
Abstract
Ensemble learning using a set of deep convolutional neural networks (DCNNs) as weak classifiers has become a powerful tool for face expression. Nevertheless, training a DCNNS-based ensemble is not only time consuming but also gives rise to high redundancy due to the nature of DCNNs. In this paper, a novel DCNNs-based ensemble method, named weighted ensemble with angular feature learning (WDEA), is proposed to improve the computational efficiency and diversity of the ensemble. Specifically, the proposed ensemble consists of four parts including input layer, trunk layers, diversity layers and loss fusion. Among them, the trunk layers which are used to extract the local features of face images are shared by diversity layers such that the lower-level redundancy can be largely reduced. The independent branches enable the diversity of the ensemble. Rather than the traditional softmax loss, the angular softmax loss is employed to extract more discriminant deep feature representation. Moreover, a novel weighting technique is proposed to enhance the diversity of the ensemble. Extensive experiments were performed on CK+ and AffectNet. Experimental results demonstrate that the proposed WDEA outperforms existing ensemble learning methods on the recogntion rate and computational efficiency.
Introduction
Facial expression recognition (FER) technology is the intersection and integration of psychology, image processing, computer vision, pattern recognition and other research fields. It has received much attention in the field of pattern recognition and artificial intelligence in recent years and holds great promise for a wide range of application, for instance, man-machine interaction, mental health assessment and social affective analysis.
Psychologist Mehrabiadu’s research [1] shows that in daily human communication, facial expressions convey as much as 55%of the total information, while voice and language transmit the remaining 38%and 7%of the total information, respectively. By the 1970s Ekman and Friesen [2] had defined the six basic facial expressions through extensive test experiments: Happy, Angry, Surprise, Fear, Disgust and Sad. Subsequently, Ekman and Keltner [3] further refined and improved the visual movement of facial expressions and proposed a facial action coding system (FACS) based on action units (AUs) to describe every single emotion change. In 2003, Russell proposed a core affect theory [4], where human emotions are described in an orthogonal two-dimensional space of arousal and valence.
Although state-of-the-art methods on well organized indoor datasets have showed great performance in FER, the recognition of human emotions in a real world scenario is still a challenging task. On the one hand, traditional hand-crafted features such as local binary patterns (LBPs), Gabor Filters, scale invariant feature transforms (SIFTs), have difficulties modeling the considerable variation of face expressions caused by illumination, occlusions and camera shooting angle in naturalistic conditions [5, 6]. On the other hand, numerous existing FER algorithms fail to obtain effective features that maximize the within-class compactness and minimize the between-class discrepancy of facial expression variations [7].
Recent developments in the computer vision community, especially in image recognition suggested that Deep Convolutional Neural Networks (DCNNs) could be used to address the above challenges on FER in the wild and improve the performance of FER tasks [8, 9]. DCNNs with layered end-to-end network frameworks and deep feature extracting techniques from local to global has largely improved the state of the art of face recognition. Various stacked network architectures for face recognition tasks such as AlexNet [10], VGG [11], ResNet [12], and DenseNet [13], have been proposed. Similar improvements have been obtained with the application of DCNNs to FER [14]. It is well known that the effective feature representation for the FER task plays a crucial role. Despite the softmax function with the cross-entropy loss (called softmax loss) has been popularly for the DCNN training, recent advances [6, 7] show that the existing softmax loss is inadequate to encourage the desired deep features.
Following the spirit of ‘The Wisdom of Crowds’, ensemble learning (EL) has been effectively used in computer vision to improve the classification performance [11, 15]. EL methods are built by independently training multiple weak classifiers on the same or different data to form one single classifier. Currently, a class of new EL algorithms using a set of DCNNs as weak classifiers have been proposed to improve these end-to-end methodologies [16]. DCNNs-based EL methods usually give rise to the following related questions: (1) How to reduce the training time and high redundancy of an ensemble of DCNNs which is inefficient? (2) How to obtain diverse, complementary and discriminant DCNN classifiers? To address the first problem, Siqueira [17] presented the ensemble with Shared Representations method (ESR), which can largely reduce redundancy and training time by sharing the low-level features learned by each branch (a single DCNN) without loss of generalization ability. In this paper we will deal with the second one.
The work proposed in the paper attempts to develop a new ensemble using a set of DCNNs for FER, termed weighted DCNNs-based ensemble with angular feature learning. In order to make individual DCNN classifier more discriminant, we employ the angular softmax loss to train DCNNs, which has a stronger geometrical significance and will give rise to more discriminative features compared to the traditional softmax loss. This work is based on the framework of ESR, which is composed of sharing layers and diversity layers respectively, therefore, the application of shared layers can largely decrease the redundancy and training time. The diversity layers of each branch have individually distinct parameters which encourage variety and complementarity of the ensemble. In order to effectively find specific expression regions of face images, we introduce an attention mechanism to this DCCNs-based ensemble framework by weighting the loss function using the weight matrix units.
In summary, the major contributions of the work are given as follows:
Applying the angular softmax loss instead of the commonly used softmax loss to train the proposed ensemble such that it can learn deep facial expression features with higher intra-class compactness and lower inter-class discrepancy. Proposing a new loss weighting techniques with weight matrix unit (WMU) to boost the diversity of the proposed ensemble. WMU can adaptively weight the loss of each branch by the ratio of its loss and the minimal loss of all branches such that the branches with large loss can be heavily penalized. Proposing a novel ensemble framework with the above proposed angular softmax loss and weight matrix unit to learning more discriminant representations for face expression.
Related works
In this section, we take a review about some facial expression recognition methods especially attention-based algorithms in section 2.1 and detailed review can be refered in [18]. In section 2.2, ensemble-based cnns proposed recently are comparied.
CNN-based FER Algorithms
Superior performance of CNN-based classification models for face recognition has inspired scholars to evaluate it for facial expression recognition. Sajjanhar [14] investigated the performance of some advanced classification models (VGG [11] and VGG-Face [19]) for FER. Extensive experiments show comparable recognition accuracy between VGG and VGG-Face where the latter outperforms the former in face recognition. Jain [20] combines convolutional layers and residual blocks together to build a DCNN model which could extract subtle differences from facial expression. Such a relatively simple model with great emotion recognition performance proves that the CNN-based classification model can handle FER tasks well and the depth of the model can also promote the recognition result.
Being different from the object classification, informative features for FER usually focused on small certain regions around eyes, nose and mouse. Lopes [21] adopted a series of pre-processing steps to extract only specific expression features of a face image and explore the influence of each preprocess technique on the model recognition accuracy. However, this will lead to low accuracy and poor robustness in unknown environments (in-the-wild datasets), in other words, the generalization ability of the model is poor. To handle the wild images where hand-crafted features fail to accurately describe the subtle emotion changes, BiaoYang [22] adopted two different networks to extract features from grayscale channel and its related LBP channel respectively. Supplemented by a weighted mixture strategy, the proposed WMDNN is able to learn informative features containing both local and global patterns. Unfortunately, the fusion weight parameter requires to be manually tuned in a discrete way to match different datasets.
Pedro D [23] imitates the human visual attention mechanism and introduces this attention module to FER tasks using U-net image segmentation method. Together with the high-dimensional features captured from basic feature module, proposed FERAtt represent the input image to a more efficient and cleaner version for better recognition and classification.
Ensemble-based CNNs
Traditional ensembles comprise a brand of independent models (teacher models), whose predictions are collected from the teacher models via averaging or voting strategy. A well-trained ensemble can effectively reduce the residual generalization error, which makes the ensemble of multiple networks perform more robust and accurate [24]. Each model was trained from scratch, which generated a mass of overlaps between the features learned from convolutional neural networks and resulted in high redundancy and computational burden. In addition, more storage space is required to save these model parameters, which makes it unsuitable for mobile devices where memory and computational power are limited.
Enhancement of the parallel computing power of GPUs greatly alleviates the computational burden of the ensemble, while many researches have been working to reduce redundancy and overlap in teacher models. Yong Li [25] proposed a convolutional neural network with attention mechanism (ACNN), using PG-Units that automatically detect shaded areas of the face image and assign them a relatively small weight. In other words, ACNN put more emphasis on informative regions with no occlusion during the training phase. Such strategy has indeed reduced the high redundancy, however, their method is still an explicit ensemble. The simple features of early network learning are still extracted repeatedly, wasting plenty of computational resources which could have been invest in processing complex features.
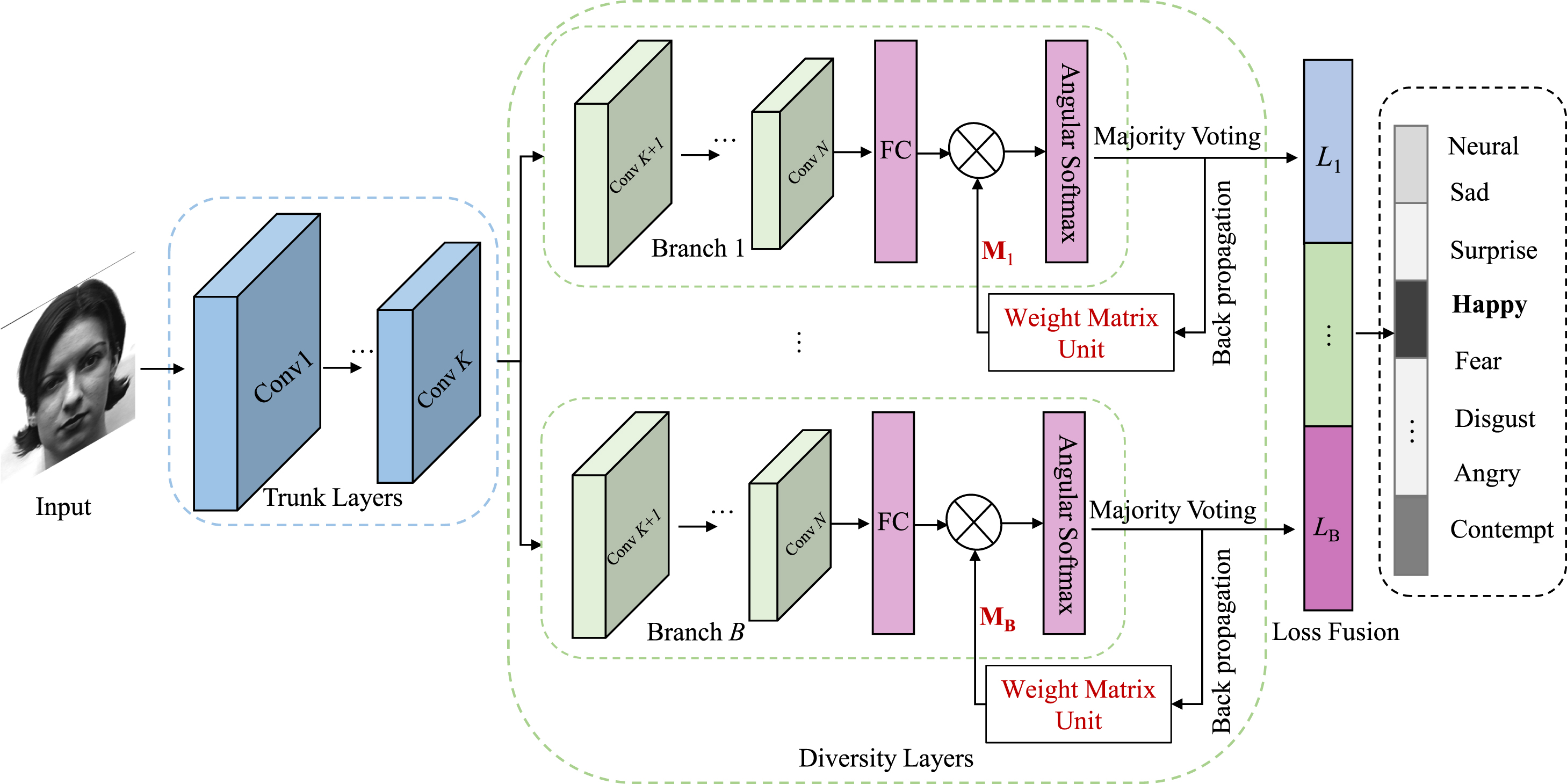
Illustration of our proposed Weighted DCNNs-based Ensemble with Angular Feature Learning (WDEA) for facial expressions recognition. The blue dashed block in the left corner of Fig. 1 represents the Trunk Layers. Simple facial patterns extracted from them are shared with green Diversity Layers that are sequentially stacked. The loss fusion employing majority voting gives the final classification results as shows in black block on the right side.
The proposal of knowledge distillation [26] provides a new solution for the development of an ensemble that can absorb knowledge from multiple models (teacher models) by a single model (student model). Zhiqiang Shen [27] proposes an implicit ensemble-based network where the single student convolutional neural network was trained under a generative adversarial learning [28] strategy, effectively reducing redundancy and maintaining diversity. Predefined block-wise loss can supervise and optimize the student network that are gradually restoring knowledge from teacher models as the network iterates. But a group of well-trained teacher models are a prerequisite for this approach, and the overall training time is quite long if you start from scratch.
Siqueira [17] gives his solution which can speed up training while reducing network redundancy: a structurally innovative semi-explicit convolutional neural network with shared representations layers and ensemble branches (ESR). The shallow convolutional layers are used to cut down the overall redundancy and training time of the network, whose learned simple patterns such as color and line information are shared with the ensemble of convolutional branches. As the explicit part of the network, branches take charge of diversity and generalization power. The model is guided by the cross-entropy loss function where features are represented as the inner product form. Also, the overall prediction is collected from ensemble-based branches by computing the sum of each branch’s loss. In this case, each branch contributes the same to the model’s prediction which violates the idea of “teaching students according to their aptitude”.
This section first introduces the proposed ensemble’s structure, followed by a demonstration of the weight matrix unit for weighting the loss of each ensemble. Finally, an angular softmax loss is described.
Framework of the proposed ensemble
The base classifier we used in this ensemble is AlexNet [10]. AlexNet consists of five convolutional layers, accompanied by max-pooling and normalization layers, and three fully-connected layers. Unlike typical ensembles, which are made up of a set of individual DCNNs, WDEA is made up of four parts: an input layer, trunk layers, a set of diversity branches and a loss fusion layer. Based on the above descriptions, the WDEA architecture is illustrated in Fig. 1. This framework, which differs from the conventional ensemble based on DCNNs, integrates several lower layers of all DCNNs into sharing layers, termed trunk. In other words, a common preprocessing step constructed using several stacked convolutional layers is added, and the output is then fed into all separate base DCCNs. The design of the ensemble framework is mainly based on the following considerations. Firstly, a DCCN often contain millions or even billions of parameters. For example, AlexNet has 60 million parameters. Therefore Training a DCNNs-based ensemble is a computationally intensive task. Secondly, it has turned out that DCNNs can learn only simple and local visual patterns such as oriented lines, edges, and colors from the lower layers. Higher layers integrate local patterns hierarchically from lower layers into increasingly complicated concepts such as nose, mouth, and eyes. Eventually, the last softmax layer encodes these higher-level representations into semantic concepts, such as emotion categories, which can be used for human emotion recognition. Therefore, utilizing the trunk may significantly reduce the amount of parameters of the ensemble, which leads to dramatic reduction of training time. Furthermore, adopting the shared trunk enables lower redundant local features and higher diversity for sequential branches. The loss fusion employs the majority voting for the final prediction.
Angular softmax loss
The traditional softmax loss is formulated as following:
where p
i
is the probability that the network correctly classify the pictures with the range of [0, 1], and
Recent advances in the softmax loss function [29, 30] show that the degree of confusion between the two classes is closely related to their angular separability in the feature space. In other words, features learned through angular space [31, 32] are more informative for classification tasks. The inner product,
Also, we normalize the feature and weight vectors and rescale them to a constant s [33].
This competitive training mechanism in the proposed ensemble framework allows each of all branches to learn cross but inconsistent facial expression features, resulting in improved diversity and generalization performance. However, such competitive strategy could make weak branches having lower classification power. To overcome this limitation, we introduce the weight matrix unit to weight the loss function for each of the branches. The weight matrix unit is designed to severely penalizes the branches with a higher rate of misclassification, while penalizing branches less for lower misclassification rate. Specifically, the loss of each branch is first computed after training a minibatch, then the weight of each branch is obtained by computing the relative ratio of the loss of each branch and the minimum of all losses. The loss ratios are used to construct the weight matrix in the diagonal manner. Obviously, the branch with the biggest loss has to be assigned the biggest weight for its loss function, while the branch with the smallest loss remains the initial loss. With the preceding description, the new loss function with the weight matrix unit can be formulated by
where B is the number of branches and L
b
denotes the loss of b-th branch.
Algorithm 1 summarizes the specifics of the proposed WDEA technique. Updates to the network parameters and how the ensemble branches are added to the model training are clear at a glance.

Experiments
In this section, we will firstly discuss the datasets used in experiments and the corresponding data augmentation. Secondly, a thorough network topology and experimental configuration will be provided, with references to both the lab dataset and the wild dataset. Thirdly, we analyzed the performance indexes of the proposed model, such as diversity, generalization power, and training acceleration. Then we performed an ablation experiment to evaluate the performance of the adopted angular softmax loss. Finally, the experimental results are going to be compared with the state-of-the-art methods, which show our superior performance.
Experimental datasets
Facial expression recognition pays more attention to the subtle changes of the facial image. High-quality facial images with good annotation are essential to develop and improve the emotion recognition algorithm. To date, some professional facial expression recognition datasets have been collected for research on emotion sense.
Under the guidance of the emotion universality theory [2], some datasets collect pictures through posing and compounding. These images are usually taken in the laboratory where the experimental environment is under control, with the lighting conditions and camera viewpoints precisely adjusted. In addition, posed images from which we call “in-the-lab datasets” are thought to be more informative than those captured in the daily life. In this paper, we used the Extended Cohn-Kanade (CK+) [34] as in-the-lab comparison experimental dataset shown in Fig. 2.

Examples from experimental datasets. Pictures in the first line are randomly selected from CK+, and the bottom are from AffectNet.

Network structure of our proposed WDEA. Bach normalization layers followed after each convolutional layer are hidden for simplicity. From top to bottom shows the in-the-lab experimental architecture, algorithm flowchart and the in-the-wild experimental architecture. Each color block corresponds to its process in the algorithm flowchart. Also, the Leaky-ReLU activation function is employed to increase nonlinearity.
The Extended Cohn-Kanade (CK+) invited 123 subjects from different ethnic and national backgrounds. They were asked to make a series of expressions ranging from calm to emotional peak and shot form the front or 30-degree view-point. Among the 593 sequences of images collected, 327 are labeled and we only take the annotated 327 groups of pictures for our experiments.
In the development history of psychology, there are also many psychologists who oppose the universal theory of emotion. For example, Russell [4] promotes the diversity of human emotional expression. The images obtained from the internet and daily life are more realistic, which helps improve the robustness and generalization power of the facial expression recognition system. We selected the most popular large-scale dataset, AffectNet [35], as our in-the-wild comparison experimental dataset, which is also illustrated in Fig. 2.
During the training phase, we adopt the data augmentation considering the imbalanced sample distribution. We use the color jitter strategy to randomly adjust the brightness and contrast. Also, the picture will be horizontally flipped at random with a probability of 0.5 and affine transformation is also adapted to ensure that each branch is training the different samples even if the input images are the same.
An improved version of AlexNet [10] is used in our experiments to extract facial patterns. As illustrated in Fig. 3, we resize the images to 96×96 pixels for uniform input. When training on CK+, we also need to convert the images to grayscale first because of the mixture of color pictures and grayscale images. As described in Fig. 3, input channels are set to 1. Batch normalization [36] layers are followed after each convolutional layer to prevent gradient disappearance and overfitting. Max pooling layers are also added to the second, third, and fourth batch normalization layers to down-sample the feature map. The global average pooling [37] layer converts the feature map generated from the last convolutional layer to a vector and transports it to the fully connected layer where the branch prediction is given. Referring to the work of Siqueira [38], we started adding branches after the third convolutional block and set the branch number to 4.
For better processing of the large-scale dataset with a high degree of noise, we added 3 convolutional layers along with a batch normalization [36] layer to obtain more memory space so the neural network could store the increasing pattern volumes. And correspondingly, we also increased the number of convolution kernels but kept the reduction rate of the feature map to achieve similar spatial structure information. Specifically, we add a max pooling layer after two convolution computations to cut the half size of the feature map. The depth of the CNN has not been pursued too much as our desire is to receive relatively good performance with limited computation resources. With the help of the transfer learning strategy, branches augment costs much less than CNN depth for model performance. We also rescaled the normalized facial features and related weight vector to 30. At the time our experiments were completed, the authors of AffectNet had not released the test set, so we used the validation set to complete the experiment and give the verification accuracy.
We adopted the Gradient Descent [39] with a momentum factor of 0.9 to guide the training and piece-wise learning rate decay strategy that every 10 epochs decays by half. We initialized the learning rate for the trunk layers and untrained branch layers to 0.1. In addition, a lower initial learning rate of 0.01 is given to the trained branch, thinking of the constantly learning on extra training images. For example, when we are training branch-5, the trained branch-1 can also update its parameters from pattern changes in the trunk layers. We tested a series of branch sizes to take a trade-off between performance and time complexity and list the results below 4. Finally, we start adding branches after the fourth convolutional block and set the branch number to 9.

Illustration of how the ensemble scale effects the model performance. Accuracy pulls up slower and slower as the branches added to the ensemble both in unbalanced and down sample label distribution.
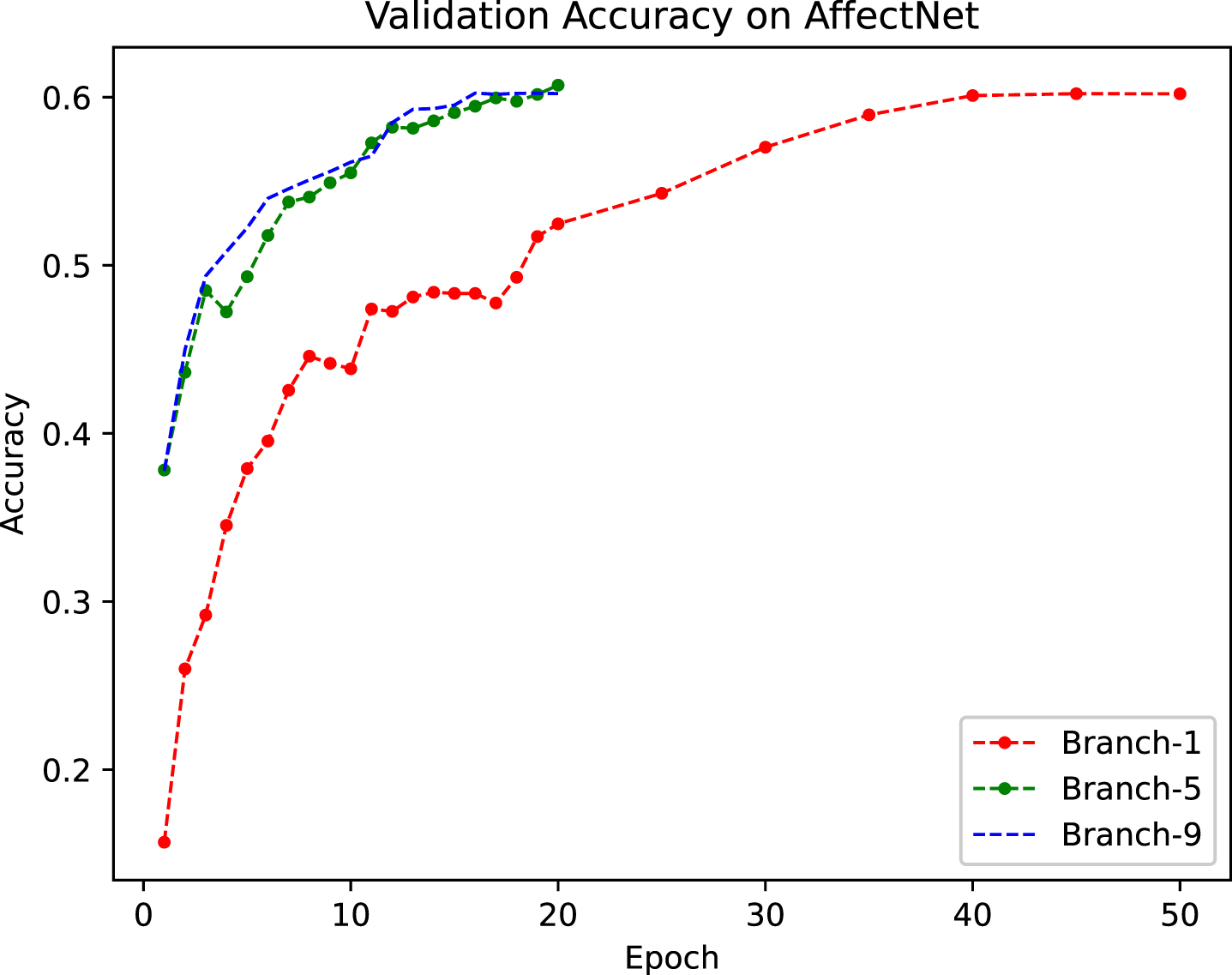
Validation accuracy on AffectNet. The red curve represents the verification accuracy of branch-1, green denotes branch-5 and blue represents branch-9. All the branches were trained from scratch.

Comparison of the Grad-CAM visualization on AffectNet between ESR-9 and WDEA-9. Red region of the saliency map indicates the informative facial patterns that plays a decisive role in the prediction of the model. We illustrate the prediction of each branch when we training the happy or surprise expressions as example.
The training time of a network is one of the most important indicators to measure its performance, particularly when training ensemble-based convolutional networks. It takes more time to train an ensemble, because we usually need to train each model from scratch. Fig. 4 describes our validation accuracy on AffectNet, which shows how shared layers improve and accelerate the training of new branches. Except for the maximum training epoch of branch-1, which was 50, the training epoch of the other branches was decreased to 20 but obtained similar performance. Despite the lower training epoch of 20, branch-5 and branch-9 converge faster than branch-1, whose training epoch is 50. When training the second epoch, branch-5 and branch-9 achieve an accuracy of 44%while branch-1 takes around 10 epochs to get the same performance. Prior knowledge coming from the trunk layers contributes to the acceleration of branch-5’s and branch-9’s training. This mode of transfer learning guarantees the generalization power of our proposed model. The ensemble structure as well as batch normalization behind each convolutional layer contribute to it too. Although the validation accuracy of latter branches is promoted slightly, the final recognition accuracy is higher than any single branch.
To discuss the diversity of our model, we used a visualize approach using Grad-CAM [40] to generate saliency maps. As illustrated in Fig. 5, saliency maps [41] visualize the activated region of the facial image whose informative feature contributes the most to the output prediction. For happy expression recognition, both ESR-9 and WDEA-9 learned about the active regions which contribute the most to the final prediction. Branch-1, Branch-4, and Branch-8 captured the cheekbone raise; Branch-2, Branch-3, and Branch-5 focused on the lips; Branch-6, together with Branch-7 paid much attention to nasorostral changes, while Branch-9 found that the winkle at the corner of the eyes expresses cheerful emotion. In addition, our model learned the pull up of lips after training the branch-9. The visualization results illustrated in figure 5 obviously reflect the high diversity of the model. When handling the more complex expressions of surprise, ESR-9 gives poor performance that only Branch-6 and Branch-7 classify the input facial image to ground truth label. Six of the remaining branches predicted the expression as fear, and branch-1, branch-5, and branch-8 (ill-trained branches) only learned quite small region around the nose. The proposed WDEA-9 adaptively adjusts the branch weight and improves the ill-trained branch. Branch-1 and Branch-5 focused on the eyelid lift, Branch-6 and Branch-7 captured regions where pull up the inside of the eyebrows. Branch-4 learned informative features from nostrils and pouches and succeeded in predicting the surprise expression under the guidance of angular softmax loss. As a result, five branch of our model made the right predictions (Branch 1, 4, 5, 6, 7) and finally gave the correct prediction based on the majority voting strategy.
Comparison results of the angular softmax loss and weight matrix unit on CK+
Comparison results of the angular softmax loss and weight matrix unit on CK+
By calculating the similarity of facial features extracted from different images, each branch gives a predicted facial expression. The cosine similarity used in our model can be treated as a normalized version of the inner-product of the learned deep feature vector and weight vector. To investigate the contribution of the angular softmax loss and weight matrix unit we used to model performance, we performed ablation experiments with the angular softmax loss and weight matrix unit off/on. Comparison results are illustrated in Table 1. The traditional ensemble, ESR-4, and WDEA-4 models were tested respectively on the CK+ dataset. As listed in Table 1, the angular softmax loss and weight matrix unit promoted the test accuracy by 0.06%, 0.10%respectively. The promotion pulled up to 0.26%after introducing two extensions, which is remarkable since the promotion between traditional ensemble and ESR is 0.18%.
Experimental results
Emotional perception is not just a simple and universal decoding process. There could be great disagreement between different annotators, even the same annotator with diverse emotions. Of the manually annotated images, 36,000 were annotated by two annotators at the same time, and only 60.7%of them had the same label. In addition, there is a serious imbalance in the label distribution of datasets, as shown in Fig. 6. In the experiments in this paper, we abandoned the automatically annotated images and adopted the down-sample strategy to handle the long tail issue.
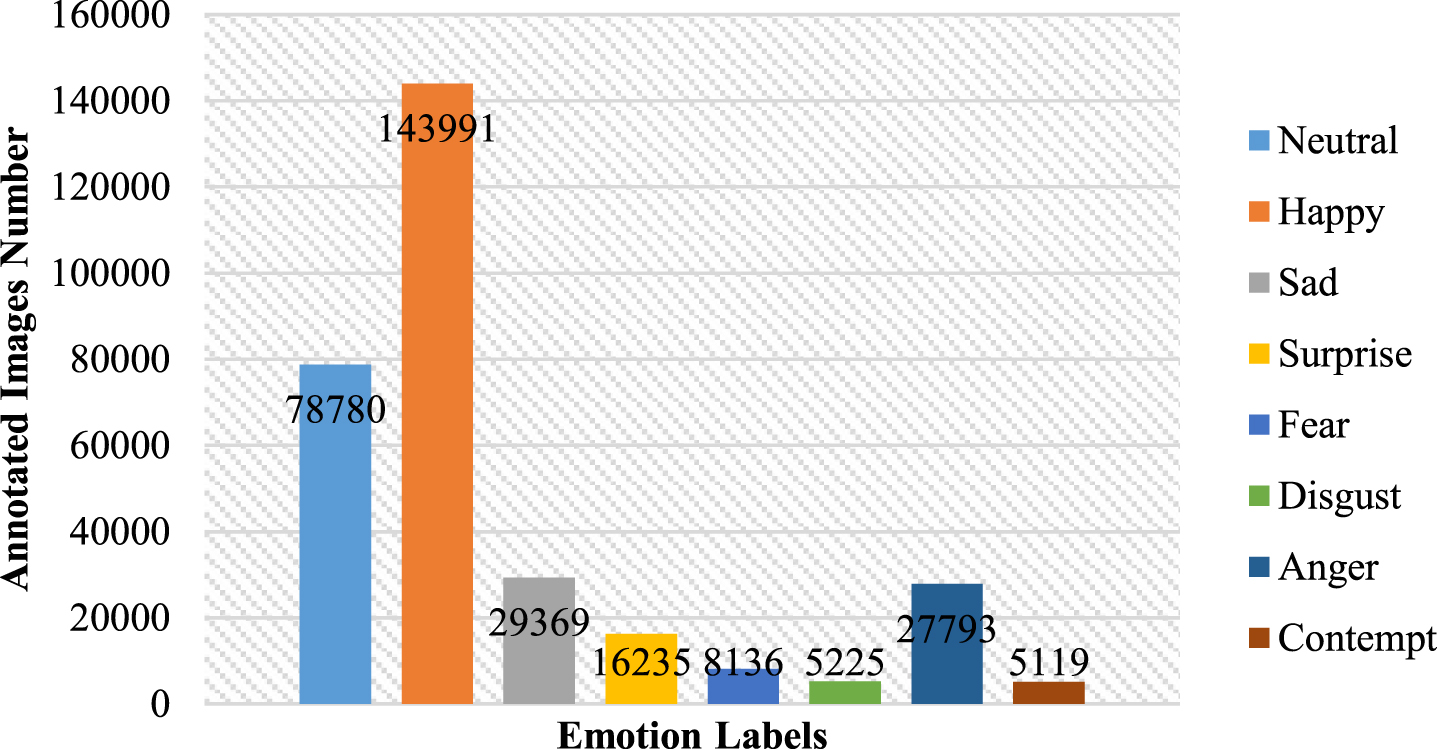
Annotated images distribution of AffectNet.
From Fig. 6 we can see that the contempt expression only has 5119 images, which accounts for around 1.6%. Such a small sample size poses a great challenge to facial recognition and pull down the overall accuracy. Besides, the neutral emotion is easily confused with negative expressions such as sad, anger, fear and contempt. The misclassification percentage pulls up to 13.39%, 7.22%, 7.20%and 13.89%after adding the neutral expression as illustrated in [18]. A number of scholars therefore chose to remove the neutral category [25] to achieve a better performance.
In the confusion matrix (Fig. 7), color of the square related to happiness is darkest, which are reasonable in condition of the abundant samples. Categories such as fear, contempt and sad are recognized in a relative lower accuracy but already well recognized if we take the short supply of training samples into account. The light gray area in the left indicates that some negative samples were misclassified as neutral and validates our previous analysis.

Normalized confusion matrix of WDEA-9 predictions on the AffectNet dataset. Squares with different colors along the diagonal represent the recognition rate of each category.
In the experiment on CK+, we extracted the first one and the last three images from 327 sequences with annotated labels. The subjects were asked to make a series of expressions ranging from calm to peak, so we annotated the first image as neutral and labeled the last three images as the same expression according to the corresponding txt file contained in the metadata. Through the above operation, we got 1308 images from 123 subjects and assigned them to 10 folds through an iteration loop. Cross validation [35] was adopted for fair comparison. We took the average accuracy of ten experiments where fold-t was used for testing, fold-t + 1 for validating and the first four folds of the remaining eight folds were chosen to be training set. Additionally, t represents the experiment index ranging from 1 to 10. Our framework focused on the feature extraction phase and achieved performance close to that of FERAtt [23] where attention-based pre-processing strategy, deeper baseline and structured gaussian manifold loss were adapted. Detailed experiment results are reported in Table 2. The DASE model performed experiments using both 7 and 8 emotion labels, so we used it to compare the performance under different tags. From Table 2 we can find a smaller standard deviation in WDEA compared with ESR, which demonstrates better adaptability towards sample changes. We also conduct a paired t-test for these two means (ESR-4 Lv.3 and WDEA-4) to show if there is any significant difference between the two models. The p-value (p=0.201>0.05) between the ESR with four branches at level 3 and our WEDA with four branches indicates that the generation abilities are comparable while the robustness is better (narrower deviation).
Test accuracies of some excellent baselines on CK+ and corresponding number of parameters and their emotion labels used in training
For the section of experiments on AffectNet, we first trained the model without any label processing, noted as WDEA-IB. Subsequently, we loaded up to 5000 facial images per category when we trained the branches. This down-sample strategy created a relatively balanced label distribution and helped our model achieve good performance. Table 3 displays the validation accuracies of various methods, including ACNN, which used 7 emotion labels in the experiment.
Validation accuracies of the existing baselines on AffectNet and their corresponding labels used in training
Under the unbalanced label distribution circumstance, our model improves the accuracy by 4.6%which shows the effectiveness of WDEA in processing large-scale datasets. By adopting the label balance strategy, our proposed model outperforms other state-of-the-art methods, including pACNN [25] and gACNN [25] whose baseline was VGG [11] with an attention mechanism.
Facial expression recognition, on account of its inherent subjectivity and diversity, is a great challenge for a single neural network. Traditional ensemble-based convolutional neural networks can build robust, high-degree of diversity models after training on big-scale datasets, but also brought high redundancy and computation burden. Recently, Siqueira gave an ingenious solution by using a semi-explicit network architecture with shared representation layers and branches of the ensemble. However, when the training sample categories are extremely unbalanced, only a few branches of the ensemble can give the correct prediction. Our weighted ensemble-based convolutional neural network with angular feature learning (WDEA) can efficiently improve the performance of ill-trained branches and promote final accuracy through majority voting. For example, 5 branches gave the right prediction in the “surprise experiment”. Finally our model successfully recognized the emotion. Although the baseline adopted in our WDEA is quite simple, performance turns out to be great in view of computational resources consumption and it outperforms most algorithms using deeper baselines. Moreover, our model enhances the diversity and generalization power without increasing the computational burden and redundancy of large-scale datasets.
From the experimental results, we can see that imbalanced label distribution has a great influence on facial emotion recognition. Our future work is to research the method of balancing sample labels and improve the performance of under-presented emotions.
Footnotes
Acknowledgments
This research was funded by National Nature Science Foundation of China under Grant 60875004. and Natural science fund project of colleges and universities in Jiangsu province under Grant 07KJB520133.