
Abstract
An efficient visual detection method is explored in this study to address the low accuracy and efficiency of manual detection for irregular gear pitting. The results of gear pitting detection are enhanced by embedding two attention modules into Deeplabv3 + to obtain an improved segmentation model called attention Deeplabv3. The attention mechanism of the proposed model endows the latter with an enhanced ability for feature representation of small and irregular objects and effectively improves the segmentation performance of Deeplabv3. The segmentation ability of attention Deeplabv3+ is verified by comparing its performance with those of other typical segmentation networks using two public datasets, namely, Cityscapes and Voc2012. The proposed model is subsequently applied to segment gear pitting and tooth surfaces simultaneously, and the pitting area ratio is calculated. Experimental results show that attention Deeplabv3 has higher segmentation performance and measurement accuracy compared with the existing classical models under the same computing speed. Thus, the proposed model is suitable for measuring various gear pittings.
Introduction
Semantic segmentation, which aims to segment and associate images with semantic categories into different image regions, is a basic and challenging problem. Semantic images may include environmental (e.g., sky, road, grass) and discrete objects (e.g., cars, bicycles, people). Research on this task has potential applications in autonomous driving, image editing, and robot sensing. Gears are a key component in gear mechanical transmission systems. Because the working conditions of gearboxes are harsh and the structure of these devices is complex, gears and bearings are highly prone to failure [1–4]. Tooth surface pitting is one of the most important faults of gear transmission. In general, the surface of a gear is prone to contact fatigue under long-term loading, which results in early pitting. Early gear pitting is difficult to inspect and gradually expands to severe pitting. If pitting is not discovered in time, gear breakage and irreparable property losses may eventually occur [5]. Gear failures must be detected as early as possible to prevent serious accidents. The gear pitting area ratio is usually used to evaluate the health (life) of gear and is a crucial criterion in the gear contact fatigue tests that determine whether the tested gear will fail. The existing gear detection technology mainly relies on manual observation, such as microscopic inspection, which is inefficient and troublesome. Therefore, developing an accurate and intelligent gear pitting approach to segment gear pitting and tooth surfaces is an important undertaking. Fortunately, this task is well-supported by rapid developments in computer vision and machine learning.
The pitting area ratio is the ratio of the pitting area to the effective tooth area. Therefore, accurate segmentation of effective tooth surfaces and gear pitting is key to the precise calculation of the pitting area ratio. Recent improvements in feature extraction and pattern classification functions have enabled the successful application of convolutional neural networks (CNN) to various fields of image segmentation [6–16]. For example, using CNN, Chen et al. with Google Inc. developed the Deeplabv3+ [17] network, and it introduced a decoder and Xception [18] to improve the network performance and reduce the computational complexity. This model can achieve accurate semantic segmentation and excellent performance. Considering that most gear pittings are irregular, and some pittings are small, traditional segmentation models may not recognize the detailed features of pitting, which can adversely affect the measurement accuracy of pitting areas. In the present work, an attention mechanism is introduced to the network structure to obtain an improved attention Deeplabv3 model that can effectively improve the segmentation ability of Deeplabv3+, especially for small irregular objects. The proposed model is then successfully applied to measure pitting area ratios, and comparative results demonstrate its superiority.
Related work
The basic requirement of
Since deep learning theory was proposed in 2006, the representation learning ability of CNNs has received increased attention, and the development of these approaches has been accompanied by the update of hardware devices. The Full Convolutional Neural Network (FCN [19]) model proposed by the University of California is a representative deep learning approach used for image segmentation and an end-to-end image segmentation method. On the basis of the VGG-16 network structure, FCN uses the convolution layer to replace the last fully connected layers FC6 and FC7 of VGG-16, so it can achieve the pixel-level prediction and output label mapping. FCN is far superior to other traditional segmentation methods in terms of accuracy and speed. Traditional unsupervised segmentation methods (contour-based method and watershed method) often have the problem of low quality when the application scenarios are complex, especially when there are a large number of targets. Moreover, since the global context information is not taken into account, the results obtained by FCN are frequently rough and the details in the image are inaccurate.
SegNet, which was proposed by Vijay et al. [20], is very similar to FCN. SegNet uses unpooling in the decoder to upsample the feature map and maintain the integrity of high-frequency details during segmentation. Additionally, SegNet has a lightweight network with fewer parameters; thus, end-to-end training is easier to perform. Overall, the performance of SegNet in segmentation is better than that of FCN. Hyeon-woo et al. proposed a deconvolution Network (DconvNet [21]) model based on SegNet; in this model, a deep deconvolution network is used to obtain dense pixel-level class probability mapping through continuous unpooling, deconvolution, and normalization operations and generate object segmentation masks. The segmentation performance of DconvNet is higher than that of FCN-8s, but the segmentation accuracy needs to be further improved.
Deep convolutional neural networks (DCNNs) have become the hotspot in the field of computer vision, which have been successfully applied to image segmentation. Many well-known models, such as FSWCRF [22], Deeplab [23], RefineNet [24], DenseASPP [25], U-Net [12], Mask R-CNN [26], and Deeplabv3+ [17], CNN-CRF [27] have been proposed for semantic segmentation. Among these models, the Deeplab network [28], a model dedicated to processing semantic segmentation, was first proposed by Chen et al. and the Google team in 2015. Since it was first introduced, four versions have been developed, including DeeplabV1, DeeplabV2, etc. Indeed, this network is considered one of the most novel and outstanding series of algorithms in the field of semantic segmentation. The Deeplabv3 network designed the pooling of spatial pyramids with an atrous module (ASPP) with dilated convolution. The ASPP module allows feature maps of any size to be extracted by using multi-scale features to obtain the feature vectors of a certain size. Thus, the model can perform feature extraction on images of different scales and features improved extraction accuracy. The encoder component of the Deeplabv3 network uses pre-trained ResNet-50/101 [28] to extract features. The fourth residual block is modified in the model structure by using an expanded convolution method (i.e., three convolutional layers in the module use different expansion rates) and applying a batch normalization layer (i.e., BN layer) to the ASPP module for optimization.
DeepLab V3+ uses its previous version, Deeplabv3, as an encoder, and then adds a decoder component to build a spatial pyramid pooling encoding-decoding structure with holes. Deeplabv3+ first performs feature extraction and then downsamples the input spatial resolution to obtain a lower resolution feature map, which can quickly distinguish categories through training. The features can be expanded to the semantic segmentation map of full-resolution by upsampling. The Deeplabv3+ algorithm shows high accuracy for semantic segmentation tasks. For example, in the traditional deep neural networks including FCN, U-Net, et al. Small objects, and irregular edges may be ignored, that is, the corresponding semantic information may be lost.
The proposed model adds two attention modules to the feature extraction network on the basis of Deeplabv3+ to enhance the original Deeplabv3+ network and improve its segmentation performance. These improvements can enhance the mining ability of the model for more object details and features and the overall segmentation accuracy. In general, the contributions of this article are as follows: Two attention modules are embedded into the original Deeplabv3+ feature extraction network to capture the details of irregular and small objects, thereby enhancing the ability of multi-target segmentation. Attention Deeplabv3 is successfully applied to the simultaneous segmentation of gear pitting and tooth surfaces, and the experimental results show that it could improve the measurement accuracy of pitting area ratios.
Attention Deeplabv3 model
The Deeplabv3+ algorithm is one of the best high-precision algorithms currently available for semantic segmentation, but its insensitivity to the details of small objects limits its wider applications. This paper introduces an attention mechanism, including spatial attention and channel attention components, to this algorithm. We insert the dual attention module into the Xception network framework of Deeplabv3+. The expression ability of the feature map is enhanced by focusing on the channel and spatial domains, more pitting details can be detected, and the accuracy of pitting segmentation is improved. Figure 1 shows the structure of the network obtained after combination with the attention module.
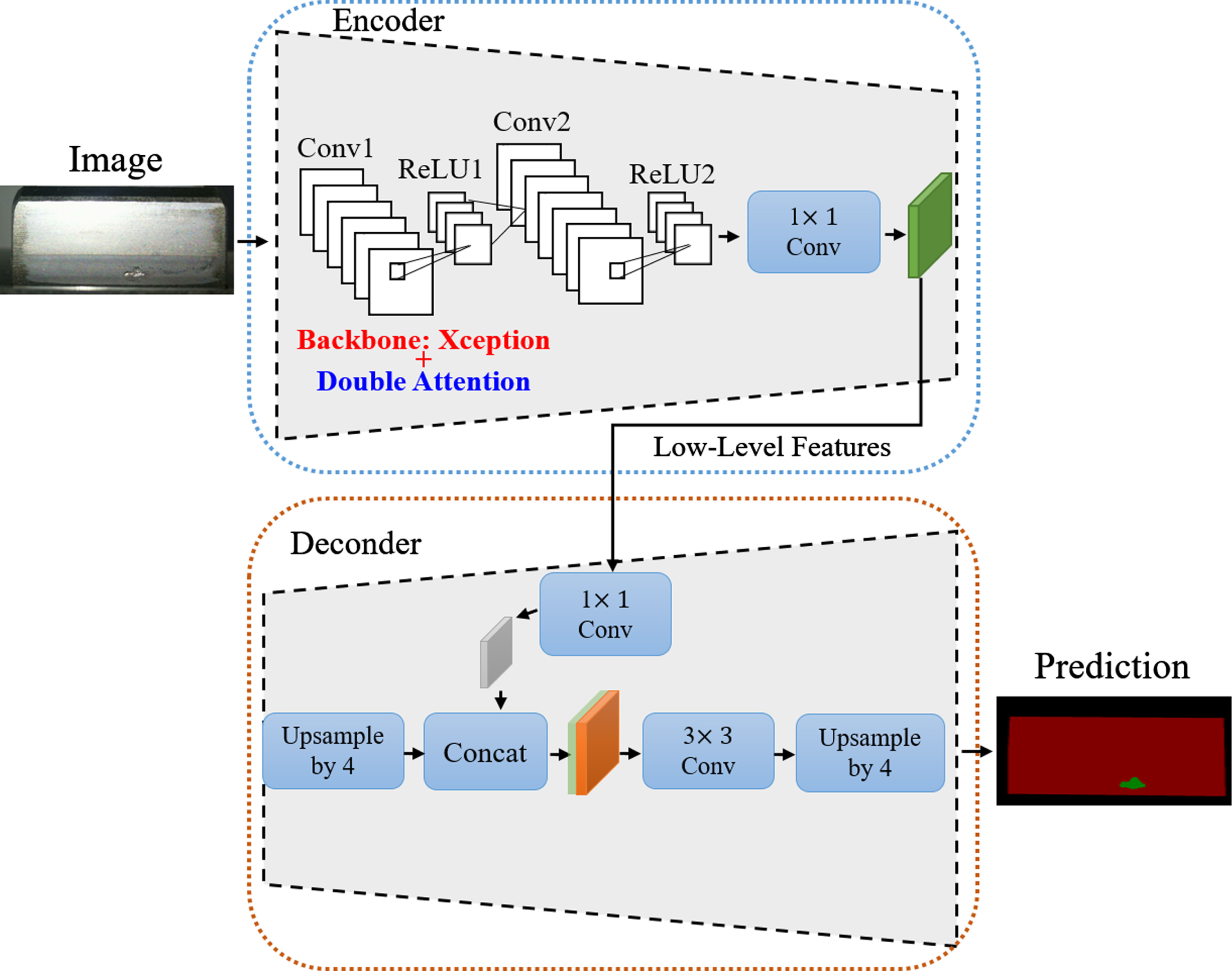
The network of Attention Deeplabv3.
Given an intermediate feature map, we obtain attention weights along the two dimensions of channel and space according to the above calculation process and then multiply them with the original feature map to adaptively adjust the features. In this way, the weight of the interesting region in the feature map becomes larger, so as to improve the feature expression ability of the feature map. Gear pitting and effective tooth surfaces belong to two kinds of objects, so they have different characteristics of shape and texture, as illustrated in Fig. 2.

Labeled features of the gear pitting and effective tooth surface.
The channel attention module (CAM) is first embedded into Deeplabv3+ to increase the relationship of feature maps between the pitting and gear surface features in the channel domain, and the channel feature map with strong correlations is screened out. The spatial attention module (SAM) is then applied to strengthen the pixel location relevance of local features and highlight the location of key features. Therefore, the expressiveness of the feature map is enhanced in both the channel domain and the spatial domain. More local features can be detected, and the accuracy of pitting segmentation may be enhanced.
In the CAM module, global maximum pooling and global average pooling are used to compress the feature map P ∈ FC×H×W in the channel dimension and obtain features
Where γ denotes the sigmoid activation function, M represents an MLP with two layers, W1 and W2 are the weight parameters of two layers, and AP and MP signify the average pooling operation and maximum pooling operation, respectively. B
C
(P) can be calculated by multiplying the input feature map P element by element to obtain a new feature map P′ ∈ FC×H×W. The sigmoid function transforms the continuous input into the probability value in the interval of (0,1), and it is defined as:
Unlike CAM, SAM mainly focuses on the position information of the target in the image.
SAM also uses global average pooling and maximum pooling of the feature map P’ along the channel direction to obtain the channel background feature maps
Where C7 ×7 denotes the 7×7 convolution operation and; represents the channel concatenation operation. The input feature map can be obtained by multiplying P’ and B
S
(P) element by element, which contains the key features of the channel domain and the spatial domain. The above element-wise multiplication calculation procedure can be formulated as follows:
From the perspective of space, channel attention represents the global perspective while spatial attention represents the local perspective. The attention maps generated by sequential arrangement are more effective than those generated by parallel arrangement. In addition, the channel attention put in front has slightly better performance than the spatial attention in front.
The cross-entropy loss (Ce loss) can express the difference between the true probability distribution and the predicted probability distribution. The smaller the value of cross-entropy is, the better the prediction effect of the model is. The formula can be expressed as:
Multiclass strategies
The network model in this paper is implemented in Python [29] by using the Tensorflow deep learning framework tool. Tensorflow is developed and continuously supported by the Google team and promises to be a common language for machine learning researchers and developers. Compared with models of other frameworks, Tensorflow has the advantages of higher flexibility, higher computational efficiency, strong compatibility, and the ability to realize distributed computing. Tensorflow expresses the programming system of an operation by calculating each node (op) on the graph and relies on the session mechanism (session) to establish the running model. Moreover, Tensorflow is equipped with a powerful visualization tool, TensorBoard, which can clearly display changes in tensors during operation, thereby facilitating parameter tuning activities.
The data format must be standardized as TFrecord when Tensorflow is used. TFrecord allows the conversion of any data into a format supported by Tensorflow. This function has two advantages. First, it can store all of the information of a sample in a unified manner and use internal binary data encoding to optimize memory. Second, multi-threaded operations of file queues are utilized to facilitate the rapid movement, reading, and storage of data in Tensorflow, which is especially important for big data streams. We apply the model to the gear pitting dataset for training.
The attention Deeplabv3 is trained by the mini-batch stochastic gradient descent (SGD) algorithm with batch size 2, momentum 0.9, and weight decay 0.001. The initial learning rate is set to 1e-3. The main hyper-parameters for training are listed in Table 2. Meanwhile, the computing platform and software used in this work are Windows10 + CUDA8.0 + CUDNN7.0.5 + Tensorflow + GeForce RTX 1080 Ti. The specific software and hardware environment configuration of this experiment is shown in Table 1.
Hyperparameter setting
Hyperparameter setting
Experimental hardware and software environment configuration
Through a large number of parameter tuning experiments, the optimized hyperparameters are selected to achieve better segmentation performance. The hyperparameter settings required for final model training are shown in Table 2.
The attention Deeplabv3 model is based on the Deeplabv3 + algorithm developed by Liang-Chieh Chen and the Google team. In this work, we evaluate the performance of the segmentation model using the following metrics.
Mean intersection and union ratio (MIOU) is the main performance indicator for current image semantic segmentation algorithms. First, we assume that i represents the true value, j represents the predicted value, p ij denotes the number of pixels that originally belonged to class i but were predicted to be class j, and k + 1 denotes the number of categories (including empty classes). In other words, p ii is the real quantity, and p ij and p ji respectively refer to false negatives and false positives.
MIOU refers to the average cross-to-match ratio used to calculate the ratio of the intersection and union of two sets of ground truth and predicted segmentation. In general, calculations are performed based on classes. The IOU of each class is calculated, accumulated, and then averaged. The specific calculation formula is as follows:
PA refers to the ratio of correctly marked pixels relative to the total number of pixels. The formula is as follows:
Mean Pixel Accuracy (MPA) refers to the average pixel accuracy, which is an improved measurement accuracy of PA. It is used to express the proportion of correctly classified pixels in each class and then calculate the average of all classes. The formula is as follows:
The relative error rate of pitting segmentation (Re) is applied in the gear pitting dataset. First, we calculate the numbers of pixels of the tooth surface and gear pitting. The pitting rate of the gear (AR) is the ratio of these two values.
The predicted pitting rate AR
p
and actual pitting rate AR
a
can be calculated through the above formula from the pitting area calculated after segmentation and the actual pitting area. Then, Re can be calculated through these two equations
Validation experiments are performed on two public datasets, namely, Cityscapes [30] and Voc2012 [31], to verify the generalizability of the model in this paper. The Voc2012 dataset is divided into 20 categories with 21 background categories; it contains 10582 training images, 1449 verification images, and 1456 test images. Cityscape is a large-scale dataset that contains high-quality pixel-level annotations of 5000 images collected from streets in 50 different cities. The training set, validation set, and test set contain 2975, 500, and 1525 images, respectively, as shown in Table 3.
Public datasets used in this work
Public datasets used in this work
Deeplabv3+ and attention Deeplabv3+ are trained in Cityscapes and Voc2012 under the same hardware and software conditions with the same parameters, and the performance of the improved model is verified by image segmentation tests on two datasets. Given the nature of the public datasets, we only train FCN on Voc2012. The results of the semantic image segmentation test and comparison based on Voc2012 are shown in Fig. 4.

Segmentation results based on Voc2012.
While the outline of objects determined by Deeplabv3+ can be divided fairly clearly, some details are not sufficiently delineated (e.g., [2, 3] of the division of a man on a horse). In image [2, 3] ([a, b] denotes a row, b column), part of the leg of the horse is blocked by the rail; Deeplabv3+ ignores these details directly, but attention Deeplabv3 is able to segment the part of the horse leg that can be seen in the image. FCN generally performs poorer than Deeplab. The improved algorithm produces clearer and smoother image segmentation, thus indicating that the addition of the attention mechanism causes the segmentation process to pay close attention to the location of abrupt changes in pixel value.
The results of the semantic image segmentation test and comparison based on Cityscapes are shown in Fig. 5.

Segmentation results based on Cityscapes.
The visual results of the test above reveal that the improved algorithm has relatively good segmentation accuracy. Specifically, its segmentation of pedestrians (red), vehicles (blue), street lights (white), and signs (yellow) is relatively clear, and the identification of some objects in detail is more accurate than that obtained from the original algorithm. Objective metrics are used to evaluate the results of segmentation, and the results are shown in Table 4. Here, running time means the time to process a batch of images (batch size = 2 images) in the training phase.
The test results of the two algorithms
The designed attention module makes the model pay more attention to key areas during the stage of feature extraction, thus the target area can be effectively and quickly processed, so as to reduce the calculated amount. It then follows that the running time of the proposed model is less than that of DeeplabV3+.
In the VOC2012 dataset, the MIOU calculated by the improved model through the test set is approximately 1.0% higher than that calculated by the original algorithm; moreover, the pixel accuracy calculated by the former is approximately 1.1% higher than that of the latter.
In terms of running time, little difference between the two models is observed, and the running time does not decrease as the number of network layers increases. Moreover, in the Cityscapes dataset, the MIOU and PA of attention Deeplabv3 increases by approximately 1.3% and 1.1%, respectively, compared with those of Deeplabv3+. In addition, the running time is not reduced, and the comprehensive performance of the model reaches optimal levels.
The visual convergence curves of the improved and original models obtained from the two datasets are shown in Fig. 6. The abscissa represents the number of iterations, the ordinate represents the loss value, and the initial learning rate is a = 0.001.

The comparison of Ce loss curves obtained by two types of Deeplabv3 for two datasets: (a) Cityscapes dataset, (b) VOC2012 dataset.
Gear pitting dataset
After initial investigation and research, the quality of the pitting images in the public gear dataset is determined to be uneven, and most of the pitting images do not completely include the tooth surface. Thus, an effective dataset cannot be formed. Instead, we use two types of gear contact fatigue testing machines shown in Fig. 7 to obtain gear pitting images according to the gear fatigue life test in our laboratory. Gear pitting images are acquired by a CCD camera.

Two gear contact fatigue test rigs for obtaining gear pitting images: (a) FZG gear contact fatigue test rig and (b) gear contact fatigue test rig manufactured by the gear design center of Newcastle University.
Given limitations in the experimental environment, the gear pitting images collected by the CCD camera (MER-131-210U3C, 210 fps, 1280 (H)×1024 (v)) and the lens (WL1425-5MP, 5.0 megapixel, the focal length of 25 mm, its distortion is less than 0.2%) may contain multiple gears, as well as background interference information, such as the gearbox. Therefore, the acquired images must be preprocessed to reduce the interference information. In this study, image preprocessing operations include image enhancement and tooth surface tilt correction. Figure 8 shows images of gear pitting after preprocessing. When gear fatigue occurs, the pitting area usually accounts for 0.4% of the effective gear working surface. In some cases, gear pitting may be accompanied by other failures, such as wear and scratches.

Images of gear pitting after preprocessing.
Because gear contact fatigue testing is expensive and time-consuming, the number of gear pitting samples is limited. Increasing the number of images in the gear pitting dataset is necessary to reduce overfitting and improve segmentation accuracy. Generative Adversarial Network (GAN) [32] is a method that could be used to solve the small-sample problem and effectively augment the gear pitting dataset. GAN includes a generative network G and a discriminant network D. G is used to create a target image via random noise, while D is used to determine whether the image is real or not. With the game process (Nash equilibrium in game theory), the samples generated by G are getting closer to actual samples, and the discriminative ability of D is becoming stronger.
Several GANs, such as original GAN, CycleGAN [33], and deep convolution GAN (DCGAN [34]), can be used to augment the gear pitting samples; some of the pitting images acquired by these networks are shown in Fig. 9 (a)– (c). The quality of the pitting images generated by DCGAN is significantly higher than that of images generated by GAN and CycleGAN; moreover, DCGAN has faster convergence. Thus, DCGAN is applied to augment our gear pitting sample images to construct a gear pitting dataset that includes actual and pre-amplified pitting images. The Deep Convolutional Generative Adversarial Networks (DCGAN) was proposed on the basis of GAN. The discriminator and generator of DCGAN use CNN to replace the multilayer perceptron in GAN. At the same time, in order to make the whole network differentiable, the pooling layer in CNN is removed, and the full connection layer in GAN is replaced by the global pooling layer for reducing the computational load. Therefore, DCGAN is utilized for augmenting the gear pitting sample images. Batch standardization is used in both generator and discriminator of DCGAN. Moreover, the ReLU function is used as the activation function of the generator network except for the last layer where the Tanh function is used, while the Leaky-ReLU function is used as the activation function in the discriminant network.

Pitting sample amplification by several GANs: (a) Pitting images generated by GAN, (b) pitting images generated by CycleGAN, and (c) pitting images generated by DCGAN.
Finally, we randomly select 1200 gear pitting images produced by DCGANs and 200 original gear pitting images to form a dataset consisting of 1400 gear pitting images. The collected images are allocated to a training set, validation set, and test set at a ratio of 6:2:2.
Figure 6 shows the segmentation results of Deeplabv3+ and Attention Deeplabv3. Due to the addition of the Attention mechanism, the Attention Deeplab network is more sensitive to the characteristics of pitting, and more sensitive to the positive sample characteristics of Attention pitting. As can be seen from Fig. 10’ s [1,1, 1,1] and [1,2, 1,2], the segmentation results of Attention Deeplab are closer to the truth value of the pitting image, and all small parts of pitting extension can be segmented. As can be seen from Fig. 10’ s [3,1, 3,1] and [3,2, 3,2], Attention Deeplab can segment the white scratches in the early stage of pitting development, which is completely different from those in the later stage, which proves that our proposed method has good generalization ability and robustness, and can accurately identify all areas of pitting.

Segmentation results of Deeplabv3+ and attention Deeplabv3: (a) image, (b) Deeplabv3+, (c) Attention Deeplabv3.
In addition, we have also carried out corresponding verification experiments on the classic FCN, U-Net, Refinenet, Mask R-CNN segmentation networks, but the input data format and labels of these networks are different from those of Deeplab series networks, so they are separately displayed. As shown in Fig. 11 below, FCN can roughly segment the positions of pitting and tooth surface, but cannot segment the edge contour information of pitting and tooth surface, and thus cannot achieve good accuracy, especially for the segmentation of effective tooth surface. However, as the originator of the segmented network, FCN has laid a foundation for the subsequent research and development of the segmented network models. Figure 12 shows the results of multiple classifications of the U-Net model, and the results of tooth surface and pitting can be obtained respectively. From the effective tooth surface segmentation results, it can be seen that U-Net segmentation performance is better than FCN, but from the pitting segmentation results, it is slightly worse than FCN segmentation results, but overall, U-Net segmentation performance for pitting and the tooth surface is better than FCN.

Segmentation results of FCN.

Segmentation results of U-Net.
Figure 13 represents the segmentation results of RefineNet. It can be seen from the figure that the segmentation results of effective tooth surface and pitting are both good and bad. Figure 14 shows the segmentation results of Mask R-CNN. It can be seen from the segmentation results that Mask R-CNN can segment the irregular contour of pitting in detail, but for small pitting, it cannot be detected, nor can it be segmenting.

RefineNet segmentation results.

Mask R-CNN segmentation results.
To quantitatively compare the performance of various models, we used the evaluation indexes mentioned above to assess the test results, and the obtained index values are listed in Table 5. It can be seen that the MIOU of attention Deeplabv3 can reach 77.90%, which is about 2%, 3.47%, 6%, 6.24%, 11% higher than those of Deeplabv3+, Mask R-CNN, U-Net, RefineNet, and FCN respectively. Compared with the traditional Deeplabv3+, PA and MPA of the proposed attention Deeplabv3 respectively increase by about 2.5% and 2%. From this table, we can also note that the Re of attention Deeplabv3 is the lowest, which is just 5.97%. Therefore, the segmentation accuracy of attention Deeplabv3 is higher than that of other semantic segmentation models. Although the running time of attention Deeplabv3 is not the least, its computational efficiency is high enough for the gear pitting measurement.
Comparative test results based on different algorithms
The computational complexity can be reflected from two aspects. The first aspect is time complexity, which is evaluated by the running time in this work. The second one is spatial complexity, which is determined by the number of parameters of the model. Both the time and spatial complexities are illustrated in Table 5. From this table, we can see that the running time of attention deeplabv3 is less than that of DeeplabV3+ although the model size of attention deeplabv3 is larger than that of DeeplabV3+., This is mainly because that the designed attention module can effectively improve the computational efficiency, as previously mentioned.
From Fig. 3, we can know that both the channel attention module and spatial attention module are made up of neural networks, thus the two modules increase the depth of the network. To investigate the convergence performance of the proposed attention Deeplabv3, the loss curves of attention Deeplabv3 and Deeplabv3+ are illustrated in Fig. 15, where X coordinate represents the number of iterations, and Y coordinate represents the loss value. In the experiment, the initial learning rate is set to 10–4. As can be seen from Fig. 15, the proposed Deeplabv3 has a similar convergence performance with the original model. As attention Deeplabv3 has a more complex network structure and more training parameters than Deeplabv3, its convergence is not improved.
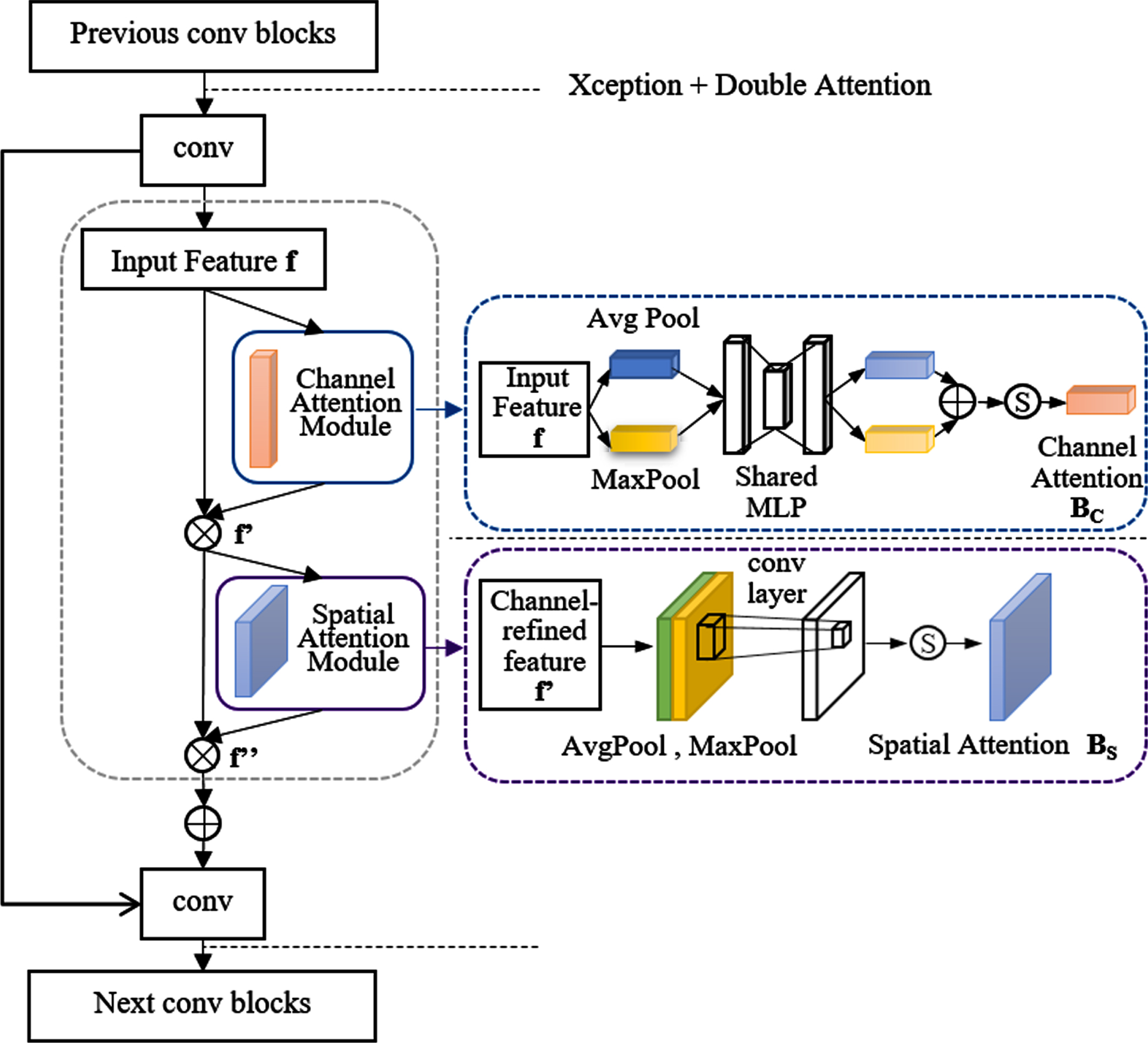
Two attention modules.

Convergence curve of Ce loss for the gear dataset.
Based on Deeplabv3+, the paper proposes an enhanced segmentation network called attention Deeplabv3 by introducing the channel attention module and spatial attention module, which can effectively improve the sensitivity to object details and the segmentation performance. Especially, the proposed attention Deeplabv3 is very suitable for the segmentation of irregular and small targets. Comparative experiments have been performed on public datasets Cityscapes and VOC2012 to verify the superiority of attention Deeplabv3. Next, the proposed model is applied to segment pitting and tooth surface simultaneously via a gear pitting imageset, and then the pitting area ratio of gear is calculated according to the segmentation results. The experimental results show that attention Deeplabv3 has a higher measurement accuracy of gear pitting than the existing deep learning-based methods, such as Deeplabv3+, FCN, U-Net, RefineNet, and Mask R-CNN. Consequently, the proposed method has important application value in the visual detection of gear pitting.
The proposed method addresses to improve the segmentation accuracy, whereas its real-time performance needs to be enhanced, so as to better satisfy the requirement of practical engineering. In the future, we will develop a method with both real-time and segmentation accuracy for the gear pitting detection. Moreover, it is worth reseaching the three-dimensional measurement of gear pitting.
Footnotes
Acknowledgment
The work described in this paper was supported by the National Key R&D Program of China (no. 2018YFB2001300), National Natural Science Foundation of China (nos. 62033001 and 52175075), and a Project supported by the graduate scientific research and innovation foundation of Chongqing, China (no. CYB21010)