
Abstract
Remote sensing image segmentation provides technical support for decision making in many areas of environmental resource management. But, the quality of the remote sensing images obtained from different channels can vary considerably, and manually labeling a mass amount of image data is too expensive and inefficiently. In this paper, we propose a point density force field clustering (PDFC) process. According to the spectral information from different ground objects, remote sensing superpixel points are divided into core and edge data points. The differences in the densities of core data points are used to form the local peak. The center of the initial cluster can be determined by the weighted density and position of the local peak. An iterative nebular clustering process is used to obtain the result, and a proposed new objective function is used to optimize the model parameters automatically to obtain the global optimal clustering solution. The proposed algorithm can cluster the area of different ground objects in remote sensing images automatically, and these categories are then labeled by humans simply.
Introduction
Remote sensing image clustering analysis is aimed at high-spectral annotation to provide technical support for decision-making in fields such as water resource evaluation, large-scale engineering site selection, geological environment monitoring and evaluation, evaluation of changes in arable land and deforestation, vegetation change research, and seasonal pasture change analysis. Due to the different geological and weather conditions, remote sensing images vary considerably, it is costly and difficult to obtain the labeled data for training. So many unsupervised techniques have been gradually developed and applied to label the massive remote sensing image samples. It can save a lot of human resources and overcome subjective factors of human labeled partly.
Clustering methods for remote sensing images can be divided into mean-shifting, density-based, hierarchical [1], spectral [2, 3], grid-based [4] methods, and so on. In recent years, there are many new research directions of the clustering algorithm. Various improved graph clustering, spectral clustering, and multi-scale clustering methods have been proposed. Both graph clustering and spectral clustering are algorithms evolved from graph theory, which have been widely used in clustering. Multi-scale clustering uses more than two indicators to measure the relationship between data and cluster the data. In addition, deep clustering is also the latest research direction. Compared with traditional methods, these new clustering methods have achieved good results in different application scenarios. These methods can solve remote sensing image clustering to some extent, however, there are still exist some disadvantages: First, no matter the image pixel points are decomposed in any way such as RGB, HSV or Lab, the pixel points show irregular distribution, as shown in Fig. 2(c). Visually, the distribution density of pixels is not uniform, and there is no obvious boundary between clusters of different types, and no obvious spherical cluster is formed. Using the centralization method to cluster the image will result in the wrong clustering of the aspheric surface cluster and lead to the defect of clustering effect. The dense-based method will cause the bad clustering of the sphere clusters with uneven density distribution to some extent, and still cannot achieve better clustering effect. The two types of methods can not take into account the clustering problem of arbitrary shape clusters, and the combination of Euclidean distance and domain density can avoid wrong clustering to a certain extent, which is helpful to solve the problem that can not be solved by using the above scale clustering alone, that is, it can reduce the sensitivity of distance-based clustering method to point distance, It can also avoid clustering errors caused by uneven density.
Next, existing clustering algorithms often require humans to determine some hyperparameters, such as the number of clusters, the measurement of point density, etc., and manually assisted determination is required no matter using the elbow method, Average Silhouette coefficient and the square error in the cluster.
So, the clustering segmentation problem of remote sensing images cannot be easily addressed using existing algorithms unsupervised. To find a suitable unsupervised clustering method for different shapes and density distributions, we propose the PDFC, and a brief description of this approach follows: the number of clusters can be confirmed by the peaks in the core data point distribution, and the positions of the cluster centers and the point density weights are also determined by the peaks. In the process of clustering, to avoid the disadvantage of using distance as the single index of clustering, we introduce the neighborhood density and Euclidean distances (hereinafter referred to simply as distance) between points as the index of clustering, and take the density weight error and the distance error of the center of mass as the convergence condition to complete the iterative process. Meanwhile, setting up a reasonable double objective optimization process to get the global optimal clustering results achieves a better clustering effect.
Based on the discrete distribution characteristics of pixel points, a computing process of a neighboring point set with low time complexity was designed to control the algorithm complexity within O (nlog (n)). Our algorithm solves the problem of the number of sample clusters and the selection of an initial clustering center point in the case of no supervision and no prior. This avoids convergence to the local optimum caused by the improper selection of an initial clustering center and accelerates the convergence process of the approach. Inspired by nebula formation, the iterative process of the clustering approach uses density weight and distance as basis of data point clustering. It avoids the clustering center offset due to outliers, making it especially suitable for the local uneven densities of aspheric clustering like remote sensing image. The screening of the optimal clustering results is set as a double objective optimization process, and the optimal clustering result is obtained by setting the double objective equilibrium optimization function of the average point density and the silhouette coefficient (SC) to avoid the situation of the single objective optimization falling into a local optimal solution.
Related work
Many clustering algorithms can be used for remote sensing image clustering. In the following, we discuss the advantages and disadvantages of various clustering algorithms to compare them with PDFC. Centroid-based algorithms such as Kmeans [5], K-medoid [6], and other improved methods [7–9] have the advantages of simple principles, convenient implementation, and fast convergence. However, because the iterative process tends to fall into the local optimal solution, the clustering effect is flawed. In response to this problem, Fritzke [10] allowed a few and limited retries for the recent jump. the improved algorithm solved the problem of the Kmeans (Kmeans-u*) iteration process ending prematurely due to local minimization, which improved the clustering performance of the Kmeans algorithm to some extent. In contrast, this type of algorithm only uses distance as the clustering scale, and such an effect is not suitable for aspheric clusters.
Fuzzy c-means (FCM) and other improved methods [7, 11–13] calculate each element in the membership matrix to represent the degree of the sample belonging to a certain category. They use the Lagrange multiplier method to calculate the minimum value of the function to complete the clustering process. However, selecting the location of the initial center of mass and the number of centers of mass is always unavoidable in soft clustering algorithms. Therefore, Pei et al. [14] proposed a novel density-based FCM algorithm (D-FCM) by introducing density of the point distribution into each sample. The density peak was used to some extent to determine the number of clusters and the initial membership matrix.
Meanwhile, the Gaussian mixture model (GMM) [15, 16] clustering algorithm is equivalent to the generalization of Kmeans and other algorithms. The characteristics of the data can be better described with only few parameters. Neagoe et al. [17] proposed a new method for semi-supervised clustering of remote sensing images using a (GMM-EM) clustering cascade according to the difficulties in remote sensing image clustering; they selected the number of clustering pixels to be added to the training set according to the GMM capabilities for remote sensing image clustering. However, the GMM algorithm incurs a large computational cost and demonstrates slow convergence.
The density-based clustering algorithm represented by DBSCAN [18] shows strong robustness for uniform-density clusters of any shape and can divide clusters well, but it is not easy to select a suitable density threshold, especially for clusters with a large difference in density. The circular radius needs to be adjusted constantly to adapt to different cluster densities, and no reference has been established. Furthermore, DBSCAN requires neighborhood queries for all objects and the propagation of labels from one object to another. This scheme is time-consuming and thus limits its applicability for large datasets. Li and He et al. [19, 20] used the improved DBSCAN method combined with supervised learning for remote sensing image clustering to detect ships and vehicles. Mai [21] proposed anytime parallel density-based clustering (AnyDBC) to compress the data into smaller density-connected subsets called primitive clusters and labeled objects based on the connected components of these primitive clusters to reduce the label propagation time. This improved approach showed a reduced range query and label propagation time compared to DBSCAN.
More and more scholars use the combination of clustering and neural network [22], and apply it to remote sensing image recognition. This method has high accuracy, but it requires high computing resources. Recently, Chen et al. [23] proposed a ReDO model to achieve a certain degree of unsupervised image segmentation by using the method of deep clustering. Gargees et al. [24] proposed a deep feature clustering for remote sensing imagery land cover analysis. These approaches are especially suitable for datasets with large image data and can complete tasks such as semantic segmentation. However, due to the need to manually specify the number of clustering and other supervisory operations, completely unsupervised clustering cannot be achieved.
Point density force field clustering process
Different geological environments present a certain area distribution in remote sensing images. If each pixel is analyzed one by one, unnecessarily high computing resources will be consumed. In this study, the simple linear iterative cluster algorithm (SLIC) [25–27] is adopted as a preprocessing image clustering step (In other clustering algorithms for comparison, SLIC is also used as the preprocessing step before clustering).
The SLIC algorithm uses the super-pixel to represent the pixel value of a small area, which has two advantages: firstly, for remote sensing image, clustering each pixel one by one will bring a huge amount of computation, which is neither economical nor necessary; secondly, SLIC algorithm is equivalent to the smooth denoising process of the image, which eliminates the influence of high-frequency noise points in the image on the clustering effect.
Core data weight density distribution
The distribution of superpixel data points is in a chaotic state, we can extract certain key samples from the data points based on a statistical concept and infer the correctness and appropriateness of the clustering result according to the differences in the densities of the key samples. That can eliminate the interference in inessential samples and strengthen the links between key samples. Because the preprocessed image data of the three channels of RGB are all discrete values between 0 and 255, any data point with a large gap in the RGB channel value cannot be a neighboring point. Therefore, it is meaningless to calculate the distance between large-gap data points. First, we use quicksort [28] to sort and store the superpixel values of the RGB three channels separately and set the step length as s. The R channel pixel value of the data point x
i
is r
i
, and the R channel pixel value of the data point x
j
is r
j
. When calculating the distance d
ij
between data point x
j
and data point x
i
(with x
j
meeting the range condition r
j
∈ [r
i
- s, r
i
+ s], and the constraint condition r
i
- s ≥ 0, r
i
+ s ≤ 255), if
E
i
is an edge point and C
i
is a core point. The distinction between E
i
and C
i
is determined by the following equation:
The number of neighborhood points is used as the weight of the core point. We calculate all core points weight, and the discrete distribution of the density weights of core points in the three-dimensional RGB space (hereinafter referred to as density distribution) is obtained. Special instructions: as the RGB channel is a three-dimensional space, the display effect is not easy to show. Therefore, the images in this paper are all replaced by R and G two-channel matrix images. It can be seen from Fig. 2(b) that the distribution of the superpixel data points presents an irregular shape, no definite clustering center, uneven densities of data points, and no obvious hierarchy. In the remote sensing superpixel scatter diagrams shown in Fig. 2(c), the red points are the edge points and the green points are the core points with the step length s equal to 3.
To determine the RGB coordinates of the peak points, it is necessary to filter the density distribution first so that it presents an approximately continuous state in the RGB space. In this study, a multidimensional Gaussian kernel function is adopted to complete this process. The expression of this kernel function is as follows:
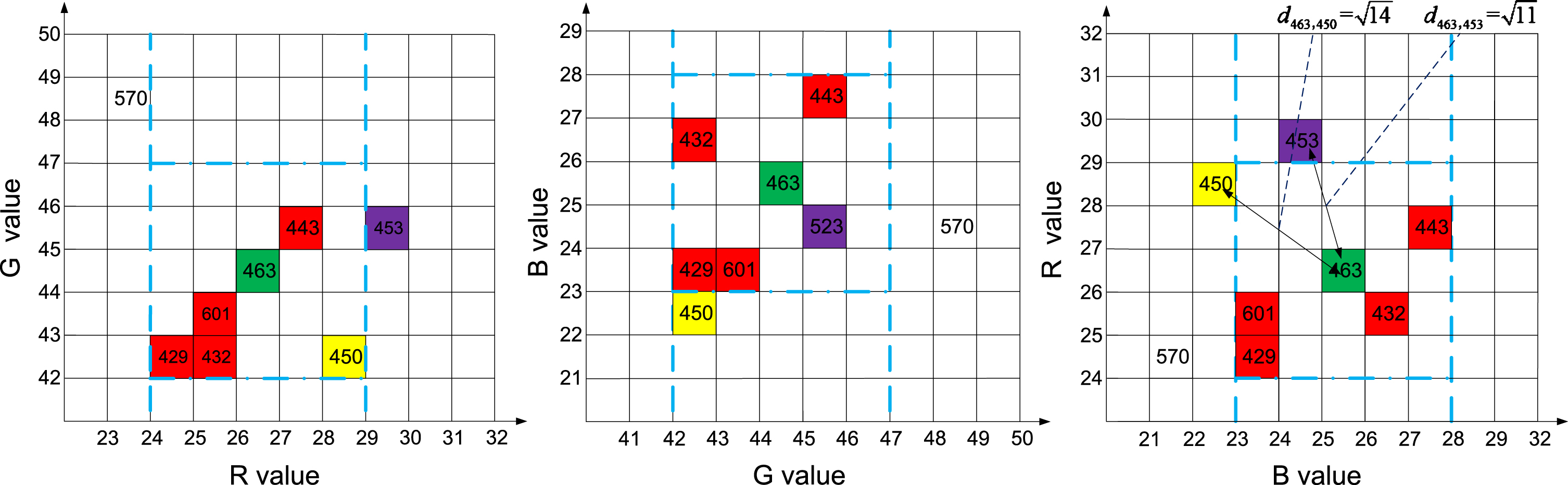
RGB space neighborhood range for point 463 with a step-length size of 2. The above figure shows the neighborhood range of point 463, where the step-length size s is 2, the cut-off distance d
R
is
Scatter image after superpixel segmentation and the density heat map. (a) are the original image, (b) are the image pre-processed by SLIC super-pixel segmentation, (c) are the distribution of super-pixel points in G-R space, green represents the core points, red represents the edge points, (d) are the thermal distribution of filtered super-pixel scattered points, and red box is the detected peak points.
Since the point density is distributed in the RGB three-space, both the density distribution and the Gaussian kernel function are three-dimensional and D is equal to 3. The three dimensions of the kernel function RGB are set as uncorrelated, and the size of the kernel function is set as a random natural number between 4 and 10. The filtered thermodynamic density distribution can be obtained. The density heat map after Gaussian filtering is shown in Fig. 2(d). There are several peak regions in the thermodynamic chart of the density distribution, and these are the high-density points where superpixel values gather. We use the maximum value in the 26 connected regions of the spatial search neighboring data points to find several peak points in the three-dimensional heat map. With a change in the step-length size s, the neighborhood density of core points also changes. Therefore, the location and number of thermal map peaks will vary. By detecting the peak in the density distribution, the initial clustering center of the distribution of superpixel data points can be determined. The RGB coordinates and point density weights of the detected peak points are taken as the coordinates and weights of the initial centroid of the clustering iteration process, respectively.
We make a simple analogy, and liken the PDFC to the nebula formation process. The less massive planets orbit the more massive stars. Massive fixed stars are first formed, followed by planets, which eventually leads to the development of stable nebulas.
First, several concepts need to be defined in this section:
1.The peak point is defined as a fixed star.
2.The other core data points are defined as planets.
3.edge points are satellites.
4.A peak point and core points of the same cluster as the peak form a nebula.
5.The average point density of all core points in a nebula is defined as the gravitational value of the nebula.
To simplify the clustering process, We ignore the gravity of satellites and the gravity between planets and only consider the gravity between fixed stars and planets. Only the magnitude of this gravitational force, and not its direction, is considered. The mass of a nebula is an important index of its gravitational range. In the clustering process, the greater the point density, the wider the gravitational range. During this process, peak point P
i
are thought of as fixed stars, and the nebula formed from it is set as z
i
. The other core data points are thought of as planet points c
j
, the density of the nebula
Step1: The density of a planet c
j
is ρ
c
j
, the density of the nebula z
i
is
Step2: The coordinates of the mean positions of all the planets in the nebula are used as the new fixed star positions, and the average density value of the planet belong the nebula is calculated as the density value of the new fixed star. Step1 and Step2 are repeated. The core points of the nebula are constantly adjusted and until the position of the fixed stars and the density value of the nebula remain essentially unchanged, i.e., the approach converges. The iteration is then stopped to obtain the clustering results of all star and planet points. Finally, the satellite points and the nearest planet point are clustered into one cluster to complete the clustering process. The gravitational map of stellar planetary points is shown in Fig. 3.
If an image has n superpixels, and when calculating the distance from each data point to all the other data points, we should have to do n × n calculations, and the time complexity is O (n2). The time cost is extremely high. The time complexity of Sections 3.1 is O (n (log (n))). The time complexity of performing in Sections 3.2 and 3.3 is O (n), because it is only necessary to traverse all the superpixel points a constant number of times. Thus, the overall time complexity of the PDFC approach is O (n (log (n))). It is also competent in the direct processing of pixel-level images. That is to say, even without SLIC pretreatment, PDFC can also directly complete the task of image clustering on a regular computer.
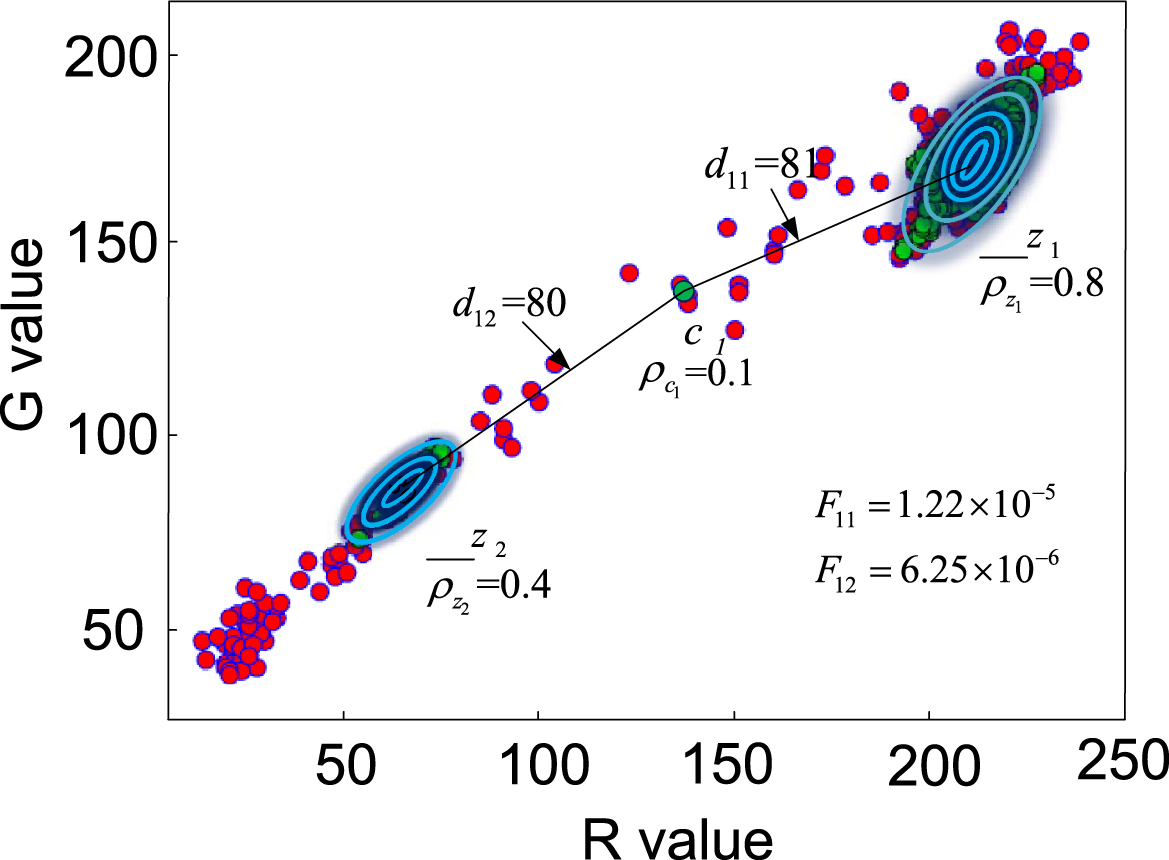
Gravitational map of stellar planetary points.
The distance between planet point e1 and two fixed star points is 80 and 81, and z2 is closer. However, the gravitational values are 1.22 × 10-5 and 6.25 × 10-6. Then, e1 is more easily attracted to z1. So e1 should be classified as z1 in this iteration.
Although the number of clusters, boundary distance, and other parameters can be set manually, without sufficient prior knowledge and multiple tuning attempts, it is difficult to find suitable evaluation criteria for these clustering parameters. As the distribution of the remote sensing image density is uneven, the clustering center is not obvious, and using a single objective optimization can easily lead to deviations from the global optimal solution. To avoid the disadvantages of single objective function optimization, we set the entire clustering process as a double objective optimization process, and an optimal clustering result is obtained by setting the double objective equilibrium optimization function of the standard deviation of the average point density and the SC. In terms of the distance, we expect a larger total SC to provide better clustering results. The equation to determine SC is as follows:

Iterative convergence curve and objective function curve of the four images. (a) and (b) are the graphs of distance and weight error convergence. (c) are different step-lengths correspond to the value of the objective function J
Summary of notations
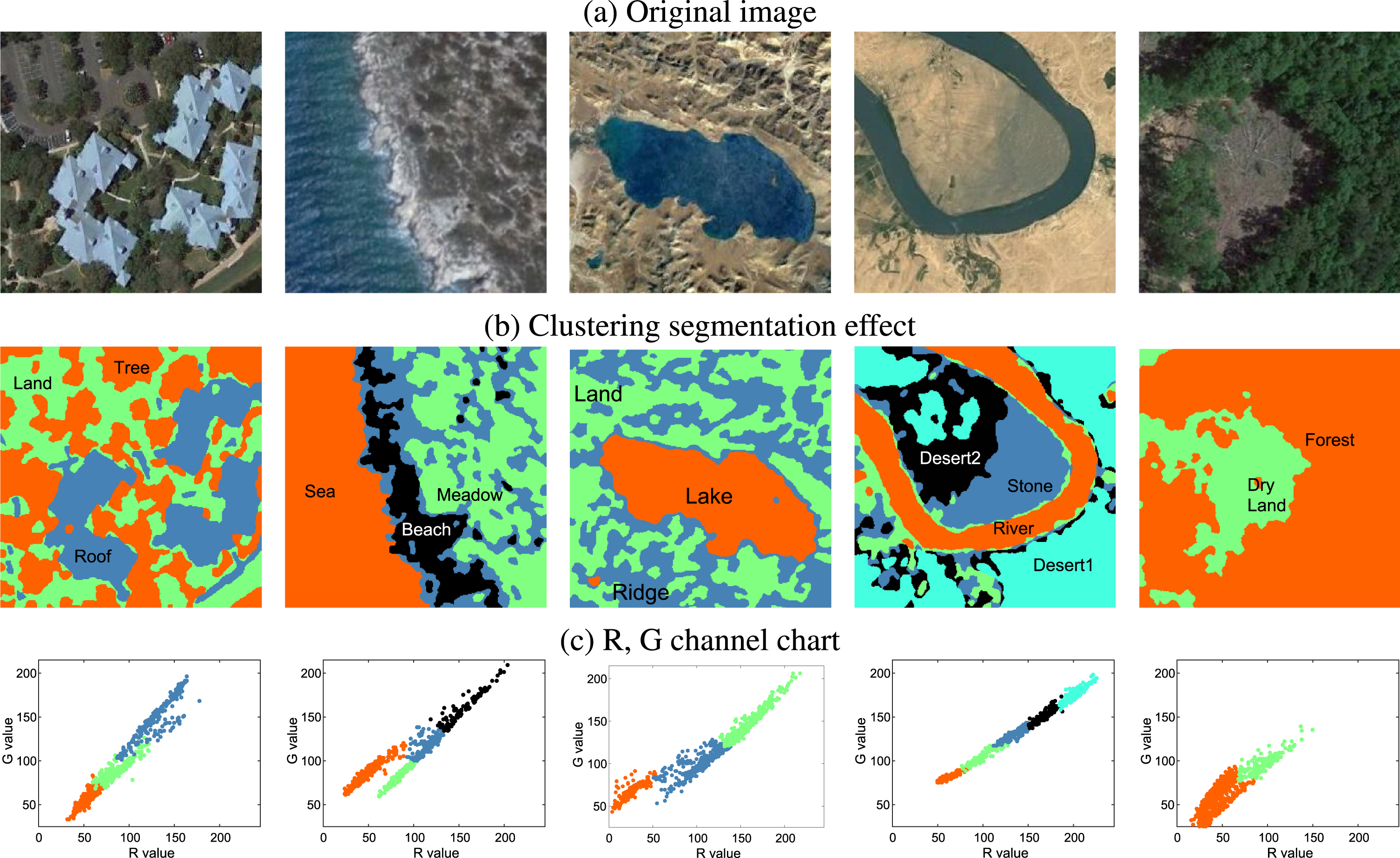
The clustering segmentation effect display of PDFC on the tag-free UCMerced-LandUse remote sensing dataset.
In terms of the point density, the mean value of the density weight standard deviation of all clusters that contain points should be obtained. We expect that the clustering result reduces the point density deviation of the data points of the same category of ground objects to the maximum extent possible, such that the data point density of the same category of ground objects is similar. Therefore, the objective function can be set as the ratio of the mean standard deviation of the point density weight within the cluster to the mean of the SC. When the smaller the objective function value is, the better the clustering effect is. Therefore, the optimization process can be completed by comparing the clustering results of different step parameters.
Objective function J can be expressed as follows:
In this study, the dataset image was first preprocessed by the SLIC superpixel segmentation algorithm to produce a collection of superpixels for each image. PDFC verifies with the other five clustering algorithms on the super-pixel dataset rather than the original image dataset.
Index
This paper compares the following indicators of different algorithms: Accuracy, Normalized Mutual Information (NMI), Rand index (RI), Adjusted Rand Index (ARI), Jacarrd Index (JI). The symbol used for the index does not conflict with the symbol representation above and it is not listed in Table 1.
Accuracy
The formula for calculating the Accuracy of sub-datasets is as follows:
The formula derivation of Normalized Mutual Information (NMI) is given below: Suppose the joint distribution of two random variables (x, y) is P (i, j). The marginal distributions are P (i) and P′ (j). I (x ; y) is the mutual information. It is the relative entropy of the joint distribution P (i, j) and the product distribution P (i) (j); the formula is as follows:
Let the clustering result of be C ={ C1, C2, ⋯ , C
m
}, and the known partition is P ={ P1, P2, ⋯ , P
m
}, Rand Index (RI) [29] and Jacarrd Index (JI) [29], the formula is as follows:
The Adjust Rand Index (ARI) assuming that the distribution of the model is random, that is, the division of P and C is random, then the number of data points of each category and each cluster is fixed.
E (RI) is the mean value of each cluster RI, and max(RI) is the maximum value of each cluster RI.
Accuracy is a simple and transparent evaluation measure. NMI can be information-theoretically interpreted. The RI and ARI penalize both false positive and false negative decisions during clustering. The F measure in addition supports differential weighting of these two types of errors. These five indexes can be used to evaluate the clustering effect of various algorithms.
Experiment I
The ‘2015 high-resolution remote sensing image of a city in southern China’ dataset [30] of the CCF Big Data competition was used as the dataset for verifying the algorithm clustering effect. It included 10,000 original geological remote sensing images and ground-truth images with a size of 256 × 256 pixels. Since all images of the dataset are not divided, in order to better verify the clustering discrimination of the five algorithms. We extracted 5000 remote sensing images with different ground object types for the validation dataset and divided them into 20 sub-datasets with 250 sample images each. In Fig. 6, compared with other algorithms, the mean accuracy of the PDFC approach for this dataset is in a higher range and the boxes are smaller.
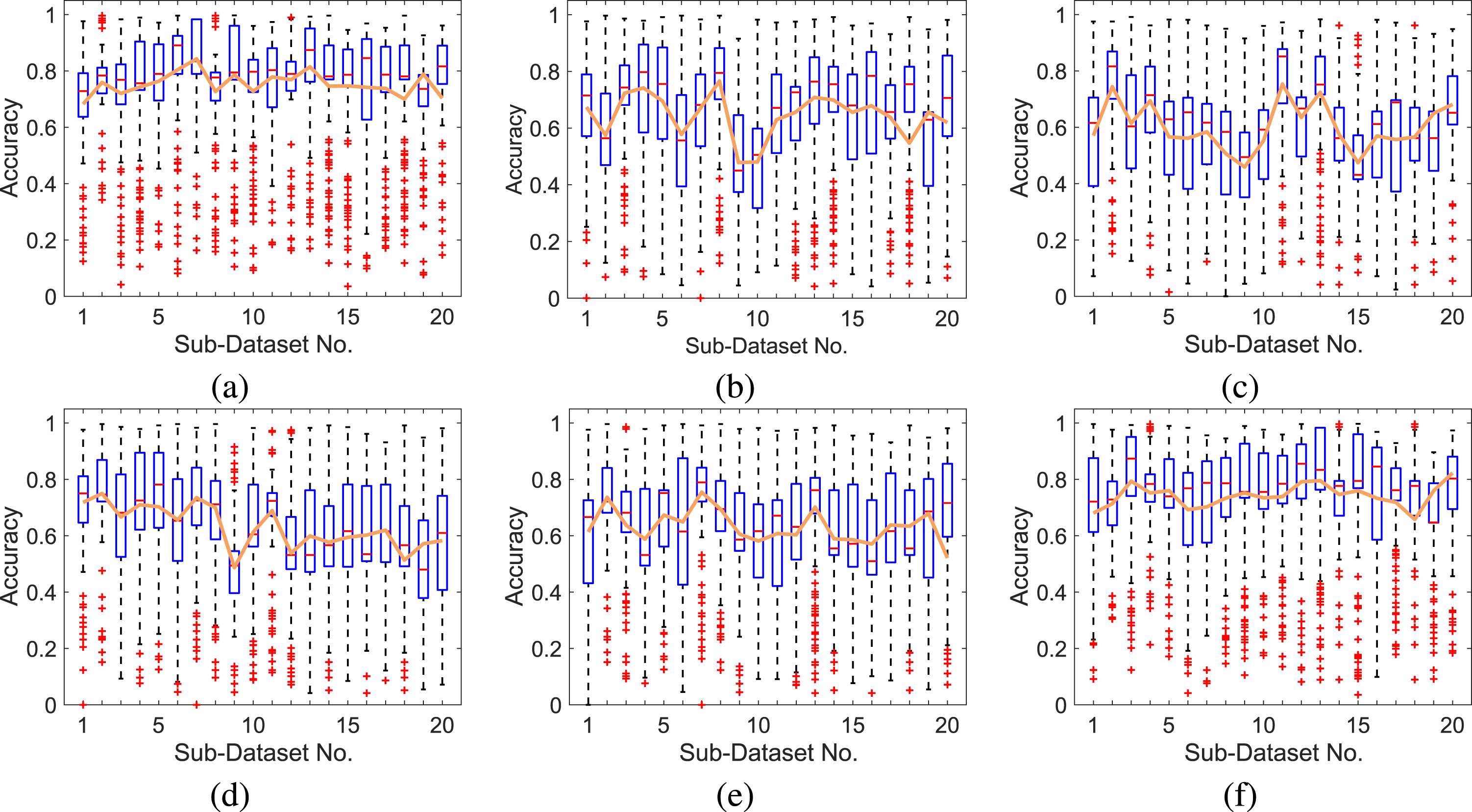
Box graphs of the accuracy of different clustering algorithms: (a) PDFC (b) AnyDBC (c) D-FCM (d) Kmeans-u* (e) GMM-EM and (f) ReDO. The orange line in the graphs represents the mean value of ACC, the blue box represents the centralized distribution of ACC, the red line of box type represents the median and the plus sign represents the outlier point.
Comparison of mean values for various algorithms on four indices on dataset, and the bold is the maximum
The mean values of the NMI, ARI, RI, and JC of the sub-datasets were calculated to test the performance of the algorithms. The closer the four indicators are to 1, the better the clustering effect will be. Due to the limited space, we randomly select 10 sub-datasets for presentation in Table 2, from which it can be seen that PDFC has achieved a large value on most of the molecular datasets, representing a good clustering effect.

The clustering segmentation effect of PDFC on the ‘2015 high-resolution remote sensing image of a city in southern China’ dataset

The clustering segmentation effect of PDFC on the ‘UCMerced-LandUse’ remote sensing dataset
Exponential performance of various methods on ’UCMerced-LandUse’ dataset
Comparison of runtimes for various algorithms
The runtime of the PDFC approach is not significantly different from that of other fast clustering algorithms.
The ‘UCMerced-LandUse’ remote sensing dataset [31] was used as the dataset for verifying the algorithm clustering effect. It is a 21-class land-use-image dataset meant for research purposes, and there are 100 images for each of the following classes. Each image measures 256 × 256 pixels. The images were manually extracted from larger images in the USGS National Map Urban Area Imagery collection for various urban areas around the country. The pixel resolution of this public domain imagery is 1 foot. All program runs 30 times. The maximum of the mean of the indicators in the table is indicated with ‘*’, and the mean deviation table of the clustering index is shown in Table 3. PDFC has achieved a better index and a smaller deviation. Figures 5(b), 9 showed that PDFC can find the number of image clusters in a completely unsupervised manner and realize clustering segmentation.
Experimental result
In Experiment I, comparing the results of Tables 3, it can be determined that PDFC can better cluster and annotate the surface features than other algorithms. And it also can be seen that the results of several algorithms including PDFC in Experiment II are better than those in Experiment I. This is because the manual annotation of the ‘UCMerced-LandUse’ dataset is closer to the actual landform. In Table 2, the number of PDFC index leading subsets is more than 6 in the randomly selected 10 subsets results, which indicates that the clustering performance of PDFC is superior to other algorithms. In Fig. 6, compared with other algorithms, the mean accuracy of the PDFC approach for this dataset is in a higher range and the boxes are smaller, which indicates that the clustering accuracy of PDFC in data sets is higher, and the robustness is better. Our method can distinguish different features and better fit the edges of features.
In Experiment II, on ‘UCMerced-LandUse’ dataset, the program runs 30 times and gets five indicators. PDFC is superior to other algorithms in both value and mean deviation indicators. Figures 5(b), and 9 intuitively show the results of remote sensing image clustering. The reason why PDFC can achieve a better clustering effect is that distance and neighborhood density are used in the clustering process, and objective function optimization is used to achieve the best clustering result.
Conclusion
We proposed a clustering method for remote sensing image segmentation based on the local densities of data points. This method has a low time complexity, and it achieved unsupervised segmentation of remote sensing images. We verified the clustering effect on the ‘2015 high-resolution remote sensing image of a city in southern China’ dataset [30] and ‘UCMerced-LandUse’ [31] remote sensing dataset. The accuracy and ARI, RI, ARI, and JC obtained showed that the clustering effect of the proposed method was better than that of five other existing algorithms. In Table 4, under general hardware conditions, the average time for PDFC to calculate a 256×256 image is 0.642s. It can better save a lot of human resources and complete the task of remote sensing image labeling.