
Abstract
In recent years, solving combinatorial optimization problems involves more complications, high dimensions, and multi-objective considerations. Combining the advantages of other evolutionary algorithms to enhance the performance of a unique evolutionary algorithm and form a new hybrid heuristic algorithm has become a way to strengthen the performance of the algorithm effectively. However, the intelligent hybrid heuristic algorithm destroys the integrity, universality, and robustness of the original algorithm to a certain extent and increases its time complexity. This paper implements a new idea “ML to choose heuristics” (a heuristic algorithm combined with machine learning technology) which uses the Q-learning method to learn different strategies in genetic algorithm. Moreover, a selection-based hyper-heuristic algorithm is obtained that can guide the algorithm to make decisions at different time nodes to select appropriate strategies. The algorithm is the hybrid strategy using Q-learning on StudGA (HSQ-StudGA). The experimental results show that among the 14 standard test functions, the evolutionary algorithm guided by Q-learning can effectively improve the quality of arithmetic solution. Under the premise of not changing the evolutionary structure of the algorithm, the hyper-heuristic algorithm represents a new method to solve combinatorial optimization problems.
Keywords
Introduction
The heuristic algorithm is a new type of computing mode with a strong search ability that is used to solve nondeterministic polynomial (NP) problems in various fields and has been actively implemented [1, 2]. Meta-heuristic scheduling involves algorithms such as the genetic algorithm (GA) [3, 4], particle swarm optimization (PSO) [5], and ant colony optimization (ACO) [6, 7]. It has been widely used in tasks such as task scheduling, control strategy, path planning, and multi-objective solving [8–10]. With the in-depth study of meta-heuristic algorithms, the defects of this type of algorithm have been gradually discovered (e.g., premature convergence to non-global optimal solutions, excessive search time, too much sensitivity to parameters, lack of effective iterative termination conditions). In general, to further exploit the advantages of this type of algorithm and avoid defects, researchers have improved some steps in the algorithm or combined the advantages of other algorithms’ strategies in the algorithm. For example, Khatib et al. [11] developed the GA and proposed the stud genetic algorithm (StudGA). The main improvement is that the best individual in the contemporary population (called the stud) is exchanged with the rest of the individuals at each time, which facilitates the rapid sharing of useful genetic information. The principle of StudGA algorithm is simple, and its optimization ability has been confirmed [12].
For some standard meta-heuristic algorithms, there are more reasonable strategies. For example, in the classical evolutionary GA, there are exchange methods such as single-point exchange and multi-point exchange in the chromosome exchange link. The use of these methods is reasonable for the entire algorithm in the optimization process; the difference is that the degree of exploration of the solution space is different. For the target problem, determining when to use a particular strategy is a combinatorial optimization problem. The hyper-heuristic algorithm starts from an empty solution, formulates control strategies or feedback values from the high-level expert level, and gradually establishes a feasible solution to the problem from a set of pre-prepared low-level construction heuristic algorithms (specific problem areas) [13]. In the heuristic algorithm of the low-level structure, different rational strategies are used to construct the low-level space, which reduces the space cost and time complexity of building the low-level area. This method is consistent with the evolutionary system of the algorithm, and it is easier to obtain better solutions than the original algorithm. In recent years, machine learning has become a research hotspot. Researchers hope to improve the problems that require human decision-making by using machine learning methods, making machines more “intelligent” and algorithm performance more “excellent” and achieving the lowest reduction in errors caused by social factors. The intensive learning method is based on unsupervised learning and is a trending research direction in the field of machine learning [14]. Among the methods, Q-learning [15] is widely studied and applied by researchers as a typical intensive learning method. The algorithm is based on Markov decision processes (MDPs) [16], which can effectively solve the problem of how agents make decisions in complex environments. In general, the Q-learning process uses the Monte Carlo method to train, obtain potential Q-values between different states, and finally make decisions based on the trained Q-table and the various states in which they are located. When the decision-making options are limited, the use of reinforcement learning methods to learn decisions under different scenarios (states) is reliable and stable. In general, if the system can switch states and has appropriate choices in different states, the relevant decisions are often better suited to the currentsystem.
Many researchers have conducted significant work on hyper-heuristic algorithms. For example, Wang Ling et al. [17] noted that coevolution has become an effective way to improve the performance of evolutionary algorithms, such as population coordination, proper coordination, algorithm coordination, strategy coordination, and human-machine coordination. In general, collaborative design methods, improvement points, and characteristic points often require a detailed analysis and a large number of experiments to verify, and they increase the complexity of the algorithm and consume more time. Islam et al. [18] used the Q-learning method to learn to use different dynamic voltage and frequency scaling (DVFS) techniques in different scenarios and relied on learning to provide enough technology to scene mapping, which was obtained on multi-core chips. A better solution for each indicator.
Choong et al. [19] proposed a heuristic architecture that uses the enhanced Q-learning technique to design a hyper-heuristic model automatically. Correctly, the Q-learning hyper-heuristic model is used to select the appropriate components. Finally, the proposed algorithm is validated on six benchmark examples. The experimental results show that the method is comparable with other models. To adapt to the dynamic software engineering environment, Shen et al. [20] proposed a multi-objective two-archive memetic algorithm based on Q-learning (MOTAMAQ) to actively re-schedule. The solves the problem of software project scheduling. In this paper, the Q-learning method is used to learn the most suitable global and local search methods in different software project environmental states. Finally, the experiment compares other heuristic algorithms, and the results show that the algorithm has better convergence and higher quality solutions.
Koulin and Anagnostopoulos [21] proposed a Tabu search-based hyper-heuristic algorithm (THH) to solve the resource balance problem under resource constraints. The algorithm uses a hyper-heuristic algorithm to control a group. A low-level heuristic modifies the priority of a selected activity by performing simple operations such as “replace” and “swap”. According to the application in three engineering examples, the algorithm has good resource optimization performance. Dokerog and Cosar [22] proposed a multistart hyper-heuristic algorithm (MSH-QAP) based on a grid for high-performance multistart. In the first phase of the algorithm, the most appropriate (meta) heuristic approximate optimal parameters are selected by using an adaptive parameter setting method for a given problem instance; in the second phase of the algorithm, if the optimal solution cannot be found, then parallel processing selects the best performing (meta) heuristic on the grid (its parameter settings are fine-tuned) and performs multiple starts to improve the quality of the solution. The experimental results show that the total deviation of the algorithm to solve the problem instance is 0.013 percent on average. Qian et al. [23] proposed a multi-objective hyper-heuristic algorithm (MOHH) for universality, which considers carbon emission factors in location routing problems and establishes carbon emissions and a multi-objective location routing problem (LRP) model that combines total costs. In the MOHH framework, LRP-related operations are constructed as low-level heuristics, and different high-level strategies are designed. Experiments show that the MOHH algorithm can better solve the multi-objective problem of LRP and can quickly find a better solution and improve the search efficiency and stability of the algorithm. Yao et al. [24] proposed a multi-objective hyper-heuristic framework for pedestrian path planning in smart cities. In the search framework, a set of low-level heuristic algorithms are designed to generate new routes, and the reinforcement learning algorithm is used to select better low-level heuristics to speed up the search. The experimental results show that the algorithm has a faster processing speed than other comparison algorithms, and a more than 80 percent Pareto optimal solution can be obtained in the large-scale road network.
The evolutionary algorithm is considered as a transition between different states in the time dimension, and different states have different decisions. In this way, the optimal determination between different states can be ascertained through the Q-learning method. Based on this design idea, this paper uses the Q-learning algorithm to learn the different strategies existing in the evolutionary algorithm (taking the StudGA algorithm as an example) and obtains a new type of selection that can guide the algorithm to choose the appropriate strategy for decision-making at different time nodes. Hyper-heuristic algorithm.
In this paper, we propose a new hyper-heuristic algorithm, a hybrid strategy using Q-learning on StudGA (HSQ-StudGA) combined with different strategies to solve the problems encountered in explaining the extreme values in the mathematical test function. The experimental results show that the StudGA algorithm guided by Q-learning can effectively improve the quality of the solution, provide a new combination method for the hybrid evolutionary algorithm to solve the optimization problem without changing the evolutionary structure of the original algorithm and help promote the development of hyper-heuristic algorithms moreintelligently.
The main contributions of this paper are as follows: First, to solve the optimization problem, a hyper-heuristic algorithm is proposed by combining the heuristic algorithm with reinforcement learning technology. Second, combining the advantages of a genetic algorithm and Q-learning, the HSQ-StudGA algorithm formed has a faster rate of convergence and can obtain higher quality solutions. Finally, since the environment of Q-learning decision is always changing, the problem of Q-value jitter is solved by using a greedy strategy.
The rest of the paper is organized as follows. The related work is introduced in Section II. The model framework is shown in Section III. The experiments and analysis are presented in Section IV. The conclusion is performed in Section V.
Overview of basic methods of genetic algorithms
A genetic algorithm is a computational model that simulates the natural evolution of Darwin’s biological evolution theory and the biological evolution process of the gene mechanism. It is a method to search for optimal solutions by affecting natural evolutionary processes. The genetic algorithm begins with a population. After initial generation of the population by encoding, according to the principle of survival of the fittest, the evolution of generations produces increasingly better approximate solutions in each generation and, according to the individual’s fitness in the problem domain, selects the individual and combines the crossover and mutation with the genetic operators of natural genetics to produce a new solution set. This process will result in a population of natural evolution such that the descendant population is more adaptable to the environment than the previous generation, and the best individual in the last generation population is decoded, which can be used as a problem to approximate the optimal solution.
Some hybrid algorithms based on open structures are described in [25] and are used in various fields. The genetic algorithm consists of several steps: initialization, selection, exchange, mutation, and optimal global convergence. The simple and widely used exchange operations are the following: single-point exchange, double-point exchange, multipoint exchange, and uniform exchange [26, 27]. Different exchange methods should be adopted for different application scenarios. Khatib et al. [11] improved the GA and proposed the stud genetic algorithm (StudGA), which is mainly enhanced by using the best individual (called the stud) and the remaining individuals in each contemporary population. Exchange operations facilitate good sharing of useful genetic information. The principle of the StudGA algorithm is simple, and its optimization ability has been confirmed [28]. The genetic algorithm chromosome single-point exchange model is shown in Fig. 1. Specifically, a single-point exchange can be described as follows: in each round of a transaction, take two chromosomes as source chromosomes (also known as parent chromosomes), and exchange some of the genes on both sides of the exchange point to form new offspring. The two-point exchange process is based on the single-point exchange, taking two points to be exchanged, and selecting the middle part of the two chromosome interchanges for transfer. The process is shown in Fig. 2. Different from the above two exchanges, each gene of two chromosomes in the uniform exchange mode has the opportunity to exchange, which can also be called random transfer; the exchange process is shown in Fig. 3.

Model of single-point crossover.

Model of double-point crossover.
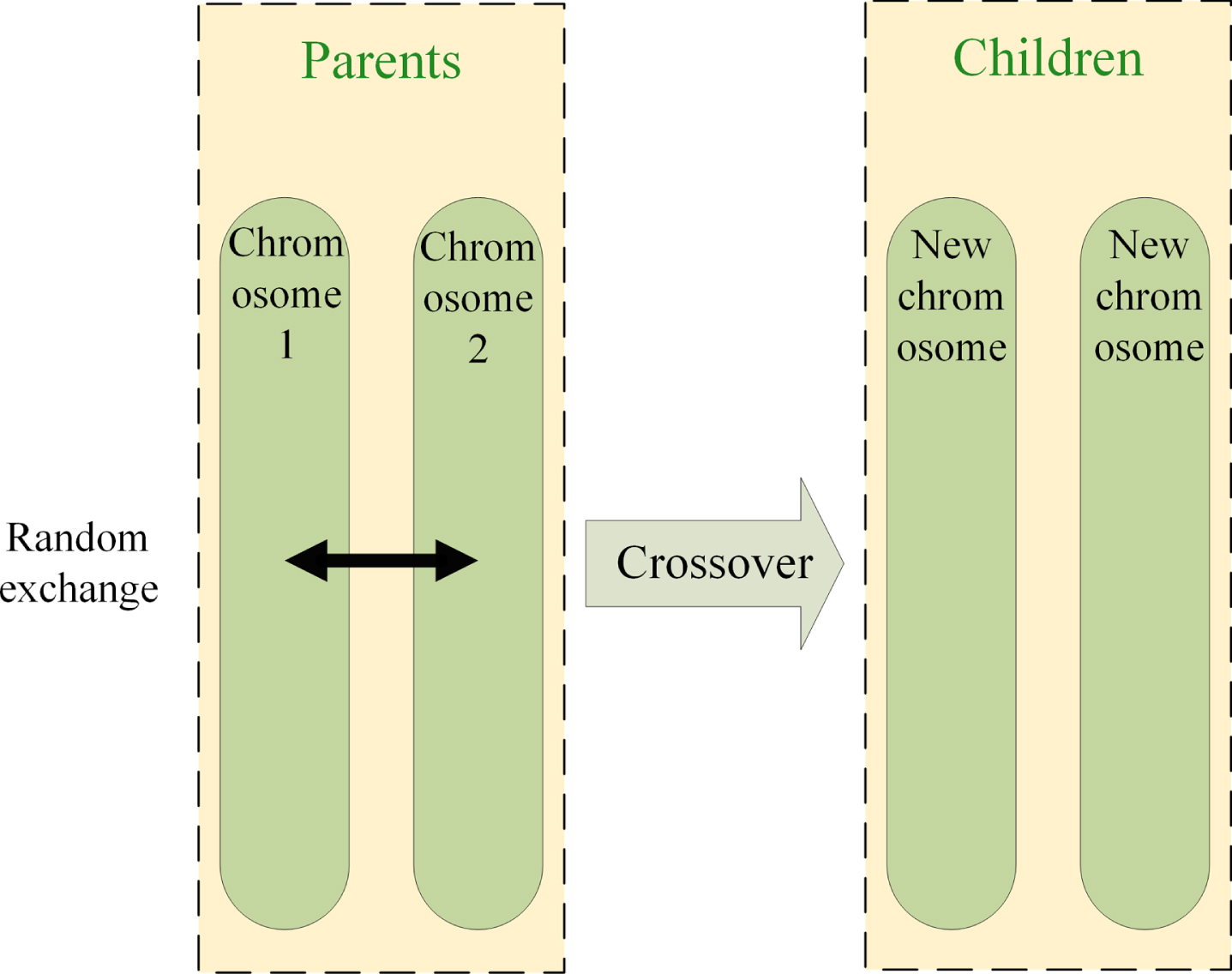
Model of uniform crossover.
At this stage, the most important macrotrend in machine learning is that the algorithm is gradually shifting from a supervised learning mode to an unsupervised learning mode.
The realization of most traditional machine learning relies on supervised learning. In other words, they are only useful when training with a large number of labeled training data. While supervised learning works well, the process of collecting and tagging large data sets is time-consuming, expensive, and error-prone. These challenges become more pronounced as the size of the data set increases. Based on the flaws of supervised learning, unsupervised learning methods have significant advantages because they do not require a large number of training data sets, do not need to be labeled and have excellent training effects. However, in real life, there is often a problem of the lack of sufficient prior knowledge, so the cost of manual labeling is too high. Therefore, this has prompted the machine learning algorithm to change from a supervised learning model to an unsupervised learning model. Q-learning is a typical unsupervised intensive learning method. Through continuous training and updating, the final Q-value is obtained.
Models
In this section, we first introduce the process of the genetic algorithm and the StudGA algorithm. Second, we describe the Markov decision process and Q-learning. Finally, we present the hybrid strategy learning model.
Model of genetic algorithm
The genetic algorithm consists of several steps: initialization, selection, exchange, mutation, and optimal global convergence. The primary process is shown in Fig. 4.

The process of the genetic algorithm.
The stud genetic algorithm formed by the improvement of the genetic algorithm is to exchange the best individuals (called the stud) in the contemporary population of genetic algorithms with the remaining individuals. The pseudocode of the standard StudGA algorithm containing exchange and mutation operations is shown in Algorithm 1:
Markov decision process
Markov decision processes (MDPs) refer to decision makers using Markov theory for optimal decision-making by observing continuous or periodic stochastic dynamic systems [29–31].
Agents in the environment only make decisions based on the state of the current situation and do not rely on historical information. The agent can observe its own state at each moment and choose a possible action to reach the next state. The symbols used in this section are defined in Table 1.
Notations
Notations
MDPs can be defined as a four-tuple of the form < S,A, P a , R a >, with S representing a set of states of the environment, A representing a set of available actions, P a representing a probability of making an action in the current state to reach the next state, R a representing a feedback function, and R(s,a) representing a feedback value obtained after the state performs the action.
When executing MDPs, the total reward value for the current action can be calculated:
If considering the composition of the total reward value in the time dimension, the total reward value at the current time t is:
In the dynamic random environment, the influence of the future on the decision at the present moment tends to be smaller as time goes by, so the above equation (2) plus the discount factor can be expressed as:
The finishing equation (3) can be expressed as:
The action that obtains the optimal decision in the current state is the action with maxRt+1.
Q-learning is an intensive learning framework based on MDPs that can make optimal action decisions in a limited MDP environment. The working mechanism is continuous trial and error in the background, and by obtaining a reasonable feedback value, the Q-value of the state that arrives after performing different actions is learned, and the final converged Q-table is obtained. In a given state, the agent queries the Q-table for the maximum Q-value of the current state and performs the corresponding action. The Q-learning model includes an agent, a rule set S, and an available state action set A, and all learned information is stored in the Q-table.
The agent makes the action aɛA according to the value in the Q-table. The update process of the Q-value is based on the Monte Carlo estimation method, that is, by simulating random selection, selecting the appropriate rule to obtain the feedback value, then choosing the proper round learning rate through the accumulated return of each round, and calculating the arrival to the next state. The possibility exists to update the current state to an estimate of the future state.
The variable learning ranges from [0-1], which controls the learning weight per round. The closer the value is to 0, the more the agent pays attention to the current reward. Conversely, the closer the cost is to 1, the more the agent pays attention to the future reward. The Q-learning update formula is shown in equation (5):
The pseudocode form of the Q-learning algorithm is shown in Algorithm 2:
Learning process of HSQ-StudGA model
In the critical operations of evolutionary algorithms to explore the solution space, the exchange operation of the algorithm is the most effective means to explore the solution space. According to the introduction in the previous section, this paper takes the StudGA algorithm as an example.
The use of the Q-learning method must clarify the representation of the current state. In the StudGA algorithm, this paper uses the time plus action as the state of the current exploration. In the different exchange modes of StudGA, this paper chooses three exchange modes that perform well and are simple to implement, namely, single-point crossover, double-point crossover, and uniform crossover; they represent three different actions, and the three actions are numbered 0, 1, and 2. Thus, the current state s1 can be expressed as s1 = (1, 0), indicating that the current algebra is 1, the action is 0. Assuming that the time (evolution algebra) is 100 and the action space is 3, the size of the solution space s is approximately 333 (the next state at time point 1 can only go to time point 2). The maximum number of different states is 100 × 3. It can be known that the size of the Q-table is (300 × 300), which is within the acceptable range of computer storage and calculation.
The Q-learning algorithm is in the stage of acquiring environmental information, and the most important thing is to obtain enough random states as input. Appropriate feedback values can capture the process of securing decision values in different states in the process of trial and error and the optimal decision in different states. In the hybrid strategy, after the current agent selects the action, the two chromosomes adopt the corresponding exchange mode according to the chosen work. According to the optimal cost value obtained by the current algebraic exchange, an appropriate feedback r value is received, and the feedback value is directly related to the optimal amount of each round. The algorithm proposed in this paper uses the offline learning method to obtain enough training data from the solution space for training the Q-table. To facilitate the convergence of the numerical function, the design of the feedback value is as follows: the slope of the optimal solution of each generation is greater than the slope of the optimal solution of the previous generation. Thus, from the current state s, action a is made, the feedback value r is obtained, the next state s′ is observed, the Q-table is updated using equation (5), and the update operation is completed. The update process is shown in Fig. 5.

Learning process of HSQ-StudGA system.
Without loss of generality, this paper proposes a model designed to have multiple options, as shown in Fig. 6. In the figure, the set E(1...n) represents an optional policy set, E1 represents the first feasible strategy, n possible approaches constitute a viable policy set, and the set P(1...m) represents all chromosomes, where P1 represents a chromosome of sequence number 1.

Model of HSQ-StudGA algorithm.
The pseudocode form of the HSQ-StudGA algorithm is shown in Algorithm 3.
In this section, we mainly describe the experimental setup and conduct the experimental analysis.
Experimental setup
The system running environment used in this article is Windows 10, and MATLAB 2016b is used as the test platform.
In [32], the performance of the BBO algorithm is verified. The specific parameters of the comparison algorithm used in this paper are consistent with the settings in the paper. Some parameters of the standard StudGA algorithm are shown in Table 2. It should be noted that from the experimental results in [33], the effect of using the uniform exchange method in the exchange part of the StudGA algorithm is better than that obtained by using several other exchange methods. Therefore, to ensure the objectivity of the algorithm, this paper uses the uniform exchange method used in the standard algorithm and implements it in the StudGA algorithm.
Benchmark functions
Benchmark functions
In this experiment, the performance of the proposed algorithm is tested using a wide range of 14 standard test functions [34–37]. The names and some parameters of these functions are shown in Table 2.
Q-table convergence
The environment in which Q-learning decisions are used is always evolving, which increases the instability of the system. Using the extensive trial and error method (completely random selection strategy), the Q-values of the two states are always in the jitter state. A wide greedy strategy approach –Q (e . g . , ɛ - greedy, ɛɛ (0, 1)) is used to eliminate this problem. The StudGA algorithm used in this paper has the same parameters as those in the Simon paper. The function labeled f14 in Table 3 is used as the test function for 200 generations of training. The comparison of the Q-value changes of a row in the Q-table is shown in Fig. 7. It can be seen from the figure that both algorithms start to converge from approximately 50 generations. Since the random action is always used in Fig. 7, the Q-value is always in the jitter state. As seen from Fig. 8, when the two algorithms use the greedy strategy, the random actions are stopped at approximately 70 generations. The Q-value tends to be stable. Therefore, this experiment proves that the greedy strategy can effectively accelerate the convergence of Q-values and can increase the stability of the system when the feedback value is unstable. To ensure the objectivity and fairness of the comparison results, the algorithm proposed in this paper also uses the parameters given in Table 3.
Experimental parameter settings
Experimental parameter settings

Strategies with random action selection.

Strategies with greedy action selection.
Some test functions f03 and f09 were randomly selected, and the convergence experiments were carried out under the condition that the evolutionary algebra was 50 generations. Each algorithm was run ten times, and the average value was taken. The convergence under test functions f03 and f09 are shown in Figs. 9 and 10, respectively.

The convergence rate comparison for f03.

The convergence rate comparison for f09.
Figure 9 depicts the convergence of the HSQ-StudGA algorithm and the StudGA algorithm within 50 generations under the test function f03. As shown, the cost result obtained by the HSQ-StudGA algorithm rapidly drops to a small value within the first 5 generations, starts to flatten in the 20th generation, and basically reaches a convergence state. Additionally, the cost result of the StudGA algorithm.
The rate of decline is significantly slower until the 45th generation converges to essentially the same results as the HSQ-StudGA algorithm.
Figure 10 depicts the convergence of the HSQ-StudGA algorithm and the StudGA algorithm within 50 generations under the test function f09. As seen, the HSQ-StudGA algorithm has a faster convergence speed in the first 20 generations and tends to converge in the 40th generation; the StudGA algorithm has a relatively slow convergence rate. This experiment shows that HSQ-StudGA has better convergence than the traditional StudGA algorithm.
The primary purpose of this experiment is to show the performance improvement of the hybrid strategy compared to the original algorithm. The evolutionary algebra is selected for 50 generations, and each algorithm runs 50 times under each objective function and is averaged.
Table 5 shows a comparison between the traditional optimal solution and the low historical optimal solution of the HSQ-StudGA algorithm and the StudGA algorithm. As seen from Table 4, all data are normalized, and the minimum value is set to a value of 1.
Comparison with HSQ-StudGA and StudGA for the best solution and mean minimum solution
Comparison with HSQ-StudGA and StudGA for the best solution and mean minimum solution
Results of benchmark functions for the best solution
It can also be seen from the detailed comparison data of the average historical optimal solution in Table 4 that HSQ-StudGA has achieved nine optimal results in the traditional optimal solution and six in the standard historical optimal solution. From the fluctuation of each of the two deviations from the superior value, HSQ-StudGA has better stability, which shows that when using the Q-learning algorithm to learn two strategies, the two strategies are complementary, thus enabling stronger exploration ability and stability.
Finally, this paper selects a variety of metaheuristic algorithms, such as ACO, BBOS, and ES algorithm, to conduct a detailed evaluation of HSQ-StudGA performance. As seen from Table 5, the HSQ-StudGA algorithm has obtained seven optimal solutions, accounting for half of the entire test algorithm. Due to its inherent advantages, StudGA also has four optimal solutions. The other three optimal solutions are ACO with two optimal solutions and BBO with one optimal solution. From the perspective of the optimal solution distribution, HSQ-StudGA’s ability to explore the optimal solution is significantly stronger than that of other algorithms, further verifying the strength of the hybrid strategy algorithm to investigate the optimal global solution. From the degree of deviation of the normalized value, HSQ-StudGA is significantly better than StudGA in each test set, which shows that the former is more capable of exploring the optimal solution.
Table 6 presents a comparison of the average historical optimal solution. As seen in the table, the performance of HSQ-StudGA and StudGA is the same. The results show that HSQ-StudGA also ensures the stability of the algorithm while achieving the optimal solution. Finally, in terms of the total time normalization result of the given CPU running all test sets, HSQ-StudGA is slightly inferior to StudGA in terms of running time because it needs to find a decision from the Q-table.
Results of benchmark functions for the mean minimum solution
The hyper-heuristic algorithm is a combination of multiple heuristics or multiple strategies and operations for optimization, and its hybrid strategy design is very critical, and the design corresponds to different problems. To solve combinatorial optimization problems, this paper combines the characteristics of Q-learning and evolutionary algorithms and learns the different strategies existing in the evolutionary algorithm through the Q-learning algorithm. A Q-learning-based heuristic algorithm HSQ-StudGA is proposed. This also allows HSQ-StudGA to acquire skills in interacting with the environment and learning from experience.
In the HSQ-StudGA model, by learning different reasonable policies in the StudGA algorithm, an adaptive hyper-heuristic algorithm that can guide the algorithm to select appropriate strategies for decision-making at different time nodes is obtained. In the experiments, there are 14 standard test functions in StudGA for Q-learning to choose to learn. HSQ-StudGA compares the best solution, the average minimum solution, and the average historical optimal solution with StudGA, and compares the performance with other metaheuristics ACO, BBOS, and ES. The results show that the proposed hyper-heuristic algorithm has a faster convergence speed and can achieve higher quality solutions. Meanwhile, the super heuristic algorithm also improves the search capability of the original algorithm solution and effectively improves the overall quality of the solution.
In the next step, we will enhance the stability of the training process, use more detailed reference values as the states, increase the number of states, further improve the quality of the solution, and apply the method to an actual problem.
Footnotes
Acknowledgment
This work was supported by the Program of National Natural Science Foundation of China (Grant Nos. 62072174, 61502165, 61602170), the National Natural Science Foundation of Hunan Province, China (Grant No. 2020JJ5370).