
Abstract
Alzheimer’s disease (AD) is a degenerative brain disease and the most common cause of dementia. In recent years, with the widespread application of artificial intelligence in the medical field, various deep learning-based methods have been applied for AD detection using sMRI images. Many of these networks achieved AD vs HC (Healthy Control) classification accuracy of up to 90%but with a large number of computational parameters and floating point operations (FLOPs). In this paper, we adopt a novel ghost module, which uses a series of cheap operations of linear transformation to generate more feature maps, embedded into our designed ResNet architecture for task of AD vs HC classification. According to experiments on the OASIS dataset, our lightweight network achieves an optimistic accuracy of 97.92%and its total parameters are dozens of times smaller than state-of-the-art deep learning networks. Our proposed AD classification network achieves better performance while the computational cost is reduced significantly.
Introduction
Alzheimer’s disease (AD) is a degenerative brain disease and the most common cause of dementia that hinders people’s ability of daily life. It is characterized by a decline in memory, language, and other cognitive skills that affects a person’s ability to perform daily activities [1]. People whose ages over 65 years are more likely to develop AD. According to related researches, around 0.64 billion people will suffer from AD by 2050 [2]. With the increasingly serious global aging, AD, which has a long-term disease course, has gradually become an urgent problem in the health field. In Alzheimer’s disease, magnetic resonance imaging (MRI) is essential for early diagnosis, differential diagnosis, and evaluation of disease progression [3]. For this purpose, radiologists can analyze the brain changes including focal lesions and gray matter loss in the lobes through structural MRI (sMRI) scans to make a further analysis of AD [4].
To investigate an effective way of diagnosing AD, computer-aided technology has been widely used in the analysis of neuroimaging data in the past decade. In structural MRI, the automatic diagnosis of atrophy by computers, even when it is not visually noticeable, is possible in daily clinical practice [3]. Currently, researchers have used a variety of statistical machine learning methods to diagnose AD, such as support vector machine (SVM), random forest classifier (RFC), sparse representation-based classification (SRC), etc., which are all widely used methods [5]. Kloppel et al. [6] used linear SVM to detect AD through T1-weighted sMRI scans. In order to develop suitable classifiers to improve accuracy, in most methods typically predefined features need to be extracted from the MRI data. However, the feature extraction from similar MRI scans in classification has considerable technical requirements and difficulties. In recent years, as a promising machine learning methodology, deep learning has been increasingly explored in the development of technology for big data and artificial intelligence [7]. Convolutional neural networks (CNNs) are becoming a wide-spread methodology via its great success in medical image analysis as well [8, 9]. For neuroimaging data, deep learning networks can discover its latent or hidden representations to effectively capture disease-related pathologies [10]. For this reason, many researchers have begun to use deep learning methods for the diagnosis of AD and other diseases.
At present, most deep learning networks have achieved good AD classification results but usually required large number of parameters and FLOPs to improve accuracy, while the research on the construction of lightweight AD classification network is relatively less. In terms of the future applicability of AI in medical diagnosis, it is difficult for large-parameter network models to be well applied to mobile devices and other devices. In order to reduce the computational parameters, in this paper we developed a lightweight AD classification neural network based on ResNet [11] architecture using ghost module [12] which can generate more features with fewer computational parameters.
The main contributions of this study are as follows. Firstly, we verified the effectiveness of the residual network for medical image classification based on OASIS dataset. Secondly, we used the ghost model to improve the residual network for better performance. The ghost model has good performance in generating feature maps, it can reduce the convolution computation and avoid feature redundancy in the convolution layer. In addition, we fine-tuned the number of layers of the residual block to achieve better classification accuracy compared with the same layers of resnet50 [11]. Finally, we indicated the feature maps in the convolution layer and classification results. Compared with other AD classification methods, the accuracy has been improved, while the precision and recall also have excellent performance. Furthermore, the computational parameters of our model have absolute advantages. The total parameters of our network are significantly reduced by dozens of times, which realizes the feasibility of constructing a lightweight network for AD classification tasks. The method in this paper provides a feasible baseline for lightweight AD classification neural network.
Related works
With the development of deep learning, it has become more and more common to implement classification tasks by convolutional neural network [13]. Deep learning received increased attention because of its reason for predicting various clinical outcomes of interest [14]. At present, deep learning methods are one of the best options for solving clinical phenotype classification. For example, the AD classification based on brain sMRI via CNN method has been continuously improved, and the LSTM method to solve the relationship between sequences has been well applied in brain fMRI [15]. For these tasks, deep learning methods have better capabilities and advantages than traditional machine learning methods in many aspects.
By far, a variety of neural network architectures for AD diagnosis have been proposed, many of which are effectively combined with other approaches. Several researches have used convolutional neural networks, and the input is 2D slice images extracted from 3D MRI volume. Farooq et al. [16] trained networks using GoogleNet and ResNet models for classifying structural MRI images to diagnose AD. Sarraf and Tofighi [17] compared the AD classification effects of sMRI and fMRI by one of the light network architectures LeNet-5. They converted the source 3D and 4D (in the case of fMRI) data into a batch of 2D slice images for binary classification of AD and HC. Hon and Khan [18] used the pre-trained VGG [19] and Inception V4 [20] models to train on 6,400 MRI slice images from the OASIS dataset to achieve binary classification(AD/HC). Jain et al. [21] adopted a similar method which using the VGG network to train 4800 MRI slice images of 150 subjects from the ADNI dataset to achieve AD vs HC classification task. Valliani [22] evaluated on the ADNI imaging data based on the deep residual network, which shows that the pretrained residual network is effective for the diagnosis of Alzheimer’s disease. Wang et al. [23] used DenseNet [24] and ensemble methods to classify the entire 3D MRI scan, leading to a state-of-the-art three-class (AD vs MCI vs HC) classification. Among these deep neural networks mentioned above, such as VGG and ResNet, can be easily used by transfer learning. At present, in the researches of AD classification based on deep learning, 2D slice and 3D volume are the main research methods and they have their own advantages. In terms of datasets based on these 2D slices, different slices can be extracted from a single 3D MRI volume for increasing the number of training samples.
In this work, we developed a modified deep CNN based on ResNet to diagnose AD and HC from sMRI slice images by taking advantage of 2D slice data. The characteristic of this network is to use a 2D convolutional network to classify each slice of the sMRI data, and final score as the output calculated by the last softmax layer of network is used as the classification judgment. Our proposed neural network can outperform some advanced and efficient deep neural networks in AD vs HC classification task. Compared with the most existing methods, the proposed method not only improves the classification performance from the perspective of network model, but also realizes the lightweight from the perspective of model practicability.
Methods
In this part, we mainly introduce the ghost module and its principle used in our construction of the lightweight network. Deep convolutional neural networks contain numbers of convolution operations, which lead to a large amount of computational cost of the deep learning method. And the output feature maps of the convolution layers usually contain a lot of feature redundancy. This model uses a few filters to generate more feature maps from the original convolutional layers to reduce the computational cost of convolutional layers. Based on this principle, we use the ghost module to replace all the original 3×3 convolutional layers in the ResNet architecture to ensemble our new lightweight neural network.
Given the input image X∈R
chw
(h and w are the height and width of the input images respectively, and c is the number of image channels), the operation of a convolutional layer to generate n feature maps can be expressed by the following formula as:
However, the convolution mechanism of the ghost module is different. As shown in Fig. 1, it first generates a small amount of intrinsic feature maps through ordinary convolution, and then uses cheap linear operations to increase the number of features and channels. Well, using a primary convolution with kernel size of 1 to generate m intrinsic feature maps
The theory of ghost module.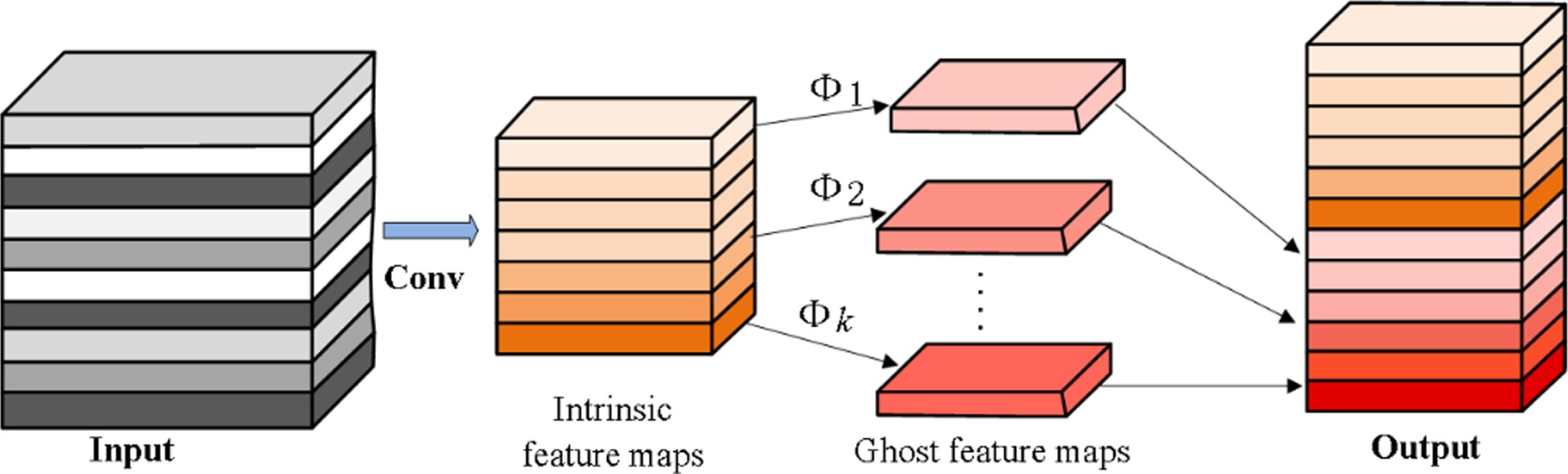
A series of cheap linear operations performed on each intrinsic feature in Y’ to generate the s ghost feature maps:
Through the above methods, the computational cost of linear operation Φ operating on each channel in the convolutional layer is much smaller than that of ordinary convolution.
In our work, the ghost module is embedded into our well-designed ResNet architecture to reduce computational cost, by replacing all 2D 3×3 convolutional layers in the ResNet with ghost module. For all the ghost module used, we set the parameters s = 2 and d = 3, which have the linear core operation of the same size 3×3 linear kernel used for effective implementation. The ghost module proposed in formula (3) is used to generate the same number of feature maps as the ordinary convolutional layer. The input undergoes 49 layers of 3×3 convolution and a fully-connected layer [14] to be the final output. We designed a new total of 50 layers of ResNet architecture as shown in Fig. 2(a). It has 3 main layers, each containings 3, 7, 14 basic blocks respectively. Our network architecture has an adjustment compared with the baseline ResNet50 of 3, 4, 6, 3 basic blocks [11].

(a) Our ResNet architecture; (b) A deeper residual function of basic block for ResNet architecture.
For each residual function of the basic block shown in Fig. 2(b), we use a stack of 2 layers which are 3×3 size 2D convolution filters to reduce the dimension of the layer output. In our ensembled network, we use batch normalization [25] after each convolution and before activation. The final linear classifier of the network is implemented by a fully-connected layer and softmax at the end of the network to complete the classification decision (the input is 64 and the output is 2 dimensions). Compared with the ordinary convolutional neural networks, the total parameters and computational complexity required in the Ghost module have been reduced significantly without changing the size of the output feature map. The total number of parameters required and the computational complexity of the ghost module are significantly reduced without changing the size of the output feature maps compared to ordinary convolutional neural networks.
In this part, we will provide the experimental process and results of our network for AD vs HC classification. Currently, most studies compare the performance of AD classification networks in different data sets, so it is difficult to evaluate the performance of these methods objectively. For this reason, we first trained multiple baseline networks using the same dataset. In order to demonstrate the performance of our lightweight AD classification network, we also select several state-of-the-art AD classification methods using sMRI images, some of which are based on the same OASIS dataset for comparison with our proposed network in terms of accuracy and parameters.
Dataset
In this paper, we used sMRI data from the Open Access Imaging Research Series (OASIS) [26], which is one of the two leading databases for Alzheimer’s Disease worldwide. The cross-sectional sMRI data of the AD and HC in this OASIS dataset consist of 416 subjects between the ages of 18 and 96, each of whom had three to four T1-weighted sMRI slices. We choose axial cross-sectional sMRI slices to perform our classification of AD and HC.
In our classification experiments, the sMRI slice images came from 200 subjects in OASIS, of which 100 subjects were from the AD group and the other 100 subjects were from the HC group [18]. By entropy-based sorting mechanism to choose the most informative 32 images from the axial plane of each subject, for which a total of 6400 image slices are included. 5-fold cross-validation was used to obtain the experimental results, and the dataset with an 80%-20%split between training and testing, so we have a total 5 data sets, each containing 5120 training slice samples and 1280 testing slice samples. The size of these sMRI slice samples is 176×208. Figure 3 shows two classes of sMRI slice samples from the OASIS dataset. In our experiments, we use these limited slice images as the dataset to train our network.

Slice images from the OASIS dataset (a) AD. (b) HC.
In network training, we use the stochastic gradient descent [27] with learning rate is optimally set to 0.01. We use a weight decay of 0.0001 and a momentum of 0.9. Our network uses cross entropy loss [28] as the loss function. The networks we trained were implemented using the Pytorch framework and performed on a Linux X86-64 computer machine with Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30 GHz, 32GB of RAM and GeForce GTX 1080Ti.
Results and discussion
Accuracy, precision, recall, etc. are important evaluation indicators for classification networks, while the Weights and FLOPs are the main measurement indicators of lightweight networks. FLOPs measure the number of forward propagation operations in the network. The smaller the FLOPs, the faster the calculation speed of the network. Firstly, the classification performance of the baseline networks on OASIS dataset can be clearly shown in Table 1. In the classification results, the accuracy rate of ResNet50 is 93.51%, the precision is 93.43%, the recall rate is 93.58%, and the f1-score is 93.50%. We can conclude that ResNet is superior to other network architectures in AD vs HC classification performance. In view of the convolution network structure and classification performance of ResNet, our proposed method is to take ResNet as the framework and embed the ghost module to construct our AD classification network.
Two-class classification performance of baseline networks
Two-class classification performance of baseline networks
In order to test the power performance of our proposed method, we trained our classification network models from scratch with a training set over 5-fold cross-validation to avoid overfitting, we trained our network on each of the five datasets. In this process, the super parameters are kept consistent. The training results of our network are obtained after 100 epochs with a batch size of 32 and the validation loss no longer improved, Fig. 4 shows the overall trend of accuracy and loss in the training step on one of the 5 datasets, the accuracy curve starts to stabilize gradually after 40 epochs of network training. Furthermore, during the experiments we extracted MRI diagrams of AD and HC to visualize the functional diagram of the ghost module in our network as shown in Fig. 5.

The trend of accuracy and loss in the training step in classification of AD vs HC.
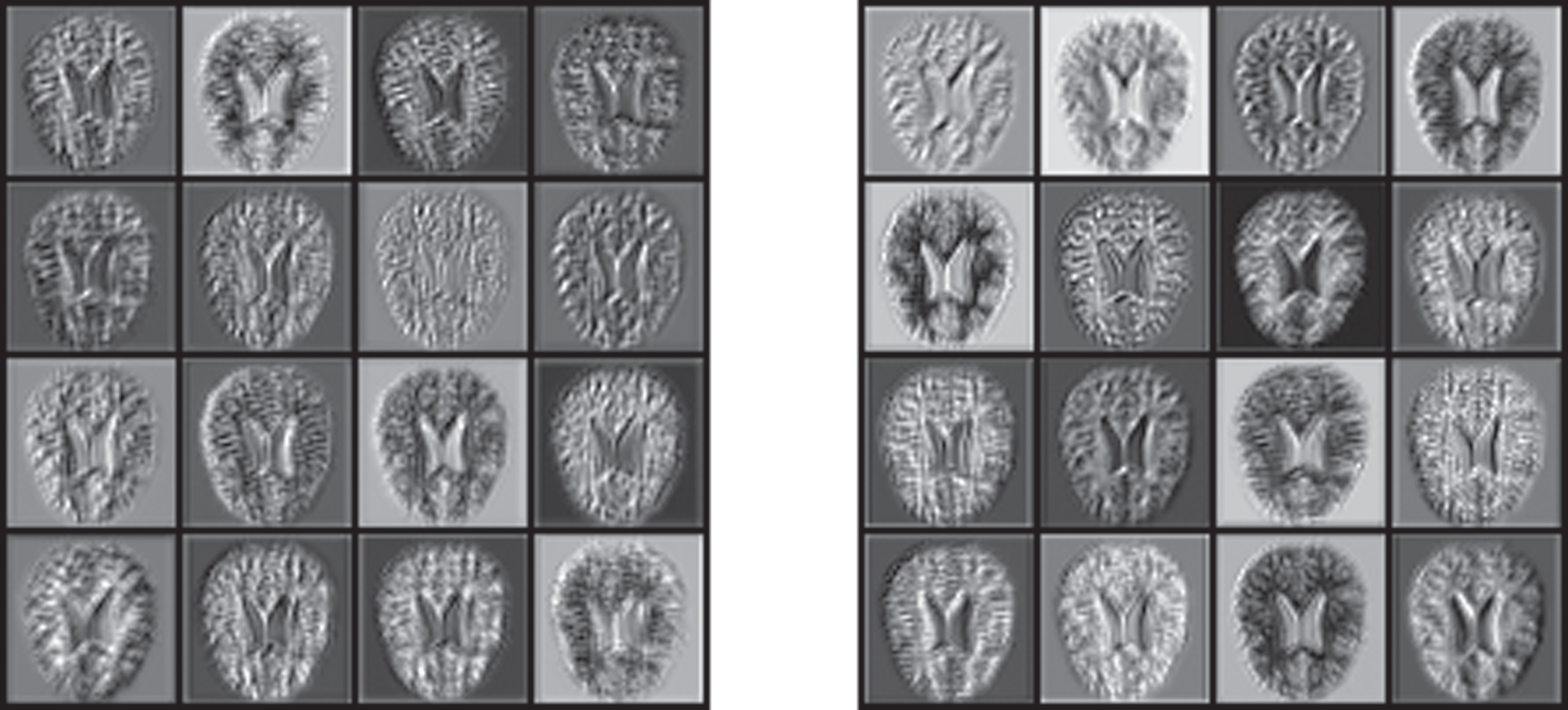
The feature maps of AD and HC MRI images in the 2nd layer of our network.
In Fig. 6, we intuitively listed the one of five confusion matrix figures on training and five confusion matrix figures on five-cross testing. For example, in the first testing confusion matrix, 628 of 640 AD images have correct prediction results, 627 of 640 HC images have correct prediction results, the total number of the correct prediction is 1255 with the accuracy of 98.04%. The classification accuracy of our method ranges from 97.26%to 98.59%, and the standard deviation 0.66 is relatively small, which indicates that our network has certain robustness. In addition, we compared the classification results of our network with several state-of-the-art methods, as shown in Table 2 (showing the corresponding average accuracy and standard deviation in brackets of 5-fold cross validation). It can be clearly seen from table 2 that our method is superior to other methods in the accuracy and recall rate of AD and HC classification. The accuracy rate of the network is 97.92%, the precision is 98.03%, the recall is 97.49%, and the f1-score is 97.91%, which is better than the best performance perception V4 (96.25%). Meanwhile, compared with resnet50 baseline (93.51%), the accuracy rate was significantly improved. Although the precision of our method is lower than that of Bhatele (99%), our f1-score is still reaching 98.03%, which indicates that the precision and recall in the classification index are relatively balanced. F1-score is the reconciling average of precision and recall. It indicates that our method has high recognition accuracy for both AD and HC symptoms.
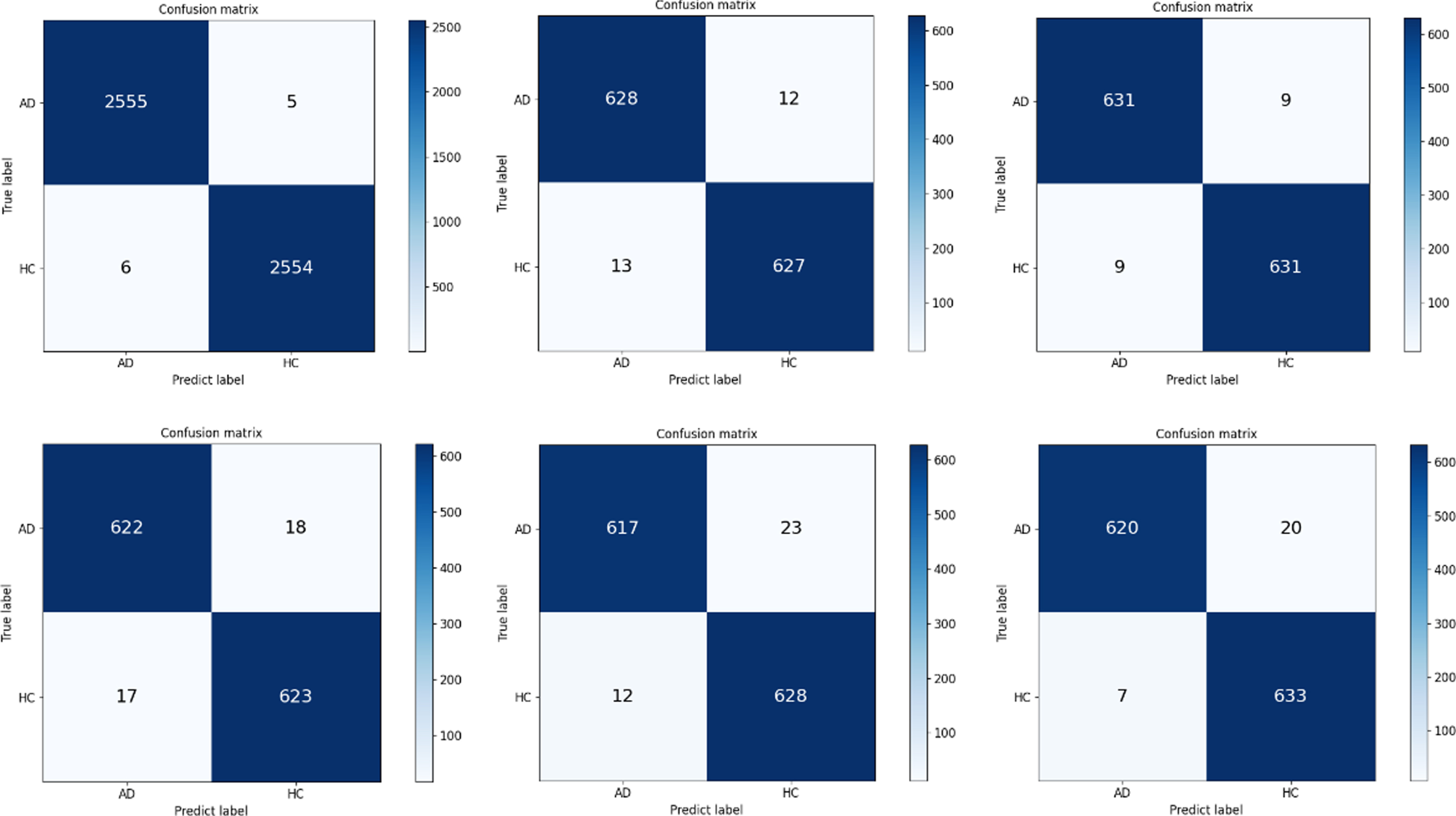
Confusion matrix of our network on training and testing sets.
Two-class classification performance of methods
In deep learning methods, many convolutional neural networks sacrifice the amount of computational costs in exchange for higher classification accuracy. It can be found from Tables 2 3 that our network achieves better classification performance, while FLOPS (2.89 G) and Weights (0.59M) are significantly smaller than other models, especially the Weights is dozens or even hundreds of times smaller. Our network is superior to other networks in all kinds of computational complexity, because the ghost module is more effective in using computational resources to generate feature maps. In our proposed network, the ghost module splits the original convolution layer into two parts, and uses fewer filters to generate some intrinsic feature maps. Then a certain number of cheap transformation operations are applied to generate the same number of feature maps as that of an ordinary convolutional layer efficiently, which greatly reduces the amount of calculation in the convolution process.
Comparison of classification model parameters
To sum up, we verified that the residual network has better classification effect in the baseline models through the experiments on OASIS dataset firstly. As can also be seen from the indicators in Table 3, in several classification network models, the residual network has a relative advantage. However, for this kind of small medical image dataset, the complex parameters of the network are more likely to appear overfitting, and the over complex computational parameters will also make a negative effect on the classification task. Such as the training parameters of VGG and other networks are too large. In addition, the large model is not conducive to the practical application in future. To this end, we have made improvements based on the residual network architecture to achieve better performance. During the convolution process, the classification network constructed by us generates the same feature maps as the ordinary convolution layer through ghost module to avoid feature redundancy, and the efficient linear operation greatly reduces the training parameters of the convolution network, which plays a necessary role in improving the classification accuracy. On this basis, we further adjusted the layers of ResNet block and achieved excellent performance in AD vs HC classification. Compared with the current CNN baseline models, the advantage of our method is to obtain excellent classification accuracy, and greatly reduce the training parameters of the convolution network, which makes the model lightweight and more effective.
Deploying CNN on embedded devices for AI medical is difficult due to the limited memory and computation resources. In this work, we proposed a lightweight network for AD classification by embedding the ghost module into the ResNet architecture. Through a series of linear operation principles of the ghost module, which can generate multiple expressive feature maps presentation over the original convolutional layer, our proposed method demonstrated superior performance on the OASIS dataset. With such a lightweight design and adjustment of the Resnet structure layers, our model achieved optimistic classification accuracy while requiring only less than half of the parameters and computational costs compared with other state-of-the-art methods, which provided a feasible reference lightweight network for further works on AD detection.
Footnotes
Acknowledgment
This paper was supported in part by Chengdu Major Technology Application Demonstration Project (2019-YF09-00120-SN).