
Abstract
Spatial clustering is one of the main techniques for spatial data mining and spatial data analysis. However, existing spatial clustering methods primarily focus on points distributed in planar space with the Euclidean distance measurement. Recently, NS-DBSCAN has been developed to perform clustering of spatial point events in Network Space based on a well-known clustering algorithm, named Density-Based Spatial Clustering of Applications with Noise (DBSCAN). The NS-DBSCAN algorithm has efficiently solved the problem of clustering network constrained spatial points. When compared to the NC_DT (Network-Constraint Delaunay Triangulation) clustering algorithm, the NS-DBSCAN algorithm efficiently solves the problem of clustering network constrained spatial points by visualizing the intrinsic clustering structure of spatial data by constructing density ordering charts. However, the main drawback of this algorithm is when the data are processed, objects that are not specifically categorized into types of clusters cannot be removed, which is undeniably a waste of time, particularly when the dataset is large. In an attempt to have this algorithm work with great efficiency, we thus recommend removing edges that are longer than the threshold and eliminating low-density points from the density ordering table when forming clusters and also take other effective techniques into consideration. In this paper, we develop a theorem to determine the maximum length of an edge in a road segment. Based on this theorem, an algorithm is proposed to greatly improve the performance of the density-based clustering algorithm in network space (NS-DBSCAN). Experiments using our proposed algorithm carried out in collaboration with Ho Chi Minh City, Vietnam yield the same results but shows an advantage of it over NS-DBSCAN in execution time.
Introduction
In recent years, the boom in big data has led to a rise in the use of Artificial Intelligence (AI) to address many challenges in the scientific community. Spatial big data attracts much attention from the academic community, business, industry, and governments, as it plays a primary role in addressing social, economic, and environmental issues of pressing importance [1]. The growth of spatial data, which plays a part in agricultural production, sustainable development, and human social development, is always speeding up. Not only are the size and volume of data immense, but the structure is also elaborate in terms of the abundance and depth of the contents. A spatial dataset is full of information and experience collection from geomatics that relates to Remote Sensing (RS), the Global Positioning System (GPS), and Geographic Information System (GIS). A wide variety of databases consist of electronic maps and planning networks from their infrastructures. As the collection of spatial data has grown exponentially and traditional methods fail to solve big data queries, the advent of more powerful techniques handling the processes of gathering, management, and transmission of data is now in urgent need. Spatial Data Mining (SDM) has thus been developed [2], especially with regard to the spatial data clustering technique.
The DBSCAN algorithm is a well-known method among a variety of types of clustering methods for detecting arbitrary shape clusters and noise elimination. Because of the significance of the DBSCAN algorithm, it has been researched thoroughly in order to develop a better version [3]. For example, the NS-DBSCAN clustering algorithm in the network space developed by Wang et al. includes a local shortest-path distance algorithm (LSPD) by gradually expanding from a central point to its adjacent vertex.
Moreover, the NS-DBSCAN algorithm creates favorable conditions to define the parameter MinPts by visualizing the density distribution of event points with the density order chart. However, due to the time-consuming clustering process, we propose solutions to reduce the time required by the NS-DBSCAN algorithm. Firstly, when data is set remove edges whose length exceeds eps because the path with a maximum length of eps definitely does not contain edges exceeding eps. This helps because the algorithm does not need to check the edges with a length greater than eps. Secondly, when building the density ordering table, we propose not including low-density points to reduce the time needed to check these points in the step of forming clusters. Thirdly, we optimize Algorithm 1 to reduce the number of calculations needed, eliminate the sort operation in Algorithm 2, and remove the noise identification part from Algorithm 3. The points that do not belong to any cluster will be considered as noise. If we are not interested in identifying noise, there will be no need to spend time to determine these points. This improvement is a step forward from the original algorithm, which can wrongly identify noise (while it’s supposed to be a border point) when the center point is not the core point.
The rest of this paper is organized as follows: In Section 2, related works are presented. Next, Section 3 presents a theorem for the early elimination of edges whose length exceeds the eps threshold and an improved algorithm based on this theorem. Section 4 then gives experimental results and evaluates the effectiveness of the proposed algorithm. Finally, Section 5 concludes the paper with a discussion on ongoing works.
Related works
In this section, current and previous studies in knowledge exploration and spatial data mining are presented. Spatial data plays an essential role in helping to detect geographic interdependence in networks and exploiting spatial data to detect relationships that exist in spatial databases. More and more studies are focused on discovering useful knowledge from large and complex spatial databases, and there are many algorithms that discover meaningful and useful knowledge from such databases.
Spatial data mining includes many different methods, such as knowledge discovery, clustering, aggregate proximity measuring, and spatial association rules, with some of the following objectives: understanding spatial data, discovering spatial relationships and relationships between spatial data and no n-spatial data, building spatial knowledge bases, reorganizing spatial database arrangement, and optimizing space queries. A crucial challenge to spatial data mining is the exploration of efficient spatial data mining techniques. As with non-spatial data, humans cannot manually analyze the enormous and complex spatial data that is now being collected. Therefore, spatial data mining algorithms are increasingly important, especially spatial data clustering algorithms.
Clustering analysis is used to identify clusters embedded in the data, where a cluster is a collection of data objects that are ‘similar’ to one another. Similarity can be expressed by distance functions, specified by users or experts. A good clustering method produces high quality clusters to ensure that the inter-cluster similarity is low and the intra-cluster similarity is high. For example, one may cluster the houses in an area according to their house category, floor area, and geographical locations. Clustering is a common technique for statistical data analysis which is used in many fields, including machine learning, data mining, pattern recognition, image analysis and bioinformatics. Clustering is the process of grouping similar objects into different groups, or more precisely, it is the partition of a dataset into subsets so the data in each subset is placed there according to defined distance measures.
The clustering problem has the aim of partitioning a set of data points into non-overlapping subsets. In the past few decades, many efficient clustering algorithms have been developed [4].
The clustering methods are classified into the following categories: Partitioning: partition the data set of n elements into k clusters, such as: K-means, k-medoids [5]. Iterative clustering operations are performed by constantly updating central cluster points to stabilize the within-cluster variance. Partition-based methods need users to assign the number of clusters. Hierarchical: Hierarchical clustering involves creating clusters that have a predetermined ordering from top to bottom, such as Balanced Iterative Reducing and Clustering using Hierarchies (BIRCH) [6], AGNES (Agglomerative Nesting), CURE (Clustering Using Representatives) [7], and so on. These methods are either agglomerative or divisive. Agglomerative methods begin with n clusters. In each step, two clusters are chosen and merged. This process continues until all objects are clustered into one group. Divisive methods begin by putting all objects in one cluster. In each step, a cluster is chosen and split into two. This process continues until n clusters are produced [8]. Density-based: Density-based clustering is an unsupervised learning method to classify high density points. Clusters are separated by regions of low density points such as DBSCAN [9], OPTICS (Ordering Points To Identify the Clustering Structure) [10], DENCLUE (Density-based Clustering) [11], ADCN (Anisotropic Density-based Clustering for discovering spatial point patterns with Noise) [12], CLARANS [8] and so on. In density-based clustering algorithms, clusters are high-density data regions divided by low-density regions. A cluster identified by density-based approaches can have arbitrary shapes. In addition, these approaches can handle noise very effectively. The majority of clustering algorithms based on density have been improved to apply to the spatial clustering algorithm [13]. Clustering by fast searching and finding of density peaks (CFDP) is a novel clustering algorithm based on density first proposed by Rodriguez and published in Science in 2014. The CFDP algorithm is based on the idea that cluster centers are characterized by a higher density than their neighbors, and by a relatively large distance from points with higher densities. However, because the CFDP algorithm still has some defects, many improvements have been proposed. The clustering algorithm named constraint-based clustering by fast search and find of density peaks (CCFDP) was proposed to solve the problem of CFDP: CFDP’s performance is quite sensitive to parameter selection, and relies on prior knowledge [14]. CFDP employs the clear neighborhood relations to calculate local density, so it cannot identify the neighborhood membership of different values of points from the distance of points, and it is impossible to accurately cluster the data of the multi-density peak. The fuzzy neighborhood density peak clustering algorithm (F-DPC) was proposed to address this shortcoming: novel local density is defined by the fuzzy neighborhood relationship [15]. The incremental variant of CFS (clustering by fast search) with multiple representatives (ICFSMR) also extended clustering using the fast searching and finding of density peaks method to process large dynamic data [16]. An adaptive core fusion-based density peak clustering (CFDPC) method is used for detecting clusters in any shape and density adaptively [17]. Kathia et al. also proposed an approach to automatically determine cluster centers by detecting gaps between data points in a one-dimensional version of a decision graph [18]. Grid-based: Grid-based clustering algorithms quantize clustered spaces into a finite number of cells to form a grid structure. Clustering is performed by identifying cells that contain more than a dense number of points and connecting these dense cells to form clusters. The processing time of these algorithms is fast because it usually does not depend on the number of data objects but on the grid’s size. Some of the grid-based methods are GRIDCLUS [19], GDILC [20], and WaveCluster [21], among others. Model-based: This clustering method is often based on statistical theory or intelligent calculation tools [22], such as EM (Expectation-Maximization) [23], SOM (self-organization map) [24], and so on. The ANN-based approach to clustering is presented in [25]. Baglietto and et al. applied a variant of the ‘mean-shift’ algorithm to density-based clustering in the state space [26]. Deep neural network-based clustering technique for secure Industrial Internet of Things (IIoT) has also been proposed based on power demand, and this ensures the security of data information in IIoT-based applications [27]. Bhattacharjee and et al. surveyed various density based clustering algorithms (DBCLAs) over last two decades along with their classification [28]. This paper studied as many as thirty-two DBCLAs and presented the related applications. Improved versions of the DBSCAN algorithm are also proposed. DDNFC is a double-density clustering method based on the Nearest-to-First-in strategy to overcome the high error rate situation when clustering datasets with mixed density clusters [29]. The study presented in [30] uses unsupervised classification algorithms of K-means and PCA and supervised classification algorithms of LDA and DBSCAN for rice image classification. NG-DBSCAN is an approximate density-based clustering algorithm that operates on arbitrary data and any symmetric distance measure [31]. DBSCAN (AA-DBSCAN) and kAA-DBSCAN have clustering performances similar to those of existing algorithms for finding clusters with varying densities, while significantly reducing the running time required to perform clustering [32]. DBSCAN++, a modified version of DBSCAN is proposed in [33] that only computes the density estimates for a subset m of the n points in the original dataset.
NS-DBSCAND algorithm
The algorithm is formed from the basic idea that adjacent points have similar densities. Therefore, the authors have proposed building the density ordering table starting from a point (called the central point), then continuing by adding the neighbors (called border points) of a high-density point (≥MinPts, called core point) into the density ordering table so the density of adjacent points is in descending order. The process is repeated for all vertices as the central vertices.
Points near each other tend to be similar in density and will be placed close to each other in the density ordering table. The density ordering table can be displayed as a graph. This chart (Fig. 1) shows hills of different sizes that correspond to implicit clusters [3].
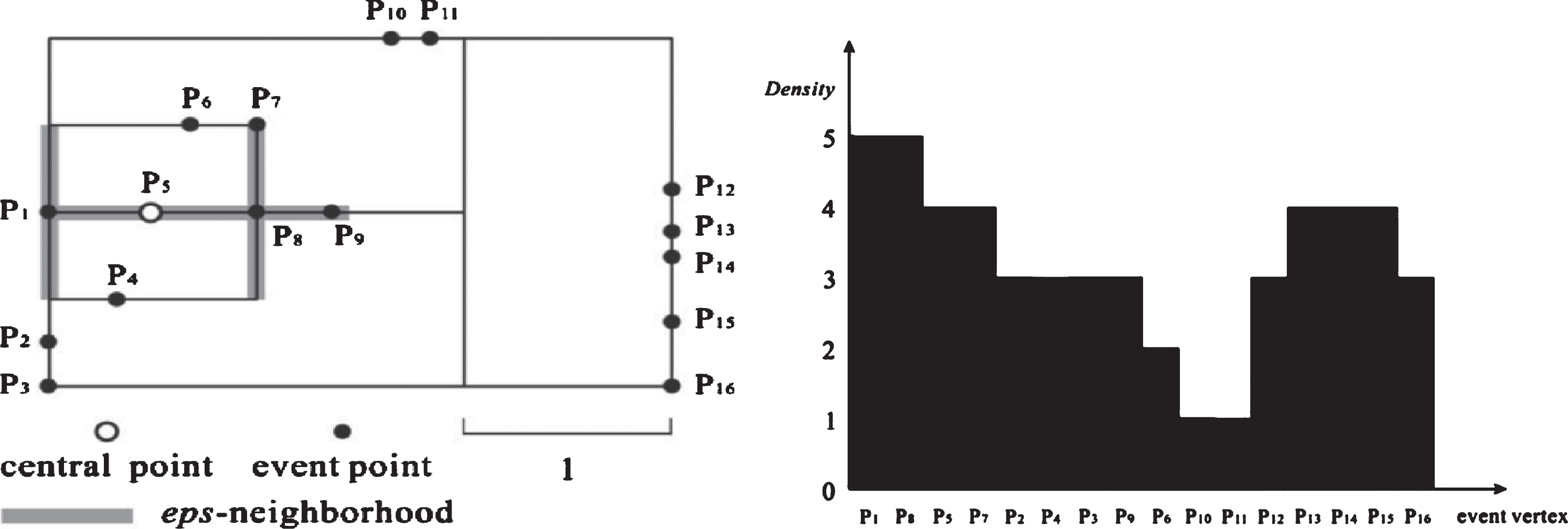
The points close to each other in space are similar in density and close to each other in the density ordering table/graph ([3]).
Expanded from the DBSCAN algorithm, NS-DBSCAN is composed of two main steps with the following three algorithms: Step 1 –Generating the density ordering table using the following algorithms: Algorithm 1 –Local shortest-path distance (LSPD) algorithm defines eps-neighbors, the density of an event point. Algorithm 2 –Generating density ordering with the densities of event points by one parameter eps. Step 2 –Forming clusters by using Algorithm 3. Based on the density ordering chart, this step determines the value for the MinPts parameter. Adjacent and dense vertices are grouped into the same cluster.
The step of generating density ordering is to determine the eps-neighborhood for all event points by calculating the shortest path length of p to the remaining points within distance eps. The point with the shortest path length to p that does not exceed eps is the neighbor of p.
The set of points are neighbors of a central vertex s in the range eps that is determined by Algorithm 1 –Local shortest-path distance (LSPD): Notations: The shortest-path distance from a central vertex to each point e is d (e). The length or weight of the edge from s to e is W (s, e). Assigning the distance from the central vertex to s to 0and the distance from the central vertex to the other vertices to ∞. Finding the eps-neighborhood of s by basic expansion from s to its adjacent vertex e along the edge so the sum of the distance from the central vertex to s and the length of edge from s to e is less than eps. Similarly, the basic expansion is continued from the new vertices until all expansion paths are blocked. After each basic expansion from s to e, the d (e) is updated using the formula: d (e) = d (s) + W (s, e). The purpose of the basic expansion is to minimize the distance from a central vertex to every ending vertex e with the eps constraint. If basic expansion does not reduce the distance d (e) or the d (e) exceeds eps, this expansion path would be blocked.
In Fig. 2, if d (P1) + W (P1, P2) ≥ d (P2) or d (P1) + W (P1, P2) > eps, the expansion path P1 - P2 would be blocked. The set N _ eps (p) contains all points that are basic expansions in turn from p that is the neighbor eps of p. The number of points in the set N _ eps is called the density of p.
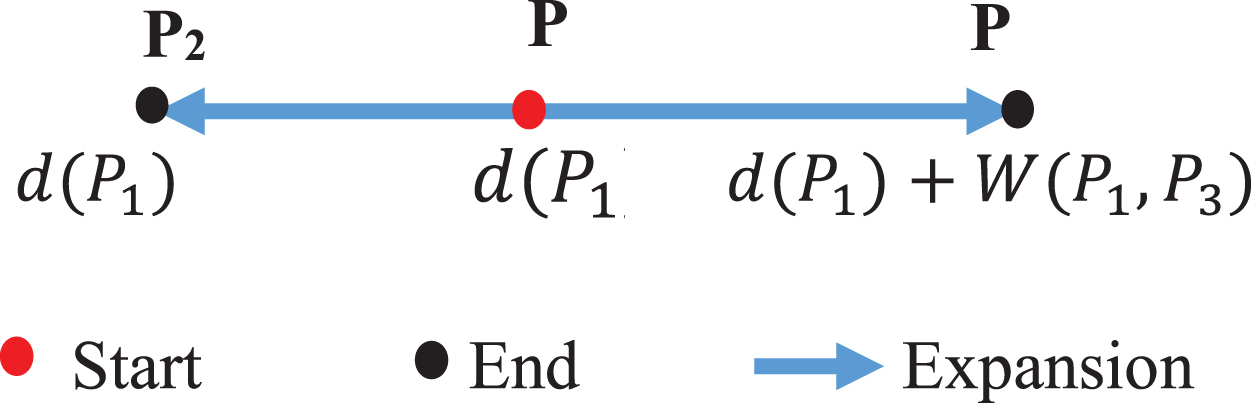
Basic expansion from the start vertex to the end vertex [3].
The authors have proposed the local shortest-path distance (LSPD) algorithm. The distribution of event points is visualized to help precisely determine the two parameters of eps and MinPts. However, in the process of basic expansion within the distance of eps with Algorithm 1 (LSPD algorithm), a check on whether the adjacent vertices with edges exceeding the distance of eps is still made. This is unnecessary because edges whose length exceeds eps can not exist in a segment with a maximum length of eps, and the process stops expanding from P1 to P2 when d (P1) + W (P1, P2) ≥ d (P2) or d (P1) + W (P1, P2) > eps. In fact, the expansion stops functioning in conditions of length = eps. This means that the stopping conditions should be d (P1) + W (P1, P2) ≥ d (P2) or d (P1) + W (P1, P2) ≥ eps to reduce the processing time. In addition, the step of forming clusters will browse through all the points in the density ordering table. Factually, there is no need to browse points that are not core points to further reduce the processing time.
The following definitions and notations are related to the proposed method:
The path can also be expressed as a sequence of edges: (P0P1) , (P0P1) , …, (Pn-1P n ) ∈ E.
There could be several paths or no path at all between the two points. When there are several paths between two points, we can determine the shortest path.
To prove this: There is no edge e i longer than eps.
If e
k
exists with 1 ≤ k ≤ n, k ∈ N so: d (e
k
) > eps.
But according to formula (1):
(4) contradicts (2).
Therefore, the initial assumption must be false. That is, there is no edge whose length is larger than eps.
Applying Theorem 1, the first improvement is to remove edges whose length exceeds esp since it certainly does not expand in a basic way to adjacent vertices whose edge length is greater than eps.
As such, the algorithm does not need to check the edges longer than eps, as shown in Algorithm 1, and this helps reduce the algorithm’s runtime several fold during the clustering process.
Applying Proposition 1, when the expansion path has reached eps, it does not perform a test operation for basic expansion anymore, and this reduces the basic expansion time for the points that have reached eps.
In Algorithm 2 –Constructing the density ordering table has two suggestions for the following enhancements: When inserting a point in queue Q, it should be inserted in the designed descending order in a bid to keep the original order of the sequence. This helps reduce the time needed to sort the Q list in the loop. When building the density ordering table, we propose not taking low density points into consideration to reduce the number of browsing points in the next step of forming clusters. A low-density point is one with a density that is less than the possible minimum value of MinPts. This helps reduce the number of scans through these points in the iteration statement of Algorithm 3 (line 1), which decreases the execution time. Thus, a heuristic is employed to determine the minimum value for MinPts threshold. The minimum value of the MinPts parameter can be taken from the size of the data set (denoted as n), MinPts ≥ n + 1. The low value of MinPts = 1 does not make sense, as then every point on its own will already be a cluster. With MinPts ≤ 2, the result will be the same as with hierarchical clustering with the single link metric. Therefore, inPts must be at least 3 [35]. However, to get denser and more significant clusters, MinPts should be set with a larger value. In general, the recommended value for MinPts is n [36]. Devkota et al. noted that “many studies in the literature follow a trial-and-error approach with various values and compare the clustering results with the background knowledge of the study area in order to select some absolute values as the parameters (e.g., eps = 100 and MinPts = 10)” [37]. Birant et al. state that “the heuristic suggests MinPts ≈ ln (n) where n is the size of the database” [38]. So with the experimental dataset consisting of 10,352 points, we do not include points for which our densities are smaller than ln (10, 352) ≈ 9 in the density ordering table.
In Algorithm 3 - Cluster formation: Noise is identified during cluster formation since noise will be those points that do not belong to any cluster. That is, we do not execute lines 3 and 4 to determine noise. With regard to line 2, we also omit the check for event points that do not belong to noise. This helps remove three test operations in the loop at line 1. Therefore, the algorithm’s execution time is decreased.
The algorithms are summarized in the schematic diagrams of Figs. 3–5.
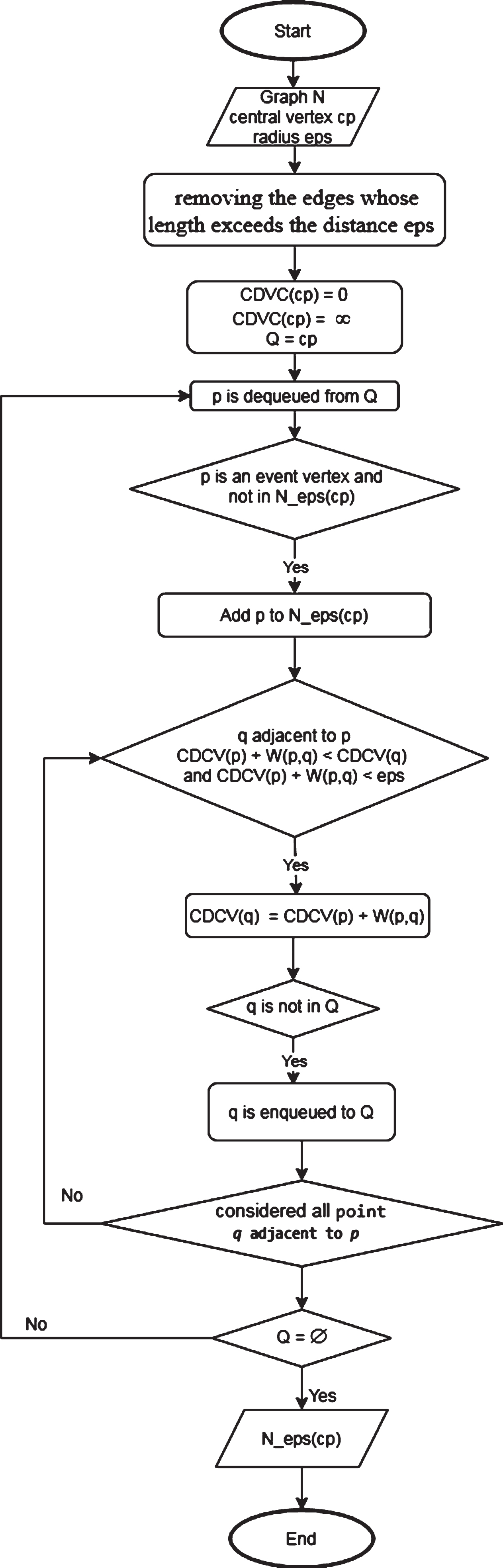
Flowchart of Algorithm 1.
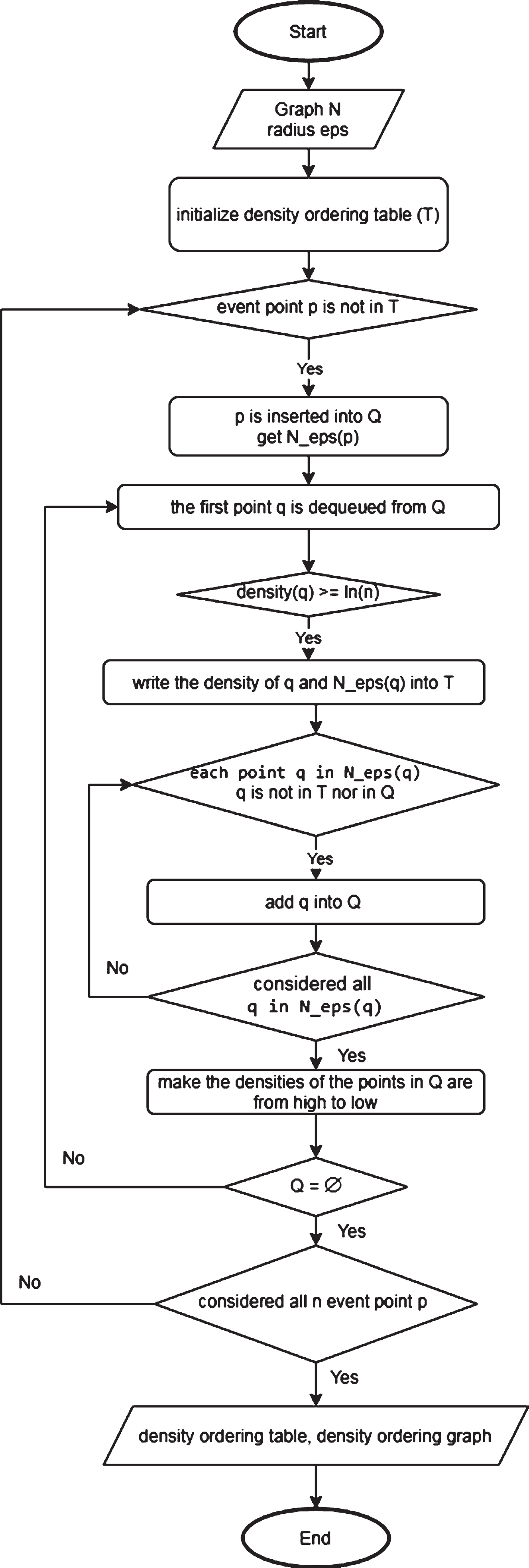
Flowchart of Algorithm 2.
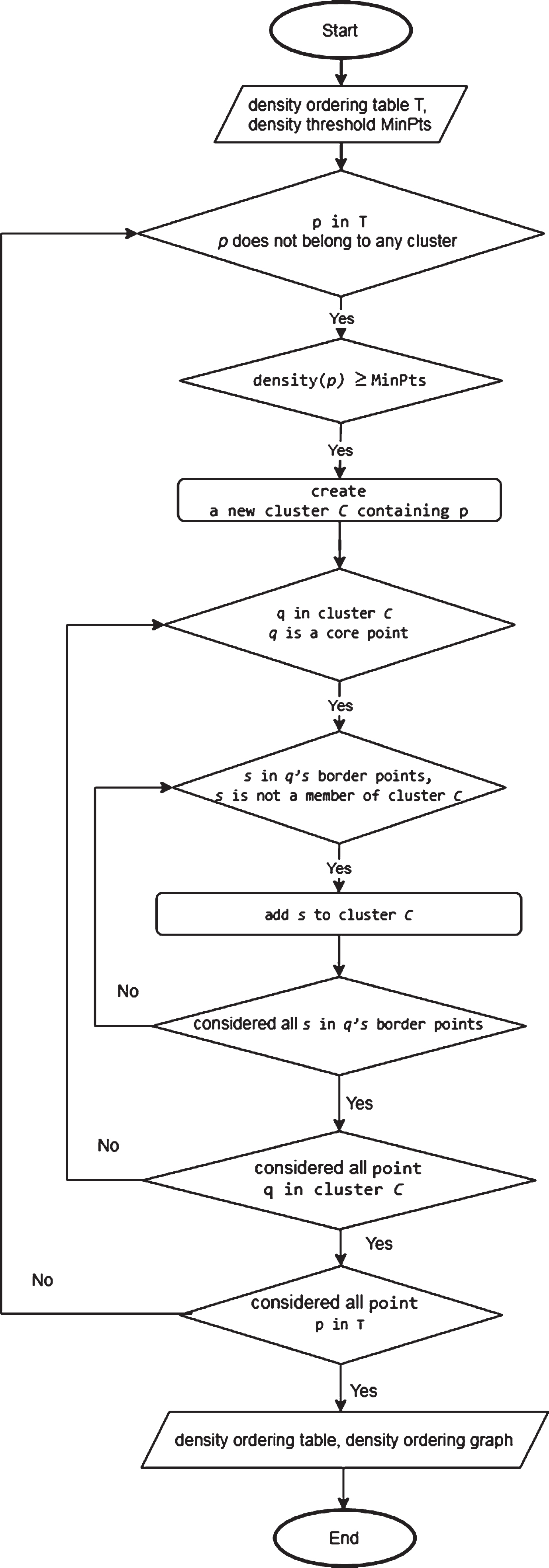
Flowchart of Algorithm 3.
Line 8 shows that the algorithm still continues the test to carry out basic expansion when the distance has reached eps.
When organizing data, we remove edges whose length exceeds eps because the path with a maximum length of eps definitely does not contain edges exceeding eps. That helps to decrease the number of adjacent points of the loop in line 7. At the point where the length from the center point to it has reached the eps distance, we do not check to expand anymore: we stop the test operation after the vertices have reached eps.
In Fig. 3, assuming eps = 1, the central point was randomly selected as P5. According to Algorithm 1, the neighborhood within the distance eps of P5 (N _ eps (P5)) is as follows:
Basic expansion from P5 to vertices P1 and P8:
–Calculate d for P1 and P8:
+d (P1) = d (P5) + W (P5, P1) =0 + 0.5 = 0.5
+d (P8) = d (P5) + W (P5, P8) =0 + 0.5 = 0.5
The new values of d (P1) and d (P8) are smaller than their current d and less than eps, so P5 is expanded to P1 and P8, meaning that P1 and P8 become the start vertex in the next expansion.
–For P1: Continue to basically expand from P1 to P2 and P1 to P3, which gives:
d (P2) = d (P1) + W (P1, P2) =0.5 + 0.5 = 1 = eps
d (P3) = d (P1) + W (P1, P3) =0.5 + 0.5 = 1 = eps
–For P8: Basically, expand from P8 to P4, P8 to P7 and P8 to P9.
+d (P4) = d (P8) + W (P8, P4) =1 = eps
+d (P7) = d (P8) + W (P8, P7) =1 = eps
+d (P9) = d (P8) + W (P8, P9) =1 = eps
Points P2, P3, P4, P7, P9 have reached eps so we do not extend anymore and the conclusion could be: N _ eps (P5) = {P1, P8, P7, P9, }. While the original algorithm still continues to expand: “The expansion continued with P2, P3, P7, P9 and P4 as the start vertices until all the expansion paths were blocked” [3].
At line 13 and in the algorithm illustration of [3], the algorithm starts to sort Q after the data is inserted into Q. The density ordering table is constructed containing all the points, including those that have a density of 0 and no neighbors at all. These points definitely do not belong to any cluster.
When inserting a point into Q, we should insert it in descending order of density measurement to maintain the original order of the array so Q does not have to be reordered. Because putting the vertices into Q is correct in the sort order, the result is correct. For sample data with 16 points, the points whose density is less than ln (16) ≈ 3 are not included in the density ordering table.
An empty table T is initialized. In order of names of the event points, P1 is selected first, and compute N _ eps (P1) = {P5, P2, P4, P8, P3} and queue Q = {P1}. Q is not empty. Take P1 from Q and put the record {(ID: P1; density: 5; N _ eps : {P5, P2, P4, P8, P3}) into the density ordering table T. The density of the points in the set of N _ eps (P1) is calculated and put into the appropriate position of Qso Qhas an order of density from high to low: N _ eps (P5) = (P1, P8, P9, P7) → Q = {P5} N _ eps (P2) = (P3, P4, P1) → Q = {P5, P2} N _ eps (P4) = (P2, P1, P3) → Q = {P5, P4, P2} N _ eps (P8) = (P5, P9, P1, P7, P6) → Q = {P8, P5, P4, P2} N _ eps (P3) = (P2, P4, P1) → Q = {P8, P5, P3, P4, P2} Q = {P8, P5, P3, P4, P2} with the corresponding density in descending order of 5, 4, 3, 3 and 3.
According to the original algorithm, if points in N _ eps (P1) are put into Q in compliance with the order already used in N _ eps (P1), the arrangement of those points will be Q = {P5, P2, P4, P8, P3}. On the other hand, if points in Q are sorted according to the order of their densities from high to low, that is Q = {P8, P5, P2, P4, P3} as in [3].
Then, take out the first point with a density that is bigger than or equal to 3 in Q (P8) and put it in the density ordering table T.
The density values of points P7, P9, and P6 are calculated as 4, 3, and 3, respectively. The queue Q is updated to be {P5, P7, P2, P4, P3, P9, P6}. Then, the first point in Q is removed from the queue to continue performing the above-mentioned operations until Q is empty. As a result, the order of points in T is P1, P8, P5, P7, P2, P4, P3, P9.
These are points related to P1 in terms of neighbor relations for the distance eps.
Continue to consider points from P2 to P16. Points from P2 to P9 are already in the density ordering table.
Similar to P1, we consider P10: Q = {P10}, N _ eps (P10) = {P11}. P10 is not included in the density ordering table T because Density (P10) =1. Similarly, Density (P11) =1 so P11 does not exist in T.
Continue with P12:
Add P12 into the density ordering table T composed of points P1, P8, P5, P7, P2, P4, P3, P9} and P12.
Doing the same as with P1, we get the following T results:
Compared to the original algorithm, there are both P10 and P11 before P12. It takes some time to examine these points in the next step in forming clusters.
The density ordering graph of the road network in Fig. 6 is depicted in Fig. 7.
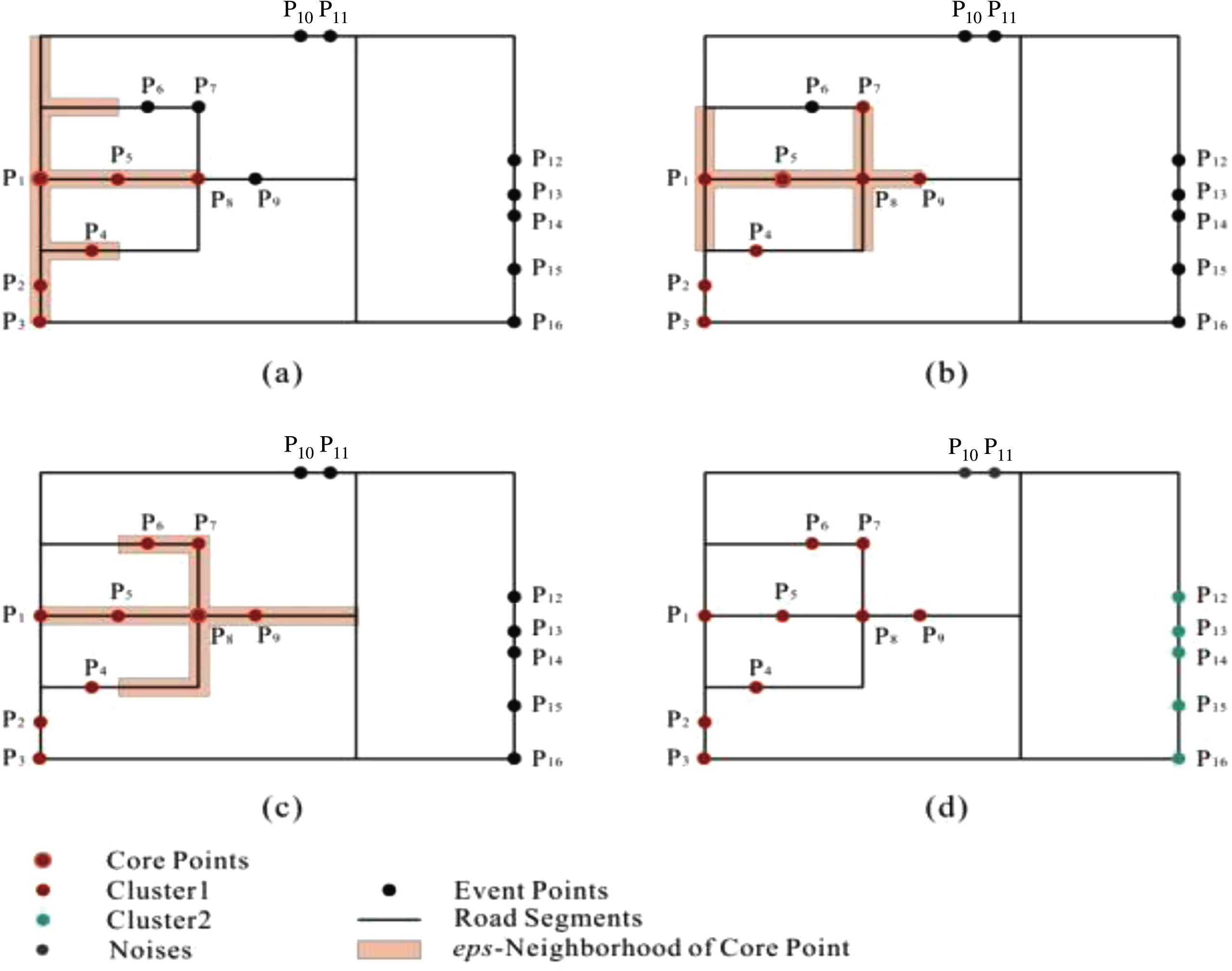
The border points of the core points are gradually put into the cluster: (a) P5, P2, P4, P8 and P3 are put into cluster C1 through P1: (b) P7 and P9 are introduced into cluster C1 through P5: (c) P8 brought P6 to C1: cluster C2 is formed from simulation data set (d) [3].
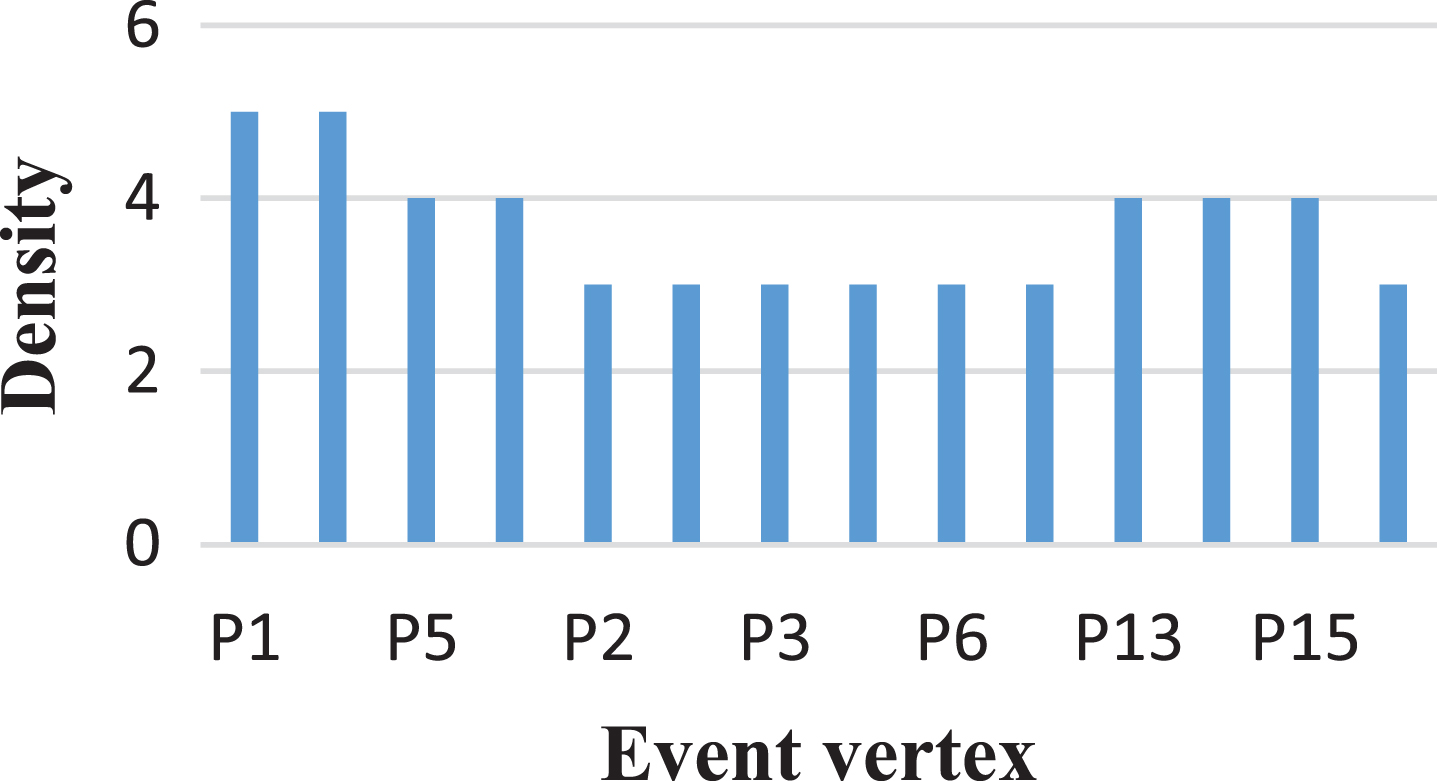
A density ordering graph of a simulated dataset.
Algorithm 3. Forming Clusters:
Building clusters: Initialize the cluster with core points and gradually add the border points into the cluster until no border points are added.
At line 2, the algorithm checks whether the event points belong to any clusters or sets of noise, lines 3 and 4 then continue evaluating the condition of points whose density is less than MinPts to assign those to noise.
The process of assessing whether points belong to any clusters or collections of noise in the for loop of line 1 costs time. Moreover, it is possible to wrongly assign border points whose density is less than MinPts to noise.
Noise is not determined during the process of cluster formation. Noise is those points that do not belong to any clusters. That is, lines 3 and 4 do not need to be executed to determine noise. Moreover, the statement in line 2 also omits the check as to whether an event point belongs to the noise set. This helps remove three test operations in the loop of the line 1. Therefore, the algorithm execution time is decreased. We do not determine core points in the process of forming clusters, and the noise will be those points that do not belong to any clusters. That is, we do not execute lines 3 and 4 to determine noise. Moreover, the statement in line 2 also omits the check as to whether an event point belongs to the noise set.
Considering eps = 1, MinPts = 4.
P1 is selected as the core and P1 does not in any clusters. Therefore, a new cluster, namely C1, is created containing P1. The border points of P1 (N _ eps (P1) = {P5, P2, P4, P8, P3}) is added into C1 so C1 = {P1, P5, P2, P4, P8, P3} (Fig. 6a).
The next selected core point in C1 is P5. The set of P5’s border points is {P1, P8P7P9}, where P1 and P8 ∈ C1, P7 and P9 ∉ C1, so P7 and P9 are added to C1 (Fig. 6b), C1 = {P1, P5, P2, P4, P8, P3, P9, P7, }. The density of P2 and P4 is 3, which is less than the value of MinPts (4), so no more points are added to C1. Similarly, P8 is the core point, so border points {P5, P9, P1, P7, P6} are added to C1 (Fig. 6c):
P3, P9 and P6 are not core points.
P7 is the core point but all its border points are {P8, P6, P5, P9}, which belong to C1.
Finally, the cluster C1 = {P1, P5, P2, P4, P8, P3, P7, P9, P6} is formed.
Similarly, the algorithm assigns P12 to P16 for the new C2 cluster.
The results of the clustering process are shown in Fig. 6d.
The original algorithm is capable of noise detection, and thus it marks P10 and P11 as noise.
This section presents the experimental results of the original NS-DBSCAN algorithm and the proposed improved algorithm, thus evaluating the efficiency of the improved algorithm compared to the original one.
Dataset
The Open Street Map (OSM) provides an easy-to-access platform that allows free access to geographic information worldwide.
The information is gathered by many volunteers from around the world, collated on a central database and distributed in many digital formats. Although OSM does not have a strict quality control mechanism, analysis shows that information about OSM can be quite accurate, and the data obtained from OSM is good enough and comparable to authoritative data to some extent [39].
OSM provides many types of data, such as points, lines, and regions. Points often represent points such as supermarkets, restaurants, hotels, schools, and so on. Polylines are used to indicate roads such as roadways, waterways, and railways. Polygons represent regional features such as national administrative regions, parks or forests, and so on. This free global dataset is currently being used by several research teams to solve social and economic problems as well as those in urban planning, ecology, and other areas, and as such this free dataset has opened boundless possibilities in commercial as well as academic research [37].
The study uses two free data layers downloaded from OSM: the points of interest (POIs) and the road layers. POI data indicates event points such as hotels, restaurants, fast food places, supermarkets, cafes, schools, etc. Road data is the national road network. This data is downloaded from the geofabric website http://doad.geofabrik.de/asia/vietnam.html.
The POIs and road dataset were downloaded from OSM on May 7, 2020. The data on Ho Chi Minh City, Vietnam was extracted from the POIs for further analysis. There are 10,352 points classified into 112 types (according to their functions) and 9,977 road segments after preprocessing, as depicted in Fig. 8.
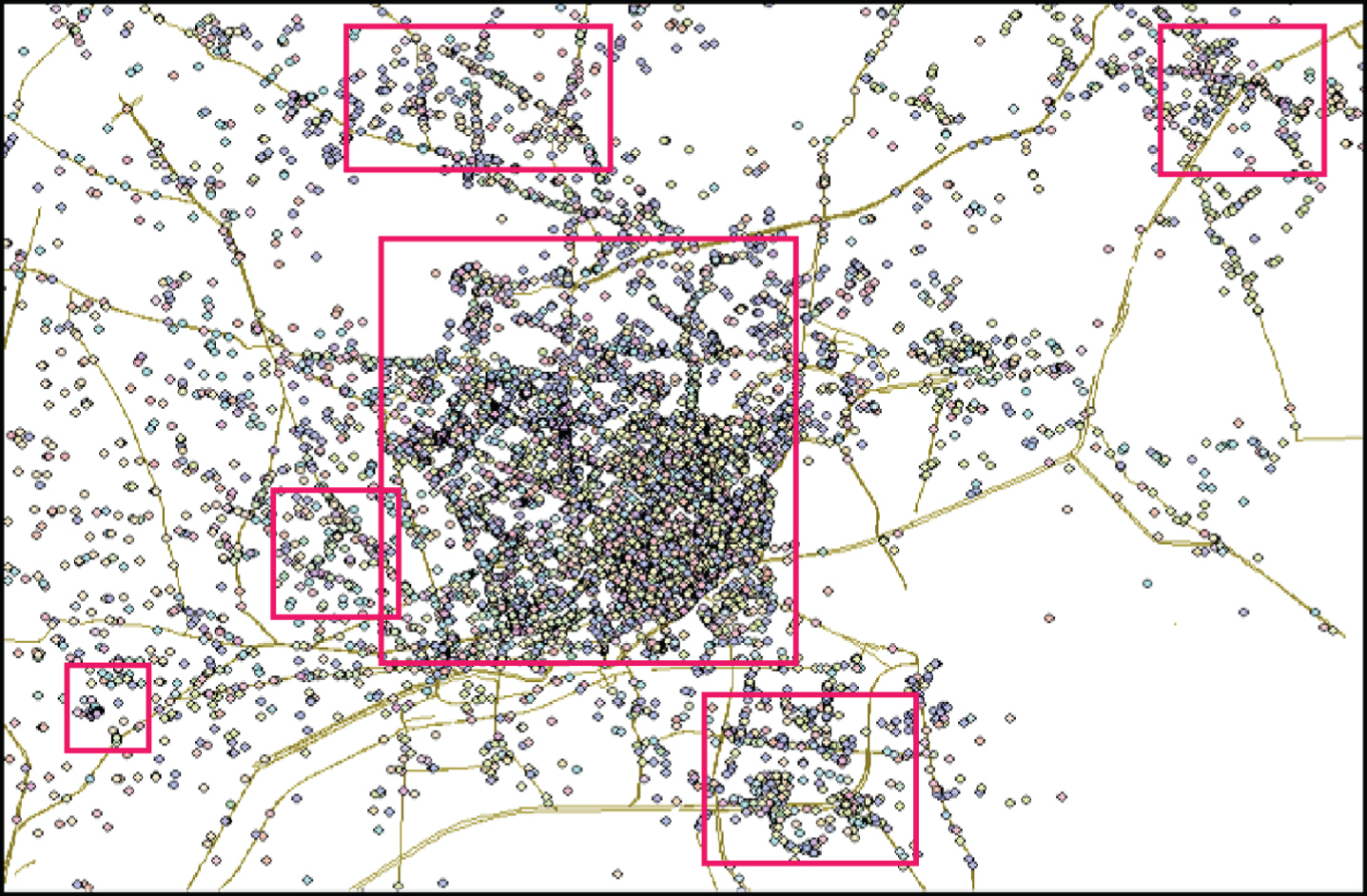
Points of interest (POIs) of Ho Chi Minh City included in 112 categories according to their functions for citizens. Each class is represented by a different color.
The road layer (gis_osm_roads_free_1) and POI layer (gis_osm_pois_free_1) were preprocessed before they were used in the experiment:
–Clipping road and POI data of Ho Chi Minh City.
Deleting all flyovers and tunnels to make the road network planar.
Merging the divided segments of a road (by drawing operations) into one fully-made road.
Moving the points along the roads to its nearest segment to create event vertices, the intersection of the segments creates normal vertice s.
Splitting road segments at event vertices.
Results
The proposed algorithm is compared with the NS-DBSCAN algorithm using the same dataset HCM (for Ho Chi Minh City). Both algorithms were implemented in Python and ArcGIS and run on a computer using an Intel(R) Core (TM) i5-8250U CPU @ 1.60 GHz (4 cores), Memory: 4GB DDR4 SDRAM. Figures 11 15 show the evaluation results.
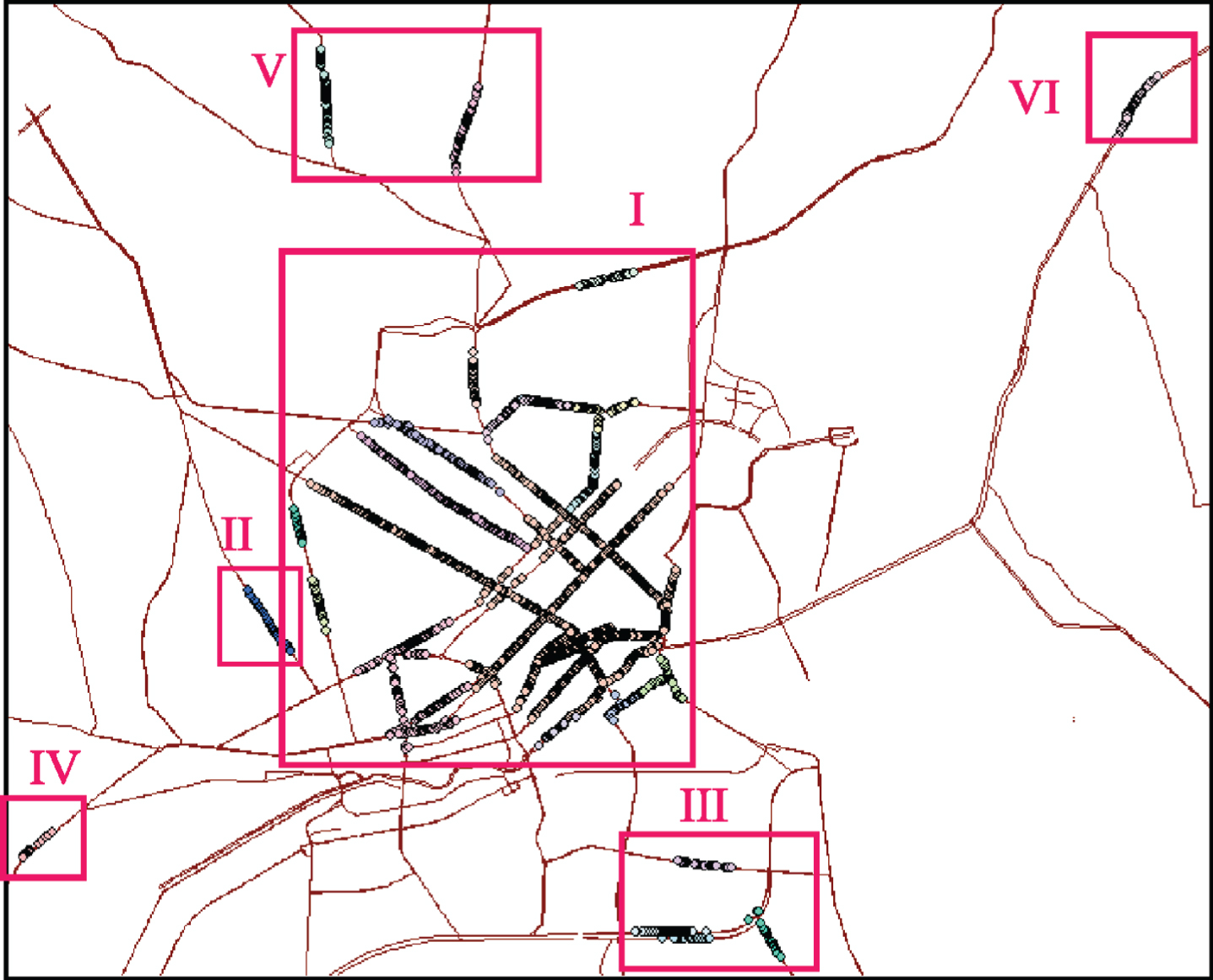
The clusters of the NS-DBSCAN algorithm (eps = 300, MinPts = 30) accurately delineated the six highly populated regions of aggregated POIs.
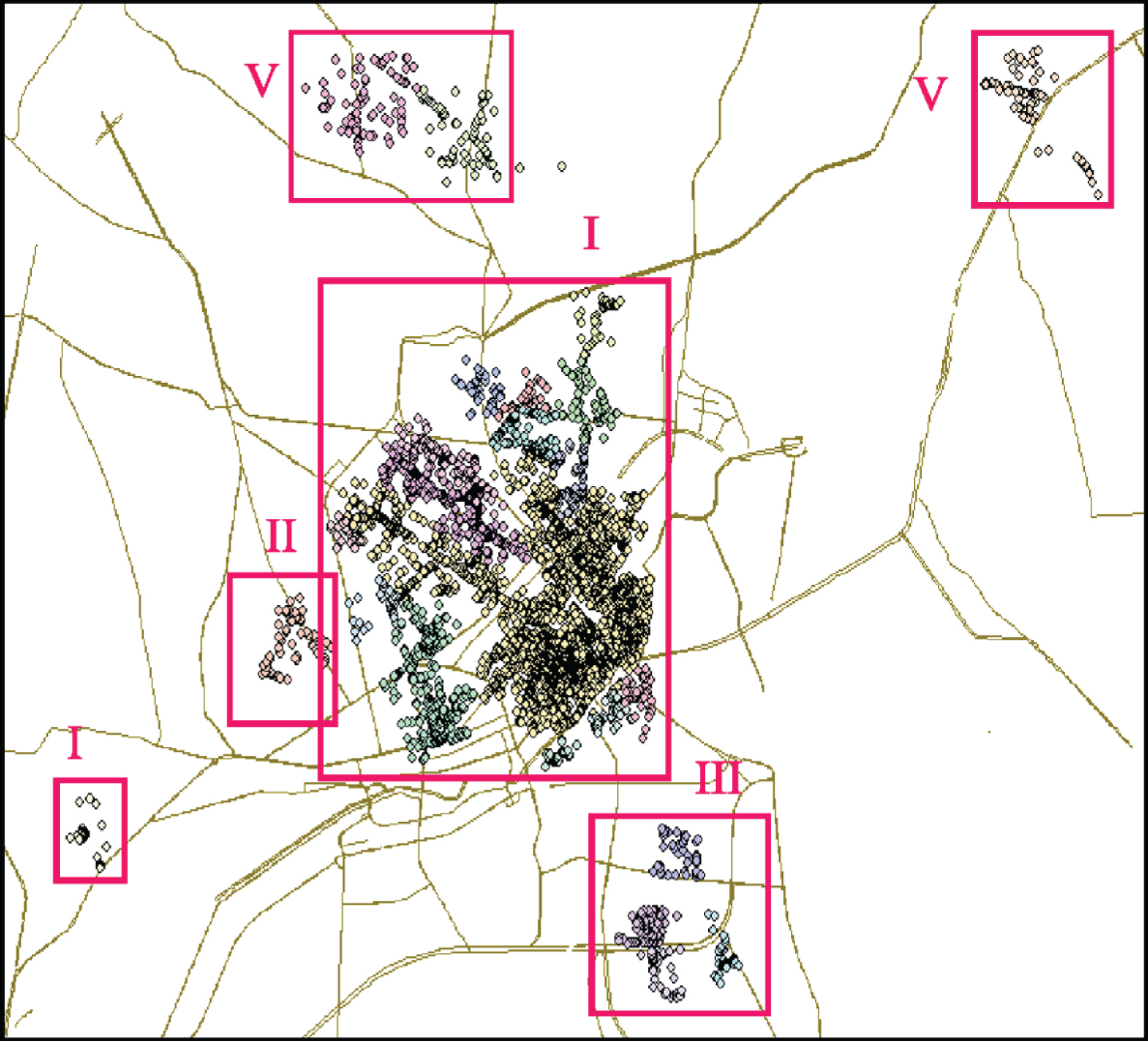
The points of interest (POIs) of Ho Chi Minh City included six aggregated regions: I, Group of Districts 1, 3, 5, 10, Phu Nhuan; II, Center of District 11; III, Center of District 7; IV, Center of District Binh Chanh; V, Area of Military Technical Officers School; VI, Area of Technical Pedagogy University.
Comparison of the original and improved algorithms.
Comparison of the original and improved algorithms (eps = 250).
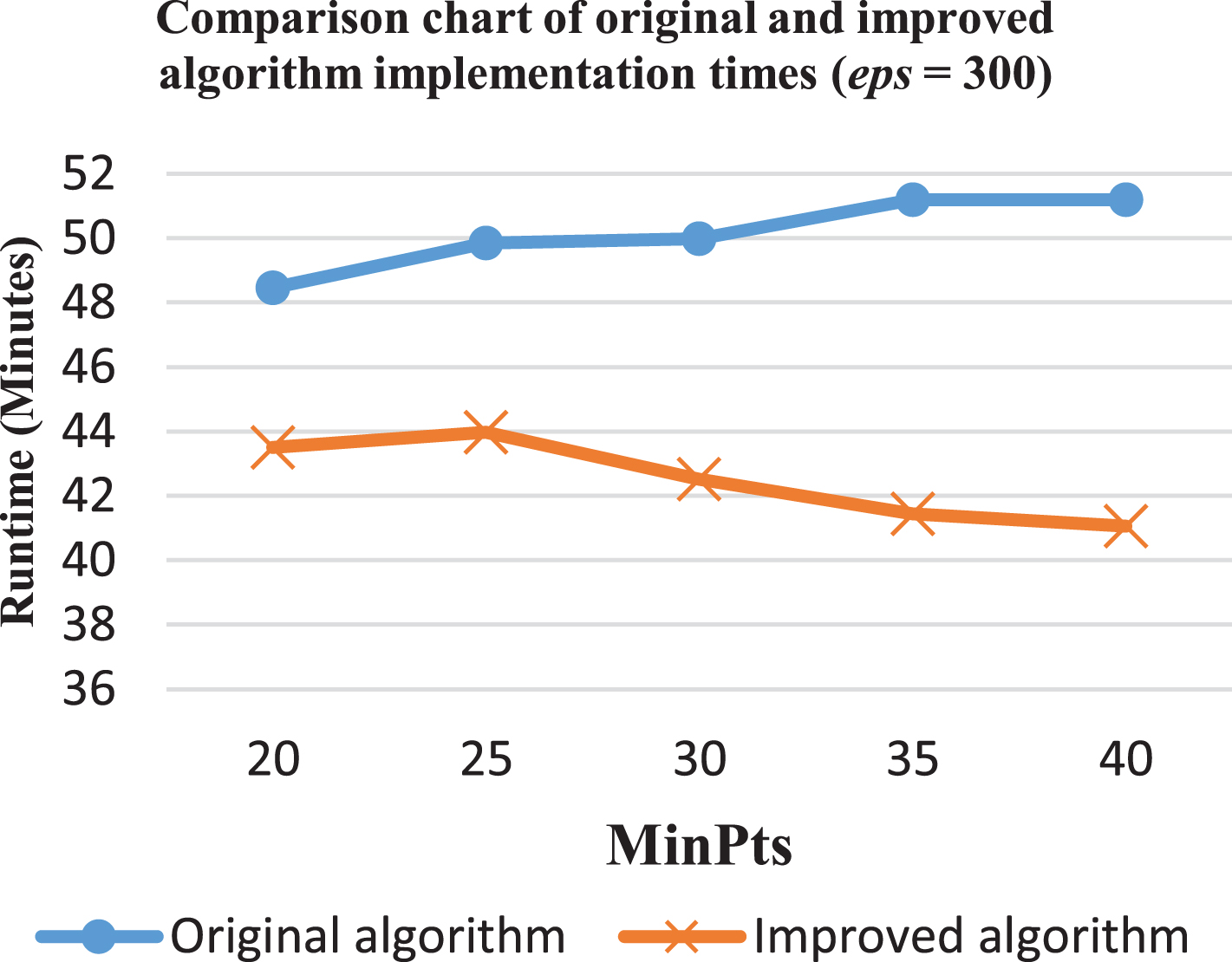
Comparison of the original and improved algorithms (eps = 300).
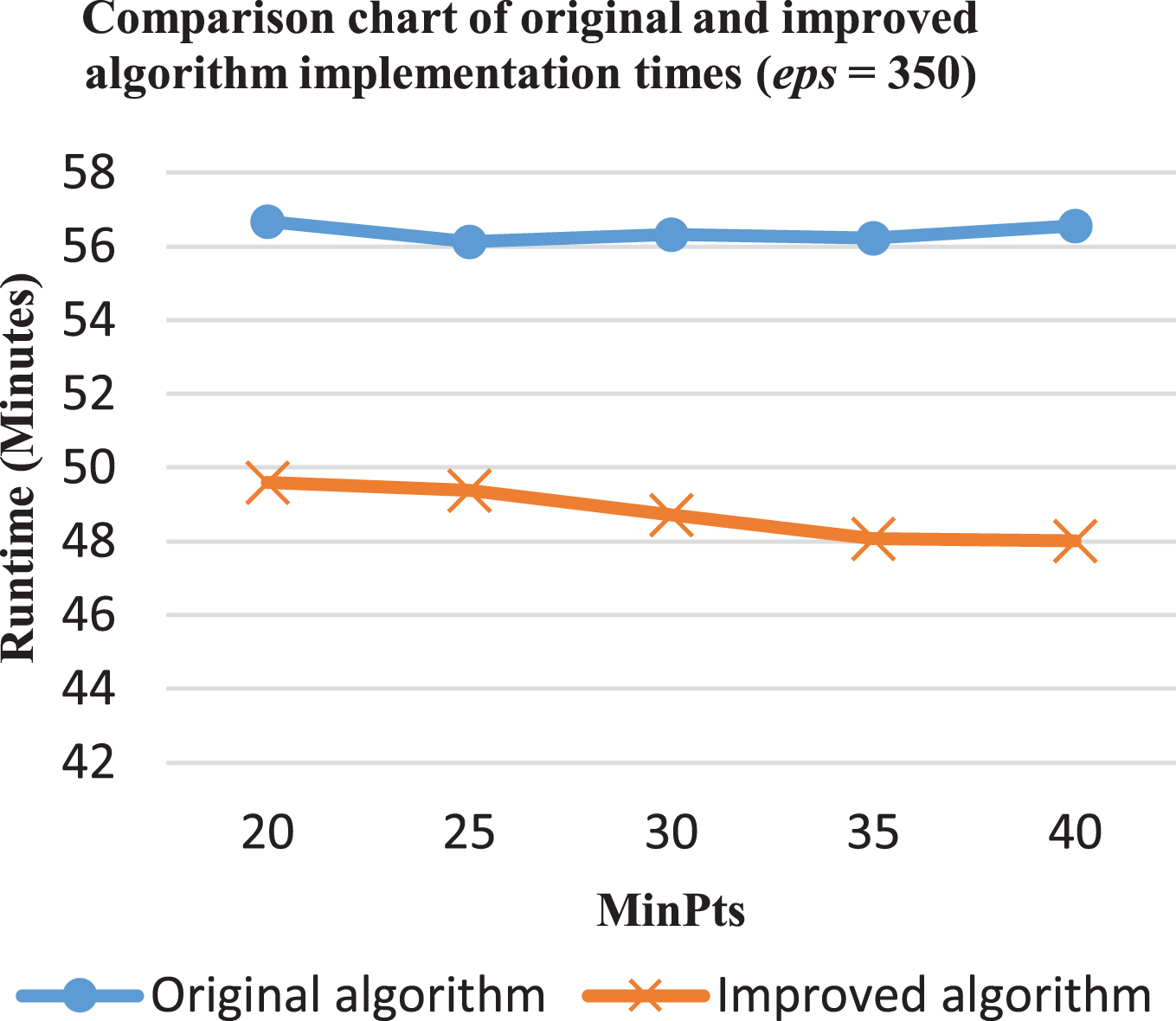
Comparison of the original and improved algorithms (eps = 350).
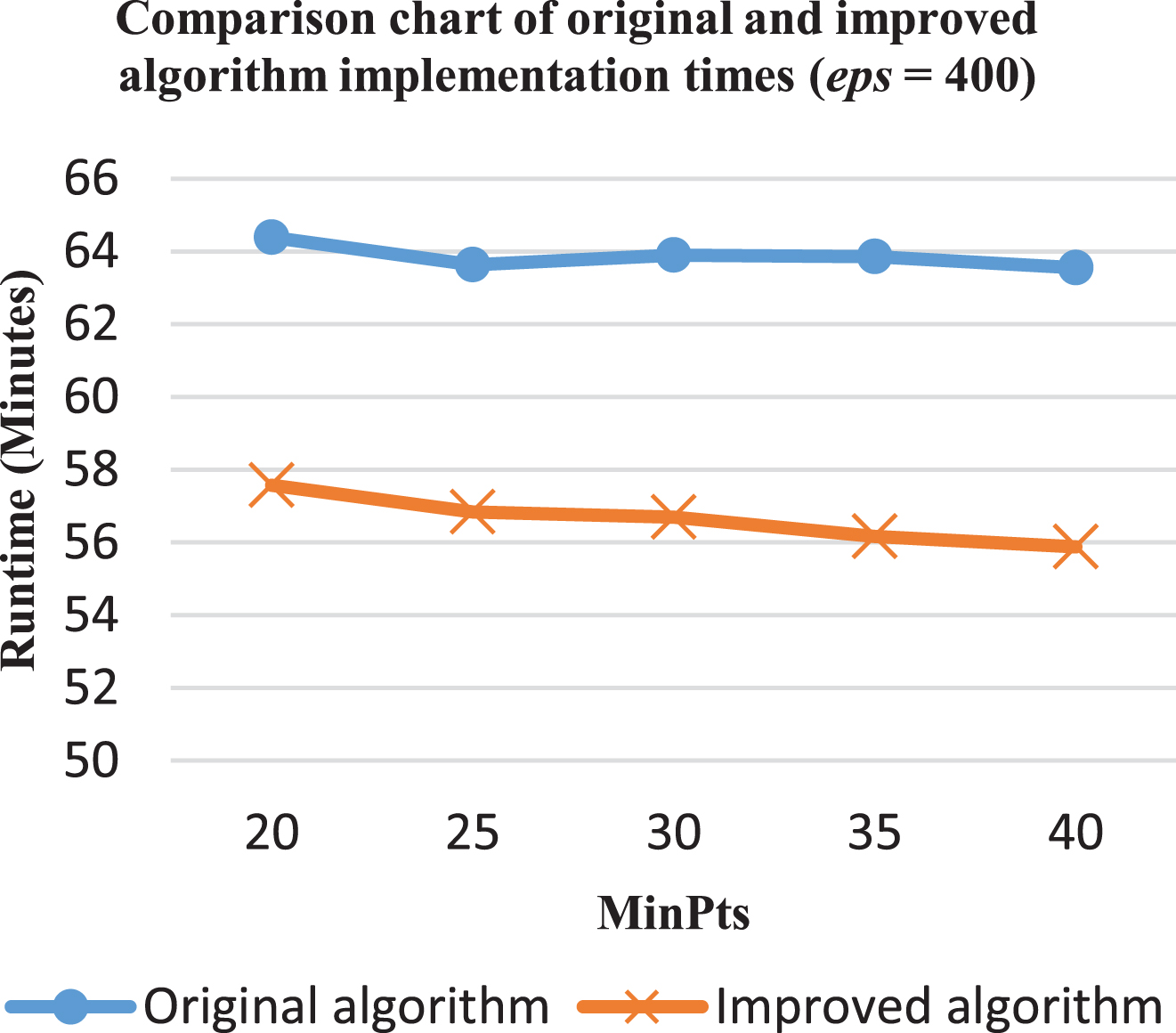
Comparison of the original and improved algorithms (eps = 400).
Figure 9 shows the clustering results of the NS-DBSCAN algorithm and proposed algorithm, and the results are expressed in real coordinates of POIs as follows (Fig. 10).
The following charts show the results of comparing the implementation time of the original algorithm with that of the improved algorithm with eps = 200, 250, 300, 350 and 400.
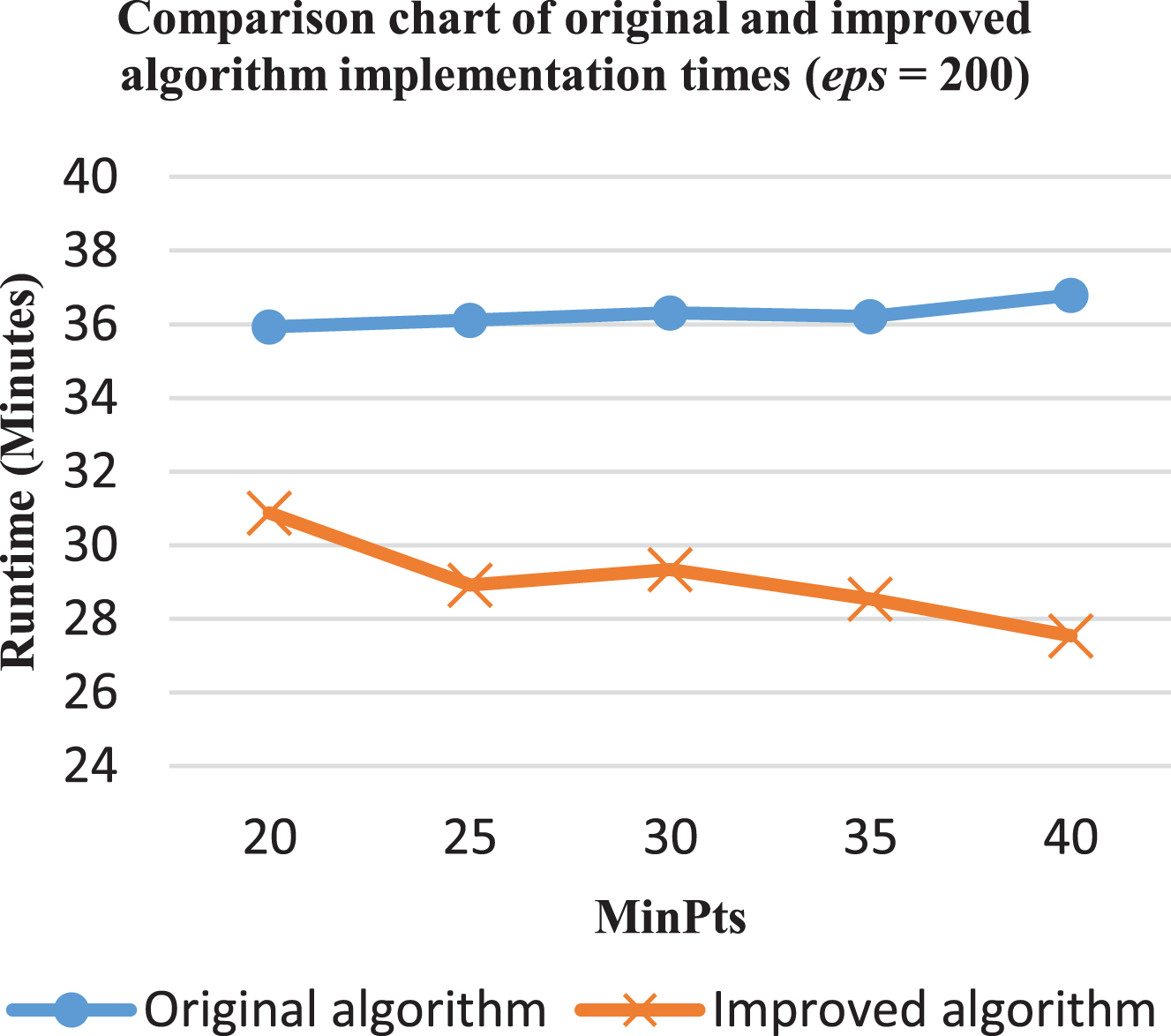
The chart shows a comparison of the execution time between the original and improved algorithms with a distance of 200 meters eps (Fig. 11). There is clearly a significant time difference between the original and improved algorithms. The improved algorithm needs from 14% to 25% less processing time. The lowest reduction is the case of MinPts = 20, for which the time needed fell by 14%, from 36 minutes to 31 minutes, the highest was MinPts = 40, which reduced the processing time by 25%, from 37 minutes to 28 minutes.
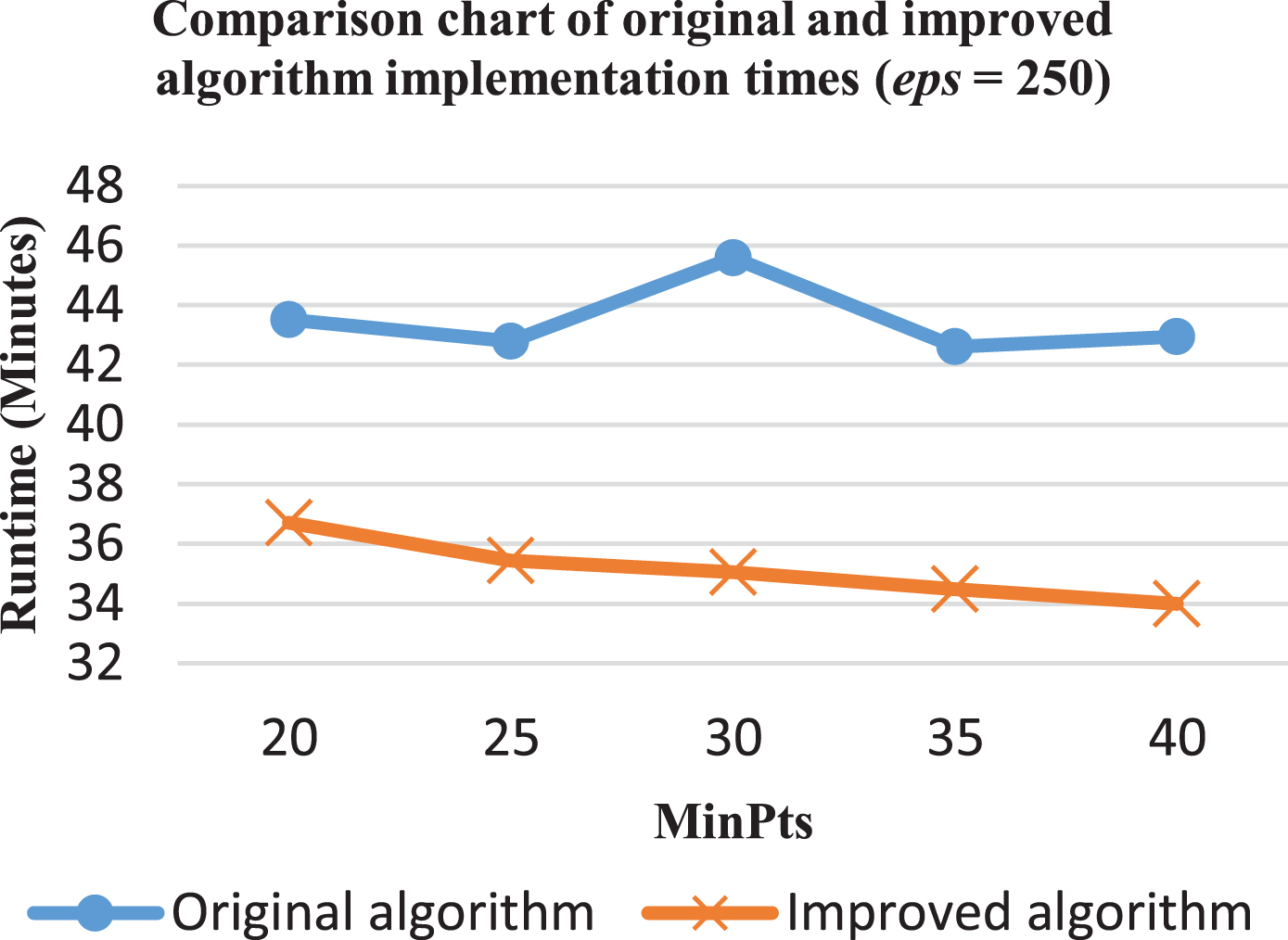
As when eps is 200, with eps = 250 the difference between the original and improved algorithms is significant with regard to time, ranging from 16% to 23% (Fig. 12). The most time-saving point in this case is MinPts = 30, when the processing time of the improved algorithm is 35 minutes compared to 46 minutes using the original algorithm, a fall of 23%. The remaining cases are 37 minutes compared to 44 (17% faster), 35 minutes compared to 43 (a decline of 17%), and 34 minutes compared to 43 (a fall of 19%), corresponding to threshold values of MinPts of 20, 25, 35, and 40, respectively.
In case of eps = 300, the difference in the time needed for the two algorithms ranges from 10% to 20%. The highest reduction is 20% at MinPts = 40, the lowest is 10% with MinPts = 20 (Fig. 13).
With eps = 350, the difference in processing time ranges from 12% to 15%. When MinPts = 40, it is reduced by 9 minutes, from 57 to 48. In the cases of MinPts = 20 and 25 it falls by 7 minutes, from 57 minutes to 50 and 56 minutes to 49, respectively (Fig. 14).
When eps = 400, the execution time of the algorithm falls in the range of 11% to 12% (Fig. 15).
Therefore, the experimental results show that the algorithm processing time decreases, on average, by 16%. In particular, in the situation that eps = 200 and MinPts = 20, the amoung of time for processing could fall by a crushing 25%, giving it an enormous advantage over the original algorithm. As such, the improved algorithm has been proved to be a time-saving tool to cluster data.
In addition, with data for Ha Noi, Da Nang, Can Tho, Dong Nai and a number of provinces, the results are as follows.
Ha Noi has 10,273 points and 11,683 road segments. The table shows a comparison of the execution time between the original and improved algorithms (Table 1). The highest reduction is 19% at eps = 200 and MinPts = 20.
Da Nang has 3,284 points and 8,339 road segments. The difference in the time needed for the two algorithms ranges from 0% to 15%. The highest reduction is 15% (Table 2).
Comparison of the original and improved algorithms for Ha Noi
Comparison of the original and improved algorithms for Da Nang
Can Tho has 2,563 points and 6,277 road segments. The greatest difference in processing time is 15% (Table 3).
Comparison of the original and improved algorithms for Can Tho
Dong Nai has 2,704 points and 6,958 road segments. The greatest difference in the time needed for the two algorithms is 15% (Table 4).
Comparison of the original and improved algorithms for Dong Nai
Provinces including Binh Thuan, Dak Lak, Dak Nong, Lam Dong, Ninh Thuan have 5,647 points and 15,694 road segments. The improved algorithm needs from 3% to 16% less processing time (Table 5).
Comparison of the original and improved algorithms for Binh Thuan, Dak Lak, Dak Nong, Lam Dong and Ninh Thuan
Provinces including Ben Tre, Can Tho, Dong Thap, Hau Giang, Tien Giang, Vinh Long have 4,316 points and 14,173 road segments. The highest reduction is 16% at eps = 350 and MinPts = 15 (Table 6).
Comparison of the original and improved algorithms for Ben Tre, Can Tho, Dong Thap, Hau Giang, Tien Giang and Vinh Long
Provinces including Binh Dinh, Gia Lai, Kon Tum, Phu Yen, Quang Nam, Quang Ngai have 4,446 points and 18,665 road segments. The biggest difference in the time needed for the two algorithms is 15% (Table 7).
Comparison of the original and improved algorithms in Binh Dinh, Gia Lai, Kon Tum, Phu Yen, Quang Nam and Quang Ngai
Other cases also give the similar results to those presented above.
The improved algorithm produces the same clustering results as the original algorithm with the following silhouette measurements [40] in Table 8.
Comparison of the silhouettes of the original algorithm and improved algorithm
The indicators for evaluating the effectiveness of the NS-DBSCAN algorithm compared with NC_DT and hierarchical clustering algorithms [3] are shown in Table 9.
Indicators for Evaluating the Effectiveness of Clustering Algorithms [3]
In this article, we have presented an efficient method, NS-DBSCAND, to help reduce processing time. In Algorithm 1 (LSPD), we determine the neighbor of the central point (cp) within an eps radius to form a set of all points within eps distance from cp by extending the line from cp to its adjacent points. The expansion to the adjacent points lasts until the expanded path is no longer shorter than the current length or it exceeds eps. As such, the expansion path will definitely not go beyond the edges whose length exceeds eps. Therefore, the first recommendation is to remove the edges whose length exceeds the eps distance when organizing data. Secondly, when generating the density ordering table, we do not include points whose density is lower than ln (10, 352) ≈ 9, according to [38]. The elimination of these points helps reduce the number of browsing points in Algorithm 3 (The original algorithm works by calculating the density for all event points and putting all vertices into the density ordering table, even those points with a density of 0). This does not affect the result because low-density points definitely do not belong to any clusters. Thirdly, some improvements in programming techniques are made to reduce computational operations and the processing time of the algorithm, as assessed in Section 3.
The most important and time-consuming operation of the NS-DBSCAN algorithm is to identify neighbors for all points, and it fares worse when processing a sequence which consists of an enormous number of points. Therefore, one future development direction is to simultaneously identify neighbors for multiple points using parallel programming techniques to reduce the algorithm’s implementation time. Distributed data processing using MapReduce is one method that may accomplish this goal.
In addition, more clustering methods will be considered for use in clustering the network space in the future works, like clustering by fast search and find of density peaks [41].