In reality there are always a large number of complex massive databases. The notion of homomorphism may be a mathematical tool for studying data compression in knowledge bases. This paper investigates a knowledge base in dynamic environments and its data compression with homomorphism, where “dynamic” refers to the fact that the involved information systems need to be updated with time due to the inflow of new information. First, the relationships among knowledge bases, information systems and relation information systems are illustrated. Next, the idea of non-incremental algorithm for data compression with homomorphism and the concept of dynamic knowledge base are introduced. Two incremental algorithms for data compression with homomorphism in dynamic knowledge bases are presented. Finally, an experimental analysis is employed to demonstrate the applications of the non-incremental algorithm and the incremental algorithms for data compression when calculating the knowledge reduction of dynamic knowledge bases.
Rough set theory, originated by Pawlak [16], provides mathematical approaches to feature selection, reasoning rules’ extraction and data mining for knowledge bases, especially for the insufficient and incomplete ones. Nowadays, this theory has been successfully applied to machine learning, intelligent systems, inductive reasoning, pattern recognition, mereology, image processing, signal analysis, knowledge discovery, decision analysis, expert systems and many other fields [6–8, 25].
One of rough set theory’s merits is that any unknown information can be approximately characterized by existing knowledge structures in a knowledge base. In rough set theory, knowledge is interpreted as the segmentation of the domain [28]. That is to say, all objects with identical descriptions are classified into a plurality of equivalence classes. Based on such classification, a set of any objects can be approximated through upper and lower approximation. According to the different features of objects, one should classify the whole objects by a family of classifications on the universe. This leads to the definition of a knowledge base [5, 14].
It is well known that a knowledge need not be as important as others in a knowledge base, and even some of them are redundant. Consequently, it is usually required to delete the irrelevant or unimportant knowledge and also maintain the knowledge base classification ability under the original conditions. Such deletion is called knowledge reduction, which is one of the core contents in rough set theory.
In reality, there is a slew of time-dependent data needed to be analyzed comprehensively if one would like to master a phenomenon’s rule, such as population growth, disease symptoms, environmental change, etc. Generally speaking, most of researchers do not allow any knowledge being changeable according to different periods when they study on the knowledge bases, so it is hard to present a real-time analysis on the dynamic information. This yields our nontrivial and interesting discussion on the dynamic knowledge bases whose knowledge can be updated as time elapses.
Data compression is a promising technique for storage and transmission of data. It is referred to reduce the amount of data and storage space, and to improve effectively the transmission, storage and processing of data without losing useful information. The data compression in a dynamic knowledge base includes two aspects of operations on data, one is to reduce data dimension, the other is to reduce stored and transferred data volume. Data dimension reduction can be seen as knowledge reduction. A data volume reduction, in mathematics, can be explained as a many-to-one mapping between two dynamic knowledge bases. Such a many-to-one mapping was called homomorphism, and introduced by Grzymala-Busse [1, 2]. Later, Li et al. [10] studied invariant characteristics of information systems under some homomorphisms. Wang et al. [19–21, 24] gave further surveys on generalized information systems under homomorphisms.
This paper is structured as follows: Section 2 recalls some basic concepts about knowledge bases, relation information systems and consistent mappings; Section 3 recalls R-mappings and homomorphisms between relation information systems, and presents some properties of R-mappings; Section 4 investigates the relationships between knowledge bases and obtains some invariant amounts and inverse invariant amounts, such as knowledge bases, the dependency of knowledge bases, knowledge reductions, coordinate families and necessary relations; Section 5 gives lattice characteristics of the dependency of knowledge bases; Section 6 concludes this paper and highlights the prospects for the potential future development.
Preliminaries
In this section, we recall some basic concepts about knowledge bases, relation information systems and consistent mappings.
Throughout this paper, U (called the universe) denotes a non-empty finite set, U × U denotes the cartesian product of U and U, and 2U denotes the set of all subsets of U. N denotes the set of all natural numbers. |X| denotes the cardinality of X ∈ 2U. Given A, B ⊆ 2U, A ∧ B denotes the set {A ∩ B : A ∈ A, B ∈ B}. All mappings are assumed to be surjective.
For any R ⊆ 2U×U, denote ind (R) = ⋂ R∈RR . For n ∈ N, denote n ! = n (n - 1) ·· ·1 .
The successor neighborhood of x ∈ U with respect to R ∈ 2U×U is denoted by Rs (x), that is, Rs (x) = {y ∈ U : (x, y) ∈ R} ([26]).
Knowledge bases
Recall that R is said to be a binary relation on U if R ∈ 2U×U. Sometimes, if U = {x1, x2, . . . , xm}, then a binary relation R is represented by the following matrix:
where
Suppose that R is a binary relation on U. Then R is said to be equivalence if R is reflexive, symmetric and transitive.
In this paper, denotes the set of all equivalence relations on U.
For and x ∈ U, [x] R = {y ∈ U : xRy} denotes the equivalence class of x. Additionally,
If , then for x ∈ U, Rs (x) = [x] R; if , then
Definition 2.1. ([33]) A pair (U, R) is called a knowledge base, if .
For each equivalence relation in a knowledge base, one can construct lower approximation and upper approximation of any subset on the universe in the following definition.
Definition 2.2. ([15]) Suppose that (U, R) is a knowledge base. For any X ∈ 2U and R ∈ R, define
Then and are called R-lower approximation and R-upper approximation with respect to R, respectively.
is said to be the boundary region of X.
A set is rough if its boundary region is not empty; otherwise, it is crisp. Thus, X is rough if .
Definition 2.3. ([33]) Suppose that (U, R) is a knowledge base and P ⊆ R.
(1) P is said to be equivalent to R (or P is said to be a coordinate subfamily of R), if ind (P) = ind (R).
(2) R ∈ P is said to be independent in P, if ind (P - {R}) ≠ ind (P); P is said to be a independent subfamily of R, if ∀ R ∈ P, R is independent in P.
(3) P is said to be a knowledge reduction of R, if P is both coordinate and independent.
Suppose that (U, R) is a knowledge base. We denote the set of all coordinate subfamilies (resp., all knowledge reductions) of R by co (R) (resp., red (R)).
Obviously,
Theorem 2.4. Suppose that (U, R) is a knowledge base. Then
(1) P ∈ co (R) ⇔ U/P = U/R.
(2) P ∈ red (R) ⇔ U/P = U/R and ∀ R ∈ P, U/P ⊂ U/(P - {R}). Denote
Relation information systems
Definition 2.5. ([15]) An information system is a pair (U, A) of non-empty finite sets U and A, where U is a set of objects and A is a set of attributes; each attribute a ∈ A is a function a : U → Va, where Va is the set of values (called domain) of attribute a.
If (U, A) is an information system and B ⊆ A, then an equivalence relation (or indiscernibility relation) RB can be defined by
Definition 2.6. ([23]) A pair (U, R) is said to be a relation information system, if R ⊆ 2U×U.
Obviously, a knowledge base is a special kind of relation information system.
Definition 2.7. Suppose that (U, A) is an information system. Put
Then the pair (U, R) is said to be the relation information system induced by the information system (U, A).
In fact, (U, R) in Definition 2.7 is a knowledge base.
Consistent mappings
Definition 2.8. ([23, 24]) Suppose that U and V are finite sets, f: U → V a mapping and R ∈ 2U×U. Let
Then {[x] f : x ∈ U} and {(x) R : x ∈ U} are two partitions on U. If [x] f ⊆ Rs (u) or [x] f∩ Rs (u) = ∅ for any x, u ∈ U, then f is said to be a type-1 consistent mapping with respect to R on U. If [x] f ⊆ (x) R for any x ∈ U, then f is said to be a type-2 consistent mapping with respect to R on U.
Remark 2.9.
(1) For each x ∈ U, [x] f = f-1 (f (x)) .
(2) If , then for each x ∈ U, (x) R = [x] R.
(3) f is type-1 ⇔ If [x] f∩ Rs (u) ≠ ∅, then [x] f ⊆ Rs (u)
⇔ If [x] f ⊈ Rs (u), then [x] f∩ Rs (u) = ∅,
(4) f is type-2 ⇔ If f (u) = f (x), then Rs (u) = Rs (x).
Definition 2.10. ([23]) Suppose that f: U → V is a mapping and R ⊆ 2U×U. If f is type-1 (resp. type-2) consistent with respect to R on U for every R ∈ R, then f is said to be type-1 (resp. type-2) consistent with respect to R on U.
Homomorphisms between relation information systems
In this subsection, we give definition of homomorphism between relation information systems.
Definition 2.11. ([23, 24]) Suppose that f : U → V is a mapping. Define
Then and are called the R-mapping and inverse R-mapping induced by f, respectively.
Obviously,
For R ⊆ 2U×U, denote
Proposition 2.12. ([23]) Suppose that f : U → V is a mapping and R ⊆ 2U×U. If f is both type-1 and type-2 consistent with respect to R, then .
Proposition 2.13. Suppose that f : U → V is a mapping and R ⊆ 2U×U. If f is both type-1 and type-2 consistent with respect to R, then for P ⊆ R, .
Proof. Note that f is both type-1 and type-2 consistent with respect to R. Then f is both type-1 and type-2 consistent with respect to P.
By Proposition 2.12, .□
Definition 2.14. ([23]) Let (U, R) be a relation information system and f : U → V a mapping. The pair is called an f-induced relation information system of (U, R).
Definition 2.15. ([23]) Suppose that (U, R) is a relation information system and an f-induced relation information system of (U, R). If f is both type-1 and type-2 consistent with respect to R on U, then f is said to be a homomorphism from (U, R) to . We write
Theorem 2.16. Suppose that f : U → V is both type-1 and type-2 consistent with respect to R on U. Then
(1) ⇔ ;
(2) If , then for each x ∈ U, .
Proposition 2.17. If with R = {R1, . . . , Rm}, then
Theorem 2.18. If , then
Proposition 2.19. Suppose that (U, R) is a knowledge base. If , then
Theorem 2.20. Suppose that (U, R) is a knowledge base. If , then
Data compression with homomorphism in a knowledge base
Wang et al. [21] introduced homomorphisms between fuzzy relation information systems. Cai and Li [3] proposed data compression with homomorphisms in dynamic fuzzy relation information systems and the corresponding algorithm. Data compression is not knowledge reduction but a data preprocessing before knowledge reduction. We can establish a many-to-one corresponding between the original knowledge base with a large amount of objects and another knowledge base with very less objects. Then the knowledge reduction will be more easily calculated when we only put attention towards the “a knowledge base with very less objects”.
Algorithm 1 is a non-incremental algorithm for compressing knowledge bases under homomorphisms. Step 2 is to compute the knowledge U/Ri with respect to Ri and the time complexity is O (|R| × |U|2); Step 3 and Setp 4 are to construct the image knowledge base and compute the knowledge and the time complexity is O (|R| × |V|2); Steps 5-6 are to compute the reduction of knowledge base and the time complexity is O (|R| !). Then the total time complexity is O (|R| × (|U|2 + |V|2) + |R| !).
Example 3.1. Let U = {xi|1 ≤ i ≤ 15}. Put
Then (U, R) is a knowledge base where R = {R1, R2, R3}.
Let V = {y1, y2, y3, y4, y5, y6}. Define a mapping f : U → V as follows:
Then is the f-induced relation information system of (U, R) where .
It is easy to verify that f is both type-1 and type-2 consistent with respect to R on U. Thus
We have
By Theorem 2.18, is a knowledge base.
Then
and
By Theorem 2.20, we get
Incremental approaches to compressing dynamic knowledge bases under homomorphisms
Based on the discussion in Section 3, the key step for constructing homomorphisms is to ensure the mappings are both type-1 and type-2 consistent. Then compressing the original knowledge base to be an image knowledge base will be more easy, as well as obtaining the reduction in the original knowledge base according to the reduction in the image knowledge base by applying Theorem 2.20. Let us consider dynamic knowledge bases whose knowledge can be increased or decreased. We will introduce two kinds of incremental algorithms, one work when adding a knowledge to the dynamic knowledge base, while the other work when removing a knowledge from the dynamic knowledge base. Both the two incremental algorithms are extensions of the non-incremental algorithm in Section 3.
Adding knowledge
In this subsection, we illustrate how to compress a dynamic knowledge base when adding a knowledge to it by using homomorphism.
Theorem 4.1. If , then
Theorem 4.2. Suppose that a knowledge base S(t) = (U, R) at time (t) be compressed into T(t) = (V, f (R)) where R = {R1, . . . , Rm} and . Suppose that that a new knowledge R+ is added to S(t) at time (t + 1) such that R + = R ∪ {R+} and S(t+1) = (U, R +). Then for the image knowledge base at time (t + 1), the following properties hold:
(1) If , then T(t+1) = T(t),
(2) If , then T(t+1) ≠ T(t), .
Proof. (1) Suppose ∀ y ∈ V, . Then
Thus, . This implies .
Then .
Hence T(t+1) = T(t);
(2) Let ∃ y* ∈ V, . By (1),
This implies
Then and so .
Let . Obviously, ∃ y ∈ V such that . By (1),
Since and , then
On the other hand, let , then , such that w = w1 ∩ w2. So , for some y1, y2 ∈ V. This implies . Pick y3 ∈ w, that is . It follows from , . We have . Then . By (1),
Then
Thus
□
Theorem 4.3. Let a knowledge base S(t) = (U, R) at time (t) be compressed into T(t) = (V, f (R)) such that S(t) ∼ fT(t). Suppose that k new knowledge is added to S(t) at time (t + 1) such that S(t+1) ∼ fT(t+1) where , S(t+1) = (U, R +) and . Then for the image knowledge base T(t+1) at time (t + 1), the following properties hold:
(1) If , then T(t+1) = T(t),
(2) If , then T(t+1) ≠ T(t), .
Proof. The proof is similar to Theorem 4.3.□ Algorithm 2 is an incremental algorithm for compressing a knowledge base under homomorphism when adding an equivalence relation. Step 2 is to compute the knowledge U/Ri with respect to Ri and the time complexity is O (|R| × |U|2); Step 3 and Setp 4 are to construct the image knowledge base and compute the knowledge and the time complexity is O (|R| × |V|2); Step 5 is to judge whether satisfies the first situation. The time complexity of this step is O (|V|); Step 9 is to compute the partition with respect to . The time complexity of this step is O (|V|); Step 11 and Setp 12 are to compute the reduction of knowledge base and the time complexity is O (|R +| !). Then the total time complexity is O (|R| × (|U|2 + |V|2) + |V| + |R +| !).
Example 4.4. (Continued from Example 3.1) Let R + = R ∪ {R+} where R+ is an equivalence relation on U. Put
It is easy to verify that f is both type-1 and type-2 consistent with respect to R+ on U.
Then f is both type-1 and type-2 consistent with respect to R + on U.
Thus
We have
By Example 3.1,
Then
Thus
and
By theorem 2.20, we get
Removing knowledge
In this subsection, we illustrate how to compress a dynamic knowledge base when removing a knowledge from it by using homomorphism.
Theorem 4.5. Let a knowledge base S(t) = (U, R) at time (t) be compressed into T(t) = (V, f (R)) where R = {R1, . . . , Rm} and . Suppose that a knowledge R- ∈ R is removed from S(t) at time (t + 1) such that R - = R - {R-} and S(t+1) = (U, R -). Then for the image knowledge base at time (t + 1), the following properties hold:
(1) If , then T(t+1) = T(t),
(2) If , then T(t+1) ≠ T(t), .
Proof. (1) Suppose that for each y ∈ V, . Then
Thus, . This implies .
Then .
Hence T(t+1) = T(t);
(2) Let ∃ y* ∈ V, . By (1),
This implies
Then and so .
Let . Obviously, ∃ y ∈ V such that . By (1),
Since and , then
On the other hand, let , then , such that w = w1 ∩ w2. So , for some y1, y2 ∈ V. This implies . Pick y3 ∈ w, that is . It follows from , . We have . Then . By (1),
Then
Thus
□
Theorem 4.6. Let a knowledge base S(t) = (U, R) at time (t) be compressed into T(t) = (V, f (R)) such that S(t) ∼ fT(t). Suppose that k knowledge is removed from S(t) at time (t + 1) such that and S(t+1) = (U, R -). Then for the image knowledge base at time (t + 1), the following properties hold:
(1) If , then T(t+1) = T(t),
(2) If , then T(t+1) ≠ T(t), .
Proof. The proof is similar to Theorem 4.5.□
Algorithm 3 is an incremental algorithm for compressing knowledge bases under homomorphisms when removing an equivalence relation. Step 5 is to compute the partition with respect to R. The time complexity of this step is O (|V| × |R|); Step 6 is to judge whether the partition blocks and generated by R - and R-, respectively satisfy the first situation. The time complexity of this step is O (|V|); Steps 9-10 are to construct the image knowledge base. The time complexity of this step is O (|R| × |V|2).Steps 12-13 are to compute the reduction of knowledge base and the time complexity is O (|R -| !). Then the total time complexity is O (|R| × (|V| + |V|2) + |V| + |R -| !).
An example is employed to illustrate the process of compressing the dynamic knowledge bases when deleting an equivalence relation.
Example 4.7. (Continued from Example 4.3) We remove R1 from R +, then R - = {R2, R3, R+}. Amount to we remove from , then ,
By Example 3.1, we have
By Example 4.4, we have
Then
Thus
By theorem 2.20, we get
Experimental analysis
In this section, we establish a test compression method for reduction of the incremental effect of dynamic knowledge base. The main purpose is to clarify the efficiency of the incremental algorithm calculation of dynamic knowledge base under the homomorphism. We can get information from Table 1 knowledge base, where (Ui, Ri) is a knowledge base for each i = 1, 2, ⋯ , 5. All experiments are run on a PC with 32-bit Windows 7, Inter(R) Core(TM) i3-2330M CPU@2.20GHZ and 4GB memory. The computational software is Matlab R2008a 32-bit.
knowledge bases
No.
Name
|Ui|
|Ri|
1
(U1, R1)
4
4
2
(U2, R2)
8
8
3
(U3, R3)
12
12
4
(U4, R4)
16
16
5
(U5, R5)
20
20
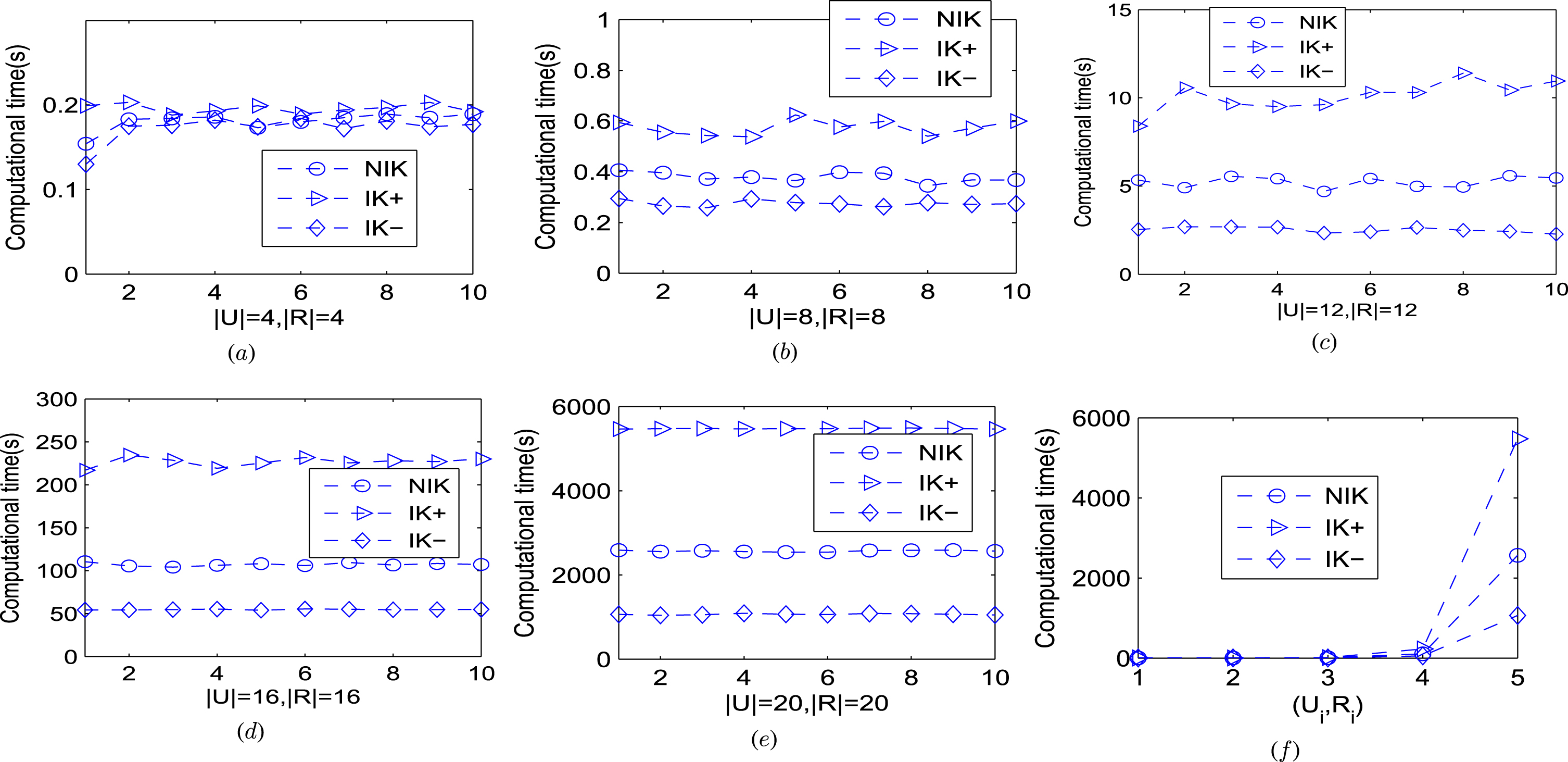
Throughout this section, we use NIK,IK+ and IK- to denote Algorithms 1,2 and 3 respectively, and apply them to the five knowledge bases for the comparison of their computational times. Firstly, we compress each (Ui, Ri) by using Algorithm 1. Secondly, by adding an equivalence relation to each Ri we obtain five corresponding dynamic knowledge bases , then we compress each by using IK+. Thirdly, we obtain five corresponding dynamic knowledge bases by removing an equivalence relation, then we compress the dynamic knowledge bases by using IK-. Each of the aforementioned steps repeats nine times. The whole results are shown in Table 2 and Fig. 1: (a) - (f). In Table 2, the measure of time is in seconds; indicates the average time of the five experiments. In Fig. 1: (a) - (e), i stands for the experimental number in X Axis. In Fig. 1: (k), i refers to the knowledge bases (Ui, Ri) in X Axis.
From Table 2 and Fig. 1: (a) - (e), we see that NIK, IK+ and IK- are stable to compress dynamic knowledge bases, that is, the computational time of each algorithm is almost identical to that of the five runs. Consequently, we see that the times of compressing dynamic knowledge bases via incremental algorithms are much longer than those of the non-incremental algorithms. From Fig. 1: (f), we can see the average times of the incremental and non-incremental algorithms increase aggressively when the cardinalities of object sets and the set of equivalence relations augment. But after compression, we can save a lot of time to ask reduction.
Computational times using NIK, IK+ and IK-
No
Algo.
1
2
3
4
5
6
7
8
9
10
1
NIK
0.154
0.183
0.184
0.186
0.173
0.180
0.185
0.189
0.185
0.189
0.181
IK+
0.199
0.203
0.188
0.193
0.199
0.189
0.194
0.197
0.203
0.192
0.196
IK-
0.130
0.175
0.176
0.182
0.174
0.184
0.172
0.181
0.174
0.177
0.172
2
NIK
0.406
0.396
0.371
0.379
0.365
0.398
0.394
0.345
0.368
0.367
0.379
IK+
0.594
0.555
0.543
0.538
0.624
0.576
0.599
0.540
0.571
0.600
0.574
IK-
0.294
0.265
0.258
0.293
0.278
0.273
0.262
0.278
0.271
0.274
0.275
3
NIK
5.338
4.912
5.551
5.421
4.691
5.426
4.985
4.952
5.583
5.460
5.232
IK+
8.398
10.567
9.658
9.509
9.615
10.316
10.305
11.403
10.447
10.954
10.117
IK-
2.535
2.687
2.683
2.667
2.335
2.409
2.655
2.490
2.429
2.271
2.516
4
NIK
110.494
105.460
104.248
106.374
108.257
105.893
109.431
106.593
108.351
107.157
107.226
IK+
216.945
234.687
228.513
219.376
225.219
231.782
225.537
228.106
227.119
230.098
226.738
IK-
54.247
54.284
54.651
55.317
53.928
55.513
55.172
54.437
54.682
54.830
54.706
5
NIK
2586.163
2552.174
2573.352
2553.218
2538.647
2542.112
2577.328
2584.573
2588.382
2567.374
2566.332
IK+
5463.116
5473.242
5477.438
5469.593
5470.641
5472.355
5483.183
5489.326
5478.154
5465.421
5474.247
IK-
1059.871
1038.417
1052.112
1087.522
1064.123
1058.072
1083.113
1078.203
1065.208
1049.387
1063.603
Knowledge bases.
Conclusions
In this paper, we have investigated data compression based on homomorphisms between two dynamic knowledge bases, and proposed two incremental algorithms (in the aspects of adding a knowledge and removing a knowledge to the knowledge base, respectively) for data compression. We have also made an experimental analysis to illustrate that the proposed algorithms are effective to simplify the calculation of knowledge reduction in knowledge bases. In the future, we will consider more incremental algorithms in the framework of dynamic knowledge bases.
References
1.
Grzymala-BusseJ.W., Algebraic properties of knowledge representation systems, in: Proceedings of theACMSIGART International Symposium on Methodologies for Intelligent Systems, Knoxville, 1986, pp. 432–440.
2.
Grzymala-BusseJ.W. and SedelowW.A., On rough sets, and information system homomorphism, Bulletin of the Polish Academy of Technology Science36(3-4) (1988), 233–239.
3.
CaiM. and LiQ., Compression of dynamic fuzzy relation information systems, Fundamenta Informaticae142 (2015), 285–306.
4.
GongZ., and Z.Xiao,Communicating between information systems based on including degrees, International Journal of General Systems39(2) (2010), 189–206.
5.
KryszkiewiczM., Comparative study of alternative types of knowledge reduction in inconsistent systems, International Journal of Intelligent Systems16 (2001), 105–120.
6.
LiZ., HuangD., LiuX., XieN. and ZhangG., Information structures in a covering information system, Information Sciences507 (2020), 449–471.
7.
LiZ., LiuX., DaiJ., ChenJ. and FujitaH., Measures of uncertainty based on Gaussian kernel for a fully fuzzy information system, Knowledge-Based Systems196 (2020), 105791.
8.
LiZ., LiuY., LiQ. and QinB., Relationships between knowledge bases and related results, Knowledge and Information Systems49 (2016), 171–195.
9.
LiZ., LiQ., ZhangR. and XieN., Knowledge structures in a knowledge base, Expert Systems33(6) (2016), 581–591.
10.
LiD. and MaY., Invariant characters of information systems under some homomorphisms, Information Sciences129 (2000), 211–220.
11.
LevyY. and RoussetM.C., Verification of knowledge bases based on containment checking, Artificial Intelligence101 (1998), 227–250.
12.
LiangJ. and XuZ., The algorithm on knowledge reductionion in incomplete information systems, International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems24(1) (2002), 95–103.
13.
LiZ., ZhangP., GeX., XieN., ZhangG. and WenC., Uncertainty measurement for a fuzzy relation information system, IEEE Transactions on Fuzzy Systems27(12) (2019), 2338–2352.
14.
LiZ., ZhangG., WuW. and XieN., Measures of uncertainty for knowledge bases, Knowledge and Information Systems62 (2020), 611–637.
15.
PawlakZ., Rough sets: Theoretical aspects of reasoning about data, Kluwer Academic Publishers, Dordrecht, 1991.
16.
PawlakZ., Rough sets, International Journal of Computer and Information Sciences11 (1982), 341–356.
17.
QianY., LiangJ. and DangC., Knowledge structure, knowledge granulation and knowledge distance in a knowledge base, International Journal of Approximate Reasoning50 (2009), 174–188.
18.
SkowronA., RauszerC., The discernibility matrices and mappings in information systems, in: R. Slowinski (Ed.), Intelligent decision support, Handbook of applications and advances of the rough set theory, Kluwer Academic, Dordrecht, 1992, pp. 331–362.
19.
WangC., ChenD., SunB. and HuQ., Communication between information systems with covering based rough sets, Information Sciences216 (2012), 17–33.
20.
WangC., ChenD., WuC. and HuQ., Data compression with homomorphism in covering information systems, International Journal of Approximate Reasoning52 (2011), 519–525.
21.
WangC., ChenD. and ZhuL., Homomorphisms between fuzzy information systems, Applied Mathematics Letters22 (2009), 1045–1050.
22.
WuW., ZhangM., LiH. and MiJ., Knowledge reductionion in random information systems via Dempster-Shafer theory of evidence, Information Sciences174 (2005), 143–164.
23.
WangC., WuC., ChenD. and DuW., Some properties of relation information systems under homomorphisms, Applied Mathematics Letters21 (2008), 940–945.
24.
WangC., WuC., ChenD., HuQ. and WuC., Communicating between information systems, Information Sciences178 (2008), 3228–3239.
25.
XieN., LiuM., LiZ. and ZhangG., New measures of uncertainty for an interval-valued information system. , Information Sciences470 (2019), 156–174.
26.
YaoY.Y., Constructive and algebraic methods of the theory of rough sets, Information Sciences109 (1998), 21–47.
27.
PedryczW. and VukovichG., Granular worlds: representation and communication problems, International Journal of Intelligent Systems15(11) (2000), 1015–1026.
28.
ZhaoJ. and LiuL., Construction of concept granule based on rough set and representation of knowledge-based complex system, Knowledge-Based Systems24 (2011), 809–815.
29.
ZhangW., MiJ. and WuW., Knowledge reductionions in inconsistent information systems, International Journal of Intelligent Systems18 (2003), 989–1000.
30.
ZhangW., QiuG., Uncertain decision making based on rough set theory, Tsinghua University Publishers, Beijing, 2005.
31.
ZhuP. and WenQ., Some improved results on communication between information systems, Information Sciences180 (2010), 3521–3531.
32.
ZhuP. and WenQ., Homomorphisms between fuzzy information systems revisited, Applied Mathematics Letters24 (2011), 1548–1553.
33.
ZhangW., WuW., LiangJ., LiD., Rough set theory and methods, Chinese Scientific Publishers, Beijing, 2001.

 with respect to R
i
and the time complexity is O (|R| × |U|2); Step 3 and Setp 4 are to construct the image knowledge base and compute the knowledge
with respect to R
i
and the time complexity is O (|R| × |U|2); Step 3 and Setp 4 are to construct the image knowledge base and compute the knowledge