
Abstract
In this paper, we presents an apporch for real-world human face close-up images cartoonization. We use generative adversarial network combined with an attention mechanism to convert real-world face pictures and cartoon-style images as unpaired data sets. At present, the image-to-image translation model has been able to successfully transfer style and content. However, some problems still exist in the task of cartoonizing human faces:Hunman face has many details, and the content of the image is easy to lose details after the image is translated. the quality of the image generated by the model is defective. The model in this paper uses the generative adversarial network combined with the attention mechanism, and proposes a new generative adversarial network combined with the attention mechanism to deal with these problems. The channel attention mechanism is embedded between the upper and lower sampling layers of the generator network, to avoid increasing the complexity of the model while conveying the complete details of the underlying information. After comparing the experimental results of FID, PSNR, MSE three indicators and the size of the model parameters, the new model network proposed in this paper avoids the complexity of the model while achieving a good balance in the conversion task of style and content.
Introduction
Image style transfer refers to the transfer of the style and contour features of one image to another image while ensuring that the basic structure of the original picture does not change. The ultimate goal is to achieve a perfect combination of generated image style content and source image content.
Image style transfer can be used in the fields of artistic creation, film and television special effects, etc. Besides, it is a research hotspot and difficulty in the current image translation field. With the rapid development of the mobile internet, unique style pictures are created through style transfer and shared on social networking sites, which are very popular among people. As one of the more popular art forms in present society, cartoon animation has appeared in every aspect of our lives. The production process of modern cartoon animation is usually that artists use various sources from real world scenes to create content while adding their own artistic characteristics, this cartoon drawing method is usually more common in Japanese cartoon works, the artist artistically processed real-world photos into usable cartoon scene materials, and some famous animation scenes were created. In the real world, the transition from a real scene to a cartoon scene requires a cartoonist to carefully sculpt one by one, and usually requires a lot of energy and time to complete a scene. In deep learning, we can use the model to cartoonize images of real scenes by learning the style of specific cartoon style images. This process is called image cartoonization, the cartoonization of images can bring a variety of artistic materials to practitioners, and assist humans in their work to a certain extent, reducing people’s workload and resource consumption.
The pioneering work of style transfer between images began with Gatys et al. [1]. Traditional non-parametric image style transfer methods are mainly based on physical model rendering and texture synthesis. The non-parametric image style transfer method can only extract the low-level features of the image, not the high-level abstract features. When dealing with images with more complex colors and textures, the final image synthesis effect is rough and difficult to meet actual needs [1–4].In response to this problem, relevant personnel have conducted a lot of research and proposed methods based on convolutional neural networks [5–8] or generative adversarial networks [9–11, 37], and achieved good results in certain specific scenarios. However, due to the complexity and diversity of human faces, when the above-mentioned work performs cartoon style conversion on human face images, there will be insufficient extraction of abstract details. As a result, the converted pictures appear to have mismatches in style and content that is too roughand noisy.
The goal of this paper is to propose a generative adversarial network model that combines an attention mechanism, by giving the style of the cartoon character avatar picture, the cartoon style conversion of the unmatched real scene character avatar is performed, after the conversion, the generated image should maintain a certain balance between content and style, and achieve the task goal of consistent style, clear content and complete details.
In order to achieve the goal of this paper, which is to maintain a balance between style and content. while considering the completeness of face detail extraction, two changes have been made to the current model:First of all, this article uses smaller convolution kernel in the generator to process the image to ensure the image quality after the style conversion. Secondly, in order to ensure that the model can learn more style details and abstract details of style content, this paper adds a channel attention mechanism between the up-sampling stage of the generator, so that the model can learn more complete style and content details, and maintain the consistency of the generated graphs in style and content.
The paper has the following contributions:
First of all, this paper proposes a new generative adversarial network that combines the attention mechanism, which achieves a good balance between style and content in the cartoon face style transfer work. Secondly, the model in this paper does not increase the complexity of the model while ensuring that the quality of the generated cartoon images is better than the former model.
Related work
Attention mechanism
Attention Model(AM), first introduced for Machine Translation [13] has now become a predominant concept in neural network literature [14], attention has become enormously popular within the Artificial Intelligence(AI) community as an essential component of neural architectures for a remarkably large number of applications in Natural Language Processing [15] and Computer Vision [16]. With the deepening of research, the attention mechanism is divided into hard attention mechanism, soft attention mechanism, global attention mechanism and local attention mechanism, etc [17–19]. The proposal of visual attention has made it popular in many computer vision tasks [20], aiming at the generative adver network in the field of computer vision. Zhang et al. proposed a self-attention mechanism generative adversarial network. Applying the self-attention mechanism to the generative adversarial network helps to capture remote dependencies [21]. Aiming at the complexity of the attention mechanism model, the channel attention mechanism proposed by Wang et al. is more effective while reducing the complexity of the model [22].
Generative adversarial network
Generative adversarial network [23] was first proposed by Goodfellow, the network model is composed of a generator and a discriminator, the game theory is adopted to train the entire model through the mutual game between the generator and the discriminator. The task of the generator is to generate a distribution that is as highly similar to the real distribution as possible, and the task of the discriminator is to determine whether the distribution generated by the generator is the real distribution or the generator generated. In the ideal state, the discriminator cannot distinguish between the generated picture and the real picture, and it reaches the optimal state of the network model, which is the Nash equilibrium point, but this point is difficult to achieve so far. As the most popular generative model network at present, it was originally proposed to solve the problem of sample acquisition difficulty in deep learning mainly for sample generation. After previous research on GAN network, its main function is to focus on image segmentation and data Enhancement, semantic segmentation, etc. The CycleGAN [24] and pix2pix [25] proposed by Jun-Yan Zhu et al. introduced the image style transfer problem on the basis of the generative adversarial network, using two pairs of GAN networks, as well as the adversarial loss function and the cycle consistency loss function to ensure the stability of training and image arrival. Style conversion between images, and CycleGAN does not require paired data sets, but the generated images have the disadvantage of being unclear. Pix2pixHD proposes a high-resolution solution on the basis of pix2pix, but it comes with resource consumption. On the basis of CycleGAN, GANILLA [26] proposed its own improvement to the generator network to complete the transfer of cartoon illustration style, but the effect on the task of cartoonization of portraits is not very good, and the balance of the converted image content and style is poor. The proposal of CGAN [27] allows GAN to use images and corresponding labels for training, and use the given labels to generate specific real-detail change images in the test phase, but it is also different from the research content of thisarticle.
Stargan and stylegan [28, 29] solves the problem of multi-domain image content conversion. The two models are mainly aimed at the detailed multi-domain style conversion of real-life images, and the image can be changed in terms of detailed features through a given label. CartoonGAN [30] can use real pictures to generate any cartoon-style pictures based on the input specific style pictures, but there will be artifacts when generating cartoon pictures, which is more obvious in the case of more green content. Secondly, it differs from the task of cartoonizing faces in this article in style and content. Compared with the former, AnimeGAN [31] proposes a new loss function, which improves the cartoon effect of the generated image. However, some of the generated pictures still have some phenomena such as loss of details of distant portraits and unobvious cartoon styles of close-range characters. White-boxGAN [32] will have spots when the cartoon style is changed. In this paper, a generative adversarial network structure is used to synthesize images with the same distribution as the target domain.
Image-to-image translation
The image-to-image translation is similar to the machine translation task in the natural language field. The task of machine translation is the conversion from text to text, such as the conversion from Chinese to English. However, the task of image-to-image translation is to convert a picture from one form of expression to another. The fundamental relationship in the field of image-to-image translation is actually the pixel-to-pixel relationship in the image.
The task of image-to-image translation [33, 34] solves the problem of image conversion from a source domain to another target domain. Image enhancement [35], rain and fog removal [36], image style transfer, season conversion, and coloring of hand-drawn manuscripts are all applied in the field of image-to-image translation tasks.
This paper uses an unpaired image-to-image conversion framework to complete the task of cartoon style transfer of real-life images, combined with the attention mechanism, so that the converted images have a good balance of content and style.
CAMGAN
In the study of the problem of face cartoon style conversion task, it was found that the former’s work had some problems[gan, Cyclegan, pix2pix, ganilla]. In previous studies, when dealing with face images with more detailed and more complex data, it is difficult for the style transfer results to achieve satisfactory results in the balance between content and style. The background content color changes, the content details are not learned enough, the content structure changes, and the problems of poor quality of the generated images will more or less exist. In response to the above problems, a new generator network is designed, which combines the channel attention mechanism on the basis of the predecessors, which can deliver styles while retaining the content. First of all, we will introduce the model in detail. Secondly, we will compare the model with previous work on cartoon face style transfer. Finally, we will conduct related parameter experiments on the model to verify the effectiveness of our model.
Model details
The CAMGAN model is a GAN-based model that proposes a new generator network combined with channel attention mechanism, as shown in Fig. 2. In order to ensure the completeness of the details of the image content, CAMGAN uses low-level features to save the content details when transferring image styles. CAMGAN’s generator model includes two stages: down-sampling stage and up-sampling stage. In the down-sampling stage, we use a modified ResNet-18 [37] network. Since the bottom layer contains information such as the morphological characteristics, edges and shapes of the image, this is very important information in the image cartoonization task. Therefore, in the down-sampling stage, we connect each down-sampled layer with the feature information of the previous layer to ensure the integrity and consistency of the content information of the image during transmission.

Use CAMGAN model for cartoon style transfer.
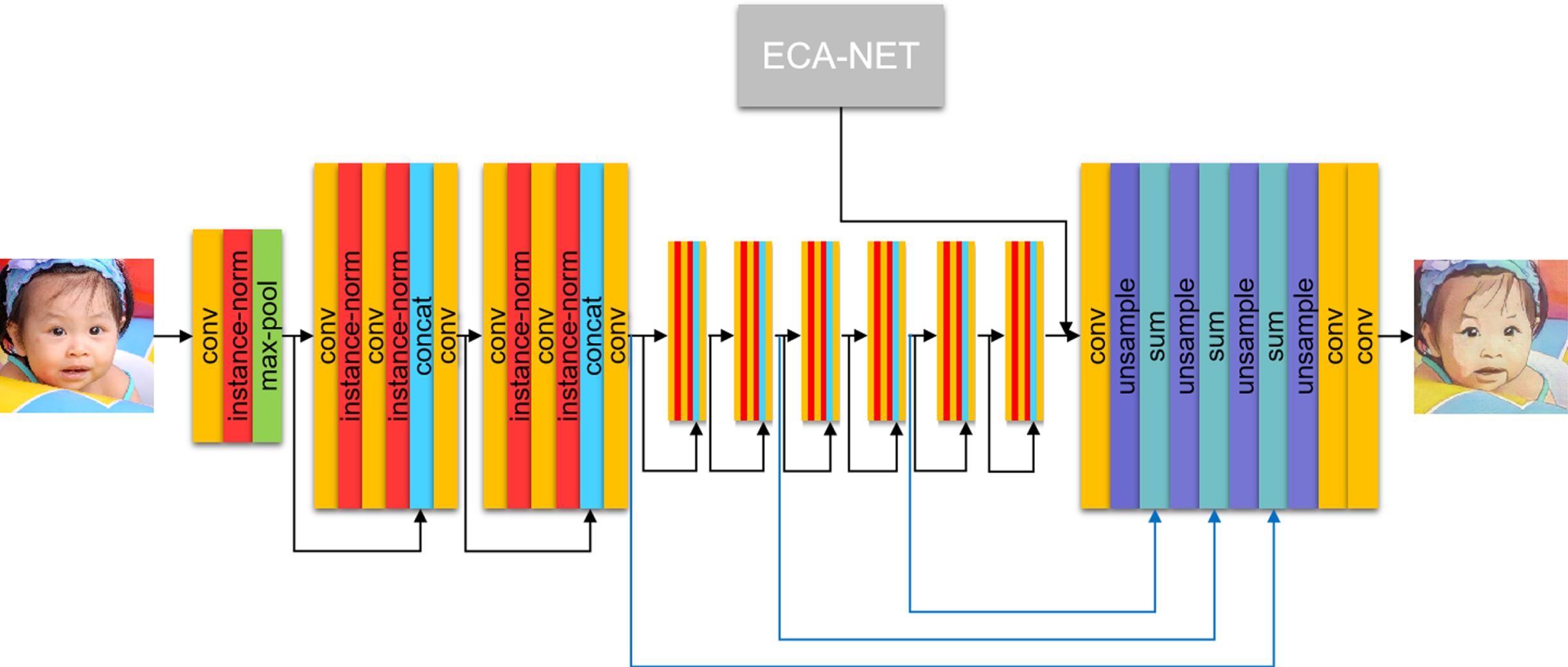
CAMGAN generator structure combined with channel attention mechanism.
First, here we combine a 7x7 kernel convolutional layer with instance norm [38] and max pooling layer. The reason for choosing to combine with in here is that when using the GAN model for style transfer, the effect of instance norm is better than that of batch norm. Then we use the two remaining blocks as a layer, a total of four layers and eight small layers to transfer and process image information. Each remaining block is similar to the above, starting with a convolutional layer, and then connecting in and ReLU to maintain the integrity of the underlying information and the stability of the network. Then pass the information to the next convolutional layer and instance norm, using a concat layer and convolutional layer as the end, and the output of the previous remaining block as the input of the next block. Taking into account the completeness of the extraction of the content details, we will use the convolution with a stride of 2 for each layer of feature maps after the first layer to halve, and the convolution kernel of all remaining blocks is 3x3.
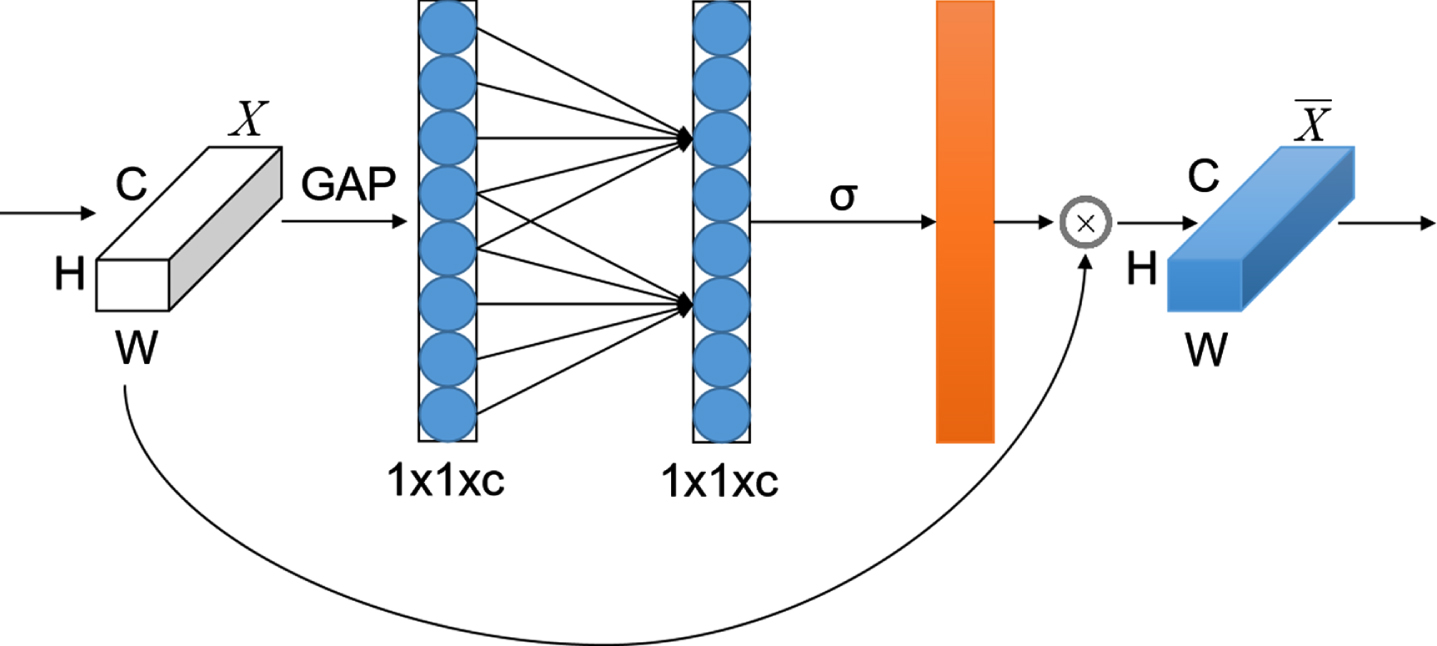
Combined with global average pooling (GAP) to obtain the channel attention mechanism of aggregated features, H, W, C represent the spatial size of the image.
Before the operation of the up-sampling stage, this article adds a channel attention mechanism with an adaptive core (ECA-NET) between the up-sampling and the up-sampling (show in Fig. 3). The size of the adaptive core can be adaptively changed according to the size of the channel dimension C. According to the experimental results, the model combined with the channel attention mechanism is helpful for effective channel attention learning while avoiding the reduction of dimensionality [39]. In the channel attention mechanism, a band matrix with KxC parameters that is not completely isolated between groups is used to learn channel attention as shown below Eq.(1).
In the down-sampling stage, we use skip connections and longer connections to pass lower-level features to the output layer, which helps to preserve low-level feature information. This is a very important step to improve the content quality of the generated image. In the upsampling stage, the main structure is convolution combined with the upsampling layer and the summation layer, and the output processed by the downsampling layer and the channel attention mechanism is used as the input. At the same time, the size of the feature map is increased in the upsampling layer. To match the size of the feature map of the previous layer. After successive up-sampling and summation layers of convolutional layers, CAMGAN finally outputs a 3x3 channel style transfer image through a 7x7 convolution.
Compared with the traditional GAN network, in order to ensure the quality of the generated pictures, we use PatchGAN [25] in the discriminator part to identify the generated images. The traditional GAN model discriminator maps the input to a real number to represent the probability that the generated sample is a real sample. Compared with the traditional GAN model discriminator, patchgan is completely composed of convolutional layers, and then probabilistic judgment is made for each NxN color block in the image, and the final output is an NxN matrix. Each element X ij of this NxN matrix represents the probability that each patch in the original image is a true sample. Then each element of the output matrix is averaged as the output of the discriminator to determine whether the result is true or false. Compared with the traditional GAN discriminator model, patchgan considers the influence of different parts of the image in the output result and makes a decision based on many factors. In most studies in recent years, it can be found that the resolution and detail requirements of images in computer vision research tasks are getting higher and higher. Therefore, the birth of patchgan helps the model to pay more attention to details in training. In CAMGAN,we use a 70x70 patchgan, and the filter sizes are 64, 128, and 256 respectively.
The CAMGAN model still uses CycleGAN’s training methods and ideas. CAMGAN and CycleGAN have two generators and two discriminators, one generator and one discriminator are a set, the model goal is to learn the mapping function between domain X and domain Y, as shown in Fig. 4(a). The mapping function learned by CAMGAN should be cyclically consistent: for each image in the domain X after the cyclic conversion, the original image that is the same as X should be obtained as much as possible. For example, X → G → F (G (X)) ≈ X, as shown in Fig. 4(b). For domain Y, the rule of Y → F → G (F (Y)) ≈ Y should also be followed, as shown in Fig. 4(c).
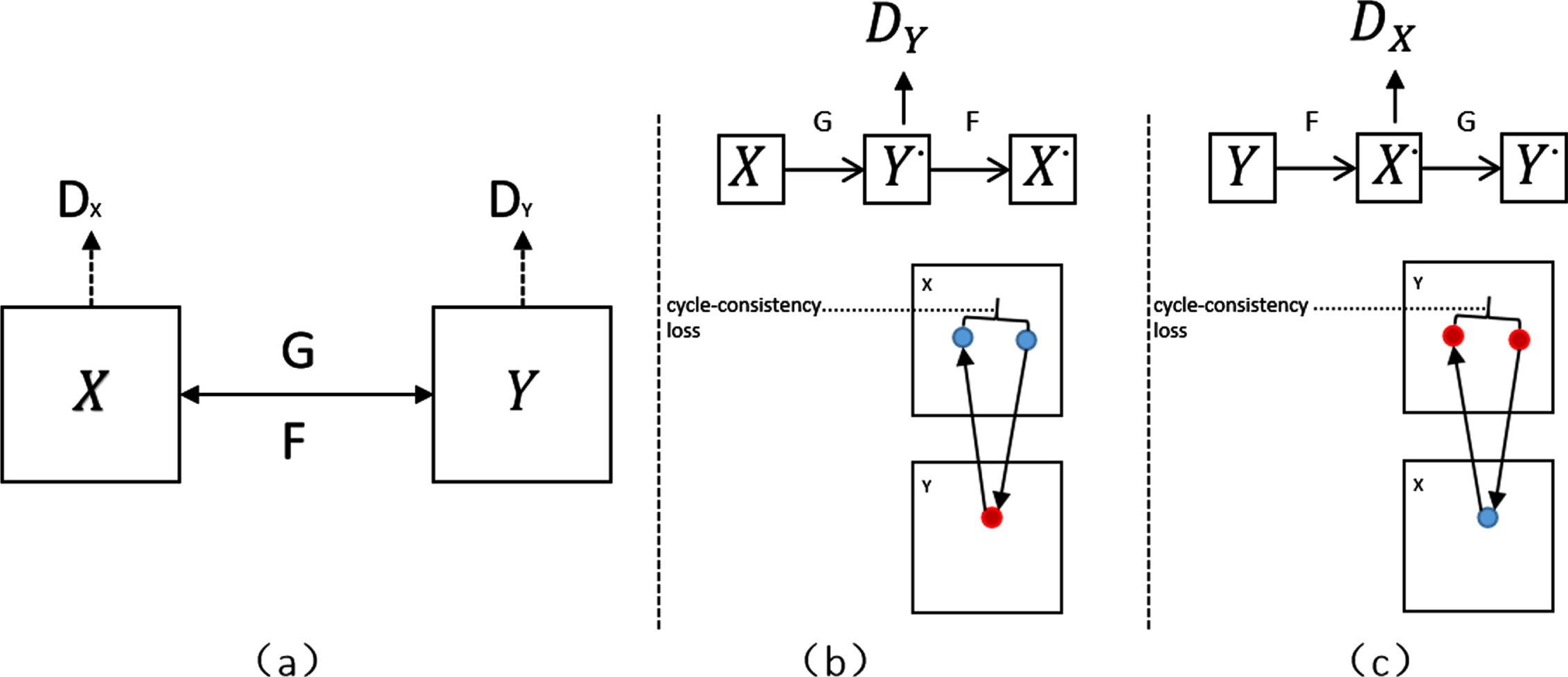
CAMGAN training method.
In terms of the loss function, in addition to the maximum and minimum loss of each generator and discriminator as shown in Eq.(5).
In addition, in order to ensure the quality of the image generation, the consistency of the image structure, and the stability of training, we also use a cyclic consistency loss function and an adversarial loss function such as Eq.(6) and formula Eq.(7).
Regarding the cyclic consistency loss, we use the L1 distance, which is the Manhattan distance. The idea of cyclic consistency comes from dual learning. The function of cyclic consistency loss function is to control image generation at the pixel level, reduce the mapping space, and preserve the contour of the input image better. Then through the introduction of L1 distance, the optimization process takes into account the changes of the image pixel level. The goal of the model is to optimize all losses, as shown in Eq.(8).It is especially important that the value of the parameter λ in the cyclic consistency loss function plays a decisive role in the entire loss function.
Considering the complexity of the model implementation, this article uses PyTorch to implement the model. In deep learning tasks, especially in the field of image translation, the situation of having paired data sets does not necessarily exist, and having paired data sets often requires a certain degree of complexity. When CAMGAN performs image style conversion, it does not need paired images, only two datasets with different styles, one for the source domain and the other for the target domain. According to the research content and goals of this article, the character image of the real scene is used as the source domain, and the cartoon style image is used as the target domain to obtain the cartoon style. The images used in all models are adjusted to 256x256 pixels. The model is trained using the Adam optimizer with a learning rate of 2x10-4, and 200 epochs are one model training. After discussion, when the number of data sets is determined to be sufficient, the pre-training method is not used to pre-train the model weights. All experiments start from scratch. For the experimental equipment, we use RTX3070 for modeltraining.
Dataset
This paper uses unpaired data sets for model training, which can better reflect the performance of the model in the task of image cartoon style transfer. The real scene character data set comes from the FFHQ data set [40], from which 10,000 portrait images of various ages and genders with diverse real scenes are collected as the source domain. For the acquisition of target domain images, 10,000 cartoon portrait images from the white-boxgan work of Wang et al. were used. During the training process, the resolution of all images is 256x256.
Evaluation metrics
This paper uses the above data set to perform cartoon image style conversion and compares with the results of CycleGAN and ganilla. Four indicators of FID [41], average psnr, average ssim, and average mse are used to evaluate the performance of the model. The evaluation is carried out to prove that the performance of CAMGAN in the task of portrait cartoon style transfer is better than the previous two as shown in Table 1.
Comparison of fid, average psnr, ssim, and mse indicators
Comparison of fid, average psnr, ssim, and mse indicators
CycleGAN and GANILLA both use two pairs of generator discriminator networks. The structure of the two generators is similar. The latter improves the generator network on the basis of it, so that the network model has a better balance in the conversion of cartoon illustrations. The model in this paper combines the channel attention mechanism on the basis of the first two. From the comparison of the model parameters, it can be seen from Table 2. The channel attention mechanism does not increase the complexity of the model while delivering more complete context information and achieves better results. After experimental verification, the performance of the model in this paper is better than the previous two in the task of cartoonizing portraits, as shown in Fig. 5.
Model parameter size comparison
Model parameter size comparison

Comparison of camgan, cyclegan and ganilla generation effects.
In this paper, we propose a new generative adversarial network model CAMGAN that combines the channel attention mechanism. The goal of the model task is to convert real-world character images into cartoon-style character images. The main contributions of this paper are as follows: A new combination of channel attention mechanism is proposed to generate a confrontation network, while retaining the content of the source domain image, the animation style conversion is carried out to achieve a certain balance between the two. Experiments have shown that CAMGAN can convert portrait photos of real people into animation-style images. Compared with the previous model, combined with the channel attention mechanism CAMGAN, the model complexity has not increased, and the image after CAMGAN conversion is in Image content, background color and image details are better than the former. In future work, in order to obtain better quality generated images, we plan to conduct research to generate better image quality generative confrontation networks, and also consider applying animation style conversion to video frame-by-frame conversion.
Footnotes
Acknowledgments
This work is supported by Key Program of National Natural Science Foundation of China, Grant/Award Number: U2003208; National Natural Science Foundation of China, Grant/Award Number: 61962057; Major science and technology projects of autonomous region, Grant/Award Number: 2020A03004-4.