
Abstract
The stock market is an important embodiment of a national economy and financial activities and has an important impact on a country, enterprises and individuals. Stock forecasting can allow investment institutions and investors to understand the trend of the stock market in advance, which is a challenging and meaningful study. First, through the impulse phenomenon of the stock market, this paper discusses the problem of stock price prediction with delay, and the impulse delay differential equation is established. Second, according to the difference between the differential and the difference, the nonlinear delay grey prediction model is established. Next, the model parameters are estimated and the solving steps are obtained. The nonlinear parameters and delay time are optimized by the particle swarm optimization algorithm. Finally, the new model is applied to the prediction of the Shanghai stock market and the Shenzhen stock market closing indexes; the results show that the new model can effectively predict stock prices, which is much better than the existing four grey models and a time series model.
Introduction
Finance is the core of the modern market economy and plays an increasingly important role in China’s economic reform and development. The stock market is an important embodiment of the national economy and financial activities, plays a significant role in China’s economic development, and has an important impact on the country, enterprises and individuals. If someone can understand the trend of the stock market in advance, this will bring benefits to investment institutions and investors. Using scientific and effective technology to analyse indicators and stock price change trends of the future, more accurate predictions can be made. This can provide investors with predictions of stock price movements in the future and specify a reasonable investment strategy to make good profits into the future. Therefore, the prediction of the trend of stock price changes in the stock market can provide the majority of investors a further understanding of the stock market. This not only has profound theoretical significance but also has more important practical significance to conduct in-depth research on the testability of the stock market.
Stock forecasting is a branch of economic projection that mainly uses scientific methods to uncover effective information from the historical data of stock prices, clarifies the change rules and makes accurate predictions. The prediction techniques of stock prices can be roughly divided into the following three methods: traditional time series forecasting, machine learning forecasting and combination forecasting [1]. The time series forecasting method is mainly based on a large number of discrete stock prices to explore the law of stock price changes with time to perform modelling. Paola et al. [2] applied the vector error correction model to the high-frequency time series of a foreign exchange market and predicted high-frequency data in the financial field. The numerical experiment showed that the results were better than the effect of the autoregressive integrated moving average (ARIMA) model and other models. Machine learning methods mainly include neural network models and random forests. For example, Ajit et al. [3] proposed a low-complexity recursive neural network model for stock price prediction and its prediction performance showed that the effect was better than other neural network models. Hyeuk et al. [4] used the improved random forest bootup method to predict stock index prices; the results were better than those of other machine learning methods. The combination prediction method combines various algorithms for prediction modelling. For example, Jigar et al. [5] used a multifusion machine learning method to forecast stock market indexes, which has a better effect than a single neural network and other methods. Paiva [6] combined the support vector machine method and the mean method into a model to predict stock returns by the daily investment value.
Most of the above forecasting models require considerable historical data, their calculations are complex, and most of them assume that stock prices change in a linear fashion. However, due to the complex nonlinear relationship between stock prices and influencing factors, which is stochastic and mutable, it is difficult to describe with an accurate mathematical model. Therefore, its prediction accuracy is low and it lacks practicality [7]. The stock price is a comprehensive result of multiple factors, the influencing factors are grey and uncertain, and the grey prediction model is characterized by a simple calculation. Therefore, many scholars regard the stock price system as a grey system and make predictions on it with relatively high prediction accuracy.
Grey system theory has been widely considered since it was proposed in 1982 [8]. The grey prediction model is one of the core contents of grey system theory, which is characterized by simple calculation; it is superior to traditional prediction methods. It has been widely used in short-term traffic flow prediction [9], traffic safety prediction [10], energy consumption prediction [11–15], economic management [16] and other fields. However, traditional grey prediction univariate models, such as the GM(1,1) model, DGM(1,1) model [17, 18], multivariable grey GM(1,N) model, and NGM (1,N) model [19, 20], also have many defects. Therefore, to improve the simulation and prediction performance of the grey prediction model, researchers have extended the existing classic grey univariate and multivariate models to the new grey prediction model [21–23]. Concurrently, a large number of in-depth and systematic studies were performed on the grey prediction model from the perspectives of the modelling mechanism, model properties and model combination, which promoted the development and improvement of the theoretical system of the grey prediction model [24–26].
There are also many papers on the application of the grey prediction model in stock price prediction, such as the GM(1,1) and Verhulst models improved by the Fourier series by Kayacan et al. [27], which are mainly used to study the short-term prediction of stocks. Duan et al. [28] used the nature of the Fibonacci sequence to optimize the background value of the GM(1,1) model and used the inflexion point data of Elliott’s wavy line as the original modelling data to make short-, medium- and long-term predictions on stocks. Wu et al. [29] used the grey GM(1,1) model to predict stock prices, which had certain effects. Wang et al. [30] applied grey system theory to the stock market and predicted the stock price index, which proved that it was feasible and reasonable.
The applications above basically applied the grey prediction model according to the time series of the stock price. However, there is an impulse phenomenon in the stock market [31] and its mathematical model can often be summed up as an impulse differential system. When the pulse phenomenon occurs, the state variable of the system can change considerably in a very short time and the stock prices are delayed [32]. This delay refers to the system input and output not matching at a specific time, i.e., there is a time lag between the system input and output. The grey forecasting models above did not consider the stock delay phenomenon, so they cannot reach the expected effect for stock prediction. The research motive of this paper is that the stock price system is an impulse system with a delay phenomenon. Based on this phenomenon, a new grey prediction model is studied and applied to stock price prediction.
Based on the impulse phenomenon of the stock market, this paper studied the differential equation of the impulse delay. According to the difference in the grey system between the differential and the difference, the corresponding nonlinear grey prediction model of the delay is established, the model parameters are estimated and the solving steps are obtained. Additionally, the model is applied to the Chinese stock market to predict the stock prices in the Shanghai and Shenzhen Stock Indexes of two typical stocks, Kweichow Moutai and AIER Eye Hospital. The results show that the effect of the model is better than that of the four other grey prediction models and the non-grey ARIMA model that were compared. This model can effectively predict the price of stocks on the Chinese stock market. Therefore, the main contributions of this paper are as follows: We introduced the impulse phenomenon of the stock market to the grey prediction model, established the delayed grey prediction model and studied the properties of the model. We established a nonlinear grey prediction model with the complex nonlinear relationship between the stock price and the influencing factors. Then, we used the particle swarm optimization algorithm (PSO) to optimize the delay time and nonlinear items. Taking the Shanghai Stock Index, Shenzhen Stock Index and two important stocks as examples, we verified the effect of the model. The results show that the new model can effectively predict Chinese stock prices.
In the full text, we use different abbreviations for different grey prediction models. These abbreviations and their meanings are listed in Table 1.
Abbreviations of models
Abbreviations of models
The remainder of this paper is organized as follows: Section 2 establishes the differential equation under the impulse state; Section 3 establishes the grey prediction model with nonlinear delay and obtains the modelling steps of the model; Section 4 optimizes the delay time and nonlinear terms by using the PSO algorithm; Section 5 applies the model to the prediction of Chinese stock prices; and the conclusion is shown in Section 6.
In this section, the impulse delay differential equation is established mainly through the impulse phenomenon of price [31].
Assuming that the trend function of technical traders at time t is Q
c
(t), u (t) represents the future market price and the following is true [31]:
Considering that the base price is closely related to market demand, the base price will be adjusted depending on market demand. The basic price function is given as follows:
where δ represents the rate at which the base price adjusts relative to market demand.
Based on the above analysis, financial stock prices are expressed as the following system with delayed differential Equations (1), (2) and (3):
Obviously, p (t) = u (t) = F (t) is the equilibrium point of the system, so we call (p, u, F) = (F, F, F) the basic stable state of the system and the price at the stable state is given by a constant. We assume that the price at the stable state is
Now, consider the equilibrium point
This section determines the nonlinear term of differential Equation (5) according to the grey difference information, namely, the differential and the relationship between the difference, to establish the grey forecasting model of nonlinear stock price impulse time delay (denoted as the DSPGM(1,1|τ,r) model), then work to estimate the parameters and the model solution.
Establishment of model
Let the original sequence of stock prices be the following:
The first-order accumulating generation sequence is defined as follows:
Z(1) is adjacent to the mean generation sequence of X(1), as follows:
Let the nonlinear term of Equation (5) be f (t, p(1) (t)) = uk r , where r is an arbitrary constant. The determination of the nonlinear term is mainly to adjust the balance state of the price system. The following whitening equation can be obtained:
Then, the grey prediction model below can be defined.
The parameter estimation formula of the model can be obtained from Definition 1. It is given by the following theorem:
Then, replacing x(1) (k) and x(1) (k - τ) with
It is represented by a matrix as follows:
Set a, b, u as the set of parameter values, substitute them into the above equation, and obtain the residual difference (e) between the actual value and the estimated value.
The sum of squares of residuals (sse) is the following:
According to the extreme value principle, minimizing the sse,
Thus, B
T
BP = (Y
T
B)
T
= BY. Multiplying both sides by (B
T
B) -1 results in the following:
Let x(1) (k) = x(1) (k - 1) + x(0) (k). Substituting it into Equation (12) provides the following:
Thus, it follows that:
In summary, Definition 2 is proved.
This section introduces an intelligent algorithm, the particle swarm optimization algorithm, to solve the problem of determining the nonlinear programming models of τ and r.
Particle swarm optimization algorithm
The particle swarm optimization algorithm (PSO) [38] was proposed from the study of the predatory group behaviour of birds to solve optimization problems. Each potential solution in the optimization problem is treated as a particle, all particles have an adaptive value determined by the optimization function, and each particle has its own velocity and distance. The optimal solution is found through iteration. In each iteration, the individual extremum and the global extremum are updated. Under the specified number of iterations, the final value is the optimal solution.
Set N particles and search in a D-dimensional space, where the position of the i-th particle is expressed as a D-dimensional vector, denoted as follows:
The flight velocity of the i-th particle is denoted as follows:
The optimal solution of the i-th particle thus far is called the individual extreme value, denoted as follows:
The optimal value searched by the whole particle swarm is called the global extreme value, denoted as follows:
After finding the individual and global extremums, update the position and speed with the following formulas:
Construct the average relative error function as an adaptation function, which is
The PSO algorithm is used to find the optimal values of τ and r. The steps are as follows:
Step 1: Initialize the particle swarm, including the population size N, the position X i and velocity V i of each particle.
Step 2: Calculate the fitness value f (r, τ) of each τ and r and select the individual extremum and global extremum according to the fitness value.
Step 3: Update the velocity and position of the particle according to Equations (16) and (17).
Step 4: Judge whether the constraint conditions are met (the error is good enough or the maximum number of cycles is reached). If so, exit; otherwise, return to Step 2 to continue.
To evaluate the effectiveness of the model, APE, MAPE, R and other evaluation indicators were introduced. The specific formula and its meaning follow. The smaller APE, MAPE and IA are, the higher the model accuracy is; in contrast, the higher R is, the better the model fitting effect.
(1) Absolute error (APE): The actual value is compared with the simulated value to evaluate the accuracy at time k.
(2) Average absolute percentage error (MAPE):
MAPE can be divided into two parts. When n is the length of the modelling sequence, it is the average absolute percentage error of the simulated data; when n is the length of the predicted sequence, it is the average absolute percentage error of the predicted data.
(3) Correlation coefficient (R):
According to Definitions 1 and 2, Theorem 1 and Section 4.2, the algorithm of the DSPGM(1,1|τ,r) model is available, as shown in Table 2.
The algorithm of the DSPGM(1,1|τ,r) model
Therefore, the flow diagram of the model from establishment to application is obtained, as shown in Fig. 1.
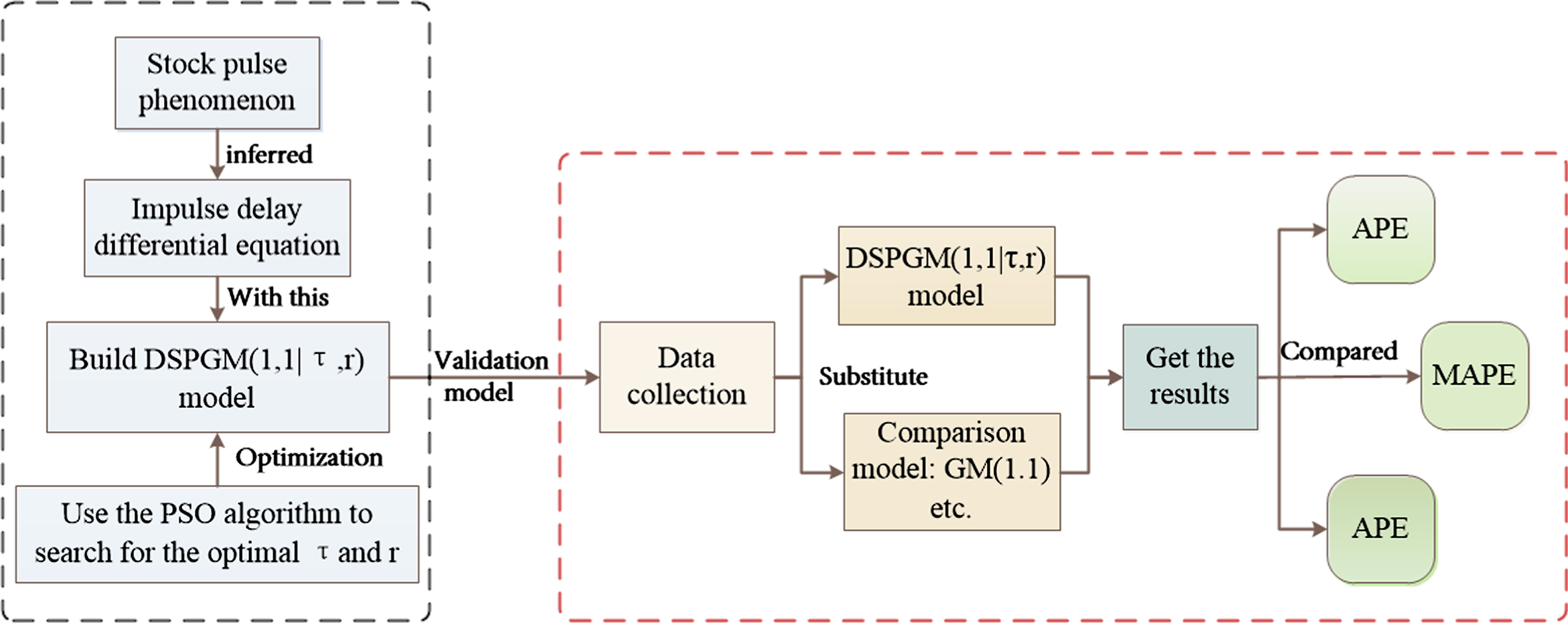
The flow diagram of the DSPGM(1,1|τ,r) model.
Each country’s stock market has its own historical environment and characteristics. China’s stock market is in the development stage, so it is more complex and affected by many factors, making it difficult to predict. Specifically, China’s stock price changes have the following remarkable characteristics:
Stock prices are characterized by large increases and decreases [39]. For example, in 2005, the Shanghai Stock Index rose from the lowest 998 points to 6124 points in only two years, an increase of more than five times. In addition, after the rise, the price collapsed. After reaching a high of 2245 points in 2001, the Shanghai Stock Index dropped 60% to 998 points in 2005. The same situation occurred in 2015, when the Shanghai Stock Index suddenly plunged more than 50% after reaching a high of 5178. For a single stock, it is more common that it rises one day and falls the next. Stock price fluctuations present the typical characteristics of policies. National regulation in some aspects will affect the stock price and be greatly influenced by the mainstream media, which further aggravates the problem of stock price instability.
Therefore, the development of a scientific prediction model is of great importance to individuals, enterprises and countries. In this section, the DSPGM(1,1|τ,r) model is applied to the Shanghai and Shenzhen Stock Indexes and forecasts the individual stocks of Kweichow Moutai and AIER Eye Hospital. The data to establish the model came from Sohu Stocks.
Example 1: Shanghai Index net forecast
In this case, on the Shanghai composite index, to predict the net value of the daily closing quotation, the data are chosen from between June 29 and July 31, 2020. There are 15 working days (during closed days the net value will not change so it is not studied), denoted by x(0) (k) , k = 1, 2 ⋯ 25. The actual data are shown in Table 3 (refer to the details in the Appendix, Table 3). Between June 29 and July 17, 15 data points are used to establish the model and between July 20 and July 31, 10 data points are used to test the forecast.
The simulation and prediction results of six models on Shanghai Stock Exchange Index
The simulation and prediction results of six models on Shanghai Stock Exchange Index
Substituting x(0) (k) into DSPGM(1,1|τ,r) yielded the optimal value τ = 1, r = 1.0163 by PSO, and the model parameters were
The results generated by DSPGM(1,1|τ,r) were compared with the ARIMA [33], Verhulst [34], DGM(1,1) [35], NGBM(1,1) [36], and WGM(1,1) [37] models, and the simulation and prediction results of these models are detailed in Table 3 of the Appendix. To compare the results of the six models more clearly, curve comparison diagrams of the six models and the actual stock price are given in Fig. 2, and the error comparison diagram is shown in Fig. 3.
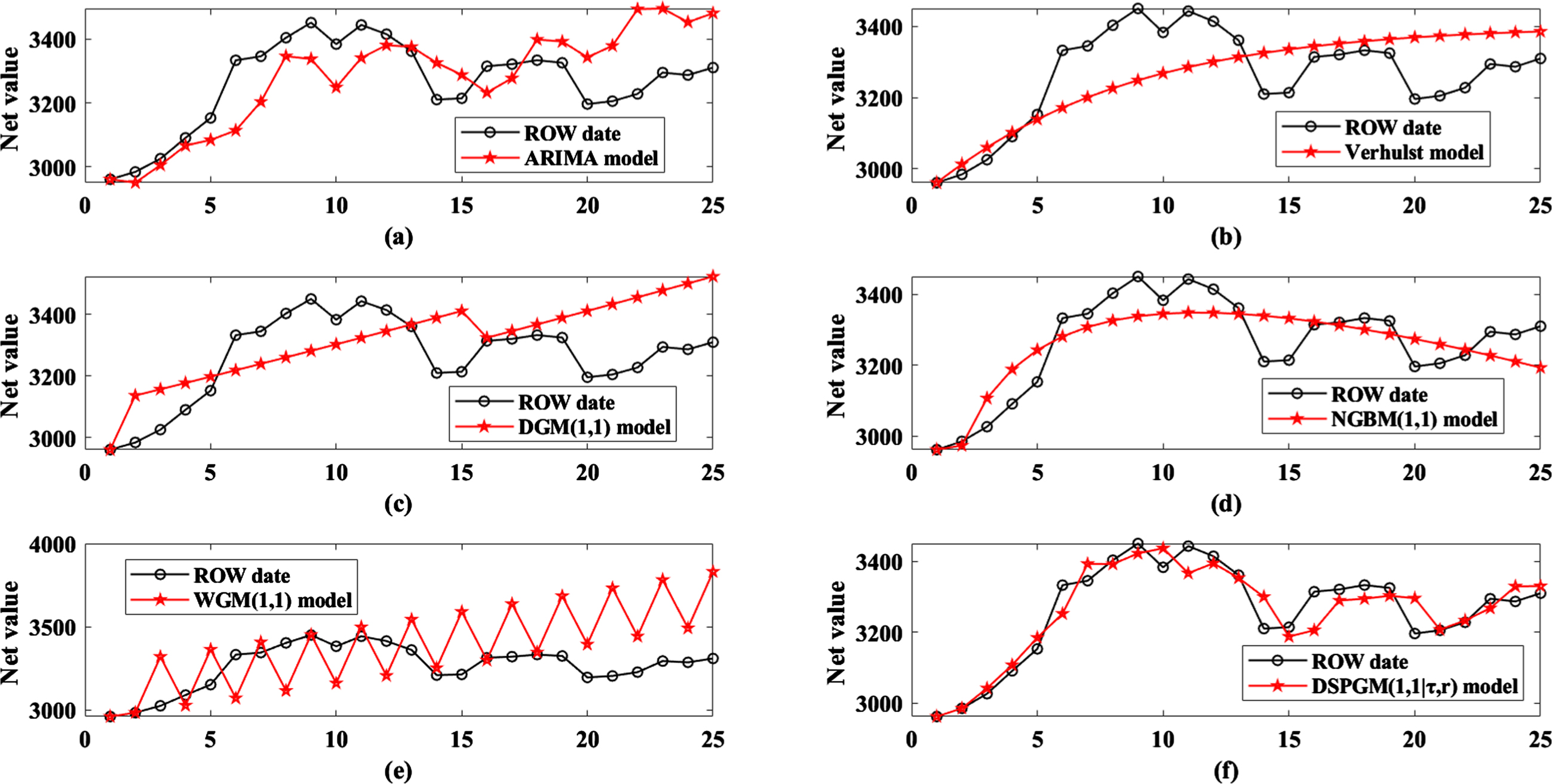
Shanghai Index net change trend charts.
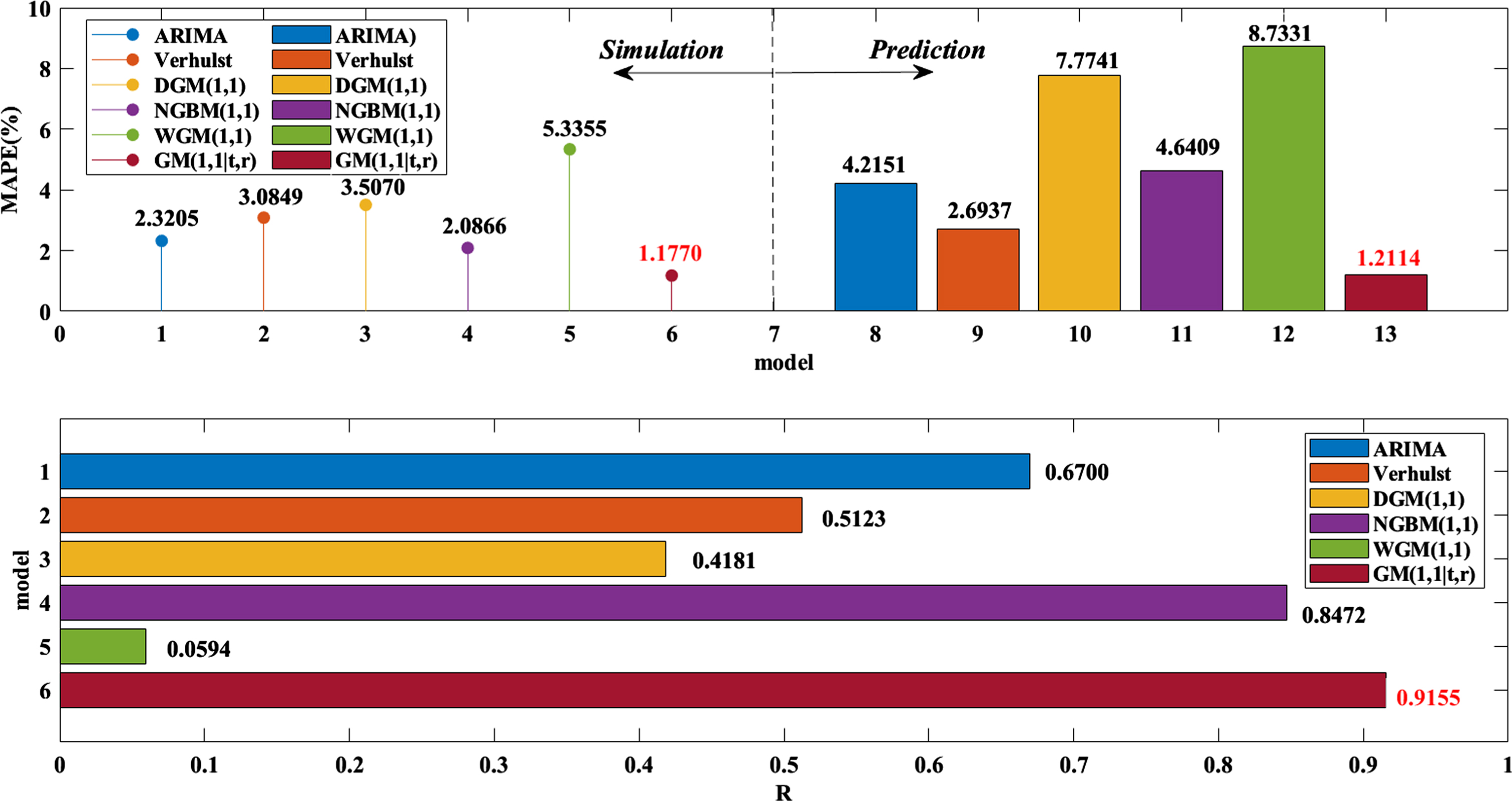
Error comparison of each model on the Shanghai Stock Exchange Index.
First, Fig. 2 shows six models. The net value of the Shanghai Index prediction results of the DSPGM(1,1|τ,r) model is very similar to the real net value. The remaining models have roughly the same trends, but they all show significant deviations. From the analysis of Table 3 and Fig. 3, it can be found that in the six models, the simulation means absolute percentage error and the prediction mean absolute percentage error of the DSPGM(1,1|τ,r) model are the smallest at 1.1770% and 1.2114%, respectively. The mean prediction errors of the ARIMA [33], traditional Verhulst [34], DGM(1,1) [35] and NGBM(1,1) [36] models are close to each other, at approximately 3%. However, the average prediction errors of the ARIMA, DGM(1,1) [31] and WGM(1,1) [37] models reached more than 7%. Then, looking at the correlation coefficient between the results of each model and the real data in Table 3 and Fig. 2, it can be seen that in the ARIMA, traditional Verhulst, DGM(1,1), NGBM(1,1), WGM(1,1), and DSPGM(1,1|τ,r) models, the fitting results of the Shanghai composite index and the correlation coefficient R of the original data were 0.6700, 0.5123, 0.4181, 0.8472, 0.0594 and 0.9155, respectively. The correlation coefficient between the DSPGM(1,1|τ,r) model and the original data is much higher than that of the others. In summary, it can be concluded that the DSPGM(1,1|τ,r) model is better than the ARIMA model in the prediction of the net value of the Shanghai Composite Index. The traditional Verhulst, DGM(1,1), NGBM(1,1), and WGM(1,1) models
The results of examples 1 and 2 show that the DSPGM(1,1|τ,r) model has a very high accuracy in the prediction of the Shanghai composite index. To verify that the DSPGM(1,1|τ,r) model can successfully predict China’s stock prices, this example forecasts the net value of the Shenzhen Index.
The daily closing net value of the Shenzhen Index between June 29 and July 31 was selected as x(0) (k) , k = 1, 2 ⋯ 25, in which 15 sets of data between June 29 and July 17 are used for modelling and 10 sets of data between July 20 and July 31 are used for prediction. x(0) (k) is substituted into the DSPGM(1,1|τ,r) model. Through a PSO search, the best value τ = 2 and r = 1.034. The results of the model are shown in Table 4 (refer to the details in Appendix 4), the Shenzhen Index net change trend charts are shown in in Fig. 4 and the error comparison of each model to the net forecast of the Shenzhen Index is shown in Fig. 5.
The simulation and prediction results of six models on Shenzhen Stock Exchange Index
The simulation and prediction results of six models on Shenzhen Stock Exchange Index
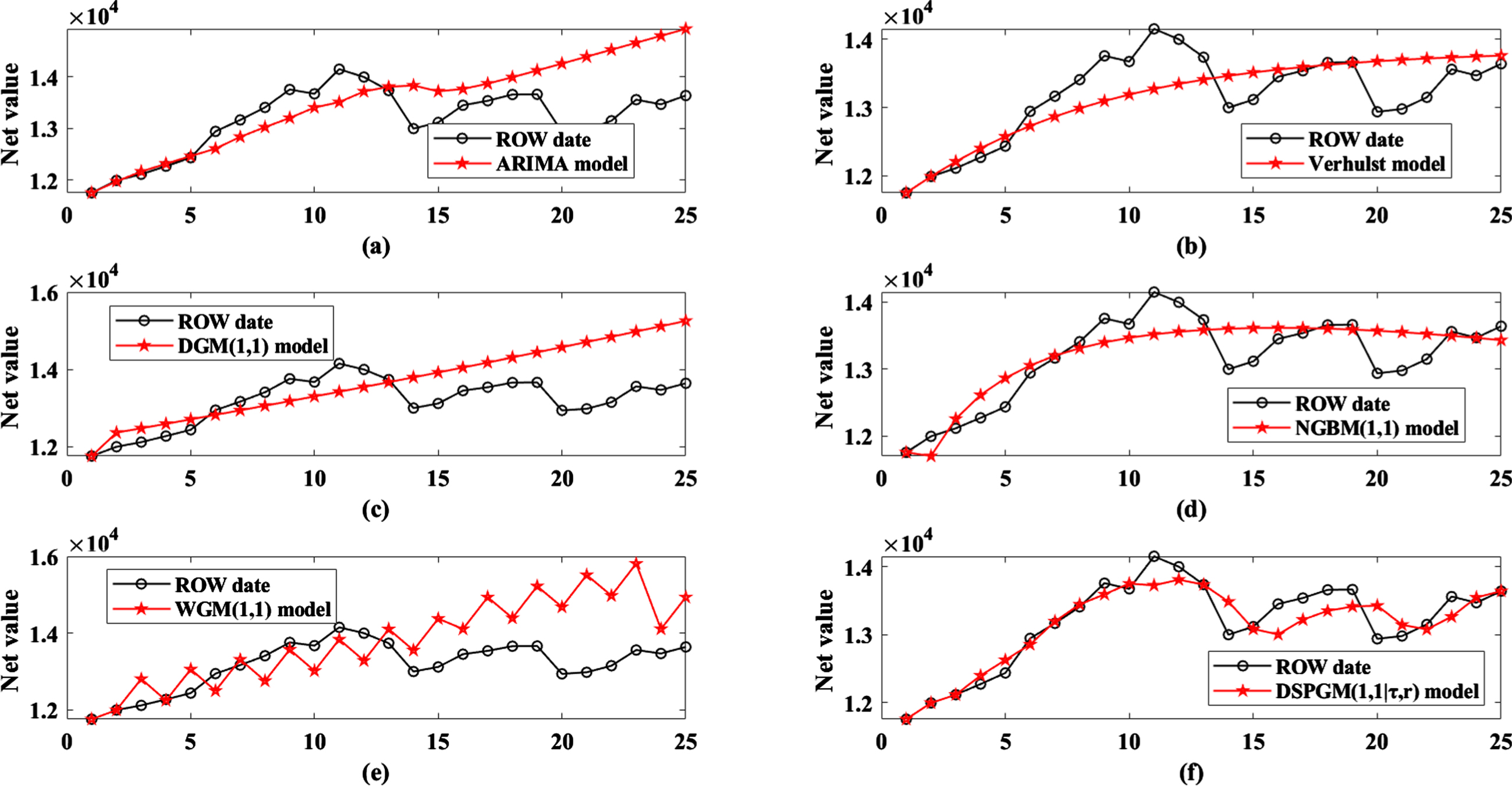
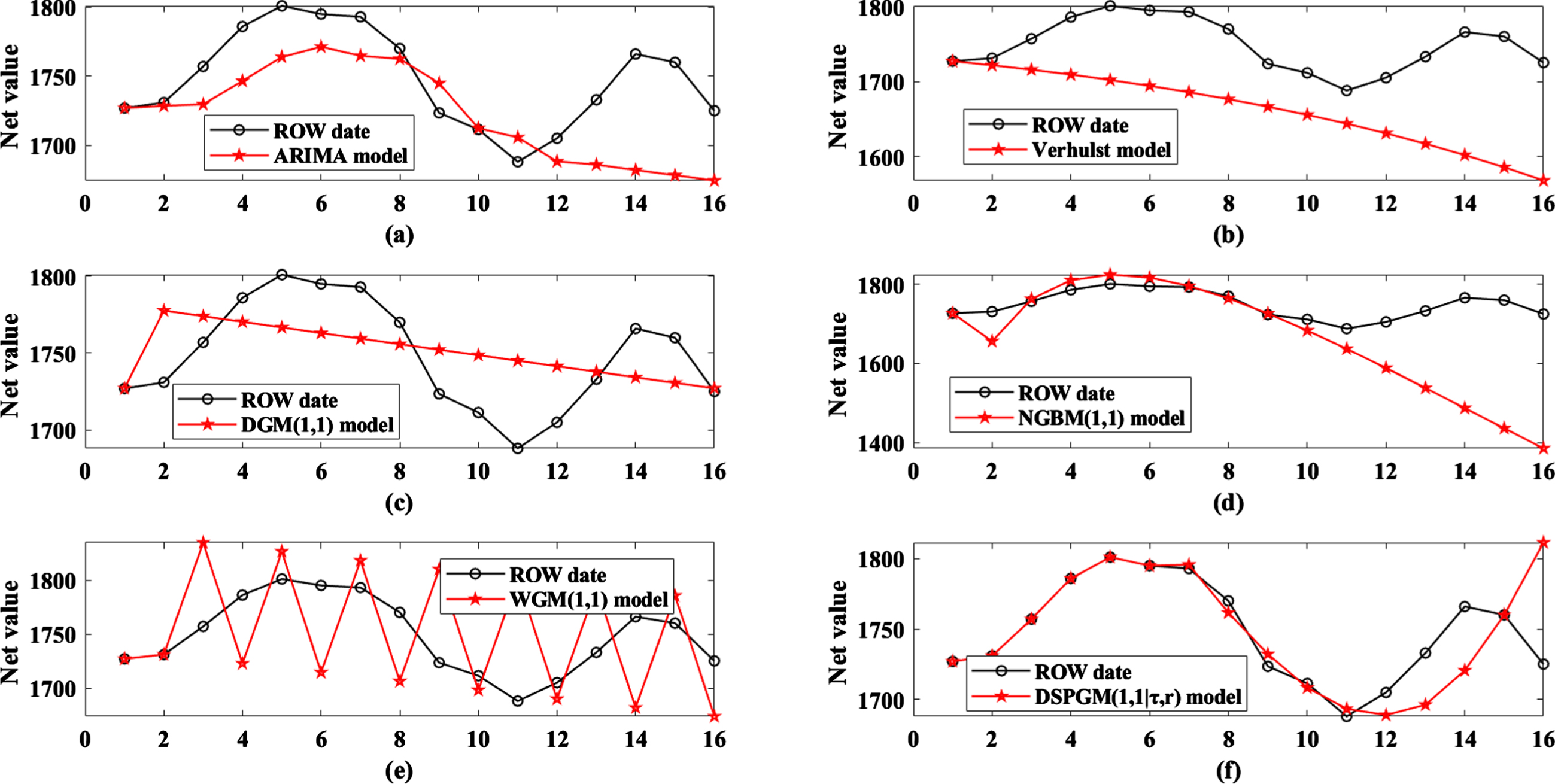
Shenzhen Index net change trend charts.
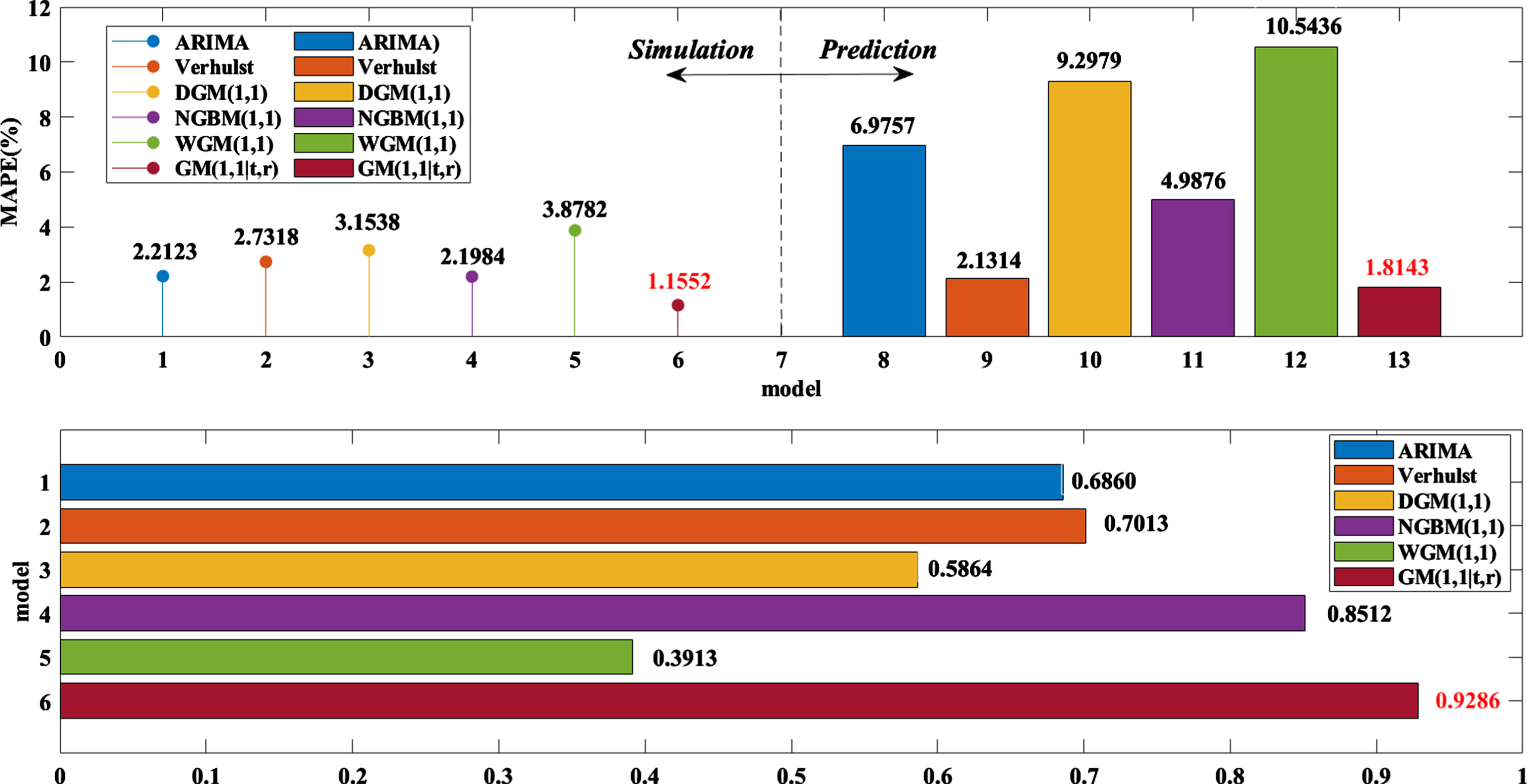
Error comparison of each model on the Shenzhen Index.
Figure 4 shows the changes in the predicted values of the six models and the true values of the net value of the Shenzhen Index. Obviously, the predicted value curve of the DSPGM(1,1|τ,r) model is closest to the true value of the net value of the Shenzhen Index. The DGM(1,1) and WGM(1,1) models are the worst. The specific results can be seen in Table 4 and Fig. 5. In the simulation and prediction of the Shenzhen Index, the simulation error of the DSPGM(1,1|τ,r) model is 1.1552% and the prediction error is 1.8143%, which are lower than those of the comparison models. The WGM(1,1) model has the worst results; its simulation error is 3.8782% and its prediction error is 10.5436%, which are higher than those of the DSPGM(1,1|τ,r) model by over 2% and 8%, respectively. The simulation errors of the Verhulst, DGM(1,1) and NGBM(1,1) models are close to 3%, but the prediction error of the DGM(1,1) model is 9.2979%. The Verhulst and NGBM(1,1) models are 2.1314% and 4.9876%, respectively.
Then, look at the correlation coefficient between the results of each model and the real data as shown in Table 4 and Fig. 6, which show that in the ARIMA, traditional Verhulst, DGM(1,1), NGBM(1,1), WGM(1,1), and DSPGM(1,1|τ,r) models, the fitting results of the Shanghai composite index and the correlation coefficient R of the original data were 0.6860, 0.7013, 0.5864, 0.8512, 0.3913, and 0.9286, respectively. The correlation coefficient between the DSPGM(1,1|τ,r) model and the original data is much higher than that of the others. It can be concluded that the DSPGM(1,1|τ,r) model is better than the ARIMA, traditional Verhulst, DGM(1,1), NGBM(1,1), and WGM(1,1) models in the CSI 300 index net forecast. Again, the effectiveness of the DSPGM(1,1|τ,r) model was proven.
Kweichow Moutai net change trend charts.
This case selects Kweichow Moutai, a typical stock in the Shanghai Stock Exchange Index, and simulates and forecasts its net value to supplement the prediction conclusion of the Shanghai Stock Exchange Index. This shows that the accurate effect of the model is not due to chance. Data from 16 working days between August 26 and September 17, 2020, are selected and denoted as x(0) (k) , k = 1, 2 ⋯ 16. The actual data are shown in Table 5 (refer to the details in the Appendix, Table 5), of which 10 sets of data between August 26 and September 9 are used to establish the model and 6 sets of data between September 10 and September 16 are used for the prediction test.
The simulation and prediction results of six models on Kweichow Moutai
The simulation and prediction results of six models on Kweichow Moutai
According to Section 4.2, the delay factor τ = 5 and the nonlinear factor r = 1.2035. The results are shown in Table 4, which uses the ARIMA, traditional Verhulst, DGM(1,1), NGBM(1,1), and WGM(1,1) models to forecast Kweichow Moutai’s net worth. Then, the results generated by the DSPGM(1,1|τ,r) model are compared to them; the results are presented in Table 5, titled “The simulation and prediction results of six models on Kweichow Moutai index”, Fig. 6, titled “Kweichow Moutai net change trend charts”, and Fig. 7, titled “Error comparison of each model on Kweichow Moutai”.
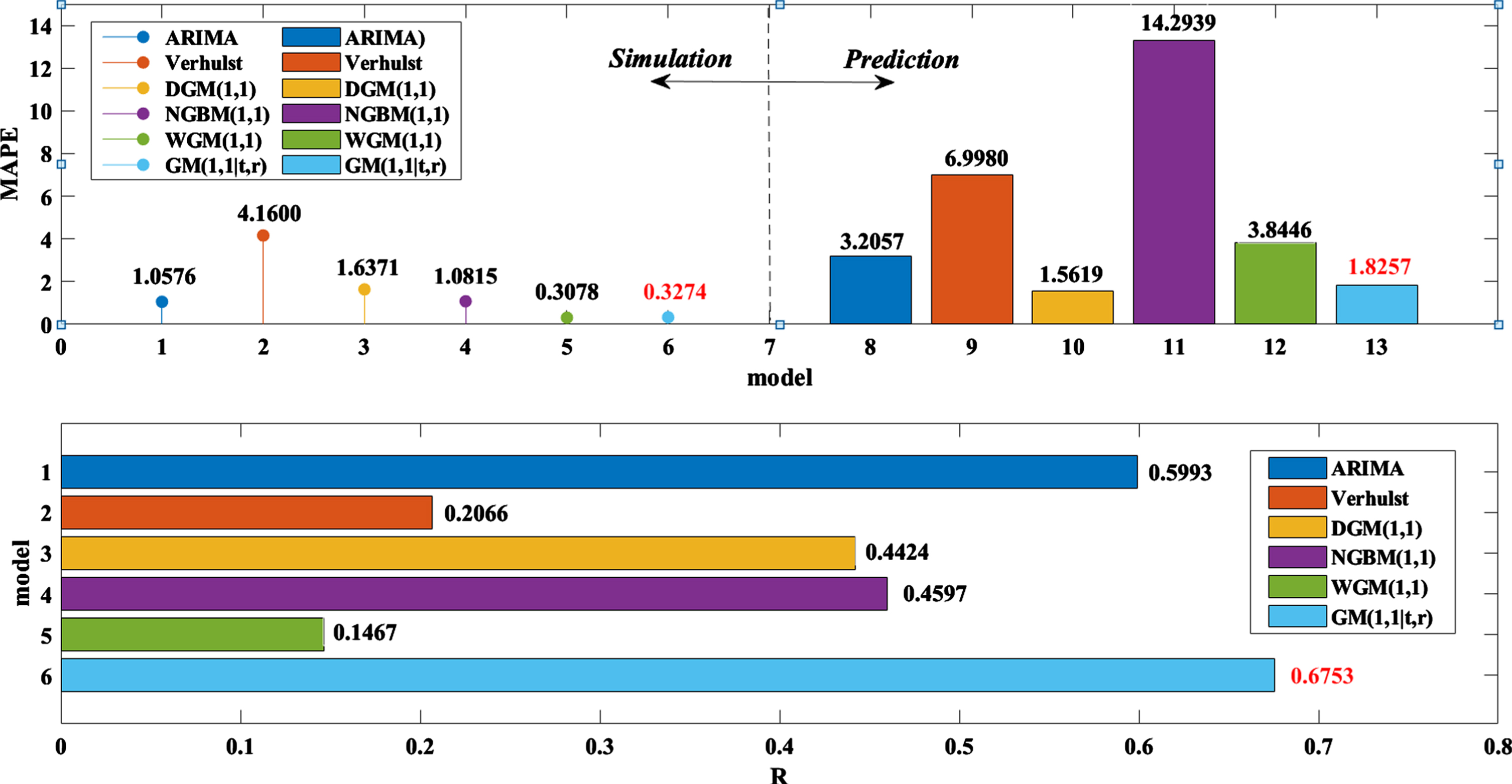
Error comparison of each model on Kweichow Moutai.
Figure 6 shows the changes in the predicted values of the six models and the true values of the net value of Kweichow Moutai. Obviously, the predicted value curve of the DSPGM(1,1|τ,r) model is closest to the true value, but other models have a large error relative to the real value. The specific results can be seen in Table 5 and Fig. 7. The simulation error of the DSPGM(1,1|τ,r) model is 0.3972% and the prediction error is 1.8257%, so it has very good prediction results. In the other models, the simulation error of the traditional Verhulst model is 4.16%, which is the highest of the six models, but its prediction error is 14.2939%. The prediction error of the NGBM(1,1) model is 14.2939%, which is more than 10%, so it does not fit the forecast of the Kweichow Moutai stock price. The simulation errors of the ARIMA, DGM(1,1) and WGM(1,1) models are approximately 1% and their prediction errors are approximately 2%, which is higher than that of the DSPGM(1,1|τ,r) model.
Then, look at the correlation coefficient between the results of each model and the real data. Table 5 and Fig. 7 show that in the ARIMA, traditional Verhulst, DGM(1,1), NGBM(1,1), WGM(1,1), and DSPGM(1,1|τ,r) models, the fitting results of the Shanghai composite index and the correlation coefficient R of the original data were 0.5993, 0.2066, 0.4424, 0.4597, 0.1467, and 0.6753, respectively. The correlation coefficient between the DSPGM(1,1|τ,r) model and the original data is much higher than that of the others. In summary, DSPGM(1,1|τ,r) is better than the ARIMA, traditional Verhulst, DGM(1,1), NGBM(1,1), and WGM(1,1) models in the forecasting of Kweichow Moutai.
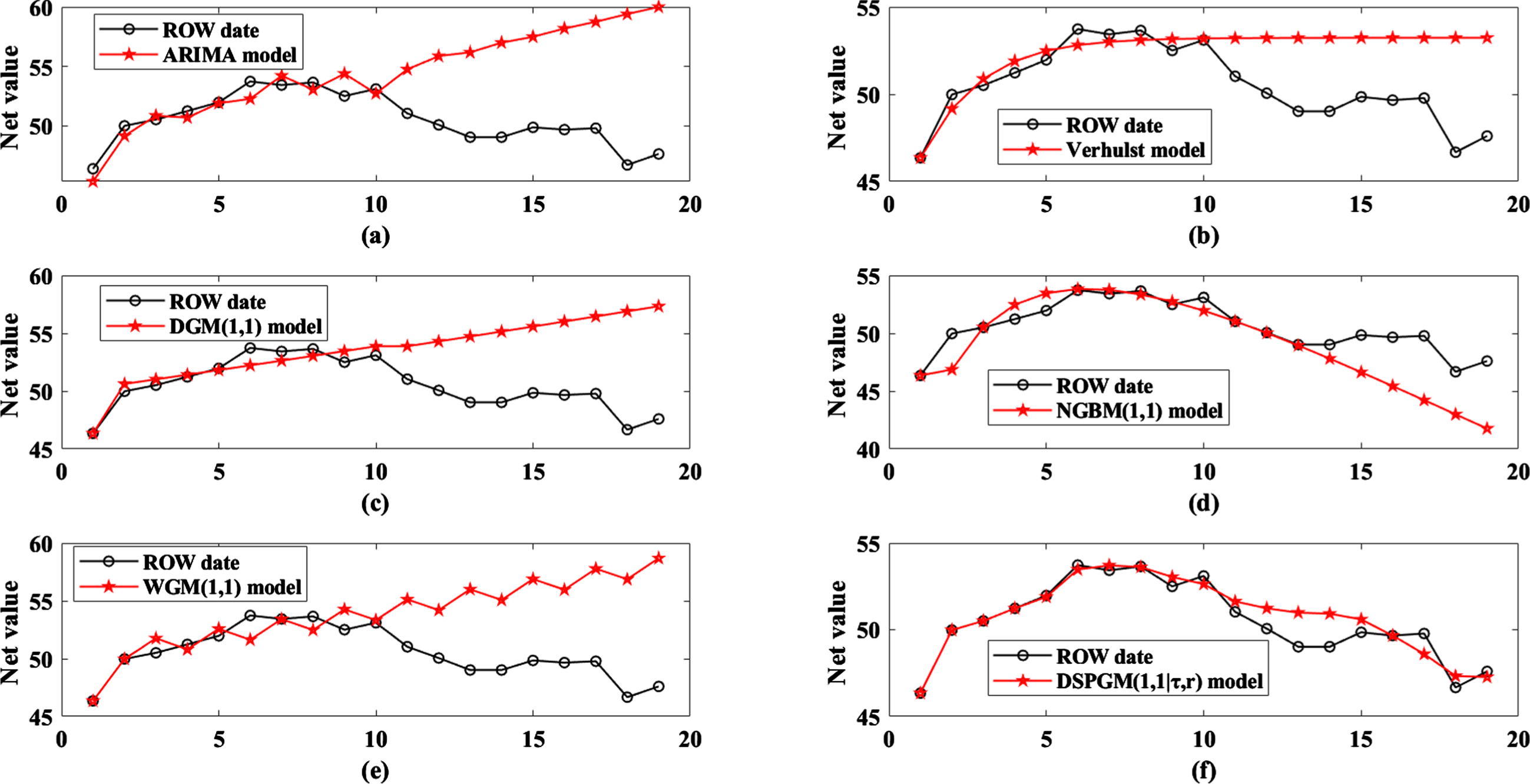
AIER Eye Hospital is a typical stock listed on the Shenzhen Index Stock Exchange. This case is to predict its net worth. The daily closing net value of AIER Eye Hospital between August 25 and September 7, 2020, is selected for modelling; there are 10 sets of data. The other 9 sets of data between September 8 to 9 September 18 are used for prediction. They are denoted by x(0) (k) , k = 1, 2 ⋯ 19 and substituted into the DSPGM(1,1|τ,r) model. Through the PSO search, the best values τ = 3 and r = 0.9398. The results of the model are shown in Table 6 (refer to the details in the Appendix, Table 6). Figure 8 presents the AIER Eye Hospital net change trend charts and Fig. 9 shows the error comparison of each model on the net forecast of AIER Eye Hospital.
The simulation and prediction results of six models on AIER Eye Hospital
The simulation and prediction results of six models on AIER Eye Hospital
Figure 8 shows the changes in the predicted values of the six models and the true values of the net value of the AIER Eye Hospital. The predicted value curve of the DSPGM(1,1|τ,r) model has a very similar trend to the true value. However, the results of the ARIMA, traditional Verhulst, DGM(1,1) and WGM(1,1) models are increasingly higher than the real price. The results of the NGBM(1,1) model are gradually lower than the real price. These results show the effectiveness of the DSPGM(1,1|τ,r) model. The specific results can be seen in Table 6 and Fig. 8. The simulation error of the DSPGM(1,1|τ,r) model is 0.5218% and its prediction error is 1.903%. For the comparison models, their simulation errors are approximately 1.5%, but all have a large prediction error. The smallest prediction error is 7.1670%, which is five percentage points higher than that of the DSPGM(1,1|τ,r) model.
AIER Eye Hospital net change trend charts.
Then, look at the correlation coefficient between the results of each model and the real data. Table 6 and Fig. 9 show that in the ARIMA, traditional Verhulst, DGM(1,1), NGBM(1,1), WGM(1,1), and DSPGM(1,1|τ,r) models, the fitting results of the Shanghai composite index and the correlation coefficient R of the original data were 0.2133, 0.3550, 0.1709, 0.8642, 0.7351, and 0.9178, respectively. It can be seen that the correlation coefficient between the DSPGM(1,1|τ,r) model and the original data is much higher than the others. In summary, DSPGM(1,1|τ,r) is better than the ARIMA, traditional Verhulst, DGM(1,1), NGBM(1,1), and WGM(1,1) models in the forecasting of AIER Eye Hospital.
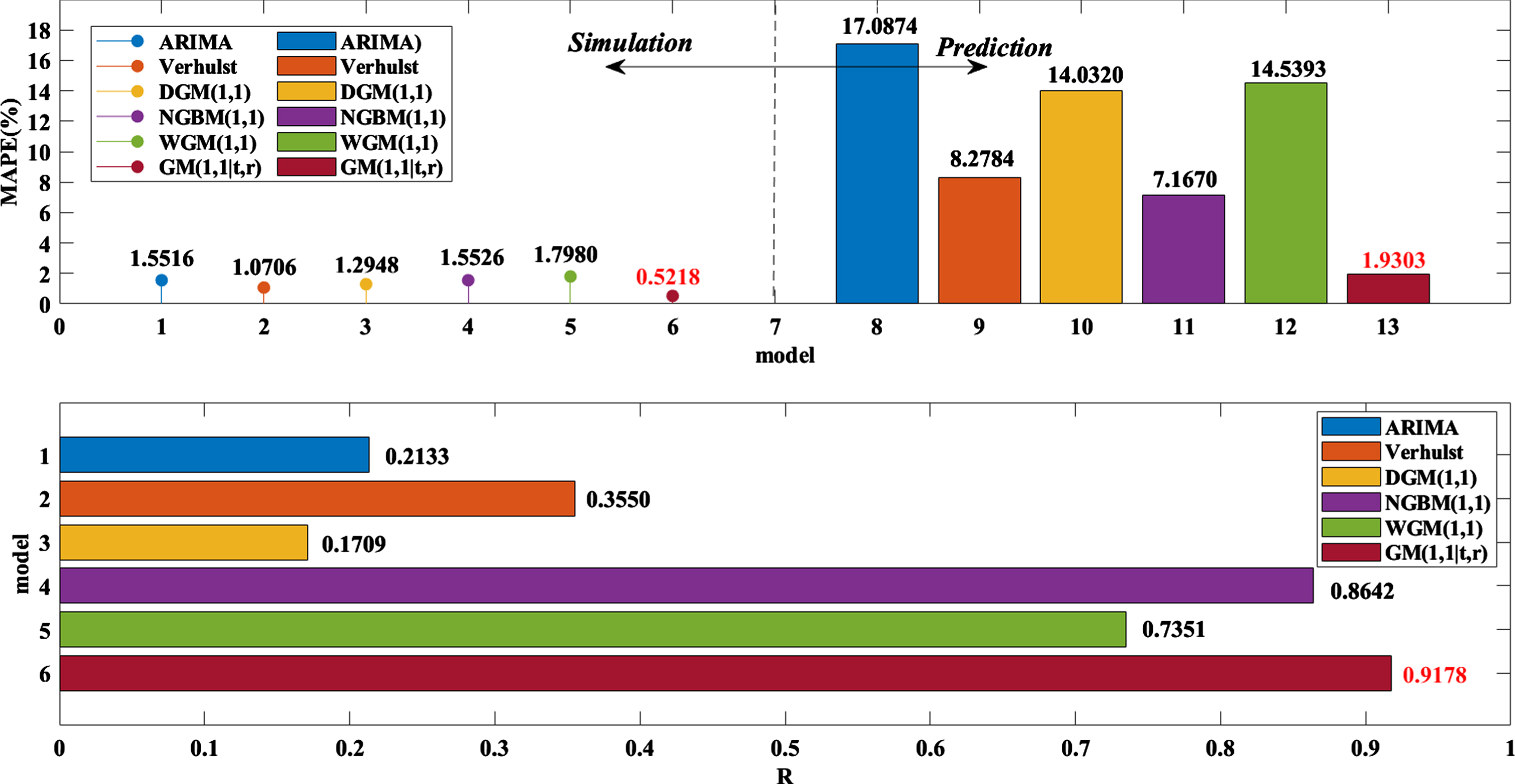
Error comparison of each model on AIER Eye Hospital.
In the above four cases, the DSPGM(1,1|τ,r) model accurately predicts the net value change of the Shanghai Index, Kweichow Moutai, Shenzhen Index and AIER Eye Hospital. It can be found that the ARIMA, Verhulst, DGM(1,1), NGBM(1,1), and WGM(1,1) models often deviate from the true trend of the stock during stock forecasting, which show that the traditional grey model and some other non-grey models have great limitations in predicting the net worth of China’s stock market. The DSPGM(1,1|τ,r) model has already solved the problem of the traditional grey model not predicting the effect very well and solved the remainder of the models, which are complex and require considerable data, such as neural network and random forest models. Therefore, the proposal of the DSPGM(1,1|τ,r) model is of great significance to the prediction of China’s stock market.
In view of the phenomenon of the pulse of the stock market, this paper builds an impulsive differential equation and introduces the particle swarm optimization algorithm (PSO) to optimize the delay factor τ and nonlinear factor r. Based on this, the grey prediction model DSPGM(1,1|τ,r) with impulse delay of stock price is proposed. This paper describes its application in China’s Shanghai and Shenzhen Indexes market closing index prediction of the stock market and studied the Shanghai and Shenzhen stock closing price forecasts. The specific results are shown in Section 5. It can be concluded that the variation trend of the predicted results of the DSPGM(1,1|τ,r) model is basically the same as the real stock price.
In this paper, the impulse delay phenomenon of the stock market price system is combined with the modelling of the grey prediction model, and the grey model is proposed. This model has a good effect on stock price prediction research, so it has an important guiding role in the prediction of China’s stock market and is of great significance to both individual enterprises and the country. However, the delay time of the new model is the time delay intercepted from the original sequence and must be an integer. When the delay is of fractional order, further study is needed.
Footnotes
Acknowledgments
The authors are grateful to the editors and the reviewers for their insightful comments and suggestions. This work is supported by the Social Science Planning and Doctoral Program of Chongqing(2020BS58); Project of Humanities and Social Sciences Planning Fund of Ministry of Education of China (18YJA630022); Chongqing Natural Science Foundation of China (cstc2020jcyj-msxmX0649).