
Abstract
In the last decade, many intelligent interfaces and layers have been suggested to allow the use of relational databases and extraction of the content using only the natural language. However most of them struggle when exposed to new databases. In this article, we present SQLSketch, a sketch-based network for generating SQL queries to address the problem of automatically translate Natural Languages questions to SQL using the related databases schemas. We argue that the previous models that use full or partial sequence-to-sequence structure in the decoding phase can, in fact, have counter-effect on the generation operation and came up with more loss of the context or the meaning of the user question. In this regard, we use a full sketch-based structure that decouples the generation process into many small prediction modules. The SQLSketch is evaluated against GreatSQL, a new cross-domain, large-scale and balanced dataset for the Natural Language to SQL translation task. For a long-term aim of making better models and contributing in adding more improvements to the semantic parsing tasks, we propose the GreatSQL dataset as the first balanced cross-domain corpus that includes 45,969 pairs of natural language questions and their corresponding SQL queries in addition to simplified and well structured ground-truth annotations. We establish results for SQLSketch using GreatSQL dataset and compare the performance against two popular types of models that represent the sequential and partial-sketch based approaches. Experimental result shows that SQLSketch outperforms the baseline models by 13% in exact matching accuracy and achieve a score of 23.9% to be the new state-of-the-art model on GreatSQL.
Keywords
Introduction
The task of translating Natural Language to Database programs is recently getting more and more momentum from the community of researchers since it can facilitate the work of users with no knowledge on databases languages and let them interact with these systems in an inteligent manner without the need to learn a new language or to use interfaces with feedback layers that ask the user for a sequence of questions to wrap the search in order to understand and build the wanted query incrementally.
Compared to other Natural language processing tasks, the one related to Natural Language to Structured Query Language (SQL) (NL-to-SQL) is relatively more complex since the source language and the target language are totally different. While the source language is a form of communication, the target one is a language that holds details of implementation necessary for interacting with relational databases.
In the last ten years, many studies have introduced solutions to translate Natural Language, especially the ones that transform an English sentence to SQL in order to interact with relational databases. Earlier, the majority of these solutions were based on approaches that adopt syntactic analysis with some traditional linguistic techniques like the construction of the syntax tree, the make of the morphological analysis, etc.... In order to enhance the performance of the models and the quality of the generated output, some researchers have introduced the use of semantic parsing with some deep learning techniques. The approach of semantic parsing becomes the base bundle of many other researches in the recent years. This provided a big improvement in the way the models generate the intended query even if sometimes they are more complicated.
Many datasets are available for models evaluation, However the majority of these models are evaluated using two main corpuses, either they are evaluated against WIKISQL [1] or using the SPIDER dataset [2]. Some state-of-the-art research works have been able to reach more than 90% on WIKISQL and exceeded 60% of matching accuracy on SPIDER corpus. This result is seen as a big step in solving the task of NL-to-SQL and offer an intelligent way to deal with this issue. The main problem with the two previously mentioned dataset is related (but not limited) to the scale of difficulty of the proposed queries structures, the total number of the included samples, the number of the hard pairs compared to the whole number in the corpus, the annotations structure, the complexity for using the corpus, etc...
Our main contribution in this proposed work is two fold. First, we present SQLSketch a sketch-based network for generating SQL queries to resolve the task of intelligently translate Natural Languages questions to SQL Queries using the schemas of the corresponding databases. Second, we introduce GreatSQL, a new large-scale, cross-domain, human-annotated and balanced dataset for developing natural language interfaces.
In this paper we discuss the details of our new sketch-based model dedicated for predicting complex SQL queries. Also we will show the limitations of the formerly published corpuses, the evaluation methods and the experimental results. Finally, we present and discuss our new Human labeled Dataset for translating English sentences to SQL which is, until the writing of these lines, the largest balanced cross-domain corpus publically available.
Background
Models
The translation of natural language to SQL queries for relational databases is part of the bigger collection of Semantic parsing tasks. Many approaches have been proposed in the recent decades, which try to resolve either completely or partially the NL-to-SQL task. We can differentiate between models that use syntactical approaches that are based on hand feature engineering like what have been proposed by [3] and the ones based on semantic analysis that treat the problem using deep learning techniques. There is Seq2SQL proposed by [1] who introduced the use of reinforcement learning to generate SQL queries; also, [4] have suggested not to use reinforcement learning for the training process for SQLNet model and have instead introduced the use of a combined decoding structure that includes sequential generation in some parts of the SQL query and the sketch structure in the others, thing that helped to yield better results. Recent works by [5–10] and [11] were all neural network-based approaches with some slight differences. The common part of all the previous models is the focus on queries with single column and table using the WikiSQL Dataset. Another category of models was proposed to handle advanced SQL queries using the Spider dataset [12]. Introduced a syntax tree-based decoder with exploitation of syntax information for the generation process [13]. Suggested a Clause-Wise and Recursive Decoding to deal with nested queries [14]. Used a sequence to sequence paradigm with a grammar based decoding thing that showed significant improvement to the task. To help models to generalize to unseen databases [15] proposed a semantic parsing model that deals globally with the structure of the output query to better choose the correct components in the unseen databases. Other research works like [16] suggest the use of Database content by replacing the detected column in the question by a random value from the database. This new method for parsing natural language sentences, based on a context-free Grammar Pre-training, helps to better decode deep relations between user questions and component of the databases.
Our model that is fully based on a sketch decoding approach is founded on a multiple neural sub-modules that take advantages of the inherent nature of the SQL structure that will be trained each of them separately on the GreatSQL dataset without sharing parameters in order to better manage the generation of queries as it can be seen in Fig. 1. Our aim is to develop a model that can generalize to unseen domains and databases as well as complex and unusual structures of SQL queries without using reinforcement learning or making use of the content of databases’ tables.
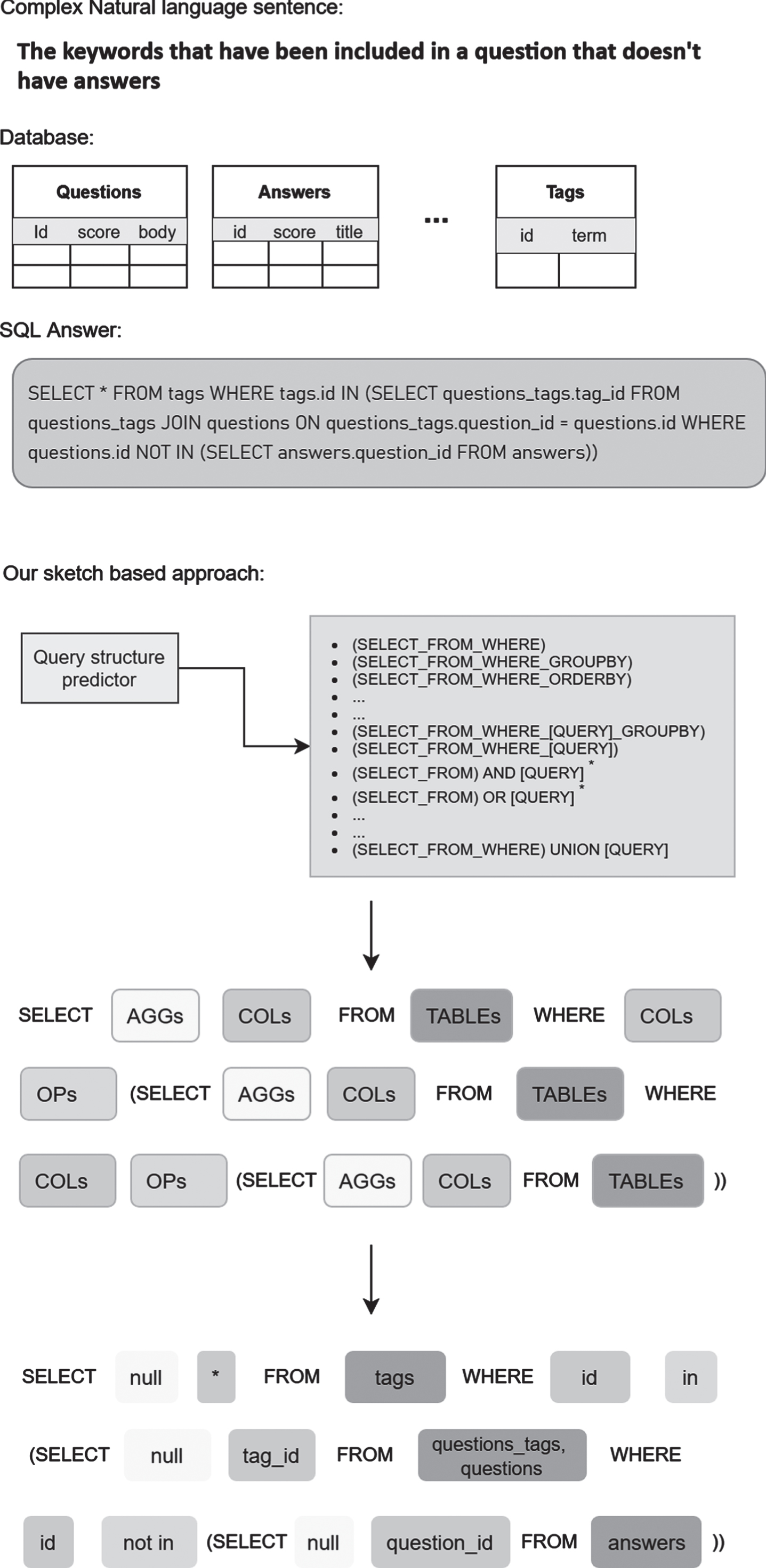
SQLSketch is based on many small neural network modules with a query structure predictor on top.
Throughout the years several datasets have been published and offered a base line for evaluating syntactic and semantic parsing models. Each time a new dataset is available, new improvements are added to the previous existing corpuses. However, the resolution of the task of NL-to-SQL is still not complete.
The first available datasets proposed simple items with limited structures. Also the output format was not totally dedicated to SQL queries as the task of NL-to-SQL is relatively newer than those datasets. The datasets were annotated using logical forms which add additional work for the evaluation process.
Datasets like ATIS [17], GeoQuery [18] and JOBS [19] are one of the earliest available corpuses. Lots of researchers [18, 20–28] have went deeply in analyzing these datasets even they were non exhaustive corpuses before they were adapted with SQL labels by [29] and [30].
The existence of the previously mentioned corpuses has not prevented other researchers for providing new datasets dedicated for SQL programs. Datasets like Scholar [29], IMDB and Yelp by [3], Academic [31] and Advising [32] were created to provide an improved tool for evaluating earlier NL-to-SQL models. This datasets have participated in the development of the task and to get closer to an acceptable result. Several works were evaluated with these databases; among them, the study of [3] which proposed SQLizer (Query Synthesis from Natural Language). They translate NL question to relational algebra then it’s transformed directly to an SQL query. Even though the solution uses a linguistic parser from the shelf called coreNLP, the solution is mainly based on syntactic techniques.
Another generation of datasets have been proposed by [1] and [2]. They respectively proposed WIKISQL and SPIDER; two datasets dedicated for evaluating models that outputs SQL programs. The first dataset (WIKISQL) is a collection of more than 80654 pairs of English questions with their corresponding SQL Queries. The corpus is based on more than 24240 tables extracted from Wikipedia pages. The dataset provides clean and well organized ground-truth sections that include all parts of each SQL query in the format of a JSON structure. On one hand, it is the largest human-annotated dataset for NL-to-SQL task, but on the other hand it doesn’t contain diversified queries. The scale of queries structures is very poor and it has some NL sentences with grammatical errors; while it can be used to train and evaluate simple models, it cannot be used for programs with multi-tables since all the included schemas are about one table. In the same context, lots of commands are missing in the dataset. For example, queries with GROUP BY, ORDER BY and JOINS are not taken on consideration, hence the use of this corpus as a dataset for the training phase and the evaluation will surely make low-quality models since in the reality the data is stored in most cases in multiple tables of relational databases systems.
With the same concept, SPIDER provides more diversified queries and a large scale of structures mainly dedicated for models that adopt a sequence-to-sequence structure for the generation; it’s created using 200 different schemas and contains about 10000 pairs of English sentences with the target SQL queries and the appropriate labels divided in a train, dev and test set. Unlike WIKISQL, SPIDER contains items of previously published datasets such as GEO and ACADEMIC. All usual SQL commands exist including GROUP BY, ORDER BY, JOINS and SET operators like INTERSECT, UNION, etc. The main drawback of the dataset is the number of samples it is by far not enough to either train the models or evaluate their pertinence and the quality of their outputs.
Despite the fact that SPIDER is a cross-domain dataset with different queries difficulties, it still contains a limited number of hard samples (10.95% of the whole corpus) as we have demonstrated in our previous research article [33].
More datasets were also constructed for other tasks like generating codes of programming languages using natural language sentences as input. That includes, DJANGO [34] for code translation tasks, HEARTHSTONE [35] for Game Cards to code translation and NL2Bash [36] for Generating bash commands from Natural Language descriptions.
SQLSketch
Methodology
We follow an extended version of the approach of SQLNet [4] of adopting a sketch decoding structure instead of a sequence-to-sequence one. However, we differ from them on many points; first we add a query structure neural network that helps us to define the general structure of the target SQL query. We use a fully sketch-based model with several sub-modules, each of our modules has its own parameters and predicts outputs independently. Unlike SQLNet we don’t use sequential decoding in WHERE Clause. Also, the structure of each module is different and we add new sub-modules to handle complex SQL queries that contain GROUP BY, HAVING, etc...
Model details
Our model is a collection of many sub-modules; each module is responsible for predicting the appropriate output taking on consideration the context of the current clause only, not the whole context of the SQL query such is made in Sequential decoding structures. To this end, we inlcude a layer of BERT [37] in order to get the contextualized word embeddings of each element of the input. The question Q and the database schema S are tokenized and concatenated then fed to the BERT Layer. We consider a token anything between two spaces. The words of columns are prefixed by the table name and separated by a reserved token [SEP] (one column might contain more than one token).
As it is mentioned previously, the input X is fed to the BERT layer to get the corresponding words embeddings which are vectors that contain the representation of each word in the input. In addition to this, a global vector [CTX] that holds the meaning of the whole input is provided by the layer. The output is used as needed by each sub-module; for example, the query structure predictor will use it to construct the skeleton of the SQL query, while the other modules will exploit it to fill the skeleton with the appropriate elements.
The SELECT slot items are predicted in many steps; we first need to predict the columns and then we proceed further with the related items like aggregation functions. For this end, we adopt a classification model that predicts the number of the columns in this slot then we choose the C (We choose 5 as the maximum number of possible columns in any SELECT slot. This is a parameter that can be modified as needed) columns with the highest probability. The output of C is computed as follows:
With U
C
, V
C
are trainable matrices. The use of R [CTX] comes to encompass the whole context of the question besides the columns and table names. The i-th dimension with the highest value is taken after applying the Softmax function. The probabilities of columns is computed in the same way using the BERT context vector of R [CTX] :
The R [CTX]/COL (i) represents the attention of the column COL(i) towards the context vector provided by BERT. This helps aligning the columns with the input question and highlighting the important parts. The C columns are chosen to be the most probable ones in that slot. The set of columns is used to define the related aggregation functions if exist. This is formulated as a simple classification problem while the number of classes is the possible aggregation functions in SQL programs (No aggreagation function; COUNT; MAX; MIN; AVG; SUM).
In the WHERE clause, the prediction is considered as a simple classification problem. The columns are predicted first in the same way as the columns of the SELECT clause. Then for each chosen column, we get the appropriate operator from the list of supported operators in GreatSQL that includes ["=", "< ", "> ", "< =", "> =", "!=", "BETWEEN", "IN", "LIKE", "NOT IN", "NOT LIKE", "IS NULL", "IS NOT NULL"]. The WHERE operator of a given column is computed as shown bellow:
The U
op
and V
op
are trainable matrices and R [CTX]/OP (i) is the representation of the context vector together with the operator word embedding calculated using column attention mechanism of [4]. The operator with the highest probability is chosen to be included in that condition in the WHERE clause. For the values and since the GreatSQL dataset provides start and end indexes of each value presents in the natural language sentence, we opt for defining the start index and end index as following:
The
As we have described in our previous research paper [33], the tables are deducted from the set of tables related to the columns that appears in the SELECT and WHERE clauses and using a graph to complete the chain of the intermediate tables.
Since the columns in the SELECT clause can include aggregation functions, it will help us to define if the query will include a GROUP BY clause or not. When the SELECT clause includes columns with at least one aggregation function in addition to the ones without them, the GROUP BY slot is added to the query and the columns that does not have aggregation functions are joined to it.
The query structure predictor aims to define the global structure of the target sql query. This module is a neural network that constructs the query incrementally by choosing one structure from a catalogue that contains all possible structures as shown in Fig. 1. It only uses the context representation from BERT layer and outputs the index of the most probable structure adequat for the natural language sentence in input. If the keyword [QUERY] is included in the selected structure then another round of query prediction needs to be made and the substitution of the keyword with the new generated structure is done until we have no [QUERY] keywords.
Regarding the advanced SQL commands like set operators, the model is able to generate, not only nested queries, but also the SQL programs that include many combinations such as the use of Intersect, Union, Except, etc. This can be done thanks to structures in the catalogue like in the example 7. The addition of structures such as of the example 8 also helps us to predict several sub queries in a single WHERE clause.
The number of sub-modules to be ran depends on the full structure generated. The catalogue contains structures with holes that will be filled by the corresponding modules.
The construction of the corpus was made by five people who participated in the making of this dataset for a period of one year. The participators were computer science engineers, PhD students and one University Professor; two of the collaborators weren’t from our University laboratory. The whole task took more than 1502 hours in average per participator. The Fig. 2 shows the global process and duration of the creation of the GreatSQL dataset.
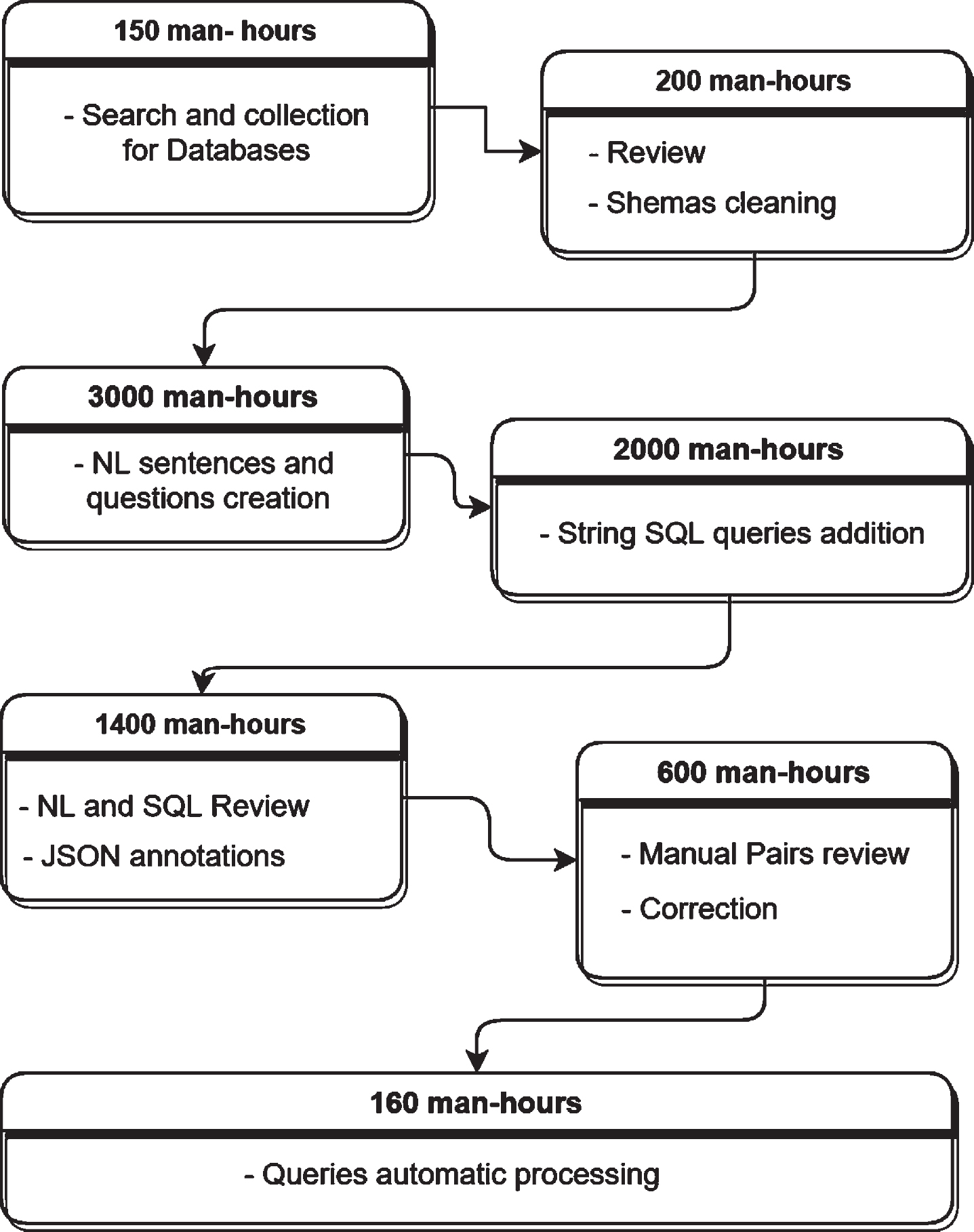
The global process and duration of the creation of the GreatSQL dataset.
The process started by collecting the databases that will be used for the dataset. This task took in total about 150 hours for searching and choosing the appropriate databases that will be used. Among the criterias for accepting databases to be part of the GreatSQL; there is the availability of the database on internet as well as the reality of the included data. In other words, all included databases in GreatSQL dataset are from real word use and no one of them has been created by us. During this phase about 250 databases have been chosen.
Schema cleaning
The schemas’ cleaning is the phase of checking the structure of the schemas of the collected databases. From 250 databases collected, only 224 databases have been kept then reviewed and cleaned by our participator. Since the databases are publicly available on internet, some of them have errors or they don’t follow standard norms of relational databases or they include items with non sense meaning or abbreviations. The cleaning process includes correcting the schemas, removing or renaming some tables or columns and creating in some databases intermediate tables for many-to-many relations. For example: Converting the values from strings (Y/N or T/F) to Boolean type (True/False). In the database of “Geography”, we changed the name of the table “Highlow” into “Elevations”. We get rid of all abbreviation and technical keys in the table “Matches” of the database “European Soccer” Some columns values that could be gotten from other tables like "number of reviews" or "calculated host listings count" are removed.
We make sure that the dataset includes all kind of usual data types, except the blob or files ones.
NL questions creation
To create natural language questions, the participators made a list of the candidate tables and all their combinations in order to spot all eligible and adequate tables for SQL queries. This list helps the participators for easily follow the combinations and create NL sentences since it contains all possible compositions for all the existing databases. Afterwards and for each item, several NL questions are created in order to cover the largest number of possible queries for each combination in every database schema. To have natural, diverse, and large scale of difficulties of questions and for the aim of imitating human intuition and reflection, we don’t use templates or generated scripts for creating these question and String SQL queries.
The whole NL sentences are reviewed to spot the grammatically wrong items. Some of the created NL questions are corrected or paraphrased either manually by participators or using an automatic tool like quillbot 1 . The rest of questions are kept as they were created by participators and moved to the next stage. The duplicated NL sentences within the same schema are also removed from the corpus.
String SQL queries addition
To guarantee an independent creation process and for high quality ends, the NL sentences are shuffled and given to other participators who haven’t worked on the related databases of each item. For every NL question in the list, a String SQL query is created by participators. Since in SQL language, we may have for the same NL question several corresponding valid SQL queries that yield the same result, few questions are slightly the same with different SQL answers, this allows the future model to have better understanding and good coverage of all possible cases.
We make sure that the majority of the popular and the most used SQL commands by users exist; among them we have: GROUP BY, INNER JOINS, ORDER BY, WHERE, HAVING, Nested Queries, etc... For simplification purposes, we have omitted samples with Set operators like UNION, INTERSECT, etc..., since all queries based on those operators are result of two SQL queries or more that the user can construct separately.
JSON annotations
The annotations in the GreatSQL dataset are made using JSON structures. First, each pair of NL question and SQL query in the temporary corpus is reviewed to make sure that String SQL queries correlate exactly to the corresponding NL sentences. The pairs that need correction are enhanced. Then the adequate JSON annotations for each String SQL are added to the corpus. The JSON structure represents exactly the structure and the elements of each SQL query, thing that is beneficial for facilitating the training and evaluation of the future models. Unlike SPIDER dataset, some of the slightly similar NL questions that have different acceptable SQL answers, have in GreatSQL different annotations. We believe that this will help the trained model to understand the similarity between queries.
Final manual review and correction phase
Before the processing of the items of the dataset, we proceed with a final stage of manual review of the whole items including the NL sentences, String labels and the JSON annotations of each sample. At this stage, we check ambiguity of questions and we verify the clarity of questions. Some NL sentences added by the participators that require additional knowledge outside of the schema of the database or the ones that are fuzzy are reformulated manually. Each item is reviewed by the five participators of the dataset. The samples that were agreed by at least 3 collaborators are approved and the rest is put for manual paraphrasing by the other reviewers. At this stage we preferred to make manual modification to be sure of the correctness of each element in GreatSQL.
Automatic processing and preparation
The last phase of the construction of GreatSQL was the execution of several scripts that parses the JSON annotations and make sure that all of them are valid. Also, at this stage, we add some organizational information like a generated ID of each query and the index of the related schema among all the databases. Once all processing task were done the split of the dataset is performed to have 3 separate sets, a Train, Dev and Test one.
Corpus statistics
The construction of GreatSQL made it the most complex and the largest human-annotated cross-domain dataset for NL-to-SQL translation task. In comparison with other datasets, we found that GreatSQL contains SQL queries from 224 distinct databases from different domains like Football, Movies, Songs, Real estates, etc... which is the highest number compared to other datasets. Among these datasets, we have integrated the biggest databases publicly available on Internet like ATIS, IMDB, Academia, Scholar and YELP as well as others available on Internet 2 . Also in term of the size, GreatSQL include about 46 000 pairs of NL questions and their corresponding SQL queries which is 4 time more than the recent dataset SPIDER; In the same context, we tried to use the biggest and the most complex schemas for our SQL queries to simulate the real use of relational databases. The average number of tables per each database is 5.6. The Table 1 shows a general comparison of GreatSQL against recent published datasets for the task of NL-to-SQL translation.
Overall comparison
At a quick glance on the Table 1, it appears that GreatSQL outweighs all the previously published datasets. It has by far more pairs, more databases and more distinct schemas’ topics as well as a higher average of the number of tables per schema than all other cross-domain corpuses.
The comparison of GreatSQL and recent datasets. The comparison shows the advantages of GreatSQL against other cross-domain datasets in term of number of NL questions/SQL queries, number of related domains as well as the complication and the largeness of schema of databases
The comparison of GreatSQL and recent datasets. The comparison shows the advantages of GreatSQL against other cross-domain datasets in term of number of NL questions/SQL queries, number of related domains as well as the complication and the largeness of schema of databases
The average number of columns in SELECT clause is 1.82 with a maximum number of 9, which exceeds by far all the previously published datasets. Also in term of items difficulty, we provide a large scale of diversified SQL queries including all popular SQL commands like GROUP BY, HAVING, INNER JOINS, ORDER BY, etc.
From the Table 2, we see that GreatSQL has more complex pairs than any other datasets. It outweighs all other datasets in term of the number of these SQL items: GROUP BY, HAVING, ORDER BY, LIMIT, Nested queries.
A detailed comparison of GreatSQL with other datasets
A detailed comparison of GreatSQL with other datasets
The complexity of a dataset can be measured using different metrics. First of all and related to the schemas, we have the number of domains included, the number of tables in each database and also the number of columns in these tables. In all cases, higher values imply greater complexity. Regarding the SQL queries, we consider many factors; among them there is the number of queries with GROUP BY, HAVING, Nested queries and also the depth of sub-queries. Also for these metric, greater values is reflected in the complexity of the dataset. Another important factor that influences the hardness of datasets is the length of the NL questions and the String SQL queries. From the Figs. 3 and 4, which shows the distribution of NL questions and SQL queries in GreatSQL, we see that about 25040 NL questions are between 15 and 25 words of length.
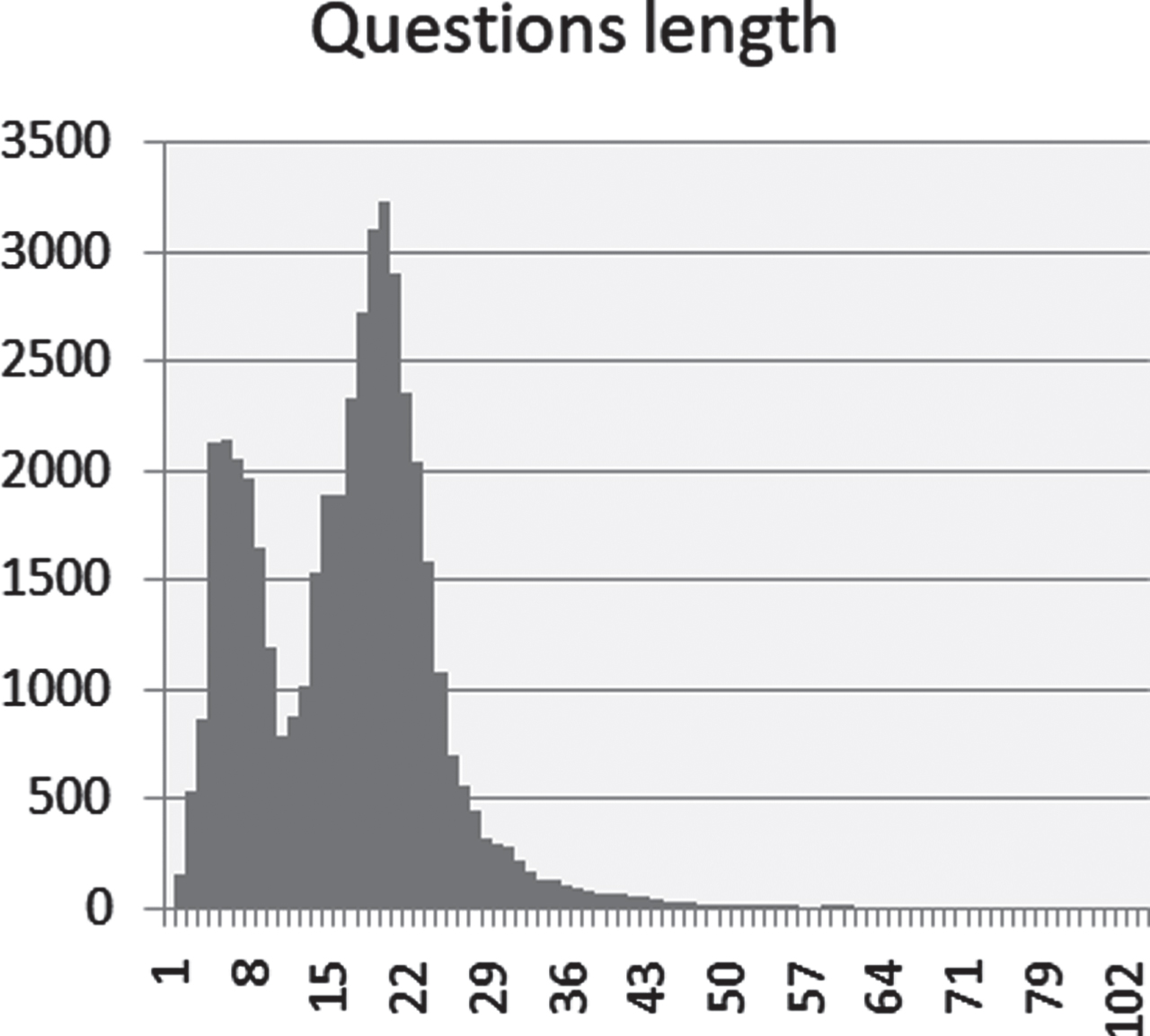
The length of questions in GreatSQL.
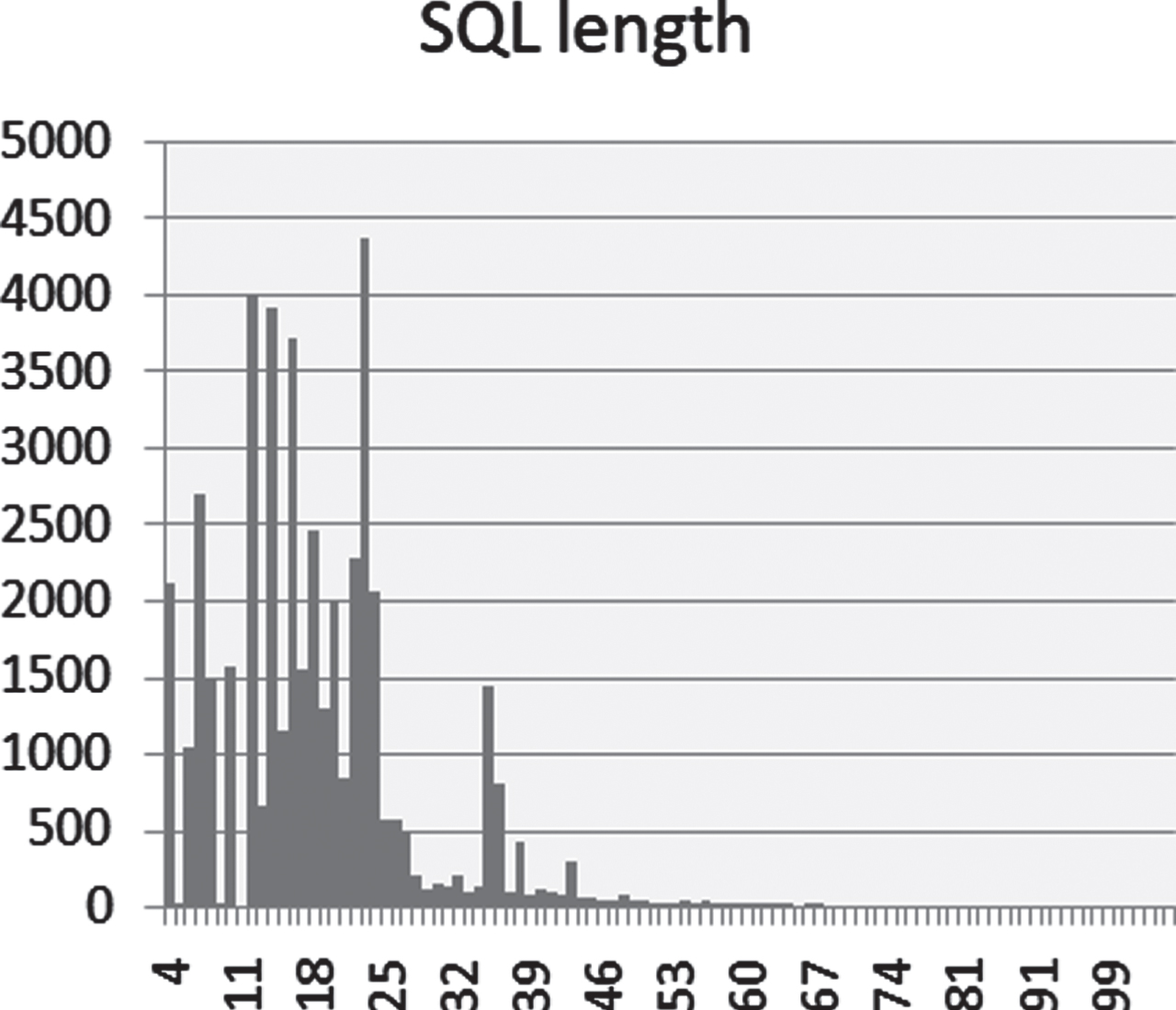
The length of String SQL queries in GreatSQL.
For String SQL queries, we have more than 25610 items with a length of 14 to 25 tokens. We also notice that some long NL questions are not always related to long SQL labels. In this context, we may have long NL sentences with short corresponding SQL queries and vice versa. The complexity, the diversity and the volume of the GreatSQL, that we make publicly available on: https://github.com/karamsa/GreatSQL, makes it the new complex challenge for NL-to-SQL translation works. We provide in the Table 3 three examples of queries of different scales of difficulty:
Pairs examples from the GreatSQL dataset
In order to prevent models from memorizing SQL queries or NL questions, we choose to make a database-based data split as shown in Table 4. We have divided the corpus to 3 sets, Training, development and Test one. To keep the same degree of complexity in all three sets and help the models to generalize to unseen NL questions, SQL queries, schemas and domains that were not seen on the corpus we first split the databases in a way to have a balanced content among the three sets in term of complexity of the schemas of databases, then we shuffle the pairs for each set. Some of the NL questions may be syntactically the same but related to different schemas, thus to prevent models to memorize the correspondences. To correctly verify the capability of the models to generalize to unseen items, we made sure to put some unique domains to be seen on the test set only.
The data split of GreatSQL
The data split of GreatSQL
We adopt 2 evaluations metrics, the component matching as it has been done by [2] and the traditional exact matching. For component matching we make sets matching between the ground truth and the predicted elements. Regarding the exact matching, we compare the generated SQL query with the gold one. We omit the execution accuracy metric as we want models to be independent of the execution result. In the usual use of relational databases, not all queries return results; some SQL queries might have the correct syntax and the appropriate calls of columns, tables and values but still give empty result, and this is due to many causes like when there is no rows in the tables of the database, a wrong value provided in the query, etc...
While the execution metric might reflect wrong accuracy, we choose not to consider this metric for evaluation. We believe that for the task of NL-to-SQL, models should be able to predict and return the correct SQL queries even if there is no data in the database in order to be totally independent of the execution of the generated queries for a question-answer concept.
Unlike Spider where the value prediction is not included in the task definition, we add in GreatSQL a start and end index of each value present in the NL sentences to allow models to make values prediction; hence for the future models which will be trained on GreatSQL, values prediction challenge is taken on consideration in the dataset.
Result
To measure the performance of SQLSketch, we evaluate the result against two of the state-of-the-art models using the new GreatSQL dataset; we took the models on the task of NL-to-SQL and evaluate their outputs using the two previously mentioned metrics. We choose two types of models, a sequence to sequence architecture model (Seq2Seq) and a partial-sketch-based one (SQLNet). Since the two models are dedicated to a simple task like WIKISQL, we have made an adaption to make them follow the structure of our ground truth. The Table 5 shows the performance of SQLSketch and the two baselines when trained and tested with GreatSQL.
The performance of models on GreatSQL on the Test set. The metrics CM and EM are respectively Component Matching and Exact Matching
The performance of models on GreatSQL on the Test set. The metrics CM and EM are respectively Component Matching and Exact Matching
We notice that the performance of Seq2Seq is very low when tested with the GreatSQL. The Component Matching (CM) gives in general better result than the Exact Matching (EM) as we have already explained in Section 5. The SQLNet could predict more items. About 40% of SELECT columns with their aggregation are predicted correctly as well as the order by clause, but on the other hand, the model suffers for generating the items of the WHERE clause since many of them contains sub-queries with different depth. Also the exact matching score is very low. In both cases the two models fail to predict HAVING clauses correctly.
We notice that for the two baseline models when tested with WIKISQL performed well and yield better result but when exposed to GreatSQL they fail to accomplish the task and didn’t exceed at least the threshold of 50%. When analyzing the performances we conclude that the previously published datasets were made in an unbalanced way. This might include (but not limited to): having more easy pairs that the hard ones, a big number of duplicated SQL queries, simple database schemas that contains small tables and that don’t cover common data types or even when the SQL queries are repetitive and have easy structures.
Using an advanced sketch-based model that fully decouples operations of the clauses of the target SQL query, without including any sequence-to-sequence decoding, leads to more independence between items and helps enhancing the quality of outputs. This can be understood since the errors are not propagated to other slots and stay within each component.
Regarding the performance of our model, the SQLSketch outperforms the previous best baseline model, SQLNet by 13% of net improvement and achieves 23.9% of score on the GreatSQL dataset. This achievement is mainly related to the structure of the model that adopts a filling sketch approach rather than making a sequential prediction of the SQL query. Our sketch-based model supports the advanced and the most popular SQL commands and provides better outcome when compared to other partial models results as it is illustrated in the Table 5.
Conclusion
We present in this paper the SQLSketch a sketch-based network for generating SQL queries to address the problem of automatically translate Natural Language sentences to SQL Queries. The model is evaluated on GreatSQL, a new balanced, large-scale and cross-domain dataset for natural language to SQL translation task. The experimental result shows that SQLSketch outperforms the two chosen baseline NL-to-SQL models when tested on the GreatSQL due to the use of a fully independent sketch-based approach.
Footnotes
Acknowledgment
We thank Sara Slila and the other anonymous annotator for their help and work in creating the GreatSQL dataset. We also thank all people near or far who provided feedback and participated in the promising discussions.
Kraggle, data.world, databaseanswers
In the train and Dev sets of Spider. The test set is not publicly available