
Abstract
Manufacturing industry is the foundation of a country’s economic development and prosperity. At present, the data in manufacturing enterprises have the problems of weak correlation and high redundancy, which can be solved effectively by knowledge graph. In this paper, a method of knowledge graph construction in manufacturing domain based on knowledge enhanced word embedding model is proposed. The main contributions are as follows: (1) At the algorithmic level, this paper proposes KEWE-BERT, an end-to-end model for joint entity and relation extraction, which superimposes the token embedding and knowledge embedding output by BERT and TransR so as to improve the effect of knowledge extraction; (2) At the application level, knowledge representation model ManuOnto and dataset ManuDT are constructed based on real manufacturing scenarios, and KEWE-BERT is used to construct knowledge graph from them. The knowledge graph constructed has rich semantic relations, which can be applied in actual production environment. Other than that, KEWE-BERT can extract effective knowledge and patterns from redundant texts in the enterprise, which providing a solution for enterprise data management.
Introduction
With the rapid development of big data, artificial intelligence and other technologies, the traditional manufacturing industry is accelerating toward a new generation of intelligent manufacturing [1]. In the process of the development from traditional manufacturing to intelligent manufacturing, with the increasing complexity of manufacturing system and personalized demand of users, the scale of industrial data generated in the manufacturing process is increasingly large [2]. At present, the storage of data is based on the traditional relational database, which exists a lot of redundancy and causes weak correlation between data [3]. It only emphasizes the storage and retrieval of data, and does not excavate the knowledge behind [4, 5], which causes the abundant knowledge contained in industrial data has not been effectively utilized. In this regard, the knowledge graph provides a good solution.
As a concept proposed by Google in 2012, the knowledge graph is essentially a sublation and sublimation of semantic web standards and technologies [6]. The knowledge graph can store the prior knowledge of human beings in the form of nodes and edges, and form a network structure through the relevance of different knowledge [7]. Compared with traditional databases, knowledge graph has a strong ability to express relationships, and enable to handle complex and diverse association analysis, so as to meet the analysis and management needs of various role relationships in manufacturing enterprises [8–10]. Extracting knowledge from a large amount of industrial data, mining the semantic information behind the data, and constructing a knowledge graph can not only effectively utilize the abundant knowledge contained in industrial data, reduce data redundancy, but also manage the enterprise production process and provide more valuable decision support. In recent years, with the continuous development of deep learning and natural language processing technology, the automatic construction of domain knowledge graph has become possible, but there are still the following shortcomings [11–13]: Natural language processing models based on deep learning rely on large-scale corpora, while domain-specific corpora are mostly labeled manually and are relatively small in scale. How to improve the effect of knowledge extraction in small sample learning is still to be studied. At the present stage, knowledge extraction mostly adopts the traditional pipelined extraction method, which will cause error accumulation in multiple extraction tasks. In order to achieve better results, entity recognition and relationship extraction tasks need to be jointly modeled in an end-to-end model.
To solve the above problems, this paper proposes KEWE-BERT (Knowledge Enhanced Word Embedding BERT), an end-to-end model based on knowledge enhanced word embedding for joint entity and relation extraction in manufacturing domain. KEWE-BERT optimizes the token embedding generated by pre-trained model BERT (Bidirectional Encoder Representation from Transformers) [14] with the existing knowledge representation model, and then end-to-end manufacturing domain knowledge extraction is carried out on this basis. KEWE-BERT can improve the extraction effect of domain knowledge under the condition of limited domain corpus size, and has good portability. The main research content of this paper includes: (1) Acquisition and embedding of knowledge with knowledge representation model; (2) Aggregator and optimization between knowledge embedding and token embedding; (3) Joint entity and relation extraction based on knowledge enhanced word embedding.
The rest of this paper is organized as follows. Section 2 reviews the related research progress of knowledge graph construction and knowledge enhanced language pre-training model. In section 3, KEWE-BERT is proposed and elaborated. Section 4 describes the case to evaluate performance of the proposed method. Finally, the conclusion and prospect are given in Section 5.
Related work
Knowledge graph construction
At this stage, with the rapid development of artificial intelligence and natural language processing, knowledge graph construction techniques are advancing and improving. It becomes possible to extract knowledge with high quality from documents automatically [15–18]. Knowledge extraction refers to the process of extracting knowledge that matches the fact from a given document content [19, 20]. Essentially, it is the extraction of the triplets of entity and relationships corresponding to the knowledge. Supervised entity and relationship extraction methods can be divided into pipeline and joint learning. Most researchers use pipeline method when carrying out triplet extraction, which treats named entity recognition and relationship classification as two separate tasks [21, 22]. This method ignores the correlation between the two tasks and will cause error accumulation [23]. Recent studies have shown that the use of joint learning can more closely interact the information between entities and relationships, which is a good solution to the problems existing in the pipeline approach. Miwa et al. proposed a novel end-to-end model to extract relationships between entities. The model uses a BiLSTM and tree-LSTM structure to extract entities and their relationships simultaneously, and is a pioneering work in joint entity and relationship extraction [12]; Zheng et al. use the neural network model of hybrid BiLSTM-ED and CNN, and performed well in entity and relationship extraction task [24]; Luo et al. proposed a joint learning method based on ATT-BILSTM-CRF for biomedical entity and relationship extraction [25].
Due to its special characteristics, knowledge graph in manufacturing domain is more concerned about the accuracy of knowledge besides the completeness of knowledge. When the knowledge is extracted from the data, the quality of the triplets obtained directly determines the quality of the constructed knowledge graph. Therefore, manufacturing domain knowledge graphs are mostly constructed by domain experts in a manual manner, and automatic extraction techniques are only used as auxiliary means. This paper will study how to ensure the reliability and completeness of the extracted knowledge at the same time.
Knowledge enhanced language pre-training model
In recent years, the training language model is a hotspot in research of natural language processing, which usually trained on large-scale general corpus, and the transfer training is then performed for different tasks. The application of pre-training language representation model in downstream tasks mainly includes feature-based methods [26–29] and fine-tuning methods (GPT [30], BERT [14]). At present, the application of pre-training model in specific fields mainly relies on the subsequent domain corpus for training. Lee et al. conducted pre-training on Bert through the biomedical domain corpus and proposed BioBERT. Through their work, BERT is introduced into the biomedical field, but it is essentially a focus on the data set. The process of pre-training consumes time and computational resources, which is difficult for ordinary researchers to realize [31]. The Knowledge enhanced language pre-training model provides a good solution. The knowledge representation model is integrated into the pretraining language model to provide domain knowledge for the model, so as to improve the performance of the model on specific domain tasks and reduce the cost of large-scale pretraining. Zhang et al. took the entities in the knowledge graph as external knowledge to improve the language representation of the pre-training model, and train an enhanced language representation model ERNIE. However, the relationship information of the knowledge graph in this method was not used [32]. Liu et al. proposed K-BERT, which integrates the knowledge graph into the pre-training language model, and use soft position coding and visible matrix to solve the problem that traditional BERT model can only deal with sequence structure but not graph structure [33]. To date, no such studies have been conducted for the manufacturing domain. This paper will continue to explore based on previous studies, optimizing the token embedding generated by pre-training model BERT with the knowledge embedding in existing ontology model. Then, the knowledge graph of the manufacturing domain will be constructed and applied to the real application scenarios to verify its effectiveness.
Methodology
Framework
The framework of this paper is shown in Fig. 1. The top of the architecture diagram is the data input, which consists of two parts: (1) Internal and external data of the manufacturing enterprise. This part is composed of enterprise information system data, production equipment information, supplier and customer information on the Internet. This text information is the data source of manufacturing knowledge graph construction, and will be input to the BERT model in the form of a single sentence to obtain a token embedding; (2) Existing ontology model about manufacturing domain. As a knowledge representation model, the ontology provides the domain knowledge needed to optimize the construction effect of the knowledge graph. After the ontology is processed to obtain knowledge, the knowledge embedding is obtained through the TransR [34], and then the token embedding generated by BERT is aggregated and optimized.

The framework of knowledge graph construction method with KEWE-BERT in manufacturing domain.
For the input single sentence, the knowledge in the existing ontology model is first aligned with the content in the single sentence, and then the two are vectorized separately. The vectorization of knowledge adopts the TransR model to represent the semantic information of knowledge as a dense low-dimensional real-valued vector form, so as to efficiently calculate the complex semantic association between entities and relations. When vectorizing a single sentence, the pre-training model BERT is used to encode it. Up to this point, the token embedding and the corresponding entity embedding of the sentence are obtained. However, encoding through BERT is very different from the process of representing knowledge, so there is a heterogeneity problem between these two. In order to solve this problem, this paper refers to the design of the aggregator module in ERNIE model to integrate the token embedding and corresponding knowledge embedding, so as to achieve the goal of enhancing the representation of pre-training model embedding with knowledge. Subsequently, the extraction of knowledge triplets is performed. The main task of triplet extraction is to perform named entity recognition and relation classification. In this paper, the end-to-end model KEWE-BERT is used for word embedding optimization and joint extraction for entity and relationship, which will be described in the following sections. After obtaining a set of triplets in the form of <rolling unit, is after, heating furnace>, it is stored in the graph database to realize the construction of a knowledge graph in the manufacturing domain.
The extraction of triplets based on knowledge enhanced word embedding is the core content of this paper. After the knowledge in the ontology has been processed into triplets, the next step is to embed the acquired knowledge into token embedding generated from the pre-training model BERT, and realize the joint entity and relation extraction on the basis. The KEWE-BERT proposed in this paper can achieve end-to-end extraction, and its process is shown in Fig. 2, including the knowledge enhanced word embedding module, entity extraction module, and relationship classification module.
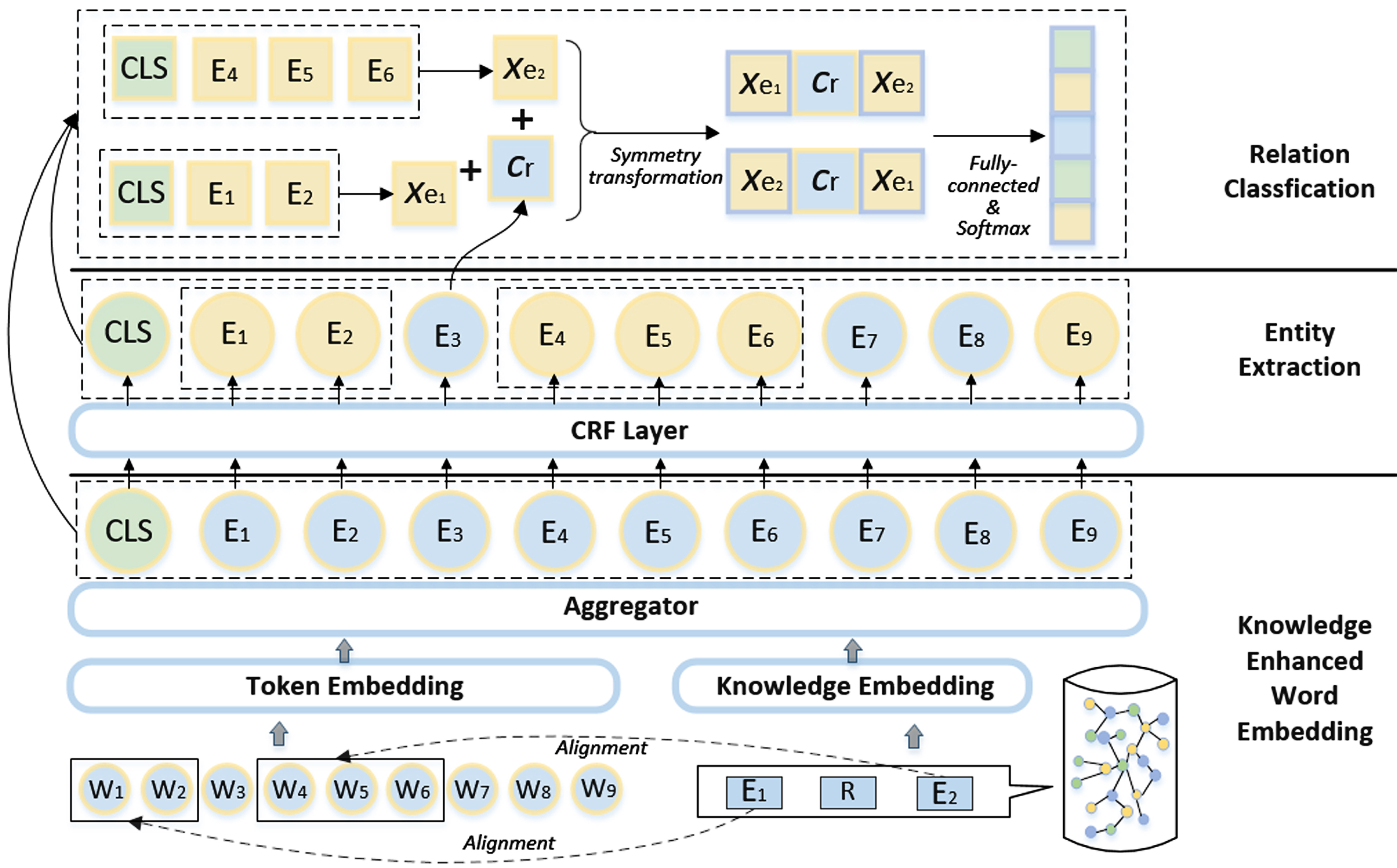
The process of KEWE-BERT.
The structure of this module refers to the design of the ERNIE, which consists of token embedding and knowledge embedding. In contrast, the internal structure of BERT is not changed in this paper, which makes the KEWE-BERT have strong portability and can share parameters with other BERT models. In addition, when encoding knowledge, ERNIE uses the TransE [35] which projects entities into a low-dimensional vector space and ignores information about relationships other than entities within the triplets. KEWE-BERT adopts TransR as knowledge embedding model. The advantage is that TransR considers that in the triplets, different relationships focus on different aspects of the entity, so it will model in the entity space and the corresponding relationship space when embedding word vector, making the entity embedding modeled by TransR associated with the relationship, which solves the shortcoming that ERNIE only cares about the entity vectors in the triplets but ignores the relationship between entities.
For a single input sentence {W1, W2, … , W
n
}, there is a corresponding entity in the existing knowledge {E1, E2, … , E
m
}, and a R relationship between E1, E2. In the TransR, the representations of the triplets (h, r, t) are h, t ∈ R
k
, r ∈ R
d
. For each relation r, there is a mapping matrix M
r
∈ Rk×d, Then the projection process of the TransR model can be expressed by the following formula:
Note that in the TransR, entities corresponding to different relationships are represented differently. Therefore, when acquiring knowledge embedding, there may be situations where the same entity has different vector representations. In this case, KEWE-BERT average and process it, and the final vector is represented as:
Wherein, num is the number of vectors represented by the i-th entity.
For a single input sentence {W1, W2, … , W
n
}, KEWE-BERT encodes it with BERT and obtains token embedding {w1, w2, … , w
n
}, The vector obtained by the corresponding entity after TransR mapping is {e1, e2, … , e
m
}. Sending them into the aggregator, so is:
The specific operation is to first perform multi-head attention integration on the two separately, the formula is as follows:
Then integrate the characteristics of the two. When there is a corresponding entity for the token in a single sentence, it is assumed that there is e
k
= f (w
j
), then:
When there is not a corresponding entity, so is:
So far, word embedding
After obtaining the feature vector with rich semantic knowledge, CRF is used to decode it to obtain a predicted labeling sequence, and then each entity in the sequence is extracted and classified to complete the entire process of entity extraction. Compared with Softmax, CRF uses log-linear model to represent the joint probability of the whole feature sequence, which better considers the dependence between tags. For a given sequence X ={ x1, x2, …, x
n
} and the corresponding label sequence T ={ t1, t2, …, t
n
}, The evaluation score calculation formula is defined as follows:
Wherein, A is the transition score matrix, and Pi,t i represents the score of the i-th word corresponding to the t i tag.
There are many possibilities for the predicted sequence. All possible sequences are normalized globally to generate the probability from the original sequence to the predicted sequence. Then there is:
Among them,
After the final decoding, the output sequence is obtained:
After the extraction of entities is completed, the task of relation classification is entered. Given a predefined set of relational classes R ={ r1, r2, …, r j }, the relation classification module handles all candidate entity pairs from the single sentence, and determine whether there is a relationship from R.
The input of the relationship classification module is composed of two parts. One is the entity vector representation x
e
obtained in the entity recognition part, including the word embedding corresponding to the entity and the semantic feature vector [CLS] that can represent the whole text, i.e.:
Among them, e i is the word embedding after the max pooling, c is the semantic representation of the whole text, n, m is the entity position embedding from the entity extraction module.
Another input of the relationship classification module is the embedding of the text between the two entities, that is, the candidate relationship vector, which is spliced with the preceding and following entity vectors after the max pooling. Considering that there may be symmetry between entities and relations in their positions [36], a symmetric exchange process will be carried out during the stitching of entities and relations, and then it will be sent into the relationship classifier. The formula is as follows:
Wherein, c r is the candidate relationship vector after max pooling, and xe1, xe2 are the entity vector representations before and after c r .
The relation classification problem adopts cross-entropy as loss function to calculate loss, which measures the degree of difference between two different probability distributions in the same random variable, namely, the difference between the real probability distribution and the predicted probability distribution. The smaller the value of cross-entropy function, the better the prediction effect of the model. The loss function for the relational classification task is:
Wherein, m is the number of samples, and r i is the one hot vector mapped from the category label.
The loss function of joint entity and relationship extraction shall be expressed as the sum of the entity identification loss function L
e
and the relationship classification loss function L
r
, namely:
This section introduces the case study background and verifies the validation of the method proposed in this paper. The results will be analyzed at the end of this section.
Problem description
With the optimization and adjustment of national production capacity policies, competition in the steel industry has become increasingly fierce. At present, steel production is faced with such problems as individuation of customer demand, increasingly strict requirement of material quality, and poor coordination of supply chain.
The continuous rolling production line of an iron and steel enterprise includes hot rolling and cold rolling. The process involved is complex, and there are many kinds and quantities of equipment. In hot rolling and cold rolling production process, data such as daily production plan, workshop operators, inventory and equipment information are involved. Some of these data rely on paper offline transmission, and some are stored through information systems, and there is no correlation between the data, which causes the low efficiency of the production workshop, the information cannot be synchronized, and the source of decision-making knowledge is single. There are following problems in the production process management of iron and steel enterprise: Product management is chaotic, and the backlog of products is serious, unable to clear and effective statistics. The workshop production process is complicated, and the equipment involved is large and varied, which cannot be effectively managed. A large amount of text information is generated during the production process in the workshop, including production logs and team plans, which cannot be directly stored in the system. These texts contain rich semantic knowledge, but they have not been effectively used.
In response to the above problems, this paper is positioned at the hot rolling production line of the enterprise, using KEWE-BERT to construct knowledge graph of hot rolling production management by extracting knowledge from the redundant production records of the company with the existing hot rolling ontology model. The knowledge graph constructed by our method can: Utilize redundant text information within the enterprise. Associate the existing data of the enterprise to form a topological structure, and the nodes in the structure have strong associations. The domain knowledge graph requires high accuracy of knowledge. Experiments have proved that the knowledge extracted by KEWE-BERT has good accuracy.
ManuDT dataset
This paper constructs an ontology model named ManuOnto and its corresponding training corpus ManuDT for the field of steel manufacturing. ManuOnto contains 1952 axioms, 427 class concepts, and 514 data attributes, which built by experts and based on real-life situations in the steel manufacturing industry, with reliable and standard knowledge.
After processing, 1064 pieces of knowledge are finally obtained. The ManuDT dataset consists of 901 single sentences, which are manually annotated and collated from textual information provided by the enterprise. This data set defines 6 types of entities and 7 types of relationships, as shown in Tables 1 and 2.
Entity Category Information of ManuDT
Entity Category Information of ManuDT
Relation Category Information of ManuDT
According to the in-depth investigation of the production activities of the enterprise, ManuDT has defined 6 types of entities and 7 types of relationships. Entity categories include equipment, staffing organization, material, business activities, equipment parameters, and text form box. In addition to the aggregation and the correlation relationship, the relation category also defines the contextual relationship and supply-demand relationship in time/space/process flow, to include the relation involved in the production activities of the manufacturing enterprise to the greatest extent.
In this paper, ManuDT is randomly divided into training set (80%), validation set (10%) and test set (10%) and input into the model for experiment. The experimental environment of this paper is Intel Xeon 5238 CPU@2.1 Hz x 2, 1T SSD, 4xTesla T4 GPU, 256 G running memory. The accuracy, recall and F1-score are used to evaluate the performance of the algorithm. The evaluation indicators are defined as follows:
Among them, N correct is the number of entities or relationships that are predicted to be correct, N all is the total number of predicted entities or relationships, N marked is the total number of marked entities or relationships.
In addition, the KEWE-BERT proposed in this paper is compared with the traditional Bert in order to observe its improvement in performance. The experimental results are shown in Fig. 3, Tables 3 and 4. As can be seen from the Loss curve and the data in the table, compared with BERT without knowledge embedding, KEWE-BERT proposed in this paper based on the knowledge enhanced word embedding, has a certain improvement in the effectiveness of two tasks of entity recognition and relationship extraction. Among them, the improvement effect of the entity recognition task is more obvious than that of the relation classification task.
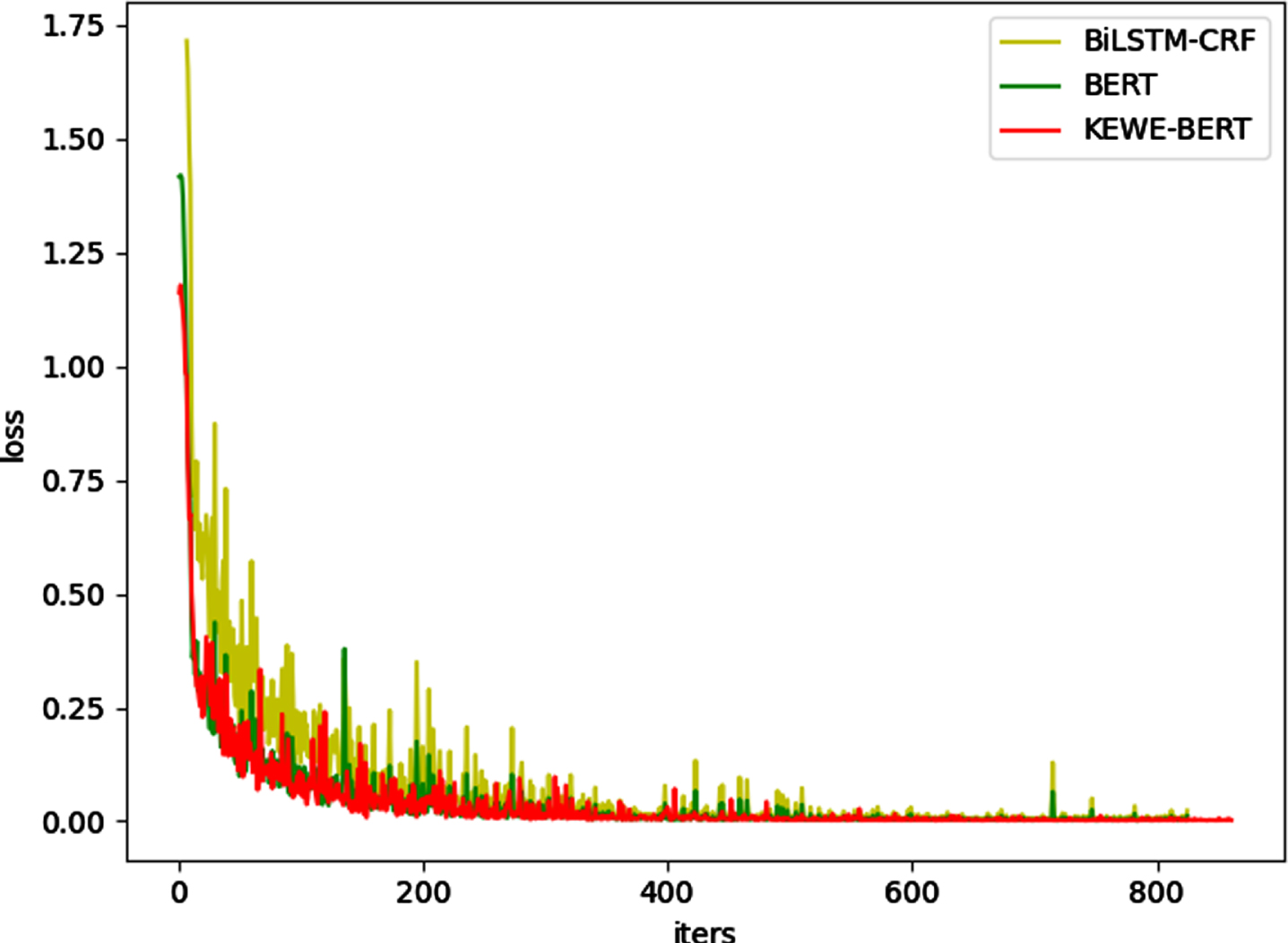
Comparison of loss curves.
The results of Entity recognition task
The results of relation classification task
The triplets in the steel manufacturing domain extracted by KEWE-BERT are stored in Neo4 j, and finally the knowledge graph of the manufacturing domain is obtained. In this paper, 150 nodes are selected for display, as shown in Fig. 4. The different colors of the nodes represent different entity types and data source. It can be seen that knowledge graph constructed by KEWE-BERT has rich relationships between nodes. Different types of nodes are related and blended with each other, which enhances the correlation between data and realizes the semantic level of various types of data. In-depth integration of the above, thereby improving the synergy efficiency of the production workshop and realizing effective continuous rolling production management.
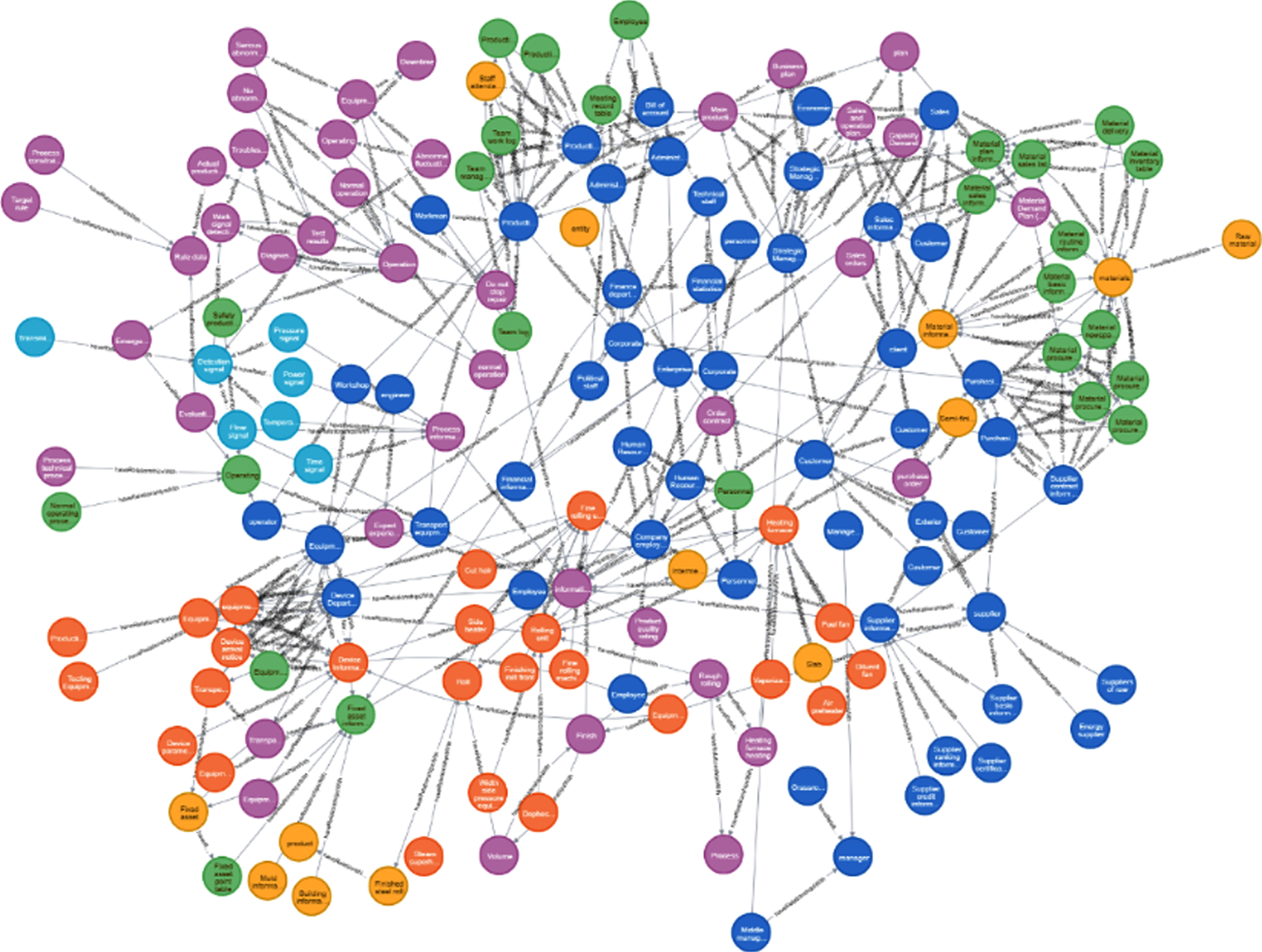
The knowledge graph of the manufacturing domain.
This paper proposes KEWE-BERT, an end-to-end model based on knowledge enhanced word embedding for joint entity and relation extraction in manufacturing domain. KEWE-BERT optimizes the token embedding generated by pre-trained model BERT with the existing knowledge representation model, and then end-to-end manufacturing domain knowledge extraction is carried out on this basis. KEWE-BERT can improve the extraction effect of domain knowledge under the condition of limited domain corpus size, and it has good portability. Experiments have proved that the triplets extracted by KEWE-BERT have better accuracy than BiLSTM-CRF and BERT. And the domain knowledge graph constructed at the end of this article has rich semantic relations, realizing the semantic level of various types of data, thereby improving the synergy efficiency of the production workshop, and realizing effective continuous rolling production management.
The main contribution of this paper lies in: (1) At the algorithm level, this paper proposes KEWE-BERT, an end-to-end model for joint entity and relation extraction. KEWE-BERT uses the domain knowledge embedding output by TransR to optimize the token embedding output by the BERT, which making embedding not only has common sense, but also has domain knowledge, and solving the problem that the current domain corpus is small due to manual annotation, which makes the deep learning model not effective. (2) At the application level, this paper constructs ManuDT and a knowledge representation model ManuOnto based on real manufacturing application scenarios, and uses KEWE-BERT to extract triplets from them, and finally builds the knowledge graph in manufacturing domain. The knowledge graph finally constructed has rich semantic relations, which can be applied in actual production, and the proposed model KEWE-BERT can extract effective knowledge and patterns from a large number of redundant texts in the enterprise, providing a solution for enterprise data management.
In the face of complex and changeable manufacturing environment, knowledge-driven and collaborative operation has become the leading direction to explore the scientific proposition of autonomous intelligent factory control and decision. In the following research, the evolutionary mechanism of self-learning knowledge graph of intelligent factory will be further explored. At the same time, knowledge-driven intelligent decision and optimization theory and method research will be carried out to solve the huge challenges faced by enterprise decision and optimization in complex manufacturing environment, and effectively promote the transformation of scientific research on enterprise comprehensive decision and optimization from expert-based to knowledge-driven model.
Footnotes
Acknowledgments
This work was supported by the National Science and Technology Innovation 2030 of China Next-Generation Artificial Intelligence Major Project, Data-Driven Tripartite Collaborative Decision-Making and Optimization, under Grant 2018AAA0101801.