
Abstract
Feature selection (FS) is a vital data preprocessing task which aims at selecting a small subset of features while maintaining a high level of classification accuracy. FS is a challenging optimization problem due to the large search space and the existence of local optimal solutions. Particle swarm optimization (PSO) is a promising technique in selecting optimal feature subset due to its rapid convergence speed and global search ability. But PSO suffers from stagnation or premature convergence in complex FS problems. In this paper, a novel three layer PSO (TLPSO) is proposed for solving FS problem. In the TLPSO, the particles in the swarm are divided into three layers according to their evolution status and particles in different layers are treated differently to fully investigate their potential. Instead of learning from those historical best positions, the TLPSO uses a random learning exemplar selection strategy to enrich the searching behavior of the swarm and enhance the population diversity. Further, a local search operator based on the Gaussian distribution is performed on the elite particles to improve the exploitation ability. Therefore, TLPSO is able to keep a balance between population diversity and convergence speed. Extensive comparisons with seven state-of-the-art meta-heuristic based FS methods are conducted on 18 datasets. The experimental results demonstrate the competitive and reliable performance of TLPSO in terms of improving the classification accuracy and reducing the number of features.
Keywords
Introduction
Nowadays, huge amounts of data are produced in the real world due to the rapid development of information technology and data storage devices [1]. The process of data analysis is challenging and often inaccurate because of the existence of irrelevant and redundant features. Feature selection (FS) is an indispensable preprocessing step in data mining tasks (i.e., classification), especially for large datasets [2]. FS aim to find the most informative features from all the features. FS can improve the classification performance, speed up the learning speed, and provide better understanding of the data and its underlying characteristics.
Based on the evaluation criteria, FS can be divided into two categories: filter and wrapper [3, 4]. The wrapper approach employs a learning algorithm to evaluate the discriminatory power of the feature subsets. In contrast, the filter approach is independent of the learning algorithm and evaluates the features with some statistical properties, such as mutual information, information gain, and correlation [5–7]. Generally speaking, wrappers can produce better classification performance than the filters because the wrappers directly use the classification accuracy to obtain feature subsets. But the filters are much faster since they do not need to call the learning algorithm repeatedly during the searching process.
FS can be considered as a combinatorial optimization problem which aims to select the optimal feature subset. It is an NP-hard problem since the search space grows exponentially with the increase of feature number. For a dataset with N features, there are 2 N candidate feature subsets. Therefore, an exhaustive search which examines all the possible feature subsets is impractical in most of the cases. Heuristic search methods are less computationally expensive, but they are prone to fall into local optimal solutions [8]. Recently, many nature inspired meta-heuristic algorithms have been used to select optimal feature subsets, including Genetic Algorithm (GA) [9, 10], Particle Swarm Optimization (PSO) [11], Ant Colony Optimization (ACO) [12], Differential Evolution (DE) [13], and Artificial Bee Colony (ABC) [14]. The meta-heuristic techniques apply randomness into their search process to explore the entire search space in order to find better solutions within an acceptable time. They have been widely used in optimization problems without prior domain knowledge or a differentiable fitness function [15–18].
Among all the population based meta-heuristic algorithms, PSO has attracted increasing attention from the FS community because of its ease of implementation and rapid convergence speed [19]. Although PSO based FS approaches have shown promising results, it still suffers from several shortcomings. Most PSO based FS methods employ the fully informed topology. By using this topology, the information exchange speed among the swarm is very fast and the algorithm displays the characteristic of rapid convergence [20]. But this topology may lead to the quick loss of diversity. In most PSO variants, all the particles learn from the historical best positions, such as the global best (gbest), the neighborhood best position (nbest), or the personal best position (pbest). These historical best positions may stay the same for many iterations, and this learning strategy easily leads to premature convergence [21]. In high-dimensional FS problems, the huge search space is a great challenge for the search efficiency of PSO. Further, the existence of local optimal solutions also increases the chance of premature convergence [22].
To overcome the aforementioned problems and improve the performance of PSO in FS problem, this paper proposes a novel three layer PSO (TLPSO) for FS. In a swarm, it is obvious that particles are in different evolution status and they have different potential in exploration and exploitation abilities [23]. Therefore, different learning strategies should be applied to particles with respect to their own evolution status. In the proposed TLPSO, a three layer structure is employed instead of the fully connected topology. In each iteration, the particles are sorted according to their fitness values and then divided into three layers: elite, ordinary, and inferior. The elite particles aim at local exploitation to further enhance the quality of solutions. For the inferior particles, they focus on exploring the entire search space and finding potential regions of good solutions. The ordinary particles keep a balance between global exploration and local exploitation.
Instead of learning from the historical best positions, the TLPSO employs a random learning exemplar selection strategy to enhance the population diversity. Particles in the ordinary and inferior layers randomly choose learning exemplars from the current swarm. Hence, all the superior particles can be the candidate learning exemplars. By using this random selection strategy, the population diversity is likely enhanced. In order to improve exploitation ability of the algorithm, a local search operator based on the Gaussian sampling is utilized on the elite particles. The main contributions of this paper are summarized as: This paper proposes a PSO algorithm with a novel three layer structure instead of the classical fully informed topology. Different particles are treated differently to fully investigate their searching abilities. The three layer structure and the learning strategy in the TLPSO can better maintain population diversity and enrich the searching behavior of the swarm. For the ordinary and inferior particles, a random learning exemplar selection strategy is proposed instead of learning from those historical best positions. Therefore, gbest does not dominate the searching process of the entire swarm. This random selection strategy is beneficial for diversity enhancement and makes particles can explore the entire feature space. For the elite particles, a local search operator based on the Gaussian distribution is utilized. It is able to improve the exploitation ability and the convergence speed of the algorithm. The TLPSO is compared with seven well known meta-heuristic algorithm based FS methods. The experimental results show that TLPSO produces more accurate feature subsets in most of the cases and selects markedly fewer features than other approaches.
The rest of the paper is organized as follows. Section 2 introduces the background information and some related works. Section 3 describes the proposed TLPSO for FS. Section 4 presents the extensive experiments to verify the effectiveness of the proposed approach. Finally, conclusions are drawn in section 5.
Background information and related works
Particle swarm optimization
PSO is a population based optimization algorithm which imitates the social behaviors of fish schooling or bird flocking [24]. Due to its simple and effective searching mechanism, it has drawn a lot of attentions. In the standard PSO, each particle is described by two vectors, namely, position and velocity. Each particle’s position is encoded as a candidate solution of the problem and the velocity decides the flying speed and direction of the particles. In the beginning, the particles’ positions are randomly generated in the search space and the velocities are set to 0. The particles are evaluated with a fitness function. During the evolution process, each particle learns from the whole swarm’s best experience and its own flying experience. For the ith particle in the swarm, its position is represented as X = {xi1, xi2, ⋯ , x
iD
} and its velocity V = {vi1, vi2, ⋯ , v
iD
}. PSO updates the velocity and position of each particle as follows:
Meta-heuristic algorithms have been widely used in various optimization problems. FS is a combinatorial optimization problem which aims at reducing the number of features while maintaining the classification accuracy. GA is considered as the first meta-heuristic algorithm used to tackle FS problems. Chakraborty [25] proposed a FS method based on GA and the feature subsets were evaluated with a fuzzy fitness function. Kabir et al. [9] proposed a new local search operator in GA to fine-tune its searching ability in FS problem. Ma et al. [26] developed a tribe competition based GA for FS in which each tribe focused on exploring a specific part of the search space.
Hance et al. [14] proposed a FS method based on ABC with a novel neighborhood selection mechanism. Li et al. [27] proposed a DE based FS method in the filter framework and a novel mutation operator was introduced into DE. Zorarpaci et al. [28] combined ABC and DE to select optimal feature subsets. Kashef et al. [12] treated the features as the graph nodes which were fully connected to each other and ACO was used to select the nodes. Wan et al. [29] proposed a FS approach based on a modified binary coded ACO combined with GA. Shunmugapriya et al. [30] proposed a hybrid algorithm which combined the characteristics of ACO and ABC to select optimal feature subsets.
The research of employing meta-heuristics to tackle FS problems is ongoing, and many recent meta-heuristics are applied to FS. Emary et al. [31] used two versions of binary grey wolf optimizer (GWO) in the FS domain to maximize the classification accuracy and minimize the number of features. Abdel-Basset et al. [32] proposed a FS method based on GWO integrated with a two-phase mutation operator. Aladeemy et al. [33] employed the self-adaptive cohort intelligence (SACI) for FS and three opposition based learning (OBL) strategies were used to enhance the searching capacity of SACI. Faris et al. introduced the salp swarm algorithm (SSA) to tackle FS problems and a crossover operator was used to enhance the exploratory behavior of the algorithm [34]. Eid [35] proposed a binary version of Whale Optimization Algorithm (WOA) using the sigmoid function for FS. Hussien et al. [36] proposed two binary variants of WOA to find the best feature subset that contains the representative information of all the data. A hybrid algorithm based on SSA and chaos theory was proposed for FS in [37]. The logistic map help SSA find better feature subsets. Mafarja et al. [38] proposed two versions of binary grasshopper optimization algorithm (GOA) to select optimal feature subsets in classification problems. Arora et al. [39] employed the butterfly optimization algorithm (BOA) to select optimal feature subset. Since this paper mainly focuses on the PSO based FS method, more works on other meta-heuristics based FS approaches can be found in [4, 40].
Various PSO based FS methods have been presented. Many works introduced several novel operators into PSO to improve its performance in FS. Chuang et al. [41] proposed a catfish PSO for FS in which the worst particles in the swarm were replaced by the catfish particles to improve the performance of PSO. Vieira et al. [42] proposed a modified PSO based FS method for mortality prediction of septic patients with several new operators including local search and swarm best resetting. Xue et al. [43] proposed three new initialization strategies and three new pbest and gbest updating mechanisms in PSO to develop novel FS approaches. Moradi et al. [44] introduced a local search operator into the binary PSO to select less correlated and salient feature subset.
Some researchers combined PSO with other algorithms to enhance its performance. Nguyen et al. [45] introduced the crossover and mutation operators into PSO to improve its search ability and the proposed approach was used to select optimal feature subsets. Mistry et al. [46] proposed a FS method based on PSO embedded with the micro GA and the FS method was used for facial emotion recognition. Some works have been done on the encoding scheme of PSO. Tran et al. [47] proposed a FS method called potential particle swarm optimization (PPSO) which employed a new representation scheme to reduce the search space. Engelbrecht et al. [48] utilized the set based PSO for FS. In the set based PSO, a particle’s position and velocity are defined as mathematical sets. Tran et al. [11] proposed a variable-length PSO representation for FS which was able to define smaller search space and improve the performance of PSO.
Observing these algorithms, most of them maintain the fully informed topology and the selection strategy of learning exemplars. In order to solve the problem of premature convergence, some PSO variants with different learning strategies were proposed. Qiu [49] proposed a FS method based on a multi-swarm PSO in which several small-sized sub-swarms evolved independently and an elite learning strategy was used to promote the information exchange among the sub-swarms. Kamyab et al. [50] utilized several local variants of PSO for FS and these approaches improved the population diversity of PSO. Gu et al. [51] employed the competitive swarm optimizer (CSO) for FS. In CSO, two particles are compared with each other and the loser learns from the winner.
The proposed approach
Searching for the optimal feature subset is a challenging problem, especially in the wrapper based framework. With the increase of feature number, the FS problem is becoming more and more difficult. Furthermore, FS can be considered as a multi-modal problem in which a large number of local optimal solutions exist [52]. PSO has attracted increasing attention from the FS community due to its algorithmic simplicity and fast convergence speed. However, PSO still faces the problem of premature convergence in complex FS problems. In the classical PSO, particles would move towards a single position by the guidance of the gbest. The fast information exchange speed among the swarm would lead to the quick loss of population diversity. FS method may easily lead to stagnation in local optimal solutions. Therefore, it is important to preserve high population diversity to avoid local optimal solutions [53]. Besides, the optimizer also needs to locate optimal feature subsets in a required time. This means that the optimizer in the FS model should keep a good balance between convergence speed and population diversity. The flowchart of the proposed TLPSO is shown in Fig. 1 and the details of the algorithm will be introduced in section 3.
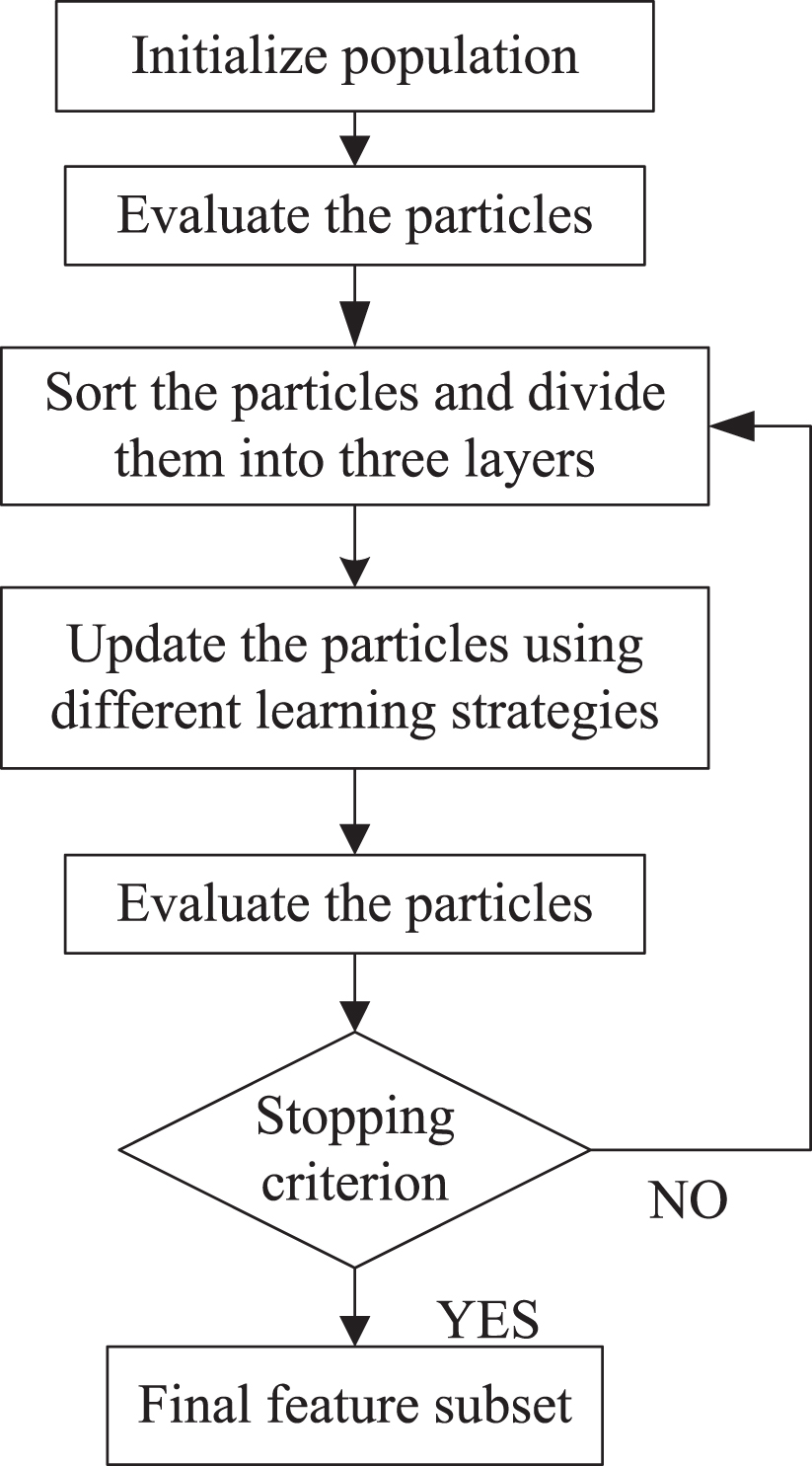
Flowchart of the TLPSO.
In the wrapper based FS method, a classifier is utilized to calculate the classification accuracy of the feature subsets. Previous works have proved that using a relatively simple classification algorithm in a wrapper approach can guarantee a good (near-optimal) feature subset in complex classification problems [4]. Therefore, KNN (K-nearest neighborhood) [54] is employed due to its simplicity and ease of implementation. KNN is a very popular non-parametric method which can be used to classify new instances based on the features and training samples. The only control parameter in KNN is the number of neighbors. In this study, K is set as 5 to keep the efficiency of KNN and avoid noisy data.
FS aims to have higher classification accuracy and fewer numbers of features. Therefore, the fitness function considers both the classification accuracy and the number of selected features.
It is a natural phenomenon that particles in the swarm are in different evolution status and their potential in the exploration and exploitation capabilities are also different. The main idea of the TLPSO is that particles are treated differently according to their evolution status. By using different learning strategies, the potential of different particles could be fully investigated. In order to promote population diversity, a random learning exemplar selection strategy is proposed instead of learning from those historical best positions. A local search operator is employed to enhance the exploitation ability and improve the convergence speed. Therefore, the algorithm is able to keep a balance between population diversity and convergence speed.
Suppose there are NP particles in the swarm. In each iteration, the particles are sorted in ascending order according to their fitness values, and then the particles are grouped into three layers: elite, ordinary, and inferior. The number of particles in each layer is equal, i.e, NP/3. Because superior solutions are more likely to be found nearby the elite particles, the elite particles focus on local exploitation and try to further improve the fitness values. Besides, the elite particles with better fitness values can be used to guide the searching of other particles. The inferior particles concentrate on global exploration and try to find more potential regions with high quality solutions. For the ordinary particles, it is favorable to keep a balance between exploration and exploitation. Figure 2 shows the main framework of the TLPSO.

General idea of TLPSO.
Based on the above analysis, the particles in different layers search for better positions in different ways. For the particles in the inferior layer, they can learn from the elite and the ordinary particles. The ordinary particles update their positions by the guidance of the elite particles. The particles in the ordinary and inferior layers update their velocities and positions as follows:
According to Equations (4) and (5), particles in the ordinary and inferior layers can learn from any better particles in the current swarm instead of learning from historical best positions. Therefore, all the superior particles are the candidate learning exemplars. The randomness in the selection of learning exemplar could further improve the population diversity, which is beneficial for complex FS problems. This kind of learning and imitating behaviors realize the concept of social learning [55].
Compared with the particles in the ordinary and inferior layers, particles in the elite layer concentrate on local search. In some similar researches using the multi-layer structure, the superior particles directly entered into the next iteration without updating their positions. In CSO [56], the winners entered into the next iteration directly. In the level based learning swarm optimizer (LLSO) [23], the particles in the top level also went into the next iteration directly.
However, those superior particles possess valuable information about the global optimal solution and have strong local search abilities. According to the design scheme of TLPSO, the elite particles concentrate on local exploitation. Therefore, a local search operator based on the Gaussian sampling is performed on the elite particles to further improve their fitness values. For the elite particles in TLPSO, their positions are updated as follows:
It can be seen from Equation (7) that the elite particles update their positions by the Gaussian distribution with the mean of (X
L
1
(t) + gbest)/2 and the variance of δ2. Each elite particle searches in the vicinity area of the midpoint of itself and the gbest. The standard deviation δ decides the search range around the midpoint. An appropriate value of δ is important for the algorithm. With larger value of δ, the elite particle can search larger area. In this study, the time decreasing δ is employed.
According to Equation (8), the standard deviation decreases from 0.3 to 0.1 in the evolution process. Figure 3 shows a simple 2-dimensional example in which the dots are randomly generation around the point (0,0) with standard deviation 0.1 and 0.3. When the standard deviation is set to 0.3, the points can locate much larger area than the value of 0.1. By using the time decreasing δ, the elite particles search for relatively large areas initially and focus on more promising areas in the later stage of the algorithm.

A simple 2-dimensional illustration of different std.
This local search operator can improve the local search ability and the convergence speed of the algorithm. Since the local search operator only performs on the elite particles, it would not bring the problem of losing population diversity or falling into local optimum. Even if one elite particle falls into local optima after the local search operation, it would be divided into a lower layer in the next iteration. Then it can jump out of local optimal position by learning from better particles.
The details of the TLPSO are shown in Algorithm 1. Compared with the original PSO, TLPSO owns several different characteristics. Instead of the fully connected topology, TLPSO divides the particles into three layers according to their fitness values and different learning strategies are adopted. In most PSO variants, all the particles learn from the historical best positions which may stay the same for several iterations. In the TLPSO, the random exemplar selection strategy can preserve better population diversity and reduce the probability of falling into local optimal solutions. The local search operator can further improve the exploitation ability of the elite particles. It can make good use of the elite particles and the gbest position. The original PSO realizes the selection mechanism by updating each particle’s pbest. The TLPSO does not need to store the pbest positions and their corresponding fitness values. In the TLPSO, the selection is implicitly achieved in the sorting process.
PSO is originally designed for continuous optimization problems. The velocity and the position in the standard PSO are both continuous values. However, in FS problems, each position vector represents a candidate feature subset and each dimension decides whether the corresponding feature is chosen (0 or 1). Therefore, a transformation function is needed to map the continuous search space to a binary version. Many previous PSO based FS methods employed the sigmoid transformation function [57]. But recently, several studies indicated that the continuous PSO with a simple decoding scheme shows better performance in FS problems [13, 49].
In this study, the position of each particle i is denoted as X = {xi1, xi2, ⋯ , x iD } in which each dimension is a real number between [0,1]. Each dimension of the position corresponds to an original feature. A threshold is used to decide whether a feature is selected. The threshold is set to 0.5 in this study. If x id > 0.5, the dth feature is selected in this feature subset. Otherwise, the dth feature is not included. In this way, the TLPSO can be used to select feature subsets. Initially, the position is randomly generated in the range of [0,1] and the velocity is set to 0. During the search process, the position is restricted in the range of [0,1].
Time complexity analysis
Given the maximum number of iterations, the time complexity of a meta-heuristic is calculated by analyzing the extra time in each iteration without considering the time of fitness evaluation, which is problem dependent. From Algorithm 1, we can see that the proposed TLPSO takes O (NP × log(NP) + NP) to rank the swarm and divide the swarm into three layers in each iteration. In the evolution process, all the particles update their velocities and positions and this takes O (NP × D) which is the same as the classical PSO. Overall, TLPSO takes extra O (NP × log(NP) + NP) in each iteration compared with PSO. As for the space complexity, the TLPSO does not need to store the positions and fitness values of pbest, which takes O (NP × D) space. Therefore, TLPSO needs much smaller space than PSO.
Experimental results and analysis
Dataset
To examine the effectiveness of the proposed TLPSO, 16 UCI datasets and 2 high-dimensional microarray datasets are used for experiments. These diversified datasets represent a wide variety of real-world classification problems and they have been used in many researches of FS. Table 1 shows a brief description of the used datasets.
Datasets
Datasets
For each dataset, 70% of the instances are randomly chosen for training and the remaining instances are used as the test set. During the training process, the feature subset is evaluated by the 10-fold cross-validation with KNN. The training set is divided into 10 folds with equal size. 9 folds are utilized for training and the remaining 1 fold is utilized to calculate the error rate. The mean error rate of the 10-fold cross validation is the classification error rate of the feature subset. It should be noticed that the cross-validation is an inner loop of the training data. The test set is kept hidden from the cross-validation process and it is only used for the final evaluation purpose only. Since the numbers of instance in the Colon and Leukemia datasets are relatively few, 5-fold cross validation is used in these two datasets.
The proposed TLPSO is compared with the original PSO [57] and six other state-of-the-art meta-heuristic based FS methods: GA [58], SSA [34], GWO [31], CSO [51], BOA [38], and WOA [59]. For all the approaches, the population size is set to 20, and the maximum number of iterations is set to 50. Other parameters are shown in Table 2. To obtain statistically meaningful results, each approach is repeated 30 independent runs on each dataset. All the experiments are implemented in Matlab on Windows operating system using a desktop computer with Intel(R) Core(TM) i5-6500 at 3.2 GHz and 8.00 GB of RAM.
The parameter settings
The parameter settings
This subsection compares the performance of the TLPSO with the original PSO and six other well known meta-heuristic based FS methods. These algorithms are quantitatively compared with the following metrics: the mean and standard deviation of classification accuracy, the average number of selected features, the average fitness value in the training set, and the average computational time.
Table 3 outlines the means and standard deviations of classification accuracies in the 30 independent runs. TLPSO achieves the highest mean classification accuracy in 11 out of 18 datasets. TLPSO ranks 2nd in 4 datasets and 3rd in two datasets. The gaps between TLPSO and the leaders in these 6 datasets are very small. SSA outperforms other methods in 3 datasets. GWO comes next by producing the best classification accuracies in 2 datasets. PSO cannot outperform other comparative methods in any dataset. In the five high-dimensional datasets (>100 features), TLPSO outperforms other comparative methods in 4 datasets. In terms of the mean rank in all the 18 datasets, TLPSO ranks 1st with the value of 1.61 while CSO and BOA ties for the 2nd with the value of 4.11. The results clearly demonstrate the strength of TLPSO in obtaining accurate feature subsets.
Means and standard deviations of classification accuracies in each dataset
Means and standard deviations of classification accuracies in each dataset
Table 4 reports the average number of selected features via the 8 algorithms in each dataset. According to Table 4, all the algorithms can significantly reduce the number of features. TLPSO outperforms other methods in 14 datasets in terms of selecting the minimum number of features. Moreover, TLPSO outperforms other methods with a remarkable difference in those high-dimensional datasets. Take the LSVT dataset for example, TLPSO selects 76.35 features on average, while the second best is 135.9 achieved by CSO. It should be noticed that TLPSO also achieve the best classification accuracy in the LSVT dataset.
Average number of selected features in each dataset
Combining the results of Tables 3 and 4, we can conclude that TLPSO can achieve similar or even better classification accuracy with much fewer features, when compared with other methods. For example in the Musk1 dataset, GA achieves the best classification accuracy of 0.8517 with 74.1 features on average. The mean accuracy for the TLPSO is 0.8434 but TLPSO only selects 47.8 features on average. In summary, these results suggest that the TLPSO can effectively enhance the average classification performance and decrease the number of features.
To show the significant difference between the classification accuracies of the TLPSO and other approaches, the Wilcoxon Rank Sum test is performed with the significance level of 0.05. If the p-value is less than 0.05, the null hypothesis is rejected which means there is significant difference between the two approaches. Table 5 shows the results of the Wilcoxon Rank Sum Test, where ‘+’ or ‘–’ means the classification performance of the TLPSO is significantly better or worse than the comparative approach and ‘=’ means there is no significant difference between the TLPSO and the comparative approach. TLPSO achieves better or similar performance in all the datasets compared to other 7 methods. Comparing TLPSO to PSO, GA, SSA, GWO, CSO, BOA, and WOA, the numbers of datasets where TLPSO achieves significantly better classification performance are 12, 7, 9, 11, 7, 8, and 9, respectively.
The results of Wilcoxon sign rank test
Table 6 outlines the computational time of the TLPSO and other seven FS methods. The running time of the 8 algorithms in the low-dimensional datasets is close. TLPSO has the best computational time in the five high-dimensional datasets. This is because the TLPSO selects much smaller feature subsets on these datasets which makes the fitness evaluation more computational efficient. Comparing the TLPSO to the original PSO, although TLPSO needs to sort the particles in each iteration, it still costs less time PSO in majority of the datasets since it selects fewer features. Overall, it can be stated that the proposed TLPSO can improve the performance of PSO in FS problems without additional computational burden.
Average computational time
Taken together, the comparison with other state-of-the-art algorithms shows the TLPSO owns following benefits: TLPSO provides the highest classification accuracy in most of the cases and it shows stable performance in all the 18 datasets. TLPSO selects much fewer features than other methods in high dimensional datasets, which is very crucial for feature selection problems. TLPSO employs a novel structure and the hybrid learning strategies and it is still computationally efficient compared with other methods. It costs less time than other methods in high-dimensional datasets. The good performance of the TLPSO can be attributed to following reasons: TLPSO maintains the multi-layer structure and it is beneficial for preserving the population diversity. Different learning strategies are utilized to fully investigate the potential of particles in different layers. The local search operator with time decreasing std. improves the exploitation ability and accelerates the convergence speed of the algorithm. TLPSO can keep the balance of global exploration and local exploitation due to its hybrid learning strategy.
Figure 4 shows the convergence curves of the TLPSO and the original PSO on four representative datasets (Glass, Ionosphere, Musk1, and Colon). These datasets cover small, medium, and large datasets. The graphs are drawn by the average values of the fitness values in the 30 independent runs. Figure 4 can show the convergence characteristics of the two algorithms and whether the algorithm falls into local optimal solutions.

Convergence curves of TLPSO and PSO for Glass, Ionosphere, Muks1, and Colon datasets.
It can be seen that TLPSO outperforms PSO in terms of fitness value in 3 cases, especially in those high-dimensional datasets. PSO is likely to get trapped into local optimal feature subsets in those high-dimensional datasets. For example in the Musk1 dataset, the convergence speed of PSO slows down at around the 16th iteration and it can hardly improve the quality of feature subsets afterwards. However, the TLPSO is able to obtain better solutions gradually in the evolution process. The results indicate that the TLPSO can jump out of local optimal solutions and better explore the entire search space.
This subsection examines the impact of the local search operator and the parameter δ. In the TLPSO, the elite particles update their positions by the Gaussian distribution in which the standard deviation δ is time decreasing. In order to verify the effectiveness of the local search operator and the affect of the parameter δ, four methods with different values of parameter δ are used for comparison: TLPSO1 (time decreasing, δ = [0.3 0.1]), TLPSO2 (δ = 0.3), TLPSO3 (δ = 0 . 1), and TLPSO4 (without local search operator). Four representative datasets (Wine, Ionosphere, Sonar, and LSVT) are chosen for this set of experiment since they cover low-dimensional, median-dimensional, and high-dimensional datasets. Table 7 presents the means and standard deviations of classification accuracy, and the numbers of selected features.
Comparison of different std
Comparison of different std
TLPSO1 achieves the highest classification accuracy in three datasets and follows behind TLPSO2 in the LSVT dataset. But TLPSO1 obtains smaller standard deviation than TLPSO2 in the LSVT dataset. TLPSO2 shows the largest standard deviations in all the four datasets which means its performance is not as stable as other methods. TLPSO3 ranks 2nd in three dataset and 3rd in the LSVT dataset. TLPSO4 places 4th in three datasets and 3rd in the Sonar dataset. It can be concluded that the local search operator can help to improve the classification accuracy. But a large value of δ may lead to unstable performance. In terms of the feature number, TLPSO2 produces minimum feature numbers in all the 4 datasets. TLPSO1 places 2nd in these 4 datasets and the gaps between TLPSO1 and TLPSO2 are not large. TLPSO4 selects more features than other methods in most of the cases.
The experimental results confirm the efficiency of the local search operator in improving classification accuracy and reducing the number of features. The time decreasing δ can achieve stable classification performance and significantly reduce the number of features.
In this research, a novel three layer PSO (TLPSO) is proposed for solving FS problems. In each iteration, the particles in the swarm are grouped into three layers according to their fitness values. Since different particles possess different exploration and exploitation abilities, different learning strategies are employed for particles in different layers. For the ordinary and inferior particles, a random learning exemplar selection strategy is utilized to promote the population diversity. A local search operator based on the Gaussian distribution is employed to improve the exploitation ability of the elite particles. The proposed TLPSO can keep a balance between population diversity and convergence speed. The proposed approach is used for FS problems in the wrapper framework. Seven state-of-the-art meta-heuristic based FS methods are compared with the TLPSO on 18 datasets to assess the efficiency and effectiveness of the proposed approach. TLPSO produces the highest classification accuracy in 11 out of 18 datasets. In several high-dimensional datasets, TLPSO selects 50% fewer features than other meta-heuristic methods. The convergence curves support the ability of TLPSO in jumping out of local optimal solutions and searching for better solutions in the entire feature space. According to the results and analyses, it can be conclude that the proposed TLPSO is an effective tool for solving FS problems.
For future research, we will study how to set the number of particles in each layer adaptively. Furthermore, it would be interesting to hybridize TLPSO with other meta-heuristic techniques to improve its searching ability.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant No.61802207 and the NUPTSF under Grant No.NY220027.