
Abstract
Recently, deep learning methods have been applied to deal with the opinion target extraction (OTE) task with fruitful achievements. On the other hand, since the features captured by the embedding layer can make a multiple-perspective analysis from a sentence, an embedding layer that can grasp the high-level semantics of the sentences is of essence for processing the OTE task and can improve the performance of model into a more efficient manner. However, most of the existing studies focused on the network structure rather than the significant embedded layer, which may be the fundamental reason for the problem of relatively poor performance in this field, not mention the Chinese extraction model. To compensate these shortcomings, this paper proposes a model using multiple effective features and Bidirectional Encoder Representations from Transformers (BERT) on the architecture of Bidirectional Long Short-Term Memory (BiLSTM) and Conditional Random Field (CRF) for Chinese opinion target extraction task, namely MF-COTE, which can construct features from different perspectives to capture the context and local features of the sentences. Besides, to handle the difficult case of multiple nouns in one sentence, we innovatively propose noting words feature to regulate the model emphasize on the noun near the transition or contrast word, thus leading a better opinion target location. Moreover, to demonstrate the superiorities of the proposed model, extensive comparison experiments are systematically conducted compared with other existing state-of-the-art methods, with the F1-score of 90.76%, 92.10%, 89.63% on the Baidu, the Dianping, and the Mafengwo dataset, respectively.
Introduction
With the rapid development and prevalence of network technology, the internet users generate a huge amount of data each day. How to extract valuable information from massive textual data has become increasingly important. Opinion mining has drawn increasing attention both in academic and engineering domains recently. Since it can dig out valuable information from user-generated comments and analyze the public opinions on a specific topic, and even help to detect threat actions [1] and network bad behavior [2]. Thus, it is of vital value not only to the users and businesses but also to the analyses of network public opinion. Especially, the opinion target extraction (OTE) is the key task of opinion mining, which aims to mine the opinion targets explicitly mentioned in sentences. The following shows some examples of OTE task and the opinion targets are underlined in the sentence.
(1)  (The scenery of
(The scenery of
(2)  (Highly recommend
(Highly recommend
The traditional methods of opinion target extraction or aspects term extraction include the supervised learning method, unsupervised learning method, and semi-supervised learning method. The primary research method of supervised learning method is conditional random field (CRF) [3–7]. Nevertheless, the drawback of the supervised learning method is that a large amount of manual labeling is required. Meanwhile, there are inherent limitations for this kind of method in some specific field. The common ways of unsupervised learning methods are based on the dependency parser by pre-setting rules and dictionary [8–13]. However, this approach dramatically depends on the quality and domain of the dictionary, which may generate a high error rate in complex sentences. On the other hand, the semi-supervised learning methods are to add the corresponding seed words or prior domain knowledge based on Latent Dirichlet Allocation (LDA) [14, 15], utilizing local annotation to complete the global mining of opinion targets. Nonetheless, the remarkable dependence on the data fields just as the unsupervised learning methods possess is indeed existing, which has been the bottleneck for its further applications.
Recently, different from the conventional extracting methods, an outstanding substitution, namely deep learning, has been applied to fulfill the OTE task with a range of excellent achievements [16–22]. Poria et al. [16] proposed a model based on a seven-layer deep convolutional network to train sentences and extract opinion targets. Wang et al. [23] used a multilayer attention network to extract aspect items and opinion items. Li et al. [24] used the BiLSTM layer to model the context information of each character, where the hidden states of the BiLSTM layers are fed into the CRF layer to optimize sequence tagging. Moreover, they added dictionary information to improve model performance, which showed good results on the real consumer review dataset. Particularly, the BiLSTM-CRF model has shown admirable performance for dealing with the OTE task. The BiLSTM layer can effectively capture the direction information and local features of sentences, while the CRF layer can learn the dependencies between tags.
Although neural networks play an essential role in OTE task, the embedding layer is the basis for all network structures. Since the embedding layer can convert high-dimensional sparse data into low-dimensional dense continuous vectors and grasp the high-level semantics of the sentences, thus the neural network can capture useful information in the sequences more effectively. Previous studies have indicated that the quality of the embeddings determines the effectiveness of the subsequent network layer when decoding useful information [17]. However, most of the existing studies focused on the network structure [16, 26] rather than the significant embedded layers, which may be the bottleneck for its further improvement, especially in Chinese OTE task. Since Chinese grammar is more complex than English, which needs more context semantic analysis. For example, turning words and contrast words in Chinese sentences may interfere with the extraction of opinion targets.
To remedy the drawbacks of the existing approaches, a Chinese opinion target extraction model based on multiple effective features is proposed in this paper, which demonstrates excellent performance on three Chinese datasets. The architecture of the proposed model is based on the BiLSTM-CRF. We use Bidirectional Encoder Representation from Transformers (BERT) to extract automated text features, and then use BiLSTM to preliminarily determine the position of the opinion target. To make the extraction of the model more accurate, we used three manual features (POS tagging, syntactic dependency, and noting words) to make the model consider the semantics of the sentence from different perspectives, thereby revising the results obtained by the first BiLSTM layer. Hence, after passing through the BiLSTM layer, automated features combining three manual features are fed into BiLSTM-CRF model. With the assistance of the three effective features, the OTE model could better handle complex sentences such as transition sentences and contrast sentences, and improve the ability to solve semantically complex sentences. Thereby improving the performance of the OTE model. The contributions of this work are presented as follows: We construct a new embedded layer structure, which combines automated features and multiple manual features. The rich embedded layer not only enables the model to obtain excellent word vectors generated by BERT, but also has the morphology, syntax, and keyword attention capabilities similar to human experience. We propose the noting words feature, which enables the model to notice the crucial words near the suspected opinion target, such as turning words and comparison words. Noting words feature could help the model better locate the correct opinion target from multiple nouns. To the best of our knowledge, the proposed method can reach the most superior effectiveness compared with the state-of-the-art literatures with the F1-score of 90.76%, 92.10%, and 89.63% on the Baidu, Dianping, and Mafengwo dataset, respectively. We innovatively assign features of words to each Chinese character, and make each character have a boundary according to the corresponding word, so that irrelevant characters will not interfere with each other.
The remainder of the paper is organized as follows: Section 2 introduces BERT, BiLSTM, CRF, Highway network and gives a short literature review on opinion target extraction. The proposed model and the detail of significant features are introduced in Section 3. In Section 4, we conduct comparison and ablation experiments to demonstrate the effectiveness of the proposed model and the three features. Finally, we conclude this paper in Section 5.
Preliminaries and related work
Preliminaries
Bidirectional encoder representations from transformers
BERT [27] is a natural language processing pre-training language model, which can calculate the relationship between words, and use the calculated relationship weight to extract important features in the text. The self-attention mechanism is used by BERT for training, which is based on all layers combining the context of the left and right sides to train the deep two-way representation. Comparing with the previous pre-training model, it captures the real context information and can learn the relationship between consecutive text segments. Essentially, it learns a good feature representation for words by running a self-supervised learning method on the basis of a massive corpus.
Bi-directional long short-term memory
BiLSTM uses forward LSTM [28] and backward LSTM to captures past and future information of the sentence, and then concatenates the two-direction hidden states to be the representation of each word. LSTM is composed of input word x
t
, cell state C
t
, temporary cell state
calculate forget gate:
calculate memory gate:
calculate the cell state at the current time:
calculate the output gate and the hidden state at the current time:
CRF [29] is a conditional probability distribution model, which can consider any aspect of the evaluated object and does not need conditional independent assumption, thus making CRF widely used in traditional information extraction tasks, such as part-of-speech tagging, named entity recognition, and so on. For a given observation sequence X, CRF calculate the probability value of each label sequence Y, and the probability P (Y|X) is expressed as:
In this study, k represents the kth transition feature, l represents the lth state feature, i represents the index of the character; yi-1 is the label of the i - 1th character, y i is the label of the ith character, and x i is the ith character. Moreover, t k represents the transition features function, measuring the score from tag yi-1 to tag y i ; s l is the state characteristic function, measuring the probability of x i to y i ; λ k and μ l are the weight coefficients of t k and s l , respectively.
Highway network [30] allows information to pass through the layers of deep neural network with high speed and without obstacles, which effectively slows down the vanishing gradient problem. In highway network, two non-linear transforms T and C are introduced, where T is the Transform Gate and C is the Carry Gate, and T = sigmoid (Wx + b).
T and C are used to control the ratio between x and H. W H , W T , and W C are the weight matrices of H, T, and C, respectively. In order to simplify, setting C = 1 - T yields:
When T = 0, y = x, all the original input is retained, and we pass the input as output directly, thus realizing the highway of information. When T = 1, y = H, the original input is converted without retaining, and the non-linear activated transformation is used as the output, which is equivalent to an ordinary neural network.
The early methods of opinion target extraction or aspects term extraction include supervised methods, unsupervised methods, and semi-supervised methods. Traditionally, the supervised methods use CRF [4–6]. To further improve the performance, Zhang et al. [3] integrate word features and domain dictionary on the basis of CRF. Xu et al. [7] introduce linguistic features and heuristics location features to form a cross-domain model. Although the supervised method has high precision, it has strong domain limitations and a large amount of manual labeling is required. The unsupervised method includes syntactic rules-based extraction [8–10], rule-based method [11, 12], domain dictionary method [13]. Most unsupervised methods do not need much human effort but need to create the rule template in advance, which involves too much manual intervention and its flexibility is insufficient. In order to avoid these shortcomings, a compromise is to introduce semi-supervised method [14, 31], which mainly uses topic modeling. Wang et al. [14] proposed to add seed vocabulary to the LDA model. By using the seed vocabulary of aspect to guide the extraction of aspect terms from comments, manual intervention can be reduced and the extracted aspects can be more human-comprehensible. Shams et al. [15] incorporate co-occurrence relations as prior domain knowledge into the LDA model to extract more precise aspects.
Recently, deep learning has been applied to OTE task, which can extract high-quality features automatically and achieve a range of excellent achievements [16–22]. Liu et al. [18] introduce recurrent neural networks (RNNs) and word embeddings to improve the discriminative ability of the opinion target extraction model without any task-specific feature engineering effort. Jebbara et al. [19] investigate whether character-level models can improve the performance for OTE task and prove that character-level information is effective in OTE task. Poria et al. [16] use Convolutional Neural Network(CNN) with linguistic rules to extract opinion target. Xu et al. [17] propose a novel and simple CNN model with general embeddings and domain embeddings, which outperforms state-of-the-art sophisticated existing methods. Liu et al. [20] develop BiLSTM-CRF framework being empowered with word-level knowledge and character-level knowledge by leveraging the language model. Comparing to previous methods, this framework is more concise and effective. Li and Lam [21] use two LSTMs with memory interaction to extract aspect and opinion terms. They combine sentiment lexicon with high precision dependency rules to generate opinion terms more accurately.
Especially, for Chinese OTE task, machine learning methods are used to extract opinion target from Chinese hotel user reviews by choosing the optimal dimension, representation of features, and maximum entropy [32]. Li et al. [24] introduce two features for each character by distributing part-of-speech(POS) tag feature and using template over dictionary and contexts. They further develop a character-based BiLSTM-CRF model with the POS feature and dictionary feature of each character. This model has been applied to Chinese datasets and achieved good performance. Yang et al. [33] explore a multi-task model, namely LCF-ATEPC, which consists of aspect term extraction and aspect polarity classification. The model adopts the domain-adapted BERT and three implementations of the local context focus mechanism to achieve state-of-the-art performance on both English and Chinese datasets.
Overall, most of the existing studies ignored the significant embedded layers, especially for the Chinese character-level embedded layers. Therefore, our work differs from the related work by focusing on significant embedded layer rather than neural network structure. With the assistance of the proposed three features of embedded layer, the performance of OTE model is improved effectively. In addition, there are only a few works mentioned or explored the Chinese opinion target extraction, so we propose a model that can handle Chinese datasets and achieve state-of-the-art results.
Overview of the proposed model
Task definition
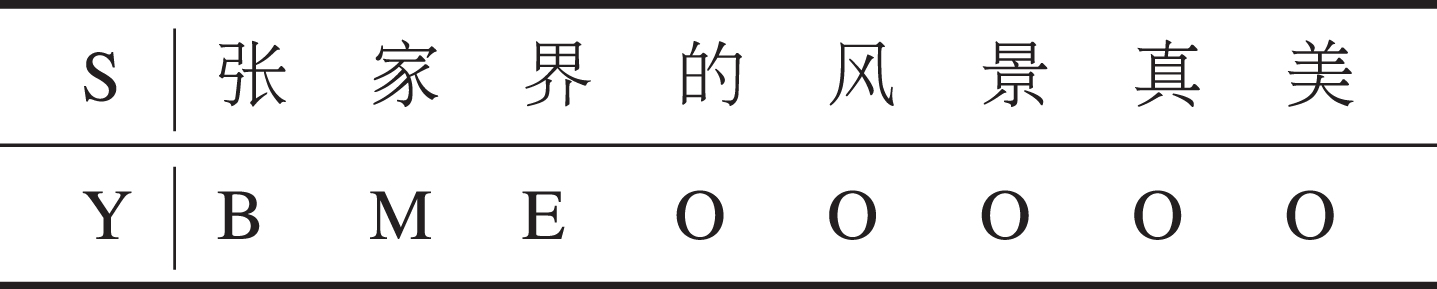
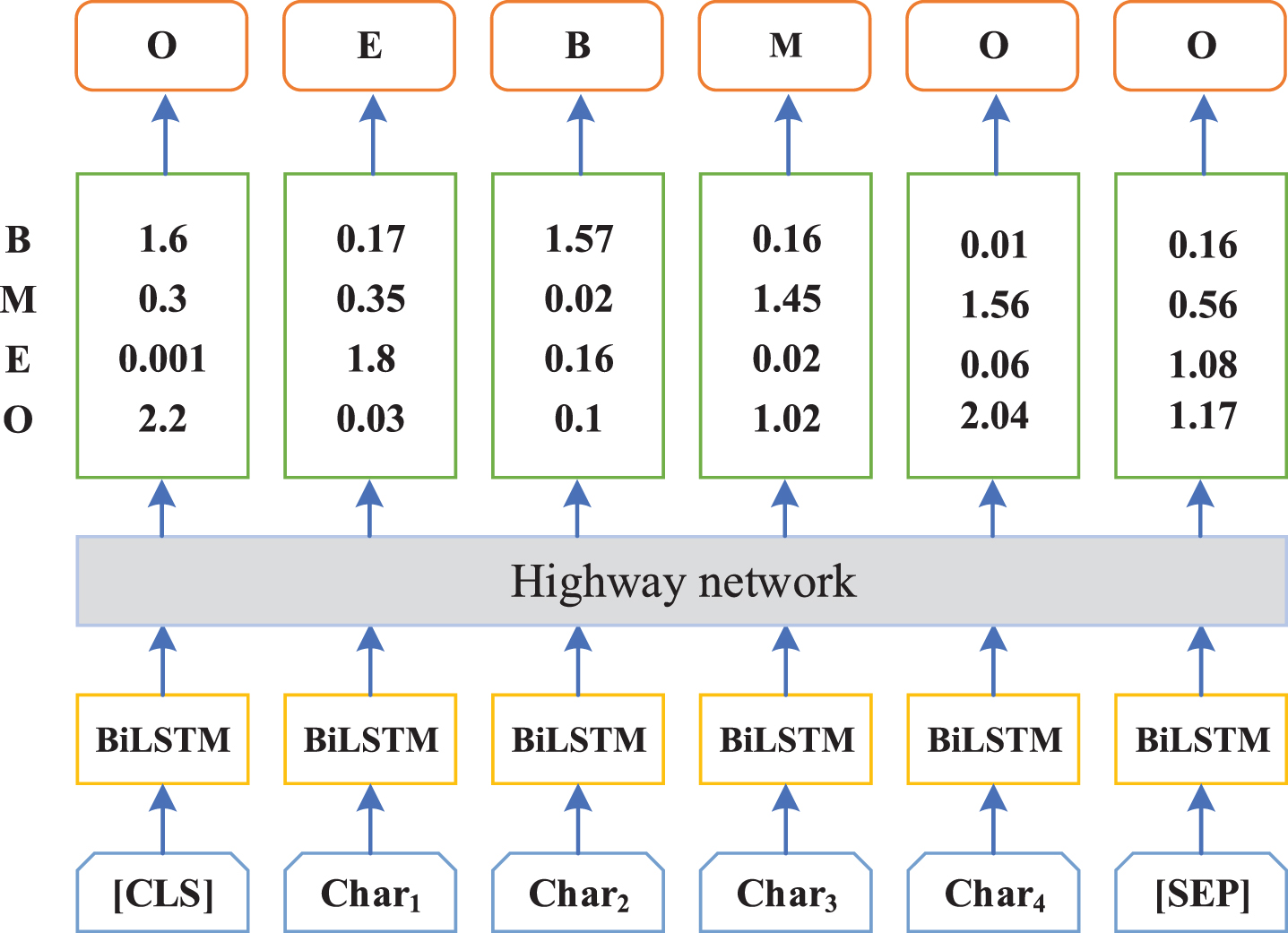
We formulate opinion targets extraction task as a sequence labeling problem with a tagging scheme: y = {B, M, E, O}. Tokens in the sentence are tagged depending on whether they are at the beginning (B), middle (M), end (E), and the outside (O) of the opinion target. For a given sentence S = {c1, c2, . . . , c n } covering n Chinese characters, our goal is to predict the tag sequence Y = {y1, y2, . . . , y n }, where y i ∈ y and i is the index of the characters from 1 to n.
As shown in the Table 1, “ (Zhangjiajie)” is the opinion target in this sentence, so the Chinese characters “
(Zhangjiajie)” is the opinion target in this sentence, so the Chinese characters “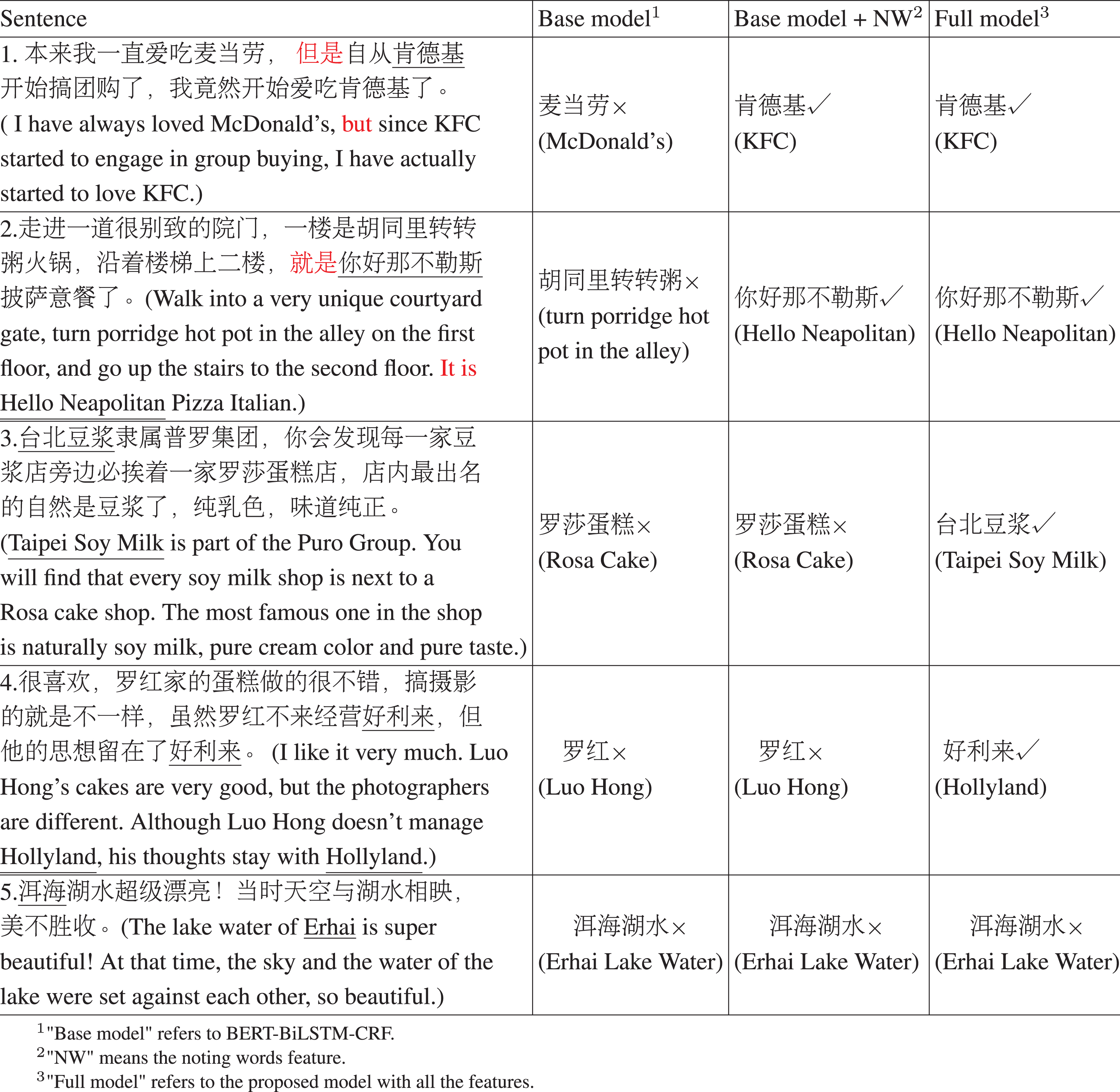 (Zhang)”, “
(Zhang)”, “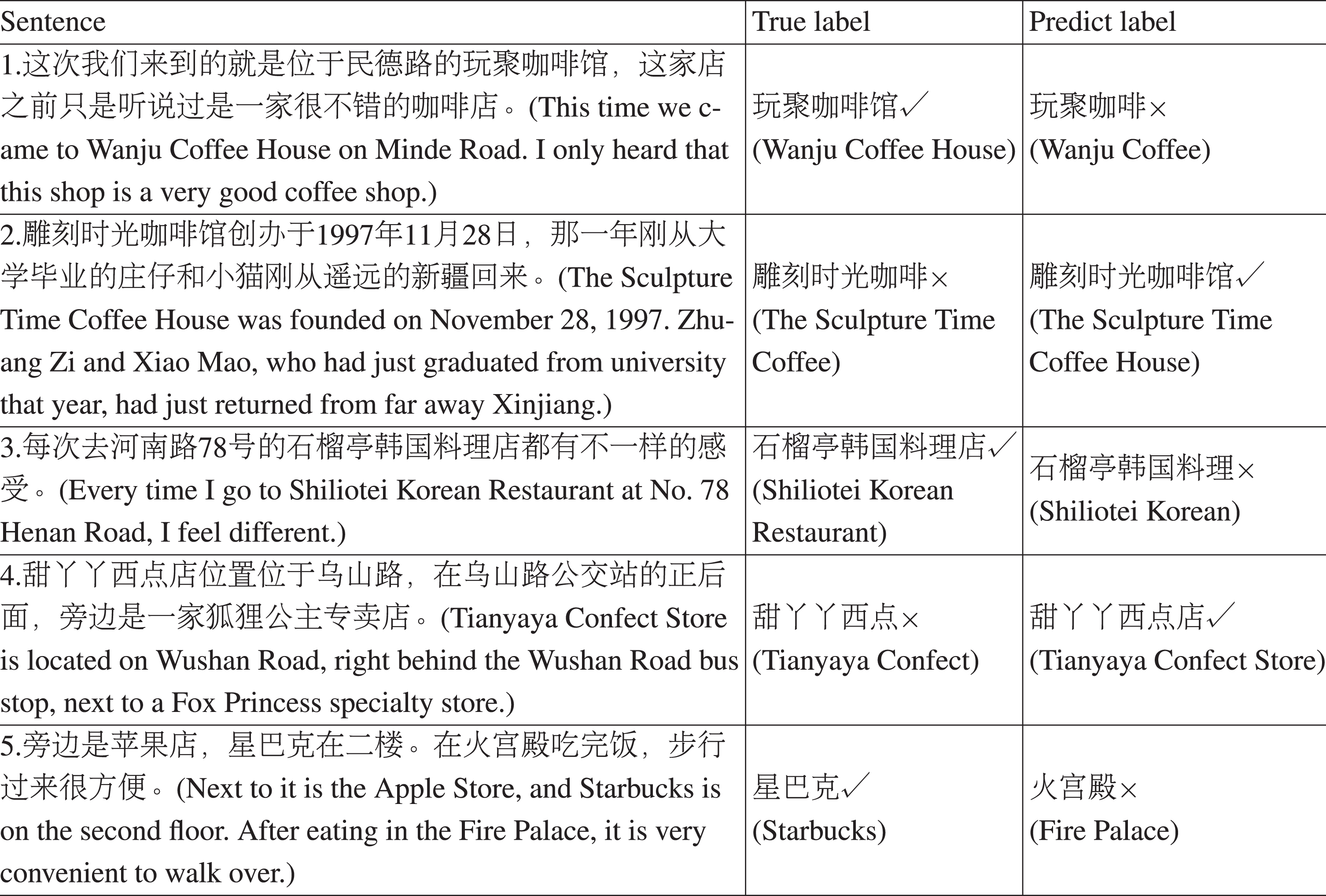 (jia)”, “
(jia)”, “ (jie)” are labeled as B, M, E, respectively. The other characters are labeld as O.
(jie)” are labeled as B, M, E, respectively. The other characters are labeld as O.
An example of the tagging scheme
An example of the tagging scheme
As shown in Fig. 1, each Chinese character is taken as the input of BERT with extra tokens at the start ([CLS]) and end ([SEP]) of the tokenized sentence. Each Chinese character passes through a token embedding layer of BERT so that each Chinese character is transformed into a vector represent. Then we feed them into BiLSTM, which can weaken the weights of unimportant words and strengthens the distribution of weights to the words that seem to be opinion target according to the backpropagation of loss. Since the number of parameters of BERT is numerous, if we do not freeze the parameters, huge computing resources are required. However, we found that adding a BiLSTM layer after BERT could further learn the potential relationship between each character and preliminarily determine the location of the opinion target, so we freeze the parameters of BERT.

Architecture of the proposed model. “Char i ” refers to the ith Chinese character.
Subsequently, we obtain the part-of-speech of each word and the dependency relationship between each word and other related words, and assign them to each character in the word, namely part-of-speech feature and syntactic dependency feature. Then check whether there are noting words near each noun, and add noting word features to each character. The details of these three features are described in Section 3.5, 3.6, and 3.7. The output of BiLSTM combined with these three features are passed through the upper BiLSTM to capture the information of different aspects of the sentence. With the assistance of these three features, the output of the upper BiLSTM has been further revised. Then we use CRF as the output layer of the upper BiLSTM, which considers the order of output tags and learns the dependency relationship between tags. In addition, each BiLSTM layer is followed by a highway networks, which can alleviate the vanishing gradient problem caused by the multi-layer neural network and furnish a fast convergence rate to feedback.
As shown in Fig. 2, the combined vector passes through the forward LSTM and backward LSTM to obtain the future and past information by concatenating forward hidden layer states (
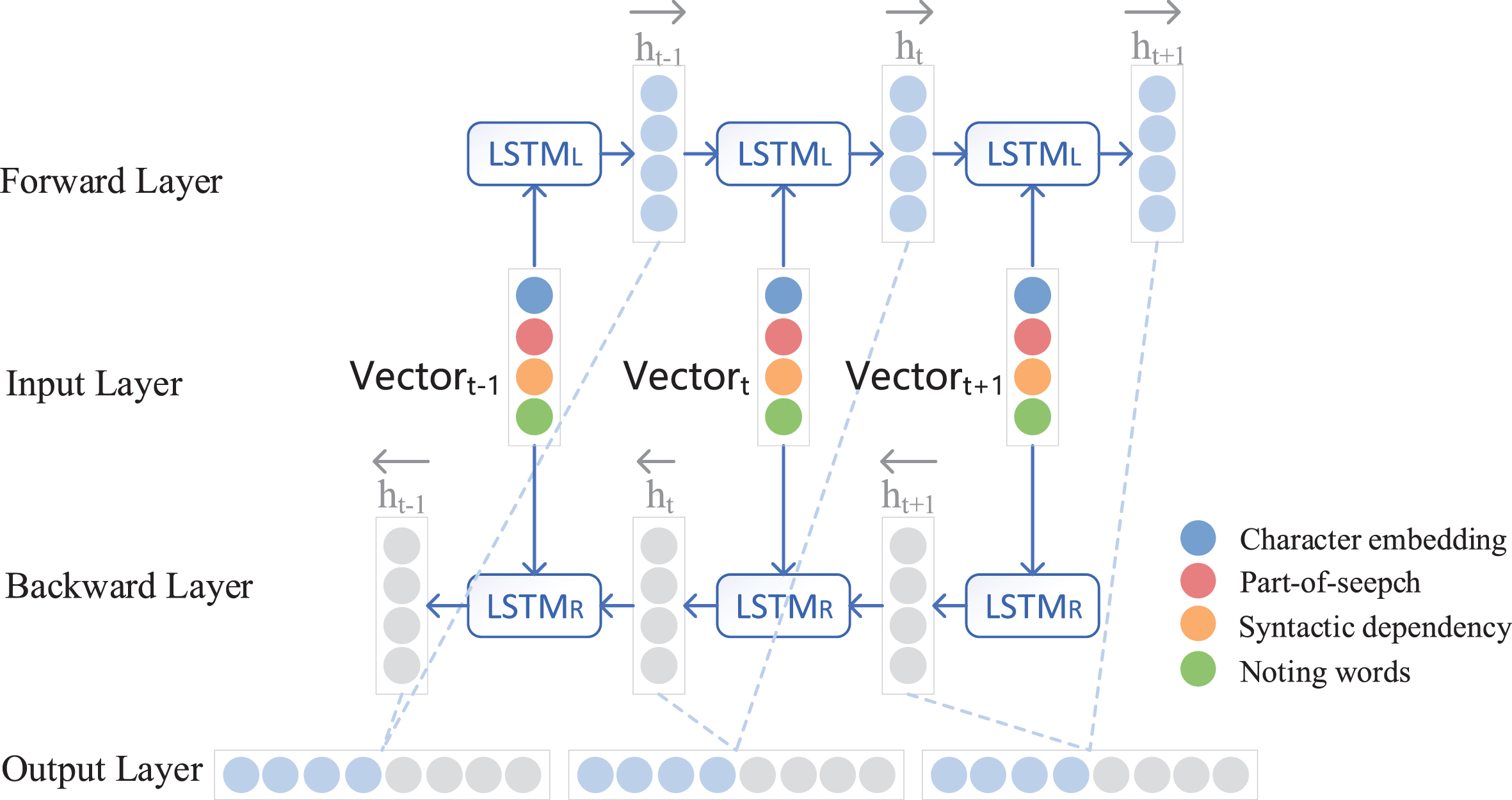
Structure diagram of BiLSTM in the proposed model.
Hence, the output of BiLSTM layer is the score of each predicted tag. As shown in Fig. 3, for character “Char1”, the output of BiLSTM layer is 0.17 (B), 0.35 (M), 1.8 (E), 0.03 (O). We can choose the one with the highest score as the label of the character. But there is no guarantee that the tag sequence is always predicted correctly. For example in Fig. 3, the tag sequence is {E, B, M, O}, which is obviously wrong. Therefore, we need to use CRF to add some constraints to the predicted tags to ensure that the predicted labels are legal, while these constraints can be learned automatically by CRF layer in the training process. Therefore, we take the output of BiLSTM as the state characteristic matrix of CRF.
Error case of label sequence predicted by BiLSTM.
For a given sentence X ={ x1, x2, …, x
n
} with n characters, the output of the BiLSTM is H ={ h1, h2, …, h
n
}. H is mapped to matrix E through softmax layer and as the state characteristic matrix of CRF. The probability formula for the label sequence Y ={ y1, y2, …, y
n
} predicted by CRF is:
T in formula 12 is the transition characteristic function, which measures the transition probability from tag yi-1 to tag y i ; and E is the state characteristic function, which represents the non-normalized probability of the word x i mapped to y i .
After on, we use the maximum likelihood estimation and take the opposite of log P (y ∣ X) and use gradient descent algorithm to minimize its opposite number, to find the globally optimal annotation sequence. As shown in formula 13:
In addition, BiLSTM is followed by highway network to alleviate the vanishing gradient problem and make convergence rate much faster.
In the previous research on OTE task, the off-the-shelf word embedding matrices such as word2vec or Glove is usually adopted, but these word embedding matrices are usually based on words to generate the corresponding vector rather than characters. However, the smallest language unit of Chinese is character instead of word, so it is not suitable to use word-based word embedding matrices. Different from the word-based embedding technology, the BERT for Chinese happens to generate a vector for each character, so we use BERT as our word embedding method.
For Chinese text, the input of BERT is a single Chinese character. Additionally, extra tokens are added at the start ([CLS]) and end ([SEP]) of the tokenized sentence. Each Chinese character passes through a token embedding layer so that each Chinese character is transformed into a vector represent. BERT takes the sum of the token embeddings, segment embeddings, and position embeddings as the input. This input representation is passed to the multi-layer Transformer to get the model output. This method naturally makes good use of context, so that it can solve the phenomenon of polysemy, and can also deal with the complex characteristics of word syntax and semantics, which is helpful to the extraction of opinion target.
We use BiLSTM as the output layer of BERT, which can use the backpropagation of the CRF loss to assign different weights to each character, thereby highlighting the words that seem to be the opinion targets and weakening other unimportant words. Therefore, after the tokens passed through the BERT and BiLSTM, we can not only obtain excellent word vectors but also preliminarily predict the location of opinion targets. Due to the numerous number of the BERT’s parameters that needs huge computing resources, and adding a layer of BiLSTM after BERT is a simple and effective alternative method, we freeze all the parameters of BERT.
Part-of-speech
Part-of-speech (POS) is a category of words that have similar grammatical properties. Although neural networks can extract information from multiple aspects of a word, if a word has been marked with part of speech, then it can provide more accurate information. Generally speaking, opinion targets are single nouns or nouns composed of verbs, so the introduction of part-of-speech is of importance in the opinion target extraction task.
We use Lexical Analysis of Chinese (LAC) [34] provided by Baidu to make part-of-speech tagging, which has 24 parts of speech and provides the functions of word segmentation and POS tagging. However, since POS tagging is usually associated with words rather than characters, we introduce the sequential tagging method, in which B, M, E represent the beginning, the middle, and the end of a word, respectively. Thus the POS feature is assigned to each character. For example in Table 2, “ ”(“The scenery of Zhangjiajie is really beautiful”). Combined with the sequence labeling scheme (i.e., B, M, and E), 72 POS tags are formed, such as “B_n”, “M_v”. The letter in front of the underline represents the beginning (B), middle (M), or end (E) of the current word, while the letter after the underline represents the part-of-speech. Besides, unknown token “<unk> ” and padding token “<pad> ” are added to the tag form, so that there are 74 kinds of POS tags. We use 7-bit one-hot vectors to represent all the POS features.
”(“The scenery of Zhangjiajie is really beautiful”). Combined with the sequence labeling scheme (i.e., B, M, and E), 72 POS tags are formed, such as “B_n”, “M_v”. The letter in front of the underline represents the beginning (B), middle (M), or end (E) of the current word, while the letter after the underline represents the part-of-speech. Besides, unknown token “<unk> ” and padding token “<pad> ” are added to the tag form, so that there are 74 kinds of POS tags. We use 7-bit one-hot vectors to represent all the POS features.
An example of POS feature of a sentence
An example of POS feature of a sentence

Syntactic dependency is a relation between two words in a sentence with one word being the governor and the other being the dependent of the relation. [35, 36]. Text data is context-dependent, especially in long sentences or sentences with pronouns. Therefore, the syntactic dependency is introduced to enable the model to consider the semantic relationship between words for non-adjacent in the sentence, thereby improving the performance of the OTE task in complex situations.
We acquire the syntactic dependency attribute of the target sequence by DDparser [37] tool, which contains 14 labeling relationships, such as subject-predicate relationship (SBV), verb-object relationship (VOB), or prepositional relationship (POB). Besides, it can also give the index of the dependent. We introduce these two features, one for the dependency relationship between the governor and dependent, and the other for the index of the dependent, which are called “Relationship” and “Target index”, respectively. For “Relationship”, the sequence labeling method is introduced to assign the syntactic dependency feature of each word to each corresponding word. Combined with the sequence labeling scheme (i.e., B, M, and E), that is, 14 (the number of relationship tags) times 3 (the number of sequence labeling tags), 42 kinds of syntactic dependency tags are formed, such as “B_SBV”, “M_VOB”. The same as POS feature, unknown token “<unk> ” and padding token “<pad> ” are added to the tag form, so that there are 44 kinds of syntactic dependency tags. We use 6-bit one-hot vector to represent all syntactic dependency feature. In addition, for the “Target index”, we assign this index value to every Chinese character in the word. For example in Table 3, the index of the word ‘ (scenery)” is 3 (since it is the third word in this sentence), which has “ATT” relationship with “
(scenery)” is 3 (since it is the third word in this sentence), which has “ATT” relationship with “ (Zhangjiajie)”. So the “Target index” of each Chinese character in the word “
(Zhangjiajie)”. So the “Target index” of each Chinese character in the word “ (Zhangjiajie)” is set to 3.
(Zhangjiajie)” is set to 3.
An example of syntactic dependency feature of a sentence
An example of syntactic dependency feature of a sentence
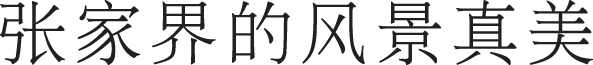
Although the model with part-of-speech feature and syntactic dependency feature has achieved good performance in the OTE task, the proposed model still makes mistakes in some difficult cases with multiple nouns. For example, “ ,
,  (I like Huangshan better than Huashan.)” In this sentence, both “
(I like Huangshan better than Huashan.)” In this sentence, both “ (Huashan Mountain)” and “
(Huashan Mountain)” and “ (Huangshan Mountain)” are nouns. This case may confuse the model, which one is the true opinion target. Evidently, paying attention to the words "
(Huangshan Mountain)” are nouns. This case may confuse the model, which one is the true opinion target. Evidently, paying attention to the words " ”(compare)”, "
”(compare)”, " (more)” in the sentence can help the model accurately capture the opinion target.
(more)” in the sentence can help the model accurately capture the opinion target.
We notice that there are many tendentious or transition words in opinion sentences, especially in comparative sentences and turning sentences. These words usually appear near the opinion target, or the other nouns that are easily confused with the true opinion target words. When humans read sentences, they usually pay attention to these words. Therefore, in order to make the model imitate this ability of human beings, we collected more than 40 words with transition, comparison, or affirmation that need special attention in the model, which are called noting words. For example: " (but)”, "
(but)”, "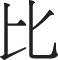 (compare)”, "
(compare)”, " (that is)”, and so on. Besides, the words that may be opinion target are called candidate words. The proposed model looks for the presence of noting words near each candidate in the sentence. If so,make the model emphasize on the candidate words.
(that is)”, and so on. Besides, the words that may be opinion target are called candidate words. The proposed model looks for the presence of noting words near each candidate in the sentence. If so,make the model emphasize on the candidate words.
The specific steps are as follows. First, we filter out nouns, gerunds, organization names, and other types of nouns in the sentence, which are called candidate words. Since our model is based on character level, we call each character in candidate words candidate character. We set a window to capture the context of nouns and judge whether the text in the window contains noting words. After experiments, we found that setting the window size to 4 characters can achieve the best performance. Hence, for each candidate word, we set up 9-bit one-hot vector to represent the noting words feature. The first bit uses 1, 2, and 3 to indicate whether noting words are before, inside, or behind the candidate word. If the noting words appear in the window before the candidate word, the corresponding position of noting words in the prior four digits is set to 1, with remains being 0. On the contrary, if the noting words appear in the window behind the candidate word, the corresponding position of noting words in the posterior four digits is set to 1, with remains being 0. Besides, if the noting words exist inside of the candidate word, then the first bit is set to 2 with the other eight bits being 0, since it doesn’t make sense. For example in Fig. 4.

An example for noting words feature.
We conduct comparison experiments with other existing representative methods and show the result of ablation study. With integrated analyses and case analyses, we show how the proposed model outperforms the state-of-the-art methods and handles some hard cases.
Datasets and evaluation
The proposed model is evaluated on three benchmark datasets 1 , which are shown in Table 4. The Baidu dataset is derived from big data competition held in 2016, which aims to extract opinion targets from consumer reviews. They provide 12000 sentences with annotation of opinion targets including movies, characters, songs, and other fields. The Dianping dataset is constructed by crawling China’s leading local life services platform and modifying data manually, which contains the evaluation on the scenic spots. The same as Dianping dataset, Mafengwo dataset is constructed by collecting consumer reviews from Mafengwo, which is China’s largest travel sharing website, with organizing data via manual handling.
Statistics of the datasets
Statistics of the datasets
Following the existing literature [17, 33], we adopt precision, recall, and F1-score metrics based on the exact match to evaluate the performance of each method. That is to say, the opinion target is deemed to be correct only if the output perfectly matches the golden standard.
BERT transforms each Chinese character into a 768-dimensional vector representation, which fine-tuned by single-layered BiLSTM to produce more accurate character vector. For the maximum input sequence length of BERT is limited to 512, with "[CLS]” and "[SEP]” need to be added at the beginning and end of each sentence. We fill sentences less than 510 with "[PAD]” to 510 words and take the first 510 words for sentences longer than 510. We utilize LAC [34] for word segmentation and POS tagging. And we construct syntactic dependency feature by using DDparser [37].
We use two single-layered BiLSTM. The lower one is used to preliminarily determine the position of the opinion target. The upper one is a part of the neural network structure. The dimension of each BiLSTM cell is set to 200. Besides, each BiLSTM layer is followed by highway network to alleviate the vanishing gradient problem. Dropout is applied on the output layer of highway with probability 0.5 to avoid over-fitting. We update the parameters of the proposed model by backpropagation using RMSprop optimizer with initial learning rate 0.001 and batch size 128.
To verify the effectiveness of the embedded layer structure, we respectively tried other two typical neural networks, i.e., CNN and RNN, as the upper structure of the model. The CNN kernel size is set to 3, and the channel number is set to 128. The dimension of each RNN cell is set to 200. In order to distinguish them from MF-COTE, we call them MF-based-CNN and MF-based-RNN respectively.
Compared models
We compare our model with the following methods: BERT-CRF: CRF is a classic algorithm of Named Entity Recognition (NER), and it is also widely used in OTE task [38]. To make the comparison fair, we adopt BERT as the pre-trained word embeddings. BERT-RNN-CRF: RNN is a kind of neural network structure that can automatically learn latent features from sentences and be applied to OTE task to extract opinion expressions [18]. To be fair, we use BERT as the pre-trained word embeddings. DE-CNN [17]: The Dual Embeddings CNN (DE-CNN) model armed with general embeddings and domain-specific embeddings, using simple and parallelized Convolutional Neural Network (CNN) model to achieve competitive performance. LM-LSTM-CRF [20]: LM-LSTM-CRF model combine word-level features and character-level features to conduct more efficient training. C-BiLSTM-CRF [24]: This OTE framework is a character-based BiLSTM-CRF model incorporating part-of-speech and dictionary features. While the domain dictionary is got from the corresponding Internet platform, which contains nouns that appear on the platform. Since the researcher did not name this model, we call this model C-BiLSTM-CRF. LCF-ATEPC-{CDM, CDW, Fusion}: LCF-ATEPC is a multi-task model, which consists of aspect term extraction and aspect polarity classification. The model adopts the domain-adapted BERT model to produce the word embedding vectors. Besides, LCF-ATEPC model has three implementations of the local context focus mechanism, namely CDM, CDW, and fusion. We rerun their code on our datasets and conducted experiments on the three implementations of LCF-ATEPC model.
Main results and analyses
The compare results of different methods are presented in Table 5. We completely follow the configuration of the code issued by the relevant papers and transplant the comparison model to our Chinese dataset. The experimental results indicate that the proposed model achieves the best precision, recall, and F1-score on all the datasets.
Experimental results of the OTE task. % is omitted, “Pre” means the precision, “Rec”‘ means the recall, “F1” means the f1-score
Experimental results of the OTE task. % is omitted, “Pre” means the precision, “Rec”‘ means the recall, “F1” means the f1-score
1“MF-based-CNN” refers to the model using CNN layer based on multiple features. 2“MF-based-RNN” refers to the model using RNN layer based on multiple features.
For traditional methods CRF and RNN, we use BERT as the word embedding method to make the comparison fair. We observe that the model being empowered with BERT and using only CRF has achieved a good performance. This result shows the effectiveness of applying BERT to OTE task.
C-BiLSTM-CRF is a model incorporating POS and dictionaries for Chinese opinion target extraction, which similar to ours. Compared to the precision of C-BiLSTM-CRF, our model achieves 6.1%, 7.2%, and 4.2% absolute gains on datasets Baidu, Dianping, and Mafengwo, respectively. Moreover, our model removes the dictionary information feature of C-BiLSTM-CRF. This dictionary feature notably improves the performance of model extraction by collecting existing nouns in a specific domain. Our model has made significant improvements even after removing the dictionary features. These observations demonstrate that our model is a generic model, which can achieve further improvement via domain dictionary.
LCF-ATEPC model is the state-of-the-art model, which uses BERT as the word embedding method and has three implementations of the local context focus mechanism. Although the three implementations of the model are all based on BERT and character-level as same as ours, our proposed model obtains about 1.8% ∼3.7% improvements in precision. This result indicates the necessity of the three features empowered to each character. Considering the model without POS feature, the feature that the majority of the opinion targets are nouns cannot be applied well. Moreover, the model cannot learn complex sentence patterns such as dependency and transition without syntactic dependency and noting words feature. That is why our model works better under the same conditions.
As mentioned above, the embedded layer has an essential role in OTE task, DE-CNN and LM-LSTM-CRF are exactly follow this rule and improve performance in this way. However, DE-CNN achieves the worst precision, recall, and F1-score in all the datasets. One reason is that DE-CNN is based on word-level English embedded layer, however, Chinese is vastly different from English, words are not simply separated by spaces but need word segmentation by segmentation tools. This illustrates that the smallest unit of Chinese is character rather than word and Chinese OTE task should be defined as a character-level sequence tagging task. Therefore, character-level based models such as LCF-ATEPC and our model have achieved good performance. Additionally, another model LM-LSTM-CRF that focuses on the embedding layer has achieved a good F1-score with 86.501%, 86.470%, and 86.343% in three datasets, respectively, since it combines word-level features and character-level features.
We respectively tried other two typical neural networks, i.e., CNN and RNN, as the upper structure of the model to verify the effectiveness of the embedded layer structure we proposed. From the experimental results, MF-based-RNN produced better results for precision on datasets Baidu and Dianping, but cannot perform better in terms of recall and F1-score on all three datasets. In general, MF-based-CNN and MF-based-RNN surpass the state-of-the-art models and are only inferior to MF-COTE. To make the results more convincing, we compare MF-based-RNN and BERT-RNN-CRF. The difference between them is only that MF-based-RNN uses the embedded layer structure we proposed, while BERT-RNN-CRF does not use it. However, compared with BERT-RNN-CRF, MF-based-RNN obtains about 2.8%, 10.9%, 7.2% improvements in F1-score on three datasets respectively. This result further proves that even on the basis of BERT, the embedding layer structure we proposed can indeed improve the performance of the model. Therefore, it can be seen that the embedded layer structure we proposed is effective, and BiLSTM-CRF as the neural network structure of our model is the best choice.
In summary, our model is based on character-level and empowers cleverly three word-level features to each character, which enrich the characteristics of the embedded layer. Moreover, we use BERT to produce excellent word embeddings. Combined with all the above, the proposed model has achieved the state-of-the-art performance on all the datasets compared with several representative works.
We conduct ablation experiments on the proposed model to verify the effectiveness of the proposed features and the corresponding results are shown in Table 6. The results given by the “Base model”, namely BERT-BiLSTM-CRF, are list in the first row. We notice that the “Base model” has a good performance, which demonstrates the superiority of BERT and BiLSTM-CRF in handling OTE task.
Results of the ablation experiment of the proposed model
Results of the ablation experiment of the proposed model
1“Base model” refers to BERT-BiLSTM-CRF. 2“POS” means the part-of-speech feature. 3“SD” means the syntactic dependency feature. 4“NW” means the noting words feature.
Table 6 shows significant improvement in terms of both precision and recall when the POS feature is used. Compared to “Base model”, “Base model + POS” achieves 1.5%, 0.6%, and 1.1% absolute gains of precision on three datasets. We consider that this is because the model has learned the part-of-speech of each word in the sequence, and thus extracts the opinion target more accurately, since the opinion targets are mostly composed of nouns or gerunds.
In addition, compared with “Base model + POS”, “Base model + POS + SD” has been further improved on dataset Baidu and Dianping and has a slight decline on dataset Mafengwo. To investigate the reason for this result, we statistic the average length and the maximum length of the sentences, as well as the average index and maximum index value of the opinion target in the three datasets. As shown in Table 7, the maximum length of the sentence in the Mafengwo dataset has reached 867, and the maximum index of the opinion target is 442, which is much higher than the other two datasets. In other words, lengthy sentences and too back position of opinion target in the sentence mean that the model needs to consider the context of a fairly long sequence, thus leading SD features more complicated and confusing.Therefore, we infer that too long sentences and too back position of opinion target are the main reasons of “Base model + POS + SD” hurts the performance on Mafengwo dataset.
Summary statistics for the datasets
1The maximum length of the sentence in each dataset. 2The average length of the sentence in each dataset. 3The maximum index of the opinion target in each dataset. 4The average index of the opinion target in each dataset.
To directly address the complicated cases such as transition sentence and contrast sentence, we innovatively propose the noting words feature and we are delighted to find that, “Base model + POS + SD + NW” obtains consistent and significant improvement of 0.46%, 0.89%, 0.84% in Baidu, Dianping, and Mafengwo datasets, respectively. This result illustrates the effectiveness of noting words. By focusing on the noting words in complex sentence, adding weight to the vicinity of noting words leads to a superior location for the opinion target.
In conclusion, the result indicates that these three features indeed improve the F1-score of the OTE task. With the assistance of the proposed three features, “Base model” possesses a continuous improvement with a new state-of-the-art efficacy.
To further validate the effectiveness of the noting word feature and two other features aforementioned from specific case perspective, we present some example in Table 8, which contains the extracted results of the “Base model” (BERT-BiLSTM-CRF), “Base model + NW”, and “Full model” (BERT-BiLSTM-CRF + POS + SD + NW). As observed in the first two sentences, the “Base model” fails to extract the right opinion target in the sentence with multiple nouns. For example, the first sentence mentions two nouns that seem to be opinion target, which are “ (KFC)” and “
(KFC)” and “ (McDonald’s)”. The “Base model” mistakenly takes “
(McDonald’s)”. The “Base model” mistakenly takes “ (McDonald’s)” as an opinion target. However, the “Base model + NW” and the “Full model” can correctly handle this case. We can draw the same conclusion from the second sentence. The first two sentences suggest that models empowered with noting words (NW) feature can handle confusing cases where there are multiple nouns and noting words in the sentence. With noting words “
(McDonald’s)” as an opinion target. However, the “Base model + NW” and the “Full model” can correctly handle this case. We can draw the same conclusion from the second sentence. The first two sentences suggest that models empowered with noting words (NW) feature can handle confusing cases where there are multiple nouns and noting words in the sentence. With noting words “ (but)”, “
(but)”, “ (namely)”, and “
(namely)”, and “ (still)”, model can better locate the opinion targets and extract opinion targets effectively.
(still)”, model can better locate the opinion targets and extract opinion targets effectively.
Several extract results for case analysis. There is an English translation of the sentence in brackets after each Chinese sentence. The true opinion targets are in underline and words in red colour are noting words. “√” represents the label is correct, “×” represents the label is wrong
Several extract results for case analysis. There is an English translation of the sentence in brackets after each Chinese sentence. The true opinion targets are in underline and words in red colour are noting words. “√” represents the label is correct, “×” represents the label is wrong

Although the noting words can guide the model to focus on the notable word near nouns, there is the possible scenario that only using the noting words feature cannot handle the complex sentences requiring semantic analysis, such as the third sentence and fourth sentence. In the third sentence, both “Base model” and “Base model + NW” mistakenly treat “ (Rosa Cake)” as opinion target. However, after adding part-of-speech feature and syntactic dependency feature to each character, the model can infer from the semantic level, and then analyze that the sentence mainly describes “
(Rosa Cake)” as opinion target. However, after adding part-of-speech feature and syntactic dependency feature to each character, the model can infer from the semantic level, and then analyze that the sentence mainly describes “ (Taipei soybean milk)” rather than “
(Taipei soybean milk)” rather than “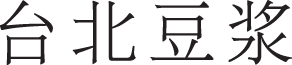 (Rosa Cake)”. Therefore, introducing part-of-speech(POS) feature and syntactic dependency(SD) feature is an effective way to make our model understand the semantics of sentences. Besides, we observed that “Full model” always performs best, which indicates that these three features are indispensable. With the assistance of these three features, the proposed model understand sentences from multiple aspects and get better performance.
(Rosa Cake)”. Therefore, introducing part-of-speech(POS) feature and syntactic dependency(SD) feature is an effective way to make our model understand the semantics of sentences. Besides, we observed that “Full model” always performs best, which indicates that these three features are indispensable. With the assistance of these three features, the proposed model understand sentences from multiple aspects and get better performance.
However, although the features we proposed can handle most of the sentences, there are still some problems that cannot be solved, such as the fifth sentence in Table 8. When the two nouns “ (Erhai)” and “
(Erhai)” and “ (Lake water)” are connected together, the proposed model may treat these two nouns as a whole and recognize them as opinion target.
(Lake water)” are connected together, the proposed model may treat these two nouns as a whole and recognize them as opinion target.
Subsequently, we check the error case to analyze the weakness of our model. Some results of the error case are shown in Table 9. As seen in Table 9, the first and second sentences are about the coffee house. The true label of the first sentence contains the Chinese character “ (house)”. However, in the second sentence, the true label does not include the Chinese character “
(house)”. However, in the second sentence, the true label does not include the Chinese character “ (house)”, which confuses the model. We call this situation ambiguous boundary. It can be observed that the ambiguous boundary of opinion target is the main error type, which contains an under-extracted error and an over-extracted error. Simultaneously, we find that the main reason for the ambiguous boundary lies in some noise from the error annotation in the dataset, as in the first and second sentences mentioned above. And there are many other similar error cases, such as the third sentence and the fourth sentence, which puzzle model whether to add the Chinese character “
(house)”, which confuses the model. We call this situation ambiguous boundary. It can be observed that the ambiguous boundary of opinion target is the main error type, which contains an under-extracted error and an over-extracted error. Simultaneously, we find that the main reason for the ambiguous boundary lies in some noise from the error annotation in the dataset, as in the first and second sentences mentioned above. And there are many other similar error cases, such as the third sentence and the fourth sentence, which puzzle model whether to add the Chinese character “ (restaurant or store)” to the opinion target.
(restaurant or store)” to the opinion target.
Several example of error case. There is an English translation of the sentence in brackets after each Chinese sentence. “√” represents the label is correct, “×” represents the label is wrong
Several example of error case. There is an English translation of the sentence in brackets after each Chinese sentence. “√” represents the label is correct, “×” represents the label is wrong
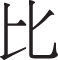
In addition, the proposed model may make a mistake when there are multiple nouns and no noting words in a sentence, such as the fifth sentence, which is an important issue for future research. Therefore, we believe that the performance of the proposed model could be further improved if errors in the dataset are excluded. But due to the huge amount of data and the time-consuming manual screening, we strand this work.
The embedding layer is significant for OTE task, which is ignored by the most of previous works, especially for the Chinese case. In previous researches, some works are based on the BILSTM-CRF framework and have achieved superior performance on OTE task. However, it is still difficult to capture the crucial information in the sentence, which can further improve the performance of the OTE model. To remedy this drawbacks, this paper proposes an enhanced BiLSTM-CRF model, which uses BERT as the character embedding method and combines the part-of-speech, syntactic dependency feature, and noting words of each character to make a multiple-perspective analysis from sentences and improve the extraction performance.
Experiments are conducted on three Chinese datasets. The experimental results indicate that the proposed model achieves better performance compared to other existing state-of-the-art methods. To verify the effectiveness of the three proposed features, we conduct ablation study on the proposed model, which demonstrates that the model performance with three features is further improved in OTE task.
Further work would focus on the novel features to handle complex sentences with multiple nouns. In addition, we plan to explore more effective feature fusion methods, rather than simply concatenation. Moreover, we also plan to further explore different natural language OTE tasks.