
Abstract
In recent years, the problem of complex multi-attribute group decision-making (MAGDM) in uncertain environments has received increasing attention. In evaluating MAGDM problems, obtaining the objective attribute weights is very important. Considering the excellent performance of intuitive fuzzy linguistic sets in dealing with uncertain information, this paper introduces a new interval-valued intuitionistic pure linguistic entropy weight (IVIPLEW) method for determining attribute weights and evaluating MAGDM problems. The IVIPLEW method considers the cases of missing values, and uses the conventional interval-valued intuitionistic pure linguistic (IVIPL) expectations to supplement the missing values. This method of dealing with missing values not only considers the expectations of experts, but also prevents fluctuations in linguistic variables from impacting the decision results. This paper establishes an analysis framework that allows the IVIPLEW method to be applied to MAGDM problems, and presents a practical case study that illustrates the practicality and effectiveness of IVIPLEW. The results are quite satisfactory. The effectiveness of the proposed method is demonstrated through a comparison with the IVIPL information aggregation method. Furthermore, the robustness of the IVIPLEW method is verified through a sensitivity analysis. The results presented in this paper show that the IVIPLEW method is applicable to a wide range of MAGDM problems.
Keywords
Introduction
With the increasing complexity of the decision-making environment [1], several drawbacks of traditional evaluation and decision-making methods have been highlighted. Moreover, due to the uncertainty of the decision-making environment, the ambiguity of decision-makers’ thinking, and the complexity of decision-making problems [2], more realistic methods are needed for evaluation. Although many multi-attribute group decision-making (MAGDM) methods have been developed, they are largely useless when dealing with very complex problems. For example, when the available linguistic evaluation terms are “excellent”, “good”, “medium”, and “poor”, and the decision-maker describes an attribute as “excellent” with membership and non-membership degrees of [0.5, 0.7] and [0.1, 0.2], respectively, then these linguistic evaluation terms may not meet the evaluation needs of the decision-making scenario. Fortunately, interval-valued intuitionistic pure linguistic (IVIPL) terms can effectively express the above-mentioned needs of decision-makers.
This paper is motivated by the case of a technical company that wishes to perform effective talent selection. The company managers believe that the application of traditional scoring methods cannot effectively reflect the psychological behavior of decision-makers. Therefore, there is an urgent need to develop a method that reflects the performance of the evaluation object and the psychological behavior of decision-makers when evaluating talents. In addition, the managers also hope that the decision-makers will use original evaluation terms to determine the attribute weights during the evaluation process, thus reducing the loss of linguistic evaluation information.
Although IVIPL is an effective tool for expressing psychological decision-making behavior, no previous studies have extended the entropy weight method to IVIPL environments. This paper describes the extension of the entropy weight method under the IVIPL environment to effectively solve the above problems. In particular, this paper answers the following questions: 1) How can the entropy weight method be effectively extended to the IVIPL environment? 2) How can the resulting method deal with situations where evaluation information is missing? 3) What are the advantages of the proposed method compared with other MAGDM methods?
The objective of this paper is to integrate the entropy weight method with IVIPL to give a new MAGDM method, called the interval-valued intuitionistic pure linguistic entropy weight (IVIPLEW) method, for evaluating talent selection. Decision-makers use IVIPL terms to represent evaluation information, and extend the entropy method to calculate attribute weights in IVIPL environments. Moreover, this paper considers the situation of missing attribute values in the decision-making process, and uses the IVIPL expectation values to replace the missing values. This method of dealing with missing values not only considers the expectations of the evaluation experts, but also prevents fluctuations in linguistic variables from influencing the decision result. The contributions of this study are as follows.
–To the best of our knowledge, this is the first paper to combine the IVIPL with the entropy weight method, while considering the situation of missing decision attribute values.
–A comprehensive analysis framework for the IVIPLEW method is constructed.
–In the fuzzy linguistic environment, the proposed method objectively and effectively determines the attribute weights. Using this method prevents the loss of decision information to the greatest extent.
The remainder of this paper is organized as follows. The relevant literature is reviewed in Section 2. Section 3 introduces the basic theories of linguistic operators, IVIPL, and the entropy weight method. Section 4 describes IVIPLEW method and develops an analysis framework for MAGDM problems. Section 5 presents a practical case study that verifies the practicality and effectiveness of the IVIPLEW method, compares the proposed method with other methods, and gives the results of a sensitivity analysis. Some management implications are discussed in Section 6, before Section 7 presents the conclusions to this study and some ideas for further research.
Literature review
Fuzzy sets [3] effectively solve complex decision-making problems that cannot use accurate numerical values, but only use a membership degree to describe ambiguity. To overcome this shortcoming, intuitionistic fuzzy sets (IFSs) [4, 5] characterize the ambiguity of decision attributes using both membership and non-membership. In recent years, extensive studies on IFSs have achieved significant research results. Atanassov and Gargov [6] proposed the interval-valued intuitionistic fuzzy set (IVIFS), in which the interval-values represent the membership degree and non-membership degree. This allows decision-makers to be more objective when describing decision attributes. Xu et al. [7] used triangular intuitionistic fuzzy numbers to express attribute values, and proposed a MAGDM method based on a zero-sum game. They also converted a fuzzy matrix into a linear programming model to obtain the best ranking. Ding and Wang [8] used interval-valued trapezoidal intuitionistic fuzzy numbers to represent attribute values, and developed three aggregation operators. Liu and Jiang [9] proposed a novel distance measure for the IVIFSs, which embodies the advantages of processing the uncertainty and imprecision of attributes. De et al. [10] proposed a probabilistic interval-valued intuitionistic hesitant fuzzy set (PIVIHFS) to solve MAGDM problems with missing attribute weights.
Various studies have used other linguistic terms to express the preferences of decision-makers, such as picture fuzzy sets [11], Pythagorean fuzzy sets [12], and probabilistic linguistic sets [13]. Huang et al. [14] proposed a Pythagorean fuzzy method to evaluate energy projects, while Lin et al. [15] developed a set of probabilistic uncertain linguistic terms and studied their normalization process, comparison methods, basic operations, and aggregation operators. In addition, to help decision-makers reach a consensus, Zhang et al. [16] defined individual consensus metrics and group consensus metrics. Zhang et al. [17] studied the interval-valued intuitionistic fuzzy entropy and proposed two entropy factors. Considering the risk preference of decision-makers, Wang and Wan [18] proposed the MAGDM method with interval-valued intuitionistic fuzzy preference relations. Besides, granular computing-based group decision-making methods have also been widely developed [19–22].
There are many extensions of IFS, such as IVIFS, triangular IFS, and trapezoidal IFS. These extended IFS method greatly expand the scope of their application. In terms of quantifying the differences and proximity of IFSs, distance measures and similarity measures are very useful [23]. Zhai et al. [24] used mathematical expressions to extend PIVIHFS, and derived three measurement methods based on entropy, similarity, and distance. Roy et al. [25] applied an optimization model to calculate the attribute weights, and proposed an interval-valued intuitionistic fuzzy number extended combined distance evaluation method to address MAGDM issues. Garg and Kumar [26] applied set pair analysis theory to IVIFSs, proposed an exponential distance measure method, and developed the technique for order preference by similarity to ideal solution (TOPSIS) method to evaluate and select the optimal alternative. After introducing a similarity measure for IVIFSs, Thao and Duong [27] developed a new similarity measure approach, and used this method to select the suitable target market. Through group discussions, Ding et al. [28] evaluated the similarity between the evaluation values given by experts to determine the reliability of these experts, and developed a MAGDM method based on evidential reasoning rules and experts’ reliability. The proposed model was applied to the selection of a shopping center site. Guo and Zang [29] reflected the nature of IVIFS through information content and information clarity, and proposed the concept of knowledge weight in multi-attribute decision-making. Tao et al. [30] combined IFS and alternative queuing methods to propose a dynamic MAGDM method, which can solve the dynamics in group decision-making. Besides, existing studies have shown that inconsistent intuitionistic fuzzy sets, picture fuzzy sets and neutrosophic fuzzy sets can be represented by IVIFS [31].
In MAGDM problems, the determination of attribute weights has long been the focus of research. Many methods can be employed to determine the attribute weights, and the entropy weight method considered one of the more important approaches. Therefore, in recent years, entropy has been widely used in IFS research. Burillo and Bustince [32] combined entropy with IFS, and proposed the concept of intuitionistic fuzzy entropy (IFE). Jin et al. [33] then proposed the interval-valued intuitionistic fuzzy continuous weighted entropy, and established an optimization model in which the minimum entropy determines the attribute weights. The effectiveness of the proposed method was verified through an emergency risk management evaluation. Li et al. [34], and Tong and Yu [35] developed models that integrates TOPSIS and interval-valued intuitionistic fuzzy cross-entropy to evaluate alternatives. Chen [36] proposed an analysis framework model that integrates gray relational analysis, with IFE, and TOPSIS to evaluate MAGDM problems. Ding and Wang [37] developed a scoring function that processes the IFE, and used this to determine attribute weights, before applying TOPSIS to rank all the alternatives. Yuan and Luo [38] established an optimization model with the goal of minimizing the IFE value to determine the weights, and used evidential reasoning to directly aggregate decision information into intuitionistic fuzzy values, before finally using TOPSIS and the Hamming distance to rank all alternatives. Narayanamoorthy et al. [39] proposed the interval-valued intuitionistic hesitant fuzzy entropy to determine attribute weights, and used the VIKOR method to rank alternatives. Table 1 summarizes the previous research on the entropy method in different linguistic environments.
Results of existing research in different linguistic environments
Results of existing research in different linguistic environments
Based on the above literature review, although there have been many studies on interval-valued intuitionistic fuzzy entropy, no research has yet developed anything similar to the proposed IVIPLEW method. Additionally, most previous studies use the entropy weight method or some other method to determine the objective criteria weights, and use other multi-criteria decision-making methods to rank alternatives. This may lead to a large gap between the determined weights and the actual situation.
Some basic definitions and operations of linguistic operators, IVIPL sets, and the entropy weight method are reviewed in this section.
Linguistic operators
(1) If α > β, then h α > h β ;
(2) If α > β, then max { h α , h β } = h α ;
(3) If α > β, then min { h α , h β } = h β ;
(4) There is a negative operator neg (h α ) = h-α.
Consider the function φ : h
α
= φ (α), where φ (α) is a monotone increasing function of α. To facilitate calculation and avoid any loss of decision information, a continuous linguistic variable set is necessary. Let
(2) λh α = h λα , λ > 0.
Let
Let
Then
Here, ω
j
= (ω1, ω2, ⋯ , ω
m
)
T
is a weight vector corresponding to the linguistic type data set {l
α
1
, l
α
2
, ⋯ , l
α
m
}, ω
j
⩾ 0 (j = 1, 2, ⋯ , m), and
On the basis of definition 4, combining intuitionistic linguistic numbers and pure linguistic variables, Peng and Ye [46] proposed the concept and arithmetic of interval-valued intuitionistic pure linguistic sets (IVIPLSs).
Here, μ
B
(x) and ν
B
(x) represent the degree of membership and non-membership of the linguistic variable value hα(x), respectively. B can also be written as B ={ hα(x), (μ
B
(x) , ν
B
(x)) |x ∈ X }. The general form of an interval-valued intuitionistic pure linguistic number (IVIPLN) is abbreviated as hα(x), ([a, b] , [c, d]), where [a, b] ⊂ [0, 1], [c, d] ⊂ [0, 1], b + d ⩽ 1. Let θ1 = hα(x1), ([a1, b1] , [c1, d1]) and θ2 = hα(x2), ([a2, b2] , [c2, d2]) be any two interval-valued intuitionistic pure linguistic variables. Then, the following properties can be obtained.
Here, h-θ(x) ⩽ S (θ) ⩽ hθ(x), and obviously, a greater value of S (θ), implies a greater value of θ.
Entropy was first proposed by Shannon [47], and has been widely utilized in social economy, engineering technology and other fields [48–52]. The basic idea of the entropy weight method (EWM) is to determine the objective weight according to the variability of certain criteria. In general, if the information entropy of the criteria is lower, these criteria play a greater role in the comprehensive evaluation, and therefore have higher weighs. The calculation procedure of the EWM is as follows.
Step 1. Consider the decision matrix A = (x
ij
) n×m obtained for n alternatives and m attribute indicators.
Step 2. Benefit-type criteria and cost-type criteria can be normalized using Equations (12) and (13), respectively. The normalized matrix
Step 3. Calculate the entropy of each criterion.
Step 4. The entropy weight value of the jth criterion ω
j
can be obtained as
In this section, based on the linguistic operator, IVIPLS, and EWM, a new method is proposed. In MAGDM problems, experts may not be able to provide any evaluation information for certain attributes. Therefore, this paper considers a complete information linguistic decision matrix and an incomplete information linguistic decision matrix.
The attribute weights are determined by the IVIPLEW method. The numerical values corresponding to the linguistic terms used by the experts are listed in Table 2.
Numerical values corresponding to linguistic terms used by experts
Numerical values corresponding to linguistic terms used by experts
Note: EP, VP, SP, F, SG, VG, and EG represent Extremely Poor, Very Poor, Slightly Poor, Fair, Slightly Good, Very Good, and Extremely Good.
Step 1. Obtain a complete linguistic decision matrix L. Each expert DM
i
(1 ⩽ i ⩽ n) gives a judgment for attribute C
j
(1 ⩽ j ⩽ m) using the linguistic terms in Table 2.
Step 2. Calculate the score function value S (θ) of θ
ij
in matrix L using Equation (10), and then compute the score function matrix L1 as
where
Step 3. Compute the normalized score function matrix L1 and the normalized matrix L2.
By combining linguistic variables using Equations (12), and/or (13), interval-valued pure linguistic normalization equations can be obtained.
The normalization of the benefit-type criteria is as follows:
The normalization of the cost-type criteria is as follows:
The normalized matrix
Step 4. The linguistic entropy H
j
can be obtained as
Specifically, if
Step 5. The interval-valued intuitionistic pure linguistic entropy weights can be obtained as
Step 6. The comprehensive linguistic information value of each alternative is calculated using Equations (5) and (6), and then all alternatives are ranked and the best one is selected.
The algorithm flow of the IVIPLEW method for a complete linguistic decision matrix is shown in Fig. 1. Obviously, the time complexity of the presented algorithm is O(n).

Algorithm flowchart.
Due to the uncertainties in the subjective judgment of attributes by experts, it is difficult to assign a specific linguistic judgment to an attribute. Therefore, several missing values appear in the linguistic decision information matrix. Failure to handle the missing values properly will affect the final evaluation results. Thus, it is necessary to deal with MAGDM problems in which some values are missing in a scientific and reasonable manner. A practical method is proposed to supplement missing values.
Step 1. An incomplete linguistic decision matrix L is obtained, in which the missing values are indicated by ɛ. The incomplete decision matrix can be represented as
Step 2. According to the incomplete linguistic information matrix, and from Equation (9), the expected value of the IVIPL is calculated using the equation
The proposed method takes the weighted arithmetic average value of the index evaluation into account. Compared with other methods, this reduces the volatility of the data and prevents other factors from having an undue influence. Based on the description of the proposed MAGDM method, the procedure of the complete and incomplete IVIPLEW method is as shown in Fig. 2.
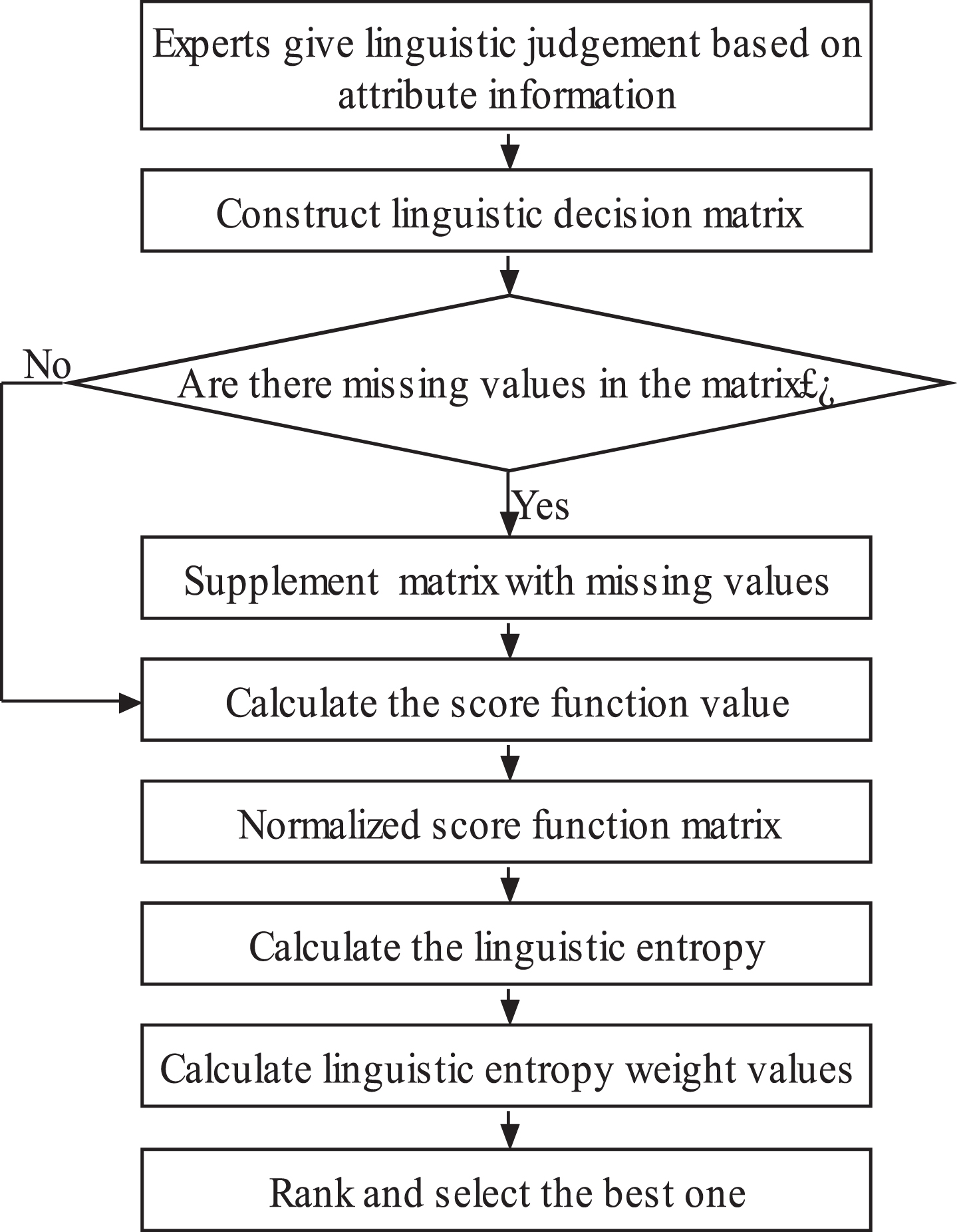
Flow chart of the proposed method.
In this section, a practical case study will be used to illustrate the practicality and effectiveness of the IVIPLEW method in dealing with MAGDM problems.
Case description
The decision-making background of this case study comes from an information technology company, which we refer to as company C. Company C is a comprehensive high-tech enterprise focusing on computer information system integration, application system development, operation and maintenance services, and providing industry solutions. The company is committed to providing customers with professional services such as information planning and design, management consulting, and industry solutions. In addition, it provides smart government, smart education, smart camp, smart manufacturing, smart medical, and other solutions using cloud computing and big data as the core.
As the development scale of company C has continued to expand in recent years, it has faced unprecedented development opportunities. Unfortunately, the company has management problems that are insufficient to meet the current challenges. First, the company has not established an effective system for evaluating and selecting talented staff. Second, changes in the environment have forced the company to speed up the construction of its management system. Finally, the company’s organizational system is not yet perfect. Therefore, the company intends to form a new department to meet the current management challenges. Each member of the senior management of company C believes that choosing the right department manager will effectively improve the current shortcomings. Therefore, the objective of this case study is to help company C to select a suitable department manager from several candidates.
To perform effective talent selection, the human resources department of company C has developed a series of evaluation processes that include a written test and an interview. During the interview stage, an evaluation team of five experts controls and implements the whole process of talent selection. Three of the five experts are currently in the human resources department, with the chief executive officer and chief operating officer making up the evaluation team. The evaluation criteria for candidates are professional skills (C1), management skills (C2), computer skills (C3), safety consciousness (C4), and communication skills (C5). The raw dataset was formed by the five experts based on the candidates’ resumes and interview performance. Officials from the human resources department will make the final decision based on various evaluation results.
Selection process
Five candidates participated in the assessment. As the experts cannot provide accurate evaluation results for each criterion, they used the linguistic terms in Table 2 to measure the degree of matching. These five criteria are expressed as C ={ C1, C2, C3, C4, C5 }, the experts are referred to as E ={ E1, E2, E3, E4, E5 }, and the five candidates are denoted as A ={ A1, A2, A3, A4, A5 }.
Step 1. Obtain the IVIPL variable decision matrices, as shown in Tables 3–7.
IVIPL variable of evaluation results for A1
IVIPL variable of evaluation results for A1
IVIPL variable of evaluation results for A2
IVIPL variable of evaluation results for A3
IVIPL variable of evaluation results for A4
IVIPL variable of evaluation results for A5
Step 2. Supplement any incomplete decision information matrices. Take ɛ52 as an example. The expected IVIPL value is calculated using Equation (24), from which we obtain the missing value ɛ52 = 〈h2, ([0.527, 0.668] , [0.141, 0.265]) 〉. Similarly, the missing value ɛ24 = 〈h2.5, ([0.654, 0.755] , [0.119, 0.221]) 〉 is obtained for candidate A3. Therefore, after supplementing the missing values of ɛ52 and ɛ24, complete decision matrices have been obtained.
Step 3. Use Equation (10) to calculate the score function value for each attribute. The final results are listed in Tables 8–12.
Score function values of all attributes for candidate A1
Score function values of all attributes for candidate A2
Score function values of all attributes for candidate A3
Score function values of all attributes for candidate A4
Score function values of all attributes for candidate A5
Step 4. As all attributes are benefit-type criteria, Equation (19) is used to normalize the score function values. The results are shown in Tables 13–17. These Tables show the normalized results for the candidates.
Step 5. The linguistic entropy can be calculated using Equation (21), and then the linguistic entropy weight is given by Equation (22). Table 18 shows the results with respect to the linguistic entropy and the linguistic entropy weight.
Normalized result for candidate A1
Normalized result for candidate A2
Normalized result for candidate A3
Normalized result for candidate A4
Normalized result for candidate A5
Linguistic entropy and linguistic entropy weight of each attribute
Step 6. Calculate the final evaluation result using Equation (5). Table 19 shows the results.
Evaluation results
As can be seen from Table 19, A4 ≻ A5 ≻ A3 ≻ A2 ≻ A1, so the optimal candidate is A4.
The effectiveness of the IVIPLEW method proposed in this paper is now verified by comparing its performance that of the IVIPL information aggregation method. In addition, a sensitivity analysis is carried out to verify the robustness of the proposed method.
Comparative analysis
To highlight the advantages and effectiveness of the methods proposed in this paper, a comparative study was conducted. First, the proposed method is compared with other IVIPL set calculators, and then it is compared against three well-known MAGDM methods, namely TOPSIS, Interactive Multi-criteria Decision-Making (known by its Portuguese acronym TODIM), and Weighted Aggregated Sum Product Assessment (WASPAS).
Peng and Ye [46] proposed a method for aggregating IVIPL information. The ordered weighted average operator has been used in many studies [53]. In this paper, the IVIPL ordered weighted average (IVIPLOWA) operator and IVIPL ordered weighted geometric (IVIPLOWG) average operator are used to aggregate the decision matrix. After using the IVIPLOWA and IVIPLOWG operators to aggregate the decision matrix, Equation (10) is applied to calculate and rank the score function values. The comparative results are presented in Table 20.
Candidate sorting results given by different methods
Candidate sorting results given by different methods
Note: * represents the existing research methods reference.
It can be seen from Table 20 that the optimal ranking result obtained given by the IVIPLOWA operator is A4 ≻ A5 ≻ A3 ≻ A2 ≻ A1, that given by the IVIPLOWG operator is A4 ≻ A3 ≻ A5 ≻ A2 ≻ A1, and that given by the IVIPLEW method is A4 ≻ A5 ≻ A3 ≻ A2 ≻ A1. Therefore, the three methods give the same optimal decision result, that is, the best candidate is A4, which demonstrates the effectiveness of the IVIPLEW method.
Table 21 compares the proposed method with TOPSIS, TODIM, and WASPAS to verify its effectiveness.
Comparison results against three other MAGDM methods
Note: * represents the existing research methods reference.
Although the MCDM methods in Table 21 have different principles, they all obtain consistent ranking results. TOPSIS calculates the distance between the evaluation object and the ideal solution, with smaller distances to the optimal solution indicating better alternatives. The TODIM method reflects the different preferences of decision-makers for the benefits and losses that may be brought about by the evaluation attributes, and ranks them by aggregating the advantages of each alternative. However, the decision-making preference parameter may impact the decision-making results. Therefore, in the TODIM method, the decision-maker needs to provide a reasonable decision preference parameter. The WASPAS method combines two well-known MAGDM methods (namely, the weighted product and weighted sum models). However, in the process of aggregating these two models, it is also necessary to consider the decision-makers’ preferences. The IVIPLEW method proposed herein not only considers the decision-makers’ psychological decision-making preference for the evaluation object, but also directly calculates the attribute weights.
The weights obtained by the IVIPLEW method are relatively objective, but seldom consider the experience and professional knowledge of decision-makers. Reasonable attribute weights should consider the subjective judgment of experts and objective factors. Therefore, Equation (25) is used to provide a comprehensive consideration of the subjective weighting of experts and the weight obtained from the evaluation.
The weights assigned by the experts to each attribute are
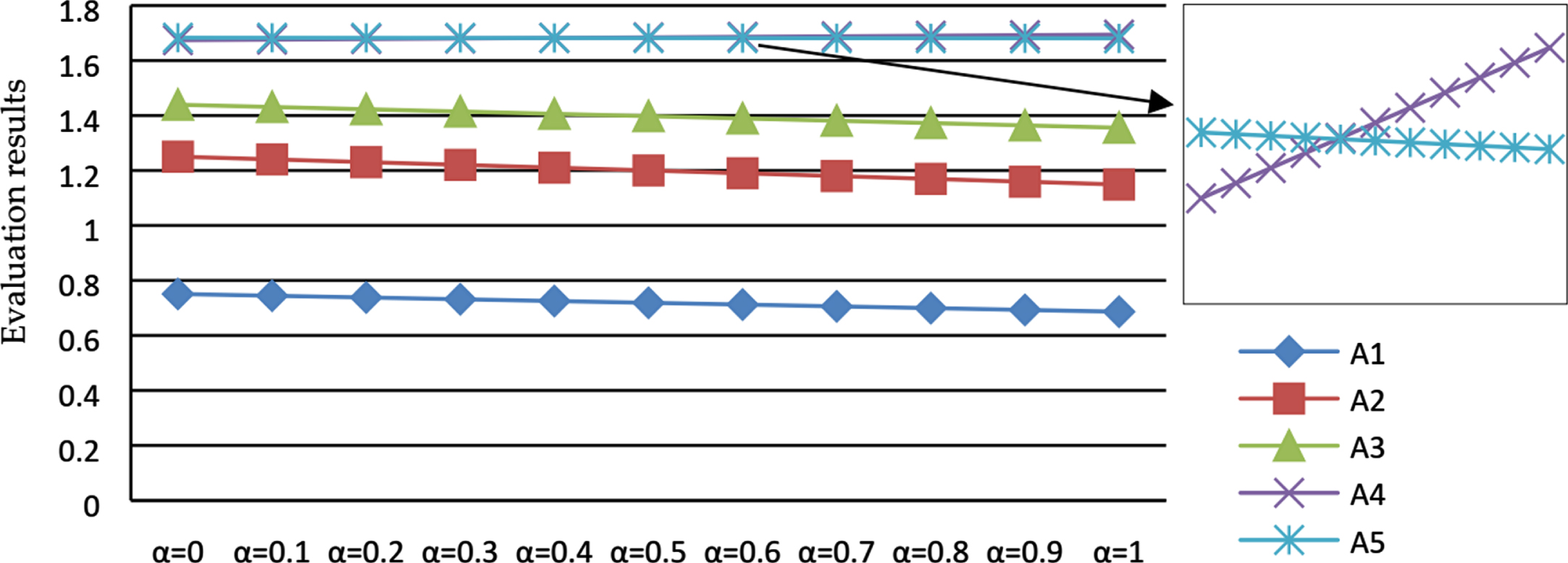
Evaluation results for different combinations of α.
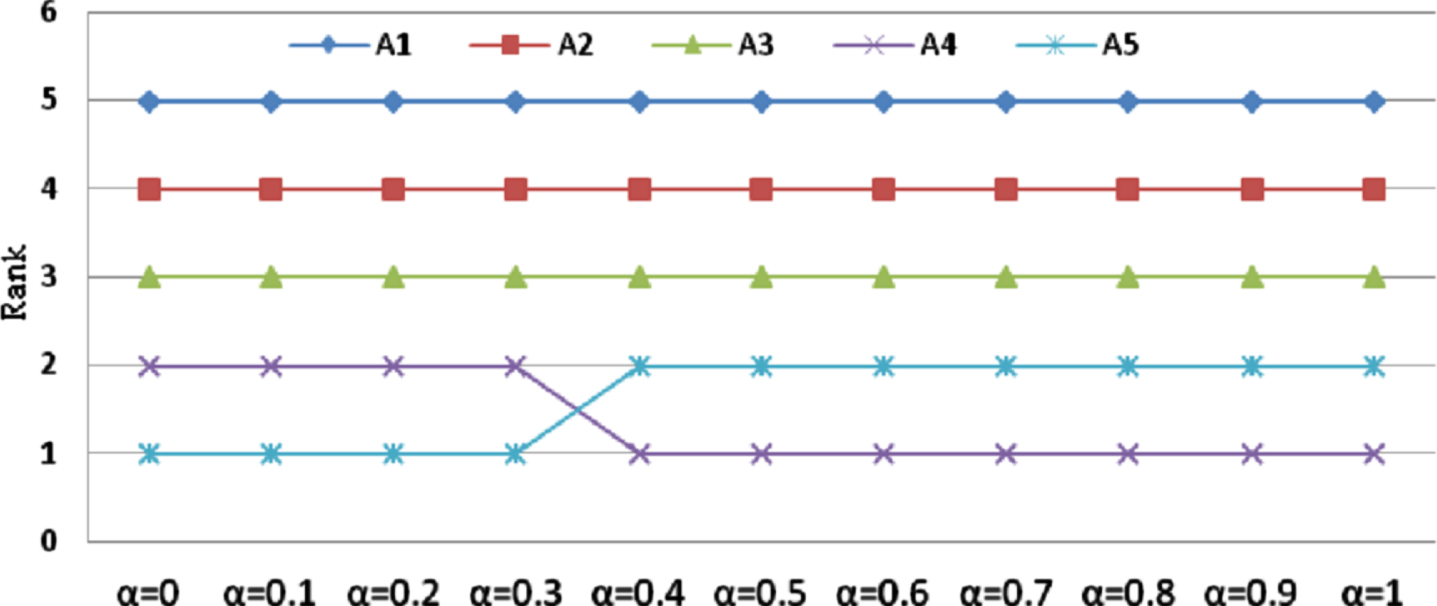
Ranking for different combinations of α.
As can be seen from Fig. 3, only the evaluation result of A4 increases as α increases. This indicates that the attribute weights obtained by IVIPLEW have a positive effect on A4, whereas the evaluation results of A1, A2, A3, and A5 may decrease as α increases, which shows that the subjective attribute weights assigned by experts have a positive effect on A1, A2, A3, and A5. In addition, it can be seen from Fig. 4 that when α is in the interval [0, 0.4), the best candidate is A5, and when α is in the interval 0.4, 1], the best choice is A4. Therefore, when choosing a different preference factor α, the best selection may change. Further analysis indicates that because A4 and A5 have similar final evaluation results, they are sensitive to the attribute weights, whereas candidates A1, A2, and A3 are some way behind the other two, so changes in the weights have no effect on the ranking of the evaluation results for these three candidates.
To reflect the decision-making preferences of the decision-makers more accurately, this paper uses IVIPL to express the decision-makers’ evaluation terms, and expands the entropy method in the IVIPL environment. Compared with other MAGDM methods, IVIPLEW has the following advantages. The proposed method directly reflects the decision-making preferences of the decision-makers. Due to the complexity of the decision-making environment, there may be some uncertainty about the linguistic evaluation terms given by the evaluation object. Therefore, we use IVIPL terms to express this uncertainty, effectively reflecting the decision-makers’ decision preference for the evaluation object. The proposed method is an extension of the entropy method in the IVIPL environment. Therefore, this method can effectively determine attribute weights and rank alternatives. In addition, the proposed method effectively reduces linguistic information loss by the decision-makers. The proposed method gives stable results. Table 21 verifies the effectiveness of the method proposed in this paper. It can be seen from Table 18 that the attribute weights of each alternative are different, and not all alternatives have the same attribute weights. Therefore, the method proposed in this paper reduces the variations in the decision results caused by changes to the attribute weights, thus providing more stable and reliable results.
Management implications
Although the proposed method can adapt to complex decision-making environments, in practical applications, attention should be paid to its limitations. In view of this, some management implications are now put forward for decision-makers who wish to use the proposed method.
First, the method proposed in this paper handles situations where there is a lack of decision information. However, when there is a lot of decision information missing, the results obtained by the proposed method may not be optimal. Therefore, IVIPLEW is only suitable when a small amount of decision information is missing. In the context of large amounts of decision-making information being unavailable, it is necessary to develop other methods to fill the data gaps.
Second, this paper has not considered the impact on the evaluation of the different professional backgrounds and practical experience of the experts. Therefore, the weights assigned to each expert are the same. However, in practice, the knowledge background and experience of each expert needs to be considered. Thus, decision-makers may wish to assign different weights to experts to reduce the decision-making risks.
Conclusions
As MAGDM problems are widely encountered in fields such as economics, management, engineering, and society, there have been an increasing number of studies on MAGDM methods. A new MAGDM method has been proposed in this paper based on IVIPL and EWM. Owning to the uncertainty of the decision-making environment, the ambiguity of decision-makers’ thinking, and the complexity of decision-making problems, there are many scenarios in which decision-making information cannot be expressed with accurate numerical values. Besides, differences in decision-makers’ professional knowledge may make it difficult to judge various attributes, which will lead to a lack of decision attribute values. The proposed IVIPLEW method can handle situations in which attribute values are missing, employing IVIPL expectations to complement the missing values. This method of handling missing values not only considers the experts’ expectations, but also prevents fluctuations in linguistic variables from influencing the decision results, which reinforces its effectiveness. With respect to MAGDM problems, an analysis framework for the IVIPLEW method was proposed. To illustrate the practicality and effectiveness of the proposed method, a real case study was introduced, and the results were found to be quite satisfactory. The IVIPLEW method was then compared with IVIPL information aggregation to verify its stability, and a sensitivity analysis was conducted to illustrate its robustness. Overall, the results presented in this paper show that the proposed method is highly applicable to MAGDM problems.
There are several limitations of the IVIPLEW method that need to be solved in future research. For example, a score function is used to convert interval-valued linguistic information into a definite numerical linguistic. This process may lead to the loss of some decision information. Therefore, future research will attempt to reduce the loss of decision information as much as possible, as this is crucial for MAGDM problems. Additionally, expanding the EWM in different linguistic environments will enable the development of more practical multi-attribute decision-making methods, such as probabilistic linguistic sets, hesitant fuzzy sets, and Pythagorean fuzzy linguistic sets. Considering the consensus of experts is also a very interesting research topic. Finally, the effectiveness of the proposed method requires further verification in scenarios where there is too much decision-making information missing.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China (grant no. 71904062), Fundamental Research Funds for the Central Universities (grant no. 21618317). The authors are grateful for the valuable comments and suggestion from the respected editor and reviewers. Their valuable comments and suggestions have enhanced the strength and significance of this paper.