
Abstract
Session-based recommendation is an overwhelming task owing to the inherent ambiguity in anonymous behaviors. Graph convolutional neural networks are receiving wide attention for session-based recommendation research for the sake of their ability to capture the complex transitions of interactions between sessions. Recent research on session-based recommendations mainly focuses on sequential patterns by utilizing graph neural networks. However, it is undeniable that proposed methods are still difficult to capture higher-order interactions between contextual interactions in the same session and has room for improvement. To solve it, we propose a new method based on graph attention mechanism and target oriented items to effectively propagate information, HOGAN for brevity. Higher-order graph attention networks are used to select the importance of different neighborhoods in the graph that consists of a sequence of user actions for recommendation applications. The complementarity between high-order networks is adopted to aggregate and propagate useful signals from the long distant neighbors to solve the long-range dependency capturing problem. Experimental results consistently display that HOGAN has a significantly improvement to 71.53% on precision for the Yoochoose1_64 dataset and enhances the property of the session-based recommendation task.
Introduction
Recommendation system has penetrated into every aspect of people’s lives to meet their demands. It aims to help users select fascinating information and meet the increasing demand for online shopping. Many recommendation models are based on explicit user profile information. In order to solve anonymous browsing problem, session-based recommendation comes into being and attracts more and more attention. Session-based recommendation is a real-time recommendation that can be generated in a session based on user anonymity and attempt to discover the information that fits their preferences. The session recommendation task is to predict the next behavior of the user according to the behavior sequence of the user in the current session, without relying on any user profile information.
There are a variety of studies on this research, such as content-based recommendation techniques, collaborative filtering-Based recommendation techniques [1], model-based techniques [2], hybrid recommendation techniques, and intelligence-based recommendation techniques [3]. Most of the existing models [4–6] are dynamically modeled based on social effects, which depend on the user’s friends. In numerous service, fashion interactions have a strong effect of time due to their fashionability, the users choose to browse anonymously and leave the logging session to be exploited [7], for example, in e-commerce, customers may give priority to choose their favorite items because of taking into account their recent demand [8]. Because the shopping behavior is a complex dynamic behavior and is affected by many factors that user profiles are invisible [9], it is a very challenging work to capture users’ dynamic preferences from interactions with interactions to accurately predict the preference.
To solve it, some session-based recommendations that adopt excellent sequence modeling techniques, such as Markov chains (MCs) [10, 11], recurrent neural networks (RNNs) [10, 12] and graph neural networks (GNNs) [7, 13], can be applied to discover the dynamic interests of the user. In the research of session-based recommendation [14], He et al. [15] constructed a new personalized order approach based on MCs to predict the L-th clicked item according to the previous L-1 interactions. At the same time, Wu et al. [16] modeled the session sequence as a graph sequence pattern and applied a gated unit to aggregate the features of the neighbors as the features of session [8]. Besides, Yuan et al. developed a parameter-efficient transfer learning to model user-item interaction sequences [17]. Most of these methods are expected to generate a reasonable transfer of interactions and express the effects of users’ interest. However, for effective modeling with a long-distance click, it is difficult for the model to find new and effective transfer information, which leads to the limitation of most modeling ideas in the sequence.
Though these methods are advanced and achieve satisfactory results, these methods mainly rely on aggregate the first-order neighborhood representation to update node representation, and they are not enough to analyze transitions of interactions between sessions simply by using the first-order neighborhood information. The main reason is the lack of higher-order interactions between interactions. Therefore, there are still some issues that can be researched in detail. Firstly, the Markov chain based model [11, 18] is a traditional research method to the top-n sequential recommendation, in which an n-order behavior is based on the n-1 previous behaviors in the sequence [5]. Secondly, recommendation systems built on historical behavior have often frequently recommended similar interactions and the scale of interactions between users and interactions easily up to millions or even larger. Furthermore, we look forward to finding interactions which are correlated to the requirement instead of finding only similar interactions in real applications. Thirdly, the existing session-based methods combine the context relationship of interactions with the attention mechanism to generate the unified interest representation without considering the high-order connected relations. In this work, we mainly concentrate on exploiting the expression modeling of high-order connectivity from item relationships in graph networks and effectively discover the latent transfer relationship between interactions.
To deal with the challenge, we propose a novel high-order graph attention-aware framework 1 for session-based recommendation. We simply illustrate an overview of our model. Firstly, we formulate the main research problems based on session recommendations. Secondly, we design a high-order graph attention aware network to select relatively important interactions and allow nodes to be selectively embedded and adaptively aggregated, but also allow the adjacent embedding nodes to be aggregated with the weighted average. Thirdly, the core idea of our mechanisms inspired by the higher-order connections method is to utilize high-hop networks to aggregate and propagate useful signals from the long distant neighbors. The graph embedding layers are used as an embedded representation of all the nodes involved in each graph. Although the neural networks of each node are different, they share the same set of parameters. Lastly, we use a similarity function to measure the similarity between the current session feature and each candidate feature. Compare to the previous methods [16], we further enlarge the attention schemes and the higher-order connectivity information to graph neural networks. Extensive experiments on four benchmarks consistently display that the presented method markedly enhances the performance of the session-based recommendation task.
All in all, the main points of this research are organized as follows. To effectively propagate information, the attention-aware mechanism is adopted to measure the correlativity of each item in interactions and capture the importance of each item within session. Our model used the high-order attention method to discover the effect of interactions within the session, which gives priority to the entire feature with due consideration to the dependence of separated session sequence and have a obvious improvement for the recommendation performance in recommendation task. For solve the long-range dependency capturing problem, the higher-order connectivity mechanism is adopted to the network, which is able to learn feature-based node assignments in each layer. We take the high-order connectivity network to aggregate and propagate useful signals from the long distant neighbors. By combining the high-order connected relations and high-order attention mechanisms, we design a GNN model that can effectively discover the shifting relationship between interactions and outperforms the existing methods in four public datasets.
Related work
Session-based recommendation has become an hot research topic in many e-commerce applications, it tends to utilize all historical user-item interactions to learn each user’s long-term and static preferences on items [19]. There are extensive advanced works to research session-based recommendation. In this part, we review some literatures on session-based recommendation and attention mechanisms. The literatures of this paper is organized as follows.
Session-based recommendation
Session-based recommendation is uncertain about the user’s information and can quickly generate personal service information for sites that cannot record the user’s browsing behavior. At present, the session recommendation task has been widely used in many fields, Several studies have gone deeply into the recommendation algorithms, Wang et al. [11] proposed a self-attention method to model sequential relationship that makes possible to discover long-term dependence. Cao et al. [9] took full advantage of the location information and contextual relation in the sequence to model location-aware to enhance recommendation performance. Liu et al. [20] made full use of the long tail effect which improves the diversity of commodity recommendation and produces serendipity. Sheu et al. [21] considered the semantic features and interactive conversational features of news, and proposed a context-aware graph embedding framework to improve the recommendation performance. Jin et al. [22] proposed a multi-behavior model which constructs a unified graph, which is used to represent a variety of behavioral data, which can solve the problem of data scarcity or cold start. Considering that the longer-term preference of a user can improve the recommendations in the current. Beutel et al. [23] came up with an RNN-based method that incorporates auxiliary context information. These positive observations usually exist in the sequential data that express the shifts of interest. These existing methods adopt data enhancement to train data, so as to improve the performance of the model. Yuan et al. [24] combined Sparse kernels and gage-filling for future data interaction to improve the recommendation accuracy.
Attention mechanisms
Session-based recommendation provides users with the suitable items or personalized service by predicting a user’s interest based on related information about the interactions between items and users, while the user facing the increasing online information explosion problem [1]. Recently, with the rapid development of deep learning technology, attention mechanisms are receiving wide attention as one of the most common deep learning measures, and have shown significant improvement in recommendation system [9]. The advantage of attention mechanisms is that they selectively assign weights to different neighboring nodes according to the importance of different neighborhoods. Quadrana et al. [25] proposed a high-order session-RNN method to model a user’s interests within a session. Later, Li et al. [26] adopted the multi-channel model to construct the transfer relationship between neighbor interactions and target interactions. Li et al. [8] the weighted attention and graph models are used to combine to mine the interest transfer relationship between the users. Most existing sequential recommendation models [4] utilize the self-attention mechanism to capture distant item-to-item transitions in a sequence and have achieved expected performance [27]. Pan et al. [28] take into account the importance of different interactions to integrate the unified vector by the SRIEM model that predicts users’ interest. Lv et al. [29] utilized a multi-head attention mechanism to discover users’ various interests, and fused long-term interests and current interests through gate mechanism to generate a unified expression for users’ interest in dynamic changes. In this work, we exploited high-order attention-aware networks to capture different interactions attention, and present a high-order graph attention-aware neural network for the session-based recommendation. However, in some application domains [30], it seems that it does not generate better recommendations by using repeated item sequence. Compared to previous work, we adopt a session-based graph pooling method, which allows nodes to select the most relevant higher-order information to better aggregate the features of neighborhoods.
Proposed method
In this part, we put forward high-order graph attention-aware networks to solve the session-based recommendation problem with the attention scheme and higher-order connections scheme as Fig. 2. This model consists of four parts, including items embedding, session graph encoder, high-order connection networks and session graph decoder. Firstly, all interactions are embedded by means of embedding layers in the session. The graph high-order connectivity layers can aggregate and propagate useful signals from the long distant neighbors. Secondly, in attention-aware layers, the attention is adopted to learn the different representations of the interactions. Finally, we calculate the relevance score for candidate items in the candidate list.
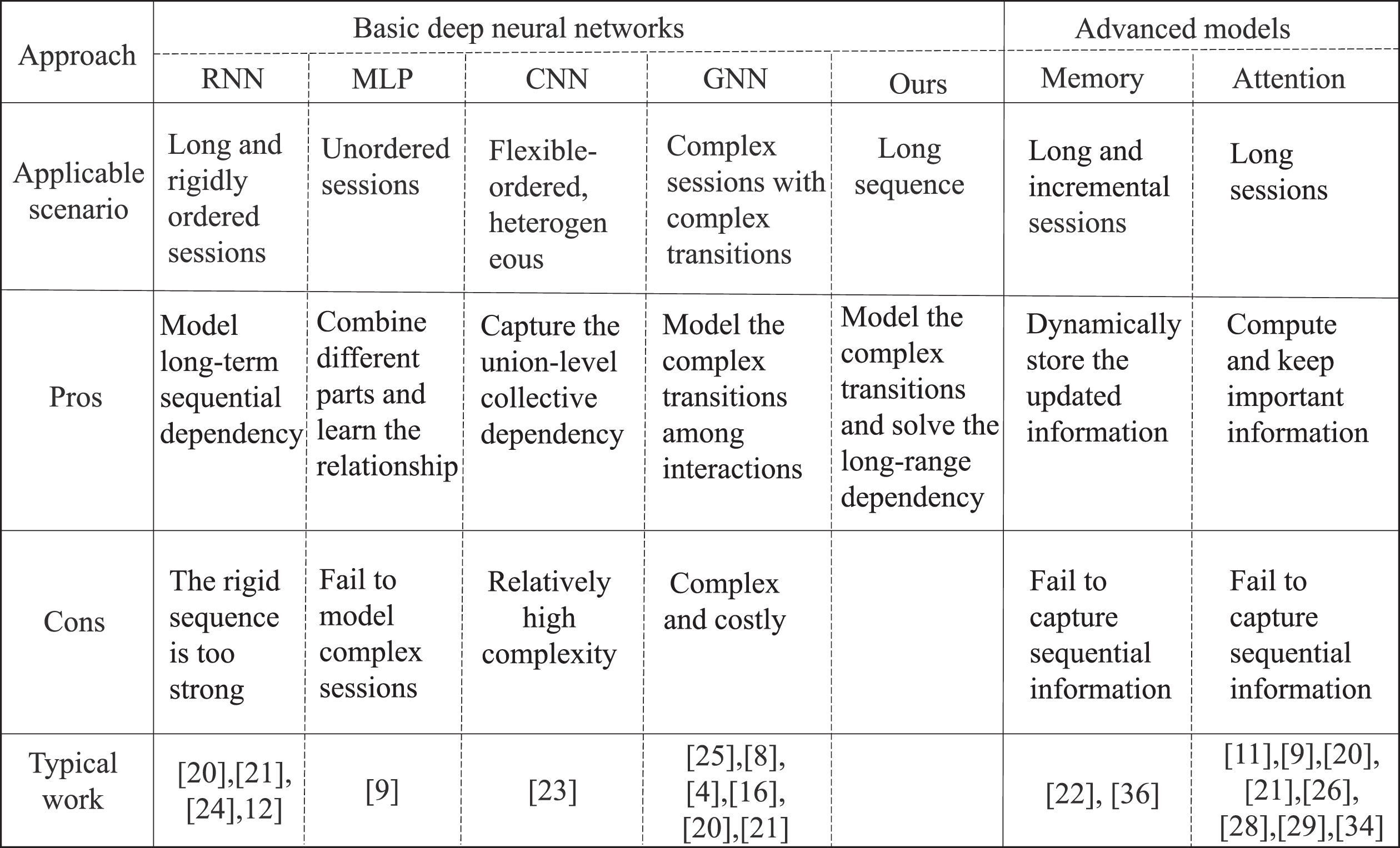
An comparison of our method and other methods in related work.
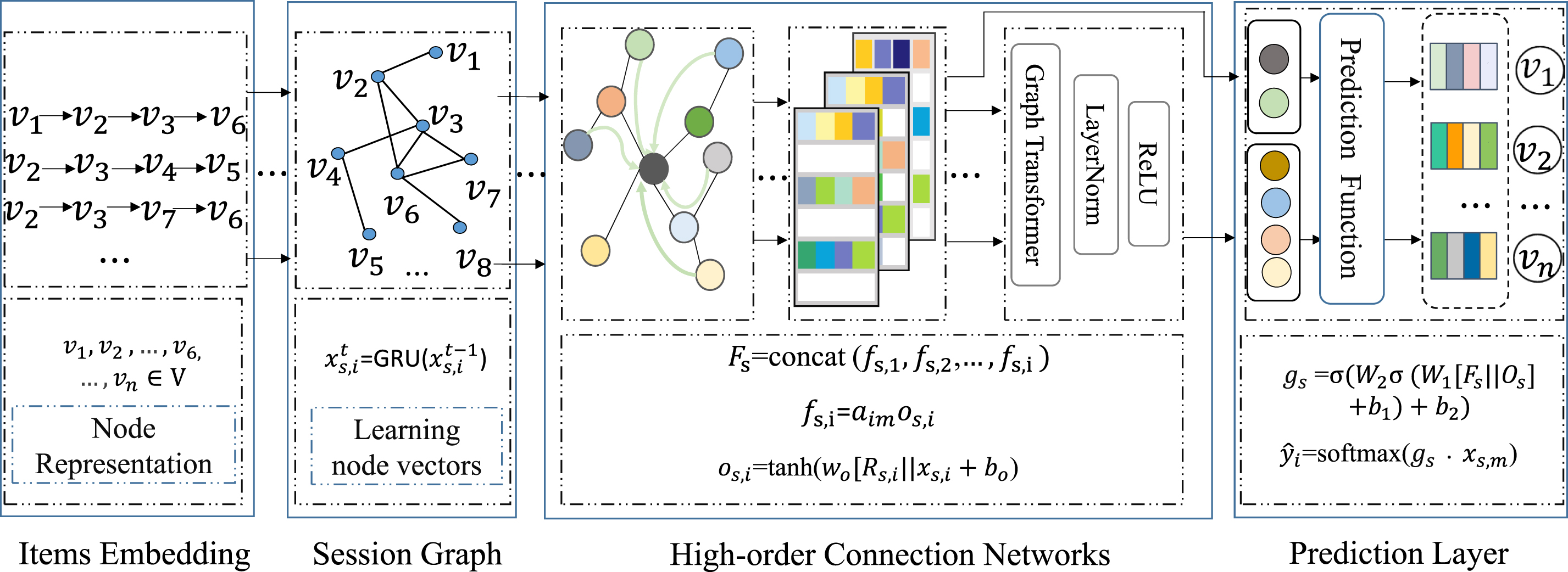
An illustration of our model.
Session-based recommendation seeks to calculate output probability of the interactions that users will click according to their previous historical behaviors [31]. For a session sequence, all items are regarded as the nodes of the session graph G
s
. G
s
= (V
s
, E
s
, A
s
), A
s
is the adjacency matrix between nodes, E
s
is the set of edges and V
s
is the set of all unique interactions that m is the length of the session. Each node was embedded into the latent space, where the node vector
where
In the propagation process, each layer of the graph network can only capture the first-order relationship between nodes. In order to be able to capture higher-order relationships, it is usually captured by stacking multiple layers of GNN networks. As the number of layers deepens, The gradient will be disappeared, and the long-distance dependency cannot be effectively captured. Therefore, we resort to high-order connection mechanism to capture the shift relationship between interactions.
Since adjacent interactions have a strong correlation in the session, the high-order connection layers are introduced to obtain high-order information and generate more important features. The high-order attention-aware network are proposed to select the relatively important neighbors’ nodes to aggregate the embedding of the neighbor nodes in a graph network [27] and capture the users’ main intention..
The graph not only needs to aggregate the node of its neighbors, but also needs to update itself node. The features of nodes are up to itself and its neighbors. We formulate the representation of an item as [32].
In order to calculate the node’s importance within current session and the candidate, the node’s sequence are modeled to discover the useful information about the users’ primary intent, the feature representation
The graph high-order layers are served to further propagate and explore the higher-order connectivity information [33], which collect the information propagated from its distant neighborhood among nonadjacent interactions, the distance behavior within item sequences may breakdown the local integrity of the chain structure but can be likely avoided through this high-order connection, which can be formulated as equation (8):
For the sake of making the best of the feature of each layer, the shortcuts are adopted to prevent information loss that it is more likely to permit additional long-rang information to forward propagation [34]. In order to integrate the concatenated dense representation vector, we adopt a four-layer fully connected layers to aggregate and propagate information and the output vector is represented by equation (10).
The hybrid embedding
For a session s, the last-visited item
Since the recommended items will appear in the candidate list, the prediction between items is a classification problem, it is required to predict the probability of the clicked items, the cross-entropy loss function is adopted to optimize the loss. To optimize the function, we used the cross-entropy loss function to verify the performance of the model on samples and the loss function demonstrates the gap between the ground-truth and the predicted value. Therefore, the model was trained by minimizing the optimization function, as formula (13):
In this paper, we have described the details of our method. To simplify here, we present HOGAN method in Algorithm 1, which is the whole algorithm in our paper.
obtain user’s current preferences F s according to Eq.(1)-(5)
obtain user’s global preferences Q s according to Eq.(6)-(10)
compute the final session representation g s according to Eq.(11)
compute the prediction
update θ with gradient descent according to Eq.(13)
Data sets
To test the effectiveness of our model, our method is conducted on four standard data sets (Yoochoose
2
, Diginetica
3
, Xing
4
, Reddit
5
) and the performance of different recommendation algorithms are evaluated through a series of comparative experiments. Yoochoose is a dataset that is from the RecSys competition. It is a collection of sessions clicked by the user. The dataset contains streams collected from e-commerce sites that users click on over six months. To filter out noise data, we filter out interactions repeated appearing less than 5 times and then remove all sessions with fewer than 1 interactions [7]. Diginetica is a common data set that has been released by cikm cup 2016. To filter noisy data, we reserve the sessions that the length of the session is greater than one and interactions with frequency of occurrence great than five. Xing is a job search dataset that contains a collection from suitable candidates recruiters. Xing has fifteen million users and approximately one million interaction records on the platform. User behavior consists of click, browse, mark and delete actions. Since this data set is crawled directly from the website, and the dataset is anonymized and derived from the user profiles, so the data is incomplete and mingle with some noise. The data set needs to be detect the clean data, we deal with the data, divide into sessions by the time intervals, and remove repeated interactions of the same type within sessions in the session [27]. Reddit. Reddit data set is crawled directly from the Reddit. The dataset contains the username, the username interactive record, and the timestamp of the interactive record. If the interactive records are commented by the user, the interactions are considered to be related. The lines of the dataset denote the corresponding interaction for the user in Reddit data. The interactions were processed and divided it into multiple sessions according to the user. In the process, we adopted the similar method as for the Xing data set [27].
Similar to the method reported by Xu [7], for a session sequence S ={ vs,1, vs,2, …, vs,m }, we make train dataset and test dataset by generating a series of sequences ({ vs,1 } , vs,2) , ({ vs,1, vs,2 } , vs,3) , …). The processed datasets are listed in Table 1.
The statistics of the four datasets in the experiments
The statistics of the four datasets in the experiments
Due to Yoochoose data set is so large that the training speed is very slow. For the purpose of conducting the experiment more perfectly, we processed the experimental data. The Yoochoose dataset is divided into the yoochoose1_64 dataset. The last-week session is regarded as the test set, with the rest of the session as the training set. The interactions in the training set are removed so they would not appear in the test set, which there will be no duplicate interactions in the train set and test set. The Diginetica and Retailrocket were dealt with by split into the train set and test set, we take the session from the seven days of the dataset as the test set. For the Xing and Reddit, we take the session from the one day of the dataset as the test set. For the purpose of inputting the session sequences in the training model, we split the input session sequences into the sequence sets and the corresponding labels.
We designed the model using pytorch to train our data. Following previous methods [8, 16], the parameters are initialized with a gaussian distribution, and the Adam optimizer is used to optimize the hyper-parameters, where the initial learning rate starts from 0.001 and is set to 0.005 and 0.01, respectively. Moreover, the L2 is set to 10-5. The batch size and the hidden size are set to 100 and 100, respectively. we use the learning rate decay rate 0.1. The epoch of model iterations is set to 30 and the latent dimensionality of the datasets is set to 100. The experiments are performed on a GeForce GTX Titan1080 GPU to accelerate the model training.
Baseline methods
To evaluate the performance of the proposed method, we compare the proposed method with other six methods: FPMC, GRU4Rec, HCRNN, NARM SR-GNN and LESSR, respectively, Among them, the proposed method and SR-GNN are based on the graph model. A brief description of the six methods are as follows: FPMC
6
[18] is a traditional model that combines matrix decomposition with a first-order Markov chain for predict the next item. GRU4Rec
7
[25] use multiple gate recurrent unit layers to learn the session embedding for session-based recommendations. It was specifically designed to predict the next item based on the behavior of a sequence by an embedding session. NARM [35] is the first time to adopt the attention mechanism to encode the user’s sequence and discover the user’s main preference [35]. In the process of hybrid encoder, they used bilinear mechanism to predict the final score. HCRNN
8
[12] adopted the gate unit to discover the shift of interest and use a complementary bi-channel attention structure to discovers users’ interests. SRGNN
9
[16] came up with graph neural network to generate latent vectors of interactions by introducing a linear approximation to spectral graph convolutions and represent each session by an attention network. LESSR [36] employed the attention mechanism in transformer to explore the effect of history session in the current session, and solve the information loss issue by taking the node sequence into account [37].
Evaluation methods
Since the recommendation system aims to quickly find the valuable interactions from the massive resource. Despite the capacity and interface show the limited number of interactions, the user’s needs are on the rise. In order to evaluate the performance of each model, we evaluate two widely adopted ranking metrics including MRR and NDCG, and two accuracy metrics including Recall and Precision, which are as follows, Recall: The main evaluation metric is Recall@ k which statistically tests the probability that the user’s real clicked interactions. Recall selects the part related to the current recommendation by the user from the global item library as the candidate set. The item data finally displayed to the user is a subset of this set. Too few recalls and too little content for users to see are not conducive to more interaction between users and the platform. MRR (Mean Reciprocal Rank): MRR@ k is the reciprocal of the ranking of interactions in the results given by the evaluated system as its accuracy. To take the interactions of the evaluation into account on the recommendation list, the MRR@ 20 metric is internationally common mechanism for evaluating search algorithms. NDCG (Normalized Discounted Cumulative Gain): It is adopted to evaluate ranking performance by taking the positions of the correct interactions into consideration [38], and thus to assess if the interactions that a user has actually consumed are ranked in higher positions in the recommendation list [38]. The performance is even better, and the relevance between interactions and candidates is the greater. In the experimental setup, the number of candidates is selected as 20. Precision: Precision(P) is the probability that the result predicted by the model is correct, which can reflect the accuracy of the prediction of the model. The predicted value is the larger, the performance of the model is better and the predicted result is the more accurate.
Comparisons of performance
In this statistical test, we select an effect test and fail to choose a parameter test due to the large model parameters generated by the model. The effect test is used to test the performance of the model in a real application. In our study, we compare our method with other algorithms by running against four datasets. Our algorithm outperforms other algorithms for the comparison on four datasets, which validates the importance of high-order attention for the session, as shown in Table 2. Table 2 illustrates the results of HOGAN and baselines. First, we can see that HOGAN outperforms the other methods in MRR@20 and Recall@20. For the baselines, we can know that the neural models generally outperform the traditional methods (e.g, FPMC) in all the datasets as a result of the benefit from deep learning in this field.
The performance of our method with other baseline methods over four datasets
The performance of our method with other baseline methods over four datasets
In these approaches based on deep learning theory, GRU4Rec makes the most of RNN-like units to model the session as a sequence and combine a current session embedding to form a unified represent to make precise sequence recommendation. Meanwhile, the RNN-based models (HCRNN, GRU4Rec) also achieve excellent results since the sequence models are benefit to capture user’s shift interest. HCRNN performs better than GRU4REC since HCRNN improves the RNN structure with hierarchical context to capture the interest drift. Besides, these methods utilizing the attention mechanism, e.g.,NARM, HCRNN, obtain a great improvement compared with GRU4REC, which shows the capability of the attention mechanism to achieve satisfactory results to learn the dependency with interactions. Especially, LESSR is specifically for the SR problem and obtain perfect results in the experiment. In this experiment, LESSR performs slightly better than SRGNN and HCRNN because graph neural networks have a strong ability to model structured data and the graph attention layer effectively captures long-range dependencies. HOGAN, LESSR and SR-GNN model the session as a graph and apply graph neural network and the attention mechanism. Different from the baseline models mentioned above, HOGAN adopts the high-order attention mechanism to adaptively assign weights to previous interactions, which make good use of higher-order information to capture long-range dependencies between interactions of a session, regardless of the item distances. Furthermore, we propose that the performance is superior to the baselines on the Recall@20 and MRR@20, which in view of the current user’s sequence behavior in the model. As far as we know, our algorithm gets the best performance among all the algorithms on the four datasets.
Table 3 shows the capability of NDCG, and we separately study the performance of NDCG for the recommended top items. As can be seen from the results, 1) As the number of recommended items increases, the performance of NDCG keeps increasing until the value of N reach the twenty, which indicates that the performance of the model is related to the number of recommended items. 2) For the recommended top-n items, the NDCG of different data sets varies significantly, indicating that the recommended performance is related to the length of the session.
The performance of NDCG over four datasets
We further evaluate our model by the top 20 recommendation results on the four datasets and adopt the Recall@20 and the MRR@20 to show the result. Figure 3 displays the performance of our method and three baselines with a different number of iterations on different data sets. It is clear from results that: (1) Fig. 3(a) and Fig. 3(e) display the experimental results of Yoochose1_64 on both evaluation metric. As we can see, the performances of the four models consistently go up with the number of epochs increasing until the twentieth epoch and have no further improvement. It is the reason that the high-hop layers would make HOGAN easier to precisely capture more detailed information. It also shows that HOGAN is consistently better than the baselines with enough propagation steps and learn the useful features for the task of interest. (2) Fig. 3(b) and Fig. 3(f) show the performances of the Diginetica on both Recall@20 and MRR@20. In the beginning, the effect of our model is better than SRGNN. In the fifteenth epoch, the performances of the four models tend to be stable, and our model is better than SRGNN in all epochs. (3) Fig. 3(c) and Fig. 3(g) show the performances of the Xing on both Recall@20 and MRR@20. In the beginning, the effect of our model is better than SRGNN. In the fifteenth epoch, four models have a closed performance. Their performances have no significant improvement after that. In Recall@20, HOGAN has the best performance in the twentieth epoch and the proposed method is better than SRGNN in all epochs. (4) The results of the Reddit on both Recall@20 and MRR@20 are shown in Fig. 3(d) and Fig. 3(h). From the results, we can see that increasing the number of layers always result in a better performance. In the fifteenth epoch, four models have a closed performance. Their performances have no significant improvement after that. In Recall@20, HOGAN has the best performance in the twentieth epoch and the proposed method is better than LESSR in all epochs.
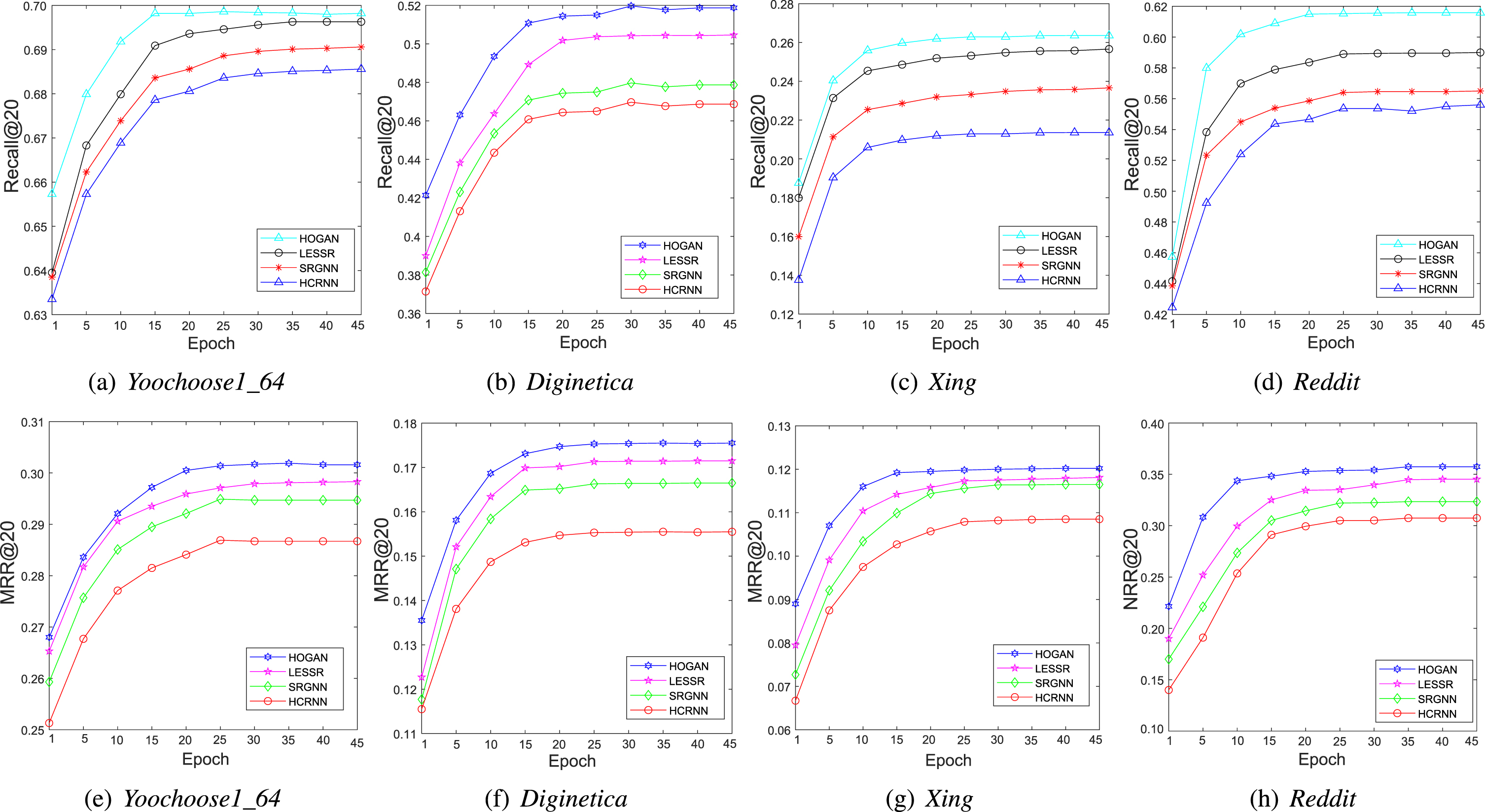
Performance comparison between our method and the baselines.
We conduct ablation experiments by studying different blocks and analysis the effects of different blocks. The Table 4 shows the performance of the ablation experiments. By research the part of the model, we compared the performance of the models. The results are shown in Table 4. We found that the attention-based model is always better than the non-attention model when the number of parameters is small, which shows the effectiveness of the attention mechanism in this task. By adding the model of the attention model, we see that the performance of the fusion method of several models is better than that of a single attention model. From the third and fifth rows of Table 4, we use the self-attention encoding method to show the performance well on the four data sets, indicating that it can capture the dependency of the global addition and solve the dependency problem of the long sequence. At the same time, it can be seen from the second and fourth rows that the addition of GAT can better establish higher-order relationships and can capture features at longer distances. In addition, we can see that the role of each model has played a good effect, which is consistent with the observation results
The performance of different block passing layers
The performance of different block passing layers
Figure 4 shows the impact of our method on Recall@20 and MRR@20 on four different datasets with different high-order layers. The left figure displays the Recall@20 when the layer is varying from one to ten, and the performance has not been continuously improved with the high-order layer increases. However, the performance is limited as the high-order layer is increasing. The right figure shows the MRR@20 achieved the best performance when the number of layers is four. Based on the above result, four layers performance is perfect for our algorithm.
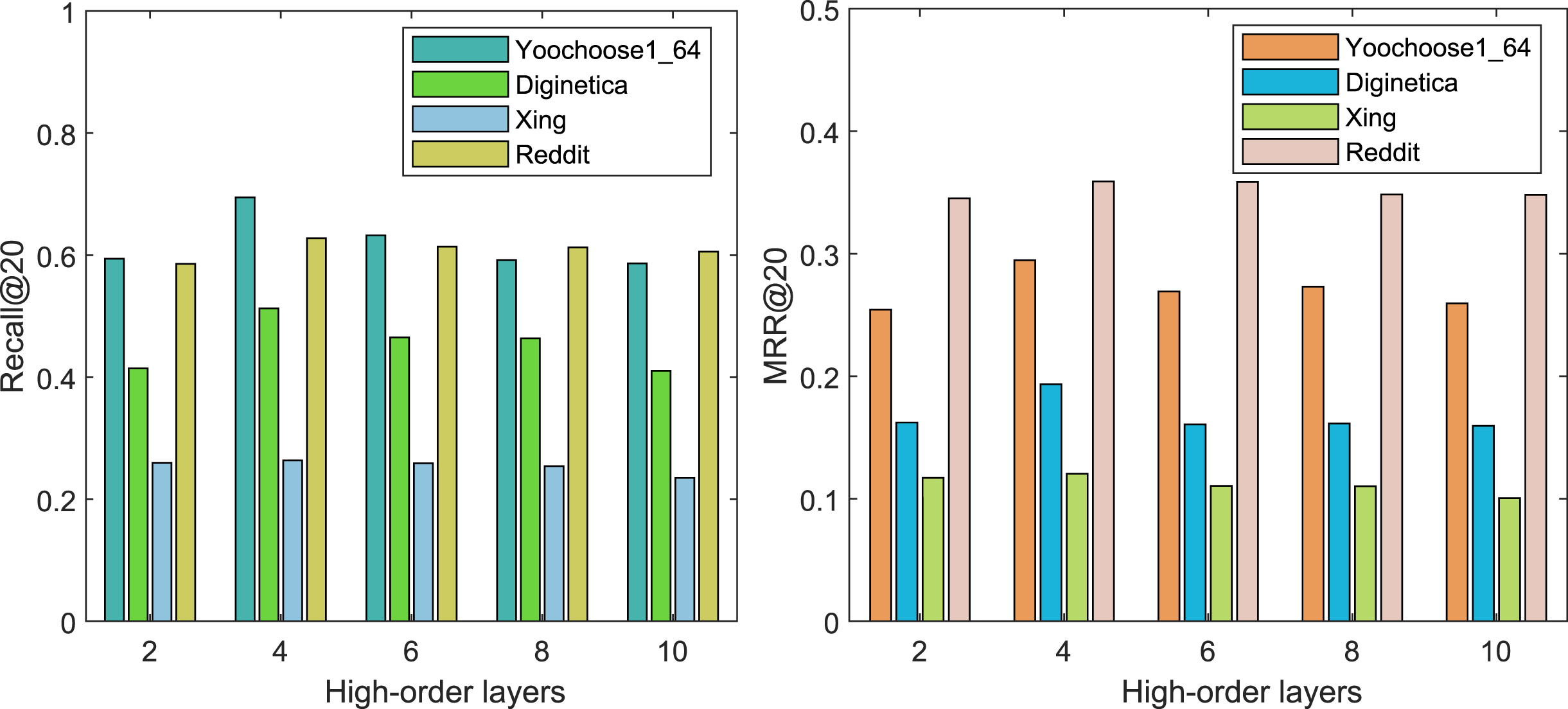
Performance comparison between different layers over three datasets.
We assessed the model by training speed (time taken for one epoch of training), and all experiments were performed with GTX-1080 Ti GPU. The Fig. 5 shows the training efficiency of the model that the training model converges to the stable performance in the training process. Figure 5 shows the training efficiency of our model and others. For a fair comparison, we are all running on GTX-1080 Ti GPU. We can see that our model requires less time to update one epoch. We can see spends 4.8 seconds on model updates for one epoch which is over 2.4 times faster than Lesser (11.9s/epoch) and 6 times faster than GNN (28.3s/epoch), we also see that our model achieved stable performance within around 200 seconds on the data set Yoochoose1_64 while other models require much longer. Meanwhile, we analyzed our model on reddit dataset, and discover that the time efficiency of our model is better than the efficiency of other baselines.
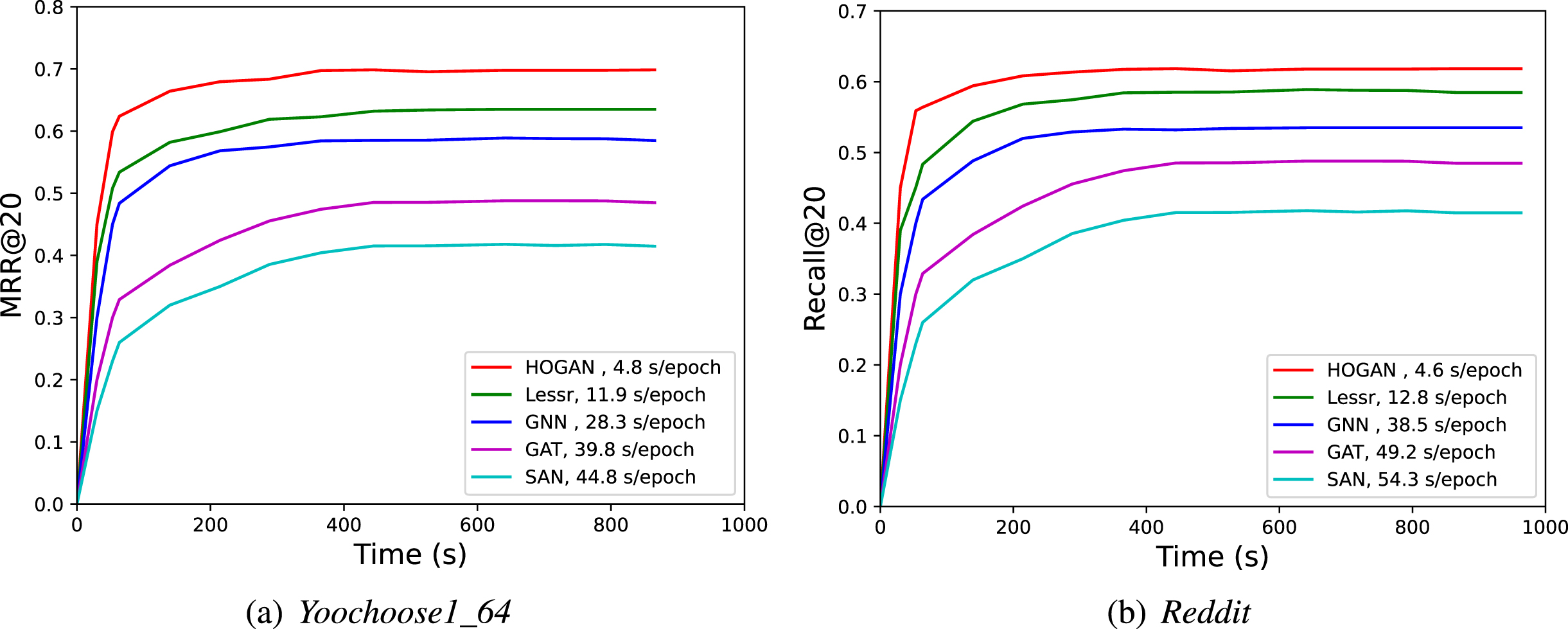
The comparison of time efficiency between our method and the baselines.
In this paper, we come up with a new high-order graph model to predict the next clicked interactions. Specifically, we introduce higher-order connections to further discover the relationships between interactions to solve the long-range dependency capturing problem. We present detailed experimental results of our model on four real datasets and verify that the performance of the proposed model delivers a significant improvement on MRR@20, Recall@20, and NDCG@20. In addition, we specifically study the time efficiency of a different model which indicates that our method excels different baselines.
This paper mainly focuses on intra-session recommendations, without considering the cross-session information that has similar behaviors with the current session. Analogous to the hypothesis of collaborative filtering, people with common interests are likely to make similar choices. Therefore, we consider combining the cross-session recommendation to further boost prediction performance. In future work, we plan to adopt cross-session recommendations to consider similar preferences, accurately predict users’ interests, and improve recommendation performance.