
Abstract
Joint extraction of entities and relations from unstructured text is an essential step in constructing a knowledge base. However, relational facts in these texts are often complicated, where most of them contain overlapping triplets, making the joint extraction task still challenging. This paper proposes a novel Sequence-to-Sequence (Seq2Seq) framework to handle the overlapping issue, which models the triplet extraction as a sequence generation task. Specifically, a unique cascade structure is proposed to connect transformer and pointer network to extract entities and relations jointly. By this means, sequences can be generated in triplet-level and it speeds up the decoding process. Besides, a syntax-guided encoder is applied to integrate the sentence’s syntax structure into the transformer encoder explicitly, which helps the encoder pay more accurate attention to the syntax-related words. Extensive experiments were conducted on three public datasets, named NYT24, NYT29, and WebNLG, and the results show the validity of this model by comparing with various baselines. In addition, a pre-trained BERT model is also employed as the encoder. Then it comes up to excellent performance that the F1 scores on the three datasets surpass the strongest baseline by 5.7%, 5.6%, and 4.4%.
Keywords
Introduction
Joint extraction of entities and relations is an essential task for information extraction and plays a vital role in many applications, like knowledge base population [1–3] and clinical information extraction [4, 5]. This task demands that entity pairs and the corresponding relations be extracted from the unstructured text simultaneously. For example, given the sentence ‘Obama was born in Honolulu’, it is aimed at extracting a relational triplet ‘(Obama, place_of_birth, Honolulu)’ from the sentence. Generally, ‘Obama’ is referenced as the subject, ‘Honolulu’ is referenced as the object, and ‘place_of_birth’ is the relationship between the subject and object.
Early studies implemented joint extraction mainly by pipeline methods, which split the joint extraction into two separate sub-tasks: Named Entity Recognition (NER) and Relation classification (RC). Pipeline methods made the joint extraction easy to conduct, but it introduced an error propagation issue [6]. Besides, the relevance between the two sub-tasks have not been exploited. One improved way is to apply the joint learning method, in which a parameter-sharing layer is designed to construct the bridge between the NER and RC [7–9]. However, after identifying all the entities, the joint learning method is also demanded to classify the relations between each entity pair; thus the interaction between the two sub-tasks is not fully exploited. Besides, the overlapping issue is yet to be fully handled by the joint learning method.
The joint extraction becomes challenging, as one entity has multiple relationships with others in the overlapping scenarios. Some examples are presented in Figure 1, where sentences are divided into three categories: Normal, Entity Pair Overlapping (EPO), and Single Entity Overlapping (SEO). In the normal category, an entity has only one relation with the other. The EPO category represents that an entity pair has more than one relations. In the SEO category, an entity has relations with multiple other entities. The overlapping issue makes the joint extraction task arduous for many joint learning methods. It requires the model to enumerate over all possible entity pairs, which leads to a heavy computational burden, since N entities will cause roughly N2 pairs. Furthermore, many entity pairs have no internal relation. Then ‘None’ labels are assigned to these entity pairs during the training process, making the neural model difficult to learn the real relationship between the entity pairs.
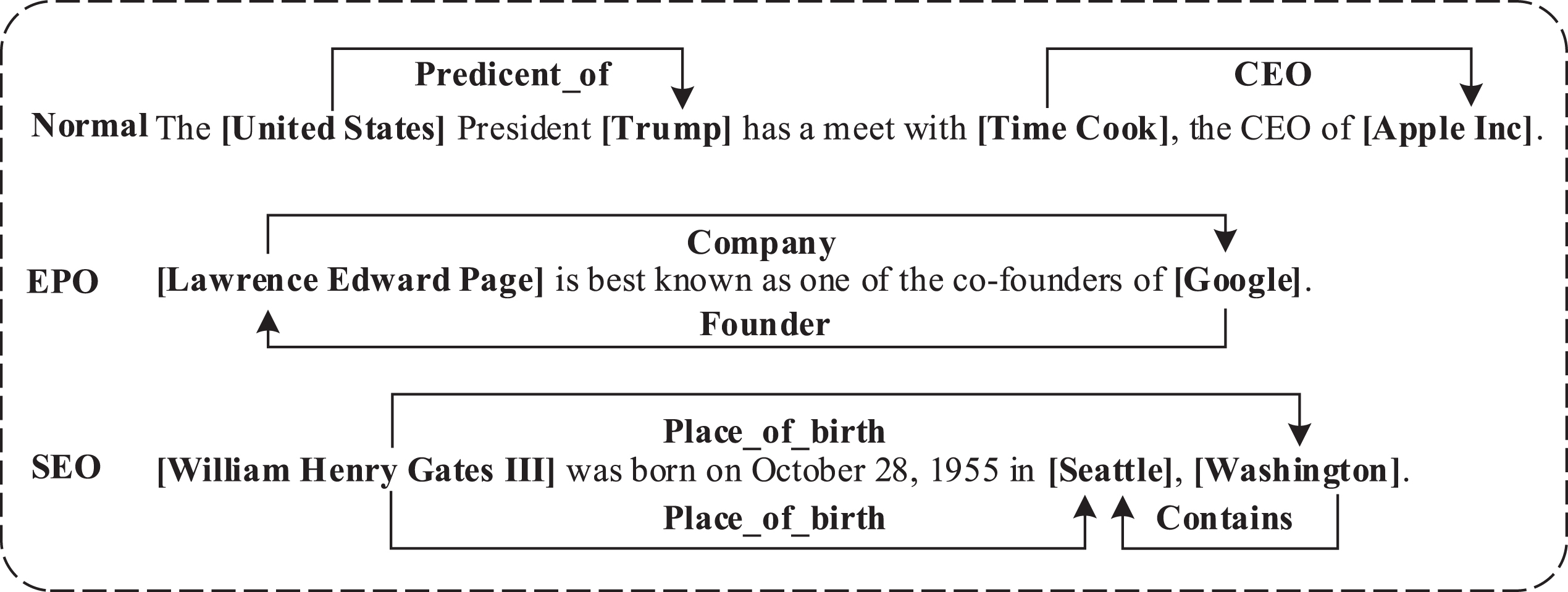
Some examples of the overlapping triplets in the real world.
Recently, many studies apply Seq2Seq architecture to address the overlapping issue [10–13]. In these methods, the joint extraction is modeled as a triplet sequence generation task. In this way, an entity or relation can be generated or copied several times when needed to participate in different triplets. Thus, the Seq2Seq methods are neither plagued with overlapping relations nor with excessive computations. However, the following limitations also exist in previous studies: (1) the relational triplets are generated on entity-level or word-level, thus requiring at least three steps to generate a triplet, which is time-consuming, and the dependencies on triplet-level is not explored; (2) Existing methods are based on recurrent neural networks (RNNs), which have own limitations, low efficiency in training and hard to model the long-dependency.
In this paper, a transformer-based Seq2Seq model is proposed to address the issues mentioned above. Specifically, the transformer network [14] is adopted as Encoder-Decoder architecture to generate the relation sequences and a pointer network [15] based on a multi-headed attention mechanism is further designed to identify the related entity pairs. In the Encoder-Decoder network, the proposed model extends the transformer’s self-attention mechanism with syntax-guided constrain to capture syntax-related parts with the concerned words. The sentence’s syntax tree works as clues and is integrated into the encoder explicitly. In the pointer network, the multi-headed layer’s attention scores are treated as a pointer to identify the related entities. Lastly, a unique cascading structure is designed to connect the transformer and pointer network.
To verify the validity of the proposed method, extensive experiments were conducted on three public datasets, named NYT24, NYT29, and WebNLG, as previous studies [10–13]. Evaluation results demonstrate that the proposed model has its superiority in effectiveness and efficiency compared with baselines. Further experiments by introducing a pre-trained BERT [16] as an encoder are also conducted. With the help of the pertained-model, a significant performance gain over the transformer encoder is made.
In summary, the main contributions of this paper are as follows: A novel cascade framework is proposed to extract entities and relations jointly from sentences, which generates triplet-level-based sequences and improves the parallelization capability. A syntax-guided network is proposed to capture the syntactic information of the input sentence explicitly, which facilitates the encoder to pay more attention to the important words in the input sentences. Experimental results on the three public datasets show that the proposed model achieves competitive performance compared with baselines.
This paper proceeds as follows: (2) section 2 summarizes related work in this field; (3) section 3 gives a formulate definition of the task; (4) section 4 presents our approach and the detail of each component; (5) experiment and discussion are depicted in section 5; (6) section 6 gives a conclusion and future work.
Over the past few decades, many efforts have been devoted to the joint extraction task. The existing methods can be divided into three categories: pipeline method, joint learning method, and Seq2Seq method.
Pipeline method
Traditional studies solved the joint extraction task with the pipeline method, which divided it into NER and RC. Early methods utilized feature-based approaches to solve the two sub-tasks [17–19]. These methods require a large amount of feature engineering efforts, and the extracted features are sparse. Recently, many neural networks were proposed for NER and RC. Lample et al. [20] introduced a neural network for NER, which utilized a bi-directional Long Short-term Memory (BiLSTM) network to encode the sentence, then decoded the sequence labels based on a conditional random filed layer (CRF). To capture the features from both word-level and character-level, some studies apply a hybrid model of BiLSTM and Convolutional neural network (CNN) for NER, where the character-level feature is captured by the CNN model [21, 22]. For the RC task, Zeng et al. [23] utilized a CNN model to extract lexical and sentence level features, then the features are fed into a softmax layer to predict the relationship between the entities. Liu et al. [24] proposed a novel end-to-end multi-level semantic representation enhancement network for RC, which can enhance the semantic representation of entities from word, phrase, and context level. The neural-network-based methods are more robust and achieve better performance than the feature-based method. As the neural network’s ability to extract deep continuous features. Despite the success of the neural-network-based methods, the pipeline model also suffers from apparent issues. Firstly, the pipeline model may introduce an error propagation problem [6]. Secondly, the interaction between the two sub-tasks is not exploited.
Joint learning method
To address the issues in pipeline methods, joint learning models have been proposed. Some are also feature-based [6, 26], which heavily rely on feature engineering. In recent years, neural-network-based methods have been investigated. The neural-network-based methods can be divided into different categories according to how they model the interaction between the two sub-tasks. The first category is the parameter sharing method, in which the input sentence is encoded by a parameter sharing encoder and then passed into two separate decoders for NER and RC [7–9]. The parameters sharing methods also have to pipeline the detected entities into the relation classifier. Therefore, the triplet-level dependency of the two tasks is not fully exploited. The second category is the tagging-based method. These methods encode entities and relations into the same space by designing a unique tagging scheme, then generate the entities and relations in one decoder [27, 28]. Besides, some studies utilized Graph Convolution Network (GCN) [29] or Reinforcement learning (RL) [31, 32] methods to tackle this task. The graph-based method model the interaction between entities and relations via two-phase GCN. The RL-based method applies hierarchical reinforcement learning (HRL) to enhance the interaction between NER and RC. These methods solve the problem of overlapping relations to some extent. Nevertheless, there also have some issues, such as over redundant computation and high computational complexity.
Seq2seq method
Recently, many Seq2Seq methods were investigated [10–12] to address the joint extraction task. These methods treat the joint extraction as a triplet sequence generation task. Thus the entities or relations can be generated repeatedly. Although the Seq2Seq model has shown its superiority in addressing the overlapping issue, existing methods suffer from some limitations. The CopyRE [10] cannot extract the entire words of the entities, hindering its usage in a real-world application. The CopyMTL [11] needs to introduce an additional NER module to identify the entity boundaries of the triplet. Besides, existing models generate the triplet sequence on word-level, thus lost the triplet-level dependency. What’s more, existing Seq2Seq methods are all RNN-based that cannot be computed in parallel and are still weak when capturing the long-dependence of two farther apart entities.
Problem statement
For a given sentence X = [w1, w2, . . . , w n ] and a predefined relation set R = [r1, r2, . . . , r n ], the goal of joint extraction is to predict all the triplets correctly. A triplet is defined as (s, r, o), where r ∈ R and s, o ∈ X, s ≠ o. In fact, s and o often contain multi-words. In this study, the joint extraction is modeled as a triplet generation task, and we apply a Seq2Seq model to generate the triplet one-by-one until ending with a special stop symbol ‘EOS’. From a probabilistic view, the triplet sequence generation is equal to predict the probability p θ (s, r, o) that the relational facts hold. Formally, for a given annotated sentence x j from the training dataset D and some potentially overlapping triplets T j (s, r, o) in x j , it aims at maximizing the data likelihood of the training dataset D, which is formalized as follows:
According to the rule-chain of probability, Eq. 1 can be rewritten as follows:
Eq. (2) implies that the model can first predict the relations from the sentence and then extract the subject entity and object entity simultaneously when given the relation.
This formulation provides many advantages. Firstly, the relationship is detected first, then the entities are viewed as arguments for each relation, and be recognized by an object tagger p θ ((s, o) |r, x j ), as opposed to classifying relations for (subject, object) pairs. Secondly, by utilizing a transformer model, the relation detection and entity identification can be completed in one decoding step. This process can be seen as extracting a triplet from triplet-level. Thus, the interactions between the relations and entities are better modeled. Thirdly, the overlapping issue can be solved in design, as multiple triples may share the same entities in this method.
The overall architecture of the proposed model is illustrated in Figure 2, which contains three components. On the left, a syntax-guided network encodes the input sentence into the hidden representation, representing the semantic information of the sentences. In the middle, the hidden representation and the embedding of relational queries are fed into a relation decoder to compute each relation’s probability. On the right, a pointer network receives the output of the sentence encoder and relation decoder to predict the span of the subject and object entities.
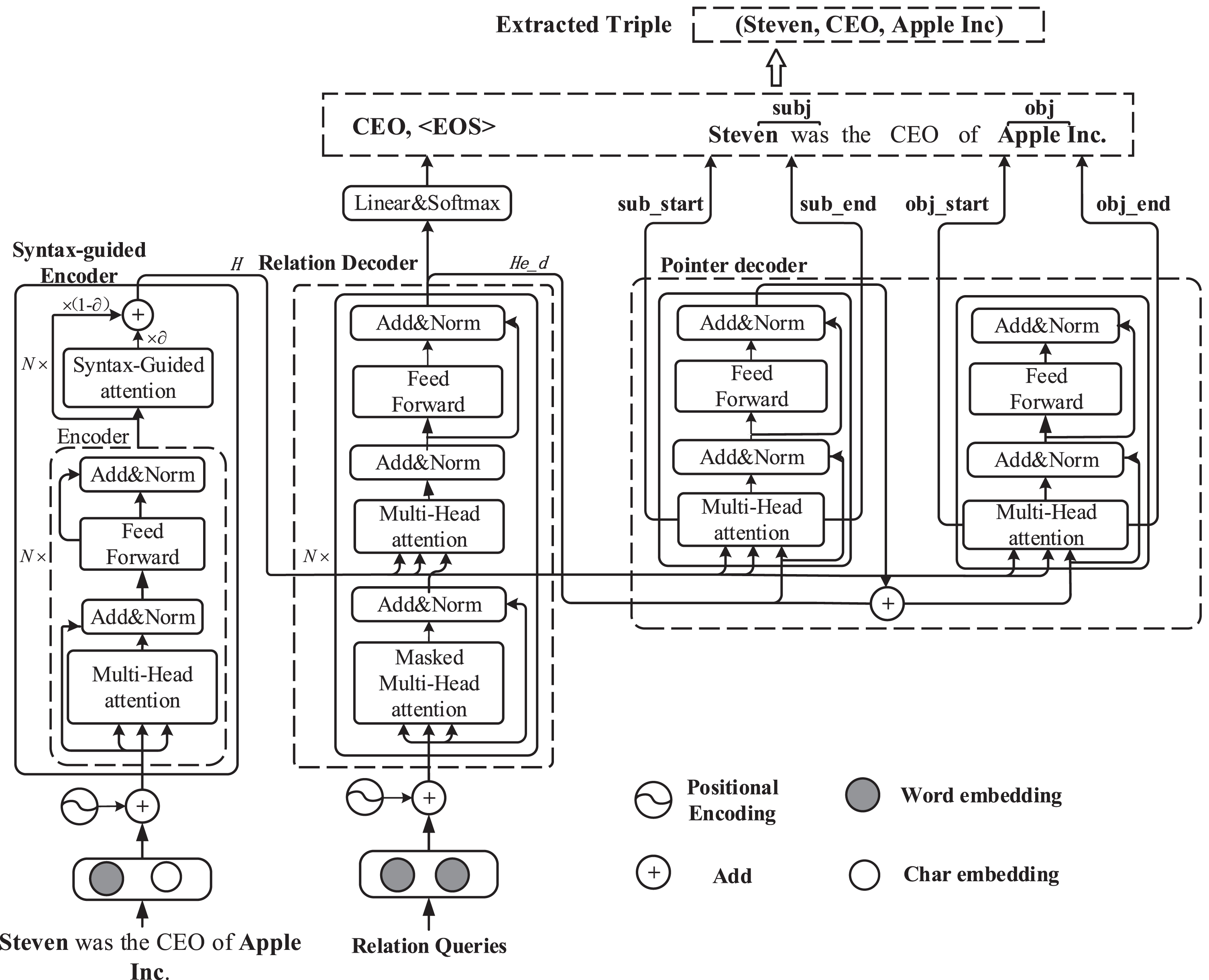
Main architecture of the proposed model. The model is composed of three parts: Syntax-Guided Encoder, Relation decoder and Pointer network.
This study utilizes two kinds of encoders to extract deep features from the input sentence: transformer encoder [14] and pre-trained model BERT [16]. As the architecture of BERT is mainly based on multi-layers of bidirectional transformer block, this subsection only gives a description of the transformer encoder.
Token embedding
For an sentence x with n tokens x = [w1, w2, . . . , w
n
], the first step is to convert the input tokens into continuous vectors
Sentence encoding based on syn-encoder
Previous studies [36, 37] have shown that the transformer-based model is able to capture certain syntactic information implicitly by learning from sufficient examples. However, there is still a gap between the syntactic structures implicitly learned and the explicit syntax structures created by human experts, which is useful prior knowledge for many NLP (natural language processing) downstream tasks. In this study, we also argue that the prior syntax information is essential for the joint extract task, as the facts in a sentence are often determined by some keywords that have syntax dependency in the syntax tree. For example, for the case described in the first section, there is syntax dependency among the keywords ‘Obama’, ‘born’ and ‘Honolulu’ (can be viewed in Fig. 4), and these information is enough to extract the fact ‘<Obama, place _ of _ birth, Honolulu>’. Conversely, noise may be introduced if the model pays attention to all the words in the sentence.
To capture the sentence’s syntax structure, this paper proposes a syntax-guided encoder (Syn-Encoder) to incorporate syntactic information, as shown in Figure 3. Firstly, the input sentence is encoded by the vanilla transformer; then, the output from the vanilla is fed into a syntax-guided attention network to get the syntax-guided representation. Secondly, the outputs from the vanilla transformer and the syntax-guided attention network are aggregated together to represent the final representation. With the guidance of the syntax dependency information, the encoder makes the word only attend to the syntactic-related words in the sentence.

The syntax-guided encoder is composed of two components: Transformer encoder and syntax-guided attention network.
The vanilla transformer is stacked by N identical layers, and each layer contains two sub-networks: a multi-headed attention layer and a fully connected feed-forward network (FFN). The multi-headed attention layer applies multiple heads to learn features from different sub-spaces, where each head is based on a self-attention mechanism. In the self-attention mechanism, each word’s representation is a weighted sum of other words in the sentence, and the weight matrix is often referenced as the attention matrix. The vanilla transformer adopts the scaled dot-product attention to generate the attention matrix. Particularly, the input embedding is first projected into query, key, and value vectors by different linear layers. Then, the transformer computes the dot products of the query vector with every key vector and divided each by
The multi-headed attention utilizes multiple learned heads to obtain features from different aspects. Then the output from different heads is concatenated together and once again projected to get the updated representation.
The updated representation is then passed to a residual connection and normalization layer to obtain a new representation.
The second layer FFN contains two linear transformations with a Rectified Linear Unit (ReLU). The output of the second layer is also fed to a residual connection and normalization layer to compute the output.
To fully exploit the syntactic information of the input sentence, the output of the vanilla transformer is further fed into a syntax-guided attention network to fusion the prior syntax knowledge. In the syntax-guided network, a masked matrix
Figure 4 gives an example of how to generate the masked matrix
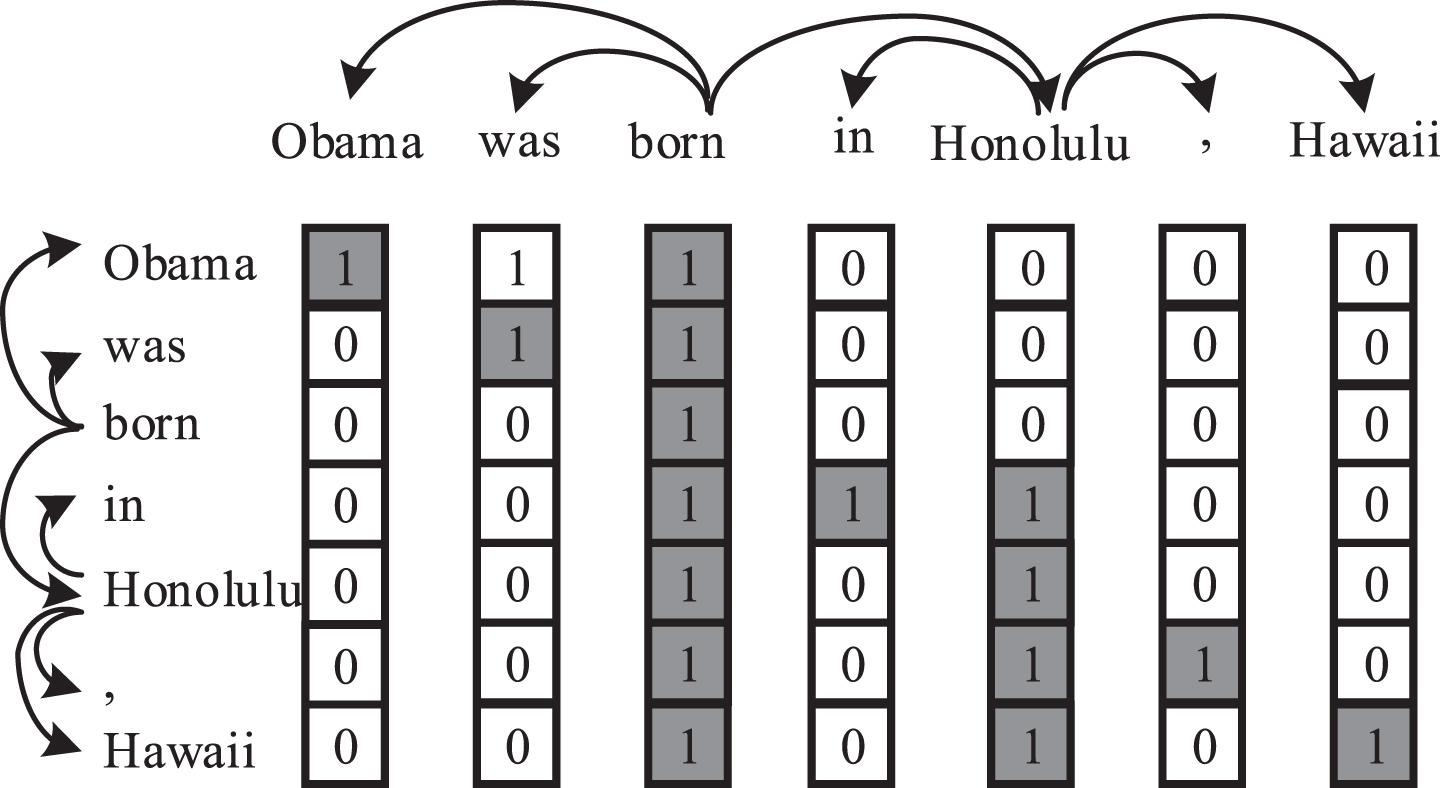
An example of the generation of the masked matrix based on the dependency tree.
When the masked matrix
The syntax-guided representation is obtained by multiply the attention matrix
A multi-headed attention mechanism is also applied in the syntax-guided network, and the representation is the concatenation from each head.
Finally, the output is the sum of the vanilla transformer and the syntax-guided network, which is computed as follows:
We control the contribution of the two part by a hyper-parameter α in Eq. (12), and it equals to 0.5 in this work.
The relation decoder is also stacked by N identical layers, and each layer consists of three sub-layers: masked multi-headed attention, encoder-decoder attention, and FFN layer. There also has a residual connection and normalization around each of the sub-layers. The decoder’s input embedding is the sum of word embedding and position embedding of the relation queries. In the masked multi-head attention, a masking operation is implemented to prevent the rightward information flow to the decoder, same as the vanilla transformer. The detail of this process is formalized as Eq. (13):
The second layer is an encoder-decoder attention layer, which performs multi-headed attention over the encoder layer’s output. The input for this layer also contains three vectors, where the query vector equals to the output of the first sub-layer
Then the encoder-decoder representations are also fed into the normalization and FFN layers, same as the encoding layer.
Lastly, the output of the decoder layer is feed into a linear layer and then through a softmax to get the probability of the relation p r , as defined in Eq. (19):
The subject and object entity are the span of the input sentence. Thus, the proposed model designs two pointer-networks to identify the start and end position of the two entities. As described in section 3, the subject and object can be seen as arguments for the relation, then the span of the entities is determined by the relation sequence and the input sentence. Therefore, a multi-headed attention network is utilized as the pointer network to recognize the entities. In the multi-headed attention layer, the key and value are the output of the syntax-guided encoder H, and the query is the output of relation decoder H
ed
. In this way, each relation makes attention to all the input tokens, and the attention scores can be treated as the pointer to select the related entities. For each headed, the attention matrix is calculated as Eq. (20):
As each entity has a start and end position, the multi-headed is split into two parts. The first part is used to determine the beginning location, and the second half is used to determine the end location. Specifically, the start position probability p s is computed by the sum of attention scores from head 1 to n/2, and the end position probability p e is calculated by the sum of the attention scores from the head n/2 +1 to n. The detail is presented in Eq. (21) and (22):
The object decoder is same as the subject decoder, which utilizes the multi-headed attention scores as the pointer network. As the object is determined by both the relation and the object, then the query vector is the sum of the relation decoder and the subject decoder, and the key and value vectors are equal to the output of the syntax-guided encoder
During the training, it aims at minimizing the sum of the negative log-likelihood of the relation classification and the four-pointer locations. The training objective is defined as Eq. (23):
where r, e1 s , e1 e , e2 s , and e2 e are the softmax score of the corresponding relation label, start, and end location of the object and subject entities. B and T stand for the batch size and the maximum number of the triplets in each sentence.
During the inference, the greedy search algorithm is utilized to generate relation sequences.
Datasets
Experiments were conducted on three public datasets, NYT24, NYT29, and WebNLG, as previous studies [10–13]. The NYT24 and NYT29 are originally produced by distant supervision method from the New York Times [30]. The NYT24 dataset was first produced by X. Zeng et al. [10], which contains 24 types of relations. The NYT29 dataset was first released by R. Takanobu et al. [31], which includes 29 types of relations. WebNLG was proposed by Garden et al. [39] for Natural Language Generation task, having 246 predefined relations types. This study adopts the dataset released by T. Nayak et al. [13] for NYT24 and NYT29. For the WebNLG dataset, the dataset pre-processed by Zeng et al. [10] is utilized. The statistics of the three datasets is illustrated in Table 1.
Statistics of the three public datasets
Statistics of the three public datasets
In this study, two different encoders are implemented, and the hyper-parameters are different for them. Tables 2 and 3 record the hyper-parameters for the transformer-based and BERT-based models.
Hyper-parameters for the transformer-based model
Hyper-parameters for the transformer-based model
Hyper-parameters for the BERT-based model
In the transformer-based model, the word embedding and char embedding dimensions are 300 and 50, respectively. The number of the filter for the 1DCNN model is set to 212, and the kernel size equals 3. The max length of the characters is set to 10. The transformer’s encoder and decoder are stacked by N = 4 identical layers, where each has 8 multi-headeds with the hidden dimension equals to 512. The pointer network layer contains one identical layer. In the BERT-based model, the BERT-Base-Cased is chosen for NYT24, WebNLG, and BERT-Base-Uncased is selected for NYT29. Both of them have 12 bidirectional Transformer blocks, and the size of the hidden state is 768. The number of the headed is 12 for the BERT-based model. We use the Stanford CoreNLP tool [40] to parse the sentence and get the dependency information.
During the training, the transformer-based model is optimized by an Adam [40] optimizer with a learning rate of 1e-5. The BERT-based model is fine-tuned with a learning rate of 1e-5 by the BERTAdam. The warm-up strategy is applied during the training and the warm-up steps is 8000. The training process lasts 150 epochs with the batch size of 64 for the transformer-based model and 8 for the BERT-based model. We also adopt the early stop strategy to train the model. If the F1-scores does not rise up for ten consecutive epochs, we stop the training process.
The network is implemented with PyTorch framework [42]. All the experiments were conducted on the Ubuntu server equipped with GeForce GTX 1080Ti GPU.
To verify the validity of the proposed model, several strong baselines are chosen as compared methods, including the following methods.
As some models cannot handle the multi-tokens entities, some previous work, such as CopyRE [10], GraphR [29], and Seq2Seq+RL [12], use a partial matching metric, where a triplet is regarded as correct only the relation and the header of subject and object entities are correct. Other models, such as HRL [31], WDec [13], and PtDec [13], use a strict matching mechanism. A triplet is regarded as correct only the relation and the corresponding full named entities are both correct. For a fair comparison, a strict matching metric is adopted in this study. Although the partial matching based methods are not strict, the results of these methods are also listed. The widely used metrics precision (P), recall (R), and F1 scores (F1) are reported in the experimental results. The definition of the three metrics is as follows:
In subsequent sections, this papers uses STP to refer to the transformer-based model and BSTP to the BERT-based model.
Overall evaluation results
The experimental results are presented in Table 4. From the results, it can be observed that the proposed method outperforms all the baselines among the three datasets. In these baselines, the WDec and Ptdec achieve a significant performance improvement than others, reflecting that the Seq2Seq method effectively handles the overlapping triplets. Compared with the WDec and Ptrdec, our model achieves a better performance. For the dataset NYT24, STP achieves the F1 score of 82.7%, which is 1.2% and 4.3% higher than the WDec and PtDec. For the NYT29, the F1 scores of STP are increased by 1.6% and 2.5% relative to the WDec and PtDec, and the F1 score reaches to 69.8%. For the last dataset, STP achieves the F1 score of 71.2%, which is 1.5% and 0.7% higher than the WDec and PtDec. The pre-trained BERT is also adopted as the encoder, and the results are recorded in the last lines. With the help of the pre-trained model, the proposed model obtains the best F1 scores on the three datasets, and the performance outperformsthe strongest baseline by 5.7%, 5.6%, and 4.4%, respectively. The performance improvements of the BERT-based highlights the importance of prior knowledge in the pre-trained language model.
Results of different methods on NYT and WebNLG datasets. ‘p’ represents the model uses a partial matching metric; ‘s’ stands for the model adopt the strict matching metric
Results of different methods on NYT and WebNLG datasets. ‘p’ represents the model uses a partial matching metric; ‘s’ stands for the model adopt the strict matching metric
To further study the capabilities of the proposed methods for extraction of the overlapping triplets, this subsection conducts an extended experiment on different types of triplets. As the NYT24 and NYT29 have a similar set of relations and text, the NYT24 and WebNLG are chosen as the experimental datasets. The NYT24 and WebNLG dataset are split into three sub-categories: Normal, EPO, and SEO. Then, evaluations are conducted on different types of sub-datasets, and the results are presented in Figure 5. As is illustrated in Figure 5, most baselines on the types of Normal, EPO, and SEO show a decreasing trend. It reflects that the difficulty is increasing over the extraction of triplets from the EPO and SPO categories. In contrast, our model attains strong performance over the baselines, especially for the more challenging patterns SEO and EPO. On the dataset NYT24, BSTP achieves the best F1 scores on the three types of patterns. For the dataset WebNLG, BSTP still has the best results in the Normal and SEO class. Although Seq2seqRl has achieved better results in the EPO category on WebNLG, BSTP is generally superior to all other models.

F1 scores by different overlapping patterns on the NYT24 and WebNLG.
This subsection further validates the proposed method’s capability to extract triplets from the sentence with a different number of triplets. We split the NYT24 and WebNLG dataset into five categories according to the number of the triplets in the sentence. Then experiments were conducted on each category. Figure 6 gives the F1 scores of the models on NYT24, and Figure 7 records the F1 scores achieved on WebNLG. From the results, it can be clearly seen that the F1 scores of the first two models (MulDecoder and Graph_2st) show a declining trend as the number of triplets increased. For the next four models, the F1 scores show a tendency to rise and then decrease. This indicates the Seq2Seq model has its superiority to handle the sentence containing multiple triplets, as the entities and relations can be repeated several times when needed to participate in different triplets. In NYT24, the proposed model achieves the best F1 score when the number of triplets is 4. In WebNLG, the best F1 score is obtained when the number of triplets is 2. For each category, BSTP achieves competitive performance compared with all the baselines on NYT24 and WebNLG, showing its superiority to extract triplets from complicated scenarios.
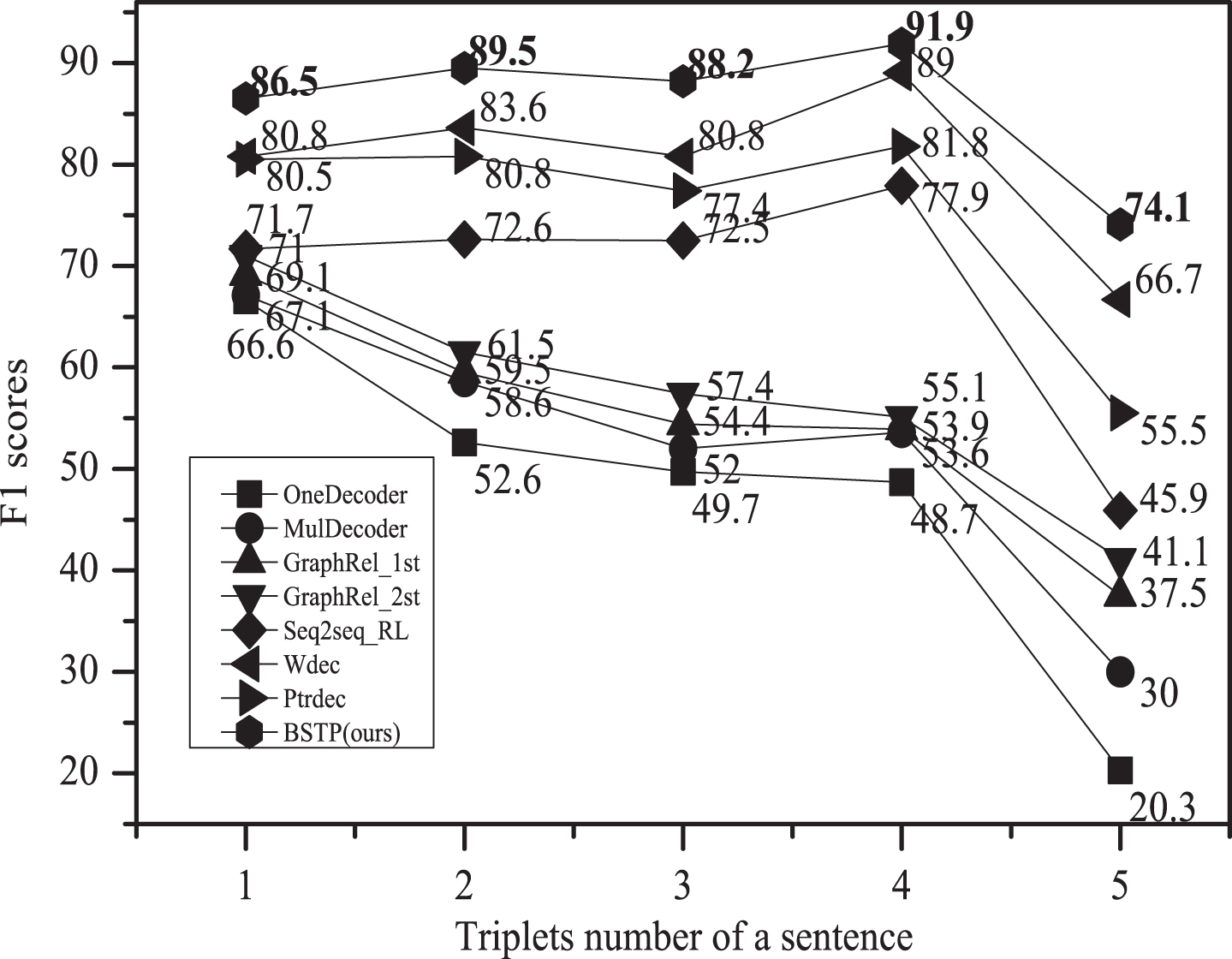
Comparison on the NYT24 dataset for extracting different number of triplets.

Comparison on the WebNLG dataset for extracting different number of triplets.
Performance analysis
This subsection gives a deep analysis of the results achieved on three datasets. Based on the results from Table 2, it can be seen that there is a significant gap between the performance on NYT24 with other two datasets. It reflects the extracting of triplets on NYT29, and WebNLG is more complicated than on NYT24. For the NYT29, the overlapping triplets on the training dataset are about 28%. In contrast, the training data of NYT24 contains a large number of overlapping triplets, accounting for more than 43%, making the model trained on NYT24 are more flexible than on NYT29. The dataset WebNLG contains 246 types of relations, almost 10 times the size of NYT24. Besides, the WebNLG dataset contains fewer training samples, making the performance of the models on WebNLG worse than that on NYT24.
Ablation study
To verify the syntax information is helpful for the joint extraction task. Ablation experiments are conducted, and the results are given in Table 5. As is observed, the syntax-guided model achieves better performance than the origin transformer-based and BERT-based models with the help of the syntax structure. It demonstrates that the syntax structure helps the model to obtain a better representation of the input sentences.
Ablation experiment of the syntax-guided networks on the three datasets
Ablation experiment of the syntax-guided networks on the three datasets
Table 6 reports the model size and inference speed of our method compared with two competitive methods: WDec and PtDec. The inference speed is measured by the number of batches processed per second during inference. From the results, it can be observed that WDec is the lowest in the decoding process. Because WDec generates the triplets on entity-level or word-level rather than triplet-level. It requires more decoding steps to produce a triplet than the other three models. Comparing the model size of PTdec and STP, STP is larger than PTdec, but it decodes faster than PTdec. The reason is that STP produces the relations and entity pairs in parallel, while PTdec still needs to determine the entity boundary before decoding the relation. BSTP is the largest due to the use of the pre-trained model, but it even decodes faster than the WDec model.
Comparison of the model size and decoding speed (Bat/s refers to the number of batches processed per second)
Comparison of the model size and decoding speed (Bat/s refers to the number of batches processed per second)
This subsection visualizes the attention map of the encoder-decoder multi-headed attention layer, and some examples are illustrated in Figure 8. In the attention map, the vertical axis represents the relationship category contained in the sentence, and the horizontal axis represents the attention weight gained by each word in the sentence when extracting the entities corresponding to each relationship. In the first case, the model gives more attention to the words ‘See’ and ‘Louis’ when extracting the first fact (See, deathplace, Louis). For the second fact (See, birthplace, Dallas), the model makes attention to the important words, such as ‘See’, ‘born’, ‘Dallas’, and so on. In the second case, the entity pair (Wal - Mard, SamWalton) contains multiple relations. The model pays accurate attention to the keywords ‘Wal-Mart’, ‘Sam Walton’ and extract the triplets correctly. In the third case, the model give accurate attention weight to the words ‘Japan’ and ‘Tokyo’, and extracted multiple triplets from the sentence correctly. It can be observed that there are no clear clues in the third case to indicate the entity pair ‘(Japan, Tokyo)’ contains the relationship ‘capital’. Our method still accurately predict the fact (Japan, capital, Tokyo). The reason for this is that the pre-trained model BERT contains large prior knowledge which helps the model to recognize this facts.
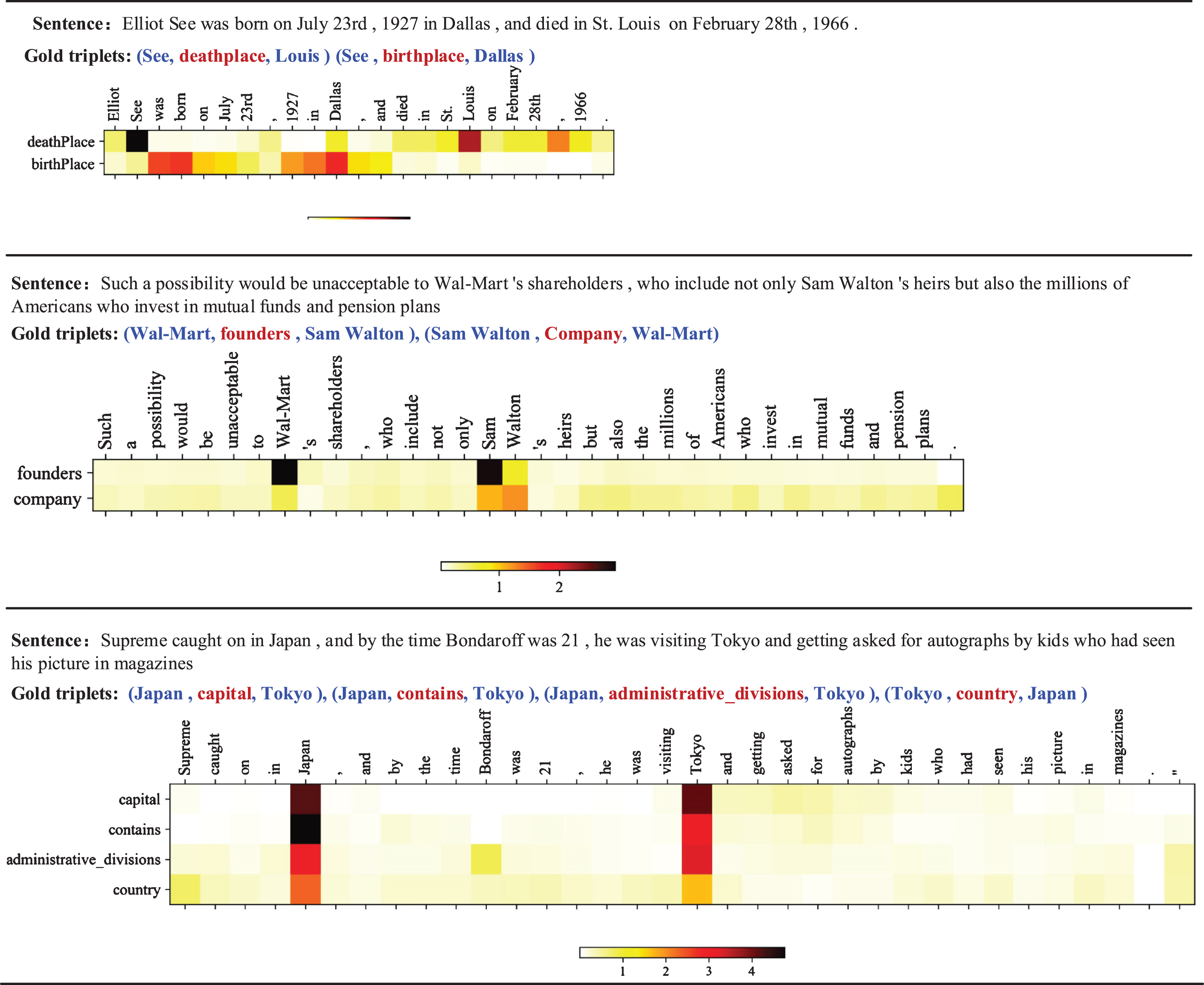
Visualization of the attention map for the multi-headed attention layer.
An error analysis is conducted in this section to further explore the factors that affect the model’s performance. This subsection analyzes the model performance in predicting different elements of the triplets, and the results are presented in Table 7. E1 and E2 represent the model predicts the subject entity or object entity correctly. (E1, R) stands for the subject and relation is predicted correctly. (R,E2) indicates the model correctly predicts the relation and object. (E1, E2) means that both the subject and object are extracted correctly. (E1, R, E2) acts for a triplet is extracted correctly.
Performance of the model on predicting different elements of the triplets
Performance of the model on predicting different elements of the triplets
In the dataset NYT24 and NYT29, the performance on R is higher than E1 and E2, demonstrating that extracting relations is easier than extracting the entities. It also finds that there is an apparent gap between the F1-score on E1/E2/R and (E1, R)/(R, E2)/(E1, E2). It reflects that many triplets are only correctly identified for one element. The performance of (E1, R, E2) is lower than the (E1, R)/(R, E2)/(E1, E2), implicating that most of the entities and relations are correctly identified, but some of them fail to form a valid triplet.
In the dataset WebNLG, it can be seen that the performance of E1/E2 is comparatively larger than R. It shows that extracting relations is more complicated than extracting entities on the WebNLG dataset. The reason is that WebNLG contains more relation types than NYT24 and NYT29. What’s more, it can be observed that the performance of (E1, R)/(R, E2)/(E1, R, E2) is significantly reduced compared with the E1/E2/R/(E1, E2). It shows that misidentifying the relations will bring more performance degradation than misidentifying the entities.
In this paper, a novel Seq2Seq architecture is presented to handle the overlapping issue in the joint extraction task, which combines transformer and pointer networks to extract entities and relations. Unlike traditional Seq2Seq methods, the new model generates the triplets on triplet-level; thus, it can capture the triplet-level dependencies and speed up the decoding process. Furthermore, a syntax-guided network is introduced to explicitly incorporate the sentence’s syntactic information into the encoder, helping the model pay more attention to the important words of the sentence. Extensive experiments were conducted on the NYT and WebNLG datasets to evaluate the proposed method. The experimental results show that our proposed model works well with the overlapping triplets in complex scenarios and outperforms other baselines.
In this study, we utilize an autoregressive approaches to generate the triplet one by one in a certain order. In the future, we would like to apply a non-autoregressive parallel decoding method, which can directly output the final set of triples in one shot. Further, we would like to promote our research’s practical application in knowledge base construction and web information extraction.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant 61871278, the Sichuan Science and Technology Program (no. 2018HH0143).