
Abstract
Outlier detection is a hot issue in data mining, which has plenty of real-world applications. LOF (Local Outlier Factor) can capture the abnormal degree of objects in the dataset with different density levels, and many extended algorithms have been proposed in recent years. However, the LOF needs to search the nearest neighborhood of each object on the whole dataset, which greatly increases the time cost. Most of these extended algorithms only consider the distance between an object and its neighborhood, but ignore the local distribution of an object within its neighborhood, resulting in a high false-positive rate. To improve the running speed, a rough clustering based on triple fusion is proposed, which divides a dataset into several subsets and outlier detection is performed only on each subset. Then, considering the local distribution of an object within its neighborhood, a new local outlier factor is constructed to estimate the abnormal degree of each object. Finally, the experimental results indicate that the proposed algorithm has better performance and lower running time than the others.
Introduction
Outliers are a special subset with a few objects, which deviate from normal objects in spatial distribution. Outlier detection is an important branch of data mining, aiming at automatically mining outliers from a dataset. Moreover, it has been successfully applied in many practical fields, including network intrusion detection [1–4], medical monitoring [5–7], and industrial testing [8–11].
After long-term research and development, many effective methods of outlier detection have proposed by researchers, which can be briefly divided into the following categories: statistical-based method, clustering-based method, distance-based method, and density-based method, etc. As a representative density-based approach, the LOF [12] algorithm has been paid much attention by scholars, and a series of extended methods have been designed. The main idea of them can be summarized as follows: the local reachable density is constructed by calculating the distance between an object and its neighborhood, the ratio of an object’s reachable density to the mean of those of its neighborhood is used to quantify the abnormal score. Finally, according to the top-n principle, the multiple objects with the largest abnormal score are regarded as outliers.
Motivation
Although the LOF has been supported by many scholars, it still has some shortcomings: It is necessary to calculate the distance among all objects, which has high time complexity. LOF only considers the neighborhood distance and ignores the local distribution of an object within its neighborhood.
LOF relies on the distance among all objects when searching the nearest neighborhood. This sub-problem with time complexity O (n2) may cause that LOF face the risk of failure on large-scale dataset. Scholars have done a lot of effective works to improve the efficiency from data structure and pruning strategy. At present, to speed up the nearest neighbor search, some tree-shaped data structures are adopted, including KD Tree, Ball Tree, BK Tree, VP Tree, and M Tree, etc. At the same time, some scholars employ the idea of pruning strategy to reduce the data scale of participating in outlier detection. The main methods of them are to design some pre-processing algorithms, which can extract a small-scale candidate outlier subset, and then outlier detection is performed only on this candidate subset. However, it is sensitive to the scale of the candidate subset. There is still the problem of high time complexity for large-scale candidate subset. Conversely, if too many objects are deleted, that is, the real outliers may be removed in the pre-processing process, the accuracy will decrease.
Objective
As we know, if n
i
≥ 0 (i = 1, 2, . . . , c) and The RCBTF algorithm is proposed to divide the dataset into several subsets. The NLOF is redefined for estimating the abnormal degree of each object.
The rest of this paper is organized as follows. Section 2 introduces the variants of LOF. Section 3 describes RCBTF and NLOF in detail. In Section 4, the experimental results are shown. Summary of this study is given in Section 5.
Related work
LOF is a pioneering work of local outlier detection. With the expansion of related work, many variants have been successfully applied in engineering practice. Their main works focus on efficiency and accuracy.
Many scholars have done related researches to improve running efficiency. Two key technologies are being followed with interest. One is to use tree-shaped data structures to conduct efficient nearest neighborhood search, and the other is to reduce unnecessary search scope in advance by utilizing pruning strategy. KD Tree was often employed to optimize the nearest neighborhood search for outlier detection on large-scale data [13]. Likewise, the efficient search was also performed by using the other tree-shaped data structures [14–17]. To further increased the running speed, Su et al. [18] proposed an approach of eliminating security objects, which eliminated normal objects from the dataset and extracted a few candidate outliers to participate in outlier detection. Although the running speed could be raised, it may misjudge the candidate outliers and normal objects. So, the accuracy might be decreased after the pre-processing. In [19], a dataset was divided into core objects (normal objects), boundary objects (normal objects or outliers) and outliers through DBSCAN [20] clustering, and then the core objects would be filtered out before the task of outlier detection was performed. Similarly, the above strategy of outlier detection, which removes normal objects from the dataset, is hard to define the boundary between normal objects and outliers. In addition, from the perspective of the calculation rule of local outlier factor, SimplifiedLOF [21] simplified the density estimation of LOF and improved the efficiency of the algorithm to some extent. Literatures [22–26] have also made relevant works in the aspect of improving efficiency, which have certain reference significance.
To improve accuracy, scholars have done extended works for the calculation rule of local outlier factor, such as connectivity-based outlier factor (COF) [27], local distance-based outlier factor (LDOF) [28], INFLuenced Outlierness (INFLO) [29]. Zhang et al. proposed LDOF, which used the relative distance between an object and its neighborhood to measure the degree of deviation. It was less sensitive to hyper-parameter. INFLO modified the selection rule of neighborhood by replacing KNN with the union of KNN and inverse KNN. However, many variants only depend on the neighborhood distance to measure the abnormal degree, without considering the local distribution of an object within its neighborhood. Recently, Su et al. [18] redefined a local deviation coefficient called LDC, which first integrated the variance and expectation of the neighborhood distance into the LOF. It took the local distribution of an object within its neighborhood into account. In [30], the relative k-distance nearest neighborhood was used to replace the k-distance nearest neighborhood, and the relative k-nearest neighbor entropy was used to redefine the local outlier factor.
In summary, all of the above variants of LOF judge whether the object is an outlier by employing the neighborhood distance to calculate the local outlier factor of each object. Only a few papers, such as [18] and [30], have considered the variation of neighborhood distance, but the rules of them can’t fully reflect the local distribution of an object within its neighborhood. So, a new local outlier factor, which fully takes advantage of the local distribution, is defined in this study. The details will be given in Section 3.2.
Enhanced outlier detection
As can be seen from Section 1, if

Framework of proposed algorithm.
In unsupervised learning, the purpose of the clustering algorithm is to partition a dataset into multiple clusters, that is, to divide the dataset into multiple subsets. Although many industry-recognized clustering algorithms have been proposed at present, such as KMeans, KMeans++ and DPC [31], all of them face the challenge of low efficiency. So, an efficient rough clustering based on triple fusion (RCBTF) is presented, which doesn’t need to iterate dataset repeatedly. The related definitions of the RCBTF are as follows.
According to Definition 1, we can obtain the core objects and core clusters in the dataset. In order to reduce the number of computing units and improve the speed of operation, some core objects and core clusters will be merged by a rough rule. This process is called the first mergence, and its rule is as follows. Let C ={ C1, C2, . . . , C m } be a set of core clusters obtained by Definition 1, and CP ={ cp1, cp2, . . . , cp m } be a set of core objects. If there exist cp i , cp j ∈ CP, such that d (cp i , cp j ) ≤ 1.5r, then C i and C j will be merged into one. The sets of core clusters and core points after the first mergence are denoted as CF ={ CF1, CF2, . . . , CF q } and CFP ={ fp1, fp2, . . . , fp q }, respectively. Obviously, we have q ≤ m, and CF i and fp i may contain several core clusters and core objects, respectively.
The clusters after the first mergence doesn’t reach the final structure, therefore, the core clusters need to be merged further, and the rule is as follows: first, the inter-cluster distance of any two core clusters in CF is calculated using Definition 2. Then, the two core clusters with the smallest inter-cluster distance will be merged into a cluster, and the currently merged core cluster still participate in the next mergence until the remaining c clusters. The process mentioned above is called the second mergence. The sets of core clusters and core points after the second mergence are denoted as CS ={ CS1, CS2, . . . , CS c } and CSP ={ sp1, sp2, . . . , sp c }, respectively.
All core clusters have been allocated after the first and second mergence, but there are some non-core objects that have not been allocated. To complete the allocation of these objects, Definition 3, Definition 4 and Definition 5 are presented.
The distance similarity and density similarity can reflect the membership degree of an object belonging to a cluster, but they ignore the influence of other clusters. In this paper, the distance similarity and density similarity are transformed by the concept of relativity. It can be found that the relative distance similarity and relative density similarity take into account the competitiveness of each cluster for an object, so that they can better reflect the membership degree of an object belonging to a cluster.
According to Definition 3, Definition 4 and Definition 5, these non-core objects will be allocated to the cluster with the greatest similarity to themselves. The above process is called the third mergence.
RTCBTF aims to improve the efficiency of outlier detection by partitioning the dataset into several subsets. Therefore, its time cost also needs to be as low as possible. As shown in Algorithm 1, RCBTF only needs to traverse the dataset once when extracting all the core clusters and core objects, and subsequent mergence are based only on the core objects. Obviously, it doesn’t need too many objects to participate in the clustering process. The idea mentioned above is to satisfy the need of RCBTF algorithm with low time cost.
According to the analysis in Section 2, the LOF can describe the abnormal degree of objects, but most of the existing variants are still inadequate. For example, Fig. 2 shows two different local distribution of the object x0, where Fig. 2(a) and Fig. 2(b) have the same neighborhood distance and the variation of neighborhood distance for object x0. The two datasets in Fig. 2 are called DS1 and DS2, respectively. Apparently, the abnormal degree of x0 is different in the two plots. Therefore, it is not sufficient to describe the local distribution within the nearest neighbors, if only considering the neighborhood distance and its variation. To address the deficiency of the existing rules of calculating the local outlier factor, we fully takes the local distribution into account and introduces the module of k-neighborhood vector’s sum, so as to define a new enhanced local outlier factor. The specific rules are defined as follows.
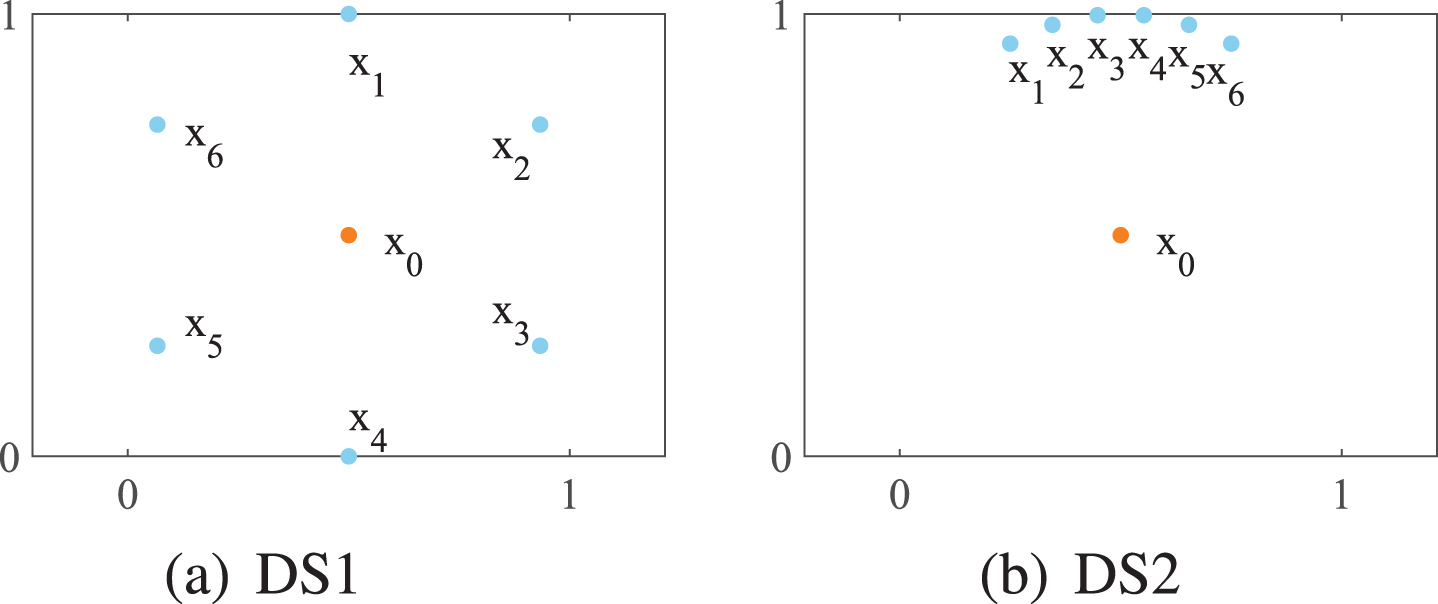
x0 and its neighborhood.
In general, normal object generally has a higher density than outlier in the same cluster, so the metric Nvector-m (x) has the following properties: The k-neighborhood of x is close to itself if x with high density, and its k-neighborhood distribute uniformly around x. Thus, we have Conversely, if x is an outlier, the values of set
So, outlier usually has a larger value of N vector_m (x) of Eq. (9) than normal object.
To further illustrate the properties of Eq. (10), we make the following analysis. If Navg_dist (x) as an independent variable, Nvector_m (x) be a constant, and N density (x) is treated as a dependent variable, then this function is strictly monotonically decreasing. Obviously, it conforms to the idea that the density decreases with the increment of the neighborhood average distance. On the contrary, if N density (x) is treated as a function of Nvector_m (x), and Navg_dist (x) be a constant, then this function is strictly monotonically decreasing. Obviously, it conforms to the idea that the density decreases with the increment of the module of neighborhood vector’s sum.
According to Definition 10, the NLOF (x) is the average of the ratio of the density of x and those of its neighborhood. It has the following properties: the greater NLOF (x) an object gains, indicates x has more opportunity to be an outlier, conversely, it is more likely to be a normal object. The details of outlier detection are shown in Algorithm 2.
It can be seen from Theorem 1 that RCBTF algorithm can reduce the time complexity of outlier detection. The maximum time complexity of decline is n2 (c - 1)/ - c, if and only if each subset with equal number of samples. Although RCBTF algorithm will bring additional time cost, the total time cost is still smaller than that of original algorithm. In the experiments, we will further explain this phenomenon.
To verify the effectiveness and efficiency of the proposed algorithms, a series of experiments are performed on synthetic datasets and real-world dataset. The proposed algorithm is compared with LOF, SimplifiedLOF and LDC from two aspects of precision and running time. In the experiments, Precision (Pr) and Coefficient of Variation (CV) are adopted to evaluate the detection performance. The calculation rules of them are defined as follows:
In this study, in order to illustrate the precision and time cost of the proposed method in this paper, we compare our method with other three algorithms (LOF, SimplifiedLOF, LDC) on five datasets, four of which are synthetic datasets shown in Fig. 2 and 3, another one is Shuttle obtained from UCI [32].
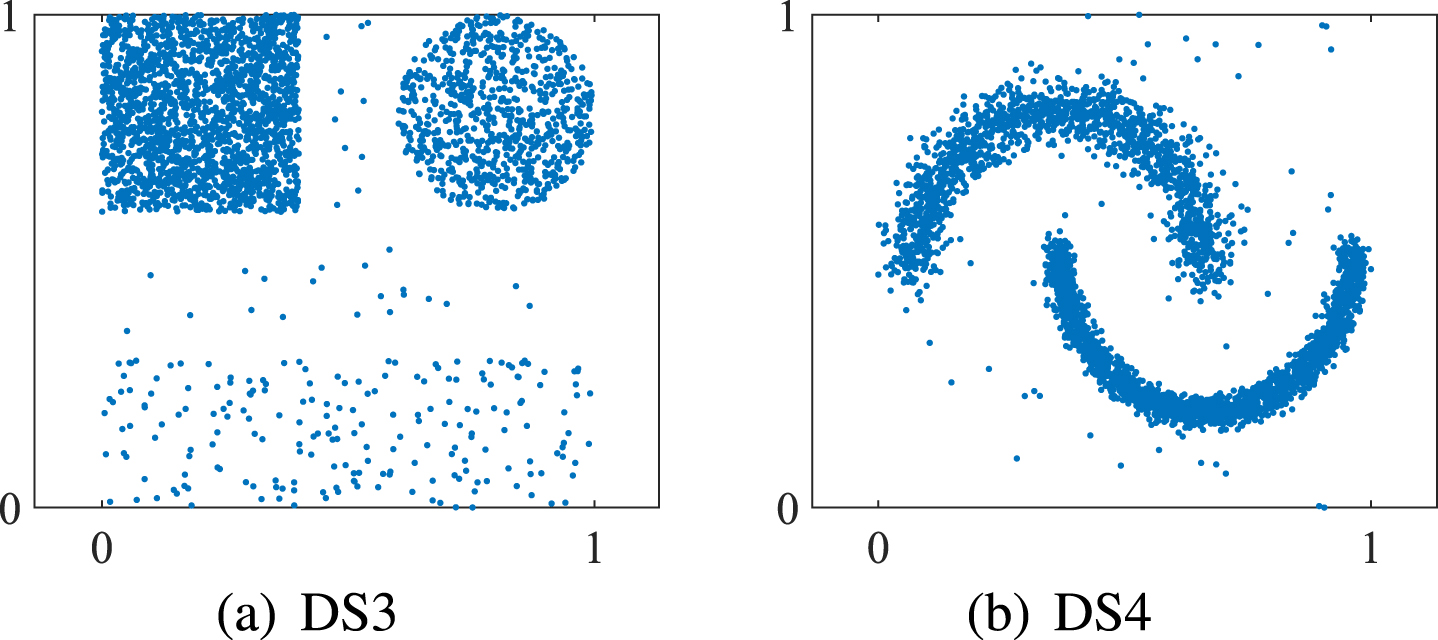
Synthetic datasets.
For the convenience of description, the two datasets in Fig. 3 are called DS3 and DS4, respectively. In Fig. 2, x0 is the center of a circle, while the other objects are located on the circle. In Fig. 3, DS3 and DS4 contain 3 and 2 clusters, respectively, which have different shape, size, and density. The Shuttle is usually used for classification. In this paper, the fourth and fifth categories of Shuttle are regarded as normal objects, while second, third, sixth and seventy categories are considered as outliers. The detail descriptions of datasets are shown in Table 1.
Descriptions of datasets
In DS1 and DS2, it is not difficult to find that the object x0 has the lowest deviation in Fig. 2(a), the object x0 has the highest deviation in Fig. 2(b). The experimental results of DS1 and DS2 are shown in Fig. 4. The abnormal scores obtained by the LOF are almost the same on DS1, which indicates that the task of outlier detection fails. In DS2, the LOF can accurately measure the abnormal degree of x0, but the abnormal scores of other objects are not accurate enough. Especially, it is completely ineffective when k = 6. SimplifiedLOF and LDC are effective for DS1 when k takes different values. But the abnormal scores of them are not accurate enough in DS2, and there are still failures (Fig. 4(e), Fig. 4(f)). The abnormal scores obtained by NLOF can accurately describe the abnormal degree of each object, which are effective for mining outliers using top-n schema.

Results of different k values on DS1 and DS2.
To further demonstrate the superiority of our method, precision (Pr) and coefficient of variation (CV) are adopted to evaluate the four algorithms on DS3, DS4 and Shuttle. In this experiment, we take r = 0.1, delta = 10. The parameters α (the number of outliers) and c (the number of clusters) are set according to Table 1. The experimental results with different values of k are shown in Table 2. Meanwhile, to reflect the detection results intuitively, the experimental results of four algorithms on DS3 and DS4 are visualized in Fig. 5.
Precision of four algorithms on DS3, DS4 and Shuttle
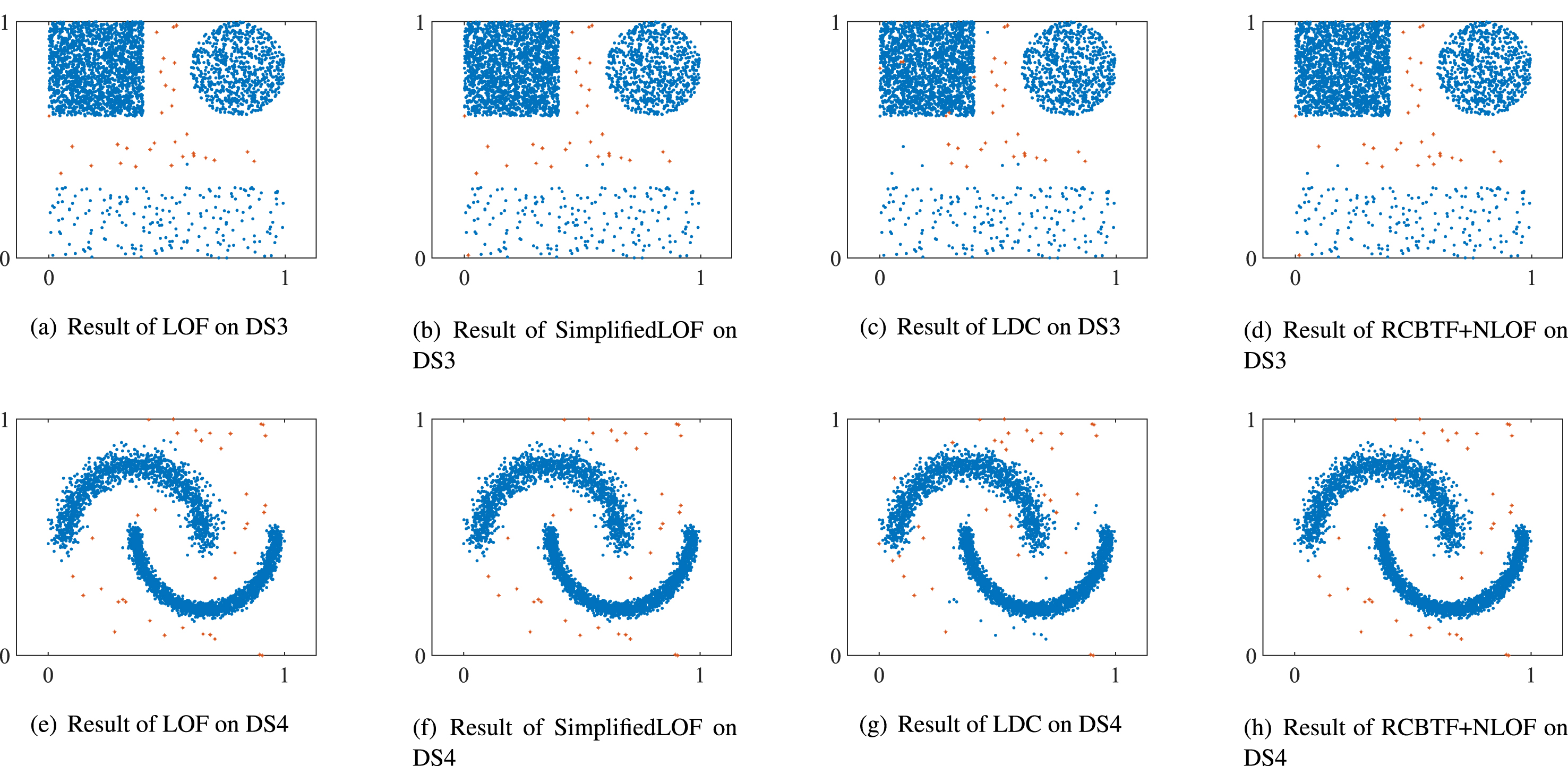
Results of four algorithms on DS1 and DS2 (k = 50). The outliers are marked as red.
In Table 2, all algorithms have high Pr values when k = 50 and k = 100. However, with the increment of k, the performance on LOF, SimplifiedLOF, and LDC shows a downward trend. Only the proposed algorithm can maintain high Pr values. In DS3, the precision of our method is lower than that of the LOF only when k = 50 and k = 100, but it is also very close to that of the LOF. As can be seen from the CV values in Table 2, LOF, SimplifiedLOF, and LDC algorithms are stable only in DS4. With the increment of k, the precision of them gradually decreased on DS3 and Shuttle, and CV values of them are greater than our method. In contrast, proposed method not only maintains the high Pr values, but also has low CV values when taking different k values. The experimental results show that: firstly, LOF, SimplifiedLOF and LDC are sensitive to the value of parameter k. Secondly, compared with the other three algorithms, the proposed algorithm has not only high precision, but also strong robustness to parameter k. In outlier detection, it’s hard to accurately determine the value of k without prior knowledge. Therefore, our method is more suitable for outlier detection than the others.
In order to fully illustrate the superiority of our method in time efficiency, the following experiments are designed to analyze the time efficiency of the four algorithms. Case 1: compare the NLOF+RCBTF with NLOF; Case 2: compare NLOF+RCBTF with other three algorithms; Case 3: combine the RCBTF with LOF, SimplifiedLOF, and simplified version of LDC (LDC that doesn’t use the approach of eliminating security objects, named SV_LDC), respectively; Case 4: combine the NLOF with different clustering algorithms (KMeans, KMeans++, and RCBTF). Compare the time efficiency before and after the combination. Note: the purpose of the experiment of Case 3 is to verify the effectiveness of combining RCBTF and extended LOF algorithms. There is a pre-processing algorithm in the LDC, which will eliminate part of objects and destroy the cluster-shaped structure of the dataset. Therefore, there is a conflict with the RCBTF. Based on the above two reasons, we only combine SV_LDC with RCBTF in Case 3. The experimental results of the above four cases are shown in Fig. 6, 7, 8 and 9, respectively. The number of objects of each cluster obtained by the RCBTF is shown in Table 3.
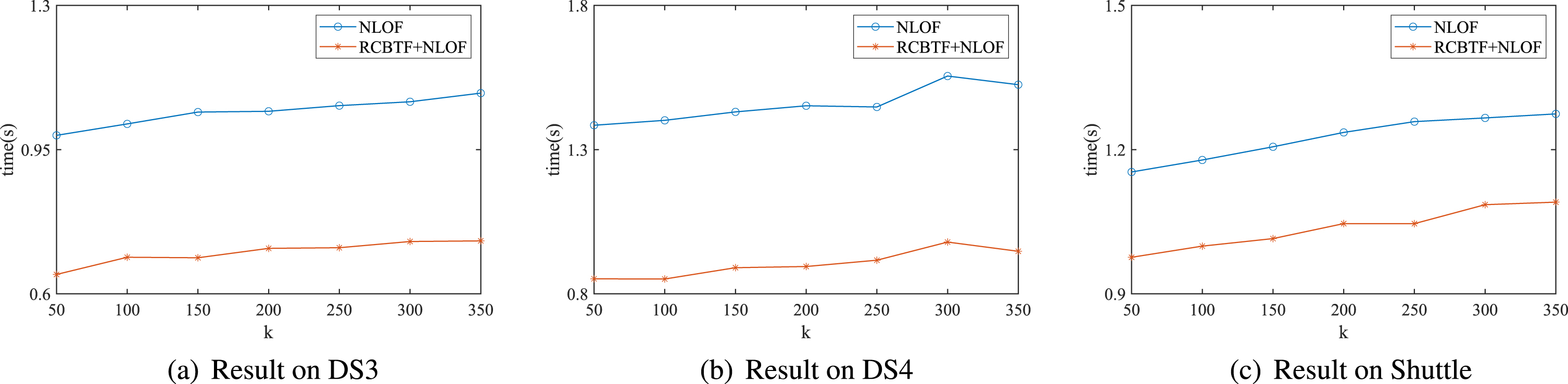
Running time of NLOF only and RCBTF+NLOF on DS3, DS4 and Shuttle.
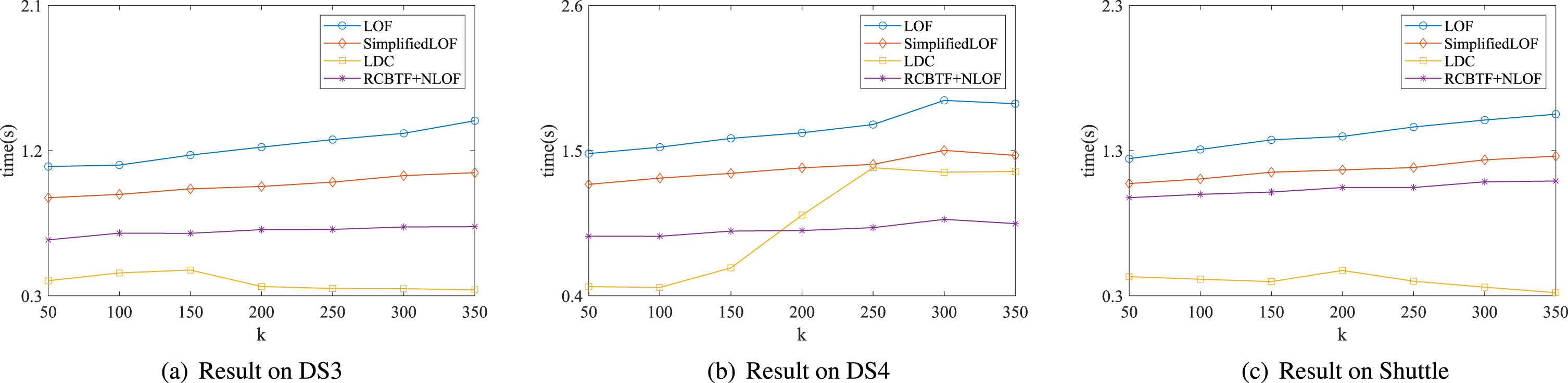
Running time of three comparative algorithms and RCBTF+NLOF on different datasets.
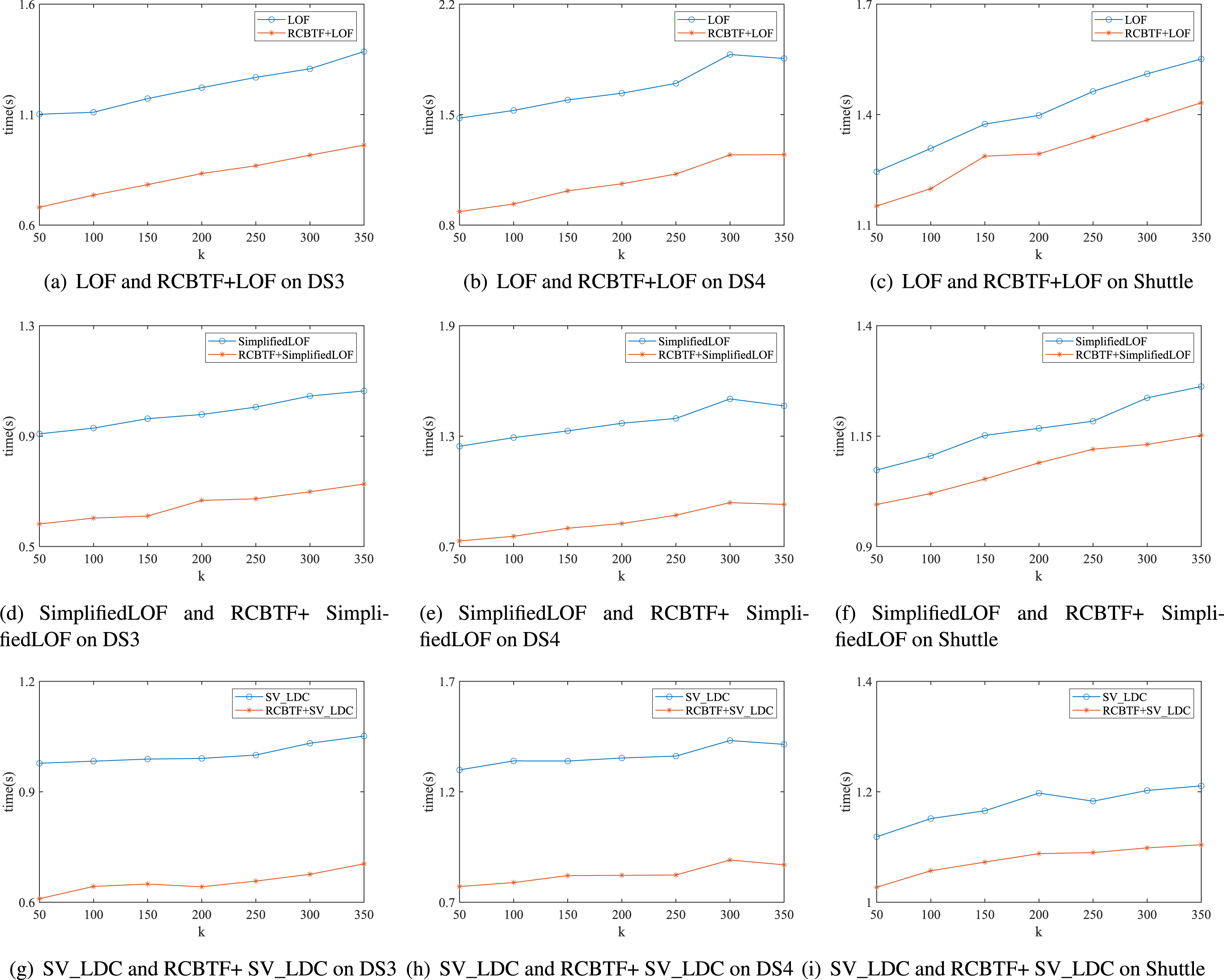
Running time of three comparative algorithms combined with RCBTF on DS3, DS4 and Shuttle.
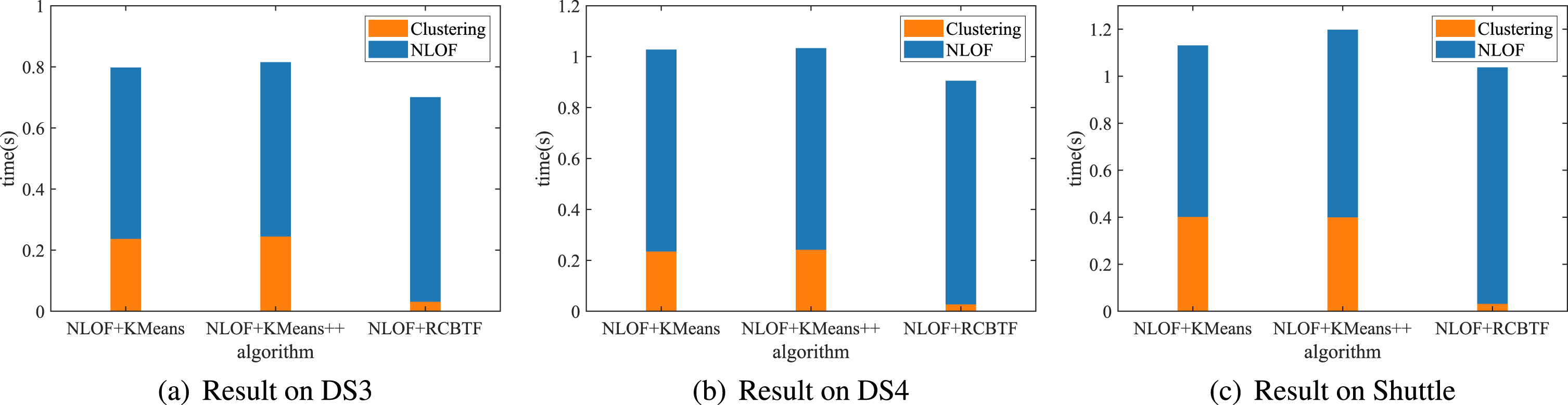
Running time of NLOF combined with different clustering algorithms on DS3, DS4 and Shuttle.
Size of each cluster obtained by RCBTF algorithm
From Fig. 6, it can be seen that RCBTF can improve the speed of NLOF on both synthetic datasets and real-world dataset. In DS3, DS4 and Shuttle, the time cost is reduced by 32.80%, 37.93% and 15.33%, respectively. There is a different degree of decline here, because the proportion of each cluster in the whole dataset is not consistent. It can be seen from the inequality mentioned in the first section of this paper that the more balanced the number of objects between clusters obtained by RCBTF, the more time cost reduces. Table 3 shows the number of samples in each cluster obtained by RCBTF. Obviously, the number of samples in each cluster is the most balanced in DS4, followed by DS3, and Shuttle is the most unbalanced. Therefore, the decrease of time cost is the largest in DS4, followed by DS3, and Shuttle is the smallest.
As shown in Fig. 7, we compare the time cost of four algorithm in the case of different k values. The SimplifiedLOF simplifies the density estimation of LOF algorithm. Therefore, compared with LOF, its time cost has been decreased to some extent, but it is still need to compute the abnormal scores on whole dataset for outlier detection. RCBTF+NLOF algorithm only calculates abnormal scores on each cluster, which reduces the scale of calculation, so its time cost is lower than that of SimplifiedLOF. It’s not hard to find out that LDC has the least time cost among the four algorithms. This is because it removes the security objects in the pre-processing process and detects the outliers on candidate outliers set containing a few objects. However, we can see two phenomena, first, when k = 200, k = 250, k = 300 and k = 350, the running time of LDC increases dramatically on DS4. Second, the running time of the LDC doesn’t increases with the increment of the value of k on DS3 and Shuttle. That’s because the value of k of LDC algorithm will influence the number of security objects eliminated by the pre-processing algorithm of LDC. The greater number of security objects pre-processing eliminates, indicates the efficiency has more opportunity to be improved. In terms of both precision and efficiency, the performance of our approach is competitive and promising. Overall, our method has better performance in the task of outlier detection.
Fig. 8 shows the experimental results of Case 3 mentioned above on DS3, DS4 and shuttle datasets. Obviously, the proposed RCBTF can not only be applied to NLOF, but also be combined with other extended LOF algorithms. To illustrate the efficiency of the RCBTF, three different clustering algorithms are combined with NLOF respectively. In Fig. 9, we show the average time cost of NLOF combined with different clustering algorithms in different k values. It is obvious that the time cost of RBCTF is less than KMeans and KMeans++. Moreover, the total time cost is lower than the others when RBCTF is used as pre-processing algorithm. Therefore, RCBTF, which can effectively reduce the time cost of outlier detection, is an effective pre-processing approach.
In this study, an efficient outlier detection optimized by rough clustering is proposed.
To improve the efficiency of outlier detection, an efficient rough clustering method based on triple fusion (RCBTF) is designed. The main idea of RCBTF is to design three mergence methods, which can merge core clusters and non-core objects. In the process of mergence, both distance and density are employed to complete clustering. In the first and second mergence, the core clusters are merged. The purpose of the third mergence is to allocate non-core objects to the core cluster.
In addition, a new local outlier factor (NLOF) is reconstructed by using the neighborhood distance and the module of neighborhood vector’s sum, which fully takes advantage of the local distribution of an object within its neighborhood. Experimental results show that: first, the RCBTF not only effectively reduces the time cost of NLOF, but also can be directly applied to other extended LOF algorithms. Secondly, the RCBTF+NLOF has higher precision than the others on synthetic datasets and real-world dataset. In the future, the proposed approach will be further optimized and applied to various practical applications.
Footnotes
Acknowledgments
This work was supported by Chongqing University Innovation Research Group funding (No. CXQT20015), the Key Science and Technology Research Program of Chongqing Municipal Education Commission (No. KJZD-K201900505), and Research Project of Chongqing Normal University (No. YKC20032).