
Abstract
It is difficult for many classic classification methods to consider expert experience and classify small-sample datasets well. The evidential reasoning rule (ER rule) classifier can solve these problems. The ER rule has strong processing and comprehensive analysis abilities for diversified mixed information and can solve problems with expert experience effectively. Moreover, the initial parameters of the classifier constructed based on the ER rule can be set according to empirical knowledge instead of being trained by a large number of samples, which can help the classifier classify small-sample datasets well. However, the initial parameters of the ER rule classifier need to be optimized, and choosing the best optimization algorithm is still a challenge. Considering these problems, the ER rule classifier with an optimization operator recommendation is proposed in this paper. First, the initial ER rule classifier is constructed based on training samples and expert experience. Second, the adjustable parameters are optimized, in which the optimization operator recommendation strategy is applied to select the best algorithm by partial samples, and then experiments with full samples are carried out. Finally, a case study on a turbofan engine degradation simulation dataset is carried out, and the results indicate that the ER rule classifier has a higher classification accuracy than other classic classifiers, which demonstrates the capability and effectiveness of the proposed ER rule classifier with an optimization operator recommendation.
Keywords
Introduction
Currently, with the amount of data growing explosively in many application fields, quickly and accurately mining valuable information has become a challenge, and data analysis has become a research hotspot [1]. Data analysis, which includes data mining, predictive analysis, visual analysis, semantic analysis, data quality management, etc., aims to acquire knowledge from data. As an important part of data analysis, classification is applied in a wide range of fields, especially in complex systems, such as pattern recognition, medical diagnosis, and fault diagnosis. It is vital to carry out classification research because of its wide range of applications.
To date, many classic classifiers have been proposed, such as the decision tree (DT), support vector machine (SVM), artificial neural network (ANN), classification based on association (CBA), and Bayesian classification. DT is a typical classifier that applies induction algorithms to generate readable rules and decision trees for classification [2, 3]. SVM follows the minimization criterion of structural risk and adopts mathematical methods and optimization techniques [4, 5]. ANN simulates the human neural network to process information, and it possesses strong fault tolerance and self-learning function [6, 7]. CBA realizes classification by generating classification association rules [8, 9]. The Bayesian classifier trains sample subsets with class labels, generalizes the classification functions, and generates classifiers to realize the classification of unclassified samples [10, 11]. These classic classification approaches have achieved some success in solving the classification of complex systems; however, these classifiers have several common disadvantages.
In the process of solving practical problems, the existing classification methods still encounter some challenges: (1) In the analysis and processing of data in some fields, expert experience and knowledge are required. For instance, the fault diagnosis of large equipment should combine the experience and professional knowledge of professional technicians. Expert experience and knowledge can also significantly improve interpretability. However, most of the existing classification methods are purely data-driven methods, which are difficult to combine with expert experience and knowledge. (2) Existing classification methods cannot classify small-sample datasets well since purely data-driven methods need large datasets to set the parameters. The sample size of some important cases is small because large numbers of training samples cannot be obtained due to the high cost or harsh conditions. Therefore, it is difficult to achieve the high-precision classification of small-sample datasets, and it is difficult to train the parameters with a small number of samples.
Considering the above problems, the evidential reasoning rule (ER rule) [12] developed from Dempster-Shafer (D-S) theory [13, 14] performs well in classification problems. As a more general Bayesian rule, the ER rule has strong processing and comprehensive analysis abilities for diversified mixed information, such as subjective/objective and qualitative/quantitative information, and can effectively solve problems with expert experience [15]. In addition, the initial parameters of the classifier constructed based on the ER rule can be set according to empirical knowledge, which can help the classifier classify small-sample datasets well. Therefore, a classifier based on the ER rule is proposed to perform classification in this study.
However, the initial ER rule classifier may not be able to accurately perform classification due to the assumptions of the initial values of the adjustable parameters. To achieve a higher classification accuracy, the initial parameters need to be optimized. That is, parameter learning by training samples is necessary when training samples are available. Thus, choosing the best optimization algorithm to achieve high efficiency is a challenge. The problem of selecting the best algorithm from among various feasible algorithms is common in theoretical research, especially regarding the selection of optimization algorithms. To make the right choice, the commonly adopted solution is to conduct complete experiments based on complete samples for all candidate algorithms individually, evaluate the algorithms by comparing the results, and finally choose the best algorithm. Although this approach can accurately select the best algorithm, it takes a long time to perform experiments with full samples, resulting in low efficiency. Considering this problem, an optimization operator recommendation strategy is developed in this study [16]. The core idea of the optimization operator recommendation is to select the best algorithm with partial samples and then perform experiments with full samples, which greatly improves the efficiency.
By comprehensively analyzing classification problems, an ER rule classifier with an optimization operator recommendation based on the original ER rule classifier [17] is proposed in this paper. First, the initial classifier is constructed by training data. Then, the optimization operator recommendation is applied to parameter optimization to select the best optimization algorithm with partial data. Finally, the optimized ER rule classifier can classify data with high accuracy.
The remainder of this paper is organized as follows. The basic concept of the ER rule and the construction of the original ER rule classifier are introduced in section 2. Section 3 describes the optimization steps of the ER rule classifier in detail, proposes the optimization operator recommendation strategy, and describes the process of the ER rule classifier and optimization operator recommendation. In section 4, the feasibility and effectiveness of the proposed ER rule classifier and the optimization operator recommendation strategy are verified by using a turbofan engine degradation simulation dataset. Finally, this study is concluded in section 5.
The basics of the ER rule
This section briefly reviews the development of the ER rule and the relevant research based on the ER rule and introduces the reasoning algorithm of the ER rule, which constitutes the theoretical basis of this study. Then, the modeling process of the ER rule classifier, which is consistent with that proposed by Xu et al. [17], is described. The process can be divided into three steps: evidence acquisition, reliability and weight calculation, and combination of activated evidence.
The basic concept of the ER rule
The concept of ER first appeared when Gordon and Shortliffe applied D–S theory to evidence-aggregation processes in a hypothesis space [18]. In 2002, to address both numerical data and qualitative information with uncertainty in multiple attribute decision analysis (MADA), Yang and Xu proposed an ER approach supporting decision analysis, the kernel of which is the ER algorithm developed based on D-S theory [19, 20].
The kernel of ER is D-S theory, while the kernel of D-S theory is Dempster’s rule, which originates from probability theory and constitutes the inference process of conjunctive probabilistic [21–23]. Dempster’s rule generalizes Bayes’s rule and was initially used as the only evidence combination rule (ECR) to combine completely reliable independent evidence. Dempster’s rule can achieve the combination of completely reliable evidence, but it also has shortcomings: (1) Dempster’s rule lacks definition and cannot be applied to the special case where two pieces of evidence completely conflict, such as the case where two pieces of evidence support different propositions. (2) Dempster’s rule assumes that every piece of evidence is completely reliable and can reject any proposition. This means that if a piece of evidence does not support a proposition, the proposition is completely excluded. In other words, Dempster’s rule only accumulates consensus support, and if a proposition is opposed by any evidence, regardless of whatever support it may receive from any other evidence, Dempster’s rule will completely reject the proposition.
Considering the existing problems and deficiencies of Dempster’s rule, on the basis of Dempster’s rule, Yang et al. proposed the ER rule, a new rule combining the weight and reliability of multiple pieces of independent evidence [12]. Yang proposed a new concept of weighted belief distribution (WBD) and extended it to weighted belief distribution with reliability (WBDR) to represent the characteristics of the belief distribution (BD) introduced in D-S evidence theory. The ER rule is obtained by the orthogonal sum of WBDs and WBDRs. The most important property of the ER rule is that it constitutes a general conjunctive probability inference process or a generalized Bayesian inference process. In addition, when the reliability equals the weight of evidence and all the weight of evidence is normalized, the original ER algorithm is a special case of the ER rule. When every piece of evidence is completely reliable, Dempster’s rule is also a special case of the ER rule. The ER rule improves Dempster’s rule by identifying new reliability perturbations to combine highly conflicting or completely conflicting yet completely reliable pieces of evidence.
Since it was proposed, the ER rule has shown its excellent performance in various applications. Xu et al. solved the fusion decision problem of uncertain fault characteristic information and the data classification problem based on the ER rule [24]. Cheng et al. applied the ER rule to evaluate the network security situation [25]. Yang studied the fault diagnosis of high-speed train bogies based on the ER rule and hierarchical classification method [26]. Gao and Xu have applied ER rule to aggregating financial analysts’ opinions for decision making in stock investment [27].
Reasoning algorithm of the ER rule
Θ ={ θ1, θ2, …, θ
N
} is a frame of discernment, which is a set of mutually exclusive and collectively exhaustive proposition. The power set of Θ is composed of 2
N
subsets of Θ [12, 28]:
A piece of evidence e
j
is defined as follows:
In ER rule, a reliability r
j
and weight w
j
are considered for each piece of evidence. The belief distribution of evidence with reliability and weight is shown as follows:
When multiple pieces of independent evidence are integrated, the combined belief degree to jointly support the proposition can also be expressed as follows:
Evidence acquisition
First, likelihood normalization is applied to obtain evidence from the training sample dataset. The relation between each attribute and each class is obtained from the input data to generate the set S:
The relationship between attribute x
i
and class y needs to be approximately transformed into the relationship between the specific referential values
Thus, a sample pair
Therefore, a piece of evidence
More precisely,
The reliability R ={ r
i
∣ i = 1, 2, …, M } reflects the ability of the information that generates the evidence to accurately solve specific problems, and it can be considered that the reliability of the evidence can represent the classification ability of its corresponding attributes. Therefore, the reliability r
i
of attribute x
i
can be defined as follows [17]:
For a certain sample with M attribute values
After all the M pieces of evidence about M attributes have been obtained by Eqs. (13-15), the ER rule in Eqs. (5-7) can be used to combine the M pieces of evidence with weight and reliability, and the fusion results are shown in Eq. (16):
According to the results O (x k ), sample x k belongs to the class y n that possesses the maximum belief pn,e(m).
In this section, the parametric optimization model of the ER rule classifier is introduced, and then an optimization operator recommendation strategy is proposed to select the optimization algorithm to optimize the adjustable parameters of the initial ER rule classifier. Finally, the overall process of the ER rule classifier with an optimization operator recommendation strategy is described.
Parametric optimization model of ER rule classifier
(1) Parametric optimization model
The construction of the initial ER rule classifier has been completed by 2.3.1-2.3.3 sections. The initial ER rule classifier may not be able to accurately model the complex causal relationship between the attributes x
i
= (i = 1, …, M) and the actual classes due to the initial value assumptions of the adjustable parameters. Therefore, it is very important to train these adjustable parameters by the sample dataset to improve the classification accuracy of the classifier. The parametric optimization model to optimize the adjustable parameters is shown as Eqs.(17-18).
I. The adjustable parameters to be optimized
The parameters of the ER rule classifier include the referential values of attributes
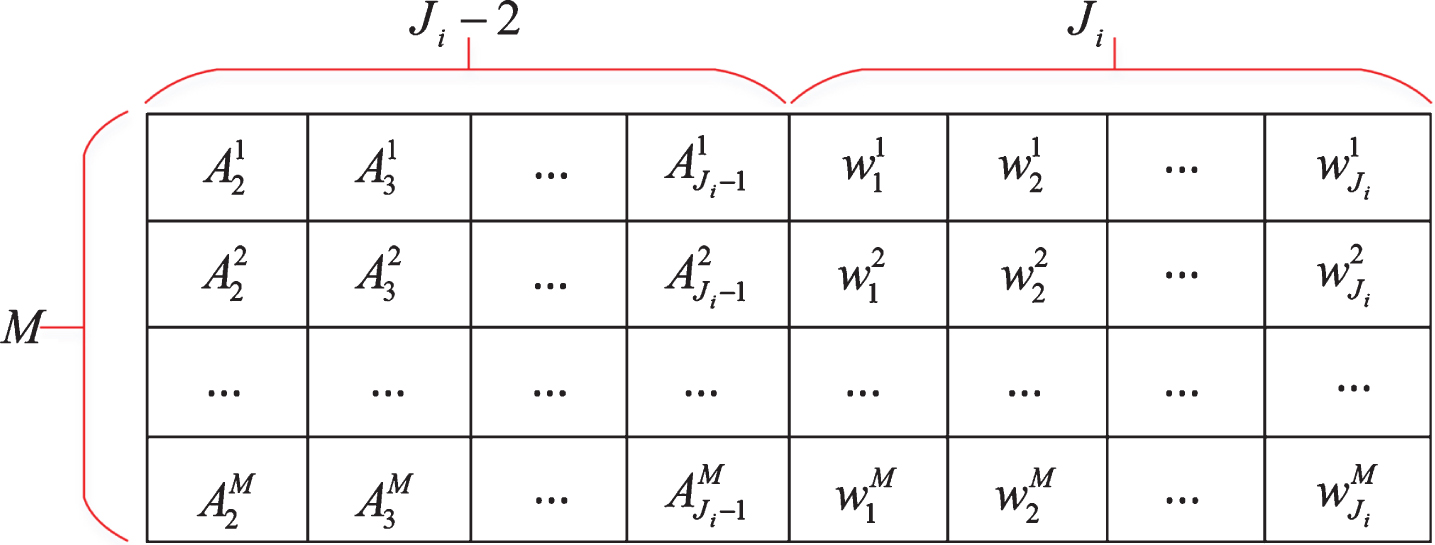
The adjustable parameters of the ER rule classifier
II. The objective function
To optimize the parameters, Xu proposed the objective function
(2) The optimization algorithms
Due to the large number of optimization parameters, it is easy to fall into local optimum. Therefore, to avoid the local optimum solution, we use a global optimization algorithm. This study applies intelligent optimization algorithms to optimize the parameters globally, while Xu utilizes SLP (sequential linear programming) to obtain the local optimal solution [17]. The encoding of parameters to be optimized is shown in Fig. 2.

The encoding of parameters
Since which optimization algorithm has the best optimization effect is still uncertain, three swarm intelligence optimization algorithms are chosen as candidates: particle swarm optimization (PSO) [29], the genetic algorithm (GA) [30], and the seeker optimization algorithm (SOA) [31]. The final optimization algorithm for the ER rule classifier is selected by the optimization operator recommendation strategy.
In practical applications, it is common to choose the algorithm that is most suitable and can improve the problem solving ability of the research method. To make the right choice, the commonly adopted method is to conduct complete experiments for all candidate algorithms in turn, evaluate the advantages and disadvantages of various algorithms by comparing the results obtained from specific experiments, and finally choose the best algorithm as the algorithm for the research method.
The general method for selecting the best algorithm uses all the sample data for complete experiments. Although the results obtained from experiments based on complete data are more accurate and can make the correct algorithm selection, the selection process involves a large workload and low efficiency, especially when the sample size is large. Therefore, it is necessary to propose a method to improve the efficiency of algorithm selection.
Considering the above problems, this study proposes an optimization operator recommendation strategy. The main idea is as follows: first, partial samples are randomly selected from the whole sample dataset, and the size of the partial sample dataset can be determined according to specific problems and scenarios. Then, all candidate algorithms are used to conduct experiments on partial samples, and the experimental results under different algorithms are obtained. Next, the experimental results are compared, and the optimal algorithm is selected as the algorithm used in the research method. Finally, the whole sample dataset is tested with the selected optimization algorithm. A schematic diagram of the optimization operator recommendation strategy is shown in Fig. 3.

Schematic diagram of the optimization operator recommendation strategy
The randomly selected partial data can reflect the characteristics of the entire sample dataset and replace the complete sample set to select the most appropriate algorithm and can effectively improve the efficiency, which can also be verified by experiments.
As shown in Fig. 3, compared with the general algorithm selection method, the proposed optimization operator recommendation strategy does not require all algorithms to conduct experiments on the whole sample dataset, which can greatly reduce the amount of data to be processed and effectively improve the work efficiency.
By applying the optimization operator recommendation strategy to the parameter optimization process of the ER rule classifier, the best optimization algorithm can be selected, and the best classification result can be obtained effectively. This process consists of three parts: acquisition and preprocessing of experimental data, training of the ER rule classifier, and testing of the ER rule classifier. The training of the classifier also comprises the construction of the initial classifier and the optimization of adjustable parameters. The test of the ER rule classifier is to classify the test dataset by the classifier, and the classification accuracy reflects the performance of the classifier. A schematic diagram of the whole process is shown in Fig. 4.

The process of the ER rule classifier and optimization operator recommendation
First, the experimental dataset is obtained from public datasets or from actual experimental operations, after which the data need to be preprocessed. Data preprocessing includes standardization of the data format, the elimination of abnormal data, the correction of errors, and determining the training and testing datasets.
According to the experimental data and the evidence acquisition method in section 2.3.1, each piece of evidence
The reliability of the attribute and the initial weight of the evidence can be determined by Eq.(12) described in section 3.1.2. According to belief value interval of different samples on each attribute and the number of samples in each interval, the individual classification ability of each attribute is clarified, the reliability of each attribute is generated, and the initial weight of evidence is determined by the reliability.
The above steps have generated evidence with reliability and weight, which can be combined to classify the test dataset. In other words, the initial ER rule classifier has been constructed. The evidence from the training dataset can generate the belief distribution of the estimated classes for each input by activating and integrating the evidence, and the class with the highest belief is determined to be the class of the input. By comparing the classification results obtained by the initial classifier with the actual results, the classification accuracy of the unoptimized classifier can be obtained.
According to the constraint conditions and objective function described in section 3.1.4, the initial classifier can be globally optimized based on various intelligent optimization algorithms. For instance, PSO, GA, SOA, and other classic intelligent optimization algorithms can be applied to optimize parameters. In the process of optimization, new reliabilities and weights of evidence are generated, which will generate a new classification accuracy for the training dataset and improve the classification ability of the ER rule classifier.
After step 2, the adjustable parameters of the ER rule classifier have been optimized by various optimization algorithms; that is, the optimized ER rule classifiers are obtained. In this step, the optimized classifiers are applied to classify the test dataset, and the results obtained will be used as the criterion to select the best optimization algorithm.
By analyzing the classification results of the test dataset, the best optimization algorithm with the highest accuracy is selected as the ER rule classifier’s optimization algorithm, after which the optimized ER rule classifier is constructed. The result obtained by the optimized ER rule classifier is the final result of the dataset.
In this section, the experimental steps and data information are first explained in detail, and second, the dataset is classified based on the optimization operator recommendation strategy. Then, experiments with complete datasets are conducted to verify the feasibility and effectiveness of the optimization operator recommendation strategy, and finally, the experimental results are analyzed.
Turbofan engine degradation simulation data
As the engine is the core of any large piece of equipment, the health of the engine is crucial to the operation of the equipment. Determining the engine’s health and then predicting potential failures is essential to improve the reliability, safety and availability of equipment, so it is necessary to classify the health status of the engine. The dataset adopted in the experiment is a turbofan engine degradation simulation dataset provided by the Prognostics Center of Excellence (PCoE) at National Aeronautics and Space Administration (NASA) Ames [32, 33]. The engine degradation simulation was carried out by recording several sensors to characterize the fault evolution using C-MAPSS. For each engine with a different state of initial wear, a set of 26-dimensional data is recorded for each turn number until failure, and a dataset with 20,631 samples is obtained. Each 26-dimensional sample in time series format contains the engine number, engine turn number, 3 operating condition setting parameters and 21 sensor parameters. The general information of each sensor parameter is shown in the appendix.
Through the observations of the sample dataset, it can be found that 7 parameters of the sensors, namely, 1, 5, 6, 10, 16, 18 and 19, are constants, the physical meanings of parameters 8 and 13 are the same, and those of parameters 9 and 14 are also the same. Therefore, this paper considers only 12 parameters, 2, 3, 4, 7, 11, 12, 13, 14, 15, 17, 20, and 21, as the attributes of the dataset.
The health of the engine can indicate the performance of the equipment and predict potential failure, which helps to maintain the equipment and improve its reliability and safety. The health status is usually measured by the health index (HI), which is a continuous value in the interval [0, 1]. HI is 1 when the device operates normally and 0 when the device is completely destroyed. In this paper, the Mahalanobis distance-based method proposed by Wang is selected to calculate the health index [34]:
Therefore, the dataset used in this experiment contains 20,631 samples, including 12 attributes and 2 class labels.
Experiment based on the optimization operator recommendation strategy
In this part, the optimization operator recommendation strategy is used to select the optimization algorithm for the ER rule classifier. To verify the effectiveness of the ER rule classifier on a small-sample dataset and the feasibility and effectiveness of the optimization operator recommendation strategy, 300 samples are randomly selected from the whole dataset for the experiment. The experimental results of each step are briefly listed as follows:
The 300 samples are randomly selected from the 20,631 samples, 2/3 and 1/3 of which are used as the training dataset and test dataset, respectively.
First, according to expert experience and historical data, the initial referential values of attributes
The initial referential values of the attributes
The initial referential values of the attributes
Then, when attribute x
i
is the referential value
The belief distribution of attribute x1
The belief distribution of attribute x2
The belief distribution of attribute x3
The belief distribution of attribute x4
The belief distribution of attribute x5
The belief distribution of attribute x6
The belief distribution of attribute x7
The belief distribution of attribute x8
The belief distribution of attribute x9
The belief distribution of attribute x10
The belief distribution of attribute x11
The belief distribution of attribute x12
Based on the calculation method and Eq.(12), the reliability of each attribute is R ={ r i ∣ i = 1, 2, linebreak … , M }= { 0.7150, 0.5492, 0.6114, 0.4093, 0.2902, 0.0725, 0.9689, 1, 0.8653, 0.5648, 0.6166, 0.5907 }, and the initial weight of each evidence is set as the corresponding reliability.
The initial ER rule classifier has been constructed after the above steps. The classification accuracies of the training dataset and test dataset based on the initial ER rule classifier are 92.5% and 93%, respectively.
In this experiment, three intelligent optimization algorithms are adopted to optimize adjustable parameters: PSO, GA, and SOA. According to the constraint conditions and objective function in Eqs.(17-18), the initial classifier can be globally optimized based on PSO, GA and SOA. After optimization, the classification accuracies of the training dataset based on PSO, GA and SOA are 93%, 94.5%, and 93.5%, respectively.
The classification accuracy of the ER rule classifier obtained by the three optimization algorithms (PSO, GA, SOA) on the test dataset is shown as follows.
Table 14 shows that the classification accuracy of the initial ER rule classifier without optimization is 93%, while the classification accuracy of the classifier optimized by PSO, GA and SOA is 94%, 96% and 95%, respectively. Fig. 5 shows in detail the classification results of different classifiers for 100 test samples, among which the white rectangles indicate that the classification results of the corresponding samples are wrong. The results indicate that the initial classifier and the three optimized classifiers all show good classification performance. However, the classification accuracy of the classifier optimized by GA is the highest, 3%, 2% and 1% higher than the initial classifier, the classifier optimized by PSO and the classifier optimized by SOA, respectively.
Comparison of results from three optimization algorithms

Detailed classification results of different classifiers
Analyzing the results in step 3.1 indicates that the optimization results of GA are superior to those of PSO and SOA, so GA is more suitable as the optimization algorithm of the ER rule classifier in this case. Therefore, GA (having the highest accuracy) is selected as the classifier’s optimization algorithm, after which the optimized ER rule classifier is constructed. This finding also confirms that the ER rule classifier can classify small-sample data well.
To verify the feasibility and effectiveness of the optimization operator recommendation strategy and ER rule classifier, experiments with complete datasets are conducted in this section. In this experiment, 2,000 samples are randomly selected as the training dataset, and the remaining samples comprise the test dataset. The classification accuracy of the ER rule classifier obtained by the three optimization algorithms (PSO, GA, SOA) on the turbofan engine degradation simulation dataset is shown as follows:
The classification accuracy of the initial ER rule classifier is 92.34%, while the classification accuracy of the classifier optimized by PSO, GA and SOA is 92.94%, 94.78% and 92.98%, respectively. The result of GA is obviously better than the results of SOA and PSO, which indicates that GA is the most effective optimization algorithm in this case.
The results obtained from the experiment with the complete dataset in this section are consistent with those obtained by the experiment with the partial dataset based on the optimization operator recommendation strategy in section 4.2.1. Both experiments indicate that GA is the most effective optimization algorithm among the three candidates. Therefore, the randomly selected partial data can reflect the characteristics of the entire sample data and select the most appropriate algorithm, which indicates that the optimization operator recommendation strategy proposed in this paper is feasible and effective.
Comparison between the ER rule classifier and classic classification algorithm
The classification accuracy of the ER rule classifier with GA is compared with the accuracies obtained by 4 classic classification methods (naive Bayes (NB), k-nearest neighbor (KNN), SVM, and DT), as shown in Table 16. Similarly, 2,000 samples are randomly selected as the training dataset, and the remaining samples comprise the test dataset when the dataset is classified by 4 classic classification methods.
A comparison of the results from the three optimization algorithms
A comparison of the results from the three optimization algorithms
A comparison among classification methods
Table 16 shows that the ER rule classifier has the highest classification accuracy among the classification methods, where the accuracy is higher than that of the naive Bayes, KNN, SVM, and decision tree classifiers by 12.64%, 1.04%, 3.13% and 0.94%, respectively. The results show that the ER rule classifier achieves good classification performance and is an effective and feasible classification method in this case.
In this section, the turbofan engine degradation simulation dataset is applied for an experiment. First, the dataset is introduced in detail, and the parameters such as the attributes and classes are defined. Then, 300 samples are randomly selected, and the operator recommendation strategy is adopted to optimize the initial ER rule classifier. The results show that GA is the best, and it is verified that the ER rule classifier can classify small samples well. Then, to verify the feasibility and effectiveness of the operator recommendation strategy, the complete dataset is used for the experiment, and the results also show that the classifier optimized by GA possesses the highest classification accuracy. Finally, compared with other classic classification methods, the classification accuracy of the ER rule classifier optimized by GA is the highest. Therefore, the feasibility and effectiveness of the ER rule with the operator recommendation strategy are verified in the experiment.
The ER rule classifier with an optimization operator recommendation based on the original ER rule classifier has been proposed in this study that can consider expert experience, classify small-sample datasets well, and improve the efficiency of algorithm selection. An initial ER rule classifier is first constructed, and then the optimization algorithm is selected to optimize adjustable parameters globally based on the optimization operator recommendation strategy. Finally, a numerical study on a turbofan engine degradation simulation dataset demonstrates the capability and effectiveness of the proposed ER rule classifier with an optimization operator recommendation. Specifically, the experiment based on the optimization operator recommendation strategy shows that the ER rule classifier can classify a small dataset well, and the result of an experiment with a complete dataset proves the applicability and capability of the optimization operator recommendation strategy. A comparison between the ER rule classifier and classic classification algorithm demonstrates the feasibility and effectiveness of the ER rule classifier with an optimization operator recommendation.
In further research, other datasets can be taken into account, demonstrating that the ER rule classifier with an optimization operator recommendation is universal among different datasets. Moreover, the reliability and weight are the core parameters of the ER rule classifier, and research on their calculation method will be a focus of future research. Studying the operator recommendation strategy to improve the efficiency of algorithm selection will also be necessary in further research.
Footnotes
Acknowledgment
This work was supported in part by the National Natural Science Foundation of China under Grant 71901212 and Grant 71690233.
Appendix
General information of 21 Parameters
| Number | Parameters | Unit |
| 1 | Temperature at fan inlet | °R |
| 2 | Temperature at LPC outlet | °R |
| 3 | Temperature at HPC outlet | °R |
| 4 | Temperature at LPT outlet | °R |
| 5 | Pressure at fan inlet | psia |
| 6 | Pressure in bypass-duct | psia |
| 7 | Pressure at HPC outlet | psia |
| 8 | Physical fan speed | rpm |
| 9 | Engine core speed | rpm |
| 10 | Engine pressure ratio | – |
| 11 | Static pressure at HPC outlet | psia |
| 12 | Ratio of fuel flow to Ps30 | pps/psi |
| 13 | Corrected fan speed | rpm |
| 14 | Corrected core speed | rpm |
| 15 | Bypass ratio | – |
| 16 | Burner fuel-air ratio | – |
| 17 | Bleed enthalpy | – |
| 18 | Demanded fan speed | rpm |
| 19 | Corrected demanded fan speed | rpm |
| 20 | HPT coolant bleed | lbm/s |
| 21 | LPT coolant bleed | lbm/s |