
Abstract
Word sense disambiguation (WSD) refers to determining the right meaning of a vague word using its context. The WSD intermediately consolidates the performance of final tasks to achieve high accuracy. Mainly, a WSD solution improves the accuracy of text summarisation, information retrieval, and machine translation. This study addresses the WSD by assigning a set of senses to a given text, where the maximum semantic relatedness is obtained. This is achieved by proposing a swarm intelligence method, called firefly algorithm (FA) to find the best possible set of senses. Because of the FA is based on a population of solutions, it explores the problem space more than exploiting it. Hence, we hybridise the FA with a one-point search algorithm to improve its exploitation capacity. Practically, this hybridisation aims to maximise the semantic relatedness of an eligible set of senses. In this study, the semantic relatedness is measured by proposing a glosses-overlapping method enriched by the notion of information content. To evaluate the proposed method, we have conducted intensive experiments with comparisons to the related works based on benchmark datasets. The obtained results showed that our method is comparable if not superior to the related works. Thus, the proposed method can be considered as an efficient solver for the WSD task.
Introduction
In natural languages, words have multiple interpretations based on their context. Natural language processing (NLP) is a sub-field of artificial intelligence, which provides the task of word sense disambiguation (WSD). WSD concerns the issue of identifying the right sense of an ambiguous word computationally using the available information [3]. For a given text, WSD asks to determine a suitable sense for each non-stopping word based on its context. Thus, it is a computational problem that requires to search the best possible set of senses that have strong semantic relatedness. This semantic value is calculated based on hierarchical relations provided by a lexical database.
In specific, the relations among the senses (or concepts) are stored by a lexical database, called the WordNet [19]. It contains information about verbs, nouns, adverbs and adjectives. WordNet organizes related concepts into hierarchies, which are represented by trees, where the root is a very general concept and the leaves are very specific. Thus, these hierarchies help to measure the similarity between two concepts by identifying the path length that connect them [26]. However, such measure lacks to the knowledge of how frequent these concepts appear in a specific corpora. Thus, more information from a corpora, like the frequency of two concepts, and their nearest root can help to measure the semantic similarity [29]. Also, WordNet provides the gloss of each concept, and thus, methods based on gloss overlap notion can measure the relatedness easily. Particularly, Lesk algorithm determines the relatedness between two concepts by counting the common words in the definitions of these concepts [16]. An extension to Lesk algorithm suggests including the glosses of concepts that have WordNet-based relations with the given concepts to be measured [7]. These semantic relatedness methods are vital to achieve the WSD, where the semantic coherent can be identified.
The WSD plays an intermediate role in various NLP tasks, like the automatic text summarization [25], machine translation [27], and information retrieval [14]. In these applications, the WSD performs the task of identifying the correct sense for each word to obtain accurate results for a final task (e.g. machine translation). For instance, a search engine with a semantic disambiguation model would retrieve highly relative results to the user query. Similarly, a machine translator would assign the suitable meaning when the vague of the words is dropped by a WSD solver. Hence, it is necessary to provide accurate WSD system to get the desired impact on the final tasks. This directs the research flow to develop methods that maximise the semantic coherent of a given text. Specifically, several meta-heuristic were proposed to search for the best set of senses that maximises relatedness of a given text [2, 38].
Recently, swarm intelligence based methods received great deal of attention for various NLP tasks [15, 24]. Firefly algorithm (FA) is a nature-inspired algorithm that mimics the flashing lights of the fireflies [35]. FA belongs to the swarm-based algorithms, which implies that a set of agents move toward a goal defined by an objective function. In swarm algorithms, there is a communication tactic to control the movement of the swarm toward the goal. In FA, fireflies communicate through the brightness of their lights. Because the light intensity is inversely proportional to the distance, fireflies only can communicate within a limited distance. In analogue to the WSD, the flashing lights of a firefly represent the semantic relatedness of the processed text (the objective function). Hence, brighter fireflies attract others to move toward them, and thus their lights become brighter. Recently, FA has found successful applications in various fields [9, 39]. Interested readers may refer to the book of Dey for more of the recent applications of the FA and its variants [12].
The efficiency of the FA across various fields has motivated us to investigate its effectiveness for the WSD task. In specific, the FA has significantly improved the accuracy of document classification [15]. This is attributed to the unique feature of the FA, which is the automatic subdivision. This feature enables the population of the FA to subdivide into subsets automatically [35]. Thus, each subset of the population can explore each mode or local optimum. From these modes, the FA can determine the best global solution. This advantage over other algorithms has motivated us to investigate the FA to determine the best set of senses that maximize the relatedness of a given text to achieve the WSD.
This study addresses the WSD by maximising the semantic relatedness of a given text through the FA. To achieve this task, the proposed method invokes a lexical database to provide the number of senses for each word in the given text. Then, we propose an improved semantic relatedness method. This method serves as a fitness function for the proposed FA. FA has the ability to explore the problem space effectively as its searching procedure is based on multiple solutions, which increase the chance of exploring a wide area in the state space. Nevertheless, the FA is less efficient in exploiting the problem space when it is compared to solo-solution-based algorithms [6, 8], and thus, the FA may fall in local optima easily. To overcome this issue, we hybridise the FA with a local search algorithm called the late acceptance hill climbing (LAHC). The LAHC exploits the neighbourhood of a given solution effectively; hence, it aids the FA to balance between exploration and exploitation.
The proposed hybrid FA (HFA) evaluates the solutions during the search process based on a semantic relatedness method is known as the extended Lesk (e-Lesk) algorithm [7]. The e-Lesk algorithm is based on the concept of gloss overlapping of the given senses. Thus, e-Lesk can measure the relatedness for a pair of senses even if their POS are different. However, the gloss overlapping does not consider the hierarchical relations for the senses that belong to the same POS. Thus, we incorporate a semantic similarity method based on the notion of information content (IC) [30]. This method aims to improve the e-Lesk algorithm for pairs of the same POS, i.e., verbs and nouns only. The most important feature is the incorporation of the IC to evaluate the semantic similarity of two concepts. That is the algorithm takes into account the hierarchical relations provided by the WordNet, instead of relying only on the glosses overlapping. This allows the semantic measure to know about the distance between the given two concepts, through their Least Common Subsumer (LCS). Overall, our contributions are as follows: Providing an effective semantic relatedness method to serve as a fitness function for the searching algorithm. Proposing an efficient optimization method named hybrid firefly algorithm (HFA) for addressing the WSD.
To prove the efficiency of the proposed methods, intensive experiments have been conducted. Also, we provide comparisons to the related works based on benchmark datasets.
This paper is organized into six sections, including the current one, which gave the introduction of this work. The second section reviews the related works. The third section explains the representation of the WSD as an optimisation problem. The fourth section describes the method proposed in this study, which consists of three subsections. These present the formulation of the FA, hybrid FA, and semantic measures used in this study. The fifth section is dedicated to analysing the components of the proposed method and presenting comparisons against the related works. Finally, section six draws the conclusion of this research.
Literature review
In WSD, the main clue to identify the right sense of an ambiguous word is its context in the given text. In most WSD approaches, the length of contexts has a strong impact on the task of the WSD, where a short context may be inadequate to identify the correct sense. In contrast, a very long context may add noise to the features used in the disambiguation process [31]. Thus, some studies triggered to investigate the impact of the context length on the WSD approaches [2, 33]. Also, filtering the context from the noisy words has been investigated using a syntactic parser based on a meta-heuristic algorithm [1].
Meta-heuristic algorithms are used for the WSD task when a bag of words is required to undergo the disambiguation process. The first investigation of such algorithms was proposed by Cowie et al. in 1992 [10]. This was followed by several experimental studies of the meta-heuristic algorithms, especially using the genetic algorithm [2, 38]. Due to the difficulty of the WSD task, the aforementioned studies either were dedicated to a single part-of-speech (POS) [38] or limited to a specific type of datasets [2]. Recently, other algorithms of the same class were able to scale for multiple datasets and POS [33, 36]. In [33], a particle swarm optimisation was used to maximise the semantic similarity of a given text. Also, a combinatorial PSO is proposed for WSD by Ajeena and Chinmayan [4]. The authors in [4] chose some parts from famous novels to test their method. However, their method was not tested using a WSD benchmark dataset. While in the study of [36], a bat algorithm was employed to find the best set of senses of the processed text. These studies show a successful searching process when a local search algorithm is invoked. Also, the type of local search has a strong impact on the search behaviour of the algorithm. For instance, using the simulated annealing in [33] revealed improved results, especially for the nouns among other POS. The authors attributed the effectiveness of their algorithm to the acceptance criterion of the simulated annealing (SA), which accepts non-improving solutions to take place for the purpose of avoiding local optima.
However, the SA in [33] requires prolonged searching process to allow the system accepting non-improving solutions at higher temperatures. On the other hand, allowing only improved solutions to take place in [36] can lead the system to fall in local optima. In [36], the authors employed hill climbing algorithm (HC) as a local search, which prevents non-improving solutions to take place as the a new point of the search process. In addition, neglecting the exploitation of the state space would delay convergence of the searching algorithm [38]. Also, the WSD system in [38] is limited to nouns only. Thus, the study in [2] attempted to provide a WSD system for all parts of speech. Nevertheless, the semantic measure in [2] is limited to only glosses overlapping of the given concepts without considering their synsets.
In this paper, we present a hybrid firefly algorithm that aims to attain a balance between exploration and exploitation. The attractiveness of the fireflies allows the algorithm to explore wide area of the search space. However, exploiting the search space is obtained by incorporating a local search with an acceptance criterion for non-improving solutions. The solutions obtained by the HFA is evaluated based on gloss overlapping method and information content notion. The proposed HFA considers all parts of speech.
Problem description
For a given sentence, WSD seeks a suitable sense for each non-stopping word based on its context. WSD is a computational problem that requires searching the possible set of senses of the given text. For a given text, there are numerous combinations of the senses (see Fig. 1), and thus it is exhaustive to enumerate all of them.

An example of the sense combinations for the words Bank and Note.
Hence, employing an intelligent searching technique would alleviate the problem of tracking all combinations by emphasising eligible ones only. To illustrate the combinations of senses, assuming two words, “bank” and “note” appeared in one context. Considering only the first six senses (obtained from the WordNet) of each word, then the possible combinations are shown in Fig. 1.
In Fig. 1, each sense from the word “bank” is paired with all senses of the word “note”. Thus, there are 36 tuples of these senses for both words. The L in Fig. 1 refers to a function of measuring the relatedness between every two senses. Each word is concatenated with its POS and the sense number, where the "#" symbol separates them. For instance, bank#n#1 refers to the first sense of the word bank when its POS is a noun. This form is used in the WordNet similarity Java API called WS4J. This API is a re-implementation of the Perl WordNet-Similarity library [22]. Hence, the library measures the relatedness between two senses rather than two words.
Figure 1 shows six senses only for the words “bank” and “note”, yet it should be noted that WordNet provides more than this number of senses for these words. Thus, considering all the senses of the given words will make the task of searching for the best set of senses more complicated. Moreover, the example in Fig. 1 gives only two words which makes it easy to iterate through all the tuples. Nevertheless, the all-word WSD task asks to find suitable senses for all non-stopping words in the given text. Hence, the WSD becomes a combinatorial problem, and thus an approximate method can serve to handle it.
In this study, the proposed method represent the problem numerically, as it searches for the best set of numbers (senses Ids). This set is evaluated based on a well-known relatedness algorithm called extended Lesk (eLesk) [7]. Also, a similarity method is combined with eLesk to refine the obtained relatedness. The refinement of the similarity method is due to the notion of information content (IC) [29]. The IC measures how frequent a sense appears in relation to other words’ senses in a specific corpus. While, a relatedness method only measures the overlap between two senses. Hence, combining relatedness and similarity methods can provide more information. In this study, the set of senses (which are provided by the proposed searching algorithm) are evaluated using the combined methods as follows:
A numerical example of the WSD
In Table 1, each number represents the Id of a concept (or sense) of its corresponding word, and a row of these numbers is a solution. For instance, solution 1 implies that concept 3 has been assigned to word 1, concept 5 assigned to word 2, and so on. Then, the semantic relatedness among these concepts is reported in the last column, the higher the better. In Table 1, we have gave four example solutions, as our proposed method process multiple solutions iteratively. These solutions evolve based on the updating rules of the proposed HFA.
For quick reference, we provide a list of notations as shown in Table 2.
List of notations and acronyms used in this paper
This study aims to maximise the relatedness of a given text by exploring the potential senses for each word. To achieve this aim, the designed method is based on stochastic searching algorithms, which are capable of providing good-quality solutions in a reasonable amount of time. These invoke a semantic measurement to evaluate the obtained solutions. These algorithms include a swarm intelligence-based method called Firefly Algorithm (FA). This kind of algorithms is effective in exploring the problem space. However, they are less competitive in exploiting the problem space when it is compared to the meta-heuristic algorithms that use a single solution. Hence, this study attempts to make a balance between exploration and exploitation through hybridising the FA with the Late Acceptance Hill Climbing (LAHC) algorithm. The work-flow of this hybridisation is presented in Fig. 2.

The work-flow of the proposed method.
In Fig. 2, the first step is to read the data, which is a text composed of paragraphs. Each paragraph is consisted of a set of sentences. These sentences are tokenized to words, where each word lies on a single line of a file. Due to the special structure of this dataset, a Java API called JSemCor is used for interfacing with dataset files. After reading the data, it is required to retrieve the number of senses for each word using the WordNet. To achieve this, we used another Java API known as JWI. The remaining steps are the main searching algorithm which includes the semantic evaluation. These are described in details in the subsequent sections.
Inspired by the flashing light of the fireflies, an objective function can be optimised by moving toward the brightest firefly in the swarm [35].
The core steps of the FA are inspired from the three rules of firefly swarms. First, fireflies are attracted to each other regardless their sex because they are unisex. Second, the attractiveness is proportional to their brightness which implies, a firefly of lower flashing light will move towards the brighter one. The brightness and attractiveness of two fireflies decrease when their distance increases. A firefly moves randomly when no one is brighter than it. Third, the landscape of an optimisation function has impact on the brightness of a firefly. Considering the optimisation problem in this study, the brightness will be proportional to the value of the objective function. These three rules can be translated to algorithmic steps, as shown in Algorithm 1.

In the FA, the movement of an agent is based on the attractiveness of others in the swarm. Typically, a firefly’s attractiveness is always determined by its brightness or light intensity, which in turn is mapped to the given fitness function. At a specific position x, a firefly’s brightness I is proportional to the objective function, i.e., I (x) ∝ f (x). Nevertheless, a firefly’s attractiveness β is relative, and thus, other fireflies should assess it. Hence, it varies with respect to the distance r
ij
between two fireflies j and i. On the other hand, light intensity is changing inversely in relation to the distance from its source. Also, media absorb fireflies’ light, which leads to variation in the attractiveness with respect to the degree of absorption. Thus, the attractiveness is calculated by considering the light absorption coefficient γ of a given medium and current distance r, as shown in Equation 2.
A firefly i changes its position affected by another more attractive (brighter) firefly j, which can be represented as follows:
The proposed method in this study employs the FA for its exploration’s capacity. The FA is based on the swarm intelligence technique, which suggests deploying a set of agents to explore the problem space effectively. In FA, this can be seen by the attractiveness feature where all fireflies move toward the brightest one. This movement will form the swarm, which moves toward a potential best area in the problem space. However, the FA and other population-based meta-heuristics are less competitive in exploiting the problem space when they are compared to the local search algorithms. These are based on a single solution, and thus a local search algorithm intensifies the neighbourhood of a given solution. This is done by moving the solution to an eligible neighbouring point. Thereafter, the same movement will be performed for the new point to move toward a better one. This movement will be repeated until a predefined stopping criterion is met. The aforementioned process is the general scheme of local search algorithms.
However, the main feature that can distinguish a local search algorithm from others is how the algorithm accepts a new movement. Intuitively, a new point will be accepted since its quality better than the previous one. However, relying only on improving solutions may end up with a low-quality local optimum. A current solution is identified as a local optimum when its neighbouring solutions have lower quality than it [32], and thus the algorithm sticks in this point. Formally, a solution x is a local optimum when it satisfied the condition in Equation 5.
To avoid local optima, the LAHC allows the searching process to accommodate non-improving solutions, which permits the movement to a new point of the search space. In LAHC, accepting a new solution depends on the history of the searching procedure. In specific, LAHC accepts a new solution if it is better or equal to a solution of previous iterations. In other words, a new move will take place even if it does not improve the current one, but it should be at least as good as it was in a number of iterations ago.
To achieve this, the LAHC uses a list to record the cost of previous solutions. The cost of a new solution is compared to the last element of the list, an then it will be accepted it is better than the compared one. After that, the cost of the newly accepted solution is inserted at the beginning of the list, and the last one is removed. In case of rejecting the new solution, the cost of the current solution is instead inserted. These steps are summarized in Algorithm 2.

Memorising previous information in a list resembles the mechanism of the tabu list in Tabu Search (TS) [13]. However, the list in LAHC is completely different from the one in TS. First, the list of LAHC holds the values of a fitness function which is the overall similarity of the given text. While, the tabu list contains the previous movements to be forbidden in the next cycles. Second, TS compares the candidates of the current solution to the whole list, whilst LAHC compares with only one value from the list. Let’s assume the LAHC list Fa = {f0, f1, f2, …, fLfa-1}, and v is a pointer to the fitness to be compared with the new solution which is calculated as follows:
Using a pointer to the target fitness in the LAHC list makes the processing time independent from the length of the list. Hence, a long list can be used to memorise more about the search history without delaying the searching process. Obviously, the Lfa is the only parameter in the LAHC, which makes it easy to set.
Practically, the proposed HFA tackles the WSD problem based on the numerical presentation of the given text, as shown in Section 3. In the FA, a solution (firefly) that holds the higher semantic coherent (attractiveness) is identified as the best solution. The semantic relatedness is calculated from the given solution, where it is composed of a set of senses’ ids that corresponds to a given text (see Fig. 1). Then, all other solutions will move toward the best solution to enhance their similarity. After this movement, the best solution so far is updated if any solution acquired more relatedness than the best one (one firefly became brighter than best one). This process works on exploring various sets of senses of the processed text. However, to make the search focuses on an eligible set of senses, the HFA will invoke the LAHC to intensify the search around a given solution. The LAHC is called within a predefined probability called local search rate (lr) as shown in Algorithm 3. Though only one solution (the best one) from the FA will be processed by the LAHC, other solutions will get updated when they move toward the best solution. LAHC searches the neighbourhood of a given solution using a predefined neighbourhood structure (NS). In this study, the NS swaps two random senses of the given solution. Then the similarity of the new set of senses is calculated. LAHC repeats these steps, including the list of costs explained above, till a predefined number of cycles.

The parameters of the HFA are set experimentally, where the Swarm_size is 40, max_number_of_iterations is 100, α is 20%, and γ is set to 1 based on the original FA study [35]. The local search parameters which are lr, L fa , and max_cycles are set to 15%, 17000 and 30000, respectively. The HFA is highly sensitive to the list length L fa of the LAHC, and thus extensive experiments is done to set the value of this parameter (see Fig. 5). On the other hand, the other parameters have negligible impact on the HFA when we experimented it with different values. That is, when we set the Swarm_size to 60, and the max_number_of_iterations to 500, the accuracy only improved by 0.006%, while, we required to make extra 26 thousand times of semantic evaluations. Hence, we followed the recommended values of the FA’s parameters based on its original study in [35].
This study quantifies the relatedness between two concepts based on the notion of gloss overlapping, which is represented by the Lesk algorithm. Given two concepts (or senses) C1 and C2, the relatedness score is the overlap in definitions (i.e., words in common) of these concepts. Given two words w1 and w2, where C1∈ concepts (w1) and C2∈ concepts (w2), then the semantic relatedness based on Lesk algorithm is calculated as follows:
The extended Lesk algorithm (eLesk) goes beyond glosses of a pair of concepts to include related ones [7]. This is enables eLesk to find more overlaps for the concepts being measured, which lead to accurate semantic relatedness. However, eLesk algorithm does not consider the information of words in frequency with respect to lexical relations. Thus, this study incorporates the Resink method to measure the similarity between two concepts.
Resnik method is a measure of the similarity between two concepts based on the notion of information content (IC) [29]. IC is based on the specificity of the concept, i.e., highly specific concepts (e.g., fork and pitch) would reveal a high similarity score. IC is calculated regarding the frequency counts of the concept in a corpus of text. Formally, IC for each concept calculated as the negative log of the concept’s frequency to its root’s frequency, as shown in Equation:
Given two concepts, the method of Resnik states that the IC of the least common subsumer (LCS) of the concepts. The LCS of any two concepts is the nearest root that subsumes them. Formally, Equation 9 presents Resnik method mathematically to calculate the similarity between two concepts (C1 and C2) as follow:
In this study the Resnik similarity enforces the relatedness measured by the eLesk. Resnik method only measures the similarity for the concepts that belong to the verbs or nouns POS because it is based on the WordNet hierarchies. This is due to WordNet isolates the noun hierarchy from the verb hierarchy. Consequently, the LCS of two concepts of different POS cannot be identified. However, this study utilizes eLesk that can measure the relatedness between concepts of different POS.
This section provides the metrics and datasets used for the evaluation of the proposed HFA. Thereafter, this section presents the gained results and compares it to the related works.
Experimental setup
The proposed algorithms in this work have been programmed using Java language. The operating system used in this work is Ubuntu 16.04.6 installed on a Dell machine. This machine has a RAM of 16 GB and the CPU model is Intel(R) Xeon(R) CPU E5-2650 of 2.30 GHz. To read the datasets, a Java API called JSemCor is used to interface with datasets files and retrieve the required data. Also, another Java API called JWI is used to retrieve data from the WordNet database.
Datasets and metrics of evaluation
To evaluate an algorithm for the WSD task, it is required to know the ambiguous words and their corresponding correct senses. The well-known Semcor dataset provides the detailed tags for each word in the given text. Semcor came from the Brown corpus, where WordNet is used to annotate some of its files to constitute a semantic concordance (which is shorten to Semcor) [20]. The Semcor is composed of set of files which covers more than 234,000 word frequencies, and thus these files could serve to evaluate a WSD system. Commonly, set of files from Secmcor is used as a benchmark for the evaluation, which have been used in previous studies [33, 38]. Particularly, these are nineteen files, which are as follows, br-a01, b13, c0l, d02, e22, r05, g14,h21, j0l, k01, k11, l09, m02, n05, p07, r04, r06, r08, and r09. Also, two more datasets are considered which are Senseval-2, and Senseval-3 [18, 21]. This dataset is formatted in tag-based files, where each sentence is tokenized to set of words. Each word occupies one line as shown in Fig. 3.

A snippet from the dataset used in this study.
In Fig. 3, each line contains the orthogonal form of the word, sense number, POS, and lemma which is the base of the word. The POS and the lemma save the effort of doing pre-processing operations like stemming and POS tagging. The lemma of word and its POS are used to retrieve the sense count from the WordNet of the targeted word.
Based on these datasets, the accuracy of the proposed method is calculated by counting the number of words correctly tagged to the suitable sense. There are three forms of calculating the accuracy which are the precision, recall, and coverage. The coverage reports the percentage of number of tackled words to the total number of word (See Equation 10). Thus, the coverage does not show the accuracy, yet it shows the coverage of the algorithm.
In WSD, some methods obtained higher precision than others, but they are inferior to others in term of recall. Hence, taking the average of these metrics is helpful to indicate the accuracy of a method. F-measure is the harmonic average of the precision and recall which is calculated as follows:
In this study, we have conducted series of experiments based on the aforementioned datasets. These experiment show the effectiveness of each part of the proposed method. The first experiment aims to show the impact of the proposed semantic relatedness method. This consists of examining the searching algorithm with different semantic relatedness methods as shown in Table 3–5. Second experiment concerns the effectiveness of the LAHC when different values used for its parameter L fa as shown in Fig. 5. Third experiment is dedicated to show impact of the LAHC on the FA (see Fig. 4). Finally, comparisons to related methods are presented in Fig. 6. In these experiments, the window of words is set to eleven words, which has been successfully employed in previous studies [1, 33]. On the other hand, selecting a window of more than eleven may contribute negatively by including unwanted attributes [17].
HFA’s results based on Resnik semantic similarity method
HFA’s results based on Resnik semantic similarity method
HFA’s results using eLesk method based on Semcor dataset
HFA’s results using a combination of eLesk and Resnik methods
Table 3 shows the results obtained using the proposed HFA, where Resnik method is employed to measure the similarity. The Resnik method is experimented on all types of datasets used in this study. In these experiments the proposed HFA tackled two classes of the POS, which are the nouns and verbs. Other POS’s classes were not experimented because the similarity method used in these experiments are limited to nouns and verbs only. Based on Semcor, the proposed HFA yielded a precision of 71.69% for nouns, which is equivalent to the recall and F-measure as all nouns are covered (i.e., the coverage is 100%). While, it achieved more than 77% and 38% for verb’s precision and recall, respectively. Due to the incomplete coverage for verb POS, the F-measure can used to identify the average of the precision and recall, which is 42.87%. On the other hand, for senseval-2 and senseval-3 the proposed HFA achieved a slightly lower F-measure in comparison to semcor four noun POS. While, it was able to cover more verbs in senseval-2 than semcor, and senseval, i.e., its verb’s coverage is more than 93%. As the Resnik algorithm is unable to measure the similarity for all POS’s classes, the proposed method in this research utilized the extended Lesk beside the Resnik algorithm.
To examine the eLesk capacity, we first experimented the HFA using eLesk only as shown in Table 4. Thereafter, the eLesk and Resnik methods are combined to serve as the objective function for the HFA (see Table 4).
Table 4 shows the accuracy of the HFA when eLesk algorithm is used for evaluating the relatedness between two given concepts. Using eLesk, the HFA was able to cover 94.34% of the given text with 64.50% for the F-measure metric. The eLesk was slightly inaccurate in comparison to Resnik algorithm when noun and verb POS are considered. However, the eLesk algorithm compensate the shortage of the Resnik algorithm, where the latter is limited to nouns and verbs only. The experimental results of combining these algorithms are given in Table 5.
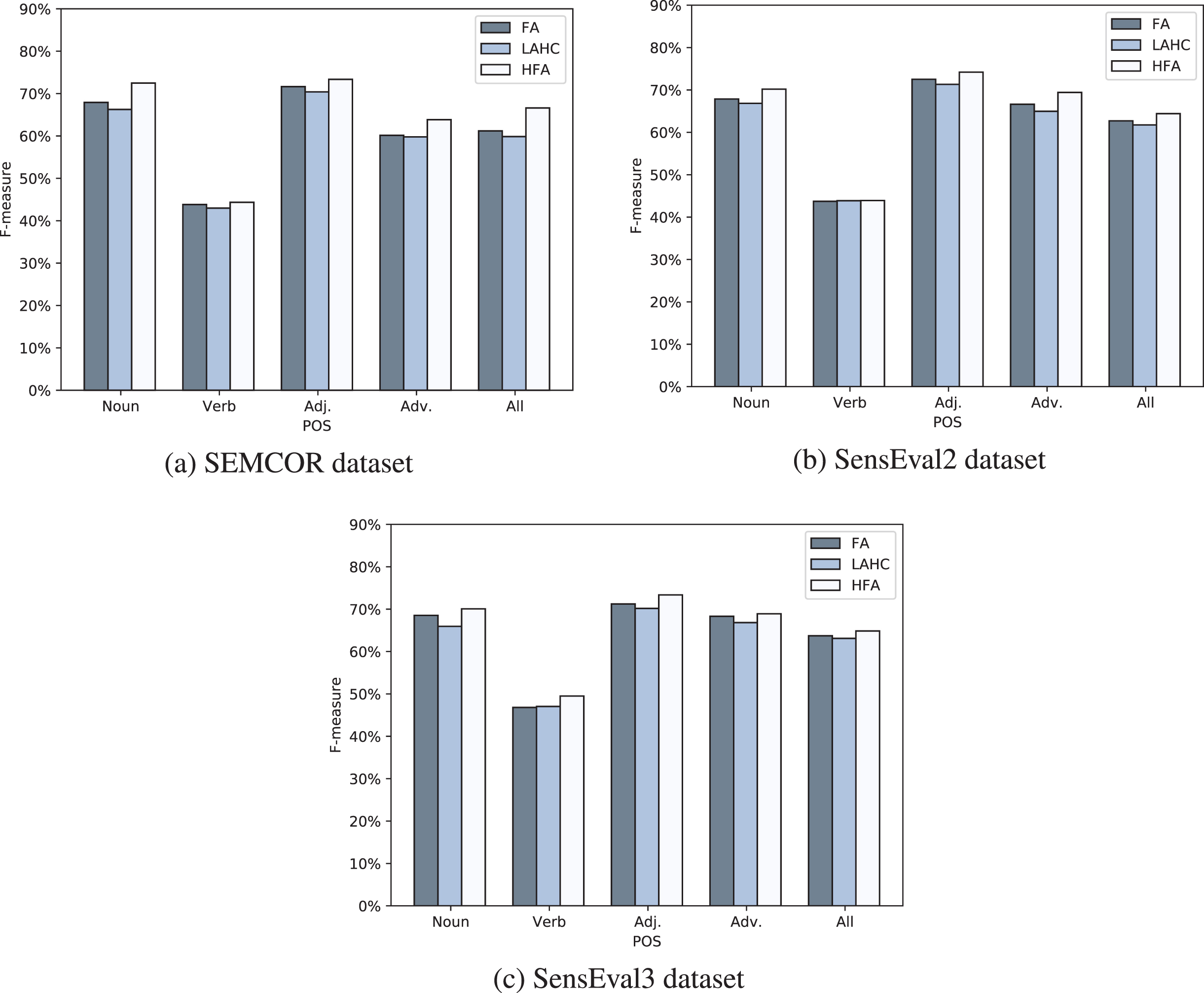
Experimental results of the hybrid firefly algorithm versus its basic form and the LAHC based on the F-measure metric.

The impact of the L fa on the accuracy of the HFA for the br-a01 instance from the Semcor dataset.
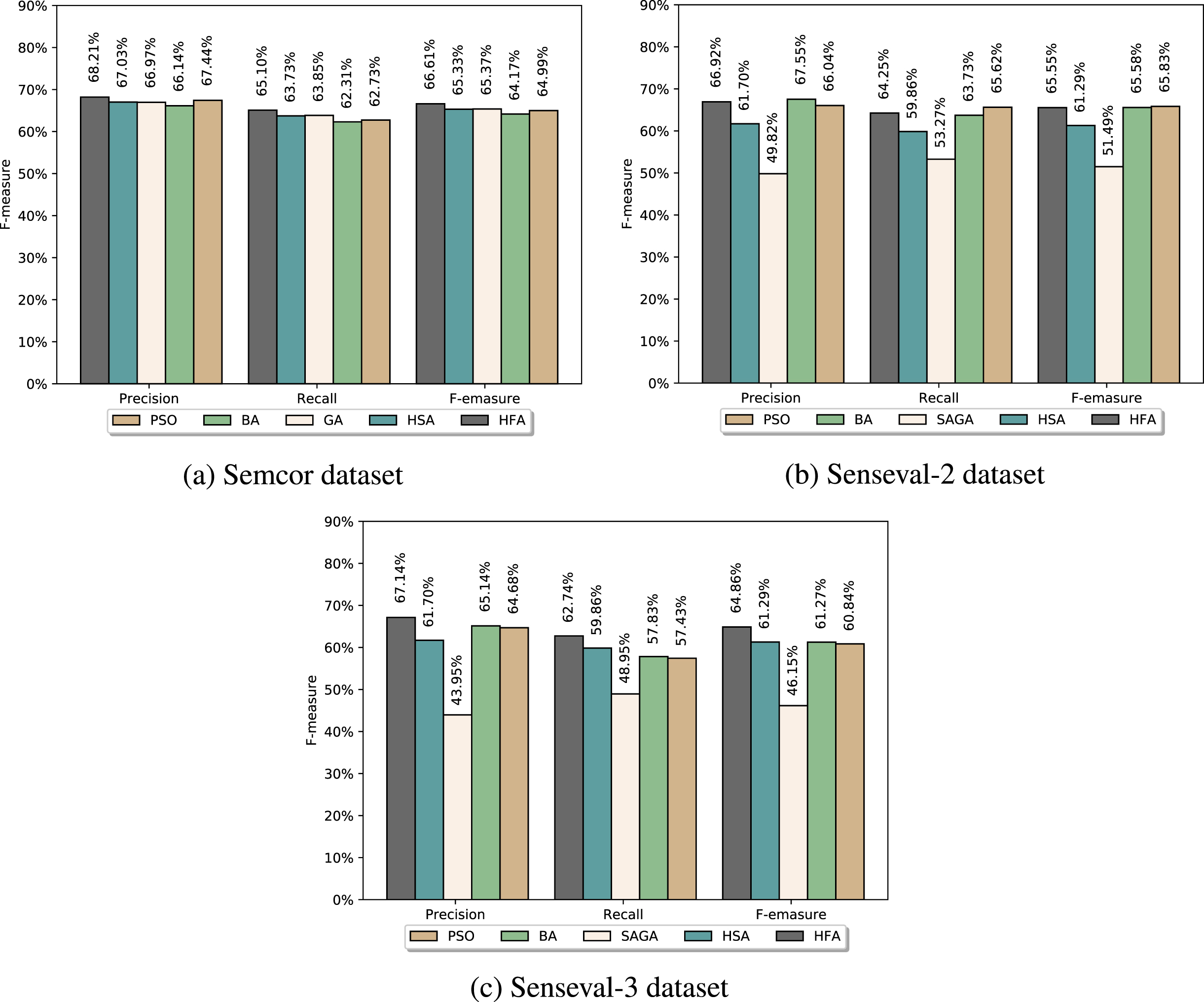
The HFA’s F-measure against the state-of-the-art meta-heuristic-based WSD algorithms for all POS classes.
The combination of the semantic measures in Table 5 shows improvement over the individual ones in Tables 4 and 3. This is can be noted when we compare the results in Table 5 to these in Tables 3 and 4. The gain of the combined measure can be observed for nouns and verbs as the Resnik method can operate on them. In specific, for the Semcor dataset, the combined measure achieved 72.35% and 44.35% in term of F-measure for nouns and verbs, respectively. While, when only eLesk was used the HFA obtained an F-measure of 71.31% and 43.81% for same POS classes. On the other hand, the combined measure yielded an F-measure of 70.19%, and 43.91% for nouns and verbs using the Senseval-2 dataset. This is more accurate than using Resnik method individually, where it has obtained under the same setting 69.21% and 46.40% for the F-measure of nouns and verbs. Also, the combined measure gained about 2% improvement over the Resnik method for nouns when the Senseval-3 is considered.
The aforementioned experiments have showed the performance of th proposed HFA using different types of the semantic measures. However, the capacity of the HFA is still not detailed. Hence, to show the impact of the LAHC on the HFA, we conducted an experiment by running each algorithm separately (see Fig. 4).
Figure 4 displays the accuracy in term of F-measure of the search methods used in this study. The proposed method in this study used two meta-heuristic algorithms which is the FA and the LAHC. The FA emphasis exploring the problem space, while the LAHC focuses on exploiting it. Figure 4 shows that the FA can obtain better accuracy than the LAHC for all POS’s classes. Yet, achieving the balance between exploration and exploitation features is vital to obtain the best possible estimation for the optimal solution [11, 34]. Thus, incorporating LAHC to perform local searching helped the HFA to exploit the problem space better than the FA individually as shown in Fig. 4. The experiment presented in Fig. 4 is done after tuning the length of the LAHC list. The tuning of this parameter consisted of extensive experiments (around 300 runs), which investigates range of values for this parameter as shown in Fig. 5. This experiment showed that setting the L fa to 17000 entries is a proper value for the WSD task.
In comparison to the related works, Fig. 6 gives the accuracy of the HFA against the related disambiguation algorithms.
The comparison in Fig. 6 is based on the three datasets. This comparison includes five methods based on meta-heuristic algorithms. For the Semcor dataset, the proposed HFA outperformed other methods for all metrics, i.e., precision, recall, and F-measure. While for the Senseval-2, the proposed HFA was slightly less accurate than the PSO for the recall and F-measure. Yet, for the same dataset, the HFA could achieve better precision than other at the expense of its coverage. On the other hand, the HFA obtained better F-measure than the PSO and other methods when the Senseval-3 was considered.
The experimental outcome shows that the proposed HFA achieved best results with respect to the solution quality in comparison to the other five methods. The proposed semantic measure has the vital role to accurately evaluate the HFA solutions. Also, the LAHC used in the HFA enabled the algorithm to effectively avoid low-quality local optima as shown in the experiment presented in Fig. 4.
The accuracy of the proposed HFA relies mainly on its objective function, which is the semantic measurement. In this study, our proposed semantic relatedness has outperformed conventional methods to achieve the WSD as shown in Tables 3, 4, and 5. That is, the overall performance of the HFA is highly impacted by the semantic relatedness. Thus, obtaining accurate semantic measurement can lead to further improvement in the searching algorithm. Also, the proposed FA has shown considerable improvement when it was hybridized with the local search.
The FA is easy to implement due to its simplicity in term of complexity as it is for the most meta-heuristic algorithms. The FA’s complexity is
Practically, the first step in the FA is to initialize the positions of the swarm members as shown in Fig. 2. Also, this steps requires sorting these members according to their attractiveness. Thus, the complexity of this step is as follows:
In this study, the HFA consists of the FA and LAHC. The LAHC is invoked within a predefined probability lr. The complexity of the LAHC is
Conclusion
This work presented a computational method to perform the task of word sense disambiguation. This method has gained improved results when it is tested on three distinct benchmark datasets. The success of the proposed method is attributed to the developed optimization algorithm and its objective function. Based on the experimental results, the role of the proposed LAHC as a local search has enabled the HFA to obtain accurate results. That is, the LAHC algorithm consolidates the intensification process of the FA. However, the LAHC is sensitive to its main parameter, which is the length of the history list. Thus, we have tuned this parameter to obtain the best possible set of senses. For the semantic measure, the developed method in this work has been proved to be more efficient than conventional methods. This is due to exploiting the information content notion beside the gloss overlapping. Specifically, the knowledge obtained from the WordNet hierarchies has added more information to the idea of calculating the commonalities between glosses of two concepts. On the other hand, the proposed method would not be able to measure the semantic relatedness for two words outside the WordNet. Thus, investigating other algorithms that can scale for informally written text will be beneficial for future works.