
Abstract
A novel actor-critic algorithm is introduced and applied to zero-sum differential game. The proposed novel structure consists of two actors and a critic. Different actors represent the control policies of different players, and the critic is used to approximate the state-action utility function. Instead of neural network, the fuzzy inference system is applied as approximators for the actors and critic so that the specific practical meaning can be represented by the linguistic fuzzy rules. Since the goals of the players in the game are completely opposite, the actors for different players are simultaneously updated in opposite directions during the training. One actor is updated updated toward the direction that can minimize the Q value while the other updated toward the direction that can maximize the Q value. A pursuit-evasion problem with two pursuers and one evader is taken as an example to illustrate the validity of our method. In this problem, the two pursuers the same actor and the symmetry in the problem is used to improve the replay buffer. At the end of this paper, some confrontations between the policies with different training episodes are conducted.
Keywords
Introduction
Differential games are a class of problems about the modeling and analysis of conflicts in dynamics. The pursuit-evasion problem is a classical zero-sum differential game, and was originally proposed by Isaacs [1]. The original pursuit-evasion problem involves optimize control policies for two players, the pursuer and the evader, playing against each other. The goal of the pursuer is to catch the evader in as little time as possible. And the goal of the evader is to delay the moment of collision as much as possible [2, 3]. Since Isaacs, to solve the pursuit-evasion problem, a large number of studies have been published, and various methods have been proposed [4–6]. In addition, more types of pursuit-evasion problems have been raised, such as pursuit-evasion problems with multiple pursuers or multiple evaders [7, 8].
In addition to the classical method listed above, in some studies, reinforcement learning (RL) algorithms have been applied for solving differential games [9]. RL is an area of machine learning concerned with how agents ought to take actions in an environment in order to maximize the cumulative reward [10, 11]. Unlike supervised learning, which are trained using data provided by humans, RL learns from the experiences gained in interaction with the environment [10, 12]. However, there is limited research on the application of RL alone to solve complex problems. With the development of deep learning technology, in many studies, deep neural networks are applied as function approximators do deal with high dimensional states. These approaches are known as deep RL [13–16].
Fuzzy logic, as a widely used engineering method, can acquire fuzzy rules from human experience and demonstrate the capacity to address the knowledge that cannot be precisely described. In recent years, fuzzy logic has been combined and adopted in the pursuit-evasion problem [16–18]. In these researches, the controllers were optimized based on value-based RL methods such as Q-learning.
Value-based RL can only handle discrete and low-dimensional action spaces. An obvious approach to adapting such RL method to problems with continuous action space is to simply discretize the action space [15]. In some cases with high-dimensional action space, however, learning fuzzy rules directly using value-based RL method can lead to "curse of dimensionality" [19]. To make RL available for problems with high dimensional state space, the actor-critic (AC) algorithm was proposed. In AC method, the evaluator (critic) and controller (actor) are separated with different approximators [20] such as neural networks. The actor learns to approximate the control policy, i.e. take action according to the current system state. The critic learns to estimate the Q value function of a state-action combination [21].
Previously, it was thought that, the application of a parametric probability density function to represent the control policy is the only wey. This is also known as the stochastic strategy gradient (SPG) theorem. After that, the deterministic policy gradient (DPG) theorem was proposed [22] In DPG theorem, the output of the controller is deterministic. It no longer depends on the probability distribution but on the system state. Recently, the combination of deep neural networks and DPG have been applied to problems with continuous action spaces [15].
However, it is generally acknowledged that a neural network is black box, its practical meaning is difficult to be described [23]. In this paper, to overcome the "curse of dimensionality" and clarify the practical meaning of learning results, the combination of DPG and fuzzy logic is used to solve the pursuit-evasion problem. A algorithm based on fuzzy inference system (FIS) and DPG referred to as the Minmax Fuzzy Deterministic Policy Gradient (Minmax-FDPG) is proposed. In this algorithm, some FISs [24] are used to approximate the actors and critics in a novel AC structure to learn the control policies. Unlike the classical AC structure, the novel structure consists of two actors and one critic, different actors represent control policies of different players and due to the properties of zero-sum game, the direction of optimization of different actors are opposite. In addition, the input of the critic is the combination of system state and all player actions. Similar to many existing RL algorithms, sometimes, nonlinear approximators may cause some convergence problems. To ensure the convergence of the proposed Minmax-FDPG, the target approximators, replay buffer and mini-batch techniques are used.
In order to illustrate the effectiveness of our method, a pursuit-evasion problem with two pursuers and one evader is established as an Markov Decision Process (MDP), and the Minmax-FDPG is used to train the control policies of these three players simultaneously. In this problem, the two pursuers share the same actor, while the evader uses the other actor. And the symmetry in the problem is used to improve the replay buffer. The goal is to train the actors of both sides of the game to learn the relatively optimal control policies via interacting with the environment.
In general, the main contributions of this paper are as follows: Instead of deep neural networks, some FISs are applied as approximators in the proposed method to deal with the zero-sum differential game with continuous action space, and a pursuit-evasion problem with two pursuers and one evader is taken as an example. Instead of training a player’s policy with a fixed opponent’s policy, the policies of all players in a pursuit-evasion game can be optimized simultaneously in the proposed method. Based on the properties of FIS, the learning results can describe the practical meaning of each rule. To demonstrate the effectiveness of training, some confrontations between the policies with different training episodes are conducted.
The remainder of this paper is organized as follows: Some background knowledge are introduced in Section 2. In Section 3, the structure of the proposed Minmax-FDPG is described, the gradients of the parameters in each actor and critic are derived and the updating process is introduced. In Section 4, a pursuit-evasion problem is taken as an example to illustrate the validity of the proposed method. Lastly, a brief conclusion is presented in Section 5.
Background
Reinforcement learning
As described earlier, instead of learning from data provided by human, RL learns from data generated by interaction with the environment. In the majority of the existing studies, the environment is modeled as an MDP denoted by a tuple
AC is the most commonly used RL structure [31], whose architecture is displayed in Fig. 1. Deep Deterministic Policy Gradient (DDPG) is one of AC algorithm. For critic, a deep neural network Q θ (s, a) parameterized by θ is used to represent the Q value function. For the actor, another deep neural network A α (s) with parameters α is used to approximate the control policy.
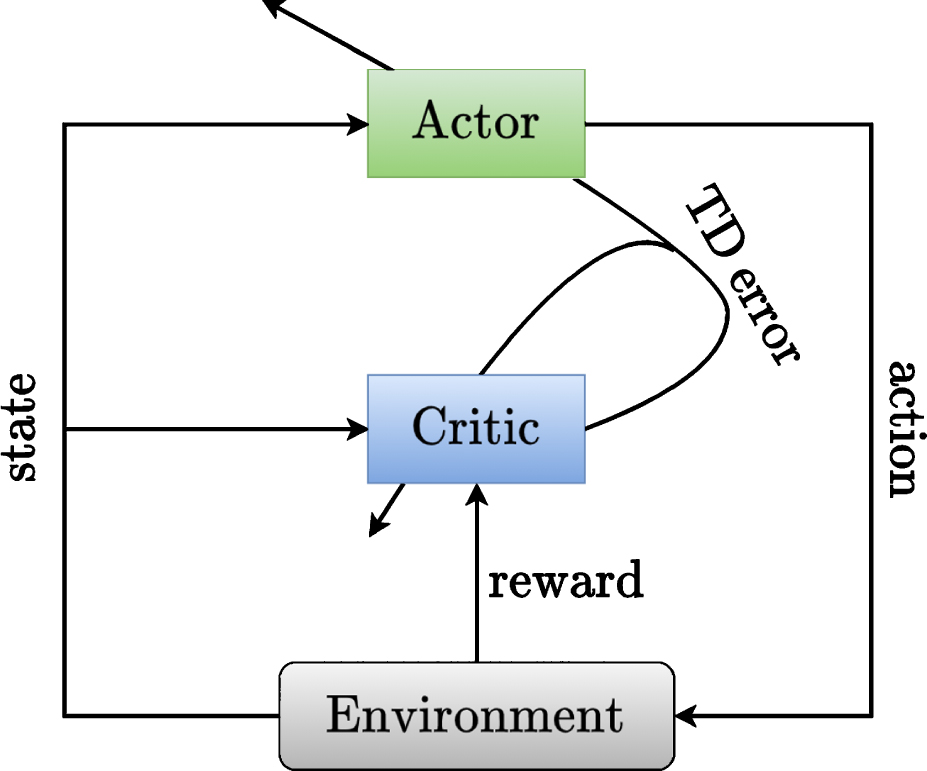
The AC architecture.
In each training iteration, the agent interacts with the environment once, the experience (s t , a t , r t , st+1) is stored in the replay buffer, and a mini-batch of experiences are randomly sampled from the replay buffer to train the actor and the critic. The target critic and actor are updated by soft copying Q θ and A α to Qθ′ and Aα′ every training iterations.
In this paper, the Minmax-FDPG is modified on the basis of DDPG, and will be introduced in the next section.
Unlike the black box represented by a neural network, a FIS is an interpretable mapping consists of several rules. A typical form of a FIS model with several inputs can be described as the following equation [16, 32]:
Fig. 2 shows the structure of a FIS consists of five layers. The first layer is the input layer, In this layer, the data consisting of multiple components are input to the FIS. The second layer is the fuzzy layer. In this layer, the membership of the ith input in the lth rule is defined by a Gaussian function with mean
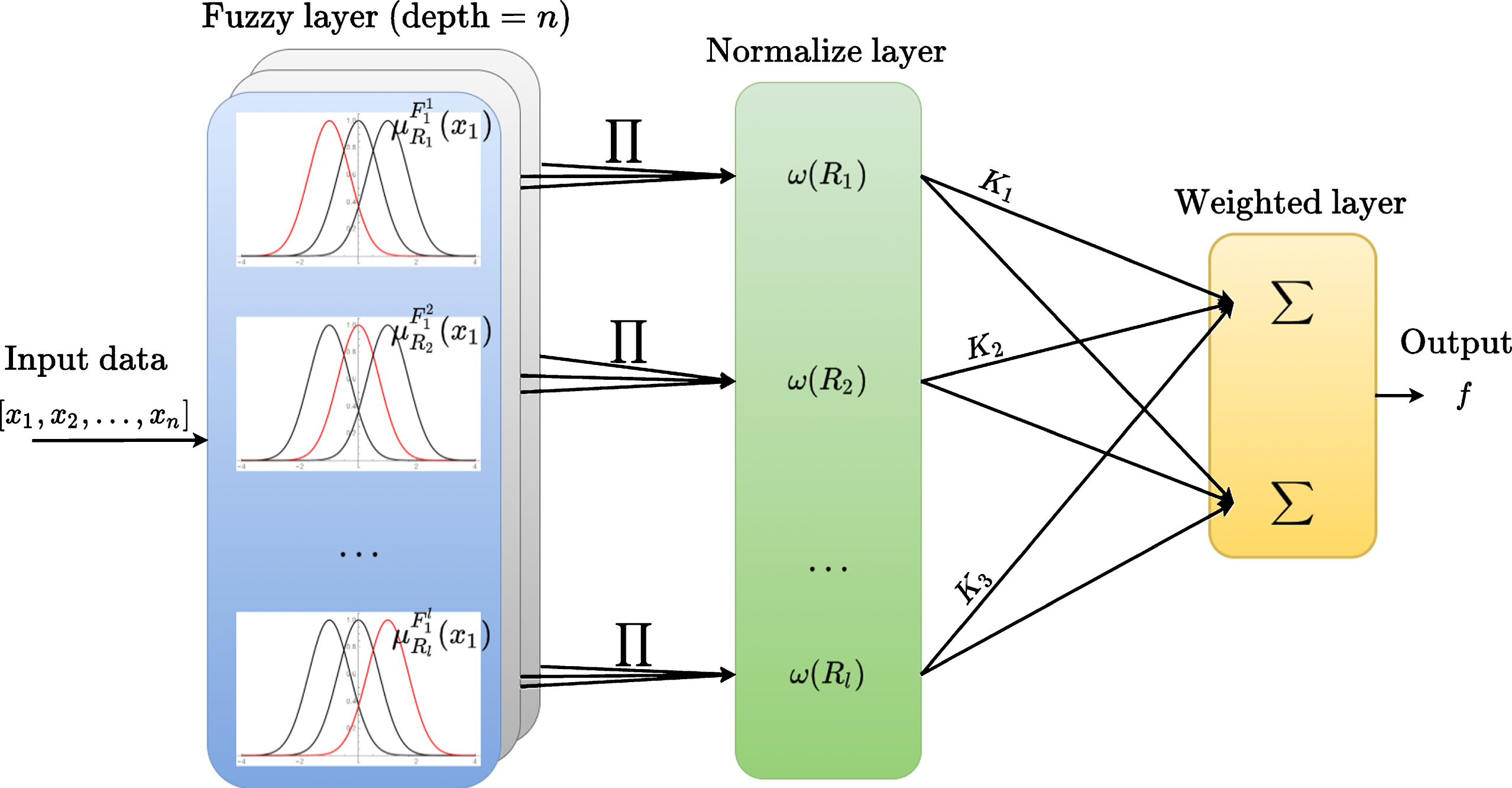
Components of fuzzy inference system.
We consider a pursuit-evasion problem with two pursuers and one evasion, as shown in Fig. 3.
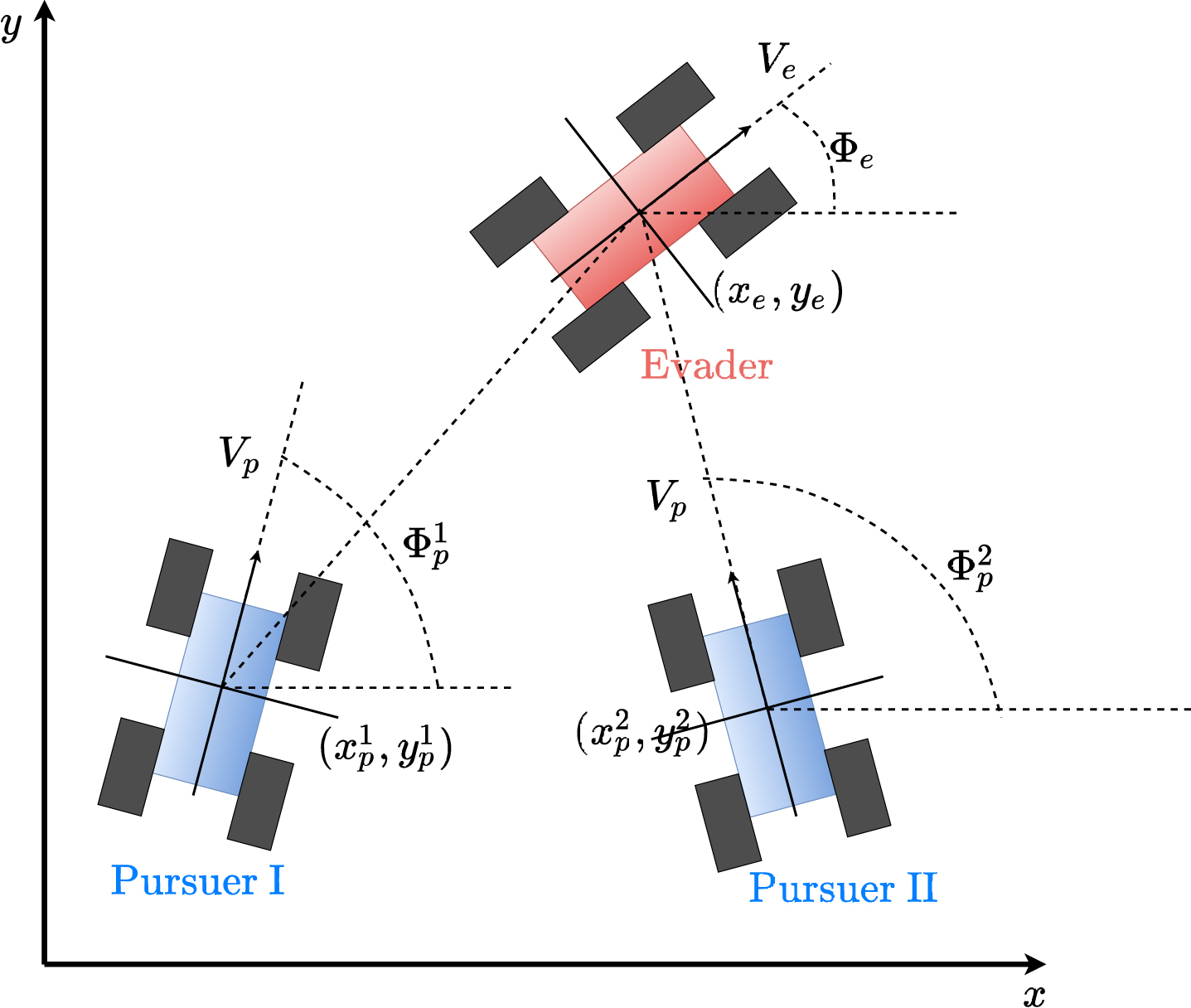
The schematic of pursuit-evader problem.
In Fig. 3, the tuples
MDP modeling
In the pursuit-evasion problem, the next states of both sides of the game are merely determined by the states and actions at this step. Therefore, it can be modelled as a MDP. To simplify the analysis of the problem, we consider a state space with reduced dimension. The pursuit-evasion game can be stated in a coordinate system fixed to the body of the evader [33, 34], see Fig. 4. Then the state of the system can be represented as:
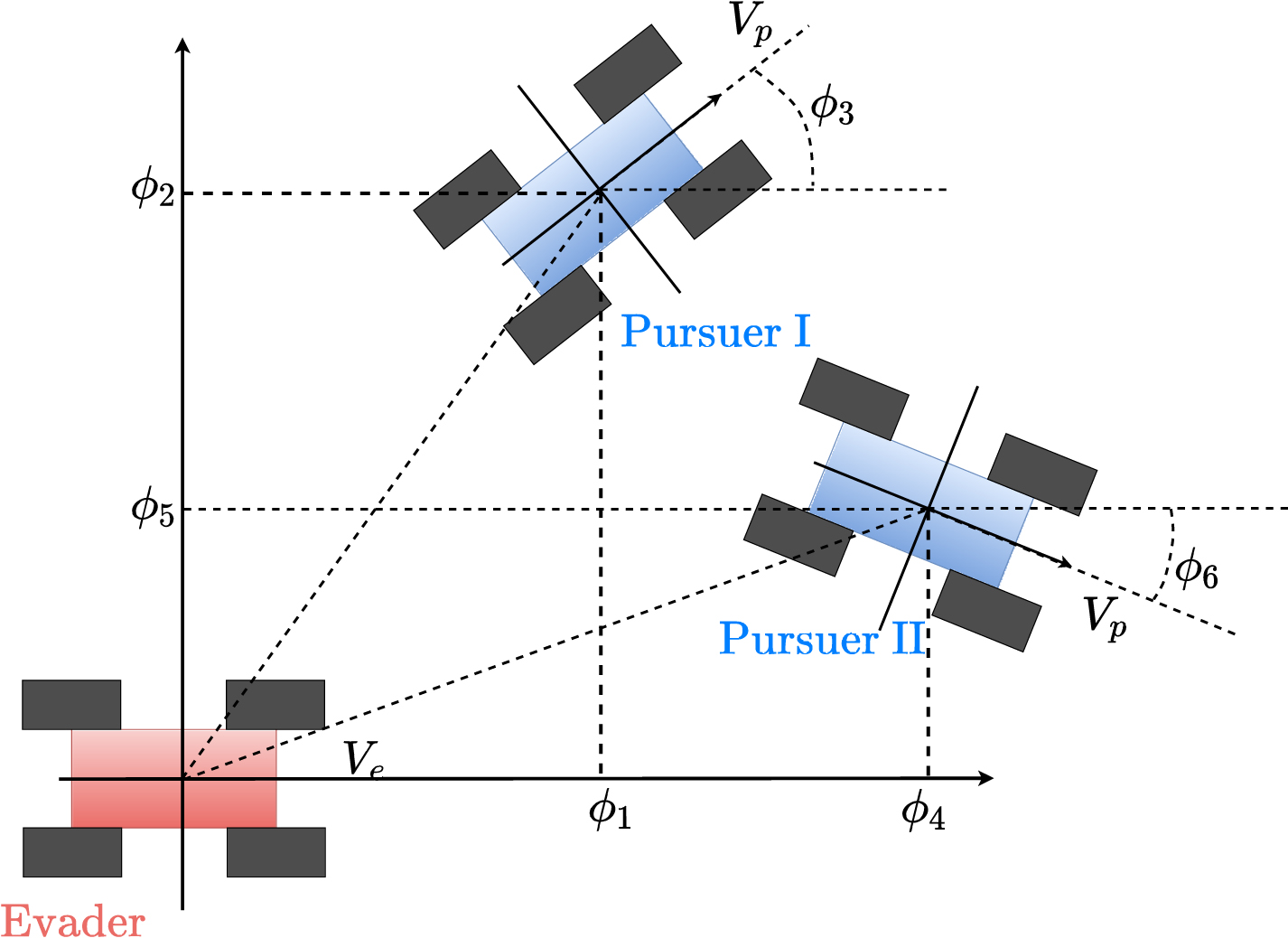
Reduced space of the pursuit-evasion game.
At time step t, the action consists of the steering angles of both players, i.e.:
In the pursuit-evasion game, the purpose of the pursuers and the evader are diametrically opposed, the goal of the pursuers is to close the distance with the evader, while the goal of the evader is to distance itself from the pursuers. Therefore, some changes need to be made in the Bellman equation in Equ. 1. The optimal state-action value function in the pursuit-evasion game is:
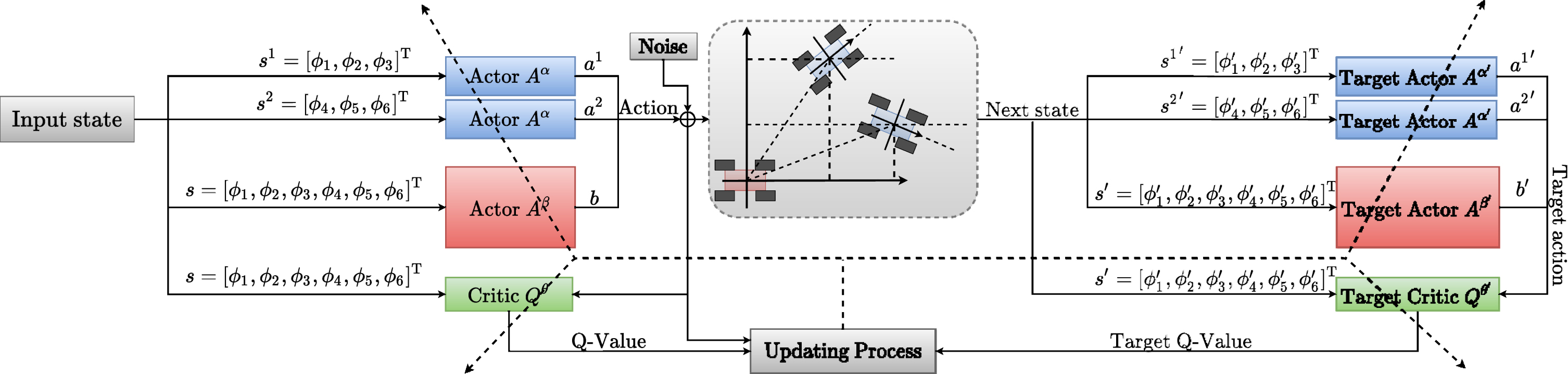
Structure of Minmax-FDPG
In order to overcome the divergence caused by the nonlinear function approximators, the replay buffer and target value technique are used [25]. And in our method, the replay buffer is improved using the symmetry in the problem. First, the agents’ experiences generated by interacting with environment are pushed into the buffer. Second, an iterative update mechanism is adopted to tune the Q values to the target values which are only periodically updated. Third, the two actors is updated towards opposite directions, for the pursuer, its actor is updated toward the direction that can minimize the Q value, while for the evader, its actor is updated toward the direction that can maximize the Q value. The updating process will be described in detail in the following sections.
Replay buffer with consideration of symmetry and mini-batch
The replay buffer is a block of memory space applied to store the agents’ experiences at each time of interacting with environment. In each training step, a mini-batch consists of some experiences which are randomly selected from the replay buffer is used to update the parameters of the networks. The replay buffer always stores the newest experience and drops the oldest experience. Moreover, the pursuit-evasion game in this paper implies a certain symmetry: For the evader, after exchanging the states of Pursuer I and Pursuer II, the situation remains the same and, therefore, the action it should take remains the same. And for the pursuers, after exchanging the states of Pursuer I and Pursuer II, the actions they should take also need to be exchanged. see Algorithm. 1.
1: Initial replay buffer
2: Observe the state [φ1,t, φ2,t, φ3,t, φ4,t, φ5,t, φ6,t] T, take the action
3:
4: i ← 0;
5:
6: s t ← [φ1,t, φ2,t, φ3,t, φ4,t, φ5,t, φ6,t] T;
7: st+1 ← [φ1,t+1, φ2,t+1, φ3,t+1, φ4,t+1, φ5,t+1, φ6,t+1] T;
8:
9:
10: i ← i + 1;
11: s t ← [φ4,t, φ5,t, φ6,t, φ1,t, φ2,t, φ3,t] T;
12: st+1 ← [φ4,t+1, φ5,t+1, φ6,t+1, φ1,t+1, φ2,t+1, φ3,t+1] T;
13:
14:
15: i ← i + 1;
As can be seen in Algorithm. 1, After taking the symmetry into account, the agents can generate two tuples of experiences for each interaction with the environment.
Tuning of the parameters of actors
For the pursuers, the gradient of the actor A α is:
The terms
Second, the gradient of a1 with respect to α is:
Similarly, the gradient of a2 with respect to α is:
In practical applications, the gradient in Equ. (17) is estimated from a mini-batch of experiences, denoted as
For the evader, similarly, the gradient of Q value with respect to β can be estimated by:
Since the goal of the pursuer is to close the distance with the evader, the direction of updating parameters α should be the direction that can minimize the Q value. The parameters α can be optimized by applying the following gradient descent:
The critic network Q θ (s, a1, a2, b) is learned based on Bellman Equation as in DDPG. The mean square error (MSE) loss function is defined as:
To tune the parameters θ, the following gradient descent algorithm is applied:
Directly copying the parameters of networks A α , A β , Q θ to the target networks Aα′, Aβ′, Qθ′ might be unstable in some environments [15]. Instead of a direct copy, a soft update method is applied:
Given all the techniques introduced above, the complete algorithm of the proposed Minmax-FDPG is described in Algorithm 2.
1:
2: Randomly initialize neural networks for two actors A α , A β and network for critic Q θ ;
3: Initialize the target networks Aα′, Aβ′, Qθ′, and α′ ← α, β′ ← β, θ′ ← θ;
4: Initialize replay buffer
5:
6: Initialize a random noise for exploration
7: Randomly initialize the state of pursuit-evasion game, observe the state [φ1,1, φ2,1, φ3,1, φ4,1, φ5,1, φ6,1] T and denote it as s1;
8:
9:
10:
11:
12:
13:
14: Execute
15: Store transition
16: s t ← [φ4,t, φ5,t, φ6,t, φ1,t, φ2,t, φ3,t] T;
17: st+1 ← [φ4,t+1, φ5,t+1, φ6,t+1, φ1,t+1, φ2,t+1, φ3,t+1] T;
18: Store transition
19: Randomly sample N transitions as a mini-batch
20: Set
21: Update Qθ′ by minimizing the loss:
22: Calculate the gradient for pursuers’ actor:
23: Calculate the gradient for evader’s actor:
24: Update the actors of both players: α ← α - l a ∇ α , β ← β + l a ∇ β ;
25: Update the target networks: θ′ ← τθ + (1 - τ) θ′, α′ ← τα + (1 - τ) α′, β′ ← τβ + (1 - τ) β′;
26:
27:
28:
Numerical examples
In this section, after transfering the pursuit-evasion problem into an MDP, the Minmax-FDPG method is applied to train the control policies of pursuer and evader. The training is conducted on a platform using CPU Intel Core i7-7800X with a 4.10GHz clock frequency and 32GBs of RAM. Adaptive moment estimation (ADAM) method is used to optimize the FISs. In pursuers’ actor FIS, there are three fuzzy sets for each input component, making a total of nine. In evader’s actor FIS, there are 18 fuzzy sets for six input components. The outputs of the actors have an up/down limit, a hyperbolic tangent function is used as an activation function for each actor. In the critic, there are 27 fuzzy sets in total, each input component contains three. The output of each rule in each FIS is initialized as zero. The other hyperparameters in this example are listed in Table 1. The settings of the pursuit-evader game are outlined in Table 2. At the begining of each episode, the positions of the pursuers are randomly initialized in the area [-3, 3] × [-3, 3], and their orientations are randomly initialized in the interval [- π, π). An episode is terminated once one of the pursuers catches the evader or time step reaches 600. The training process starts when the replay buffer is full. The replay buffers with and without the consideration of symmetry are tested. And it is assumed that, both pursuers and evader do not known anything about the optimal control policies. Their initial control policies are randomly generated.
Hyperparameters in simulation
Hyperparameters in simulation
Pursuit-evasion game setup
Fig. 6 displays the changes in total reward and loss function with number of training episodes. The training starts at the 34th episode. In both cases with and without the consideration of symmetry, the total reward decreases to a small value and maintains stable after 400 episode, and the loss function descents with the increasing training episodes. However, the total reward and the loss function decrease faster when symmetry is considered. It indicates that considering symmetry in the replay buffer can effectively improve the training rate. The trajectories of all players after 50 training episodes and 500 training episodes are displayed in Fig. 7 and Fig. 8, respectively.
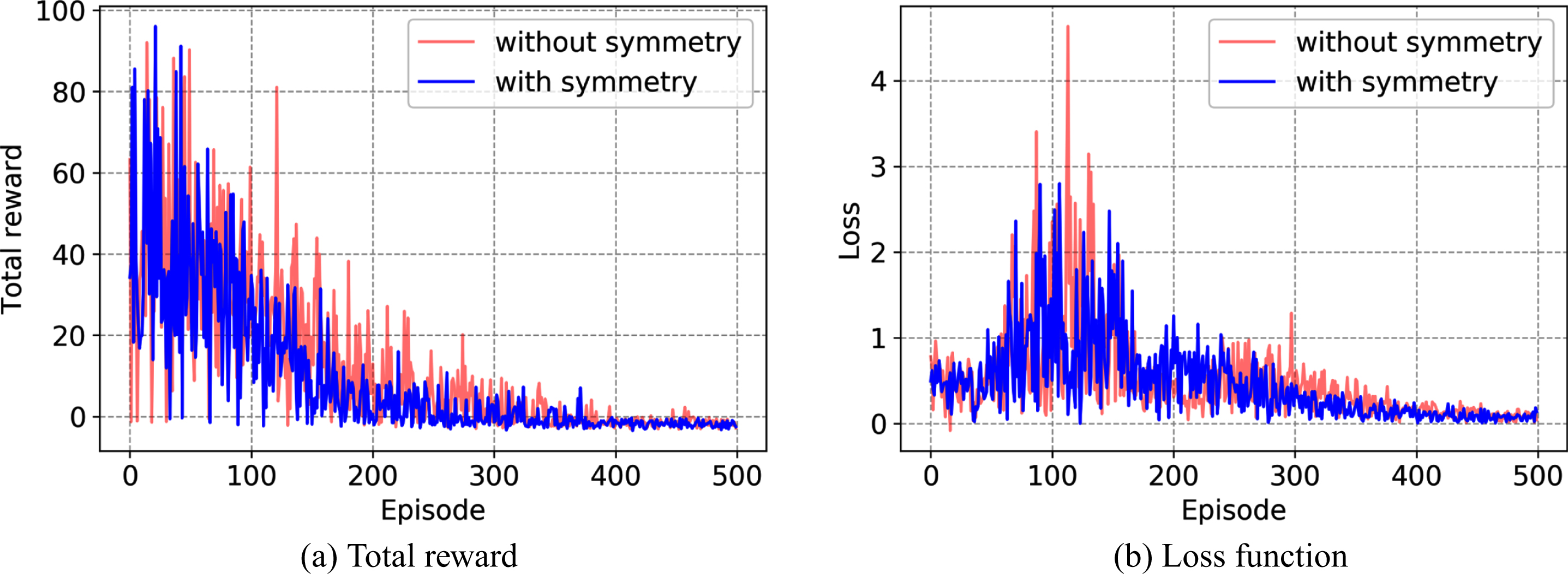
Total reward and loss function.
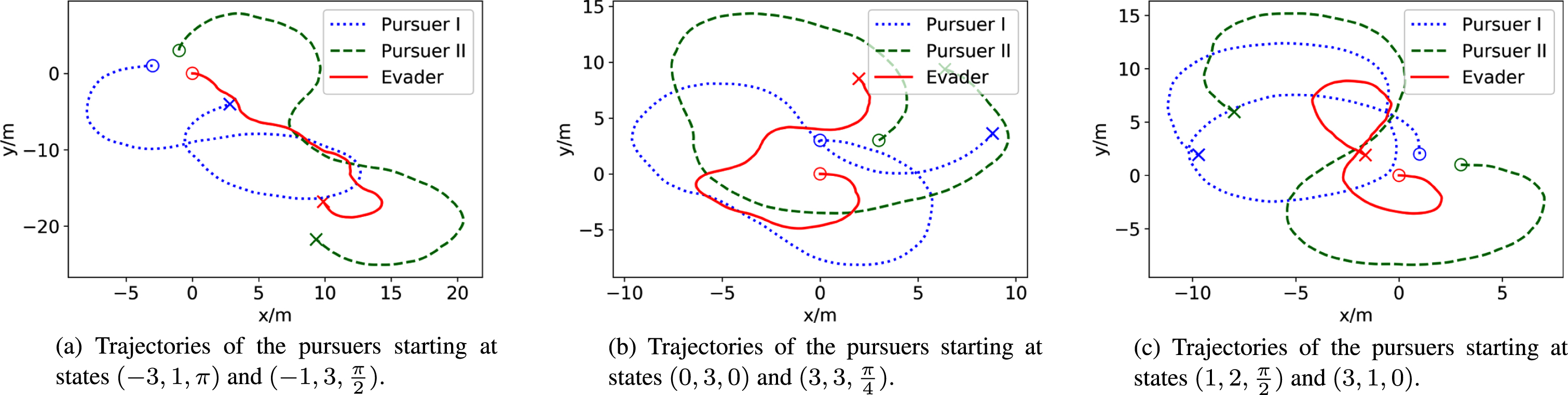
Trajectories after 50 training episodes.
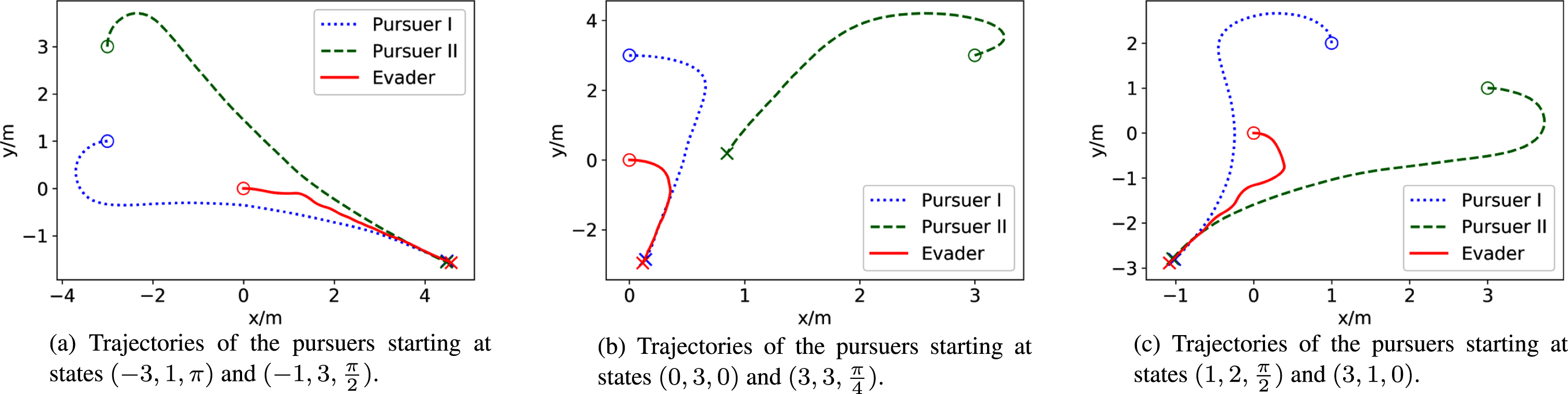
Trajectories after 500 training episodes.
The initial positions of both players are marked with hollow circles and the terminal positions are marked with crosses. It can be seen that both Pursuer I and Pursuer II fail to catch the evader after 50 training episodes and at least one pursuer successfully catches the evader starting from a different initial position after 500 training episodes. Fig. 9 and Fig. 10 show the membership functions in the FIS of the pursuers and evader’s actors after tunning using the proposed Minmax-FDPG algorithm. Note that the FIS of the pursuers’ actor has three inputs ([φ1, φ2, φ3] T for Pursuer I or [φ4, φ5, φ6] T for Pursuer II). And the FIS of the evader’s actor has six inputs. The symbols "N", "Z" and "P" in the figure represent the linguistic values "Negative", "Zero" and "Positive", respectively.
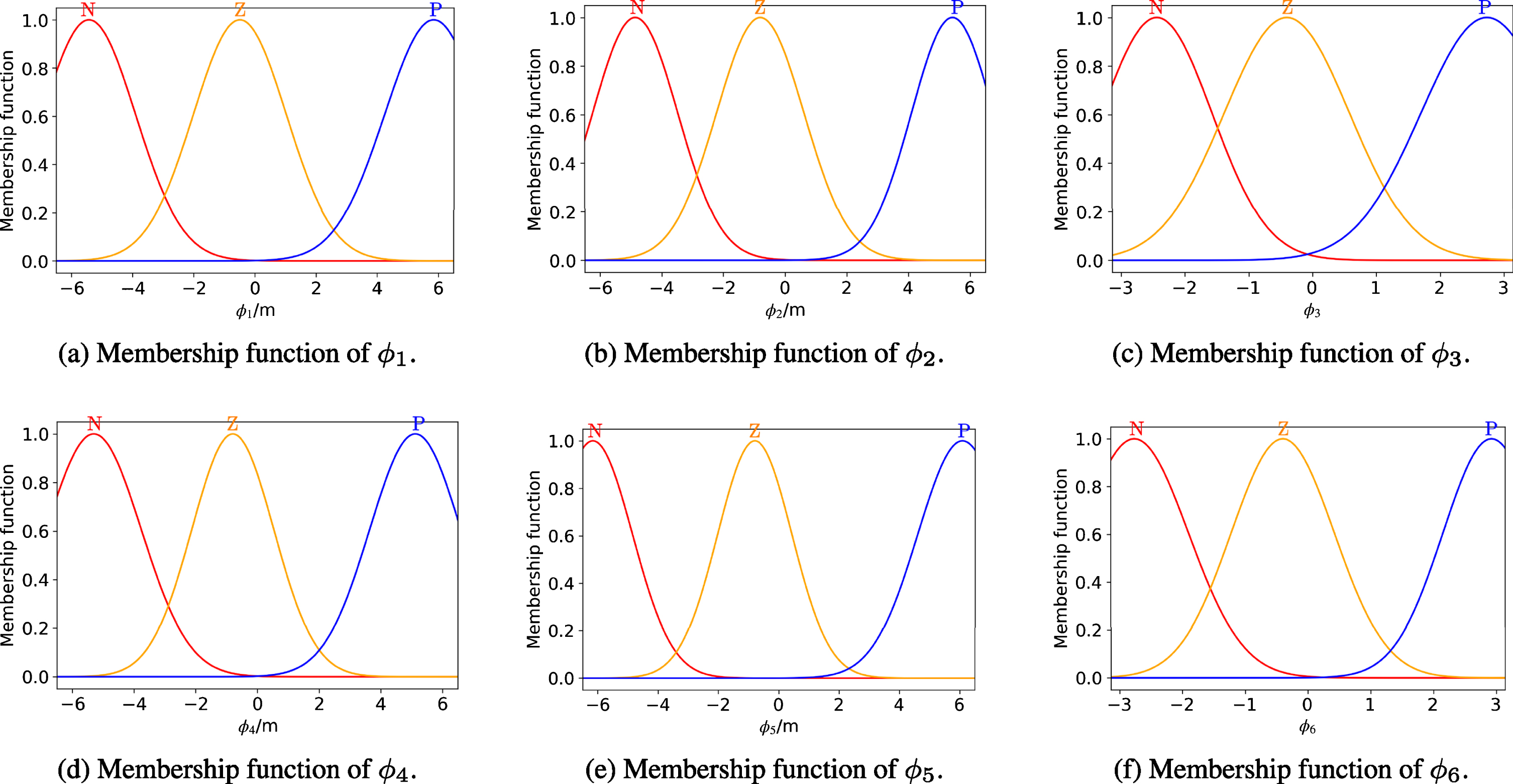
Membership functions in the FIS of the evader’s actor.
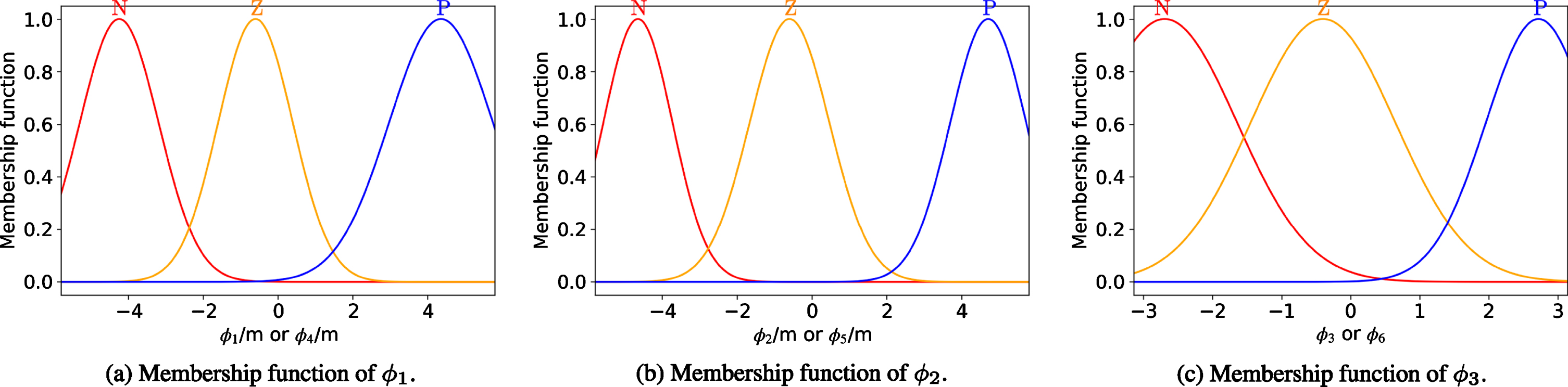
Membership functions in the FIS of the pursuers’ actor.
In the proposed Minmax-FDPG method, the control policies of both sides of the game are improved simultaneously. However, in a zero-sum differential game similar to the pursuit-evasion problem, the goals of different players are opposite, the changes in total reward and loss function with number of training episodes cannot demonstrate the effects of training in a comprehensive manner. A more persuasive verification approach is to conduct some confrontations between control policies with different training episodes.
During the training, the actors of the pursuers and the evader are saved every 50 episodes. The collections of alternative actors for the pursuers and the evader are denoted as:
We take 100 times of simulations for the confrontation between each pair of policies, and take the mean value of the total rewards and capture times of these simulations as the result of the confrontation. The initial state and termination condition of each simulation are set as in the training process. The results of these confrontations are shown in Fig. 11. The two matrixes displayed in Fig. 11 have rows and columns corresponding to the policies taken by the pursuers and the evader. As shown in the figure, the total reward and capture time decrease with the row and increase with the column, roughly. It means that the performance of the policies of the pursuers and the evader improve with the increasing training episodes.
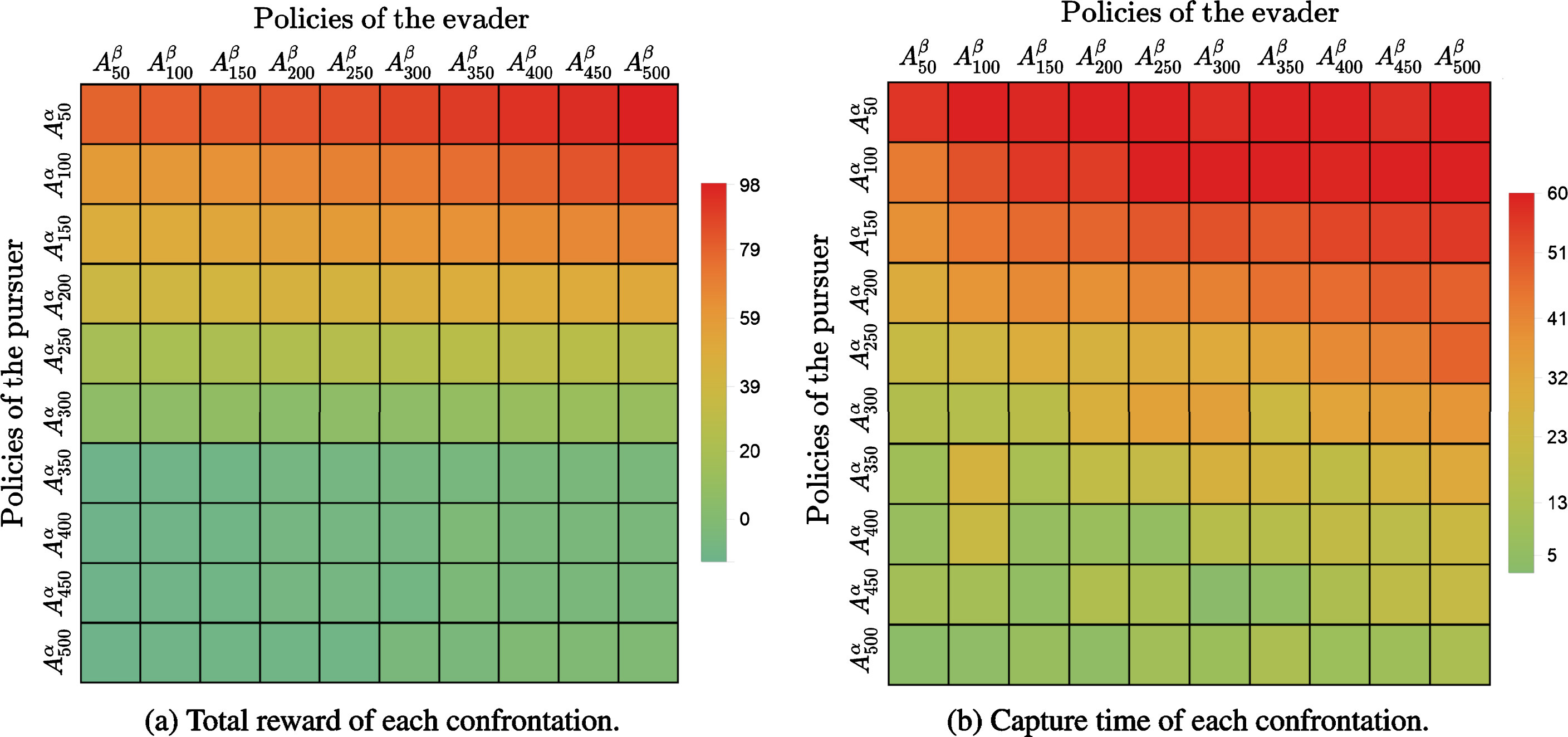
Results of confrontations.
This paper proposes a novel RL framework referred to as the Minmax-FDPG for solving pursuit-evasion problem. The proposed method is modified on the basis of DDPG algorithm, which is a kind of AC based method. The structure of the proposed algorithm consists of two actors and one critic. These actors represent the control policies of different players. In order to obtain the practical meaning of learning result, instead of neural networks, FISs are applied to approximate the control policies and the Q value function. The parameters in the FISs are tuned by the temporal difference method. During the training process, the parameters in the FISs of different players’ actor are updated along the opposite directions simultaneously. For the pursuer, its actor is updated toward the direction that can minimize the Q value, while for the evader, its actor is updated toward the direction that can maximize the Q value. A pursuit-evasion problem with two pursuers and one evader is taken as an example to illustrate the validity of the proposed algorithm. First, the pursuit-evasion problem is transformed into an MDP. Then the proposed Minmax-FDPG algorithm is adopted to optimize the actors and the critic. During the training, the symmetry in such a problem is used to improve the replay buffer. In order to demonstrate the effects of training in a comprehensive manner, the FISs of actors are saved every 50 episodes. After the training is complete, the specific practical meaning of each linguistic fuzzy rule is obtained. Lastly, several confrontations between the control policies with different training episodes and the analytical optimal control policies are conducted to show the changes in total reward and capture time over training episodes of policies of both sides of the game. The result indicate that, after training, the pursuer and evader can learn a relatively good policy, and performance of the policies of both pursuer and evader improve with the increasing training episodes. And considering the symmetry in the replay buffer can significantly accelerate the training process.
In our future work, some more complex structure of FIS can be used to solve some more practical differential games or the pursuit-evasion problems with more number of pursuers and evaders.
Footnotes
Acknowledgments
The authors gratefully acknowledge support from National Defense Outstanding Youth Science Foundation (Grant No. 2018-JCJQ-ZQ-053), and Central University Basic Scientific Research Operating Expenses Special Fund Project Support (Grant No. NF2018001). Also, the authors would like to thank the anonymous reviewers, associate editor, and editor for their valuable and constructive comments and suggestions.