
Abstract
Social networks have become a popular communication tool for information sharing. Twitter offers access to data and provides a significant opportunity to analyze data. During pandemics, Twitter becomes a big source for the dispersal of unverified information. In social media, it is difficult to find the sources of rumors. To tackle this problem the authors have developed a hybrid rumor centrality algorithm for rumor source detection in social networks. The authors propose an S-RSI algorithm for identifying a single rumor centre and an M-RSI algorithm for identifying the propagations of multiple rumor centres in the thread of conversation. The proposed rumor centrality algorithm efficiently predicts the rumor disseminating possibilities in a conversation tree with the aid of graph theoretical approach. The authors have evaluated the performance of the algorithms on the PHEME dataset containing seven real-time event conversational trees based on the tweet messages. The results show that the proposed is best suitable in finding the rumor source centre with a high probability in social media during a crisis.
Introduction
Social Network is defined as a network of individual users and their connections. Social Network Analysis (SNA) is to derive and interpret the characteristics of the complete network [1]. It provides both mathematical and visual analysis of the relationships in the network. Twitter has 330 million monthly active users to access breaking news and real-time updates for earthquakes and disasters [2]. This information circulates among Twitter users in an unproven manner. During crises, Twitter plays a key role in providing valuable information to a large community of people. Most of the users share rumors without verification, and they tend to retweet the message in their community making it viral on all other social media. Research reveals that if a tweet contains a rumor, it spreads six times faster than real tweets to reach 1500 users during disaster times [3]. In the context of breaking news stories, a rumor is defined as a “circulating story of questionable veracity, which is credible but hard to verify, and produces sufficient skepticism and/or anxiety to motivate finding out the actual truth” [4].
The authors of [4] examined nine events related to the rumor conversation threads and analyzed how people react to a particular rumor which they support or deny. In [5], the authors proposed a sample path-based methodology to detect a single rumor source. The maximum distance between a node and an infected node is known as Jordan Infection Centre. In the SIR (susceptible-infected-recovered) model, they proved that a node with a minimum infection eccentricity is the root of the rumor in a sample path node. The authors of [6] extended the analysis of the heterogeneous SIR model with the partial observation of the node. In [7], authors identified multiple sources under the SIR model and demonstrated that the separation between the estimator and its nearest real source value is limited by a constant high probability value in tree networks. In [8, 9] the authors proved that the Jordan infection center is optimal for detecting sources under the SI (susceptible-infected) model and SIS (susceptible-infected- susceptible) model. The authors of [10] discussed two-stage algorithms; stage one to cluster the most likely candidates in one group with the aid of the optimal ML estimator and stage two locates the rumor source within the cluster. The authors of [11] addressed the problem of finding a rumor source in social networks with incomplete information. They had proposed techniques like Compressed Sensing Base, DN Matrix Completion, and DN Matrix Completion for source identification. In [12], the authors analyzed a large volume of the tweets in the August 2011 riots in England. They proposed a computational tool to create the structure of the corpus which helps in analyzing the data by human expertise. Tweets are clustered based on the semantic similarity using NLP Technology. The authors suggested that their computational method can be applied in managing rumors during a crisis. The transmission of rumor networks is checked using uniqueness theorem [27]. Comparison of three susceptible-infected-susceptible epidemic models and numerical simulation are discussed in [29]. In emergency periods like natural disasters such as floods and cyclones, government organizations had faced difficulties in controlling the rumor information flow in social media platforms. It is important to control such rumors on social media during the crisis. In this work, the authors propose a rumor centrality model to identify the origins of the rumor in a conversation tree. The authors have analyzed the PHEME dataset containing a large corpus of rumorous tweets. The identified trustworthy information is annotated manually and the tweets are classified based on the features. The main contribution of this work is as follows: From the conversation tree, the authors computed the probability of the rumor source centre with the aid of Single Rumor Source Identifier (S-RSI) and Multiple Rumor Source Identifier (M-RSI) algorithms. A single rumor centre identifies the source of the rumor while multiple rumor centre predict the possibility of rumor spreading nodes in the network. The authors evaluated the proposed algorithm in the PHEME dataset, which achieves better performance for detecting the rumor source in social media.
In the conversation tree, the identified rumor community, single rumor centre, and multiple rumor centre have been evaluated for taking appropriate decisions. The existing veracity assessment approaches addressing the text classification of an event. It can classify the tweet as rumor or not using supervised learning technologies.
The authors are motivated to detect the rumor source probability on a conversation tree during crises. Most of the previous source identification was made on either single or multiple observations on a general network. The authors contribute this work to both the observations. The rumor centrality is derived in a real-time conversation tree which measures the network strategy for the conversation tree in a sparsely connected network. This research work is organized as follows. Section 2 briefly reviews the rumor source detection methods during crisis events. Section 3 describes Twitter conversational threads in the PHEME dataset. Section 4 illustrates the model for identifying the rumor source using S-RSI and M-RSI algorithms. Section 5 demonstrates the performance of the proposed algorithm in all conversational threads. Section 6 concludes with the technique for rumor source identification.
Related work
This section presents an outline of the research work closely related to the rumor source identification in graph theoretic and general tree perspective.
Fanti et al. suggests how to hide the identity of the author of sensitive messages for personal safety. Snapshot adversarial model spreads the rumored content using virtual source and achieves perfect obfuscation of the source. The results were implemented on the Facebook network and show how effectively locations of the rumor sources are hidden. They describe the adaptive diffusion over the infinite d-regular tree, with varying amounts of control information. R-regular trees are used to achieve the desired source obfuscation. Spy based adversary models implement a virtual source in fully distributed networks for detecting the rumor source. In the spy+snapshot adversarial model, detection probability was improved by increasing estimated time and degree value [13].
Zhu et al. derived a MAP estimator to find the rumor source on general tree networks under the independent cascade model. They had proposed a Short-Fat Tree algorithm to identify the source in general tree networks. SFT performance was evaluated on tree networks, ER random graph, and IAS networks [14].
Shah et al. established the rumor centrality estimator to detect the source of the rumor on Polya’s urn model based on continuous-time, branching-time, and branching processes. Additionally, they checked the results on a sparse random graph like Erdos-Renyi. The universality rumor centre overcomes the limitations of rumor centrality and improves the effectiveness of various tree-structured graphs [15]. Zhou et al. presented the SEIR model and was performed well for rumor source identification with the aid of observed snapshot. They proposed an optimal infection process for calculating the Jordan infection centre on observed graph topology. They had proved optimal infection process-based estimators outperform in finding the rumor source on various networks as compared to other centralities like Closeness Centrality (CCE) and Betweenness Centrality (BCE) [16]. Fuchs et al. detected rumor source on random increasing trees based on the asymptotic formulas. This formula was applied to tree families like d-ary trees, recursive trees, and generalized plane-oriented recursive trees to detect rumor probability and its values vary from 0 to 1. They had also checked the formula on an unordered tree [17]. Twin SIR model to reduce the influence of the rumor and control rumor spreading [28]. In social network rumor propagation was identified by behavioral psychology of the users [30]. An influential spreaders identification algorithm has calculated the k-score, page rank and degree centrality for identifying the rumor sources [31]. Table 2 explores the detailed study of the rumor propagation models in the social network. Rumor source detection using scale free network [35] and online social network [36] are discussed.
Taxonomy of Rumor source detection algorithms for different network
Taxonomy of Rumor source detection algorithms for different network
Example of conversational thread
The authors analyzed the PHEME Dataset containing a collection of conversation threads related to the breaking news which widely spread rumors and specific rumors that are known priori. This research work is focused on to identify the source of rumor in seven real-time events namely Putin-missing, Michael Essien contracted Ebola, Germanwings plane crash, Charlie-Hebdo shooting, Ferguson unrest, Ottawa Shooting, and Sydney siege. This PHEME dataset was extracted from the newsworthy event source tweets which are highly replied and retweeted. There were 285 conversational threads containing source tweets, reactions, URL content, and images. The author has considered the entire conversation thread for each rumor and non-rumor in the dataset. With respect to a single source tweet there are a vast number of retweets and reply tweets which are used to evaluate the proposed algorithm. The huge volume of the PHEME dataset is tested with the aid of the rumor source identifier algorithms. Source tweets support rumors. Reactions are responses of following users, who agree with the rumor or deny. The tweets are annotated and labelled using their Tweet-id. Figure 1 shows the structure of the conversational tweets.

Structure of Conversational thread in PHEME dataset.
The following Table 1 presents the various categories in the sample conversation thread for the source id 544268732046913536.
The authors propose a hybrid rumor centrality model for identifying the rumor source during a natural disaster period with the aid of rumor source identifier algorithms. Figure 2 represents the architecture of the proposed system. This model comprises three categories: (1) Dataset, (2) Data annotation, (3) Rumor Source Identifier model.
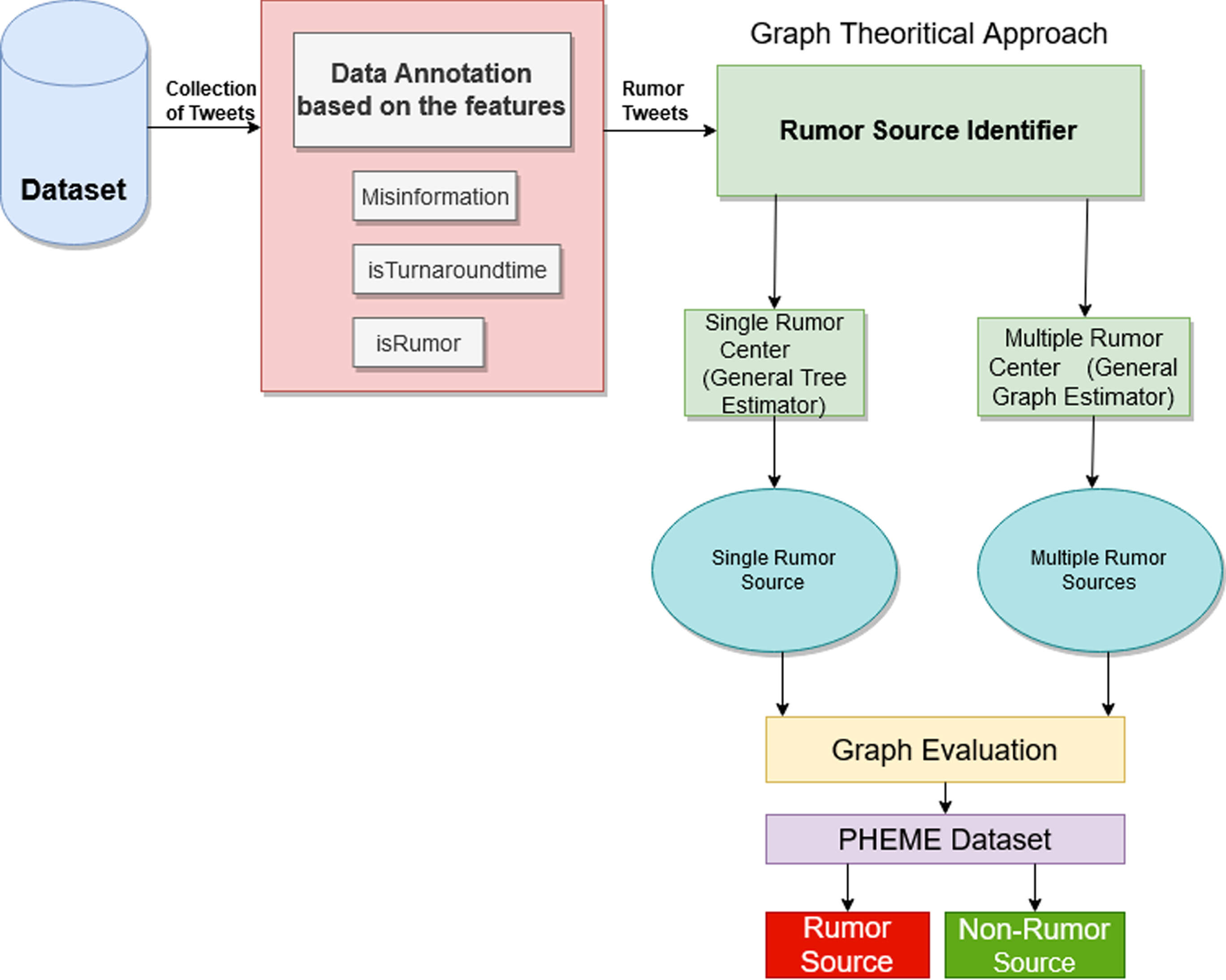
Architecture for rumor source identification.
The authors have used the PHEME dataset to build the repository. This data store consists of a thread of conversation as mentioned in section 3. This dataset has source tweets, highly retweeted tweets and reaction tweets associated with these newsworthy events. The retweet threshold is nearly 100 for all events. Every event had generated a huge volume of content on Twitter and affected a large community of people. Within the source tweet there are a vast number of retweets and reply tweets are available to test the algorithm. The huge volume of the dataset is tested with the aid of the dataset.
Data annotation
The seven-event dataset has 285 conversational threads stored in the JSON file. Every thread contains source tweets, retweets, replies, URL and images related to the event [26]. In the large dataset, all tweets are annotated manually. Data annotation was done based on the features of misinformation using, is_turnaround, and is_rumor. The feature of misinformation determines the rumor tweet message and later proven to be true or false. A conversation thread is marked as a turnaround if it represents a shift in the story either by confirming or debunking based on the truth of the story. The tweet message is marked as a rumor or non-rumor using the feature is_rumor. A tweet is marked as a rumor if the annotated values are misinformation = 1, is_turnaround = 0, and is_rumor = 0, and the rest are non-rumor. The human annotated labels are predicted with the aid of the S-RSI and M-RSI algorithms.
Rumor source identifier model
The main objective of this research work is to find the source of the rumor in the conversation tree. The authors have introduced the hybrid rumor centrality model for finding the rumor source in the general tree and graph.
Single rumor center
In level one each node in the graph has two states (i) susceptible nodes, capable of being infected (ii) infected nodes that spread the rumor to its neighbour nodes. Initially, all the nodes are susceptible except the source node. The source node can infect its neighbour nodes connected by an edge. The proposed system adapts the Susceptible-Infected model. In this model, the infected node always preserves the rumors. Two susceptible nodes l and m connected through edge (l . m ∈ E). At time ‘t’, the node starts to spread rumor from an infected node to any one of its neighbours independently and follows an exponential distribution.
Where ‘t’ is the total number of infected nodes and G
t
be the graph connected to ‘t’ infected nodes.
In the general tree, S_RSI algorithm is used in identifying the single source of rumor in twitter conversational tree. In a tree network, the infected nodes are represented by a user who supports the rumor. Let v1 = {v, v2 … vn} be the conversation tree, where v1, v2 … vn are the nodes involved in a single conversation thread. If v1 is the source node, then v, v2, v3...vn are the replying and retweeting nodes in the thread of conversation. Conversation tree is constructed for seven real-time events with the aid of a rumor thread of conversation. S-RSI scores for all the infected nodes are calculated by using equation 1. This score for all infected nodes are compared and the node with maximum score id is identified as the single rumor centre. Figure 3 shows the conversation tree for all events and the identified single rumor centre(source) is marked using green color. The authors represented the thread of conversation with spanning trees. This tree network has a subset of rumor nodes in the conversation tree. For eg Putin-missing events have nine conversation threads. Based on the features, namely, misinformation, is_turnaround, and is_rumor, eight threads are identified as rumor nodes. One rumor source node is marked as green color(v) in the graph.
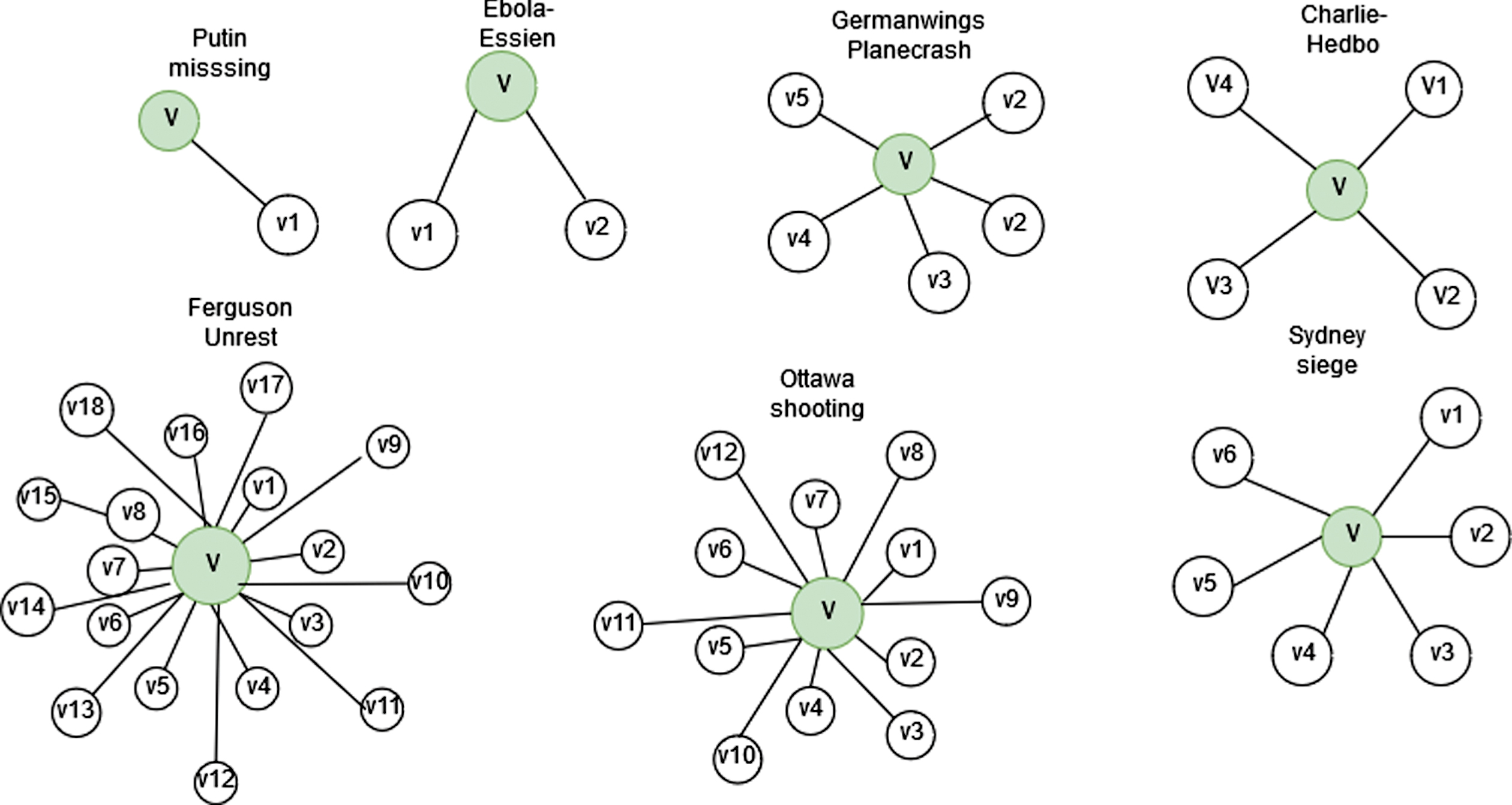
Conversation tree for seven events with a single rumor centre.
In level two, the general graph is constructed to predict the possible chances of the rumor spreading along the network based on the S-RSI identified source. In rumor graph G
t
, the permitted permutations σ for degree ‘d’ is computed using the following equation:
Where P (σ i /l) is the probability of all possible rumor nodes (l1 = l, l2 … l k ) for 1 < k < N.
The authors evaluated these algorithms using the PHEME dataset. The possibilities of the rumor prediction are determined in the seven real-event conversation trees. The multiple rumor sources are computed with the aid of a general graph with spanning tree. There is an ‘n’ number of nodes involved in the rumor spreading process. The authors computed the probability of rumor spreading nodes in the spanning tree network. Assume a node ‘l’∈Gtbe the source node, it spreads the rumor to all nodes in the tree in BFS (Breadth-First Search) ordering which is rooted between l1 and T bfs (l). Source node for rumor centre was identified with the aid of the single rumor centre.
This centre spreads the rumor to all other nodes through the conversation tree. The infected nodes in the tree find the shortest path to spread the rumor. The PHEME dataset assumes that every node has a degree of 4. For all real-time events, the rumor spreading order is estimated and their detection probability value is shown in Table 3. The prediction possibilities of rumor spreading nodes are estimated using formula 2 and 3. The highest M-RSI values of left and right nodes are two infected nodes which act as the multiple rumor centre to spread the rumors. The results show that multiple rumor centres have predicted the possible rumor spreading nodes in the conversation tree.
Estimated Value of rumor spreading order for multiple rumor centre
Number of conversation threads used for rumor classification for all seven events
Comparison of existing rumor source detection approaches
The PHEME dataset contains conversational threads of tweets for seven real-time events which are related to crises. In the identified rumor conversation threads, the authors had categorized a large number of replies and retweets compared to all other tweets. The single rumor centre is identified in the thread of conversation with the aid of manual annotation as explained in section 4.2. Following Table 4 shows the seven event threads of conversation and the number of rumor and non-rumor threads. The node of Tweet ID:5008 has a high reaction count and is marked as a rumor source.
A S-RSI value of the rumor source is derived from equation 1 and the result shows that Tweet ID:5008 has a higher GTE value as same as rumor source marked by features. Ebola-Essien has three conversation threads. The rumor node of Tweet ID:1040 is identified using the S-RSI algorithm. Charlie-Hedbo, Germanwings-crash, and Sydney-siege have almost 6 or 7 rumor nodes. Their conversation trees are constructed for highly reaction nodes of Tweet ID:4530, Tweet ID:5968, and Tweet ID:9121 which are computed using the S-RSI algorithm. As the number of conversation threads increases, the probability calculation will become complex. S-RSI algorithm with the complex network performs well for high conversation threads of events like Ferguson unrest and Ottawa-shooting events. These events have 13 and 19 rumor nodes and their probability values were calculated. The identified rumor centre nodes are Tweet ID:4705, Tweet ID:8160 respectively. The S-RSI results are then compared with the manual method of identifying the single rumor source. It is observed that the estimator has been able to recognize the same sources. Figure 4 shows the S-RSI and M-RSI estimator values of the rumor source node with the TweetID. The node with higher S-RSI value is known as a single rumor centre. This single rumor centre result shows that the source can infect their neighbour nodes in the conversation tree. Figure 4 shows the estimated computation of possible rumor spreading nodes using M-RSI algorithm.
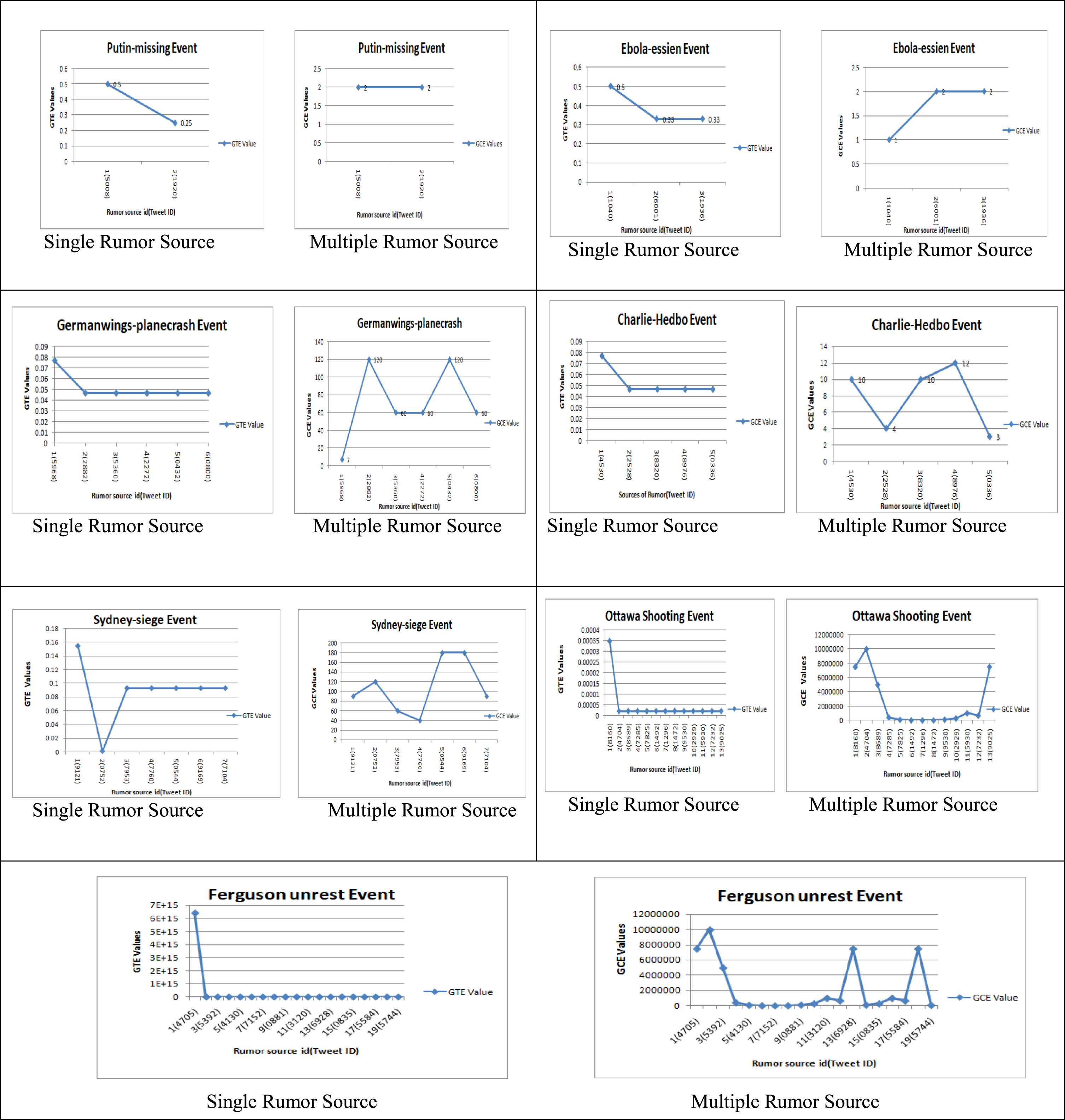
S_RSI and M-RSI Values for single and multiple rumor centre in seven events.
The prediction of possible nodes for rumor spreading is derived by using equation 2 and 3.The multiple rumor source estimator is evaluated in seven real-time events. The highest probability value of two nodes is identified as rumor spreading nodes in the graph. Figure 3 represents the predicted probability of rumor spreading nodes. The authors observe that Putin-missing event has only two rumor nodes, the possibility of the rumor nodes should be calculated using GGE and the multiple rumor center nodes are Tweet ID: 5008, Tweet ID:1920.For Ebola-Essien event Tweet ID:6001, Tweet ID:1930 has the highest probability to spread the rumors. In Charlie-Hedbo, the authors have identify three nodes of Tweet ID:8976, TweetID:4530 and TweetID:8320 act as multiple rumor center to spread the rumor. Similarly, Germanwings-crash, Ferguson unrest and Sydney-siege event there are two possible nodes are identified to spread the rumor. Ottawa Shooting event has three nodes to spread the rumor in the conversation tree. The authors observed that General Graph Estimator, to predict the possibility of the rumor center in social during a critical situation.
The authors have discussed the propagation of rumors and identified the source of the rumor centre in social networks. The PHEME dataset was annotated using the features and classified based on the information provided by news articles. The authors have proposed a two-level rumor centrality model using a S-RSI and M-RSI algorithm to identify the rumor source in a thread of conversation. If a node has a rumor, it propagates along the conversation tree. In level one a single rumor centre identifies the source of rumor, based on the S-RSI value and multiple rumor center predicts the possibility of rumor spreading nodes in social networks at level two. These algorithms are applied on seven real-time events described on the PHEME dataset and the results show the calculated estimator values correctly in identifying the rumor source in social media. The S-RSI and M-RSI estimator values are compared with the manually annotated features. This result shows that the estimator has been able to recognize the same sources. In a social network the majority of the existing work focused on a single rumor source detection only. But in real time rumors are spread from multiple users. The proposed algorithm has the potential to handle both single and multiple rumor source identification in a static manner. With the growing dynamic nature of social networking the detection of a source plays a significant role for controlling the spread of rumor across all sectors.