
Abstract
Classification of incomplete instance is a challenging problem due to the missing features generally cause uncertainty in the classification result. A new evidential classification method of incomplete instance based on adaptive imputation thanks to the framework of evidence theory. Specifically, the missing values of different incomplete instances in test set are adaptively estimated based on Shannon entropy and K-nearest centroid neighbors (KNCNs) technology. The single or multiple edited instances (with estimations) then are classified by the chosen classifier to get single or multiple classification results for the instances with different discounting (weighting) factors, and a new adaptive global fusion method finally is proposed to unify the different discounted results. The proposed method can well capture the imprecision degree of classification by submitting the instances that are difficult to be classified into a specific class to associate the meta-class and effectively reduce the classification error rates. The effectiveness and robustness of the proposed method has been tested through four experiments with artificial and real datasets.
Introduction
Classification is one of the most important tasks in statistics machine learning communities [1, 2]. Many algorithms have emerged, including decision trees, support vector machines, K-nearest neighbors and neural networks, to deal with classification problems. Whereas most of them require complete data and cannot directly and effectively analyze missing data. Unfortunately, incomplete instance, also called missing data, which is a common phenomenon in many real-world domains [3]. The causes of missing values range from human errors to equipment failures. For example, the data collected from the questionnaire is often incomplete because the respondents will reject some privacy issues. Because of the confidentiality of medical data, not all clinical trials of patients can be obtained [4]. As such, a number of methods [5, 6], based on three missing mechanisms: missing completely at random (MCAR), missing at random (MAR), and not missing at random (NMAR), have been developed to address classification problems with missing data. Majority of the existing methods for treating missing data depend on the assumption of MCAR, i.e., missingness does not rely on observed instances, which is also the focus of our work.
In a general way, incomplete instance treatment methods can be divided into two types: discarding and imputation methods. Discarding incomplete instances is a very simple and convenient technique, but it is inefficient especially for the cardinality of incomplete instances is high.
Imputation strategy, in many scenarios, has an attractive property of solving incomplete instance classification [7–15]. For example, in mean imputation (MI) [7], the missing values can be substituted by the average values of the complete features in the same dimension. However, the main limitation of MI is that replacing missing values with the average values may be imprecise, which causes a distorted estimate of the distribution function. K-nearest neighbor imputation (KNNI) [8, 9] is arguably the most popular method for solving missing values largely due to its ease of use and effectiveness, which uses K-nearest neighbors (KNNs) of instances to estimate missing values. Fuzzy c-means imputation (FCMI) [10], as an imputation method based on machine learning, exploits the clustering centers generated by iteration and the distance between the centers and the instance to impute the missing values. In [11], an interesting estimation method, called support vector regression imputation (SVRI), is proposed to estimate the missing values by minimizing the observed training error. In [12], an imputation method based on self-organizing mapping (SOM) is presented and successfully applied to the prediction of physicochemical parameters of water patterns. Recently, a new method, called linear local approximation (LLA) [13], uses the optimal weights of KNNs obtained by local linear reconstruction to estimate the missing values. In extreme learning machine imputation (ELMI) [14], the missing value is filled by the output of ELM network, which can also handle the problem of missing values. Although the above imputation methods are effective in solving the problem of classifying incomplete patterns in some way, they are all single imputation strategies. In some specific scenarios, however, estimating only one value is unreliable and does not take into account the uncertain caused by missing values. Interestingly, some recent research works have been dedicated to multiple imputation of missing values [16–18]. Multiple imputation is generally better than single imputation, whereas multiple imputation is often more computationally expensive because it takes time to estimate a set of values for each missing value.
To address these challenges, in this paper, we propose a new adaptive imputation method for incomplete instance evidential classification, which will minimize the negative impact of imputation strategy and adopt a more cautious strategy to rationally characterize the uncertainty and imprecision caused by imputation strategy thanks to the evidence theory.
Evidence theory [19] has gained widespread attention as a powerful tool for modeling uncertain information, which has been successfully applied to data classification [20–23], data clustering [24–27], fault diagnosis [28, 29] and information fusion [30–32]. In evidence theory, the instance may belong to multiple classes with different degrees of belief, called meta-classes, which can well represent the imprecision of classification for uncertain instance. On the basis of evidence theory, some classification of missing data methods have been developed [22, 23]. For example, a new incomplete pattern belief classification (PBC) [22] method, where the incomplete pattern is directly submitted into a singleton class or estimated by KNNs, and then, a possibility distance method to partition the uncertain incomplete pattern under the framework of evidence theory. More recently, a new transfer classification of missing data method, named credal transfer learning (CTL) is proposed in [23] to model the uncertainty of estimations for missing values with multi-mapping and the imprecision of classification results. Whereas these methods use K-nearest neighbor to estimate missing values, but their performance will be affected in the case of fewer training set. The nearest centroid neighbor (NCN) [33] is an alternative and effective method that can replace the nearest neighbor method, and its performance is better than KNN.
Based on the above discussions, we attempt to apply K-nearest centroid neighbor into the estimation of missing data and characterize the uncertainty caused by missing values in the framework of evidence theory. Specifically, we first propose K-nearest centroid neighbor imputation (KNCNI) to adaptively fill the instance with missing values, which not only considers the proximity of KNNs, but also considers their geometric distributions. For a query (incomplete) instance, a more rigorous imputation strategy based on Shannon entropy [34] and K-nearest centroid neighbors (KNCNs) to estimate the missing value adaptively, which both consider the weights of different features and the similarity between instances as a whole. After that, we select a standard classifier (such as SVM [35], K-NN [36], EK-NN [37]) that handles the complete instances and use the labeled instances in the training set to classify the each instance with estimation. Finally, different discount (weighting) factors of multiple classification results can be obtained depending on the distance between corresponding KNNs and the query instance, and then a adaptive fusion method is designed to obtain the final decision. By doing this, the instance that is difficult to be correctly classified into a specific class will be automatically submitted to the reasonable meta-class, which can effectively reduce the error rate and reveal the imprecision of classification.
The rest of this paper is organized as follows. The basic information of evidence theory and K-nearest centroid neighbor is shortly reviewed in Section II. The proposed method is introduced in the Section III. The performance of the proposed method is then tested and compared with several other classical methods in Section IV. The conclusion of this paper is given in Section V.
Background
Basic of evidence theory
Evidence theory (also referred as belief functions theory or D-S theory) [19] is originally introduced by Dempster and developed by Shafer, which is considered as an extension of Bayesian probability theory [38] and has permeated into a wide range of fileds [20–32]. In evidence theory, the frame of discernment Ω = {ω1, . . . , ω c } is extended to power set 2 Ω, which contains all the possible subsets of Ω. For example, for a frame of discernment Ω = {ω1, ω2}, the corresponding power set is 2 Ω = {∅ , ω1, ω2, ω1 ∪ ω2}.
1) Mass function
The basic belief assignment (BBA) on the framework of discernment Ω is a function m (.) from 2
Ω to [0, 1], and satisfying:
2) Dempster-Shafer rule of combination
The DS combination of two distinct sources of evidence characterized by the BBA’s m1 (.) and m2 (.) over 2
Ω is denoted m = m1 ⊕ m2, and it is mathematically defined by m
DS
(∅) =0 and for A ≠ ∅ , B, C ∈ 2
Θ by:
1) Nearest Centroid Neighbor (NCN)
As the alternative of nearest neighbor (NN), NCN [33] displays very good performance. The basic idea of NCN is to find the nearest neighbor by the centroid. For a query instance, thereby, NCN not only requires the centroid neighbors are as close as possible to the instance in distance, but also are distributed as evenly as possible around the instance. For a set of instances X = {
The nearest centroid neighbor of the query instance
a) Calculate the distance between the query instance
b) Obtain the nearest centroid neighbor of
c) Calculate the i-th nearest centroid neighbor
2) K-Nearest Centroid Neighbor (KNCN)
As an extension of NCN, KNCN [33] is introduced into pattern classification. Different from KNN, KNCN considers the neighbors proximity and geographical placement to classify the query instance. It is mainly classified by the following steps:
a) Find K-nearest centroid neighbors of the query instance
b) Assign the instance
The proposed method is developed for classification of incomplete instance based on evidence theory, which can properly address the classification that test set contains missing values 1 . For each incomplete instance, KNNs are found in the training set depending on the observed features, and the missing values are estimated respectively by a more rigorous strategy based on KNCNs and Shannon entropy, which fully consider the weights of different features and the similarity between instances. Then, these incomplete instances with estimations will be classified by the chosen classifier to obtain one or multiple classification results. Finally, the classification results with different weights (reliability) are submitted to an adaptive fusion system to obtain the final decision-making. For the instance that is difficult to be correctly classified into a specific class, it will be submitted to a corresponding meta-class in order to reduce the error rate. The classification of the uncertain instance in meta-class can be eventually identified using some other (costly) techniques or with extra information sources. So the proposed method avoids us to take erroneous fatal decision by carefully partitioning the classification result.
Adaptive imputation of incomplete instance
Let us consider a dataset with p-dimensional features including the training set Y = {
So, one can get different Shannon entropy of different features by Eq. (6), and Shannon entropy is a measure of uncertainty, so a small value of entropy means that the uncertainty is small and the corresponding amount of information is large. The weight of feature for test set can be obtained by Shannon entropy, denoted as follows:
After obtaining different weights of different features of instances, one can calculate the distance between the observed features of
Thus, one can obtain the KNNs of incomplete instance
The aforementioned K-nearest centroid neighbor imputation (KNCNI) method can be performed in four steps:
a) The KNCN set is found in each class according to the observed features, denoted as
b) Calculate the distance between incomplete instance
c) Calculate the weight factor
d) Estimate the missing values
where
Therefore, we find KNCN set in the first and second classes depending on the corresponding observed features, and then, estimate the missing value of
By doing this, one can get estimations for each incomplete instance in test set X, and complete estimated instances will be classified by standard classifier and submitted to the fusion method to determine the final class in the next part.
After obtaining each instance with estimation from Part 3.1, the instance in the test set X can obtain single or multiple classification results with different weights (reliability) using the basic classifiers, and the single or multiple pieces of classification results for
Then, the well known discounted rule introduced by Shafer in [19] is employed here, more precisely, discounted masses of belief are obtained as follows:
As we all know, DS rule has better convergence in the low conflict sources of evidence, which is helpful for decision makers to make correct judgment in time. In the high conflict sources of evidence, however, if the DS rule is directly used to fuse these mass functions, all the conflicting beliefs are proportionally redistributed back to the focal elements, so that most of the instances that are difficult to accurately classify will be misclassified. As the derivative of DS rule, Dubois-Prade (DP) rule can avoid unreasonable phenomena by increasing the uncertainty of fusion results when the high conflict sources of evidence. Whereas all conflict beliefs will be simply preserved and assigned to the meta-class if DP rule is directly employed to fuse. This will cause to a large number of instances are submitted to meta-classes, so that the result of credal classification will be very unclear, which is not an effective classification method.
Based on the above analysis, combined with the characteristics of DS rule and DP rule, we design an adaptive dynamic fusion method, which can select the conflict information conditionally and submit to the corresponding meta-class. When multiple sources of evidence are fused, it can not only avoid the unreasonable fusion results of high conflict sources of evidence, but also ensure the fast convergence of fusion result.
In the proposed method, we can use Eq. (3) to calculate the contradiction factor
In the proposed method, for the instance
For the convenience of implementation, the proposed method is outlined in Table 1.
Evidential classification of incomplete instance
In this section, two particular artificial datasets and nine well-known datasets from UCI
2
machine learning repository to test and demonstrate the effectiveness of the proposed method with respect to mean imputation (MI) [7], K-nearest neighbor imputation (KNNI) [8], Fuzzy c-means imputation (FCMI) [10], Local linear approximate (LLA) [13] and Fuzzy c-means centroid based imputation (FCMCI) [15] methods. For convenience, we denote ωj,...,k ≜ {ω
j
, . . . , ω
k
},
In this paper, the Support Vector Machine (SVM) [35], K-Nearest Neighbor (K-NN) [36], Evidence K-Nearest Neighbor (EK-NN) [37], Adaboost [41] and Decision Tree (DT) [42] classifier are employed as basic classifiers, respectively. K = 11 is the default in KNNs, K-NN and EK-NN. In the proposed method, the meta-class parameter ɛ is optimized by grid search using training instances. Generally, a better optimized value corresponds to the acceptable imprecision rate. In the proposed method, the class of each instance is decided by the maximum mass of belief. Thereby, the classification results include singleton classes and meta-class. To fully evaluate the performance of the proposed method, the error rate (Re) (respectively, imprecision rate (Ri)) (In %) [23], Precision (P), Recall (R), F-Measure (FM) [43] and Rand Index (RI) [44] will be used as indexes
3
. These indexes can be defined as:
where Ne (respectively, Ni) is number of instances submitted to error classes (respectively, meta-classes), and N is the number of instances under test. A (respectively, B) denotes the number of instance pairs that are simultaneously submitted to the same classes (respectively, different classes) by the ground truth and classification results. C (respectively, D) denotes the number of dissimilar (respectively, similar) instance pairs that are submitted to the same classes (respectively, different classes). Note that a smaller value of Re corresponds to the better classification performance, whereas the larger values of P, R, FM, and RI correspond to the better classification performance.
Experiment 1
Classification results on square data set via different methods: (a) Training and test instances. (b) Classification result via MI (Re = 32.56). (c) Classification result via KNNI (Re = 18.00). (d) Classification result via FCMI (Re = 16.44). (e) Classification result via LLA (Re = 21.33). (f) Classification result via FCMCI (Re = 16.33). (g) Classification result via proposed method with ɛ = 0.1 (Re = 0.44, Ri = 32.89). (h) Classification result via proposed method with ɛ = 0.15 (Re = 1.89, Ri = 29.11). (i) Classification result via proposed method with ɛ = 0.2 (Re = 4.56, Ri = 22.78).
We assume that the values in the first feature (i.e., x-axis) of test instances are all missing, the classification of test instances only depends on values in the second feature (i.e., y-axis). Here, SVM is employed to classified test instances. In the proposed method, three different meta-class thresholds ɛ = 0.1, ɛ = 0.15 and ɛ = 0.2 are selected to test their effects on classification results. The classification results of different methods are shown in Fig. 1(b)-(i).
As can be see from Fig. 1(a), in the case of the missing of feature values in the x-axis, there are local overlaps in the edges of classes ω1 and ω2, ω2 and ω3 only according to the feature values of the y-axis, and the instances of these overlapping zones are difficult to be submitted to a specific class accurately. Whereas MI, KNNI, FCMI, LLA and FCMCI provide only one estimation for missing values. The classification results submit all instances to a singleton class, which leads to a more misclassification rate for the instances in the overlapping zones. With the proposed method, most instances of overlapping zones are submitted to the corresponding meta-classes ω1,2 and ω2,3, which characterize the uncertainty and imprecision of classification caused by missing values. In the proposed method, taking ɛ from ɛ = 0.1 to ɛ = 0.2 as shown in Fig. 1(g)-(i), the degree of imprecision will be reduced but the classification error rate will increase. In applications, the meta-class parameter ɛ should be tuned depending on the imprecision rate the user can accept in the classification.
In this experiment, we consider a 3-class parabolic dataset as shown in Fig. 2 with 300 training instances and test instances of each class. K-NN is employed to evaluate the proposed method with respect to KNNI, FCMI, LLA and FCMCI. In the proposed method, the meta-class threshold is ɛ = 0.15. Let assume that the values in the second feature (i.e., y-axis) of test instances are missing, and test instances only one value in the first feature (i.e., x-axis). The error rate Re and imprecision rate Ri (for the proposed method) of these methods are given in the caption of each subfigure.
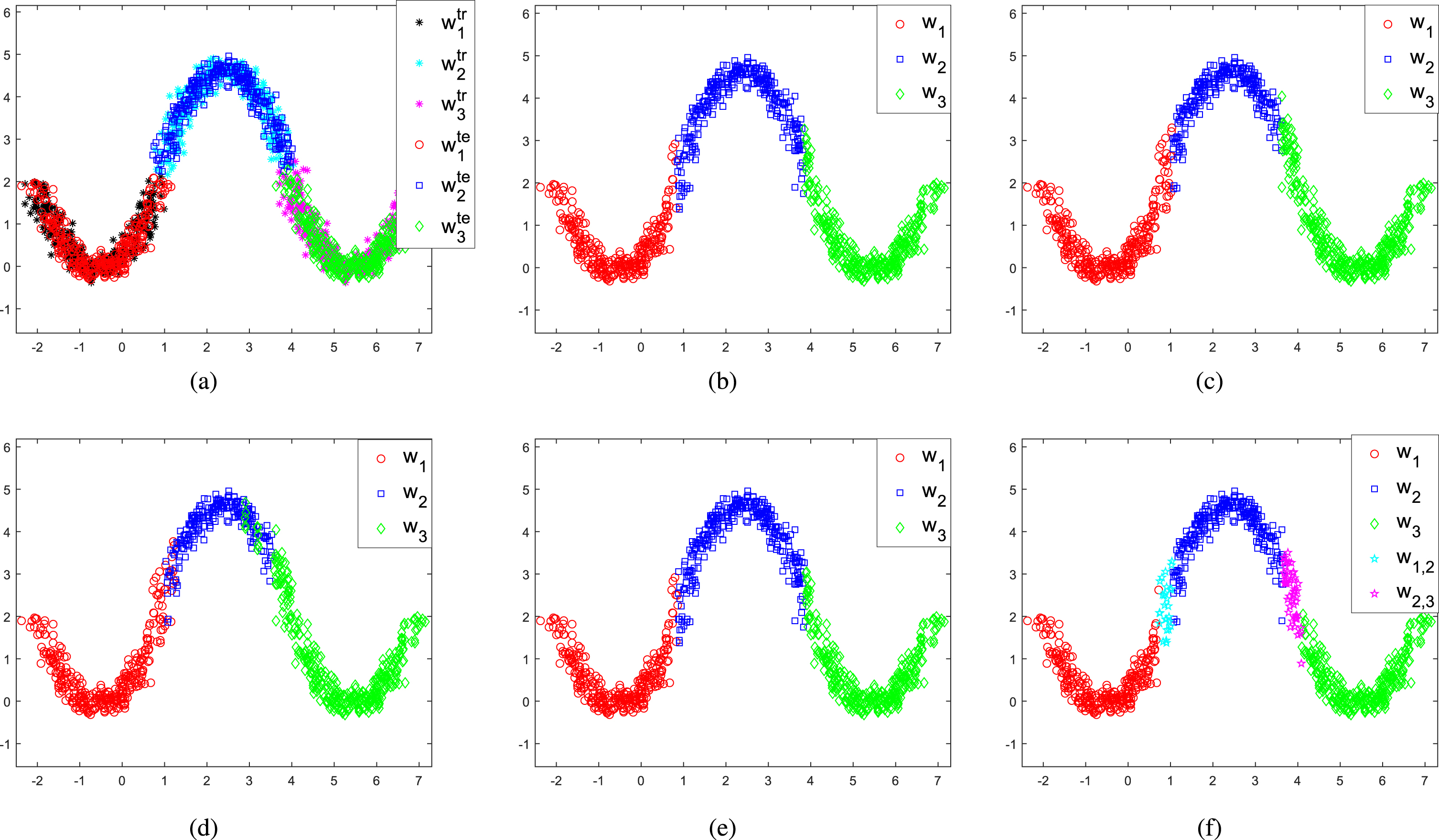
Classification results on parabolic data set via different methods: (a) Training and test instances. (b) Classification result via KNNI (Re = 3.70). (c) Classification result via FCMI (Re = 6.50). (d) Classification result via LLA (Re = 9.07). (e) Classification result via FCMCI (Re = 3.92). (f) Classification result via proposed method (Re = 0.56, Ri = 8.40).
In Fig. 2(a), one can clearly see that different classes overlap in the edge zone. Due to the missing y-axis, only according to the x-axis classes ω1 and ω2 (respectively, ω2 and ω3) overlap in the interval [0.5, 1.5] (respectively, [3.5, 4.5]), and the instances in the overlapping zone are difficult to distinguish for a specific class.
In Fig. 2(b)-(e), KNNI, FCMI, LLA and FCMCI submit instances to a singleton class without considering meta-class in framework of probabilistic, which leads to relatively high error rate. Whereas the proposed method can cautiously submit the instances of overlapping zones to appropriate meta-classes under the framework of evidence theory, thereby the error rate of classification result is greatly reduced but with some imprecision rates, which can well interpret the uncertainty caused by insufficient feature information of the instances.
Nine real datasets have been used to test and evaluate the performance of the proposed method with other methods, K-NN is still selected as standard classifier. The basic knowledge of the used real datasets including number of classes, features and instances, are shown in Table 2.
Basic information of the used datasets
Basic information of the used datasets
Each dataset is randomly divided into half training set and half test set. For the test set, MACR mechanism is used to simulate missing values, which τ feature values are missing in each test instance. The average error rate Re and imprecision rate Ri (for the proposed method) of different methods are reported in Table 3.
Classification results of different methods (In %)
The result of Table 3 clearly shows that the proposed method generally produces lower error rate than MI, KNNI, FCMI, LLA and FCMCI methods under different missing features. One can find that the proposed method introduces meta-class in the framework of evidence theory to characterize the uncertainty caused by missing values has been submitted to the appropriate meta-classes for instances that are difficult to classify into specific classes. Note that the increase of the number of missing values (i.e., τ) in test instances results in the increase of error rate and imprecision degree of the proposed method, since the more missing values, the greater the uncertainty of classification.
Figure 3 shows the influence of different K values in K-NN on different methods classification results. The x-axis corresponds to the K value, ranging from 7 to 17, and the y-axis corresponds to the average classification results (including error rate and imprecision rate), which is expressed in [0, 1]. Among them, the nine data sets shown in Fig. 3 are randomly missing different dimensions. One can observe that the error rate of the proposed method is much lower than other methods. The classification results associated with different K values have little change in the proposed method, which further shows that the classification performance is insensitive to the setting of K value. This also explains that the proposed method has strong robustness to the selection of K value, so one can take K from 7 to 17 in practical applications.

Classification results on UCI data set via different K values.
To further analyze the performance of the proposed method, Fig. 4 displays the mean values of P, R, FM, and RI of the proposed method with respect to KNNI, LLA and FCMCI. Here, we use pignistic transformation to make credal partition generated by the proposed method into crisp partition. Figure 4(a)–(c) shows the P values obtained by the proposed vs. those obtained by KNNI, LLA and FCMCI. One can fins that the proposed method outperforms other methods on nine real-world data sets. Similarly, Fig. 4(d)–(f) and (g)–(i) display the R and FM values of the proposed method with others, it can be seen that the proposed method is better than that of KNNI, LLA and FCMCI. Finally, we can be seen from Fig. 4(j)–(l) that the RI values of the proposed method outperforms KNNI, LLA and FCMCI in most cases.

The mean P, R, FM, and RI values via different methods: (a), (b), (c) P via Proposed method vs. P via KNNI, LLA, FCMCI. (d), (e), (f) R via Proposed method vs. R via KNNI, LLA, FCMCI. (g), (h), (i) FM via Proposed method vs. FM via KNNI, LLA, FCMCI. (j), (k), (l) RI via Proposed method vs. RI via KNNI, LLA, FCMCI.
In this experiment, we also use the nine real data sets to test the performance of the proposed method with respect to other methods. EK-NN, Adaboost, DT are selected here as basic classifiers. The average error rate Re and imprecision rate Ri (for the proposed method) of the different classical method with different basic classifiers (i.e., EK-NN, Adaboost, DT), are given in Table 4.
Classification results of different classifiers (In %)
Classification results of different classifiers (In %)
In Table 4, one can see that error rates of the proposed method with EK-NN, Adaboost and DT are smaller than the other applied methods. Meanwhile, some incomplete instances that are very difficult to classify into a specific class have been submitted to the meta-classes. So the proposed method including meta-class is very useful and efficient here to characterize the imprecision caused by missing values and it can help to reduce the classification error rate. We can also see that the proposed method has good adaptability in three basic classifiers: EK-NN, Adaboost and DT, which is undeniable. That is, the proposed method has good robustness and can be applied to various basic classifiers. However, we find that the DT classifier will consume less time than EK-NN and Adaboost in the case of large amount of instances, since EK-NN and Adaboos method will bring heavy computational burden in this case.
Figure 5 displays the error rates of various methods with different classifiers (i.e., EK-NN, Adaboost, DT) in the case of hard partitioning, where the x-axis denotes different classifiers, and the y-axis represents the error rate. One can intuitively find that the proposed method has better classification performance than other methods in most cases.
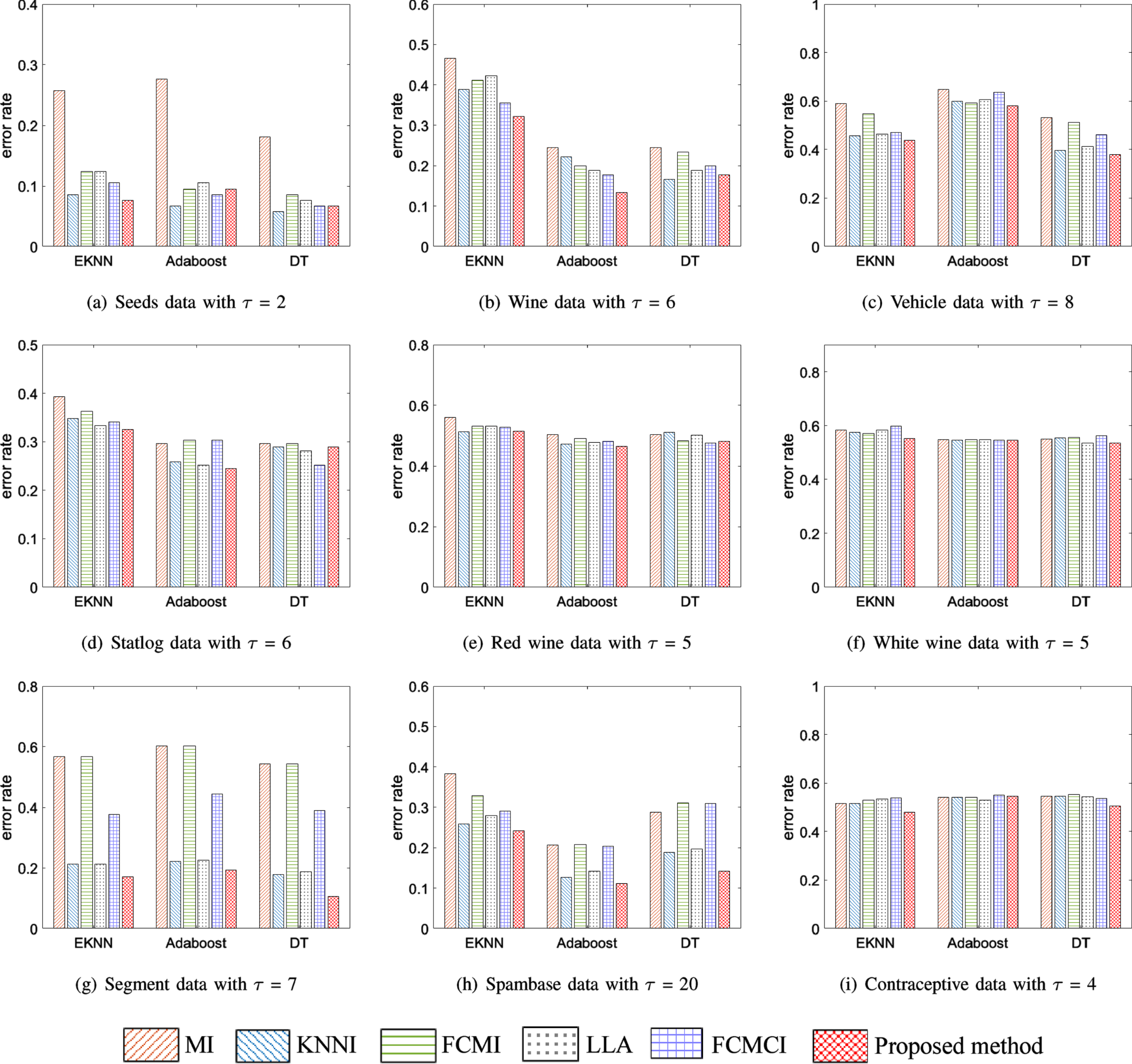
Classification error rates on UCI data set via different classifiers.
A new method is proposed to classify incomplete instance thanks to the evidence theory, which can effectively solve the classification problem of missing values. In the proposed method, we first propose a new K-nearest centroid neighborhood imputation (KNCNI) method, which considers the weights of different features. For query (incomplete) instances, a more strict imputation strategy based on Shannon entropy and KNCNs is proposed to adaptively estimate the missing values. Then, we select a standard classifier to process the complete instances, and use the labeled instances in the training set to estimate and classify each instance. Finally, an adaptive method is designed according to the distance between the discount factor and the final decision. In this way, patterns that are difficult to be correctly classified into specific classes will be automatically submitted to reasonable meta-classes, thus effectively reducing the error rate and revealing the imprecision and uncertainty of classification. Four experiments with artificial and real datasets have been done to evaluate the performances of proposed method with respect to other classical and state-of-the-art methods. The results show that the proposed method is able to reduce misclassification rates, and well capture and represent the imprecision of classification caused by missing values. In future, we intend to extend this method to the classification of incomplete multi-view data, which is worthy of further study.
Footnotes
Acknowledgments
This work has been partially supported by the National Key Research and Development Program of China (2019YFC1907105), the Key Research and Development Project of Shaanxi Province (No. 2020GY-186, No. 2020SF-367).
In practical application, if there are incomplete instances in the training set, complete instances of the same class can be used to estimate the missing values. In this paper, we focus on the classification of incomplete instance in the test set, so we assume that the training set is complete.