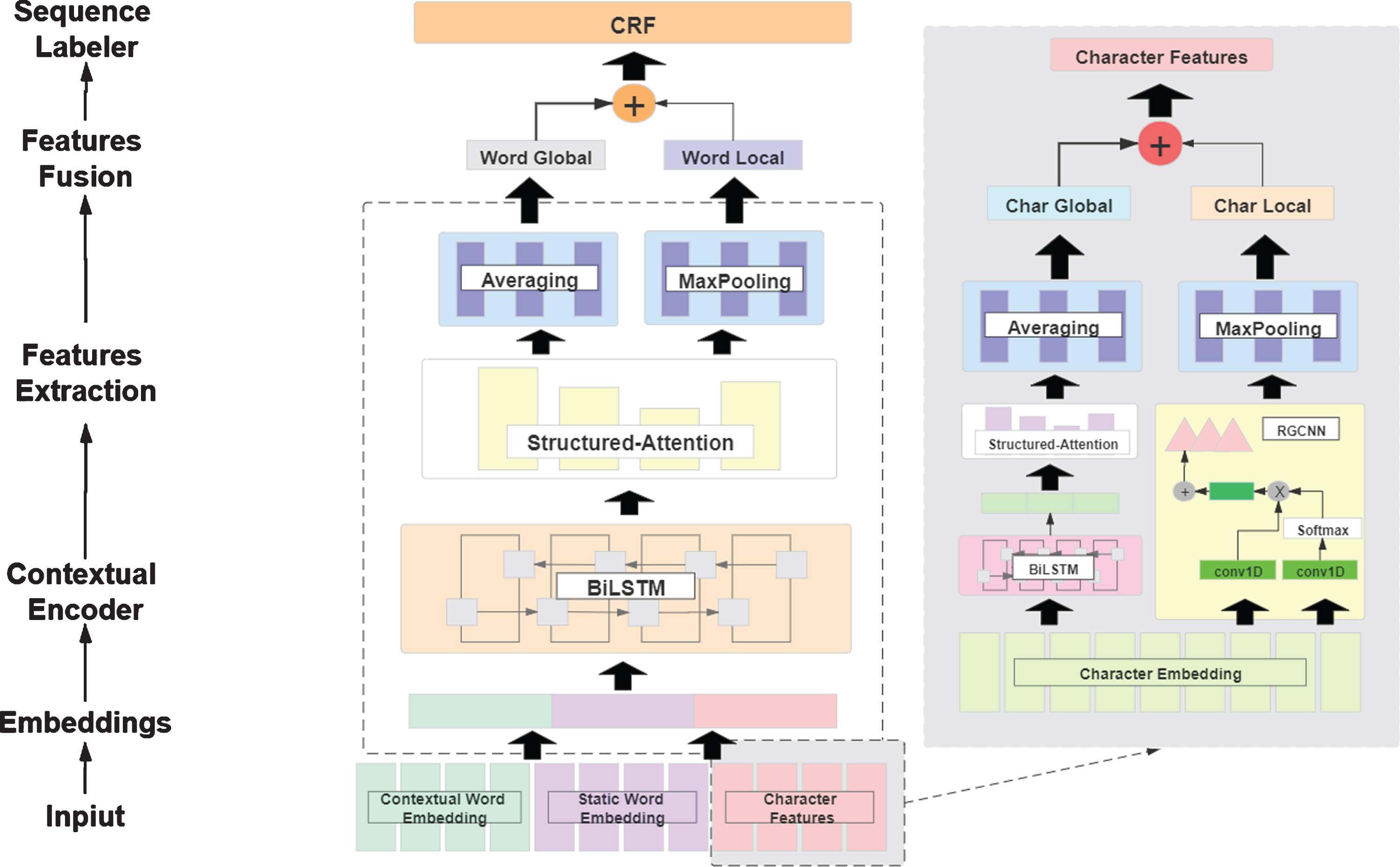
The architecture of HSA. Firstly, a RGCNN and a structured-attention are used to extract character features. Secondly, character features and word embeddings (contextual embedding and static embedding) are concatenated and then fed into a Bi-LSTM layer and another structured-attention to obtain token features. Lastly, token features are plug into a CRF layer for final label prediction.
Global character feature
As stated in Bi-LSTM-CRF model [18] that Bi-LSTM is useful to model the input sequence for many sequence labeling problems, but it does not deal well with long-distance dependencies that may cause gradient vanishing and gradient exploding. As attention mechanism can relieve the limitation of encoding all information equally [30], we use a Bi-LSTM network followed by a structured self-attention layer to extract global character features. Specifically, taking character embedding
Later, the character vector
Where
In order to obtain the global feature, we average the 2-D A
c
to a 1-D vector
In view of CNN’s insufficient capability to extract Indonesian character features, we utilize a residual gated CNN (RGCNN) to extract local character features as shown in Fig. 4. Sigmoid function allows the network to exploit the full input field, or to focus on fewer elements if needed. Hence, based on the GLU [32], our convolutional structure consists of two blocks: a normal 1-D convolution and a 1-D convolution followed by a sigmoid function. Besides, we use a residual connection to enable character information to be transmitted in multiple channels. In order to maintain the same dimension as the convolution input, we learn a linear projection function for character embedding. Given the character embedding
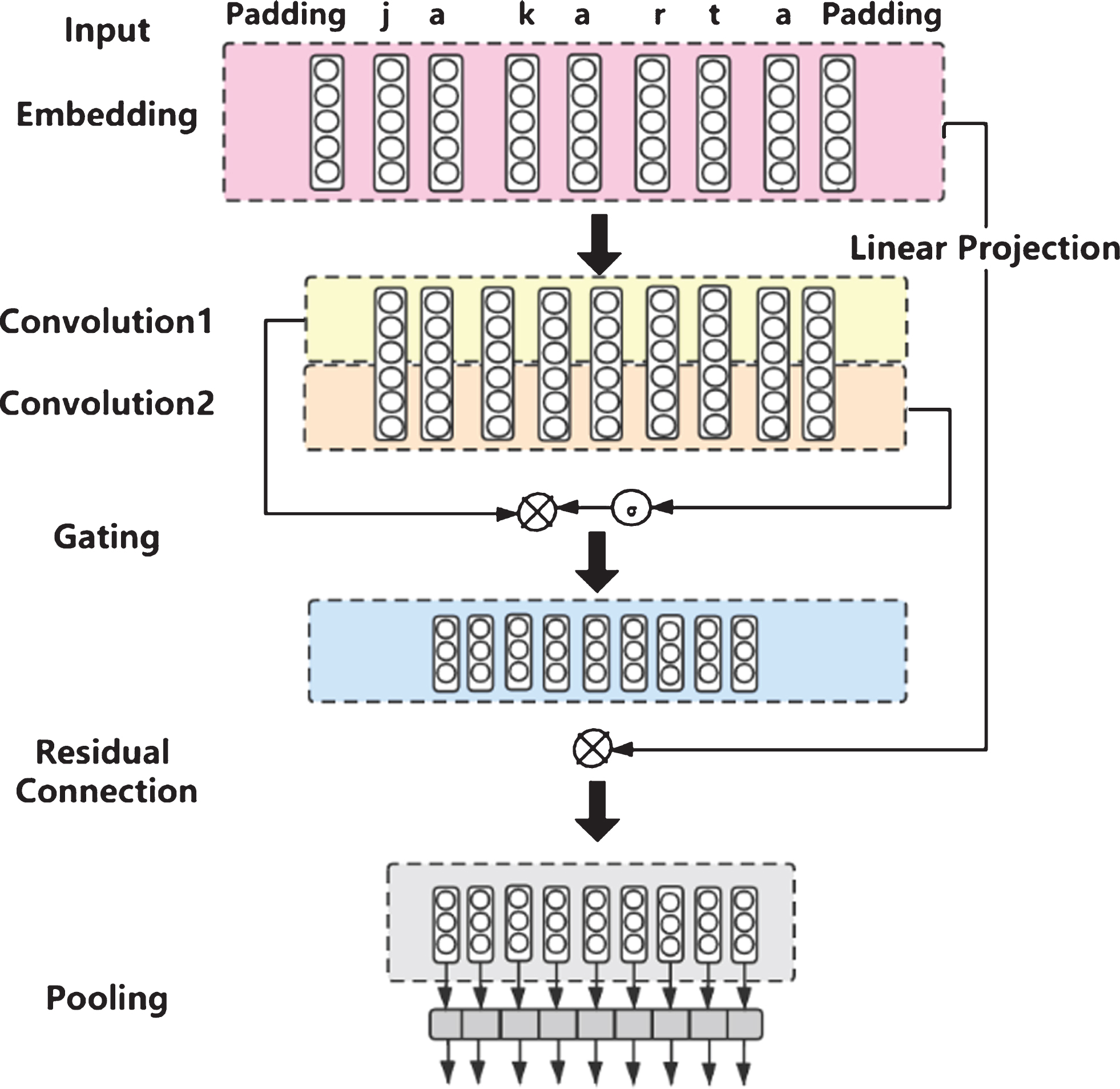
The architecture of RGCNN.
Later, a max pooling layer is adopted to capture the significant local features assigned with the highest value for a given filter [33], the final local character feature can be obtained as follow:
We concatenate the global and local character feature with two weights to combine the advantages of them:
Where λ1 and λ2 represent the weights of each feature
As shown in previous works [9, 18–22], pre-trained word embeddings play an important role in capturing word similarity and relations with other words. We employ a concatenation strategy to static pre-trained word embeddings [34, 35], contextual pre-trained word embeddings [7, 8] and character features since they extract different semantic features from tokens. And a Bi-LSTM layer is further introduced:
Where
After that, another structured self-attention is adopted to capture the multi-perspective information of the tokens:
Where
Then, we compute the weighted matric M
wc
by multiplying the attentive matrix A
wc
and H
wc
:
In order to obtain the global feature, we adopt an average pooling in the 2-D
Inspired by the model [33] that the max pooling operation facilitates the selection of prominent features, we adopt a max pooling operation on
We concatenate the global as well as local word features to combine the advantages of them with an automatic adjustment:
Where λ3 and λ4 represent the weight of each feature
Condition random field (CRF) [36] model is a conditional probability model for labeling and segmenting sequenced data. For linear chain CRF, given an input sentence, the score of one of the possible tag sequences can be calculated by:
After that, we adopt Viterbi to calculate the sequence labels.
Datasets
We evaluate the proposed model on three publicly available datasets including DEE corpus, MDEE corpus and MDEE+Gazz corpus [17], as well as IDNER. Table 4 shows some statistics of the four datasets. Specifically, IDNER is divided into (80%, 8%, 12%) for (training, development, test) sets.
Indonesian datasets
Indonesian datasets
We compare HSA with some stop-performance neural NER models, including classic neural models (Bi-LSTM-CRF [18], NeuralNER [20], CNNs-Bi-LSTM [37], CNNs-Bi-LSTM-CRF [6] and AMFF [22]) and fine-tuned PLMs (mBERT 4 and ELMO [7]). We repeat each experiment 10 times and report the average results on the test set. Evaluation metrics are accuracy, recall and F1-score.
Parameter initialization
Word embedding
Due to the lack of publicly pre-trained Indonesian word embeddings currently, we pre-train GloVe and word2vec embeddings with 300 dimensions and ELMO embeddings with 512 dimensions from Indonesian news articles (more than 150 million tokens) grabbed by several Indonesian news websites (shown in Table 3). If the token does not appear in the vocabulary of pre-trained word embedding, we will assign it a random word embedding (subject to a gaussian distribution). Besides, we continually pre-trained mBERT3 on Indonesian news for domain adaption.
Character embedding
We use a random uniform distribution of 114 Indonesian characters and punctuations to initialize the character vector table. The dimension of the character vector is 52 with a value range [–0.5, 0.5].
Hyperparameters setting
Keras 5 with TensorFlow backend is utilized to construct the model. The hyperparameters of our best model are shown in Table 5. In addition, we also use some other operations such as dropout [43] to avoid over-fitting.
The value of hyperparameters
The value of hyperparameters
It can be seen from Table 6 that, character feature extractor brings significant improvements to Indonesian NER, indicating the effectiveness of various character feature extractors. Meanwhile, it seems that models that incorporates a CRF layer have certain improvements. At the same time, classic neural models seem to be slightly inferior to fine-tuned PLMs which shows that fine-tuned PLMs are better than classic neural models in mining semantic features in Indonesian NER. It is worth to note that the performance of mBERT is not so good as ELMO. For this, we believe that it is because mBERT pays more attention to learning language-independent features (which has superior performance in cross-lingual researches). However, language-specific features have been ignored to a certain extent, which may cause a deficiency in NER tasks. On the contrary, ELMO is pre-trained for a specific language, which can be better adapted to Indonesian NER tasks, achieving better performance. Another point worth noting is that the overall performance of the models on the DEE, MDEE and MDEE+gazz datasets is poor. A notable phenomenon is that the precision of these three datasets is relatively high and the recall is relatively low. The main reason is that there are many errors as annotating entities as non-entities in training sets of three benchmark datasets, which results in insufficient training and in turn affects the recall of test sets. While ensuring the precision of the models, HSF can effectively improve the recall, indicating that HSF can better learn entity features in training sets.
The result in four datasets
The result in four datasets
HSA in this paper has obtained the state-of-the-art performance which demonstrates its superiority. By using an enhanced CNN structure and a structured-attention mechanism, we can extract deeper sequential features. Besides, different pooling operations (average and max pooling) can obtain semantic information from different perspectives, which achieve significant improvement to Indonesian NER. Another advantage of HSA is that the fusion and complementarity of static and contextual pre-trained word embeddings can further boost the NER performance.
We carry out ablation study on all datasets for HSA. Tables 7–10 show the results on IDNER dataset. We omit the results on the other three datasets, which have similar trends.
Performance of different word embeddings
Performance of different word embeddings
Performance of different feature extractors
Performance of three types of entities
Proportion of different error types
This experiment is to explore the impact of different word embeddings. As mentioned above, contextual word embeddings will pay more attention to the contextual information of the sequence, while static word embeddings will pay more attention to the information of the word itself to a certain extent. Therefore, we think that fusing them to complement each other will promote the Indonesian NER performance. We separately use Word2Vec, GloVe, ELMO and BERT embedding and the concatenation of them as the pre-trained word vectors. It can be seen that compared with directly fine-tuning mBERT, it is more effective to use mBERT vector as an external word vector. We hold the opinion that it is because fine-tuning a mBERT with such a totally different dataset tends to destruct its pre-trained representations leading to catastrophic forgetting [38]. In addition, NER performance of combining two kinds of vectors can be further improved. Among them, the type of static word vector has little effect on the experimental performance. And the combination of GloVe and mBERT achieves the best result of 91.02%.
The effect of different corpus sizes
In order to explore the impact of different data sizes on the model, we train the model with data sizes of 10,000, 15,000, 20,000, 25,000, 30,000, 35,000, 40,000, 45,000, and 50,000 sentences (the sum of training, development and test set) respectively and observe the trend of model results as the data size increases. It can be seen from Fig. 5 that when reaching 35000 sentences, with the increase of data size, the improvement growth is gradually flattening out.
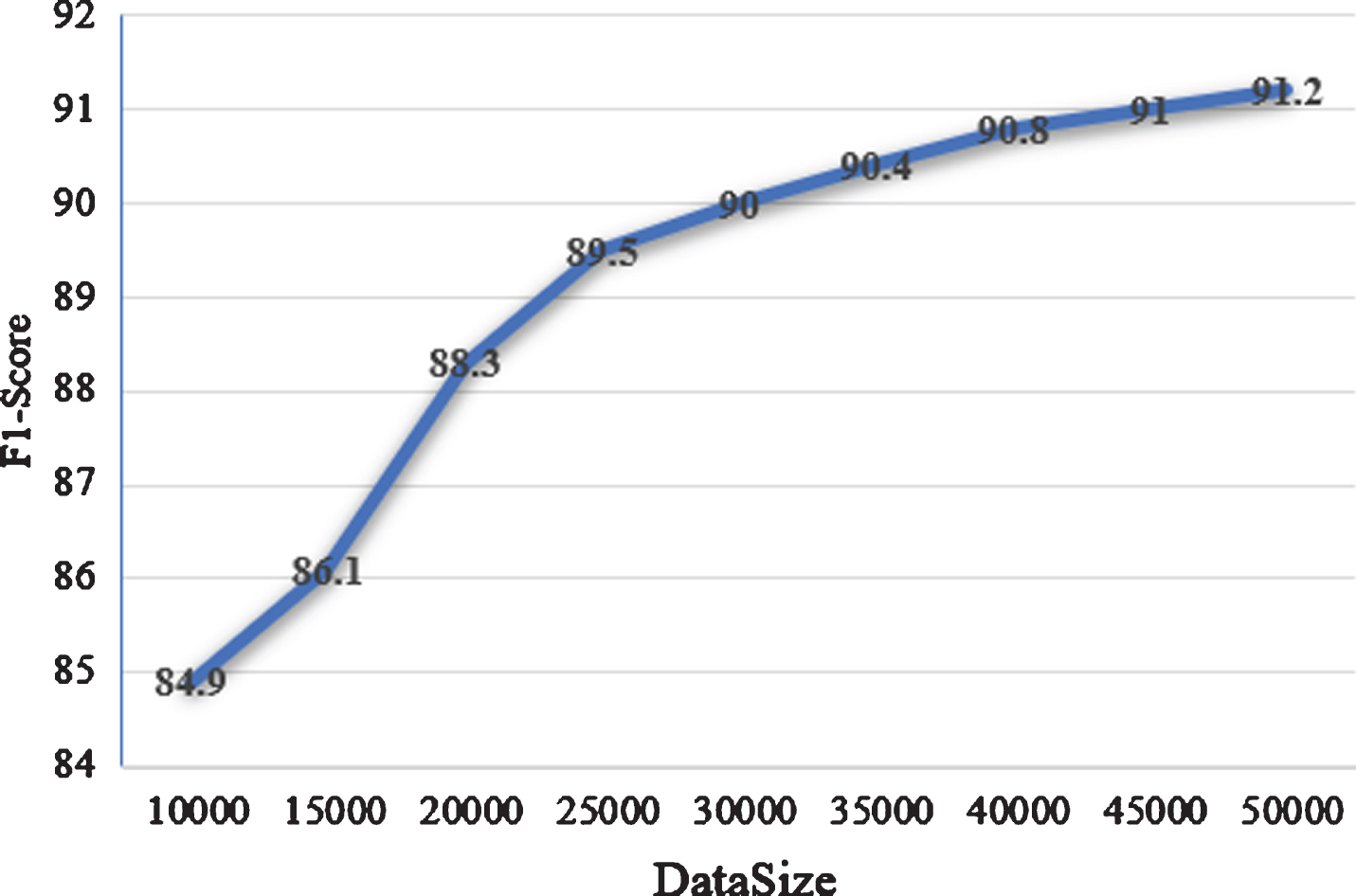
F1-score of different corpus sizes.
In order to explore the effectiveness of all four features extraction modules for Indonesian NER, we conduct verification experiments on different modules. As can be seen from the table below, focusing on only character features or only token features are not good enough. In addition, token features seem to contribute more to Indonesian NER than character features thanks to the superior performance of pre-trained word vectors and efficient structured-attention operations. While the performance of local features and global features are not much different, it further indicates that both of them are essential to Indonesian NER. Combining all the four kinds of features simultaneously maximizes the performance of NER.
Discussion
Table 9 shows the recognition results of three types of entities in this paper. As can be seen that the F1-score of person and place is higher than that of organization. NER errors mainly include three categories: (1) labeling entities as non-entities / labeling non-entities as entities, (2) entities type recognition error, (3) boundary recognition error.
As can be seen from Table 10, most of the recognition errors focus on entities type recognition error and boundary recognition error. Boundary recognition error mainly occur when the entity length is greater than or equal to 4, which proves that the entity length is an important factor affecting the performance of NER models. In the case of entities type recognition error, the recognition of person and location is relatively easy to confuse each other. And the mislabeling of organization is mainly concentrated on being wrongly labeled as location.
Conclusion
In the context of scarce Indonesian language resources and immature language processing technologies for Indonesian language, this paper constructs a large Indonesian NER dataset with high quality. At the same time, in view of the particularity of Indonesian word composition, we construct a novel neural model which can extract sequence features from different perspectives. Experimental results show that the dataset and model constructed in this paper achieve superior performance, surpassing previous Indonesian NER models and datasets. As future work, we plan to extend the proposed model to other sequence labeling tasks like POS tagging and explore other possibilities of implementing more effective feature extractors.
Footnotes
Acknowledgments
The work is supported by grants from National Social Science Foundation of China (No. 17CTQ045), Soft Science Research Project of Guangdong Province (No.2019A101002108), Science and Technology Program of Guangzhou (No.202002030227), Social Science Foundation of Guangdong Province (GD20CWY10), and the Key Field Project for Universities of Guangdong Province (No. 2019KZDZX1016).