
Abstract
The Dempster-Shafer evidence theory has been extensively used in various applications of information fusion owing to its capability in dealing with uncertain modeling and reasoning. However, when meeting highly conflicting evidence, the classical Dempster’s combination rule may give counter-intuitive results. To address this issue, we propose a new method in this work to fuse conflicting evidence. Firstly, a new evidence distance metric, named Belief Mover’s Distance, which is inspired by the Earth Mover’s Distance, is defined to measure the difference between two pieces of evidence. Subsequently, the credibility weight and distance weight of each piece of evidence are computed according to the Belief Mover’s Distance. Then, the final weight of each piece of evidence is generated by unifying these two weights. Finally, the classical Dempster’s rule is employed to fuse the weighted average evidence. Several examples and applications are presented to analyze the performance of the proposed method. Experimental results manifest that the proposed method is remarkably effective in comparison with other methods.
Introduction
Dempster-Shafer evidence theory (D-S theory), which was proposed by Dempster [1] and developed later by Shafer [2], has grown to be a systematic theory for uncertain reasoning. Due to its special ability in handling uncertain information [3], D-S theory has been extensively used in a plethora of applications [4].
D-S theory can represent uncertainty by using a belief function and can combine a number pieces of evidence obtained from diverse sources without prior information [5]. This theory needs weaker conditions than the Bayesian theory of probability, and thence it is often considered as an extension of Bayesian theory [6]. In D-S theory, the belief can be given to not only singleton elements but also non-singleton elements, which is denoted in the form of basic probability assignment (BPA). The Dempster’s rule of combination is a critical step in the process of information fusion, which assumes that the pieces of evidence are reliable and distinct [7]. Nevertheless, in some real-world applications, this condition is hard to meet. As a consequence, Dempster’s combination rule may produce unreasonable results [8]. Particularly, when collected pieces of evidence are highly in conflict, counter-intuitive results can be generated [9–12].
To solve the above problem, great efforts have been made by researchers [10, 13–17]. Some researchers hold the view that counter-intuitive results are mainly brought about by the normalization operation in Dempster’s combination rule. In this regard, they have improved the combination rule from different dimensions. For example, Yager [13] modified the Dempster’s combination rule by assigning the conflicting mass to the unknown space. Whereas, in Smets’s improvement [18], the conflicting mass was assigned to the empty set. Dubois and Prade [19] proposed the disjunctive rule of combination, which requires that at least one source of evidence is reliable. Lefevre et al. [20] presented a general framework to unify different combination rules. Nevertheless, the properties of commutative law and associative law in Dempster’s combination rule are destroyed. Moreover, if counter-intuitive results arise from sources of evidence, for example, the sensor failure, such improved rules would have no effect. On the other hand, some researchers take the attitude that the unreasonable results are caused by unreliable sources of evidence rather than Dempster’s combination rule itself. Therefore, they proposed to pre-process the original evidence before fusing them. Murphy’s method [10] is a representative, which directly averages all pieces of evidence. However, this method simply distributes equal weight to each piece of evidence. Deng et al. [14] proposed a weighted average approach, where the credibility degree of evidence is evaluated in the light of Jousselme’s distances [21] between the bodies of evidence. Following the idea of pre-processing evidence, Yang et al. [22] estimated the weight of evidence according to the ranking distances between the bodies of evidence. Zhang et al. [23] computed the support degree of evidence by using a new cosine theorem. Zhang and Deng [7] employed the DEMATEL method to ascertain the weight of each piece of evidence. Lin et al. [24] determined the credibility degree of evidence by measuring Euclidean distances among pieces of evidence. Wang and Xiao [25] calculated the weight of evidence by considering two factors of support degree of evidence obtained by means of Euclidean distance and belief entropy [26], respectively. Xia et al. [27] defined the evidential reliability indicator to measure the quality of a piece of evidence via belief entropy [26]. Different from the above methods, Yu et al. [16] pre-processed the original bodies of evidence by discounting them other than averaging them. The discounting factors are generated according to the proposed supporting probability distance. Although those methods produced reasonable results compared to the original Dempster’s combination rule when fusing unreliable sources of evidence, there is still some room for improvement. For example, the Euclidean distance used in [24, 25] is a bin-by-bin distance [28], which cannot characterize the difference between a singleton element and a non-singleton element.
The motivation of this work is to design a new evidence fusion method that can effectively combine conflicting evidence to make a decision. Firstly, the differences of belief in both the same and different propositions should be considered when measuring the distance between two BPAs. Secondly, the desirable properties of Dempster’s combination rule should be kept. To this end, the Belief Mover’s Distance (BMD) is defined to measure the distance between two pieces of evidence. BMD is regarded as a special case of the famous Earth Mover’s Distance [29–31] by representing a BPA as a histogram, in which a proposition is a bin and the belief of the proposition is the mass in the corresponding bin. Unlike Euclidean distance, BMD is a cross-bin distance [28], where the distance between two pieces of evidence is defined as the minimal cost that transfers the belief of one evidence to another. Example analysis shows that BMD has adequate capability to describe the divergences of evidence. In [32], a similar distance measure is presented by extending the Wasserstein metric on a random set. However, the ground distance between propositions in that measure and BMD is different. In that measure, the ground distance is the cardinality of symmetrical difference between propositions, while it in BMD is the Euclidean distance between the mapped points of propositions.
Afterward, a new combination method is proposed for fusing conflicting evidence. The proposed method evaluates the weight of a piece of evidence by means of its credibility degree and distance information. The credibility degree of a piece of evidence is calculated according to its distances from other pieces of evidence, and the distance information is computed based on its distance to the negative ideal BPA. Then, averaged evidence is obtained by applying the weights of evidence, and fused using Dempster’s combination rule.
In summary, the primary contributions in this paper are as follows: A new cross-bin distance, i.e., BMD, is proposed to measure the difference of evidence. A new evidence combination method is designed to fuse multiple pieces of evidence, in which both credibility weight and distance weight of evidence are computed on the basis of BMD. Experimental analysis on some examples and applications demonstrates that the proposed method achieves superior fusing results compared with the state-of-the-art methods.
The rest of this work is structured as follows. Section 2 introduces the related conceptions of D-S theory, belief entropy, and Earth Mover’s Distance. The proposed Belief Mover’s Distance is defined in Section 3. Section 4 describes the proposed combination method, and Section 5 experimentally analyzes the effectiveness of the proposed method. Some discussions are given in Section 6. Finally, Section 7 concludes this work.
Preliminaries
This section briefly introduces the following preliminary theories: Dempster-Shafer evidence theory, belief entropy, and the Earth Mover’s Distance.
Dempster-Shafer evidence theory
Dempster-Shafer evidence theory (D-S theory) [1, 2] is a powerful tool for uncertain reasoning.
In D-S theory, a mass function is also called a basic probability assignment (BPA) [33]. Given a proposition A, m (A) reflects the belief assigned to A by the evidence. If m (A) >0, A is a focal element.
Given an FoD, BPAs can be collected from different sources of evidence. To make a final decision, multiple BPAs should be fused. To this end, Dempster proposed a rule to combine different BPAs using the orthogonal sum [1].
Furthermore, the fusion result from multiple sources of evidence can be converted into a probability distribution based on the pignistic probability transformation [34].
To assess the degree of uncertainty of a BPA, recently, Deng [26] proposed a new belief entropy, namely Deng entropy, which is a generalization of Shannon entropy [35] in D-S theory. The definition of Deng entropy is presented in the following.
It can be seen from Eq. (7) that the form of Deng entropy is similar with that of Shannon entropy. When belief is only given to singleton element of Θ, Deng entropy degenerates to Shannon entropy, which is
Belief entropy measures the degree of uncertainty of a BPA. Therefore, a BPA with greater entropy can provide poorer quality of information. According to Deng entropy, the positive ideal BPA and negative ideal BPA are introduced in [27, 36].
From Definition 6, if a BPA has the minimum of Deng entropy, it is a positive ideal BPA [27]. On the contrary, if a BPA achieves the maximum of Deng entropy, it is defined as a negative ideal one. From Definition 5, if a BPA m assigns all its belief to a singleton element, then its Deng entropy is zero. In other words, it provides completely certain information. As a result, this BPA is a positive ideal BPA. On the other hand, according to [26, 27], m attains the maximum of entropy when the condition in Eq. (9) is held for all propositions. Thus, this BPA is a negative ideal BPA.
The Earth Mover’s Distance (EMD) is a well-known distance measure designed originally for image retrieval [29]. EMD is a cross-bin distance that addresses the alignment problem between two histograms [29–31]. Because of its robustness and effectiveness, EMD has been employed in a host of applications, such as image retrieval [29, 38], face verification [39, 40], and common pattern discovery [41, 42]. EMD converts the alignment problem into the famous transportation problem. It regards the distance between two histograms as the minimum cost that must be paid to move the mass of one histogram into another. The formal definition of EMD is presented at follows.
Definition 7 shows that EMD is computed as per the minimum cost of moving one histogram into another. The cost for transferring one unit of mass from bin s i to bin t j is determined by their ground distance d ij . One bin in S can transform its mass to many bins in T, while one bin in T can receive mass from many bins in S. Therefore, EMD is a cross-bin distance measure.
In D-S theory, how to measure the distance of two pieces of evidence is still an open issue [6, 43]. Distance measure is critical for estimating the conflict among evidence and fusing different pieces of evidence. A BPA can assign belief to both singleton and non-singleton elements. The belief of a non-singleton element denotes the overall degree of support to all singleton elements in it. Therefore, an adequate distance measure should consider the differences of belief of not only the same propositions but also different propositions. As mentioned in Theorem 1, EMD is a metric when (1) ground distance measure is a metric and (2) two histograms have the same total weight. In D-S theory, we have the characteristic that the total belief of every BPA is 1. Thus, we propose to define an evidence distance measure by adopting the idea of EMD. To this end, we convert a BPA into a histogram and treat the belief of a proposition as the amount of mass in the corresponding bin. In this study, we call the new evidence distance as Belief Mover’s Distance (BMD) since the object transferred is belief.
After mapping a BPA into a histogram, there is a corresponding bin in the histogram for each proposition. The distance between two propositions is the ground distance between the corresponding bins. In what follows, we first give two definitions about distance of proposition.
The function ρ maps a proposition into a point in n-dimensional space. The corresponding coordinate is determined according to the singleton elements in the proposition.
Then, we introduce the histogram function, which maps a BPA into a histogram, and present the definition of BMD, which measures the distance between two BPAs.
In Eq. (12), f
ij
δ (A
i
, B
j
) represents the cost that must be paid to transfer belief f
ij
from
□
At follows, we give some examples to show the computation of BMD.
The corresponding locations of bins
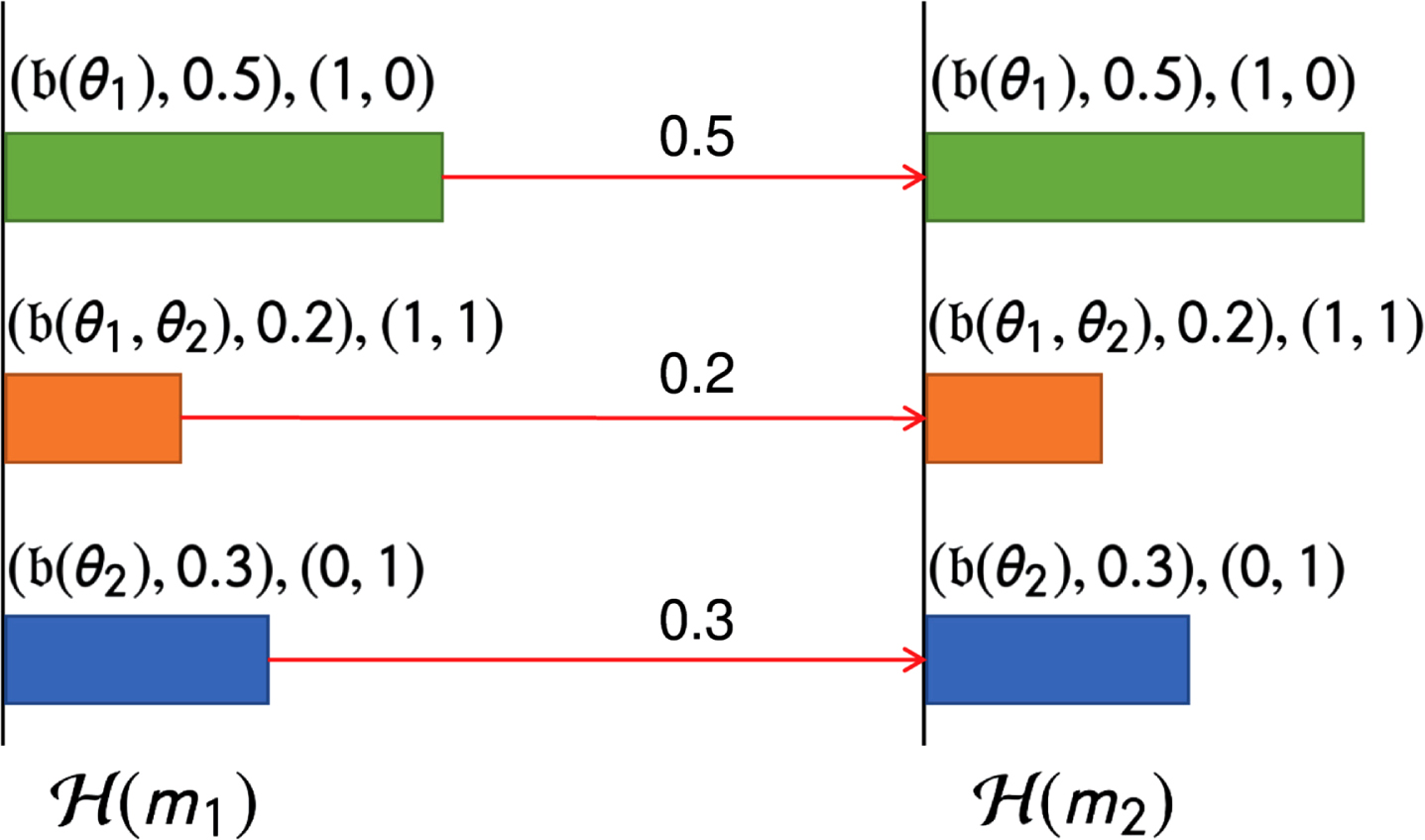
An example to show the computation of BMD between m1 and m2. m1 and m2 have the same probability assignment, and thus the mapped histograms are identical. To minimize the total cost for moving beliefs from
Example 5 shows us that when two BPAs have the same probability assignment, their BMD is 0.
The corresponding locations of bins
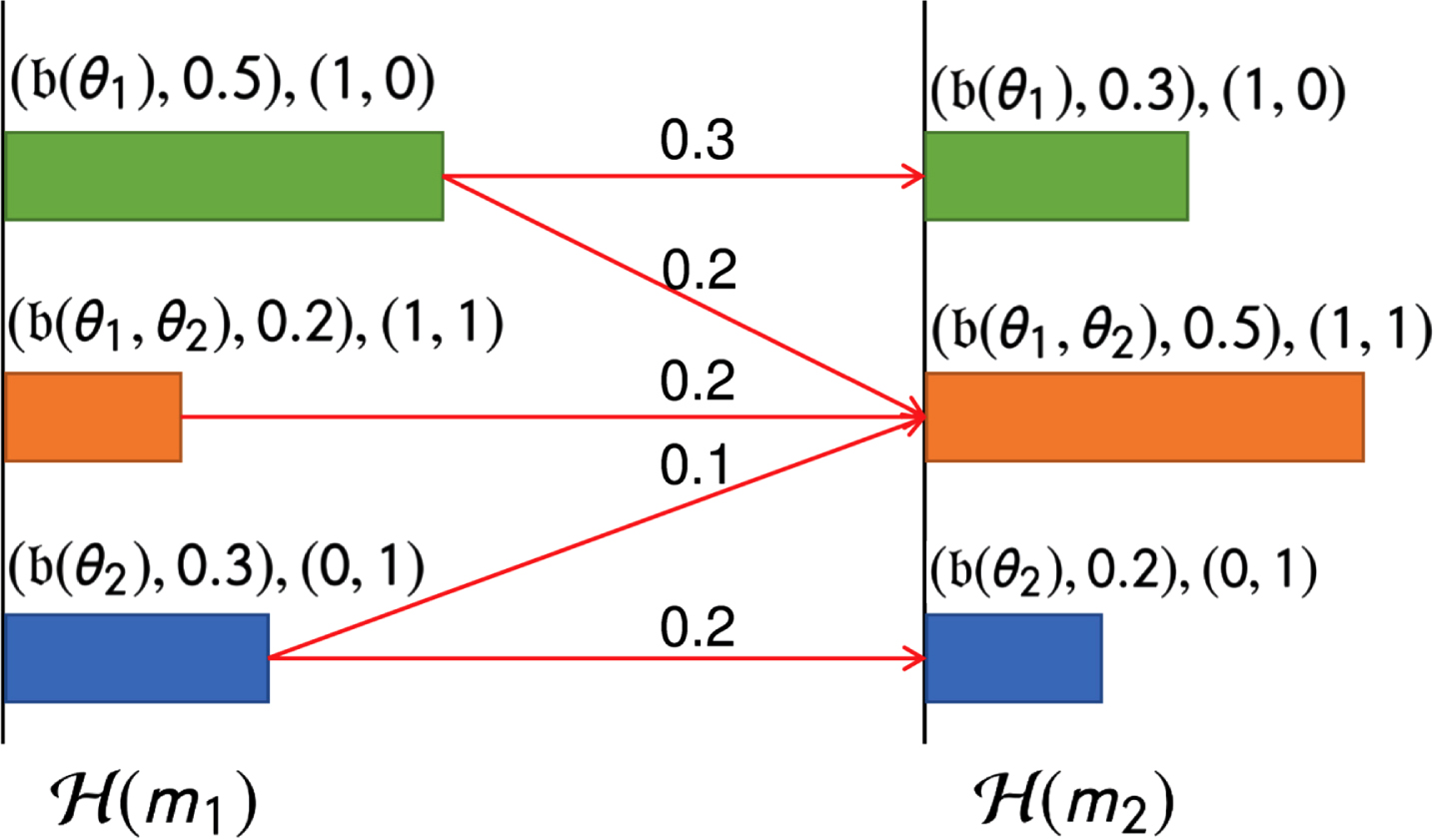
Another example to show the computation of BMD between m1 and m2. m1 and m2 have different probability assignment, and thus the mapped histograms are not identical. In this example, the belief in a bin in
The corresponding locations of bins

The optimal flow of beliefs between different histograms in Example 7.
Analogously, we can calculate the two other distances according to Figs. 3(a) and (b), which are BMD (m1, m3) =1.3533 and BMD (m2, m3) =1.1677. Clearly, m1 is close to m2 but far away from m3. Likewise, m2 is close to m1 but far away from m3. The results indicate that BMD can measure the consistency relationship between BPAs.

An example to show the distance between m1 and m2 with the change of α.
In Example 8, m2 gives high belief to θ1, which is m2 ({θ1}) =0.8. As the value of parameter α increases from 0 to 1, the support degree of m1 to θ1 is gradually enhanced. According to the definition of BMD, the distance between m1 and m2, when α is in [0, 0.8], can be calculated as follows:
As shown in Fig. 4, with the increasing of α from 0 to 0.8, the distance between m1 and m2 is decreasing. When α = 0.8, the distance is the smallest. Whereas, when α changes from 0.8 to 1, the distance is increasing. The reason is the support degree of m1 to θ1 is gradually higher than that of m2 to θ1.

The BMDs between m1 and m2 vary with the size of A.
In Fig. 5, size of A equals to l (1 < l < 20) means that A = {θ1, θ2, ⋯ , θ
l
}. From this figure, one can see that the proposed BMD metric is reasonable to measure the difference between BPAs that contain multi-focal elements. The trend of the distance between m1 and m2 with A changes is very obvious. When A changes from {θ1} to {θ1, θ2, ⋯ , θ5}, the distance gradually decreases. When A equals to {θ1, θ2, ⋯ , θ5}, the distance is the minimum because the amount of belief transferred cross-bin is the minimum. When A changes from {θ1, θ2, ⋯ , θ5} to {θ1, θ2, ⋯ , θ20}, the distance gradually increases since the cost that must be paid to transfer belief from
In this section, a new combination method is designed to fuse evidence with their distances measured by the proposed Belief Mover’s Distance. The new method computes the weight of a piece of evidence from two aspects. The first part of weight considers the support relationship between different pieces of evidence as in [14], and the second part takes the distance of this evidence from the negative ideal BPA into account. The final weight of the evidence is unified by combining both parts. Eventually, the weighted average evidence is obtained by calculating the weighted sum of multiple pieces of evidence and then fused via the Dempster’s combination rule. The flowchart of the proposed method is depicted in Fig. 6.
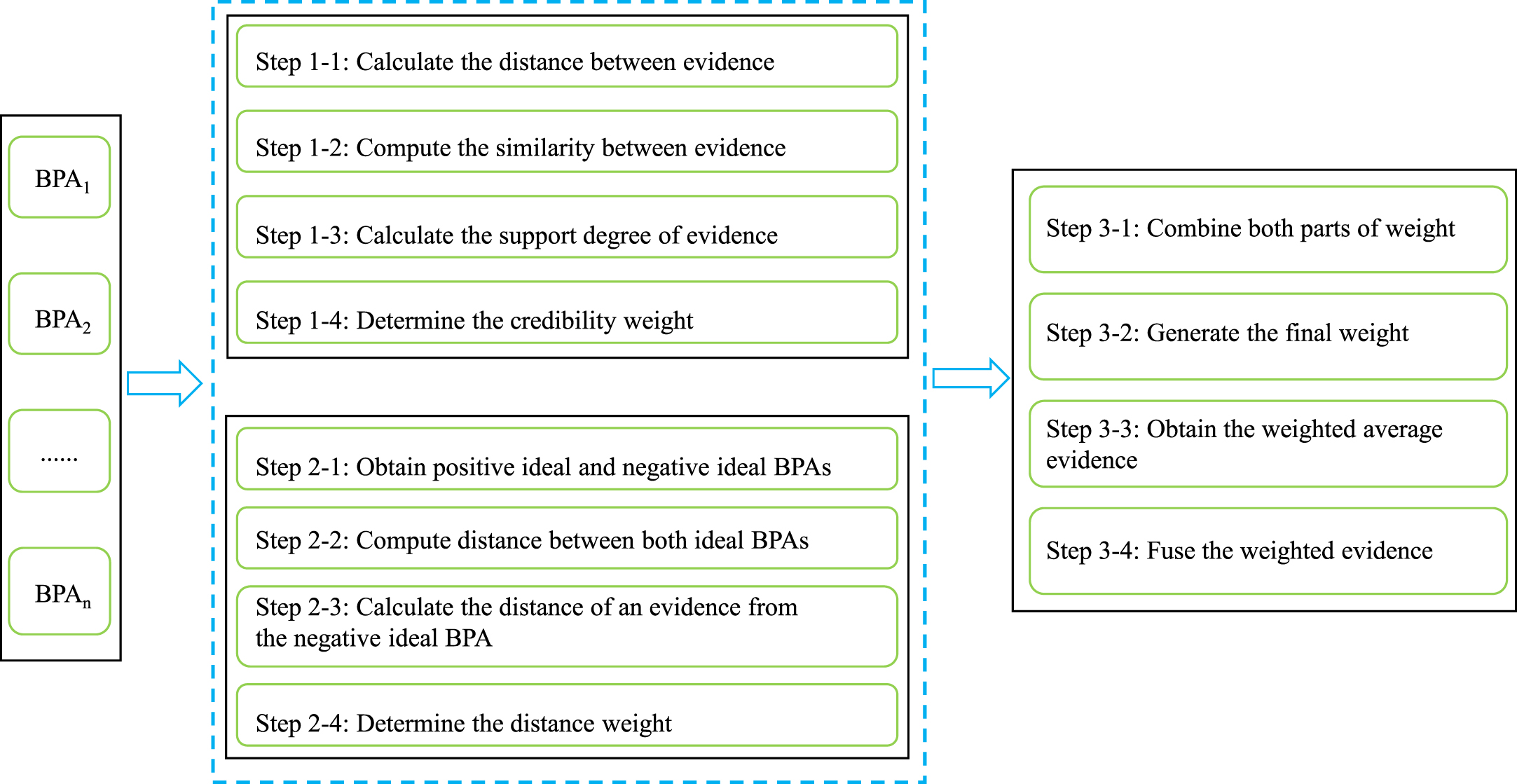
Flowchart of the proposed method.
In what follows, the detailed process of the proposed method will be elaborated.
Suppose M = {m1, m2, ⋯ , m
n
} is a set of BPAs defined on the FoD Θ. According to Definition 11, a distance matrix can be calculated as
Here, we define the similarity between BPAs m i and m j as
Then, we get the similarity matrix as follows:
If evidence m i is similar with another one, namely m j , we say that m i is supported by m j . Thence, the support degree of m i is defined as
According to [14], if a piece of evidence has bigger support degree, then this evidence is more credible and consequently has higher weight when averaging multiple pieces of evidence. The credibility weight of a piece of evidence is determined in Eq. (15).
As per Definition 6, the positive ideal and negative ideal BPAs have the minimum and maximum of Deng entropy, respectively. As aforementioned, there are multiple positive ideal BPAs and one negative ideal BPA on FoD Θ. Suppose m+ is one positive ideal BPA and m- is the negative ideal BPA, which can be computed according to the analysis in subsection 2.2.
Among all BPAs defined on FoD Θ, the positive ideal BPA and negative ideal one have the maximum distance, which is denoted as BMD max , BMD max = BMD (m+, m-).
After computing the distance of each evidence from the negative ideal BPA, a distance vector
Then, we normalize the distance vector
In this step, we estimate the second part of weight of the evidence based on its distance from the negative ideal BPA. Before defining the distance weight of the evidence, we measure the importance of the evidence as
The distance weight of a piece of evidence is determined by Eq. (17).
By combining the credibility weight and distance weight, the modified weight of each piece of evidence is computed as
The final weight is the normalized modified weight, which is defined as
Using the final weight of each piece of evidence, the weighted average evidence, denoted as
For n pieces of evidence, the final combination result can be obtained by fusing the weighted average evidence
We think it is helpful to show the process of the proposed method by providing an example. Here, we consider the three BPAs given in Example 7 again, which are
The BMDs among the three BPAs are
Then, using Eqs. (14) and (15), the support degrees and credibility weights of these pieces of evidence are computed. The support degrees are sup (m1) =1.0890, sup (m2) =1.1417, and sup (m3) =0.5695; the credibility weights are w crd (m1) =0.3889, w crd (m2) =0.4077, and w crd (m3) =0.2034.
Let m+, m- denote the positive ideal BPA and negative ideal BPA on Θ = {θ1, θ2, θ3}, which are defined as
Next, we compute the distances of three BPAs from m-, and then normalize these distances. The obtained distance vector and normalized distance vector are
Based on Eqs. (18) and (19), we compute the modified and final weights of three BPAs. The modified weights are W (m1) =0.1870, W (m2) =0.1920, and W (m3) =0.0148, while the final weights are
To attain the final result,
These results indicate that the proposed method can reduce the negative effect caused by m3 and assign high belief to hypothesis θ1. For the purpose of comparison, Table 1 lists the fusion results of several baseline methods and Fig. 7 depicts the corresponding pignistic probability. Both Table 1 and Fig. 7 show that the proposed method gives higher belief and pignistic probability to hypothesis θ1 than others. As a result, the proposed method is more effective than others for the illustrative example which contains highly conflicting evidence.
Fusion results of different methods for the illustrative example
Fusion results of different methods for the illustrative example
To further show the superior performance of the proposed method, a numerical example and two applications in fault diagnosis and classification problem are demonstrated in this section. The compared methods include Dempster’s combination rule [1], Murphy’s method [10], Deng et al. ’s method [14], Wang and Xiao’s method [25], Zhang and Deng’s method [7], Yang et al. ’s method [22], Lin et al. ’s method [24], Xia et al. ’s method [27], and Yu et al. ’s method [16].
Numerical example
Here, we employ the fictitious example used in [7]. Suppose there are three objects, namely A, B, and C, in a multi-sensor-based target recognition system [7]. Thence, the FoD is Θ = {A, B, C}. Based the results reported by five different sensors, five pieces of evidence are derived, which are outlined in Table 2. Assume hypothesis C is the true target. From Table 2, it can be seen that m2 is abnormal because it highly conflicts with others.
Five pieces of evidence collected from different sensors [7]
Five pieces of evidence collected from different sensors [7]
Table 3 lists the combination results of the proposed method and nine compared ones. From Table 3, we can observe that Dempster’s rule generates the counter-intuitive conclusion that object B has the highest support, because it is disturbed by m2. Whereas, all other methods recognize the true target C. In addition, in comparison with other methods, the proposed one has a faster convergence rate and the highest belief to the correct target. Because m2 is abnormal and gives high support to B, most of the methods, except Wang and Xiao’s method [25] and the proposed method, wrongly support target B when only combining m1 and m2. However, after combining m1, m2 and m3, the proposed method already can identify the true target C with belief = 0.7130. When combining m1, m2, m3 and m4, the proposed method assigns near 94% belief to object C. In other words, the proposed method has a very high probability of detecting the true target even if combining partial sources of evidence. Furthermore, Table 4 outlines the pignistic probability of object C generated by different methods with incremental evidence. As observed from Table 4, the proposed method has a higher speed in convergence and higher support to true target than others. In a nutshell, our method is more effective when handling conflicting evidence.
Fusion results of different methods for numerical example
Pignistic probability of object C with incremental evidence
The reason is that our method takes into account two aspects of weight, which makes full use of the new Belief Mover’s Distance. Thence, it increases the weights of reliable evidence whilst decreases the weights of unreliable evidence.
In this experiment, a case study in fault diagnosis of a rotating machinery system [24,25, 24,25] is adopted to evaluate the effectiveness of our proposed method.
A rotating machinery system has four different fault types: “Imbalance”, “Shaft crack”, “Misalignment”, and “Bearing loose”, which are symbolically marked as F1, F2, F3, and F4. So, the FoD is Θ = {F1, F2, F3, F4}. Five sensors are distributed in the system to monitor its status. When working, these sensors can continuously report diagnostic evidence for different faults. At some time, the fault F3 happened, and then five sensors got a lot of data. According to the data reported by these sensors, BPAs are calculated, which are listed in Table 5. In Table 5, m1, m2, and m4 suggest the fault is F3. However, m3 says the fault is F2, and m5 believes the fault is F4.
Table 6 presents the fusion results of ten methods. Based on the results in Table 6, all methods can recognize the true fault F3. Notably, the proposed method gives the highest support to F3. In addition, the support degree of F3 decreases when m1, m2 and m3 are fused owning to conflicting information from m3. Similar phenomenon also appears when all BPAs are combined, because the fifth sensor does not support F3. Nonetheless, the corresponding drop of the proposed method is the slightest. It indicates that the proposed method suffers less negative effects from conflicting evidence.
Fusion results of different methods for fault diagnosis
Moreover, the belief entropy of the final BPA fused by each method is shown in Fig. 8. From Fig. 8, the belief entropy of the final BPA calculated by the proposed method is the smallest, which indicates that the result produced by the proposed method has the smallest uncertain. As a consequence, the proposed method is flexible and effective in combination of evidence.

Pignistic probability of hypothesis θ1 computed by different methods for illustrative example.
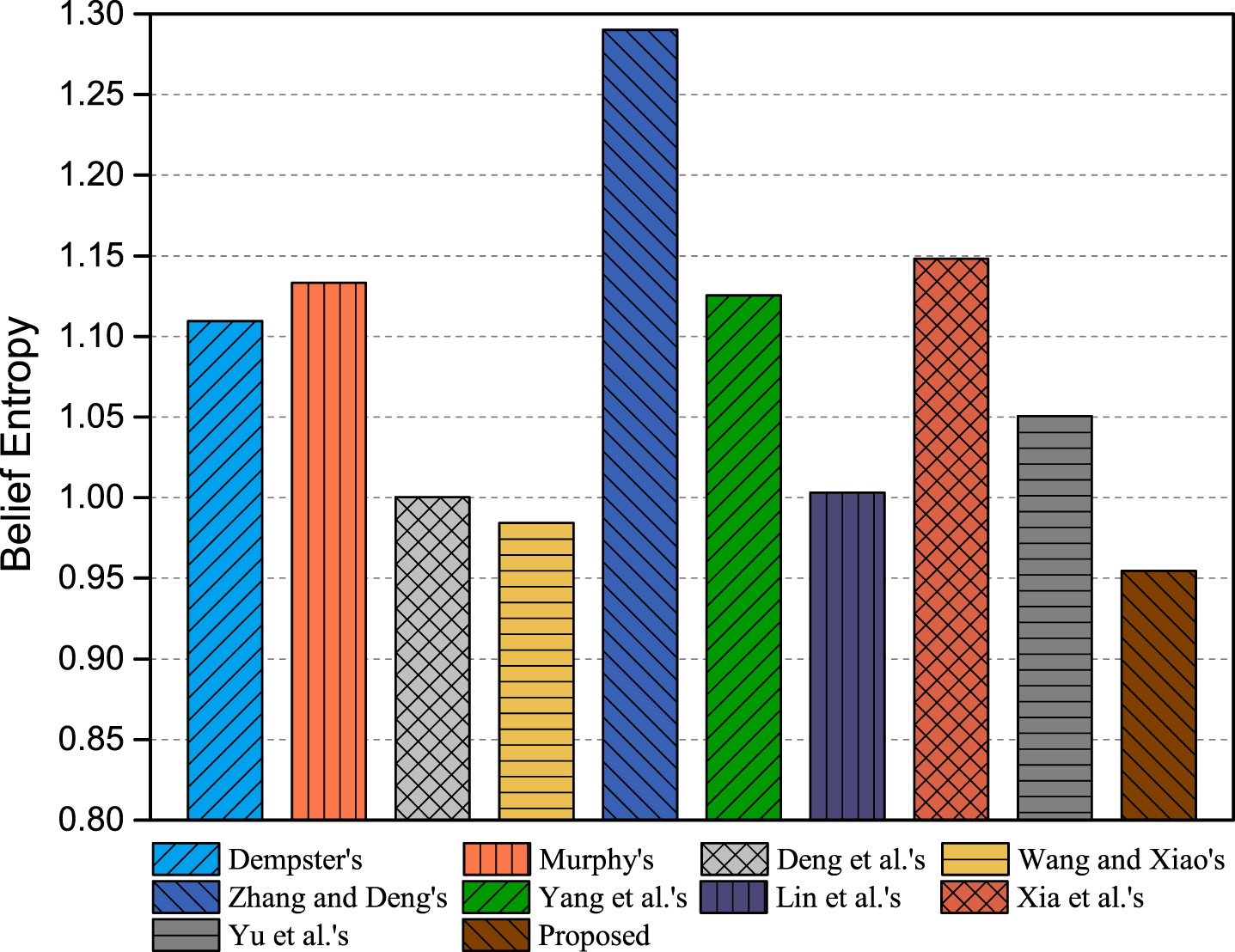
Belief entropy of the final BPA generated by each combination method.
In this subsection, another experiment on the Iris dataset is performed to verify the performance of the proposed method. The dataset covers three species of iris flowers, i.e., Setosa (Se), Versicolor (Ve) and Virginica (Vi), with four attributes, i.e., sepal length (SL), sepal width (SW), petal length (PL), and petal width (PW). Therefore, the FoD is Θ = {Se, Ve, Vi}. One species contains 50 instances in the dataset. In this experiment, we follow the experimental settings in [45], where 40 instances are randomly selected for a species to generate BPAs by using the interval number model. For a randomly chosen testing instance from Setosa, i.e., (4.5, 2.3, 1.3, 0.3), the BPA of each attribute generated based on the interval number model is listed in Table 7.
BPAs of four attributes for an instance in Iris dataset [45]
BPAs of four attributes for an instance in Iris dataset [45]
Table 7 manifests that attributes PL and PW give high belief to species Se, while attributes SL and SW assign small belief to all species. As a consequence, there is no clear conflict between these pieces of evidence. To determine the category of the testing instance, the four pieces of evidence are fused. The results of different methods are shown in Table 8. From this table, one can see that all methods can identify that the testing instance is likely to be Setosa with a belief of more than 60%, which conforms to the actual situation. Remarkably, the proposed method gives the highest belief to {Se}, which suggests that our method is more powerful than the compared ones in detecting the species of iris flowers. The Dempster’s rule correctly recognizes the category of the instance with the belief of 0.8137 since these pieces of evidence are reliable and not conflicting. However, Zhang and Deng’s method assigns only 60.17% belief to {Se}, which is much lower than those of other methods. Therefore, the method may be insufficient to combining evidence with no evident conflict.
Fusion results of different methods for the Iris classification experiment
In BMD, we employ the Euclidean distance as the ground distance, i.e., proposition distance. Actually, other distance measures, such as Manhattan distance and Jaccard coefficient, may also be used in our BMD. But, the influence of these measures to BMD should be further investigated. In addition, a side effect caused by Euclidean distance is the range of BMD is not in [0, 1]. Although this limitation does not affect the use of BMD in the proposed method, it may be not clear how different two BPAs are.
When gauging the distance weight of a piece of evidence, a parameter β is introduced in the proposed method. By using β, we intend to assign large weights to valuable evidence but suppress the importance of conflicting evidence. In this work, we just fix the value of β after a simple test. However, an ideal scenario is to automatically determine the value of β based on the information of evidence. In fact, this is a hard job that requires in-depth study.
The computation of BMD is to resolve the transportation problem. As a result, it may be time-consuming when the FoD contains more elements. Fortunately, some efforts have been made by researchers [30, 37] to accelerate the computation of EMD. In this paper, we use the implementation of Ofir Pele and Michael Werman 1 .
Conclusion
In this paper, a new evidence combination method is proposed to address the issue of counter-intuitive results derived from highly conflicting evidence. In our proposed method, the Belief Mover’s Distance is introduced to accurately evaluate the differences among pieces of evidence. According to distances of evidence, the credibility weight and distance weight of each evidence are computed. Next, the final weight is calculated by unifying two aspects of weight, and then the weighted average evidence is produced by computing the weighted sum of all pieces of evidence. Finally, the weighted average evidence is fused via the classical Dempster’s combination rule. To demonstrate the superiority of the proposed method, a number of examples and applications are analyzed. The results show that the proposed method has faster convergence rate and higher effectiveness in comparison with others.
In the future work, we intend to study how to automatically set the value of parameter β in the proposed method according to the information of evidence. β is a critical parameter, the value of which can gravely affect the performance of the proposed method. In addition, we would like to further investigate the measure of proposition distance to make the range of BMD between 0 and 1. Specially, we want to apply our method to some real-environment applications, such as multiple sensor surveillance systems, complex network analysis, and pattern recognition.