
Abstract
Short text matching is one of the fundamental technologies in natural language processing. In previous studies, most of the text matching networks are initially designed for English text. The common approach to applying them to Chinese is segmenting each sentence into words, and then taking these words as input. However, this method often results in word segmentation errors. Chinese short text matching faces the challenges of constructing effective features and understanding the semantic relationship between two sentences. In this work, we propose a novel lexicon-based pseudo-siamese model (CL2 N), which can fully mine the information expressed in Chinese text. Instead of utilizing a character-sequence or a single word-sequence, CL2 N augments the text representation with multi-granularity information in characters and lexicons. Additionally, it integrates sentence-level features through single-sentence features as well as interactive features. Experimental studies on two Chinese text matching datasets show that our model has better performance than the state-of-the-art short text matching models, and the proposed method can solve the error propagation problem of Chinese word segmentation. Particularly, the incorporation of single-sentence features and interactive features allows the network to capture the contextual semantics and co-attentive lexical information, which contributes to our best result.
Keywords
Introduction
Short text matching plays a crucial role in natural language processing tasks, such as information retrieval [1], question answering [2], dialogue systems [3], and so on. It compares two sentences and determine the relationship between them.
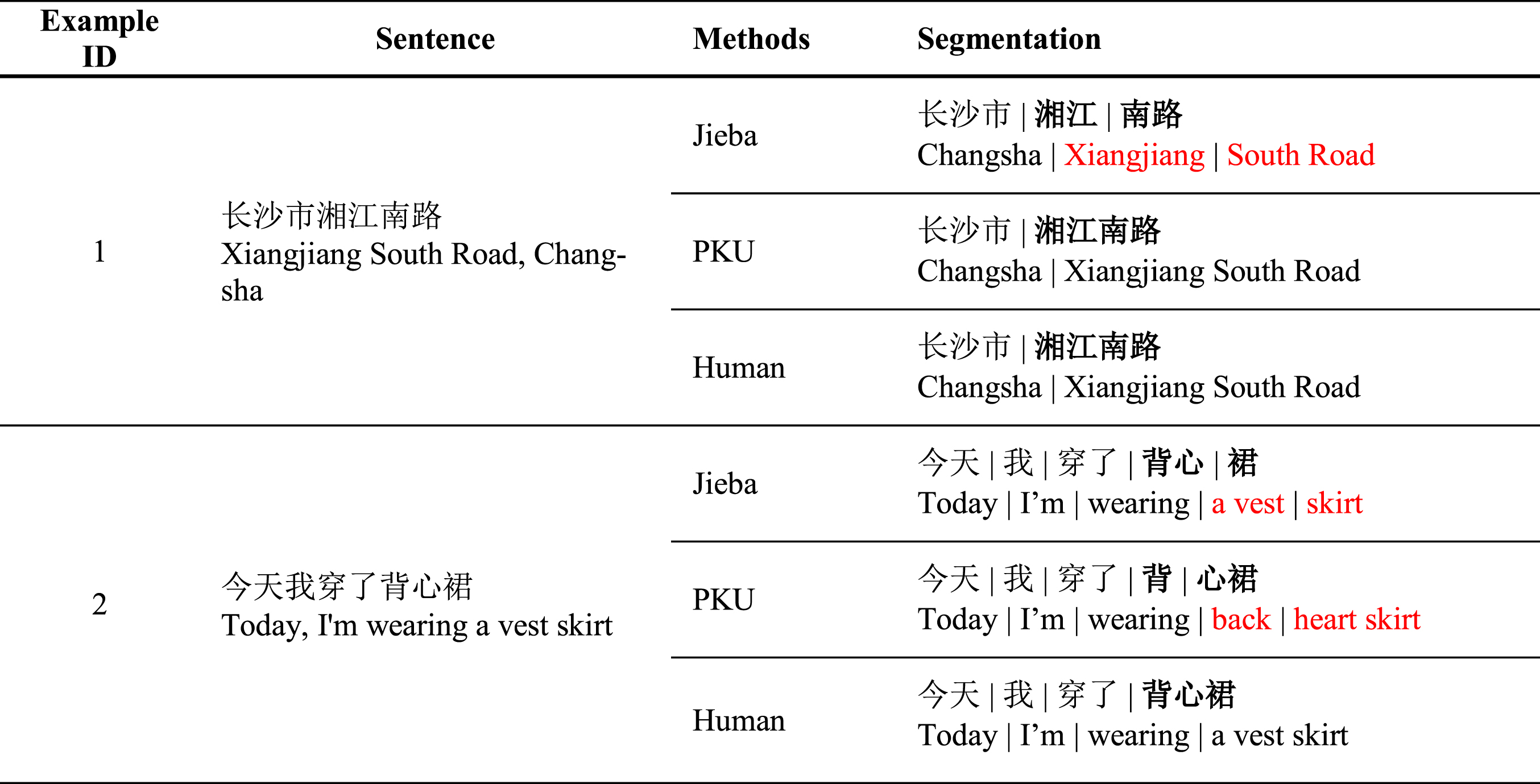
With the successful application of deep learning in computer vision, speech recognition, and other fields, deep neural network models have been adopted to natural language processing tasks to reduce the cost of manual feature engineering. In recent years, several deep neural matching networks have made much headway [4–7], which can deeply mine the semantic information of sentences and obtain better matching results. However, these methods have relatively poor performance in Chinese text matching, since they are proposed for English text matching and Chinese is not naturally segmented [8, 9]. The common practice to process Chinese text is to take Chinese characters directly or to perform word segmentation using an existing Chinese words segment (CWS) system. Chinese texts have complex structures and rich semantics. The existing CWS systems fail to process word segmentation like humans. It is inevitable to make word segmentation errors. This will result in semantic ambiguity, inconsistency and changes, and errors in final matching. Table 1 shows the word segmentation of two CWS systems: Jieba1
1
and pkuseg [10]. The CWS systems make segmentation choices at one time, which often results in word segmentation errors and defective matching models. For example, “  (Xiangjiang South Road, Changsha)” is wrongly segmented by Jieba. The correct word should be one word “
(Xiangjiang South Road, Changsha)” is wrongly segmented by Jieba. The correct word should be one word “  (Xiangjiang South Road, a road)”, however it is divided into two words “
(Xiangjiang South Road, a road)”, however it is divided into two words “  (Xiangjiang, a river)” and “
(Xiangjiang, a river)” and “  (South Road, an unknown road)”. The character-based models can overcome the difficulties caused by word segmentation errors to some degree. The main drawback of these models is that word information is not fully exploited, which possibly serves the purpose of semantics understanding.
(South Road, an unknown road)”. The character-based models can overcome the difficulties caused by word segmentation errors to some degree. The main drawback of these models is that word information is not fully exploited, which possibly serves the purpose of semantics understanding.
Word segmentation results of different CWS systems
Word segmentation results of different CWS systems
To address the limitation of prior studies, Lattice-CNN [9] introduces word lattice to Chinese text matching. The word lattice is a combination of all matched words and characters. The authors propose to preserve all possible words, and it is not necessary to make a firm decision for word segmentation. Due to the inherent structure of a word lattice, all possible words can be represented explicitly, no matter the overlapping and nesting cases, all of them are conductive directly to the sentence representations, which is called multi-granularity information. It has been shown that multi-granularity information is useful for text matching [9]. However, the architectures of the lattice-based models are quite complicated. To contain the information of all matched words, Lattice-CNN adds extra edges in the input sequence, which significantly reduces the training speed. Moreover, Lattice-CNN only considers the information of single-sentence, while ignores the interaction between two texts. Both features are important for text matching tasks.
In this work, we propose a simple method to realize the idea of Lattice-CNN. In addition, we design a network CL2 N (character-word two-stream network), which supply a gap of its architecture about interaction. As shown in Figure 1, we use word lexicon (HyperLexicon) to collect all matched words of each character, and then put the HyperLexicon into CL2 N for training. The first principle of our model design is to obtain Chinese text features with rich semantic information while minimizing the burden of network training. Compared with other text matching models, our model is more appropriate for Chinese text matching tasks. Our method has advantages in integrating more complete and clearer word information. Furthermore, it can enrich the textual representation as much as possible. The contributions of this work are summarized as follows: We propose a simple but effective method for integrating more completely word information into the training of the matching model. We design a weight for incorporating word Lexicons and confirmed that this weight is helpful for the robustness of the network. The designed network can extract single-sentence features and the interaction of sentences. At the same time, it can reduce the burden of increasing vocabulary on network training.

Overview of our proposed framework.
We perform experiments on two public Chinese question matching datasets. The experimental results show that our model is not only better than the previous models but also has a slight improvement in training speed and matching speed.
The rest of this paper is organized as follows: In Section 2, related works about deep learning in short text matching task are summarized. In Section 3, our method is described in detail, including the HyperLexicon and CL2 N. Section 4 consists of experimental settings consisting of datasets, evaluation metrics, parameter settings and baseline. Experimental results and statistical analyses are also presented in Section 4. Section 5 concludes the paper.
Natural language text matching has been studied for many years. Early approaches rely on hand-craft designed features and focus on using n-gram overlap features [11], word reordering phenomena [12], and sentence alignment [13, 14] to model. They can perform well on specific tasks or datasets, but are difficult to generalize to other tasks.
With the emergence of large-scale annotated datasets [15, 16], deep neural networks have made great progress in matching natural language sentences. These approaches can be divided into two groups: representation-based models [4, 9] and interaction-based models [5–7]. The representation-based model encodes the text into sentence vectors through neural network encoders without any interactions, and then determines the relationship between sentences based on the two independent sentence vectors [4]. These representation-based methods are simple to extract sentence representation and can learn the grammatical structure of the text blocks, that is, the feature of a single sentence. Generally, they can be well generalized to other deep tasks of natural language. However, these frameworks ignore the lower-level interactive features between the two indispensable texts. The interaction-based models make up for this deficiency by using the attention mechanism, which has been applied to many deep learning tasks and achieved significant performance improvement [17]. The interaction-based models use the attention mechanism to obtain the interactive features of words or phrases between two texts [5]. They are significantly better than the previous methods. Both single-sentence features and interactive features are crucial for the representation of the short text matching task text. Therefore, both of them are considered in our network.
Recently, many researchers have increased attention on various external or multi-granularity information, which have been shown to have a positive effect on extracting single-sentence features and interactive features on multiple datasets. Yin et al. [18] use deep neural networks to realize the interaction of different granular subsequences between texts; Wang et al. [19] gather multiple matching strategies when forming sentence features; Chen et al. [20] join texts of different lengths in different levels of interaction to get more matching information.
The models mentioned above are specially devised for the English datasets. While for Chinese text, they still do not fundamentally solve the problem of word segmentation errors. Lai et al. [9] propose to integrate all possible words into a word lattice, and the matching model uses the multi-granularity information in the lattice to obtain rich text features. Essentially, this approach converts the input form of a sentence from a chain into a directed graph G =〈 V, E 〉. V is a set of nodes and includes all the characters and possible words of a sentence, which are matched in vocabulary. E is a set of edges. If a node v i ∈ V is adjacent to another node v j ∈ V in the original sentence, then a directed edge e ij is added between them. From our perspective, the word lattice mainly has the following two advantages. First, it retains all possible vocabulary matching results in the original sentence, which helps to avoid the error propagation problem introduced by single mechanical word segmentation results. The second is to use pre-trained word embeddings in the system, which greatly improves the performance of the system. Nevertheless, compared with other text matching methods, these lattice-based approaches require additional modeling of side information, resulting in a large and complex model, which is not conducive to transplantation to other downstream tasks of natural language processing. Additionally, due to the complicated implementation of word lattice, it is sluggish for model training. These problems limit its application in some industrial fields that require real-time response. In this work, we sought to retain the merits of word lattice while overcoming its drawbacks.
Our method is to create a word set containing all the matched words for each character, which is called softword technique. In the previous researches, the softword technique is mainly adopted in the task of Chinese named entity recognition [21–23]. Literature survey published so far reveals that few studies involve this technique in Chinese text matching tasks. Our method uses multi-granularity information in the lexicon to alleviate word mismatch and diversify expression in Chinese text, while they mainly focus on error propagation from CWS systems.
Approach
In this Section, the Chinese short text matching method is explained in detail. Our study is composed of the following two components: the sentence representation layer (HyperLexicon, described in Sub-section 3.1) and the text matching model we designed (CL2 N, described in Sub-section 3.2). We denote two sentences input with HyperLexicon, then incorporate single-sentence features and interactive features for sentences through CL2 N, and finally get the matched score.
HyperLexicon
Constructing a text representation with rich vocabulary information is elementary but necessary for Chinese short text matching task. To this end, we propose a novel method in which lexicon information is introduced simply and comprehensively. We refer to this method as HyperLexicon, shown in Fig. 2.

The HyperLexicon method.
In previous models, the input text is seen as a character-sequence T ={ c1, c2, ⋯ , c
n
} or a word-sequence T ={ w1, w2, ⋯ , w
m
}, where c
i
is the character, w
j
is the matched word in the original text, and c
i
, w
j
∈ V, V denotes the vocabulary. Both character c
i
and word w
j
are represented using a dense vector (embedding):
The deficiency of monotonic character-based representation is the under-utilization of word information, while the purely word-based representation may lead to segmentation errors. To overcome these difficulties, we propose the text representation with character and lexicon, which is the HyperLexicon. Instead of choosing one segmentation result for each sentence, it proposes to retain all possible segmentation results obtained using the soft lexicon. For input text T ={ c1, c2, ⋯ , c n }, there is a sub-sequence dic (c i ) ={ w1, w2, ⋯ , w p } for each character c i in T.
As an example shown in Fig. 2, the character c4 “  (Xiang)” occurs in three words that matched in vocabulary, w1 “
(Xiang)” occurs in three words that matched in vocabulary, w1 “  (Xiangjiang River)”, w2 “
(Xiangjiang River)”, w2 “ (the South of Xiangjiang River)” and w3 “
(the South of Xiangjiang River)” and w3 “ (Xiangjiang South Road)”. Therefore, its corresponding soft lexicon is {“
(Xiangjiang South Road)”. Therefore, its corresponding soft lexicon is {“ ”, “
”, “ ”, “
”, “ ”}. In Algorithm 1, it is described in detail how to build a lexicon for each character. Moreover, if a word set is empty, a special word “NONE” is added to the empty word set. So that we can introduce the word embedding for the soft lexicon. Note that in this way, our model gets off the problem of word segmentation errors. And the multi-information can directly contribute to the text representation.
”}. In Algorithm 1, it is described in detail how to build a lexicon for each character. Moreover, if a word set is empty, a special word “NONE” is added to the empty word set. So that we can introduce the word embedding for the soft lexicon. Note that in this way, our model gets off the problem of word segmentation errors. And the multi-information can directly contribute to the text representation.

Lexicon condensation
After obtaining the soft lexicon of each character, each lexicon is then condensed into a fixed-dimensional vector. In this study, we explore three methods to implement this condensation.
The first implementation is the straightforward mean-pooling method:
However, the contribution to each word for the semantic representation of the text is somewhat different. For instance, the character “ (Xiang)” in the text “
(Xiang)” in the text “  (Xiangjiang South Road, Changsha)” tend to “
(Xiangjiang South Road, Changsha)” tend to “  (Xiangjiang South Road)” rather than “
(Xiangjiang South Road)” rather than “  (Xiangjiang River)” or “
(Xiangjiang River)” or “  (the south of Xiangjiang River)”. Thus, it may be reasonable that “
(the south of Xiangjiang River)”. Thus, it may be reasonable that “  (Xiangjiang South Road)” has a higher weight than others.
(Xiangjiang South Road)” has a higher weight than others.
Therefore, a weighting algorithm is adopted to help words more reasonable representation. To maintain computational efficiency, we do not choose a dynamic weighting algorithm like the attention mechanism. Instead, we propose using the term frequency (TF) of each word to serve as its weight. Since the TF is a static value that can be acquired offline, this can speed up the calculation of word weights and reduce network burden. The second implementation is as follow:
Here, t k is the summation of the word w k that occurs in all lexicon of the text, d denotes the statistical words of all lexicon and W TF denotes the TF of a word. And then weight normalization is performed on all words in each lexicon for effective operation.
For a word, the higher the TF value it acquires, the more it represents the meaning of the character and text representation. Conversely, if the TF value is smaller, it means that it may has little meaning for the representation. In this way, the influence of noisy words introduced by lexicon will be reduced to some degree.
Based on the text matching task, we give further thought to the weight. Since a shorter word is always covered by other longer words, the frequency of shorter words may be very high, especially for some noisy words. Moreover, the shorter words are more likely to appear in both matched texts. For example, the word “  (hotpot)” obtain a high TF value in the sentence pair “
(hotpot)” obtain a high TF value in the sentence pair “  (What kind of hotpot condiment and hotpot dipping sauce do you like)” and “
(What kind of hotpot condiment and hotpot dipping sauce do you like)” and “  (Which do you prefer, Chengdu hotpot or Chongqing hotpot)”. In this case, these noisy words will determine the result of the sentence semantic matching task, disturb the network extensive learning from other possible words and perhaps lead to overfitting.
(Which do you prefer, Chengdu hotpot or Chongqing hotpot)”. In this case, these noisy words will determine the result of the sentence semantic matching task, disturb the network extensive learning from other possible words and perhaps lead to overfitting.
Inspired by TF-IDF [22], a novel word weighting scheme namely TF-IDF-2 is proposed to improve this extreme case. This scheme calculates in a pair of sentences that taking a match. Each word is weighted as follow:
Here, n (w k ) is the number of sentences containing the word w k . Its value may be 1 or 2. The logarithmic function is named IDF (inverse document frequency). Jones [24] firstly proposes IDF based on the knowledge of information entropy. With the function of IDF, the weights of noisy words will diminish. This can help network use all matched word effectively.
Finally, we normalize the weights of a lexicon to obtain the final weight W
norm
(w
k
) for each word:
In our work, the input data of each text is construct by character-sequence and lexicon-sequence and then trained after word embedding. The final input x
i
is obtained as:
Siamese
The siamese network is a frequently-used deep neural framework for similarity matching tasks [25, 26]. Many complex text matching networks are built upon this architecture. As shown in Fig. 3 (a), the siamese network is composed of two branches that share exactly the same architecture and the same set of weights. Each branch takes one of the two texts as input and then applies a user-defined network structure, which can be CNN, RNN, or others. Then branch outputs are concatenated and put into a top network that consists of fully connected layers. The matching score is generated in the last layer. Branches of the siamese network can be viewed as features capture modules and the top network work as a similarity function.

Two network architecture: siamese on the left and pseudo-siamese on the right. The custom net-work can be CNN, RNN, or other complex deep learning structures.
In the previous Sub-section, we built a HyperLexicon for each character in the text. With the word information incorporated, the sentence representations are then put into the siamese network to model the dependence between contexts. It is a conventional training method for semantic textual similarity tasks. The single-sentence features that retain sentence meaning and syntactic structure can be learned in this architecture. However, there is nothing about interactive-features because of lacking any interaction. It is indispensable for semantic similarity analysis to expressing the word- or phrase-level alignments, which are acquired in lower-level interaction. To improve the performance of matching, we develop a new network structure, which contains word interaction.
Inspired by the pseudo-siamese network, we propose the Character-word two-stream network (CL2 N). The pseudo-siamese network is firstly proposed in [27]. As shown in Fig. 3 (b), it has the structure of the siamese network described above except that the weights of the two branches are unshared. Compared with the siamese network, the pseudo-siamese network can handle different tasks. It is more flexible, but the parameters should be doubled. Except the double parameters, it is more flexible and maintain the efficiency of siamese network while testing.
As shown in Fig. 4, the overall architecture of our model is as follows. This model consists of two independent streams, character and lexicon, which enable processing in the sentence representation that takes place over two levels. Each stream has two branches that share the same weights. We put the characters and lexicons of HyperLexicon into different streams. LSTM is the foundation layer of the whole network, which has a time cycle structure that can capture the contextual features of a text sequence [28]. The character-stream applies a BiLSTM [29] layer with inner-attention (att-BiLSTM) mechanism in each branch. The lexicon-stream consists of LSTM and co-attention layers. The character-stream is trained to obtain contextual single-sentence features while the lexicon-stream is applied to capture interactive-features.
Here, we show the precise definition of a single-layer forward LSTM:
The BiLSTM network extend a forward LSTM networks by introducing a backward LSTM, which have the same definition as the former yet model the sequence in opposite temporal order. Therefore, the output in i
th
step of the hidden notes is defined as:
Here, it forms context-dependent representation for text by combining the forward and backward pass outputs. In the character-stream, we also add an inner-attention layer to capture important semantic information of texts. Let H be a matrix of output vectors [h1, h2, ⋯ , h
n
] that the BiLSTM produces and n is the length of sentence. The inner-attention is formulated as follow:
Here, W is a trained parameter which has the same dimension as word embedding vectors. We obtain the final sentence-feature of each branch in the character-stream from:
Zhang et al. and Sen et al. [30, 31] have revealed the significant similarities between human attention and att-BiLSTM that forms the primary structure of the character stream, particularly for a short text processing task. Since it can be interpreted as human-like explanations, we use the character stream to obtain the semantic features and context-dependent of a single text.
On the other hand, we calculate the co-attentive lexical information of both texts with the word stream, then make them part of the sentence representation. The difference between these two streams mainly lies in the attention module. The attention layer works on a single sentence in the character stream while functions on lexicon information of both sentences for the word stream. The co-attention of lexicons can be computed follow the method shown in Figure 4 (b). Given two sentences, suppose the lengths of the two texts p and q are n and m.

A character-word two-stream network (CL2N) that uses a siamese-type architecture to build each stream. There are 4 branches in total given to the top decision network and two branches in each stream have shared the parameters.
After all lexicon information of the sentence have been operated in the first layer of LSTM, the i
th
character-lexicon in the text p gets the transfer parameter
Here, cos(·) is the cosine similarity between two vectors. Then, the input of the second LSTM is enriched by:
Therefore, we will not only obtain two single-sentence vectors Hp_char, Hq_char that include the information from their reachable characters, but also get the other two interactive vectors Hp_lexicon, Hq_lexicon with paired comparative information. Then the single-sentence vectors and the interactive vectors are stitched together to be the final representations of two text p, q respectively, i.e. [Hp_char, Hp_lexicon], [Hq_char, Hq_lexicon].
One reason to make use of such a two-stream architecture is that the single-sentence features and interactive features are equally important for expressing sentences in the text semantic matching task. In the character stream, we obtain the inner-attention information of a single text that is its own semantic and contextual information. We do not capture interactive information on the character-level as computing similarity between char-char is not as meaningful as word-word. It is widely known that the Chinese characters are more polysemous while the words are more explicit in presenting the information. And the probability to contain the same characters in a pair of sentences is higher than words. As a result, there is more noise information with interactions operated between Chinese characters. On the other hand, our method handles characters and words separately which is novel compared to the siamese architecture. Note that the total input dimensionality is reduced by a factor of two, which results in model training faster. This is the other practical advantage of our architecture.
With two multi-level sentence representations p and q, the similarity of two texts is predicted as:
Here, FFN denotes a two-layer fully connected feedforward network and P ∈ [0, 1].
Based on the overall description of the model above, the output of the model is the result of a binary classifier. Therefore, in the stage of training model, we use a binary cross-entropy loss term and squared l2-norm regularization as the loss function.
Our experiments are designed to answer: (1) whether HyperLexicon helps alleviate the word mismatch problem, (2) whether CL2 N is suitable for Chinese short text matching tasks, and (3) whether TF-IDF-2 contributes in favor of the robustness of our network. In this section, we will first introduce the general setting of our experiment in Sub-section 4.1. Then, we demonstrate the properties of our model through some ablation experiments in Sub-section 4.2, 4.3. The ablation studies of HyperLexicon and lexicon condensation schemes are shown in Sub-section 4.2.1 and 4.3, while the results of CL2 N are revealed in Sub-section 4.2.2. Finally, we present a case study of text semantic similarity predictions with different models in Sub-section 4.4.
Experiment setup
Dataset
We conduct a semantic text similarity experiment on two Chinese datasets: LCQMC [32] and BQ [8]. LCQMC is an open field large-scale Chinese question matching corpus containing 260,068 question pairs while BQ is a large-scale domain-specific Chinese corpus for bank question matching with 120,000 question pairs. Each sample of these two datasets contains a pair of sentences and a binary label. The binary label is used to indicate whether these two sentences have the same semantics or the same intentions. In other words, 0 and 1 denote a non-matching and a matching pair, respectively. The ratio of the training set to the test set is 10 : 1. For each epoch, we randomly select 30000 pairs from the training set to train and use them as dev.
We use precision (P), recall (R), accuracy (Acc.), and F1 score as the evaluation metrics for these two datasets. These metrics can be formulated as in the following equations:
We use the vocabulary provided by Song et al. [33] to build the HyperLexicon. For sentence integrity in networks, we set the maximum length of the sentence to 100. Each LSTM layer has 100 hidden units. We set 1000 and 200 hidden units to the two fully-connected layers, respectively. The dropout is applied after the embedding layers with a rate of 0.2. The RMSProp optimizer with an initial learning rate of 0.0001 is used to train the models. Training is done in mini-batches of size 64 within 50 epochs. The model parameters are regularized with a per-minibatch L2 regularization strength of 10-5.
Baselines
We compare our model with two sets of baselines. The first set is based on the siamese network as the training model with character- sequence or word- sequence as the input. The model consists of LSTM used as the branching architecture and a top network with two fully connected layers used as a similarity function. We take two Chinese word segmentation tools, namely Jieba and PKU, to obtain two different word-sequences.
Our second set of baselines combines some latest text semantic similarity models which have achieved high performance in matching tasks. Such models include lattice-CNN [9], BiMPM [19], MLCA [34], and DRCN [35].
Note that these models all take characters and words as input. However, BiMPM, MLCA, and DRCN can only use single word segmentation results obtained by CWS while others retain rich word information.
Main results
Table 2 shows the main results of these two datasets. In general, the experimental results of the LCQMC dataset are better than the BQ dataset. This is determined by their characteristics. LCQMC is an open-domain dataset with a variety of corpora, which is more conducive to extensive network learning.
The performance of all models on LCQMC and BQ test datasets
The performance of all models on LCQMC and BQ test datasets
HyperLexicon (1), (2), (3) are the sentence representations obtained by the three condensation schemes mentioned in sub-section 3.1.
From the first part of the results, the matching results of purely word level models are the worst because Chinese texts involve various structures, different words, and complex pragmatic conditions. Incorrect word segmentation will damage the matching results. At the same time, the matching result of the character-based model is better than word-based models. This reveals that fine-grained text representation can alleviate the problem of word mismatch to a certain extent. Our sentence representation methods of HyperLexicon get the best results on the simple matching model, which expresses semanteme with characters and rich words. That shows the superiority of multi-granularity information in text representation. The combination of different granular information can solve the problem of word segmentation and enrich the sentence representation. Furthermore, comparing three models with different lexicon condensed schemes, we find that TF-IDF-2 has a better performance than the other two. In Table 3, the effectiveness of TF-IDF-2 is shown intuitively. The high weights of the noise words are decreased while the weights of correct words are increased. This weighting scheme is more reasonable and can preferably deal with the noise words introduced by the lexicon.
Performance comparison of TF and TF-IDF-2
Performance comparison of TF and TF-IDF-2
The total word weights are calculated by the two lexicon condensed schemes respectively (i.e. Equations (4) and (6)). Δ denotes the weight change. Bold means the correct word.
In short, the combination of different granularities of information can help improve text matching, which indicates that it is necessary to consider both characters and more possible words, which the HyperLexicon can provide.
From the second part of the results, it can be found that interaction-based models are generally better than representation-based models. Although Lattice-CNN uses the word lattice structure to enrich the text representation with multi-granularity information, due to the limitation of its network structure, it fails to mine the relevant information between the two texts, resulting in significant performance degradation. As for the interaction-based model, our model is better than BiMPM, MLCA and DRCN. This shows that our network based on HyperLexicon is powerful.
On the other hand, we observe that our network is more effective than siamese models by using HyperLexicon as text representations. And our model outperforms the DRCN which has achieved state-of-the-art results in short text matching tasks. Note that, the siamese networks lack interactive function while the DRCN is thoughtless of single-sentence features. These two factors have been deeply considered when we designed the architecture. These results illustrate the importance of the unity of language personality and commonality. In other words, single-sentence features and interactive features are both important significant for text representation.
Parameters and efficiency
Compared with the current excellent text matching model, CL2 N only increases the parameters of vocabulary, and its structure is not as complicated as they are. Moreover, this model processes characters and vocabulary separately, which greatly reduces the burden of model training. As shown in Table 4, the parameters of our network model are less than others. The training speed of our model is about 4.6 batches per second. It has the characteristics of fast speed and few parameters, and has a broad application prospect in natural language processing tasks.
The number of parameters in each model
The number of parameters in each model
In this module, we explore the results of applying different word segmentation tools to our network. We use Jieba, PKU, Jieba+PKU text segmentation sequences as the input of the word stream in our model. As shown in Figure 5, we compare the matching results of the BQ dataset with four different representations on two networks. We can find from the results that CL2 N performs better than the siamese-LSTM, which once again shows the practicality of co-occurrence information in text matching tasks. It is also noticeable that the text representation of HyperLexicon and Jieba+PKU is better than using PKU or Jieba alone in our network. The union of different word-sequence from various CWS systems can be regarded as a lexicon, which is complementary in different granularities. Therefore, it is reasonable that the result of Jieba+PKU is close to HyperLexicon. The results suggest that will bring noise, but the influence of noise words can not offset the positive information brought by the lexicons.

Performance (Acc., Equation (23)) of the siamese network (branches are LSTM) and CL2N with different inputs on LCQMC dataset branches in each stream have shared the parameters.
Note that HyperLexicon is slightly better, which probably benefits from the weight of our design. Characterizing the text with the combination of various granular information will definitely introduce noise, and the lexicon condensed method we propose can smooth the noise to a certain extent. Figure 6 presents validation results along iterations when training the matching model with different lexicon condensed schemes. It shows that when using the weighting algorithm of TF-IDF-2, the learning speed is more stable and faster. Although the model using TF converges fast, the fluctuation is relatively large. The performance of using mean-pooling is the worst, because of its poor processing in noise words. And the overfitting phenomenon in the model using TF-IDF-2 is much lighter than the other two. These results affirm that TF-IDF-2 is robust against overfitting and effective for training.

Comparison of the three lexicon condensed schemes. The objective function is a binary cross-entropy loss term with squared l2-norm regularization.
In summary, although introducing some noisy information, multi-granularity information provides a significant role for text representation. Furthermore, the test studies indicate that our model has the ability to deal with these noises.
In Table 5, we give an example comparing prediction results in different input levels. The word-based models make mistakes in word segmentation to varying degrees, which spread in the network and eventually lead to prediction errors. There are two errors of word segmentation with Jieba. Firstly, “  (Welidai, a financial APP)” is wrongly segmented into “
(Welidai, a financial APP)” is wrongly segmented into “  (particle)” and “
(particle)” and “  (loan)”. Since both matched texts are operated in this way, it has no fatal effect on the similarity prediction. The second mistake is crucial to the prediction result, that the word “
(loan)”. Since both matched texts are operated in this way, it has no fatal effect on the similarity prediction. The second mistake is crucial to the prediction result, that the word “  (total users)” is segmented into “
(total users)” is segmented into “  (total)” and “
(total)” and “  (user)”. Such a mistake also can be found in word-sequence from PKU. In this case, the subject has changed and make it difficult to distinguish the word “
(user)”. Such a mistake also can be found in word-sequence from PKU. In this case, the subject has changed and make it difficult to distinguish the word “  (how many, how much)” of two sentences, which result in semantic fuzziness. The models mistakenly believe that the subject of the two sentences is the same, and judges that the two sentences are similar. Our model can identify the subject “
(how many, how much)” of two sentences, which result in semantic fuzziness. The models mistakenly believe that the subject of the two sentences is the same, and judges that the two sentences are similar. Our model can identify the subject “  (total users)” in sentence 1 correctly, and extra learn the phrase “
(total users)” in sentence 1 correctly, and extra learn the phrase “  (how much to borrow)”. With the sentence representation of HyperLexicon, the model grasps the key points of the two sentences and correctly judges that the two sentences have different intentions.
(how much to borrow)”. With the sentence representation of HyperLexicon, the model grasps the key points of the two sentences and correctly judges that the two sentences have different intentions.
Matching results of different text representation methods
Matching results of different text representation methods

Word segmentations of HyperLexicon are represented with weights. The middle of the table is the matched sentence pair, and the semantic similarity matching results given in the right of this table.
In this paper, we propose a sentence representation enriched method (HyperLexicon) and a novel network (CL2 N) for Chinese short text matching. Our model does not rely on a word-sequence but takes HyperLexicon as input. The use of word sets can provide multi-granularity information, enrich text representation, and avoid the problem of error propagation in word segmentation. Furthermore, our model puts the characters and the lexicon into two streams, captures single-sentence features and rich interactive features, and obtains a strong representation in Chinese text. At the same time, our proposed lexicon condensed method can improve the robustness of our model. Experimental research results on two Chinese question matching datasets show that compared with the existing methods, this method can obtain faster matching speed and better performance.
Our method is based on large-scale annotated datasets, while high quality annotated Chinese text datasets are few. This is the limitation of our method, which is also the limitation of many text matching models based on deep learning. Therefore, it is worth further study on how to break through the constraints of the datasets. In the future, we will further explore the following directions: In terms of sentence representation, we will combine data enhancement methods to improve the performance of models trained with small-scale datasets. We will further optimize the structure of the matching model to reduce dependence on datasets and improve matching effect.