
Abstract
Although the existing transfer learning method based on deep learning can realize bearing fault diagnosis under variable load working conditions, it is difficult to obtain bearing fault data and the training data of fault diagnosis model is insufficient£¬which leads to the low accuracy and generalization ability of fault diagnosis model, A fault diagnosis method based on improved elastic net transfer learning under variable load working conditions is proposed. The improved elastic net transfer learning is used to suppress the over fitting and improve the training efficiency of the model, and the long short-term memory network is introduced to train the fault diagnosis model, then a small amount of target domain data is used to fine tune the model parameters. Finally, the fault diagnosis model under variable load working conditions based on improved elastic net transfer learning is constructed. Finally, through model experiments and comparison with conventional deep learning fault diagnosis models such as long short-term memory network (LSTM), gated recurrent unit (GRU) and Bi-LSTM, it shows that the proposed method has higher accuracy and better generalization ability, which verifies the effectiveness of the method.
Introduction
The rolling element bearing is the important part of mechanical equipment, and timely diagnosis of bearings can prevent industrial accidents [1]. However, in practical engineering applications, the bearing data is often small, and the working environment is often variable, so it is difficult to obtain the bearing fault data, which brings severe challenges to the fault diagnosis of rolling bearings [2].
Now, there are many deep learning methods used in bearing fault diagnosis [3]. Deep learning [4] overcomes the defects of traditional bearing diagnosis methods, and can automatically learn valuable features from the original data. To a large extent, it gets rid of the signal processing experience of diagnosis experts, and has been applied to bearing fault diagnosis. Nowadays, a lot of achievements have been made in fault diagnosis of rolling bearings. Amar M et al. present a novel vibration spectrum imaging (VSI) feature enhancement procedure for low SNR conditions and used ANN to classify bearing faults [5]; Wei Zhang et al. proposed a novel method named Deep Convolutional Neural Networks with Wide First-layer Kernels for bearing fault diagnosis [6]; Y Li et al. proposed a method based on multi-scale permutation entropy (MPE) and improved support vector machine based binary tree (isvm-bt), and applied it to extract vibration features of bearings [7]; Guo X et al. proposed a novel hierarchical learning rate adaptive deep convolution neural network based on an improved algorithm for bearing fault diagnosis [8]. However, these traditional methods based on deep learning have the following problems: firstly, they need to carry out complex training on the original data, secondly, they need a large number of training data to train the network, the training time is long, the manpower and material resources are expensive, and there are not a lot of training data in the actual application [9]. Aiming at the problems of traditional deep learning methods, in recent years, transfer learning is widely used in rolling bearing fault diagnosis, which has the ability to learn the knowledge and skills of previous tasks and apply them to new tasks. The transfer learning method does not need to assume the same distribution of training data and test data, and it can avoid the manpower and material costs caused by relabeling the acquired data in traditional machine learning [10]. The main idea of transfer learning is to learn knowledge from the existing source domain, and then transfer the knowledge to the target domain [11]. J Shao et al. proposed an adversarial domain adaption method based on deep transfer learning [12]; Piao Lei et al. proposes a new transferable fault diagnosis method with adaptive manifold probability distribution (AMPD) under different working conditions [13];Wang et al. proposed a transfer learning method based on ResNet [14]; Han et al. applied data enhancement to Convolutional Neural Network (CNN) and proposed a new transfer learning method [15]; Xu G et al. proposed an online fault diagnosis method based on a deep transfer convolutional neural network (TCNN) framework [16].
In this paper, the Elastic Net [17] is introduced into the bearing fault diagnosis model, and the relationship between L1 regularization and L2 regularization penalty terms is illustrated through experiments. The improved Elastic Net is added to the LSTM, and the bearing fault diagnosis is carried out by using transfer learning. The trained model parameters are transferred, and then we use a small amount of target domain data to fine-tune the network parameters, and finally realize the rolling bearing fault diagnosis under different working conditions.
A introduction to elastic net transfer learning
Transfer learning
The meaning of transfer learning is to apply the knowledge learned from previous tasks to new tasks [18], transfer the model parameters learned to other network models, and retrain the network. The main purpose is to improve the generalization ability of the model. Traditional machine learning requires sufficient training data to train a good model. However, for the target domain classification problems with only a small amount of data, transfer learning can be used to solve this kind of problems [19, 20]. Transfer learning can quickly train to get an ideal result, and it can also have a better effect when the data set is small [21, 22].
The two extreme forms of transfer learning are one-time learning and zero-time learning. The transfer task with only one labeled sample is called one-time learning; the transfer task without labeled sample is called zero-time learning. Only when additional information is used in training, zero-time learning is possible. There are many kinds of transfer learning methods. According to the content of transfer learning, transfer learning methods can be divided into feature-based transfer, instance-based transfer, model-based transfer, and relationship-based transfer. Table 1 shows the comparison of four different transfer learning methods.
Comparison of different transfer learning methods
Comparison of different transfer learning methods
One of the main purposes of transfer learning is to improve the generalization ability of the model. Even if the model is applied to other test data rather than training data, the model can also have high recognition accuracy [23]. Aiming at the problem of insufficient training data of fault diagnosis model, which leads to low generalization ability of the model, this paper adopts the model-based transfer learning method to make the source domain and target domain share weight parameters, so as to improve the generalization ability of the model. In deep learning, a very key problem is how to design a model, which has a very good performance in both training data and test data. In machine learning, many methods are used to reduce test errors, suppress over fitting [24], and improve the generalization ability of models, which are called regularization [25]. At present, the commonly used regularization methods are L1 regularization and L2 regularization [26].
L1 regularization is as follows:
wrepresents the weight parameter to be updated.
L2 regularization adds the following regularization item to the objective function:
It can be seen from above formula that L2 regularization is the sum of squares of each weight parameter.
In order to further improve the generalization ability of the model, the Elastic Net is introduced in this paper.The formula is as follows:
λ1 and λ2 are penalty terms. It can be seen from the above formula that Elastic Net is a linear combination of L1 regularization and L2 regularization.
Elastic Net is to add L1 regularization and L2 regularization to the loss function at the same time.The cost function after adding Elastic Net is as follows:
J (w ; X, y) is the cost function, L (w ; X, y) is the loss function, λ1 and λ2 control the strength of regularization.
Explain the physical meaning of λ1 and λ2from two-dimensional space. The two-dimensional space graph of L1 regularization and L2 regularization can be expressed by the following formulas:
It can be seen that the two-dimensional space graph of L1 regularization is a diamond, and the two-dimensional space graph of L2 regularization is a circle. When the penalty terms λ1 and λ2 increase, the graph will shrink, and the corresponding weights w1 and w2 will also decrease; When the penalty terms λ1 and λ2 decrease, the graph will increase, and the weights w1 and w2 will also increase. Therefore, the penalty terms λ1 and λ2 can control the size of the weights, suppress over fitting, and improve the generalization ability of the model.
Next, in order to better adapt to the bearing fault data of rail transit, the relationship between λ1 and λ2 in this paper is analyzed by experiments. The experimental data is the rolling bearing data set of Case Western Reserve University, and the data sources will be introduced in Section 5. The experimental results are shown in Table 2.
Comparison Results of The Relationship Between λ1 and λ2
According to the above experiments, the accuracy of the first group is higher, the accuracy of the second and third group is lower. In the second group of experiments, over fitting occurred once. And from the above three groups of experiments, it can be seen that with the value of penalty term λ2 increase, the accuracy of the model is higher when the value of penalty term λ1 decreases. Therefore, in order to simplify the above cost function formula, unify λ1 and λ2 in Elastic Net, the following improved cost function is proposed, as shown below:
λ is the unified penalty term. When λ takes different values, different combinations of regularization can be obtained.
When λ is equal to 0, L2 regularization will not work, only L1 regularization work on the loss function. Next, observe the performance of L1 regularization through the formula. For convenience, the penalty term of L1 regularization in the following formula is represented by λ1, and the cost function with L1 regularization is as follows:
Assuming that w* is the optimal solution when L (w ; X, y) takes the minimum value, then the second-order Taylor expansion of L (w ; X, y) at w* is as follows:
At w*, L′ (w* ; X, y) is equal to 0,and can be represented by Hessian matrix, so the loss function can be reduced to the following form:
The cost function is as follows:
The analytical solution of the following form can minimize this cost function:
sign (w*) just takes the sign of w*. When
In (7), when λ is equal to 1, L1 regularization will not work, only L2 regularization work on the loss function. Next, we observe the performance of L2 regularization by studying the gradient of the cost function. In the following formula, the penalty term of L2 regularization is represented by λ2,and the cost function with L2 regularization is as follows:
The gradient of cost function is as follows:
The weight update formula is as follows:
The simplified weight is as follows:
α is the learning rate,
In (7), when λ is not equal to 0 or 1, L1 regularization and L2 regularization work on the loss function at the same time, that is, Elastic Net. According to the above analysis, Elastic Net can not only generate sparse solutions, but also restrain the excessive weight, thereby further improving the generalization ability of the model.
Finally, the improved Elastic Net is added to LSTM for transfer learning, so as to realize bearing fault diagnosis.
In machine learning, transfer learning is an important method used to solve the problems of difficulty in obtaining labeled data in practical applications. When we design a model and optimize it with data, we consider using independent and identically distributed training data and test data. At this time, the number of samples required is also very large, and the training optimization of the model is also takes a lot of time and resources, but transfer learning can solve the above problems. This paper uses LSTM to realize transfer learning., the structure of LSTM memory unit is shown in Fig. 1.
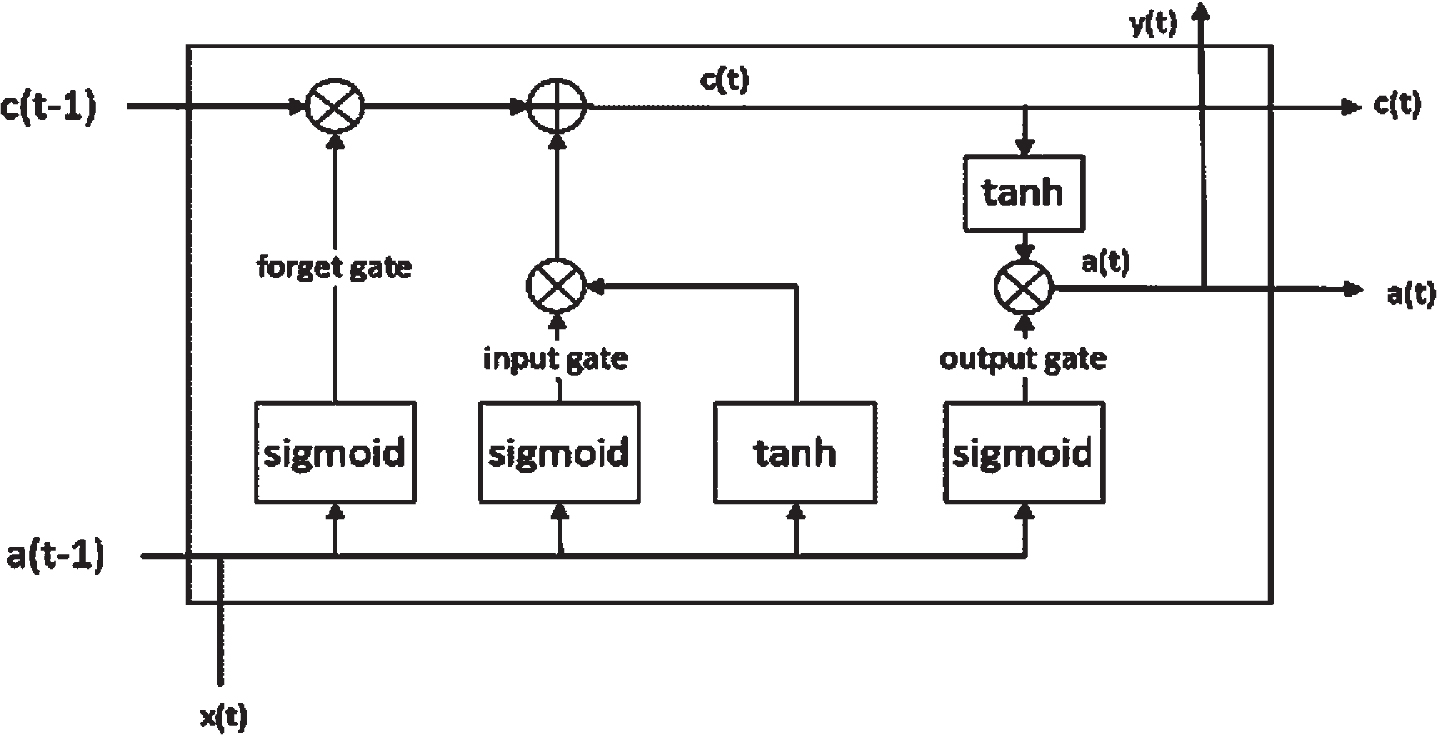
Structure of LSTM memory unit.
In this paper, we add the improved Elastic Net to LSTM to realize bearing fault diagnosis. We train the model by adding a small amount of target domain data to the source domain, and then transfer the trained model parameters to the target domain, and use a small amount of target domain data to fine tune the model parameters. Finally, we build a bearing fault diagnosis model with a certain generalization ability. Table 3 shows the fault diagnosis algorithm proposed in this paper.
Algorithm Description Based on Elastic Net and LSTM
Figure 2 shows the fault diagnosis process proposed in this paper based on improved Elastic Net and LSTM.

The construction process of fault diagnosis model.
According to the construction process in Fig. 2, we finally built the fault diagnosis model based on improved Elastic Net transfer learning and LSTM. The method proposed in this paper can greatly reduce the complexity of parameter adjustment, and the number of penalty terms is changed from two to one, which brings great convenience to the experiment.
In the neural network, the distribution of data in each layer is constantly changing, and the change of data distribution between each layer will affect each other. The change of data distribution in the front layer will affect the back layer. Batch normalization (BN) [27] is proposed to solve the problem of data distribution changes between network layers. Therefore, BN is also added to the network model used in this paper. BN processes one mini-batch data at a time, which is to normalize the mean value and variance of the data distribution to be 0 and 1. The formulas are as follows:
B is the set of m input data of a mini-batch, B ={ x1, x2, . . . , x
m
}, μ
B
is mean value,
γ and β are parameters, the initial value of γ is 1, and the initial value of β is 0, which can be adjusted to the value suitable for the network model through learning.
The above is the batch normalization algorithm. The purpose of adding BN is not to make the data distribution fluctuate too much with the increase of the number of network layers, which means that no matter how the input value changes, it can ensure that their mean value is 0 and the variance is 1, or they depend on γ and β.
Introduction of data sources
In this paper, the rolling bearing data set of Case Western Reserve University is used for fault identification experiment. The experimental platform is mainly composed of a 1.5KW motor, a torque sensor / decoder, a power tester and electronic controller. The processed faulty bearing was reassembled into the test motor, and the data of vibration acceleration signal under the motor load conditions of 0HP, 1HP, 2HP and 3HP was record respectively. The rolling bearing fault data set used in this paper is generated at the driving end of 12 kHz, the faults are located in the outer ring, inner ring and rolling elements, and the diameters of the faults are 0.1778 mm, 0.3556 mm and 0.5334 mm. The source domain data is 1HP and the target domain data is 2HP.
Comparison experiments of model before and after adding Elastic Net
The method proposed in this paper is compared with the conventional LSTM. The experimental results are shown in Fig. 3 and Fig. 4.

The conventional LSTM model.

The method proposed in this paper.
It can be seen from Fig. 3 and Fig. 4 that the difference between the recognition accuracy of training data and the recognition accuracy of test data is shrunk compared with the model without Elastic Net. However, it should be noted that the training accuracy of the model with improved Elastic Net is reduced, which does not affect the accuracy of the test data. By increasing the number of training, the training accuracy can reach 100%. Moreover, by increasing the number of training, the accuracy of the model with Elastic Net is higher than that of the model without Elastic Net. The above experiments show that the over fitting is restrained and the generalization ability of the model is improved.
In order to further demonstrate the feasibility of the method proposed in this paper, we visualize the experimental results. The experimental results are shown in Fig. 5 and Fig. 6.
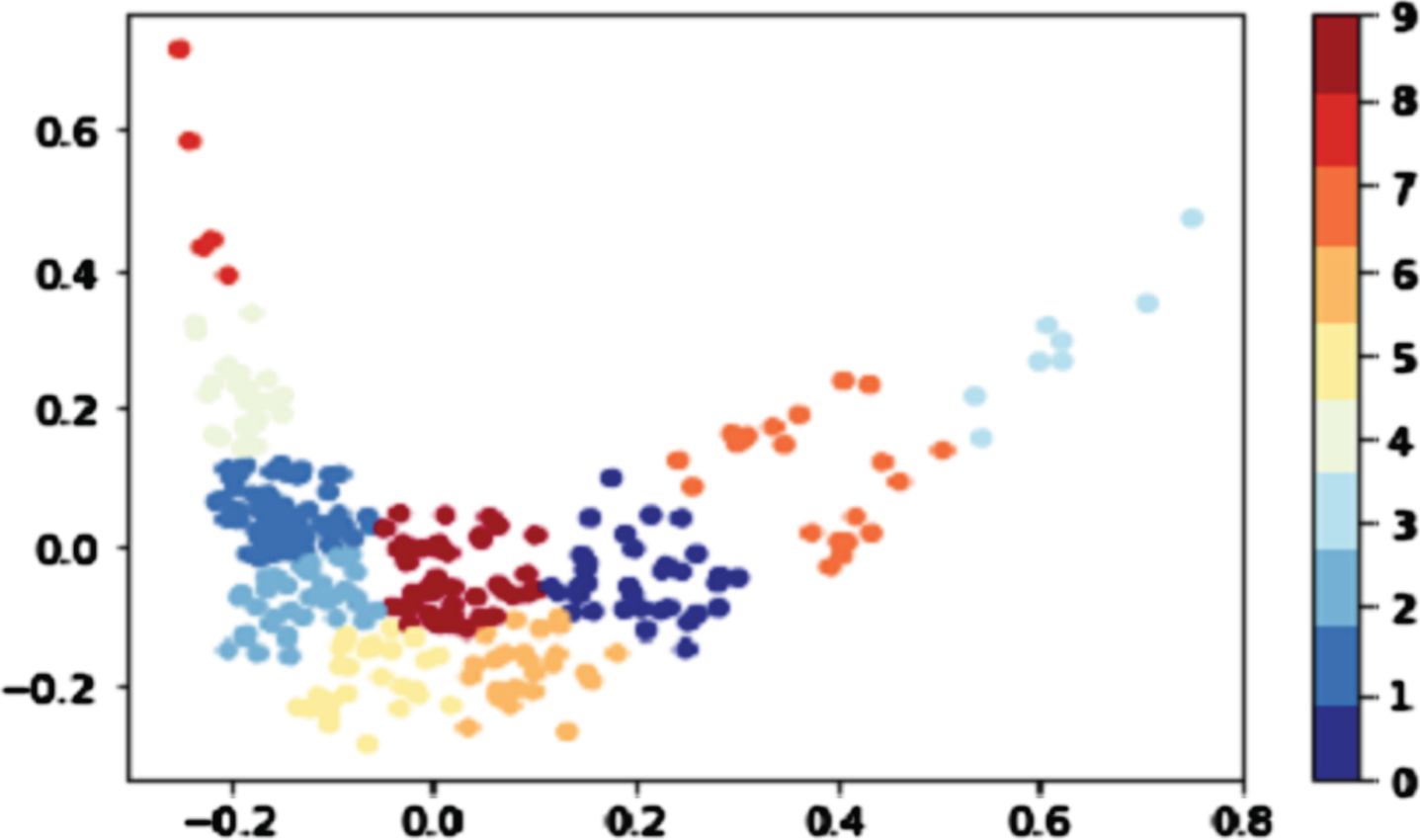
The conventional LSTM model.
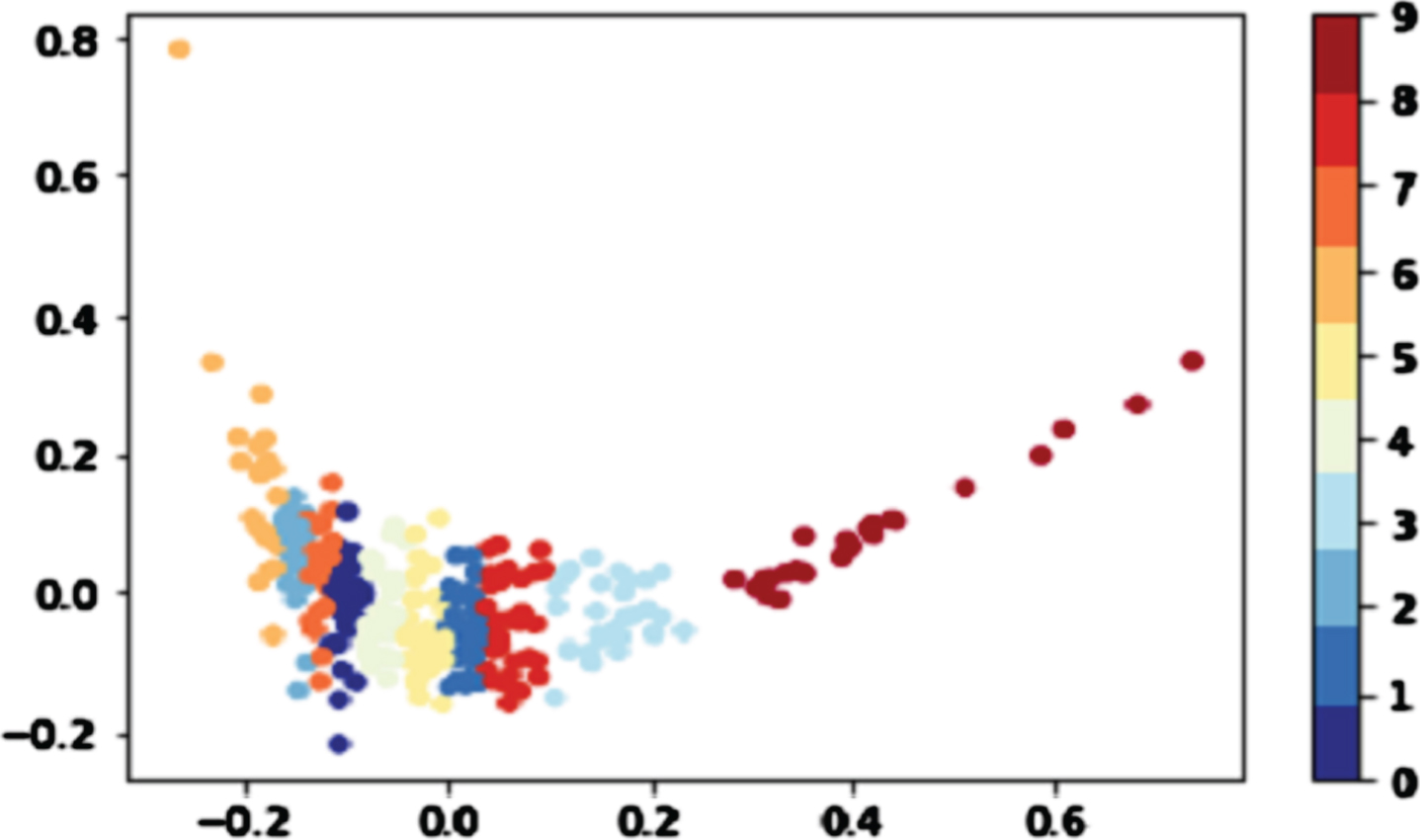
The method proposed in this paper.
As can be seen from Fig. 5 and Fig. 6, the method proposed in this paper is better.
In this paper, the LSTM with improved Elastic Net was compared with traditional LSTM, GRU and Bi-LSTM. Table 4 shows the comparison results.
Comparison results of different network models
For LSTM with Elastic Net, the generalization ability of the model is improved and the over fitting is restrained, which can improve the accuracy of the model. However, the generalization ability of the other three models is not high and over fitting is easy to occur. Under variable load conditions, the difference between the recognition accuracy of training data and test data will be enlarged, so the accuracy is not as high as the method proposed in this paper.
In order to further verify the effectiveness of the method proposed in this paper, the LSTM with Elastic Net is compared with other methods, and the comparison results are shown in Table 5.
Comparison results of different methods
It can be seen from Table 5 that the method proposed in this paper is higher than that in reference [29] and reference [30], which further proves the effectiveness of the method proposed in this paper.
The proposed method in this paper and the conventional LSTM, GRU and Bi-LSTM were trained under 1HP, and then transferred to 2HP. The accuracy of the four methods was compared under different training times. The experimental results are shown in Fig. 7.

Comparison results of different training times.
As can be seen from Fig. 7, with the increase of training times, the accuracy of the models is on the rise. The accuracy of the proposed method under different training times is higher than that of the other three transfer learning models.
Experiments were carried out under different number of target domain samples, and the LSTM with improved Elastic Net was compared with the traditional LSTM, GRU and Bi-LSTM to observe the accuracy. The comparison results are shown in Fig. 8.
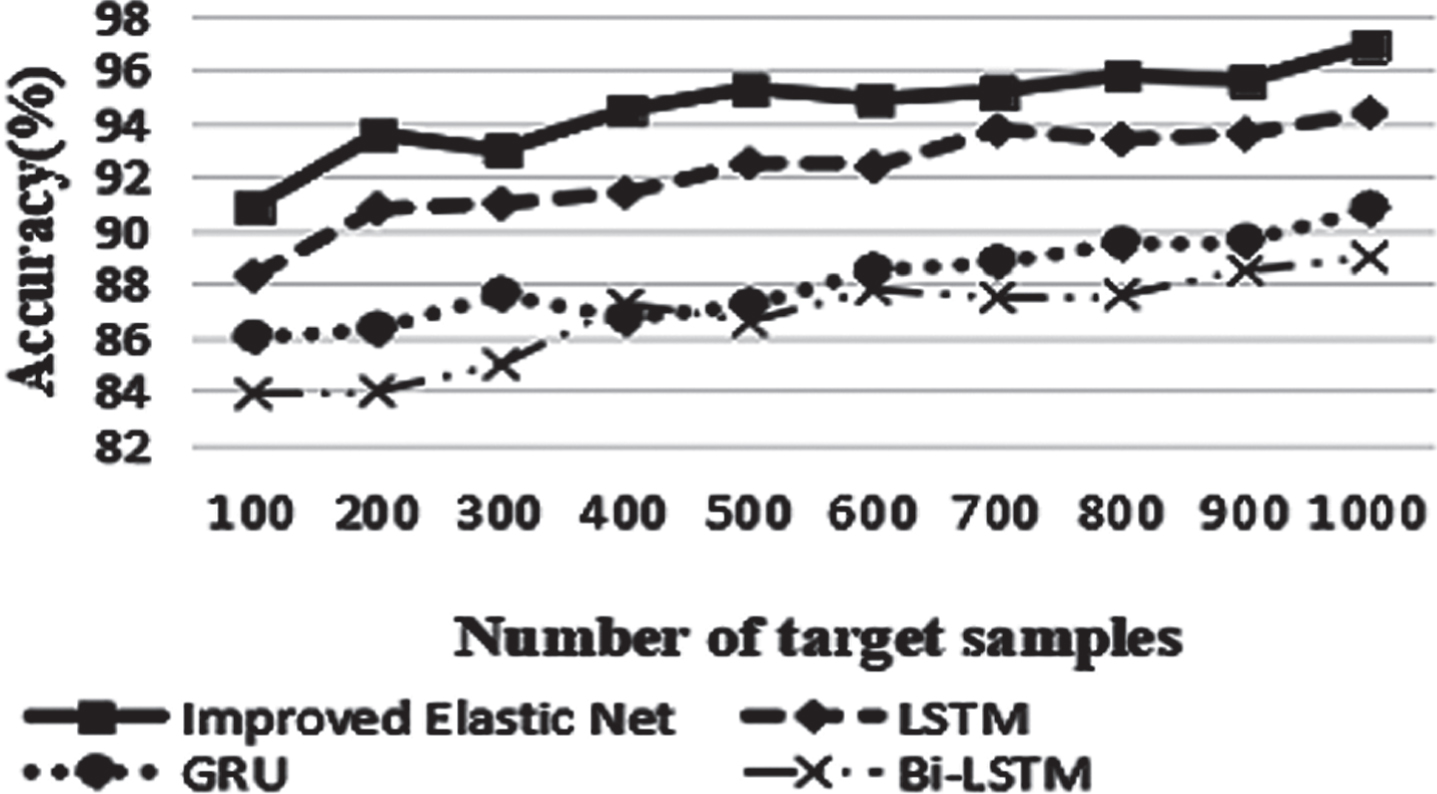
Comparative experiments under different number of target samples.
The Fig. 8 shows that the performance of the model proposed in this paper is much better than the other three models, further verify the feasibility of the proposed method in this paper.
In this paper, aiming at the problems of less rolling bearing data and difficulty in obtaining bearing fault data in practical application scenarios, a fault diagnosis method based on Elastic Net transfer learning and LSTM is proposed. This method can suppress over-fitting and improve the generalization ability of the model. The LSTM with improved Elastic Net is compared with the conventional LSTM, GRU and Bi-LSTM through related experiments to further verify the effectiveness and feasibility of the method proposed in this article.
In future work, we can judge the similarity between the source domain samples and the target domain samples, and avoid negative transfer, so as to further improve the accuracy of bearing fault diagnosis.
Footnotes
Acknowledgments
This work has been supported by Liaoning Provincial Natural Science Foundation of China (No. 2019-ZD-0105).