
Abstract
Face recognition is one of the most challenging and demanding field, since aging affects the shape and structure of the face. Age invariant face recognition is a relatively new area in face recognition studies, which in real-world implementations recently gained considerable interest due to its huge potential and relevance. The Age invariant face recognition, however, is still evolving and evolving, providing substantial potential for further study and progress in accuracy. Major issues with the age invariant face recognition involve major variations in appearance, texture, and facial features and discrepancies in position and illumination. These problems restrict the age invariant face recognition systems developed and intensify identity recognition tasks. To address this problem, a new technique Quadratic Support Vector Machine- Principal Component Analysis (QSVM-PCA) is introduced. Experimental results suggest that our QSVM-PCA achieved better results especially when the age range is larger than other existing techniques of face-aging dataset of FGNET. The maximum accuracy achieved by demonstrated methodology is 98.87%.
Introduction
Age invariant face recognition is a key element across several uses, including forensic biometric monitoring technologies and the identification of missing persons. The facial characteristics gradually change with different age patterns per human. That refers too personal DNA, personal health, lifestyle, etc., extracting robust features representing aging facial descriptions is a challenging research concern, particularly where broad age differences between face images are considered [1–4]. A well-known model database FGNET is being investigated for age invariant face recognition. The problems posed in the facts can be outlined as follows [5]: a) every object has a low-image vector series of different ages. This makes it challenging to learn because of the small number of training products per participant and the fact that each participant has their aging period, b) Possessing, lighting, blurring, and distance from the sensor vary from one image to another, c) The section of data between the ages of 0–2 years, where clear customized features of the face have not yet been identified. It is very difficult at this age to compare the face of this age (0–2) with the right elder faces of the same individual, except with human being eyes, and d) Presence of high age gaps in FGNET (age from 0 to 69 years) in particular.
The method is mainly known that facial aging is a dynamic process that influences both the function and the expression of the face. The key change of age growth is craniofacial development in the early stages of the face from childhood to adulthood. When people grow aged from young to elderly, the primary factor is skin aging due to differences in texture. There are many explanations for finding facial recognition more complicated than other variants under age differences: (a) the progression of age through life is not straightforward progression as mentioned above; (b) outcomes of aging are very special to many individuals because the origin of the development of age is often impossible to determine precisely. For example, young people who are elderly would tend to be somewhat different from those experiencing disabilities or diseases in their lives; (c) it is therefore impossible to achieve adequate testing data to examine the consequences of aging since it requires much more time and more effort. Aging data sets taken from photographs of varying age ranges can be more skewed than other versions. Finally, but not least, nearly all of the research works relating to age is centered on datasets in which each person has an actual number. Aging data sets generated from pictures at varying age groups may be more blurred than other versions. This renders it difficult to identify machines since much of the techniques now known still teach machines to learn from the knowledge of face appearances. It can look very distinctive for two individuals of the same actual generation. Finally, the method of learning or marking would be less successful. A variety of age-related experiments have been proposed in recent years, based on age and age-invariant facial recognition or monitoring assessments [6–19]. While the fundamental hypotheses and approaches have varying functions, they converge and relate broadly. Usually, these two methods can be split into two classes. First, generative approaches [6, 18] that create 2D or 3D generational models to correct facial images, indicating the age of facial images in the aging process.
The second method is focused on discriminatory [17, 19–22] models that use comprehensive facial characteristics and discriminatory approaches to learning to minimize the disparity between face photos taken during different age groups. Both age and simulator use standard approaches for age-invariant face recognition activities. Age forecasts and simulators concentrate primarily on information that is linked to age development, while age-invariant face recognition aims to identify information that is secure for the same person over decades. This major disparity encourages a modern way of distinguishing the face from the aspect of age and the variable of personality [14, 23].
In [21–25] one of the early studies on facial recognition depicted a mask with its inner and interindividual variations. In a generative linear model, Probabilistic Linear Discriminant Regression (PLDA) [26] was used and an ideal latent identity variable was obtained iteratively using EM [27]. This strategy was also used for the identification of an age-invariant face in [18] where the internal difference was defined by age-relevant information, and identity awareness was the interdependent discrepancy. Again, an EM algorithm is used to simultaneously remove and classify all latent variables. Experimental experiments have also demonstrated that all existing methods are effective for this method. This principle was subsequently also used to model aging ears, though remaining invariant over time [14], by representing the aging layer as a linear combination of age-progress intervals. All these approaches generate an aged subspace and a subspace for identification using a single structure. This method, however, has a large demand for training data sets; because personality and aging data must be taught as comprehensively as practicable.
Unfortunately, the processing of appropriate data sets for age-invariant face recognition is a major obstacle. For the three most well-known data sets for this assignment, either the absence of samples of training (FGNET dataset [28]) or the lack of samples of long-term established learning trends (MORPH [29] dataset and CACD datasets). Worse, both past curriculum frameworks centered on real age markers that can be consistent with youth and facial features of the era concerned. This results in limited facial recognition performance for age gaps. One approach to resolving age gaps consists of researching the fundamental temporal dynamics [6, 30] and then utilizing numerous analyses to determine age characteristics [7, 31]. It has been shown that the application of an OLPP to an aged population of ages from 0 to 93 years produces reliable statistical findings in terms of age. With the interest in subjects relating to age, the subsequent tasks in the next 100 years have become extremely difficult.
One of the main sources of age growth is to measure the appearance age for the ChaLearn data set [32] public for wild face images, identified by their appearance age. A generative model was established based on the PLDA, close to the method of aging and self-identification [14, 23]. In contrast to the earlier literature, which discovered and developed the subspaces of aging and identification, it is one of the key sources of study of age development. In the same way, as for the approach of aging and self-identification [14, 23] a generative model focused on the PLDA was created. Previous literature that simultaneously analyzed and extracted aging and identity subspaces to achieve a higher recognition rate. First of all, this approach refers to the issue of age-invariant face recognition and allows it possible to easily and reliably analyze aging findings. This scheme’s by-product will encourage the sorting of old images, where identification labels are only needed. Any aging dataset with marks of presence will learn the characteristics of aging. A powerful fusion process focused on Canonical Correlation Analysis (CCA) [33], has been used to further enhance distinguishing and aged sub-spaces, and to further develop the underlying identification factors based on various characteristics. Extensive experiments on three separate aging datasets indicate that the system can greatly boost the accuracy of rank-1 identification with other state-of-the-art methods, particularly when faced with wide age differences.
Currently, age invariance face recognition [AIFR] is an ongoing research concern and has many future applications. It has various real-world applications such as passport renewal system, driving license renewal system, finding missing children, finding criminals, providing securities to VIP’s, etc. [34–36]. Face recognition will verify the identification of an individual by equalizing facial biometrics against recognized faces in a database. Authentication is an ongoing process for testing the affinity of an individual. It is used for access management where users are incorporated characteristically. Face empathy is tougher since the complete Security Matching List help is provided and user assistance is not planned. Many challenges in developing an effective facial recognition device require shifts in the stance and age of a motion lighting brain. Many approaches for illumination and/or posing invariant facial recognition have been mentioned. Aging is a guaranteed normal practice of a human being’s life. There are three peculiar features of the aging series [33, 38]: a) aging development is unmanageable and is gradual and permanent, b) aging patterns are customized and has a particular aging sequence for each individual who in turn depends on factors like environment, diet, fitness etc., and c) time-based changing of aging patterns.
The rest of the paper is organized as follows. Section 2 addresses the study of literature. Section 3 describes the approach presented. Section 4 offers results and discussions are drawn in Section 5. The conclusions and future analysis are clarified in Section 6.
Literature survey
AIFR methods are categorized as generative, discriminative and deep-learning’s as follows:
Generative approaches seek to mimic the aging mechanism by producing a synthesized facial picture utilizing old images acquired before face recognition. Lanitis et al. [13] have built a 3D model of virtual aging based on the structure and intensity characteristics of a private database that achieve an RR of 68.5%. Park et al. [4] employ a virtual structural and shape 3D aging model for FGNET and MORPH data sets with an RR of 37.4% and 79.8% respectively. These models are limited by irrational, stable parametric assumptions, while generative approaches might simulate age models [39].
Most traditional face aging works focus to learn the transformation between age groups and thus would require the paired samples as well as the labeled query image. In [40] a generative modeling perspective approach is presented which eliminated the need for paired samples. An unlabeled image given to the generative model can directly produce the image with desired age attribute. A conditional adversarial auto encoder (CAAE) that learns a face manifold, traversing on which smooth age progression and regression can be realized simultaneously. In CAAE, the face is first mapped to a latent vector through a convolutional encoder, and then the vector is projected to the face manifold conditional on age through a de-convolutional generator. The latent vector preserves personalized face features and the age condition controls progression vs. regression. A recent study shows that Generative Adversarial Networks (GANs) can produce synthetic images of extraordinary visual reliability. Opposite to previous works, a novel GAN based approach [41] for Identity-Preserving optimization of GAN’s latent vectors was introduced which proved to be high potential.
Discriminative approaches exclude the standard face features that mostly represent the aging phase. Ling et al. [42] used the gradient orientation pyramid (GOP) for classification purposes to define an aging process and used the support vector machine (SVM). Li et al. [16] used transform (SIFT) [43] and multivariate local binary pattern (MLBP) [44] as differential characteristics for age-invariant detection. Gong et al. [15] used the maximum entropy descriptor (MEFD) function which encrypted the facial images in a variety of discreet entropy codes. Li et al. [45] studied discrimination using an updated hidden factor analysis (HFA). They found an age-gender interaction, instead of believing that they were equally distinct. Zhou et al. recently used an AIFR identity inference model based on linear probabilistic analytics and the EM algorithm [46].
To overcome spatial associations in natural images, CNN uses fully-linked hidden layers and locally bound convolution layers, shared parameters, and detached parameters to significantly reduce the number of features CNN has learned [1]. The present research has shown that the performance of CNN layers generates extremely biased AIFR descriptors. Using CNN to remove facial gestures, Yan et al. [47] used the SVM classification for AIFR. In comparison, Li et al. used a profound CNN model [48] that conducted both feature extraction and classification functions. Xu et al. [49] have used a related auto-encoder network to obtain the AIFR face register name. Li et al. [50] implemented a paradigm for optimizing AIFR functions and distance metrics at the same time. Shakeel et al. [51] also used an innovative CNN design to strip facial characteristics. The extracted characteristics have been further encoded using the analyzed codebook and a linear encoding of regression to fit the face. Recently the pre-trained model VGG-Face CNN is commonly used in applications of facial recognition in [1, 53].
To reduce the intra-class discrepancy caused by aging, a novel approach Orthogonal Embedding-CNN [54] was introduced to learn the age-invariant deep face features. This decomposes deep face features into two orthogonal components to represent age-related and identity-related features. The identity-related features that are durable to aging are used for AIFR along with a constructed brand-new large-scale Cross-Age Face dataset (CAF). Extensive experiments conducted on the three public domain face aging datasets (MORPH Album 2, CACD-VS and FG-NET) have shown the effectiveness of the approach and the value of the constructed CAF dataset on AIFR. An algorithm [55] was introduced to remove age related components from features mixed with both identity and age information. The technique factorizes a mixed face feature into two uncorrelated components: identity-dependent component and age-dependent component, where the identity-dependent component contains information that is useful for face recognition. To implement this idea, a Decorrelated Adversarial Learning (DAL) algorithm, where a Canonical Mapping Module (CMM) is introduced to find a maximum correlation of the paired features generated by the backbone network, while the backbone network and the factorization module are trained to generate features reducing the correlation. Extensive experiments have been conducted on the popular public-domain face aging datasets (FG-NET, MORPH Al-bum 2, and CACD-VS) to demonstrate the effectiveness of the approach.
Demonstrated methodology
This section describes an overview of demonstrated AIFR methodology and details of each process.
Preprocessing
Relevant images include image areas that distort face recognition, i.e. hair and clothing. In this way, we remove from the nose of the eyes and mouth of the particular picture a near box of the local face given in advance. Around the same moment, we uniformly alter the layout of the labeling and modify the grayscale.
Feature extraction
Part 1: Canny edge filter
The canny filter is a multi-stage edge detector that uses a filter dependent on a logarithmic derivative to measure the gradient strength. The logarithmic reduces the noise effect of the image. It is used to extract useful structural information from various facial images and to dramatically reduce pixels. It is a method of seeking out the rims by isolating image noise without impacting the characteristics of the rims and then using the inclination to locate the rims and the critical threshold value. The next steps [56–58] are:
Mathematical model: It has the following steps:
Noise contained in an image is smoothed by convolving the input image I(i,j) with Gaussian filter G. Mathematically, the smooth resultant image is given by
Prewitt operators are simpler to the operator as compared to the Sobel operator but more sensitive to noise in comparison with the sobel operator.
In this step, we detect the edges where the change in grayscale intensity is maximum. Required areas are determined with the help of a gradient of images. A Sobel operator is used to determining the gradient at each pixel of the smoothened image. Sobel operators in i and j directions are given as
These Sobel masks are convolved with smoothed image and giving gradients in i and j directions.
Therefore, edge strength or magnitude of the gradient of a pixel is given by
The direction of the gradient is given by
G
i
and Gj are the gradients in the i and j-directions respectively.
Non-maximum suppression is carried out to preserves all local maxima in the gradient image, and deleting everything else results in thin edges. For a pixel M (i, j):
Firstly round the gradient direction θ nearest 45°, then compare the gradient magnitude of the pixels in positive and negative gradient directions i. e; if gradient direction is east then compare with a gradient of the pixels in east and west directions say E (i, j) and W (i, j) respectively.
If the edge strength of pixel M (i, j) is largest than that of E (i, j) and W (i, j), then preserve the value of gradient and mark M (i, j) as an edge pixel, if not then suppress or remove.
The output of non-maxima suppression still contains the local maxima created by noise. Instead of choosing a single threshold, for avoiding the problem of streaking two thresholds t high and t low are used.
For a pixel M (i, j) having gradient magnitude G following conditions exists to detect pixel as an edge:
If G < t low then discard the edge.
If G > then t high keep the edge.
If t low < G < and t high and any of its neighbors in a 3×3 region around it have gradient magnitudes greater than t high , keep the edge.
If none of the pixel (x, y)’s neighbors have high gradient magnitudes but at least one falls between t low and t high search the 5×5 region to see if any of these pixels have a magnitude greater than t high. If so, keep the edge.
Else, discard the edge.
This section enhances the performance of the recognition based on the facial shape of the subject. The following various features are extracted [59]:
Gray level co-occurrence matrix (GLCM)
Mathematically, a co-occurrence matrix C is defined over an n x m image I, parameterized by an offset (Δx, Δy), as
The co-occurrence matrix is often formed using a set of offsets sweeping through 180 degrees (i.e. 0, 45, 90 and 135 degrees) at the same distance to achieve a degree of rotational invariance. After making the GLCM symmetrical, there is still one step to take before texture measures can be calculated. The measures require that each GLCM cell contain not a count, but rather a probability. The normalization equation is
When i and j are equal, the cell is on the diagonal and (i –j) = 0.
ASM and energy use each Pij as a weight for themselves. High values of ASM or energy occur when the window is very orderly. ASM equation is
The square root of the ASM is sometimes used as a texture measure and is called energy. Energy equation is
The following local features are considered:
One of the most effective methods for image identification and compression is the Principal Component Analysis (PCA). The reason for using PCA for FR is that large 1-D vectors of 2-D face pixels are voiced in smaller PCAs in the component region. This is known to be a different space projection. A decent threshold is usually difficult to select [60].
Offer a face an opportunity to view an M of two-dimensional values by N series. A range of 200 pixels per 149 pixels is used here. An image can also be used as a measurement vector M by N, with the intention of turning the ordinary image in the size of 200×149 into a measurement vector 29,800 or a dot similarly in the size of 29, 800.
Step 1: Preparation training faces to obtain face images I1, I2, I3, …, I M (training faces). The face images must be, centered and of same size.
Step 2: Prepare data set each face image I1 in database is transformed into a vector and placed into a training set S.
This is M = 34. Each picture is translated to an MN×1 size vector and mounted.
Step 3: Computation of average face vector (Ψ) is done by:
Step 4: The average face vector Ψ is subtracted from original face s τ i and the result stored in the variable ∅ i .
Step 5: Matrix C of covariance is determined as
Step 6: Determine the eigenvectors and eigen values of the covariance matrix. The covariance matrix C in step 5 has a dimensionality of consequently individual would contain eigen face and eigen values. For a 256×256 images with the intention of means to the individual should compute a 65,536×65,536 matrix and compute 65,536 eigenfaces. Computationally this is not much competition as mainly of an individual’s eigen faces be not helpful designed for the task. So, compute the eigenvectors u i of A A T The matrix A A T is very large.
Step 6.1: consider matrix (M×M matrix)
Step 6.2: compute eigenvectors v
i
of L = A
T
A
Thus C = A A
T
and L = A
T
A have same eigen values and their eigenvectors are related as follows:
Step 7: Hold just K vectors (related to K’s greatest own values). Eigen faces with low eigen values are excluded, as they clearly only a small part of the features of the faces.
To solve quadratic problems, a new quadratic kernel-free nonlinear vector support machine (QSVM) is used. There is no need to use dual kernel trick optimization. A quadratic function (W bc) that can split non-linear data into two groups is
It is assumed that: a) the decision surfaces f (X) = ct can be of wide-ranging forms of hyper-planes, hyper-spheres, hyper-ellipsoids, hyper-paraboloids, hyper-hyperboloids of different type and b) f (X) is consider as the sum of two conditions: the non-linear term
Parameters:
While
for i = 1 to |T| do
set r y = 0 for every y ∈ C
/* here r y is a counter
For shot = 1 to R do
prepare initial feature map state
apply discriminator circuit W
get outcome measurement {M y } y∈C by applying |C|
get measurement outcome label y by setting r y → r y + 1
end
Calculate empirical distribution
Check the accuracy and error rate by evaluating
end
end
This section explains the experimental results. All of the tests are carried out with MATLAB 2017a (64-bit) with Intel i5 6600U 8 GB RAM 2 GB NVidia GPU. However, the development of a broad age variation “data set” is an exhausting task, and only a few aging “data sets” available are therefore used which restricts the research into age invariant face recognition.
FGNET is considered to be the main facial maturing “data set”, commonly used for the assessment of age-related facial image analysis tasks. FGNET comprises 1,002 images of 82 subjects and 6–18 images of each subject. The age of the participants ranges from 0 to 69 years. Every image is annotated with vertical and horizontal orientations and image quality. The key drawback of FGNET is that fewer topics are accessible in the index. The “data set” contains several images that differ in era, voices, lighting, and head location of the same person [62, 63]. Figure 3 shows some FGNET database sample images with age values.
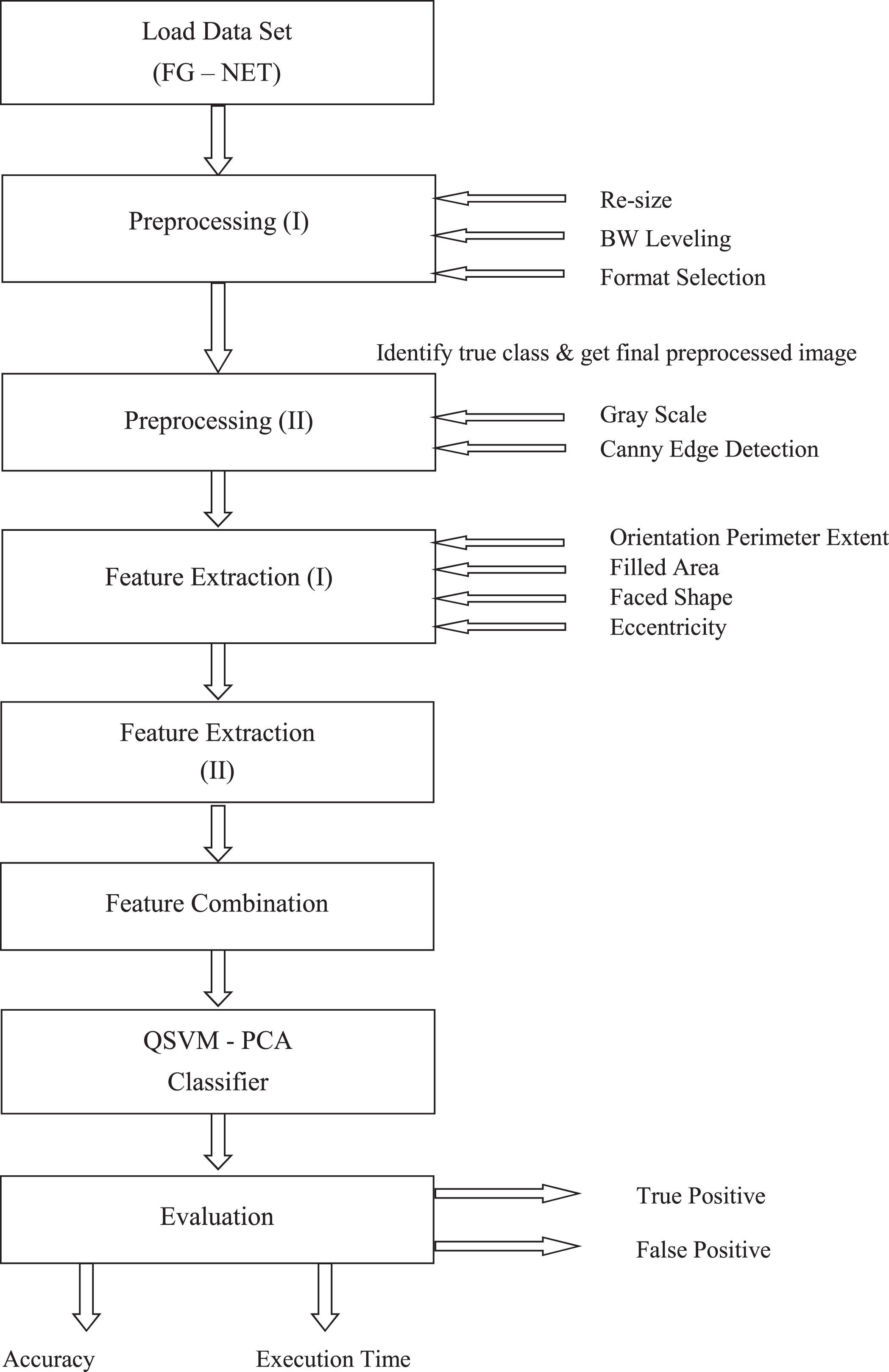
Demonstrated Methodology.

Sample image of FGNET dataset.

Sample images from FGNET database.
We have applied 240 FGNET images whose outcomes are given in Table 1 below:
Recognition rate on FGNET “data set”
The true PR appears in Fig. 4. The cumulative iteration to be done is 1 for 1400 iterations.
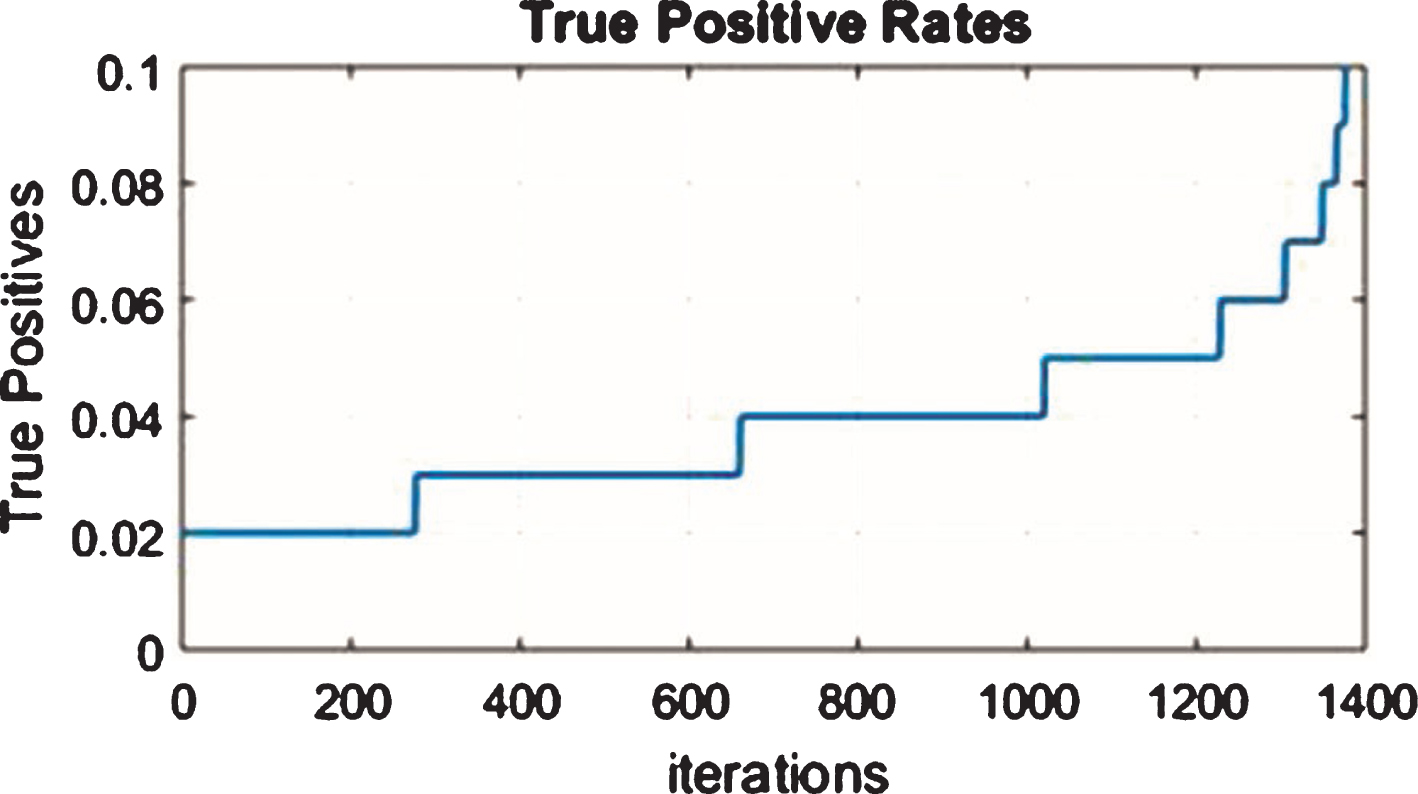
True PR.
By Calculation formula:
Precision: P = TP/ (TP+FP),
Recall: R = TP/ (TP+FN),
F1-score: 2/ (1/P+1/R),
ROC/AUC: TPR = TP/ (TP+FN), FPR = FP/ (FP+TN)
ROC / AUC are same criteria and PR (Precision-Recall) curve (F1-score, Precision, Recall) is also same criteria. Real data will face imbalance problem, namely imbalance between positive and negative samples. ROC/AUC curve can remain curve, but PR change intensely when testing set occurs imbalance. The sum of true PR and false PR is 1. False PR is shown in Fig. 5. Comparison of True PR and False PR is shown in Fig. 6. Comparative analysis is given 0.5 curve area.
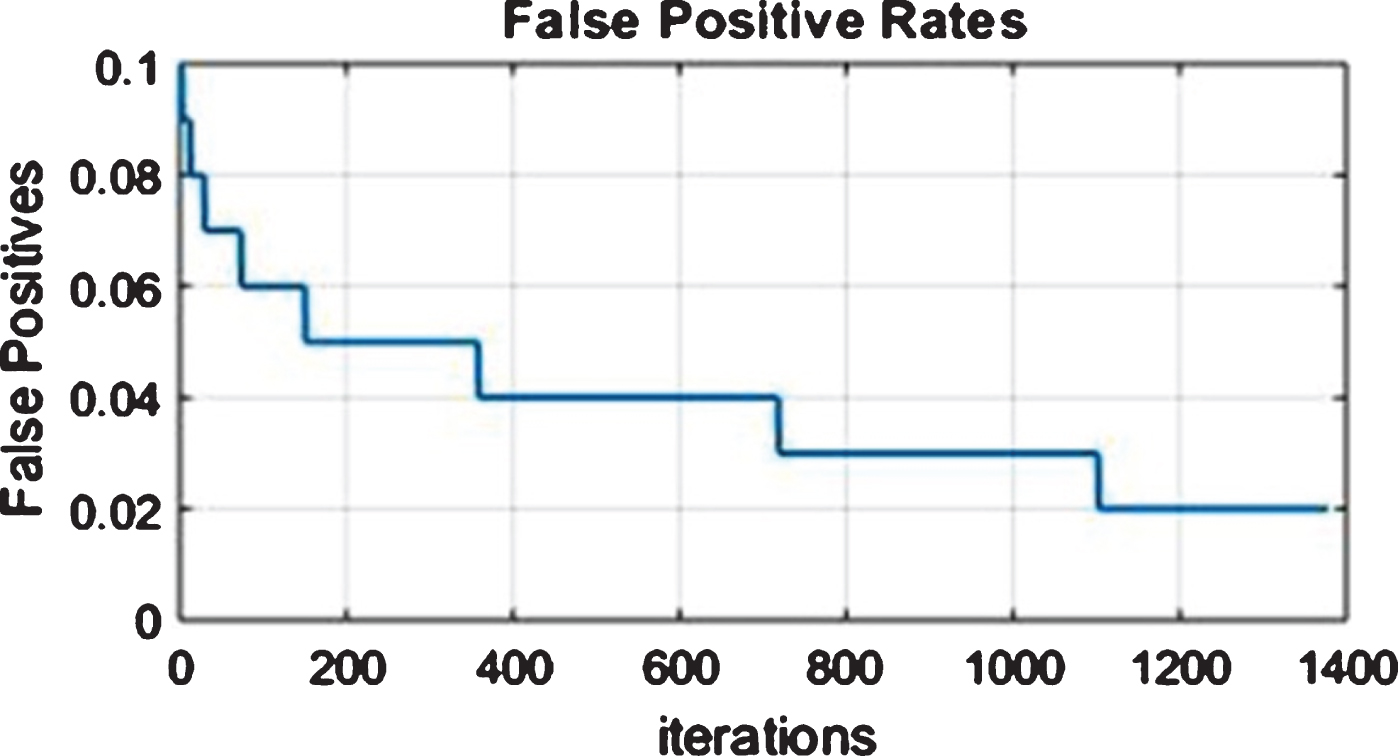
False PR.

Comparison of True Positive & False Positive.
The total images in FGNET “data set” 1002 images and 28 images incorrectly recognized results using proposed method. In Fig. 7, some findings were incorrectly identified by the proposed technique where the numbers below display the age of the person.

Some findings were incorrectly defined by the proposed method. The numbers below display the age of the person.
In specific, the FGNET “data set” [64], MORPH “data set” [65] and CACD “data set” [66] are compared with other best techniques. FGNET is called the largest facial maturation “data set” and has also been used to perform facial expression-related age studies. The MORPH “data set” comprises two parts, MORPH one and MORPH two sets. Since collection one is limited (“only 1690 pictures”) latest collection two have been used for study, as the set contains “55,134 face images of 13,617 individuals”. The newest maturing data set is CACD, which includes “163,446 images of 2000 esteemed web-based individuals”. Any face images are reviewed and tested as below. The FGNET measures only “data sets” because it contains the smallest number of images, but the highest age difference.
Each of our parameters is chosen from past works and our test findings for an assessment of our model in depth.
May be the most important leeway in our approach is that the names for planning tasks in age trials are never needed again because we have taken autonomously a maturing sub-space to the induction model of personality. Besides the FGNET “data set”, the overall images are 1002 while the number of elements is even greater. We also related an important way of coping with the problem of exercise. Unlike previous systems [67, 68] that connect irregular undercut spaces with highlight cutting, ChaLearn and FGNET images use images with 95% of the fluctuation in the subspace of PCA. More DAM strength can be safeguarded, and the maturing images from ChaLearn “data set” can also boost mature example learning, expecting an analogous subspace in PCA. Our estimation is weakened by the FGNET model of “data set” which is prepared using FGNET, which also can be related to recognizing the faces of various displays of “data sets”. We also carried out a detailed review and connotation of some of the better current AIFR techniques. The 240 images are tested on the FGNET “data set” by our proposed technique which produces a recognition accuracy of 98.87% which shows substantial improvement over state-of- the-art recognition techniques. A comparative analyses of different methods are tabulated in Table 2.
Comparative analysis of different methods and demonstrated method
Comparative analysis of different methods and demonstrated method
Table 2 provides a comparative study of a range of advanced FGNET AIFR techniques like 3D maturing [4], DAM [16], FA [69], ME [15], and AG-IIM technology [70]. Our model is based on FGNET’s “data sets”, while most of the AIFR models in [71] are compared to a few other facial data sets. Exhibition changes can hardly be understood from the technique itself or large-scale knowledge planning for varying training scales. In comparison with other first quality approaches designed entirely on FGNET, our approach produces oriented efficiency. Our model produces recognition accuracy of 98.87% and computational time of 80 sec respectively.
Age-invariant face recognition (AIFR) is a relatively new area of face-recognition science that, due to its immense capability and relevance in real-world applications, has recently gained considerable popularity. The AIFR, however, is still in the emergence and growth phases, providing a large space to further investigate and improve accuracy. We implemented a hybrid QSVM-PCA method that, by decreasing PCA-dependent dimensionality, packs an enormous high-dimensional dataset. The key contributions of this work are fourfold: a) extracting different textural, statistical, structural, local, and GLCM features to achieve better accuracy of recognition, b) implementing a hybrid QSVM-PCA technique that bundles an enormous high-dimensional dataset by reducing the dimensionality of PCA-dependent, c) Finally, QSVM served the purpose of reducing dimensionality, and d) Our proposed model has greatly improved the recognition accuracy by 98.87% and computational time of 80 sec respectively for the AIFR on the FG-NET dataset which demonstrates its effectiveness.
More features will be explored in the future to make the method more reliable, especially where a wide age gap is taken into account. We will also concentrate on our future work on creating a new convolutional layer that can be built into the feature recovery network to build all feature mergers. We have already started our future work on age-invariant face recognition improvements utilizing Convolutional Neural Network in conjunction with an improved active shape model.