
Abstract
Model pruning aims to reduce the parameter amount of deep neural networks while retaining the performance. Existing strategies often treat all layers equally and all layers simply share the same pruning rate. However, it is observed from our experiments that the redundancy degree differs from layer to layer. Based on this observation, this work proposes a pruning strategy depending on the layer-wise redundancy degree. Firstly, we define the redundancy degree for each layer by the norm and similarity redundancy of filters. Then a novel layer-wise strategy, Redundancy-dependent Filter Pruning (RedFiP), is proposed which prunes different proportion of filters at different layers according to the defined redundancy degree. Since the redundancy analysis and experimental results of RedFiP show that deeper layers need fewer filters, a phase-wise strategy, Phased Filter Pruning (PFP), is proposed that divides the layers into three phases and layers in each phase share the same pruning rate. The phase-wise PFP allows the layer-wise RedFiP to be easily implemented in existing structures of deep neural networks. Experimental results show that when total parameters are pruned by 40%, RedFiP outperforms the state-of-the-art strategy FPGM-Mixed by 1.83% on CIFAR-100, and even slightly outperforms the non-pruned model by 0.11% on CIFAR-10. On ImageNet-1k, RedFiP (30%) and PFP (30%) outperform FPGM-Mixed (30%) by 1.3% and 0.8% with ResNet-18.
Introduction
Deep convolutional neural networks (CNNs) have been widely applied in many computer vision fields including face recognition, object detection, instance segmentation, etc. In general, CNNs containing more layers and/or kernels have a stronger feature learning representation ability, and hence perform better on many tasks, such as image classification and object detection. A variety of deeper and wider architectures [1–3] have been designed for better feature learning representation ability [4–6]. In these architectures, two hyperparameters are often manually set: the number of convolutional layers and the number of filters at each layer, i.e., the width and depth of the deep models. Since deeper and wider models generally have a better generalization, both parameters tend to be manually set to larger numbers.
Nevertheless, many reported results show that an excessive number of parameters are actually not necessitated, i.e., part of parameters are redundant and of little importance for extracting meaningful features. Denil et al. [7] demonstrated that there is significant redundancy in CNNs which are over-parameterized. For example, ReLU converts some units of feature maps to zero. This amounts to deactivating the units of filters [
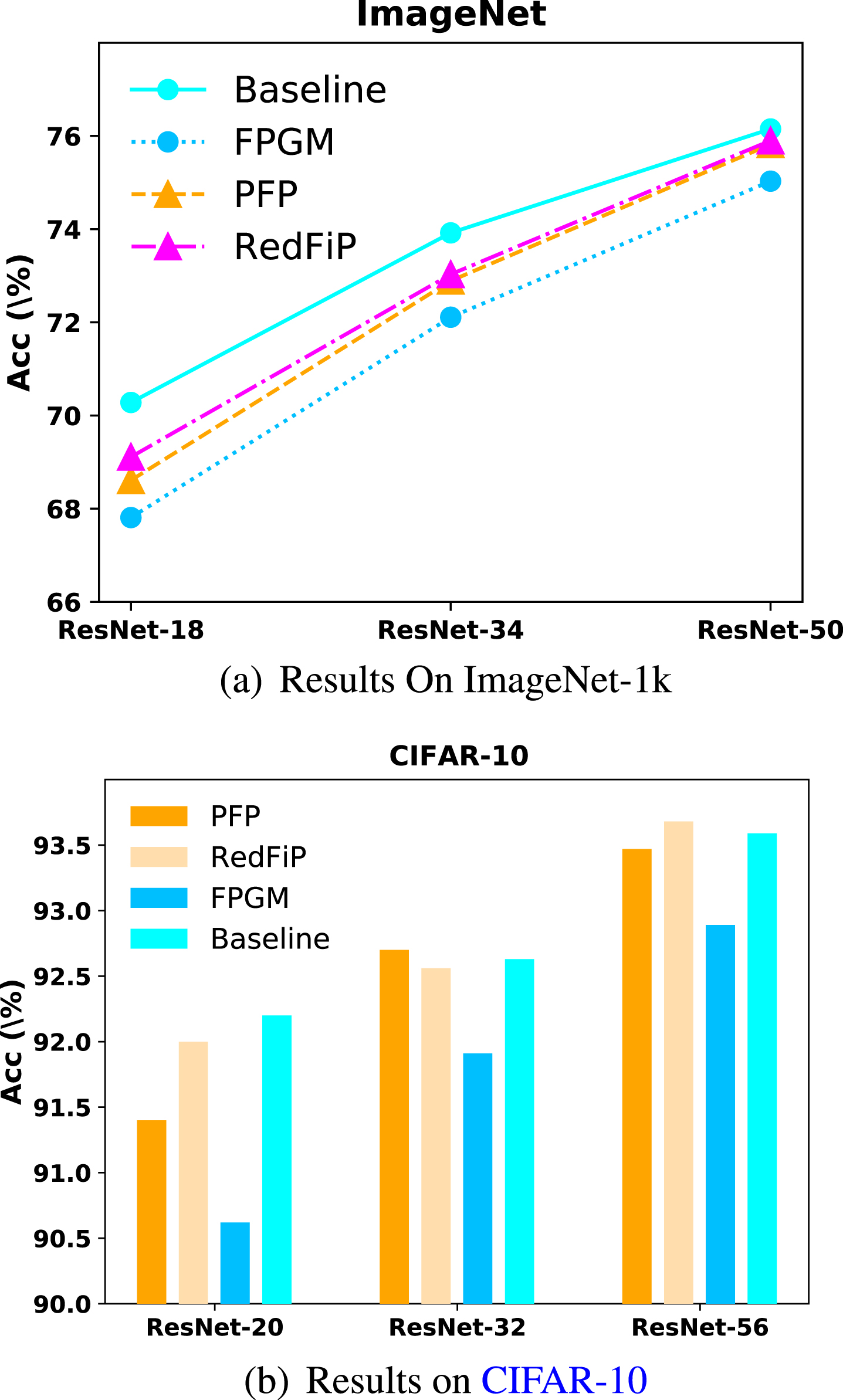
The results of the proposed pruning strategies, RedFiP and PFP on ImageNet-1k and CIFAR-10. (a) On ImageNet, PFP outperforms the state-of-the-art FPGM [9] by about 0.8% without finetune. (b) On CIFAR-10, RedFiP and PFP even outperform the baseline for ResNet-32. The figure is best viewed in electronic form.
Seeing much redundancy in very deep CNNs [10], Jonathan [10] proposed that pruning technologies can drastically reduce the total parameters of CNN architectures, making them lighter at the cost of little performance drop. Also, pruning technologies have improved the practicability of deep CNNs as they demand less computational and storage resources. Pruning is becoming an active research direction that can help people explore the importance of components and understand the inference mechanism of CNNs.
The existing pruning methods can be divided into three categories. The first category adds regularization terms in loss functions to reduce the dimensionality of network parameter spaces. The second category adopts Network Architecture Search (NAS) for getting the appropriate pruned architectures, to find the most compact models by reinforcement learning and greedy algorithms. The third category directly prunes components and filters of CNNs according to the criteria measuring the their importance. These three categories will be introduced in Section 2.
This paper focuses on the structured component pruning methods because the pruned components can be readily dropped instead of zero-valued setting of the redundant neurons in many unstructured pruning methods. This means that the structured methods can be used in practical applications. Also, the study on structured component pruning technologies helps understand the inherent logic of deep convolutional neural networks.
However, as stated in Section 2.3, one drawback of the structured component pruning method is that the designed criteria treat the filters in different layers equally. They implicitly assume that all filters or layers have an identical importance (contribution) to the whole architecture. However, different layers actually are responsible for extracting different abstract levels of information, and thus the redundancy degree may also differ from one layer to another. Observing this, we aim to develop a pruning scheme that reduces a varying number of filters at each layer according to its redundancy.
To more effectively suppress the redundant kernels at different layers, we firstly analyze the redundancy degree of each layer, and then propose the Redundancy-dependent Filter Pruning (RedFiP) strategy according to the redundancy of each layer. Our analysis shows that the redundancy degree of the shallow layers is significantly lower than middle and deep layers, and hence the shallow layers are more improper to be pruned. The shallow layers are typically responsible for extracting low-level features such as edge, contour, and gradients, etc., and various low-level features are important for deeper layers to generate certain abstract features for specific tasks. As shown in Fig. 1(a), RedFiP outperforms the SOTA pruning strategy, FPGM, by a lot.
According to the redundancy analysis and experimental results shown in Section 3, we observe that filters in deep layer are more suitable for being pruning than those in shallow layers. Seeing this, we further present the Phased Filter Pruning (PFP) strategy to simplify the implementation of RedFiP. PFP divides all layers into three phases, and the layers within each phase share the same pruning rate instead of the original layer-wise pruning rate.
In addition to the implementation simplicity, another advantage of PFP is that deep layers generally contain much more filters and filter channels than shallow layers, and hence a larger pruning proportion in deep layers reduces more parameters of the whole model. For examples, for ResNet20 with three phases (16, 32, and 64-channel kernel per phase), phase 1 (layer 1 ∼ layer 7) and phase 3 (layer 14 ∼ layer 19) contain 5.25% and 75.8% parameters of the whole model. Therefore, PFP can prune more parameters than the existing methods while maintaining the performance of pruned networks. PFP can be readily applied to any architectures, especially the architectures containing a larger number of layers. The highlight results of PFP are also shown in Fig. 1(b).
It is worth mentioning that, when the smallest-norm criterion is used to prune filters, unlike [11], RedFiP explores the effect of pruning different proportion filters in different layers during training stage (i.e., soft pruning proposed in [12]) instead of after training (i.e., hard pruning). Also, [11] pruned both the m filters of the smallest norms and their corresponding output feature maps, i.e., they will not be used by the kernels in next layer. Unlike [11], RedFiP preserves these feature maps and still uses them in the convolution process in next layer. This means RedFiP prunes the filters in different layers independently, which is simpler than [11]. In addition, this work employs the largest-similarity criterion together with the smallest-norm criterion [9]. Only the smallest-norm criterion may prune the filters of smaller norms but important for the whole structure, leading to notable performance decrease in some cases.
The contributions of our proposed strategies are summarized as follows. The redundancy of a layer is defined that encodes how much fraction of each layer can be pruned. Then Redundancy-dependent Filter Pruning (RedFiP) strategy is proposed that prunes filters by a varying fraction depending on their redundancy. Experiment results show that RedFiP outperforms the smallest-norm [11, 12], largest-similarity and their combined criteria (used in [9]), which treat equally all kernels of different layers. A simpler phase-wise pruning strategy, Phased Filter Pruning (PFP), is proposed that divides layers into three phases and the layers within each phase share the same pruning rate. The PFP is much easier to be applied to the existing architectures such as ResNet and still outperforms the state-of-the-art strategies by a large margin. The redundancy analysis and experimental results show that there are more redundant kernels in deep layers than in shallow layers. It indicates that a sufficiently large number of various kernels in charge of extracting low-level image features play an indispensable role for generating high-level semantic information.
Regularization
Many researchers focus on designing different regularizations to reduce the dimensionality of network parameter space. Han et al. [13] simply added L1 and L2 norm of all parameters in loss function to get more parameters close to zero. Louizos et al. [14] proposed L0 regularization to reduce the parameters and learn a sparse neural network. L0 regularization term encourages the weights of some filters to be exactly zero. Alvarez et al. [15] designed a regularization item to learn the number of neurons. A group of sparsity regularizations on the parameters were used to make the overcomplete network more compact and sparse by sufficiently employing structured sparsity.
NAS-based strategies
In 2018, AMC [16] was proposed to use the learning-based pruning policy by NAS instead of the conventional rule-based policy. Following [16], many NAS-based methods were proposed. Yu et al. [17] proposed a simple and one-shot method, named AutoSlim, to get better performance under the fixed constrained resources (e.g., FLOPs, model size, etc.). Instead of training a lot of architectures for finding the the best architecture by reinforcement learning, a simple slimmed architecture is trained to achieve network accuracy of different channel configurations. Dong et al. [18] proposed TAS applying a differentiable NAS method to search directly for a network with flexible channel and layer sizes to break the architecture limitation. Furthermore, Wang et al. [19] proved that a pre-trained model is not necessary and a fully-trained over-parameterized model will reduce the search space for the pruned structure. Furthermore, Meta-Learning is also applied for model pruning. Liu et al. [20] proposed a method based on Meta-Learning to generate the weights of pruned networks.
Component Pruning strategies
The key of component pruning is to measure the importance of the pruned components. Many criteria measuring the importance of network components were proposed. Hertz et al. [21] proposed a weight importance measuring criterion according to the magnitude of the weights. Variant magnitude measures were subsequently proposed, e.g., the weights and filters are pruned according to their L2 or L1 norm [11, 12].
Hassibi et al. [22] proposed a strategy that measures the importance of each weight by its second order derivative. Joseph et al. [8] used the gradient norm [23] to measure the importance of each filter and evaluated the impact of a filter on error. He et al. [24] proposed an iterative two-step algorithm to select pruned channels based on LASSO regression. He et al. [9] proved that the criteria only measuring the norm are not suitable for all situation. They proposed a novel largest-similarity criterion to measure whether a filter is ‘replaceable’ or not, instead of measuring the usefulness of the filters only according to the norm.
Besides the importance of filters, Wang et al. proposed that identifying structural redundancy plays a more essential role than importance measuring. [25] verified that pruning in the layer(s) with the most structural redundancy outperforms pruning the least important filters across all layers. Moreover, He et al. proposed LFPC [26] to learn the filter pruning criteria for replacing the handmade criteria and achieving adaptive pruning criteria. Gao et al. proposed a performance prediction network [27] to directly guide the channel pruning via the pruned sub-network performance.
Recently, dynamic channel pruning technology [28] becomes more and more popular. The structural pruned channels should be dependent on the input samples. Liu et al. proposed a novel method [29], which focuses on the difference between sample, to learn the instance-wise sparsity adaptively. The informative features for different instances are identified. Furthermore, Tang et al. proposed ManiDP [30] to remove redundant filters by aligning the recognition complexity and feature similarity between images.
Method
This section represents the proposed RedFiP and PFP strategies for effectively pruning filters at each layer. Contrary to the general understanding of filter redundancy, we will show that the deep layers have higher redundancy degree. We firstly define redundancy of norm and similarity. Then the definition will be used to analyze the layer-wise and phase-wise redundancy pattern across the whole networks. The common stacked convolutional neural networks and ResNets [1] are used in our analyses. According to the redundancy pattern, RedFiP and PFP are proposed. These two strategies are visualized in Fig. 2.
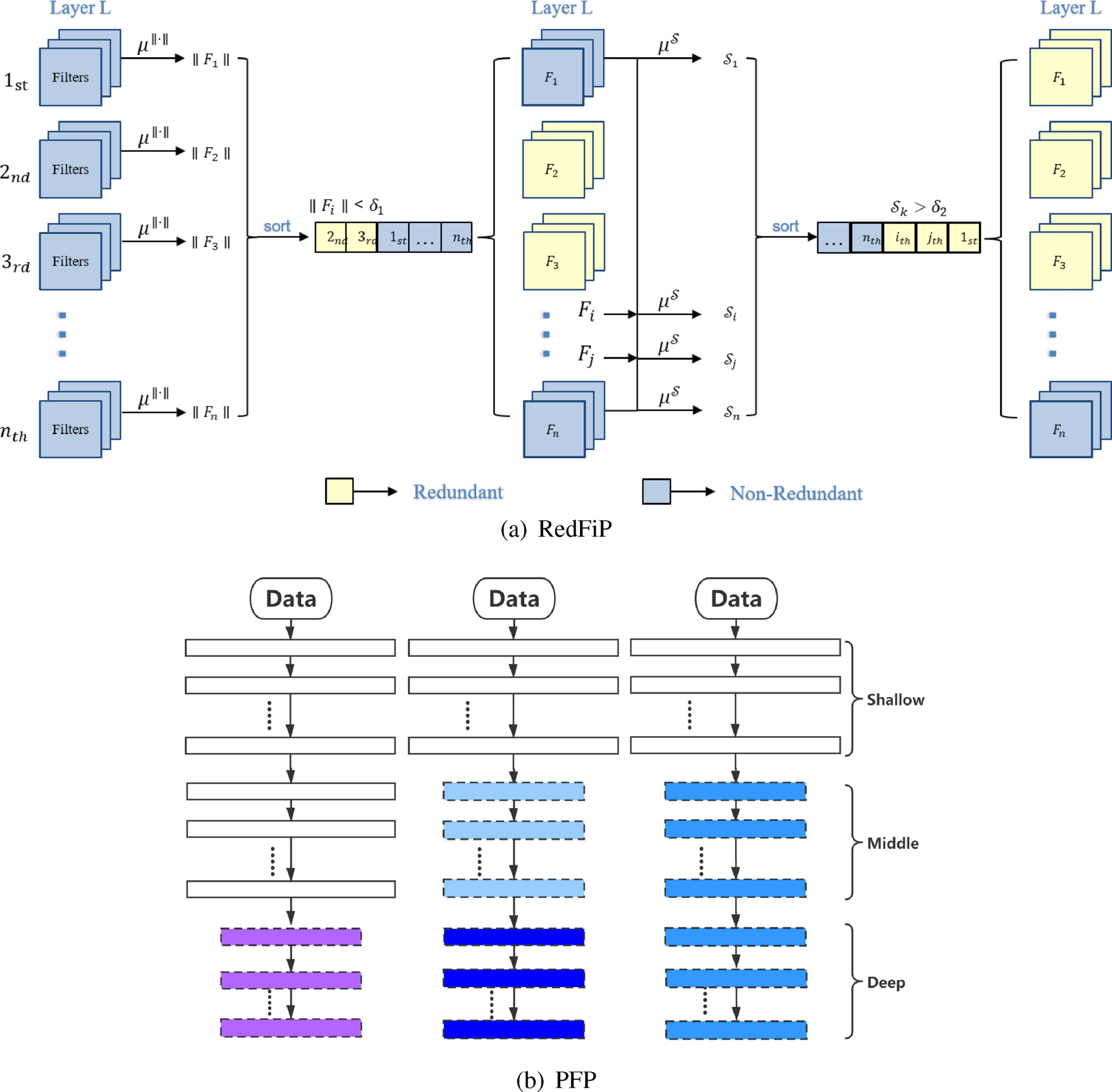
The filter redundancy and the proposed strategies. (a) RedFiP strategy. For each layer, the redundancy degree is computed based on the norm and similarity of filters, and the pruning rate is determined by the layer-wise redundancy. (b) PFP strategy, the layers are divided into three phases and the filters within a phase share the same pruning rate. The larger the pruning rate is, the darker the color of this phase is.
Let N L denote the number of convolutional layers, and L i (0 ≤ i ≤ N L - 1) represents the i th layer. To define the redundancy of the L i layer, we firstly define the redundancy of each filter Fi,j in L i , where 0 ≤ j ≤ N i - 1 and N i is the filter number of L i . A step function is to encode the filter-wise redundancy of target networks to analyze the redundancy pattern across the whole networks. The responding value δ of the step function is determined by the target parameter pruning (such as 30% parameters of the whole network) or the value of acceptable performance drop. These two values are preset by the pruning tasks.
The norm redundancy of Fi,j is defined as
Finally, the redundancy of the whole architecture is defined as the summation of the redundancy of every filter over all layers, formally
The redundancy degree defined in Equation (3) can represent that of three pruning criteria: norm criterion, similarity criterion, and their combined criterion. In Equation (1) and (2), except pruning task requests, δ1 and δ2 are also experimentally determined to find a good trade-off between smallest-norm and largest-similarity criteria. This is still an open question in [9], which proposed largest-similarity criterion and used it combined with smallest-norm criterion to get a better performance. δ1 and δ2 typically take the value in ranges [0.5, 0.7] and [0.9, 1] for ResNet-20 on CIFAR-10 respectively, and more details can be seen in Section 4.1. It is worth mentioning that the proper values for the two thresholds δ1 and δ2 change with the architecture of networks, the training datasets. In general, the larger the architecture, the larger the δ1 and the smaller the δ2, meaning a looser condition for defining a filter to be redundant in Equation (1) and (2).
This section will analyze the redundancy degree of filters and then prune the filters according to the redundancy. Since the redundancy of each layer may differ from another, one straightforward layer-wise strategy is to prune a proportion of filters at each layer according to the defined redundancy degree. Alternatively, a simpler strategy that is much easier to be implemented in existing architectures will be discussed in Section 2.3.
To see how much the redundancy exists, we build a generic CNN architecture of 20 layers composing of only convolutional layers, BatchNorm layers, and ReLU layers. We firstly analyze the norm redundancy of each layer when δ1 in Equation (1) is set to 1. For the norm redundancy of the first 8 layers, 17 filters are determined to be redundant, while 77 filters are non-redundant. The norm redundancy rate is 18.1%. The middle 6 layers have the norm redundancy 81, and the norm redundancy rate is 48.8%. As a comparison, the deep 6 layers have the norm redundancy 384, and the norm redundancy rate is 100%. Similarly, when δ1 is 0.8, the norm redundancy rate of shallow layers is 10.6%, while that of deep layers is 100%. When δ1 is 0.5, the norm redundancy rate of shallow layers is 10.6%, while that of deep layers is 97.4%. The norm redundancy patterns are visualized in Fig. 3(a) and Fig. 3(b).

The pattern of filter norm and similarity in a 20-layer convolutional neural network. In the norm pattern analyses (a, b, c), The blue bar represents the number of filters with their norms smaller than the threshold δ1, which means the number of filters can be pruned in this layer under the threshold δ1. And the pink bar represents the number of filters with their norms larger than δ1. In the similarity pattern analyses (d, e, f), The blue bar represents the number of filters with their similarities larger than the threshold δ2, which means the number of filters can be pruned in this layer under the threshold δ1. And the pink bar represents the number of filters with their similarities smaller than δ2. (a), δ1 is set to 1.0; (b), δ1 is set to 0.8; and (c), δ1 is set to 0.5; (d), δ2 is set to 1.3; (e), δ2 is set to 1.0; (f), δ2 is set to 0.8.
In some deep layers, the redundancy rate of certain layers may be as high as 100%. However, we cannot prune all filters of these layers convolutional neural networks. For such cases, we firstly select an appropriate threshold for the step function of previous layers, and prune a small proportion of shallow filters, e.g., 5%. For the norm criterion, the redundancy rate for the deep layers will become smaller than 90% [10] by decreasing the threshold of the step function. For examples, if the task requests 40% parameters of the generic CNN being pruned, the previous 13 layers prune 5% parameters of total model. Then the threshold has been reduced to make the redundancy of last six convolutional layers comprise the rest 35% of total parameters. For the similarity criterion, a similar result can be achieved by appropriately increasing the threshold δ2 in Equation (2). 90% is also a threshold for similarity redundancy rate for each layer.
Then, we continued to analyze the similarity redundancy defined in Equation (2). When δ2 is 1.3, the similarity redundancy rate of shallow layers is just 15.6%, while that of deep layers is 100%. When δ2 is 1, similarity redundancy rate of shallow layers is 6.25%, while that of deep layers remains to be 100%. When δ2 is 0.8, similarity redundancy rate of shallow layers is 0%, while that of deep layers is 100%. The similarity redundancy patterns are visualized in Fig. 3(c) and 3(d). The norm and similarity redundancy indicate that the deep layers have a much higher redundancy rate than shallow layers and so a higher proportion of filters can be pruned at deep layers.
To further verify the effectiveness of the defined norm and similarity redundancy, we conduct another kind similar analysis on ResNet-20 [1]. Fig. 4 shows the norm and similarity redundancy. Again, it can be observed that deeper layers contain much more redundancy than shallower layers. In fact, the redundancy results observed in our experiments are in accordance with what are reported in [31] that shows shallow layers usually need more filters to represent various features whereas deep layers need much fewer filters to represent the highly abstract semantic information. One possible explanation for these results is that deeper layers are gradually focused on the extraction of the semantic information about objects in an image as well as their location [32, 33]. This hence means that the non-object regions will require much fewer deep-layer filters.
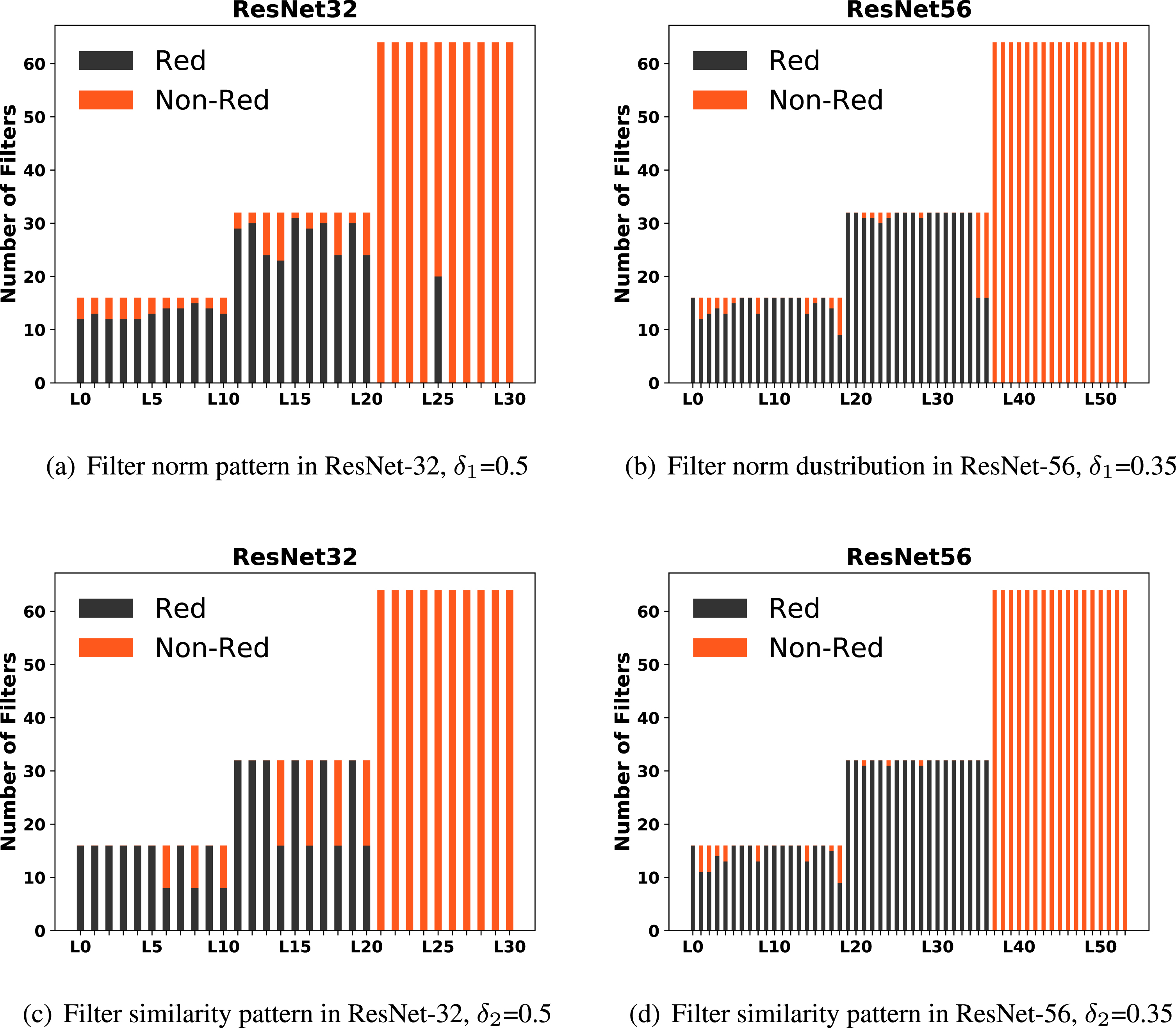
The pattern of filter norm and similarity in ResNets. The blue bar represents the number of filters with their norms / similarities smaller / larger than the threshold δ1 / δ2. The pink bar represents the number of filters with their norms / similarities larger / smaller than δ1 / δ2.
With the defined norm and similarity redundancy, this work presents a redundancy dependent pruning strategy, RedFiP, that prunes filters according to the calculated redundancy degree at each layer. RedFiP is shown in Fig. 2(a). The advantage of this strategy lies in that it is tailored for each layer and thus the layer-wise redundant filters will be pruned to the maximum degree under the requests of tasks.
Despite its advantages, RedFiP is relatively difficult to be implemented since the hyperparameters δ1 and δ2 in Equations (1) and (2) need to be finely tuned for individual networks and datasets. Also, δ1 and δ2 are carefully determined to ensure that not all filters in one layer are pruned, like the careful strategy described in Section 3.2. This can be quite cumbersome and require specific tuning skills. To facilitate the implementation, this work further proposed an alternative pruning strategy, Phased Filter Pruning (PFP), that divides all layers into three phases: shallow phase, middle phase, and deep phase for phase-wise pruning. Layers in the same phase share the same pruning rate in phase-wise strategy.
According to the redundancy degree calculated in Section 3.1, shallow layers responsible for extracting various low-level features can hardly be pruned. Middle layers conveying shallow features to the high-level semantic information have a little redundancy and can be partly pruned. Compared with shallow and middle layers, deep layers have a much higher redundancy degree and can be substantially pruned while the performance drops little.
The shallow phase contains fewer and more important filters than those in middle and deep phases according to the analysis in Section 3.2. PFP maintains all filters in shallow phase, while pruning severely filters in middle and deep phases. Each phase shares the same pruning rate instead of layer-wise determined strategy, RedFiP. As the example in Section 3.2, if only 50% filters in deep phase are pruned, the reduced parameters would comprise 32.9% of total model parameters. PFP is a phase-wise strategy and much simpler in the threshold selection aspect than the layer-wise RedFiP.
We evaluate the PFP strategy by designing three schemes shown in Fig. 2(b). The first scheme is to only prune the filters of the deep phase, as shown in the left column in Fig. 2(b). The second scheme is to prune the filters of the middle and deep phases by the same proportion. are pruned, as shown in the middle column in Fig. 2(b). The third scheme is also to prune the filters of the middle and deep phases, but the deep phase has a higher pruning proportion, as shown in the right column of Fig. 2(b).
In addition, another phenomenon is observed. The last layer’s high similarity may actively maintain the invariance of classification to improve the confidence of the right decision. This maybe provide another view of the reason why the ReLU neural network always produces the confidence so high [34].
Experiments
In this section, the proposed RedFiP and PFP strategies are compared with the norm-based strategies SFP [12] and MIL [35]. Also the similarity-based strategy FPGM [9] is used. The experiments are evaluated on datasets CIFAR-10, CIFAR-100, and ImageNet-1k [36]. We directly use the reported results of SFP, MIL, and FPGM in [9, 35] except the results of FPGM on CIFAR-100, which was not reported in [9]. To make the experimental comparison more complete, we evaluated the FPGM on CIFAR-100 with the code provided by [9]. The implementation of RedFiP and PFP are based on the source code of FPGM.
ResNet-20, ResNet-32, and ResNet-56 are adopted to serve as the baseline. ResNet-110 is not used since a large number of layers contain too many redundant filters for training on the small datasets CIFAR-10 and CIFAR-100.
ResNets are divided into 3 phases, and each phase contains (depth - 2) / 3 convolutional layers. The hyperparameters of all ResNets are similar to those of FPGM [9]. For PFP, Table 1 summarizes the three schemes devised to prune the filters of phase 2 and/or 3.
Description of different schemes for the PFP strategy
Description of different schemes for the PFP strategy
Inspired by the work [37], we train the networks from scratch and apply the soft filter pruning. SGD is used to optimize the training model and the initial learning rate is set to 0.01. The learning rate is divided by 5 when the training epoch equals 60, 120, and 150. Additionally, the warmed up [38] strategy is used. Decay is set to 0.0005 to make the network robust against noise.
For each experiment, we repeated 5 times to alleviate the effect of random initialization, and the 5-time average test accuracy is reported. The proposed RedFiP strategy is compared with FPGM and SFP, and the results are listed in Table 2. The results of the proposed PFP are listed in Table 4. To show the universality of RedFiP and PFP, we also apply them to VGG. The results on CIFAR-10 are given in Table 6. In Section 4.4, filters in shallow phase are severely pruned for ablation study.
Comparison between RedFiP and state-of-the-art strategies for ResNets on CIFAR-10 and CIFAR-100. The pruning strategies are listed in ‘Method’ column, the pruning rates of the total parameters are listed in parentheses. The values listed in ‘Acc ↓’ mean that the test accuracy errors between the pruned networks and the non-pruned networks
The combination of smallest-norm and largest-similarity criteria is used in RedFiP evaluation experiments, which is similar to pruning criteria FPGM-Mixed [9]. For simplifying the description, we use the form like RedFiP (30%) to represent that 30% of total parameters are pruning by the strategy RedFiP in the following sections. Table 2 gives the best results of RedFiP (40%), FPGM (40%), and SFP (30%) for ResNets of different layers on CIFAR-10/100. For ResNet-20, the RedFiP outperforms FPGM-Mixed and SFP by 0.91% and 1.17% in terms of the classification accuracy on CIFAR-10. On CIFAR-100, RedFiP (36%) outperforms FPGM-Mixed (30%) by 0.51%. Also, RedFiP (40%) outperforms FPGM-Mixed (40%) by 1.38%.
It is also worth noting that when 22% parameters are pruned by RedFiP, the pruned ResNet-20 achieves the test accuracy 92.23% on CIFAR-10, which is even higher than the non-pruned ResNet-20. This indicates the redundancy existence in the deep neural networks and verifies the benefit of the RedFiP.
Similarly, for ResNet-32 and ResNet-56, RedFiP (40%) achieved 0.68% and 0.79% accuracy improvements on CIFAR-10. Also, on CIFAR-100, 1.21% and 1.28% accuracy improvements are achieved for ResNet-32 and ResNet-56.
Phased Filter Pruning
This section presents the evaluation performance of the Phased Filter Pruning (PFP) strategy. For the implementation of pruning filters, we apply the smallest-norm and largest-similarity criteria to suppress filters at each phase. Let Rt i (n % , v %) denote the pruning rates at the i th phase with the smallest-norm and largest-similarity criteria. (n+ v) % means the total pruning rate in the i th phase.
Filters in different phases are pruned for Conv-20
To see the redundancy of different phases, we firstly build a simple stacked CNNs of 20 convolutional blocks. Each block contains a convolutional layer, a Batch Normalization (BN) layer, and a ReLU layer. The stacked 20-layer CNN is divided in 4 phases, and each phase contains 6 layers. We picked the 6 layers to be {, [2, 8] , [12, 18] , [14, 20]}. For each experiment, 40% filters of the corresponding phase are pruned by the smallest-norm criterion, and all layers in each phase share the same pruning rate. Table 3 gives the classification accuracies of the pruned models. Obviously, when the 4 th phase is pruned, the pruned model provides the best test accuracy even if it is pruned the most parameters. The simple comparison experiments verify that the deep layers contain more redundancy. Also, the pruned model provides 87.3% classification accuracy, which is higher than the baseline of non-pruned model.
Filters in different phases for Conv-20 on CIFAR-10
Filters in different phases for Conv-20 on CIFAR-10
Comparison between PFP and state-of-the-art strategies for ResNets on CIFAR-10 and CIFAR-100. The pruning strategies are listed in ‘Method’ column, the pruning rates of the total parameters are listed in parentheses. The values listed in ‘Acc ↓’ mean that the test accuracy errors between the pruned networks and the non-pruned networks
The scheme PFP-S3 only prunes filters in phase 3. In phase 3, 40% filters, which accounts for 30% of the total network, are pruned. Rt3 (10 % , 30 %) outperforms FPGM-Mixed (30%) by 0.67% for ResNet-20. Then 54% filters in phase 3, which accounts for 40% of the total network, are pruned. As listed in in Table 4, 0.78%, 0.79% and 0.58% improvements are achieved compared with FPGM-Mixed (40%) for ResNet-20, ResNet-32, and ResNet-56 respectively. Especially, the result of PFP-S3 (40%) outperforms FPGM-Mixed (30%) by 0.31% for ResNet-20.
The scheme PFP-S2∼3 prunes filters in phase 2 and 3 with the same rate, without pruning phase 1. Table 4 lists the results. Rt2,3 (20 % , 24 %), pruning 40% of total network parameters, outperforms FPGM-Mixed (40%) by 0.66% for ResNet-20. Similar pruning schemes achieve 0.39% and 0.40% improvements for ResNet-32 and ResNet-56 respectively.
For evaluating PFP-S2≺3 listed in Table 1, we use Rt2 (10 % , 10 %)-Rt3 (20 % , 30 %) to denote that 10% parameters are pruned with both the smallest-norm and largest-similarity criteria at phase 2, while 20% parameters are pruned with smallest-norm criterion and 30% with largest-similarity criterion at phase 3. This scheme prunes about 42% parameters of the whole network, which is higher than the 38% of PFP-S2∼3. It outperforms FPGM-Mixed (40%) by 0.57%, 0.44%, and 0.44% for ResNet-20, ResNet-32, and ResNet-56, respectively. The Rt2 (10 % , 10 %)-Rt3 (15 % , 20 %) scheme prunes about 30% parameters of the whole network, and outperforms FPGM-Mixed (30%) by 0.42% for ResNet-20.
The results on CIFAR-10 listed in Table 4 clearly show that the PFP-pruned networks have a comparable feature representation ability to the non-pruned network. Compared with FPGM, PFP can prune a higher rate of filters while achieving better performance. Also, PFP-S3 performs better than PFP-S2≺3, and PFP-S2≺3 outperforms PFP-S2∼3. This verifies that the filters in deeper layers are more suitable for being pruned.
PFP on CIFAR-100.
Like Section 4.2.2, we continue to evaluate the three schemes of PFP on CIFAR-100. PFP-S3 (30%) prunes the parameters of ResNet-20 and evaluated on CIFAR-100. As is listed in Table 4, it achieves 0.46% accuracy improvement over FPGM-Mixed (30%). Similarly, PFP-S3 (40%) outperforms FPGM-Mixed (40%) by 0.87%. For ResNet-32 and ResNet-56, PFP-S3 (40%) also outperforms FPGM-Mixed (40%) by 0.78% and 1.01% respectively.
For PFP-S2∼3, Rt2,3 (10 % , 34 %) scheme is used to prune 40% parameters of total parameters. It outperforms FPGM-Mixed (40%) by 0.78%, 0.46%, and 1.26% for ResNet-20, ResNet-32, and ResNet-56 respectively. For the scheme PFP-S2≺3, Rt2 (10 % , 10 %)-Rt3 (15 % , 20 %) scheme is used to prune 30% parameters. It outperforms FPGM-Mixed (30%) by 0.45% for ResNet-20. Similarly, PFP-S2≺3 (42%) outperforms FPGM-Mixed (40%) by 0.6%, 0.28%, and 0.89% for ResNet-20, ResNet-32, and ResNet-56 respectively.
Similar to the evaluation on CIFAR-10, PFP-S3 achieves the highest accuracy on CIFAR-100, and outperforms FPGM by a large margin. Also, PFP-S3 is slightly inferior to RedFiP on CIFAR-100, which again tells that the deeper layers have more redundancy and the much simpler scheme PFP-S3 can effectively prune the network without fine-tuning the hyperparameters.
PFP and RedFiP on ImageNet-1k
For experiments on ImageNet-1k, the initial output-channel number is 64, and the maximum output-channel number is 512, like a typical ResNet architecture for ImageNet-1k.
On ImageNet-1k, PFP is applied to three architectures, ResNet-18, ResNet-34, and ResNet-50, to investigate its performance. Also, we investigate the performance of the PFP-pruned structures with finetuning. For RedFiP, it is applied to the three architectures, but finetuning is not used as its performance without finetuning is already comparable to that of PFP with finetuning. Among the three schemes of PFP, PFP-S3 achieves the best test classification accuracy for all the three structures, and os only the results of PFP-S3 are reported.
All evaluated results on ImageNet-1k are reported in Table 5. For ResNet-18, ResNet-34, and ResNet-50 without finetuning, PFP-S3 (30%) outperforms FPGM (30%) by 0.8%, 0.78%, and 0.79%. While all pruned models are fine tuned, PFP-S3 (30%) outperforms FPGM (30%) with finetuning by 0.59%, 0.84%, and 0.5% for ResNet-18, ResNet-34, and ResNet-50. RedFiP (30%) outperforms FPGM (30%) by 1.3%, 0.92%, and 0.87% for these three architectures on ImageNet-1k.
Experimental results comparison between our strategies and state-of-the-art strategies on ImageNet for ResNets. The experiments with and without finetuning are conducted. For ImageNet-1k, only 30% parameters are pruned and the best test accuracies are in bold
Experimental results comparison between our strategies and state-of-the-art strategies on ImageNet for ResNets. The experiments with and without finetuning are conducted. For ImageNet-1k, only 30% parameters are pruned and the best test accuracies are in bold
Pruning scratch VGGNet on CIFAR-10
Similarly, VGGNet is pruned by RedFiP and PFP on CIFAR-10. Same as the previous experiments, pre-trained model is not used, and each model is trained from scratch. Not surprisingly, these two proposed strategies outperform state-of-the-art strategies and even the baseline. The proposed RedFiP achieves the test classification accuracy 93.83% on CIFAR-10, which outperforms PFEC and FPGM by 0.52% and 0.29% respectively. Also, FPF-S3 achieves accuracy improvements 0.42% and 0.19% over PFEC and FPGM respectively with the same proportion parameters pruned. RedFiP and PFP also outperform the baseline accuracy by 0.25 and 0.15. For the architecture like VGGNet, good performance is also achieved, and it verifies the effectiveness and universality of our proposed strategies.
Ablation Experiments
For ablation study, we evaluated the pruning classification performance on CIFAR-10 and CIFAR-100 in the ablation experiments that only shallow layers are pruned by a large pruning rate. As is shown in Fig. 5, when the pruned 40% parameters of the whole model are composed of the filters in the previous layers, especially the filters in shallow phase, the classification performance of ResNet20 drops by 4.4% and 5.66% on CIFAR-10 and CIFAR-100 respectively. When 40% parameters of the shallow layers are pruned, which account for about only 2% parameters of the whole model, the classification performance just slightly outperforms FPGM-Mixed (40%). Seeing this, the performance drop of FPGM-Mixed can be mainly due to the pruned filters in shallow phase. Also, compared with PFP-S3 (40%), the classification performance of the shallow-layer-pruned model drops by 0.6% and 0.76% on CIFAR-10 and CIFAR-100, indicating the indispensable role of shallow layers in extracting semantic features.

Shallow layers pruning. Four compared experiments are conducted and the percentages on each bar represents the pruning rate of the whole model. On X-axis, for example, ‘CIFAR-10-20’ represents that ResNet20 is used to evaluate the pruning performance on CIFAR-10. For the legend, ‘Shallow-All’ denotes that we severely pruned filters in previous layers, i.e., shallow, middle phases, and few previous layers in deep phase, for pruning 40% of the whole model. A few previous layers in deep phase are used to be pruned because all parameters of shallow and middle phases only account for 25.2% of total parameters. And ‘Shallow-Less’ represents that only 40% parameters of shallow phase are pruned, and the pruned parameters account for 2% of the whole model.
This paper focuses on the problem that filter redundancy differs from layer to layer. Different from the previous pruning strategies, which treat the all layers equally, this paper proposes that different layers should be treated differently according to the redundancy degrees of different layers. Firstly, the redundancy degree is defined based on norm and similarity criteria. The defined redundancy degree is used to analyze the neural networks, and the analysis shows that the redundancy differs from layer to layer. Moreover, the deeper layers have a higher redundancy degree. According to the analysis, a layer-wise pruning strategy RedFiP is proposed. Then a simpler and more effective phase-wise strategy FPF without the layer-wise thresholds is further proposed.
When RedFiP is applied to the ResNets, the pruned models outperforms the SOTA pruning methods. It even outperforms the non-pruned model under a certain pruning rate. This justifies the redundancy definition. Furthermore, the PFP strategy is proposed to essentially simplify the implementation process of RedFiP, and can be readily applied to existing architectures. PFP significantly reduced the parameters while maintaining or even improving the performance, which verifies again the redundancy existence and the value of the proposed pruning strategies.
Footnotes
Acknowledgments
This work was supported by the National Key R&D Program of China under Grant 2019YFF0302601, National Natural Science Foundation of China (No. 62071060), and the Beijing Key Laboratory of Work Safety and Intelligent Monitoring Foundation.
The source code is from ‘https://github.com/he-y/filter-pruning-geometric-median/’