
Abstract
In the software development process, many developers learn from code snippets in the open-source community to implement specific functions. However, few people think about whether these code have vulnerabilities, which provides channels for developing unsafe programs. To this end, this paper constructs a source code snippets vulnerability mining system named PyVul based on deep learning to automatically detect the security of code snippets in the open source community. PyVul builds abstract syntax tree (AST) for the source code to extract its code feature, and then introduces the bidirectional long-term short-term memory (BiLSTM) neural network algorithm to detect vulnerability codes. If it is vulnerable code, the further constructed a multi-classification model could analyze the context discussion contents in associated threads, to classify the code vulnerability type based the content description. Compared with traditional detection methods, this method can identify vulnerable code and classify vulnerability type. The accuracy of the proposed model can reach 85%. PyVul also found 138 vulnerable code snippets in the real public open-source community. In the future, it can be used in the open-source community for vulnerable code auditing to assist users in safe development.
Introduction
The rapid development of computer technology. On the one hand, it has accelerated the progress of human society, but it also brought many threats. Technology is always a double-edged sword. In recent years, hacker activities are getting more and more frequent. They use the program vulnerabilities to steal personal privacy and even launch attacks to endanger national security. As the foundation of computer systems, software programs have vulnerabilities that allow criminals to take advantage of them.
During the software life cycle, most of the bugs come from the development phase. During the software development process, developers will mostly find code through open-source communities, including StackOverflow and GitHub, but few people consider whether the code on it is safe or not. Suppose some hackers maliciously upload code or program with vulnerabilities, and developers do not carefully review and refer directly to their software. In that case, it is very likely to leave fatal vulnerabilities [1].
GitHub and StackOverflow [2] are the most popular open-source communication communities for software developments. GitHub is a hosting platform for open and private software projects, hosting many program source code. StackOverflow is an IT technology Q&A website. Developers can submit questions, browse questions, find relevant content, and so on for free. Until September 2018, StackOverflow had over 9,400,000 registered users and over 16,000,000 questions, with the most common topics being JavaScript, Java, PHP and Python. Many posts contain much vulnerable code, and research has found that StackOverflow copies the most code ever containing bugs [3], which seriously threatens the development of software programs. Python, one of the most global popular programming languages, ranks among the top three in all major programming charts, and has more than 1,440,000 communication topics on StackOveflow. Well-known Internet companies, including Google and Facebook, are using it. Python also has many vulnerabilities [4]. Rahman et al. [5] found 12 common types of vulnerabilities in Python, including Command Execution, HardCode, and SQL Injection.
There are many tools for vulnerability mining, such as Scan Dal [6], Hybri Droid [7] and PREfix [8]. They are mostly used to detect vulnerabilities in C language or Java, such as Fortify [9], which can detect vulnerabilities in many programming languages. There is also a certain amount of research on Python vulnerability mining. There are mainly the following methods.
We found that the code in some posts on StackOverflow contains vulnerabilities. Concurrently, in the context discussion contents of associated threads, many users discuss the details of the vulnerabilities, including the types of vulnerabilities and repair methods.
For this reason, the paper proposes a vulnerability mining system named PyVul for the source code snippets of the open-source community. The system consists of two parts, a vulnerability mining module for source code snippets and a vulnerability type classification module for context discussion contents in associated threads.
The specific contributions of this work are the following: The paper constructs a general code feature extraction method for open-source community. This method can effectively integrate unstructured code and extract code feature while retaining semantic and structural information. The paper introduces the BiLSTM algorithm to the vulnerability mining of Python code and achieves good results. The accuracy of the model can reach 85%. The paper combines the vulnerability mining of source code snippets with content mining for the first time, which realizes the vulnerability detection of code snippets and uses the OVO SVMs algorithm to identify its vulnerability types. The recognition accuracy can reach 90%.
The rest of the paper is organized as follows: Section 2 is a mathematically formalized problem definition. Section 3 details the implementation process of the PyVul system. Section 4 presents the experiments and analyses. Section 5 summarizes the conclusion and proposes future works.
Problem definition
Let P = {p1, p2 . . . , p n } be a set of post in open-source community, R (p i ) = {r1, r2 . . . , r n } represents the reply corresponding to the p i post. T (r i ) = {s i , w i } represents the source code and text content in each reply.
Our goal is to detect the security of the Python code snippet s i in the post, and determine the type of vulnerability if it is malicious code. The process is divided into two steps. The first step is vulnerability code detection. We define the problem as a binary classification problem. c indicates the label category, where c = 1 indicates that the code is a vulnerable code, and c = 0 indicates that it is a secure code. We train a model f (centerdot) to detect the label of a given code snippet s i , where f (s i ) =1 indicates that s i is a vulnerable code, and f (s i ) =0 indicates that s i is a secure code. The second step is the classification of vulnerability types. We define the problem as a multi-classification problem. c = {i1, i2, . . . i11} represents different types of vulnerabilities. We train a multi-classification model g (centerdot) to detect the corresponding post content w i . where g (w i ) = i n indicates that vulnerability type of s i is i n .
Methodology
In this section, the paper will introduce the source code snippets vulnerability mining system PyVul for the open-source community. The system is mainly composed of four modules. The high-level design of PyVul is illustrated in Fig. 1. Data Collection and Preprocess crawls posts content from the open-source community and cleans them, then uses the web tags to separate the source code and content in the post. Code Feature Extraction uses AST and data dependence to extract code feature. Vulnerability Code Detection uses code feature and BiLSTM algorithm to build a vulnerability classifier for code detection. If the code is benign, outputs the security code. Otherwise, further, analyzes the associated context. Vulnerability Type Classification extracts associated text feature and combine with the OVO SVMs algorithm to build a type classifier for vulnerability type classification. Finally, the system gives the vulnerability types of code snippet to complete vulnerability mining.

The framework of PyVul.
To collect data from the open-source community, a crawler has been designed and developed in this paper. In practical application, we found that different pages have different structures, so we adapted them. In the open-source community, user interaction is based on threads. Users create topic posts in the community, ask questions, and then other users reply. In data collection, crawling is also carried out according to the above organization, and all threads in the forum are obtained first. Then, according to the thread, collect all the reply information under it. For the next step of the better analysis, We use <code> </code > <p> </p > tags to separate the code and content from the post and store them.
The existing open-source community has some specific protection mechanisms. Users who do not login in can only view part of posts. At the same time, to prevent tracking analysis, many websites have some anti-crawler mechanisms. In order to evade these, the crawler adds the mechanisms of simulated login, random request header, and dynamic IP proxy pool.
To better carry out the next step of text analysis, we preprocess the data. Preprocessing includes five aspects: case conversion, word segmentation, stop word removal, punctuation removal, and lemmatization. First of all, all the data are converted to lowercase to keep the data format consistency. NLTK [17] is used to deal with word segmentation and stop words to ensure its accuracy. At the same time, remove the nontext data such as punctuation in the data. Finally, NLTK is used to restore word form to reduce the phenomenon of multiple words with one meaning and reduce text redundancy.
Code feature extraction
The source code crawled from the open-source community is more chaotic and has no uniform format. There may not be any semantic relationship between these code. If the unprocessed code is directly used in the machine learning model’s training, it may increase a lot of overhead. Therefore, we introduce AST technology to obtain intermediate structure to extract code feature. The specific steps are as follows:
Source code normalization
There are many comments in the source code extracted from the open-source community, these are not helpful for vulnerable code mining. Therefore, we use Python regular expressions to remove. Simultaneously, We found that the source code indentation in some posts is incorrect and cannot be analyzed. However, there may be some vulnerabilities in these codes, so it is necessary to format them. We use the Python code formatting tool: Autopep8 to solve this problem. Autopep8 formats Python program code according to the specification and eliminate errors caused by indentation. For code snippets that still cannot construct AST after normalization, such as command line and non-Python code. we remove it without analysis.
API / Library
API and Library refer to the module imported by the source code, which is reflected in the code as import and from . . . . . . import statements. In Python code, many library functions have some vulnerabilities [14]. When developers import these library functions, they may bring these vulnerabilities into their code. Therefore, it is essential to extract the library dependency from the code. Similarly, the order in which libraries are imported may be different. Therefore, we sort the libraries after extracting them to unify them and reduce the inaccuracy of the model caused by code style differences.
Data flow
Code feature extraction is a difficult problem in static analysis. At present, the mainstream and effective method is based on data flow [18]. In the analysis process, we found that the leading cause of source code vulnerability is that malicious parameters are not filtered and directly passed into dangerous functions. Through the data flow method, we can extract the parameters and functions that lead to code defects. Other code statements that are not related to the vulnerabilities, such as assignments and definitions, will be ignored. When extracting the code’s data flow, we mainly use AST [19] (abstract syntax trees). AST can parse program source code into a syntax tree, so developers can modify the syntax tree directly to change code. AST module provides the possibility for Python source code security check, program debugging, and syntax analysis.Data flow is the process of function parameter passing. Function parameters are passed to another variable through assignments and other operations, and so on, and finally output. Through data flow to find the input parameters path, then extract it and recombine a new function. Remove the lines of code without parameter conversion.When there are multiple input parameters in the function body, it may generate multiple data flows. To facilitate analysis, we merge the multiple data flows. In this paper, the AST module is used to construct the abstract syntax tree of the source code snippet. Considering the input as an origin point, tracking the variables and functions entered by the input parameters, and then extracting these parameters trajectory as the suspicious code.
Variable substitution
Since the source code in the post comes from different developers, there are big differences in code habits. If it is directly input into the neural network for training, there will be some errors. So in this step, some user-defined variables need to be replaced. The variables have two main parts. The first part of the variable is the function name: the user-defined function name in the extracted function body, such as getUsers. For the replacement of function names, use funcN (N = 0, 1, . . . n) to replace; the second part is the replacement of user-defined variables, such as user _ id, for the replacement of these variables use varN (N = 0, 1, . . . n) to replace. In this way, errors caused by differences in user code can be eliminated.
Code recombine
After extracting the import library and data dependent code and completing all variable replacement, the next step is recombining them. This paper uses a unified format to sort the dependencies at the source file’s head and then reorganize the code parts according to the original order. The purpose of this is to maintain the structural and semantic relationships between code contexts. As shown in Fig. 2, there is a comparison of source code snippet and code feature.
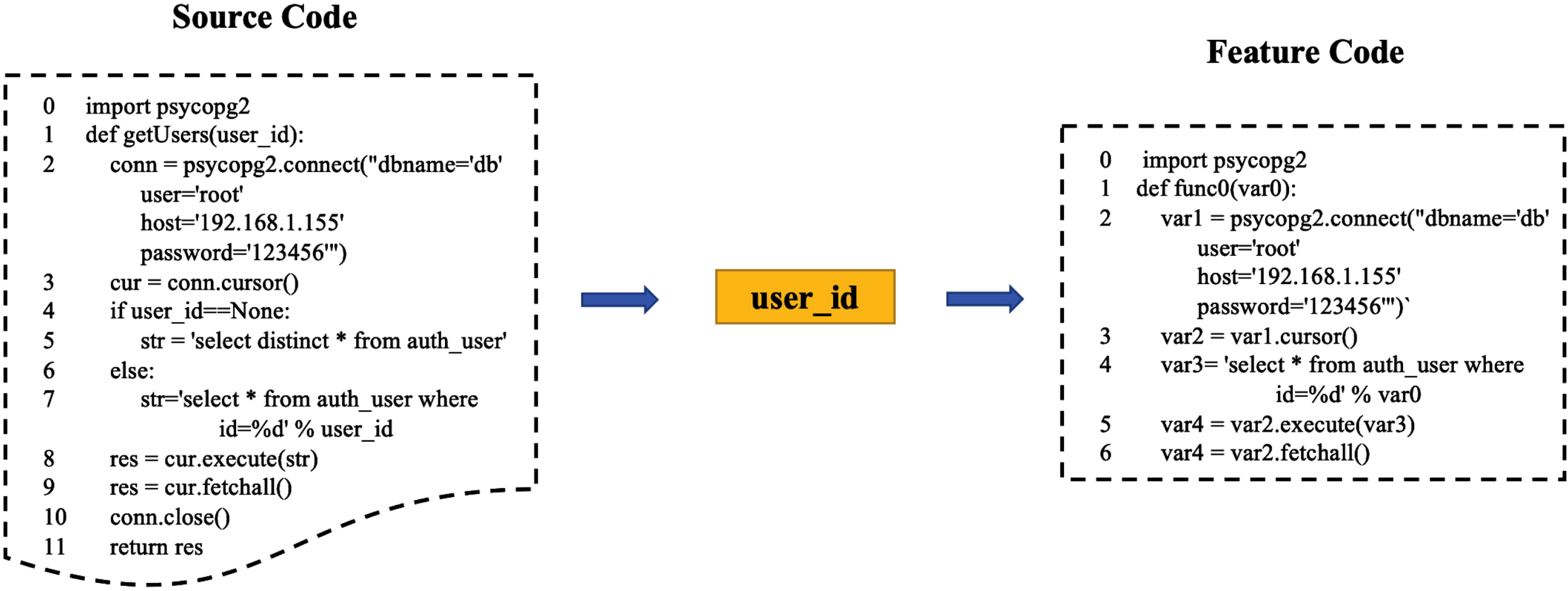
Comparison of source code snippet and code feature.
Data annotation
This paper first uses the tool to label once and then manually label and review some samples. We define two labels of source code: “1” (vulnerable code) and “0” (secure code). Here we use the Python code audit tool Bandit to complete automatic annotation. The Bandit [20] tool can find vulnerabilities in Python source code. During the detection process, Bandit parses the source code, generates its abstract syntax tree, and then performs security checks for the abstract syntax tree. After completing the AST scan, Bandit will directly generate code security reports for users. First of all, using Bandit to complete the first annotation will produce many positive samples and negative samples. In the actual labeling process, we found that the positive samples accounted for the majority, and the negative samples were few. For this reason, it is necessary to label the samples marked as “0” manually and then label them again to find some missing and unrecognized vulnerable code.
Source code vectorization
The input received by the neural network is vectorized data, which cannot directly train the source code. Therefore, it is necessary to vectorize the preprocessed code feature.
Because in vulnerable code, every character may have crucial semantic information. Therefore, we need to divide the source code snippet into tokens, including keywords, identifiers, operators, and symbols. For example, the source code for the symbolic representation is as follows:
Lexical analysis is expressed as tokens as follows:
In order to convert the above token into a vector, the Tokenizer method in Keras is used to vectorize it. We found that the average number of tokens in the training data is 107, and 93%of the data are less than 200 tokens. Therefore, we use 0 to fill in the data less than 200, and truncate the data more than 200.
The neural network is very successful in image processing, speech recognition, and natural language processing [21–23], which are different from vulnerability detection. This means that many neural networks are not suitable for detecting vulnerabilities.
RNN [24] (Recurrent Neural Network) is one of the most commonly used models when using deep learning to deal with sequence problems. The current output of each sequence in the model is related to the previous output. RNN will take the t-1 time slice’s hidden node as the input of the current time slice at the time t. Then it is applied to the calculation of the current output, and the nodes between the hidden layers are no longer unconnected but connected. The output of the traditional model’s hidden nodes only depends on the input of the current time slice, so RNN has a better effect on sequence data processing. However, RNN can only memorize the last state information and cannot handle long-term dependent information well. Sundermeyer and others [25] proposed the LSTM for language modeling. LSTM (Long Short-Term Memory) is a variant of RNN. It adds a line to the RNN to express the long-term dependence of the input information. Therefore, LSTM has excellent advantages in modeling time sequence data.
The key of the LSTM model is to add the concept of “gate”. The gate structure contains a sigmoid function, which takes a value between 0 and 1, as shown in Formula 1. Any value multiplied by 0 is 0. In this way, the value is “forgotten”. Any number multiplied by 1 is the original value. Therefore, the value will be “kept”. Important information can be retained, and unimportant information can be forgotten through the gate.
However, LSTM model can only carry out forward calculation. Due to the particularity of Python source code, function definition can be pre or post set, so it is necessary to calculate backward propagation. BiLSTM [26] (Bi-directional Long Short-Term Memory) is a combination of forward LSTM and backward LSTM. BiLSTM can learn the characteristics of serialization and long-term dependency and capture the implicit dependency between sequences.
As shown in Fig. 3, in the Forward layer, the forward calculation is performed from time 1 to time t, and the output of the forward hidden layer at each time is obtained and saved. In the Backward layer, the backward calculation is performed from time t to time 1, and the output of the backward hidden layer at each time is obtained and saved. Finally, combine the Forward layer and the Backward layer’s output results at the corresponding time to get the final output. The mathematical expression is as follows:

BiLSTM structure diagram.
In the paper, our model network structure includes the embedding of the Token sequence, the BiLSTM layer, and then use the Dropout layer to randomly disconnect some neurons to prevent overfitting, and the Dense layer to match the previous layer The neural network is fully connected to achieve the nonlinear combination of features, and then the BatchNormalization layer is added to solve the problem of gradient disappearance and explosion. Next, the Relu function is used to activate the neurons, and after the Drop, Dense and BatchNormalization layers are passed again, since vulnerability detection is essentially a binary classification problem, we use the Sigmoid function for activation output, aiming to realize the detection of vulnerabilities.
In source code snippets vulnerabilities mining, we identify whether the code snippet is safe, but we cannot judge the vulnerability type. It is also essential to judge the types of code vulnerabilities. It is helpful to patch the vulnerability further.
In this part, we first preprocess the text of all the posts collected, then extract the text feature to feature representation, and finally use the OVO SVMs algorithm to analyze each post to get its related vulnerability type [27], and then associate the vulnerable code involved in the post with the vulnerability type extracted from the text, so as to obtain the vulnerable code and its vulnerability type.
Text preprocess
Text data can not be directly used for OVO SVMs model training, so it is necessary to extract text feature. At present, when extracting text feature, the commonly used method is to set the feature threshold according to the feature vector of words in the text, select the best feature as the text feature subset, and establish the text feature model.
There are many methods for extracting text feature, and word frequency weight is still the most effective method. There are generally many useless words and symbols in text data. Therefore, it is necessary to preprocess the text, including case conversion, removal of non-ASCII codes, word segmentation, removal of stop words, removal of punctuation, stemming, and Lemmatisation. Then count the word frequency to calculate its weight and sort from the largest to the smallest. Sort out a new sequence, and then extract the first N words with the highest weight.
In summary, the extraction steps of text feature are as follows: First, we need to preprocess the text data to remove irrelevant content. Calculate and sort all the words and their frequency in each category document, and then filter and delete the useless words. Calculate the word frequency of the words in each category and use the previous N words with the highest frequency as the category’s feature word set. Merge the feature word sets of all categories and delete the duplicate words from them. The final word set is the feature set to be used later, and then select the feature used in the test set.
Feature extraction and representation
TF-IDF [28] (term frequency-reverse document frequency) is a statistical method to evaluate the importance of words in document sets or corpus documents. If a word appears in the corpus with very low frequency, but it appears in the document frequency is very high, it indicates that the word is essential for the document, has a strong distinction, and can be used for classification. On the contrary, it indicates that the word is not highly differentiated and is not suitable for text classification. TF-IDF algorithm is used to express text feature. The formula is as follows:
It can be seen from the above formula that the higher the frequency of words, the lower the discrimination. On the contrary, the lower the frequency, the greater the discrimination and the weight. Therefore, we need to select words with high discrimination to better the classification effect in selecting text feature.
The primary purpose of normalization is to prevent the model from being biased into files, resulting in model errors. The formula is as follows:
In the formula, a is the word frequency of the keyword, min is the minimum word frequency of the word in all texts, and max is the maximum word frequency. This step is standardization. When comparing word frequency, there may be a big deviation. Normalization can make the classification of text data more accurate.
SVM [29] algorithm has exceptional advantages in text classification. It maps data to high-dimensional feature space through nonlinear transformation and classifies data in high-dimensional space with linear discriminant function, avoiding dimension disaster. The algorithm’s complexity is independent of sample dimension; Its mathematical form is simple, geometric interpretation is intuitive, less manual setting parameters, easy to understand, and use.
Because of the advantages of SVM in performance, SVM is widely used in text classification. In two classifications, the SVM algorithm tries to find a hyperplane to separate two categories. As shown in Fig. 4, red and blue dots represent different categories. A is the hyperplane where they are divided, and the dotted line points are support vectors.

Maximum interval classification diagram.
OVO(one-versus-one), referred to as 1-v-1 SVM [30], its core idea is to build multiple SVM classifiers, and any two samples build a classifier, then K (K - 1)/2 classifiers need to be designed for K categories. When the sample is predicted, each SVM classifier will give a score, and the highest one is the prediction category of the sample.
Datasets
Currently, there is no open dataset for Python malware detection. Therefore, in the experimental process, all the data are collected and constructed by ourselves. The data source of the paper was the StackOverflow open-source community. We collected data through the Security and Python keywords retrieval method and collected 30,924 topic posts and 51,436 replies. Simultaneously, in order to train the vulnerability detection model and the classification model of code vulnerability types, the data are filtered and labeled. There are 5,372 data and 11 categories in text data annotation. There are 5,000 training data labels in the code feature, including 2,300 vulnerable codes and 2,700 security codes.
Evaluation methods
Evaluation indicators are significant for machine learning evaluation. Different machine learning models generally need to build different evaluation systems, and the same model also has different evaluation indicators. Each indicator has a different focus, such as classification, regression, clustering, topic model, etc. At the same time, various indicators can be used for the comprehensive evaluation of different models. In this paper, the following indicators are used for evaluation.
True Positive: Positive samples predicted to be positive by the model.
True Negative: Negative samples predicted to be negative by the model.
False Positive: Negative samples predicted to be positive by the model.
False Negative: Positive samples predicted to be negative by the model.
To evaluate the vulnerability detection model, we conducted experiments using a Ubuntu server with a 4-core 3.6 GHz Intel Core i7-7700 processor, 6GB GeForce GTX 1060 graphics processing unit (GPU), and 16GB memory.
Python vulnerability type and description
Python vulnerability type and description
In the vulnerability detection model, to better analyze the model’s performance, we build the ROC curve and the curve of accuracy and loss rate. As shown in Fig. 5 is the ROC curve of the vulnerability code detection model. It can be found that the area under the curve reaches 0.9068, which proves that the model has good performance.
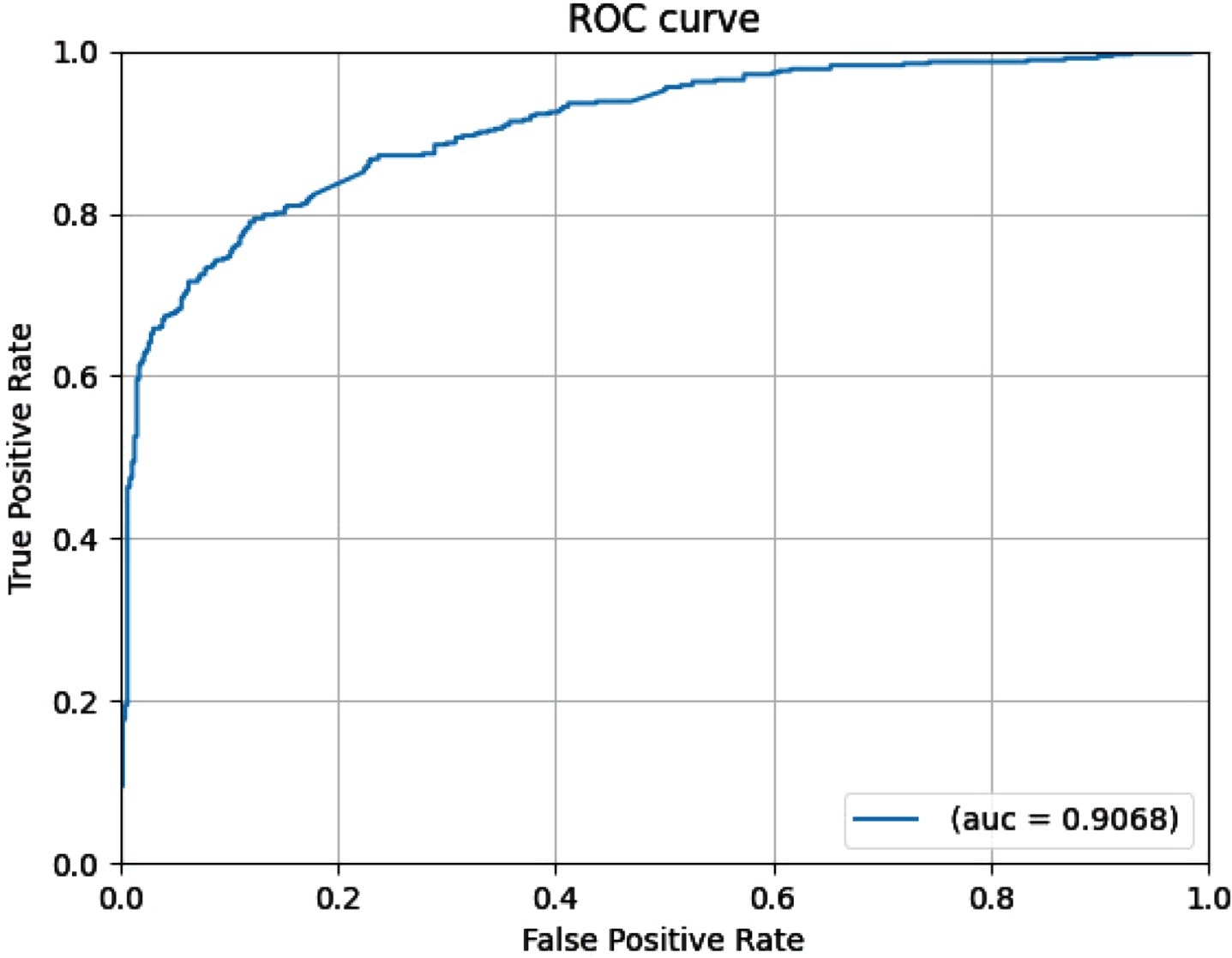
ROC curve of the vulnerability code detection model.
It can be seen from Fig. 6 that during the training process, the loss rate continues to drop, from 0.8 to the final 0.3, and the accuracy rate is also rising. Finally, the accuracy and loss rate on the validation set and training set tend to be consistent.
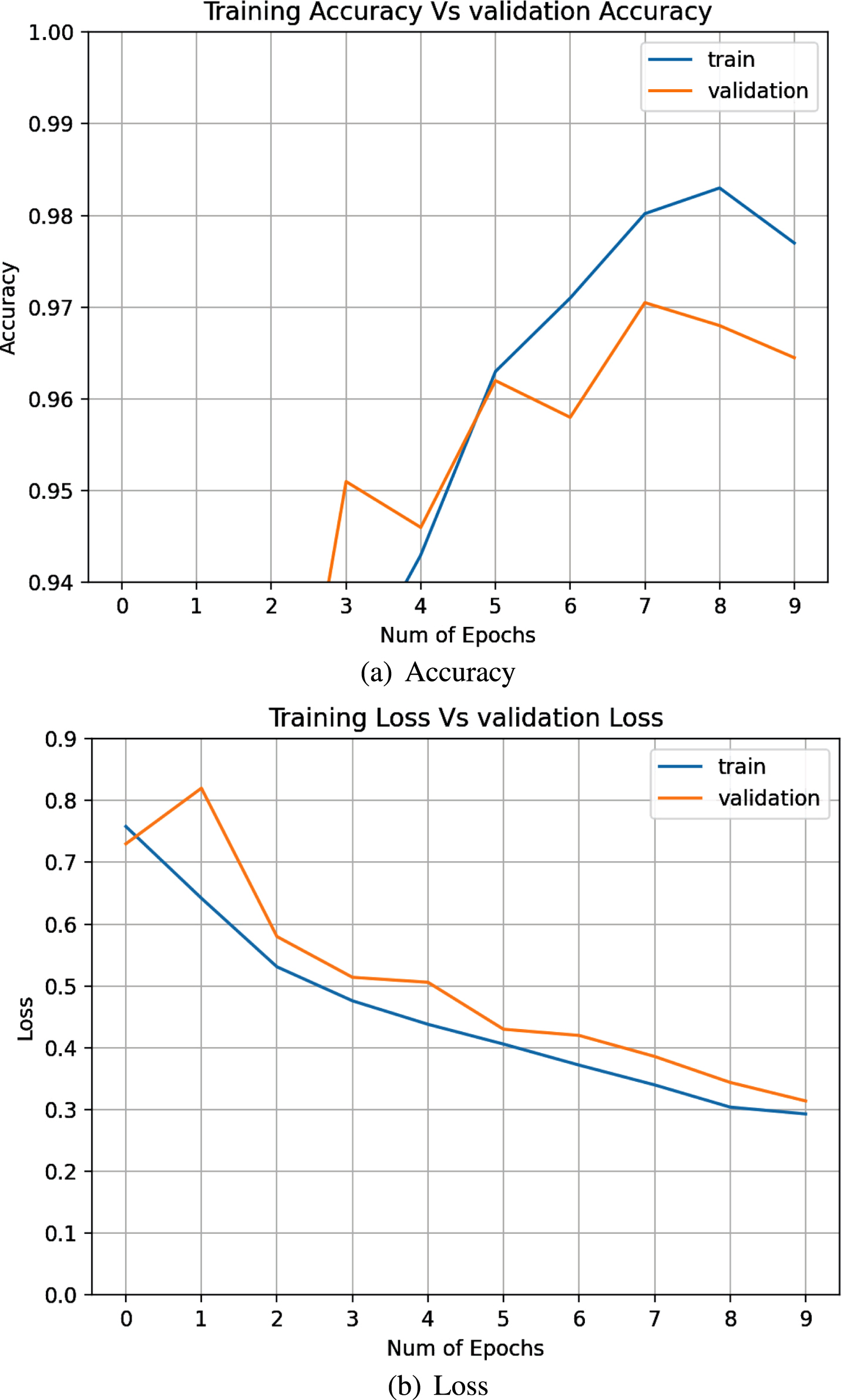
Accuracy and loss rate curve of the training set and validation set.
Because whether the code contains vulnerabilities may depend on the context, a neural network that can handle the context may be suitable for vulnerability detection. Many existing papers use RNN and LSTM algorithms for vulnerability detection [32–34]. The experimental results are shown in the Table 2, whether it is Precision, Recall, F1-Score, the BiLSTM algorithm results are optimal. Simultaneously, to verify the performance of the model, we carried out a ten-fold cross validation experiment. The average accuracy of the model was 84.35%. This shows that our model has good performance and strong generalization ability.
Experiment results of comparison algorithms
In the vulnerability type classification experiment, we compare the Random Forest algorithm with the OVO SVMs algorithm, as shown in Fig. 7 and Fig. 8, respectively, showing the confusion matrix of the two algorithms. The average accuracy of Random Forest is 87.5%, and the accuracy of OVO SVMs is 89.08%.

Confusion matrix of Random Forest algorithm.

Confusion matrix of OVO SVMs algorithm.
As can be seen from the figure, both algorithms can achieve good results in identifying vulnerability types. In the classification of XSS, CSRF, Command Execution, SQL injection, Deserialization, File Upload, Insecure Encryption, and Insecure Connection types, the two models can reach about 94%, in Directory Traversal and HardCode two types of classification. The OVO SVMs algorithm is better than the Random Forest algorithm.
To further analyze and compare the model’s recognition ability for different vulnerabilities, we made a histogram about the accuracy, recall, and F1-score indicators. It can be seen from Table 3 evaluation that the average accuracy of the model can reach about 89%. The classification accuracy of most vulnerability types is above 90%.
Vulnerability type classification model evaluation
In order to verify the actual effect of the model. We deploy the PyVul system to detect Python posts on StackOverflow in real-time. Not surprisingly, we found much vulnerable code. Table 4 shows some examples of vulnerable code that we found from StackOverflow. At the same time, these posts have a great impact. For example, the post with question_id 23739832 contains a command execution vulnerability code. The post has been viewed more than 1,000 times and has been widespread. The post with question_id 49308355 contains the vulnerability of too high file permissions. It has been read more than 8,000 and has been adopted. Meanwhile, we checked and found that these posts are not in our dataset.
Some unsafe posts detected by PyVul
It shows that our system has excellent accuracy and practical value.
This paper builds a vulnerability mining system named PyVul for the open-source community’s source code snippets. It includes a vulnerability mining model based on deep learning BiLSTM neural network and OVO SVMs algorithm. The open-source community’s source code is relatively complex, and many of them are not complete code. Therefore, the paper first construct a source code preprocessing framework and uses the method based on data flow to extract the code feature. Simultaneously, the differences of user-defined are eliminated based on ensuring the code structure and semantics remain unchanged. In vulnerability mining, A detection model based on the BiLSTM algorithm was constructed. Compared with RNN, this model can memorize more semantic information. Simultaneously, the paper construct a vulnerability type classification model based on the OVO SVMs algorithm for the context discussion contents in associated threads to determine the vulnerability type of the code snippets. In the experiment, we use ten-fold cross validation to find that the BiLSTM model and OVO SVM have significant advantages in vulnerability mining. At present, The PyVul can only detect whether the code contains vulnerabilities, but it can not locate the vulnerabilities. The main reason is that the granularity of the code is different. In the future, we will also make efforts to achieve locating vulnerabilities.
Acknowledgments
This research is funded by the National Natural Science Foundation of China (No. 61902265), National Key Research and Development Program of China (No. 2016QY13Z2302, No. 2018YFB0804103), Sichuan Science and Technology Program (No. 2020YFG0047) and Guangxi Key Laboratory of Cryptography and Information Security (No. GCIS201921).