
Abstract
Multi-focus image fusion is a technique that integrates the focused areas in a pair or set of source images with the same scene into a fully focused image. Inspired by transfer learning, this paper proposes a novel color multi-focus image fusion method based on deep learning. First, color multi-focus source images are fed into VGG-19 network, and the parameters of convolutional layer of the VGG-19 network are then migrated to a neural network containing multilayer convolutional layers and multilayer skip-connection structures for feature extraction. Second, the initial decision maps are generated using the reconstructed feature maps of a deconvolution module. Third, the initial decision maps are refined and processed to obtain the second decision maps, and then the source images are fused to obtain the initial fused images based on the second decision maps. Finally, the final fused image is produced by comparing the QABF metrics of the initial fused images. The experimental results show that the proposed method can effectively improve the segmentation performance of the focused and unfocused areas in the source images, and the generated fused images are superior in both subjective and objective metrics compared with most contrast methods.
Introduction
Due to the limitations of natural and physical conditions, it is difficult for the ordinary optical digital camera to capture images with all-in-focus, simultaneously. Multi-focus image fusion can integrate the focused areas of different source images into a fully focused image, resulting in more complete information and better visual effects [1–6]. As an important branch of image fusion, multi-focus image fusion has been widely used in computer vision [7], macrophotography [8], microscopic imaging [9], mobile applications [47], and other applications [48–50].
In the past decades, many multi-focus image fusion methods have been proposed, which can be broadly divided into two categories: conventional methods and deep learning-based methods. There are some well-known conventional methods, such as wavelet transform [10], crossover bilateral filter (CBF) [11], discrete wavelet transform (DWT) [12], discrete cosine harmonic wavelet transform (DCHWT) [13], dual-tree complex wavelet transform (DTCWT) [14], curvelet transform (CT) [15], and non-subsampled shearlet transform (NSST) [16]. In these methods, the source image is first decomposed to obtain a set of sub-images representing the information of space and frequency. Then, the sub-images of different source images are fused by a certain fusion rule. Finally, the inversion transformation is performed to obtain the fused image [51]. However, most of these methods are relatively complex and have certain limitations in terms of feature extraction and fusion strategy. Besides, most conventional methods are limited in the performances and may produce unexpected artifacts.
With the rise of computing device and theory, deep learning is showing strong power in both industrial and academic fields. Therefore, many multi-focus image fusion methods based on deep learning have emerged. Du et al. [17] proposed a multi-focus image fusion method based on image segmentation and multi-scale convolution neural network. This network performs multi-scale analysis on each input image to obtain independent feature maps on the boundary of focused and unfocused regions. Then, these feature maps are fused to generate the fused feature map. After initial segmentation, morphology, watershed and other post-processing operations, the final fusion decision map is then obtained. Tang et al. [18] proposed a multi-focus image fusion method based on a neural network, they firstly set the corresponding fusion labels on the samples of dataset according to different focus levels, and then the p-CNN was trained to measure the focus level of each pixel for fusing them. Li et al. [22] proposed a method to respectively fuse the chromaticity and luminance components of the color multi-focus images in YCbCr space. In Li’s method, a U-net was trained to fuse the luminance components in YCbCr space by a hybrid objective function containing L1 loss and SSIM loss. Besides, a weighting strategy was used to merge the chromaticity components in YCbCr and obtain fused images. Li and Guo et al. [19] proposed deep regression pair learning (DRPL), which divided the input image into some small patches and applied a classifier to judge whether the patch was the focused or unfocued areas, and used the DRPL directly to convert the whole image into a binary mask. Liu et al. [18] utilized Haar wavelet and simple fusion rules to propose a fusion algorithm that was suitable for hardware implementation. Jung et al. [19] proposed an unsupervised deep image fusion network (DIF-Net), which parameterized the entire processes of image fusion to generate an output image that had an identical contrast to high-dimensional input images.
However, deep learning based methods always require a large datasets of labeled images to train the model, but there are not so many natural image datasets for model training in multi-focus image fusion. Thus, the collection and production of large datasets becomes a time-consuming and laborious task; besides, the large datasets have high requirements on machine hardware to train models and have high time costs in model training. Thus, the applications of conventional deep learning-based methods are limited in many field of image fusion.
Fortunately, transfer learning can be used to address these problems in conventional deep learning based methods. In transfer learning, the source task usually has a large number of training samples, and the target task usually has limited training samples. Therefore, the knowledge and feature extraction ability learned from the source task can be employed to improve the performance of the target task. In this way, we do not need to retrain a new model with a large amount of training data to complete the target task. In image fusion, it is difficult to produce a large number of training samples to train a deep learning model. Therefore, a novel color multi-focus image fusion method is proposed based on transfer learning, which also exploits the advantages of deep learning to achieve competitive performance based on a pre-trained model (VGG-19). The contributions of this paper are presented as follows: This paper proposes a novel transfer learning-based color multi-focus image fusion method by combining deep learning model, in which the VGG-19 network is transferred into our newly defined model for feature extraction. An efficient network structure is designed for feature reconstruction that is used to generate the fusion decision maps; besides, a layer-by-layer hybrid loss function is introduced to better supervise the training and improve the robustness of the network. Unlike most previous methods based on image patches or blocks [18], this work makes pixel-level predictions for both focused and unfocused areas in an entire source image to fuse them.
The remainder of the paper is divided into four sections. The second section briefly describes transfer learning and the VGG-19 network. The third section details the proposed method. The fourth section analyzes the experimental results. The last section summarizes this paper.
Related work
In this section, we briefly introduce the background knowledge about convolutional neural network and transfer learning. In addition, since our transfer learning network is based on VGG-19, we first briefly describe the VGG-19 network model.
Convolutional neural network
Convolutional neural network (CNN) is one of the most representative models in deep learning, and it has made many breakthroughs in image processing. The convolutional layer is the crucial component of CNN, which extracts the specific features of the image by the different sizes of the convolution kernels. After applying the convolutional layers several times, a set of feature maps of input images can be extracted. Let C
i
represent the feature map of the i-th layer in our network, then the C
i
can be generated as follows:
Because of the excellent performance, the transfer learning (TL) [23, 33] is now widely used in computer vision [36], text classification [34], natural language processing [37], medical image processing [35], and other fields.
Given a source domain D S and source task T S a target domain D T and target task T T , TL aims to improve the learning performance of the target predictive function f (□) in D T using the knowledge in D S and T S , where D S ≠ D T , or T S ≠ T T [23].
The main idea of TL is to apply knowledge or patterns learned from a domain or task to another related domains or problems. By transferring the labeled data or knowledge from source domain, and the learning efficiency and performance of the target domain or task will be improved. Generally, TL can be divided into four categories according to transferring way: instance-based TL, feature-based TL, parameter/model-based TL, and relation-based TL. Parameter/model-based TL is a transfer method to find the parameters shared between the source and target domains. This transfer way has an assumption that the data in the source domain and the target domain can share some important model parameters. This work is a parameter/model-based TL model that is transferred from the VGG-19 network.
Since the VGG-19 network has been trained to learn excellent feature extraction capabilities with stable network parameters, we transferred its convolutional layer parameters and rebuilt a new hybrid network based on the transferred parameters for fine-tuning, thus our network inherited the VGG-19 parameters and had excellent feature extraction capabilities. Figure 1 describes our idea of transfer learning in this work.

Our idea of transfer learning.
The VGG [24] network is a very classic model in the field of deep learning, proposed by the Visual Geometry Group at Oxford University.
The VGG network was trained on a massive image samples and widely-used in many fields. The VGG network has two architectures as: VGG-16 and VGG-19, and this paper implements TL based on the VGG-19 to complete the multi-focus image fusion task. The VGG-19 contains 16 convolutional layers, five max-pool layers, two fully connected layers and a Softmax layer.
The proposed method
In this section, the proposed method is introduced in detail. Firstly, we introduce the overall processes and network architecture; meanwhile, the feature extraction and feature reconstruction module, as well as the implementation of TL are explained. Then, we provide the definition of the loss function.
Overall processes and framework
The proposed network consists of two parts: feature extraction module, and feature reconstruction module. The network architecture is shown in Fig. 2, and the steps are shown as follows:
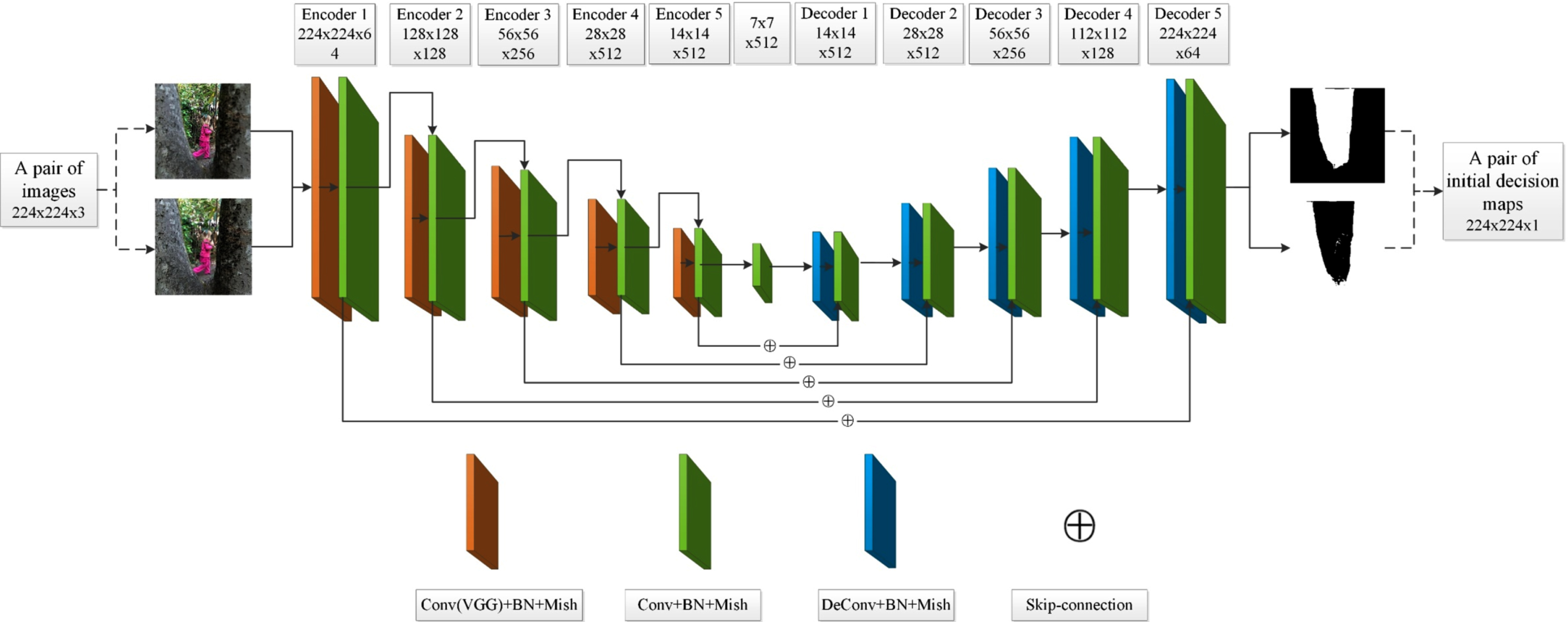
The proposed network architecture.
A pair of color source images (224×224 pixels) are fed into the pre-trained VGG-19 network for initial feature extraction. The convolutional layer parameters of the VGG-19 network are transferred into our designed feature extraction module to get the feature maps. The obtained feature maps are input into the feature reconstruction module that can generate the initial decision maps. The initial decision maps are processed by logical operation to obtain second decision maps, and pixel-level fusion process is performed based on the second decision maps to obtain the corresponding initial fused images. The Qabf metric of the initial fused images are calculated respectively, and the fused image with the higher Qabf metric are output as the final fused image.
In Fig. 3, the feature extraction module has five Encoders, in which the Encoder 1 and Encoder 2 have the same network structure, and the Encoders 3, 4 and 5 have the same network structure. Both the Encoder 1 and Encoder 2 contain seven convolutional layers, in which the first two layers (the orange layers) are the transferred convolutional layers from the VGG-19 network, thus the word “VGG” is marked to indicate them. The next five layers are routine convolutional layers defined by us for depth feature extraction, in which do not have the word “VGG”. Encoders 3, 4, and 5 all contain nine convolutional layers, and their network architectures are the same as Encoders 1 and 2, in which the first four layers are convolutional layers transferred from the VGG-19 network and the last five layers (the green layers) are routine convolutional layers. Thus, the naming way of convolutional layers in Encoders 3, 4, and 5 are the same as Encoders 1 and 2.
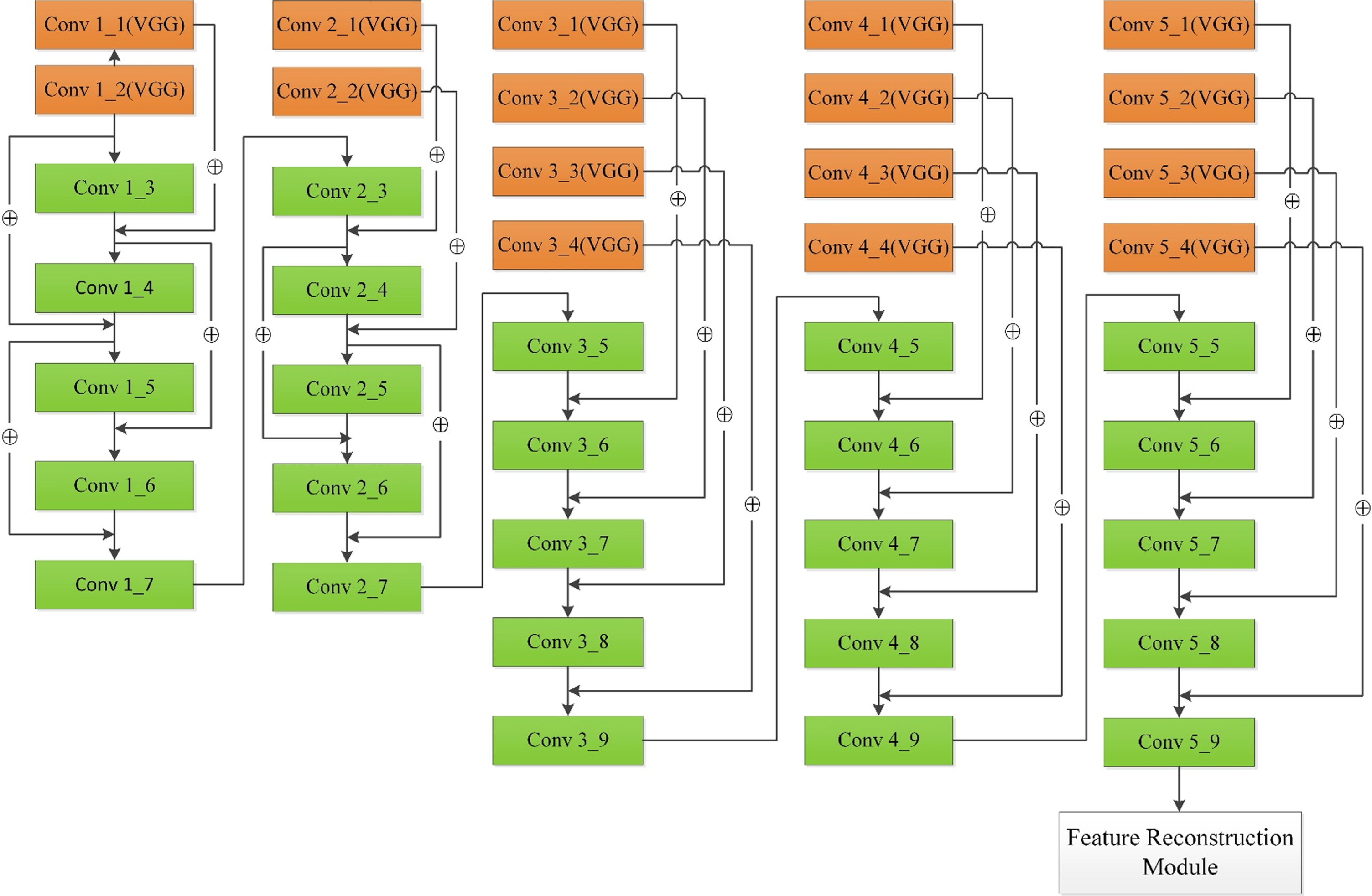
Feature extraction module.
Firstly, the source images are inputted into the pre-trained VGG-19 network for initial feature extraction. Secondly, all the parameters of the VGG-19 networks convolutional layers are correspondingly transferred into our designed network. Thirdly, the transferred convolutional layers and our newly designed layers are combined for secondary feature extraction. The VGG-19 network has been trained on a massive dataset and has achieved excellent results in many fields that can be regarded as source domain, thus we transfer the parameters of the pre-trained VGG-19 network into our model to apply them for color image fusion (target domain). In this method, the transferred VGG-19 network is used to segment the focused and unfocused areas in the source images, which can be regarded as a parameter/model based TL. The source images are inputted into the network, and five Encoders are used for feature extraction.
Thus, after the processing of each Encoder, the size of the feature maps will become quarter of the original images, and the size of the feature maps of the feature extraction module is reduce to 7×7 pixels from the initial 224×224 pixels. To retain more detailed information of the source images, we employ the convolution operations instead of the pooling operations to reduce the dimensionality of feature maps. In the last layer of each Encoder, we set the size of its convolution kernel as 3×3, the stride is set as 2, the padding is set as SAME. In addition, in the feature extraction module, except for the last convolutional layer of each Encoder, we set the size of the convolution kernels of all other convolutional layers as 3×3, strides is set as 1, padding is set as SAME.
Figure 4 shows the structure of Encoder 1, in which each convolutional block consists of a convolutional layer, a Batch Normalization (BN) layer, and a Mish activation function layer. Similarly, the convolutional blocks of the other Encoders have the same structure, in which each convolutional layer followed by a BN layer and a Mish activation function layer.

Encoder 1.
The adopted feature reconstruction module and skip-connection is introduced in this sub-section.
Feature reconstruction module
In Fig. 2, the feature reconstruction module also includes five Decoders that is corresponding to the feature extraction module. Decoder 1, 2 and 3 have the same network structure, which are composed of one deconvolution layer and eight feature reconstruction convolution layers. The Decoder 4 and Decoder 5 have the same network structure, they are composed of one deconvolution layer, and six feature convolutional reconstruction layers. In the Decoders, a BN layer and a Mish activation function layer follow each deconvolution layer and each convolutional layer.
In Fig. 5, the feature maps outputted by the feature extraction module will be inputted into the Decoders of the feature reconstruction module for feature reconstruction. After each deconvolution layer, the size of feature map will be expanded to quadruple of the original size, and the feature maps will be fused with the corresponding feature maps in the feature extraction module, and then the feature maps are fed into the next feature reconstruction convolutional layer combined by the skip-connection structure. The size of the final output feature maps was expanded to 224×224 from 7×7, and the size is the same as that of the original map and source images. The predicted map has only two values, as 0 and 1, which is regionally distributed and represent the focused and unfocused areas of the source image. At last, the loss function is used to analyze the errors between the predicted map and the label image (Ground-Truth). In the all Decoders, the size of all deconvolution kernel is set as 4×4, and the strides is set as 2, padding is set as SAME. The size of all convolutional kernel is set as 3×3, and the strides is set as 1, and padding is set as SAME.
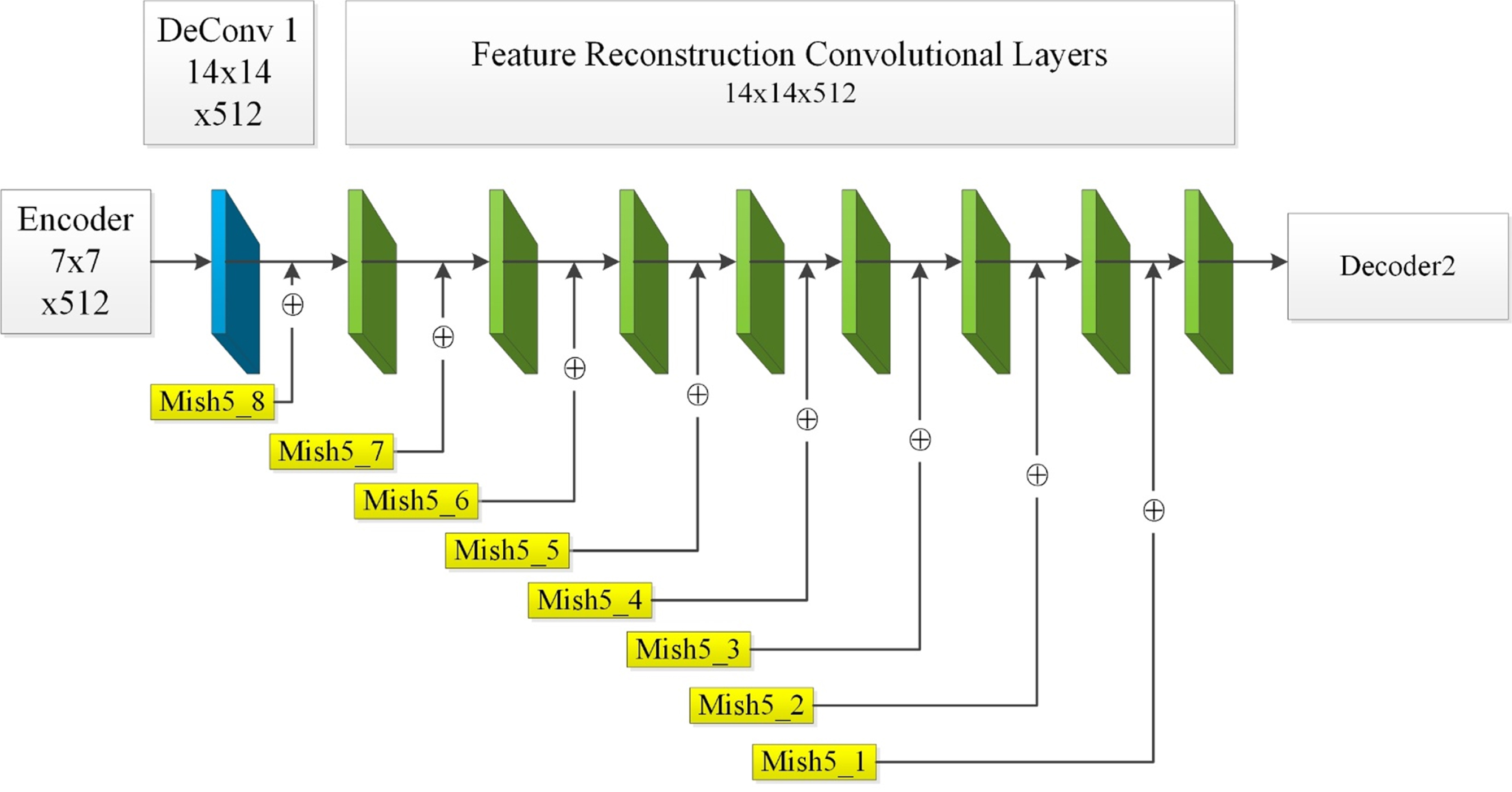
Decoder 1.
As shown in Figs. 2, 3, the layers marked by arrow are concatenated to input the feature maps into the next layers. By the skip-connection operations, the low-level and high-level features are integrated, allowing the network to retain more detailed information. In addition, the skip-connection can effectively overcome the problem of gradient disappearance and network degradation while the network deepens.
The operation of skip-connection is shown as follows:
In this work, the label “1” is used to mark the unfocused areas in the source images; conversely, the label “0” is used to mark the focused areas. In model training, we assume the network has learned the distribution of the label images when the loss function stabilizes at a sufficiently small interval. To better supervise the learning of the network, we use the layer-by-layer hybrid loss function to train our network. That is to say, in the feature reconstruction module, we put the feature map output by each Decoder into the loss function and calculate the loss value with ground-truth, and the weighted average of the five loss values is our final loss value. Our network uses a hybrid loss function that combines cross entropy loss and L2 loss, and the hybrid loss function is formulated as:
In Formula 6, the Softmax function is used to normalize the output components that is corresponding to each category of the network, its output is a probability that the input data belongs to each category.
In Equation 7,
Our TL-based model first outputs a pair of initial decision maps M1 (i, j) and M2 (i, j) that are corresponding to the source image S1 and S2. The initial decision maps are a pair of binary images that only have 0 and 1, where the black area is 0 and the white area is 1, marking the focused and unfocused areas of the source image S1 and S2, respectively. While the initial decision maps generated by our model can accurately predict most of the focused and unfocused areas in the source images, there may be some prediction errors, such as Fig. 6(a) and (b).

Initial decision maps and secondary decision maps.
To solve this problem, we propose a sample method to integrate the decision maps and produce the fused images. We take a pair of source image as an example that is shown in Fig. 6, the initial decision maps are respectively M1 (i, j) and M2 (i, j), and the secondary decision maps are respectively M4 (i, j) and M5 (i, j). In this method, a logical operation is first used to refine the initial decision maps, resulting in a second pair of decision maps M4 (i, j) and M5 (i, j), such as Fig. 6(c) and (d). Secondly, the decision maps M4 (i, j) and M5 (i, j) are respectively used to produce the fused images F1 (i, j) and F2 (i, j). Thirdly, the Q ABF metric of the fused images F1 (i, j) and F2 (i, j) are computed, respectively. Finally, we take the fused image with the higher Q ABF metric as the final fused image, thus the decision map M4 (i, j) in Fig. 6(c) is selected to produce the result.
The proposed operation is shown as the Pseudo-Code of Fusion Strategy.
In this section, we firstly introduce the production of the training set, and then the setting of the key parameters in model training is introduced. In order to verify the performance of our method, several state-of-the-art methods are employed to compare with the proposed method, and five common metrics are used to evaluate the quality of different fused images.
Production of training dataset
In this work, 2000 natural images and the corresponding 2000 label images were selected from the PASCAL VOC 2012 image dataset. To better fit the natural multi-focus scene captured by the digital camera, we made 5 fuzzy levels of these 2000 natural images after five times of Gaussian filtering (window size is 3×3, and the standard deviation is 2). Firstly, the selected natural images are filtered once to get the fuzzy level 1; then, the same Gaussian filter is done again on the image set of level 1 to get the fuzzy level 2; after repetitive operation, we can obtain 5 fuzzy levels of image dataset. Therefore, each fuzzy level contains 2000 images, and the total number of fuzzy images in our dataset is 10000. Then, according to the segmentation label and fuzzy strategy, image-stitching operation is performed on the 10000 images to get a new dataset including 10,000 pairs of color multi-focus images. In each image pair, the focused in one image is complementary with the unfocused areas of the other one. Some information about the production of dataset can be found in [25].
For model training, the dataset divides into a training set and a validation set, and the training set contains 9000 pairs of multi-focus images with 9000 pairs of label images. The 9000 pairs of training images contain five fuzzy levels, and each level contains 1800 image pairs. The validation set contains 1000 pairs of multi-focus images with 1000 pairs of label images, the 1000 pairs of images also have five fuzzy levels, and each level contains 200 image pairs. Figure 7 shows our training images and the corresponding label image.

Training images and corresponding label images. (The first row are the multi-focus training images; the second row are the corresponding label images, which the black area pixels are 0 and the white area pixels are 1, marking the focused and unfocused areas of the source images respectively.
The experiments are implemented on the TensorFlow framework. During the training phase of the network, we use Xavier initialization [41] method to initialize all convolution kernel parameters except for the convolutional layers that migrated from the VGG-19 network. The RMSprop [42] optimizer is used to train our network. Initial learning rate is set as 1e-6; weight decay and momentum are respectively set as 0.001 and 0.9, and the finalized network model is obtained after 50 epochs of training.
Parametric ablation experiment
To verify the influence of the key parameters on the proposed method, we carried out some comparative experiments. We use a single cross entropy loss function to replace the layer-by-layer hybrid loss function, and name the network as Compare-loss. Based on the original network, we removed the BN layer, and named the new network as Compare-bn. We also changed the initialization mode of the convolutional layer in the network from Xavier to normal initialization, and named this network as Compare-initial. We trained these three networks to get the experimental results respectively. The comparison results are shown in the Table 1, the ablation experiments of these key parameters show that the final model of our proposed method achieves best results each metric.
Comparison of parametric ablation experiments
Comparison of parametric ablation experiments
To get an available model, we carried out a large number of experiments to verify the performance of the proposed model. We performed several experiments to verify the stability of our proposed method. In this sub-section, we retrain our neural network another four times to get four image fusion models, and the testing results of these models are shown in Table 2 and Fig. 8.
The quality metrics after five experiments
The quality metrics after five experiments
As shown in Fig. 8, we cannot distinguish the difference among the experimental results of the five image fusion models, subjectively. We can find that the stability of our model is satisfactory, visually. In Table 2, we can see that the difference among the evaluation indicators obtained from the five experiments is very small, which shows the stability of the model proposed in terms of objective indicator.

Model stability verification.
To further verify the effectiveness of TL-based method, we also train a non-TL-based network whose structure was the same as the TL-based method for color multi-focus image fusion, and the experiments are shown in Fig. 9 and Table 3.

Comparison of TL-based method and our non-TL-based method.
The quality metrics of TL-based method and our non-TL-based method
In the red boxes marked in Fig. 9, some blurred areas appear in the fused images obtained by the non- TL-based method. However, the fused images obtained by the TL-based method performs well without artifacts or blurred areas. The results show that the proposed TL-based method can achieve better performance compared with non-TL-based model. The evaluation metrics are listed in Table 3. The values of Q ABF , Q MI , and Q AG of the TL-based method are better than those of the non-TL-based method.
The Q SF values of the TL-based method are better than that by the non-TL-based method, except the fifth image pair. Besides, the Q LABF value of the TL-based method are better than that of the non-TL-based method. In general, the metrics of the fused images obtained by the TL-based method are better than those by the non-TL-based method.
To demonstrate the effectiveness of the proposed method, several popular image fusion methods are contrasted with the proposed method, including ASR [26], CSR [27], DWT [40], MSVD [28], GD [38] MSTSR [29], MGIVF [30], PCA [40] IFCNN [46], SESF [45] and NEMI [32]. Moreover, the “Lytro” [39] dataset is employed to indicate the performance of different image fusion methods, and it is a commonly used dataset for multi-focus image fusion.
Five commonly used objective evaluation metrics are employed to evaluate the quality of fused images of different fusion methods, such as spatial frequency (Q SF ), edge feature similarity (Q ABF ), overall in formation loss (Q LABF ), mutual information (Q MI ) and average gradient (Q AG ). Among them, for the Q LABF values, the smaller is better; for the other metrics, the larger values indicate the better quality of fused images.
The expression of Q
SF
is as follows:
Q
ABF
is an evaluation metric based on the richness of edge information and presented is as follows:
Q
LABF
can be used to present the feature loss of the fused image and is expressed as follows:
Q
MI
is a measure of the interdependence between variables, and its expression is as follows:
Figure 10 shows the fused results of the first image pair, it can be seen that the color distortion of the fused images obtained by DWT and GD methods is relatively obvious than that of the fused images produced by other methods, and this phenomenon slightly exists in the fused image obtained by ASR. The loss of texture information of the fused images obtained by MVSD and PCA methods is serious, so that the visual quality of their whole images is poor. Some details of the fused images obtained by MGIVF and NEMI methods are missing, for example, the upper edge of the head of koala (as marked by the red box in Fig. 10) are obviously fuzzy. The quality of fused image obtained by CSR, and the proposed method is superior to that of other methods. In Fig. 11, the texture and detail of the fused images generated by MVSD and PCA methods are obviously lost, which can also be found in Fig. 12. Besides,

The first group of fused images.

The second group of fused images.

The third group of fused images.
Figure 11 also reveals some detail loss in the fused images obtained by GD and NEMI. In Figs. 13 and 14, the fused image obtained by DWT method is obviously dark compared with that by other methods. In Fig. 14, the fused images obtained by PCA, MSVD and GD have the phenomenon of detail loss and edge blur, while DWT and MGIVF have color distortion.

The fourth group of fused images.

The five group of fused images.
Generally, the proposed method has the better performance on image details and edges without the problem of significant artifacts or ambiguous areas in the fused image, which indicates that the performance of the proposed method is better than most of other comparison methods visually.
However, because of the uncertainty and subjectivity of human vision, the images quality obtained by some methods is difficult to be distinguished visually. Therefore, various evaluation indexes are employed to verify and analyze the performance of different methods from objective perspective.
The objective evaluation metrics of different fused images are shown in Tables 4–9. In Tables 4, 5, 6, and 9, the Q SF values obtained by proposed method is better than others, and the Q ABF value obtained by our method is better and closer to IFCNN and SESF methods, and the Q LABF value obtained by the SESF method is better than other methods and our method is the second. Besides, the Q MI value of the proposed method are most similar to NMEI method and generally better than other methods. It can be seen from Tables 4, 5, 6 and 8 that the metrics obtained by the proposed method are superior to that by other methods except the Q LABF . Besides, the Q ABF and Q AG values of the proposed method in Table 4 are far superior to that by other methods and close to the IFCNN and SESF. The Q MI value is slightly lower than that of fused image obtained by NMEI, and the Q LABF value is lower than SESF in Table 9, but other metrics obtained by the proposed method are better than those of other methods. In Table 8, the Q MI value obtained by the proposed method is much better than other methods. According to above analysis, it can be found that the performance of the proposed method is generally better than most image fusion methods in objective evaluation metrics.
The quality metrics of the first group of fused images
The quality metrics of the second group of fused images
The quality metrics of the third group of fused images
The quality metrics of the fourth group of fused images
The quality metrics of the five group of fused images
The quality metrics of the sixth group of fused images
More experiments of the proposed method are shown in Fig. 16, in which we can find the focused areas of source images are effectively extracted and fused into the final images. In summary, the proposed method can achieve good performance in color multi-focus image fusion. Besides, the fused images have superior visual quality compared with those of other methods and have better performance in objective evaluation indexes as well. This experiment shows that the TL-based image fusion method is feasible and effective.

The sixth group of fused images.

More fused images obtained by the proposed method. (The first and second column are the multi-focus source images, and the third column are the fused images).
In summary, the proposed method can achieve good performance in color multi-focus image fusion. Besides, the fused images of the proposed method have superior visual quality compared with those of other methods and have better performance in objective evaluation indexes as well.
This paper proposes a color multi-focus image fusion method based on transfer learning. First, the trained VGG-19 was used to extract the primary features of the source images, and then an efficient network was designed based on the convolutional layer parameters transferred from the VGG-19 network, so that the image features are extracted again based on the newly designed network. Second, the primary decision mask is obtained by inputting the extracted deep features into the reconstruction network. Finally, an effective fusion strategy was designed to synthesize the fusion decision masks and generated the fused image. The experiments show that the proposed method is competitive. This work shows that the image fusion method based on transfer learning is feasible.
Based on the trained VGG-19 model, this paper realizes the transferring and reusing of the structures and parameters of VGG-19 network, which is combined with the newly designed model to achieve feature extraction of the source images. Given the advantages of TL, we will introduce TL to complete other image fusion tasks in future studies, such as remote sensing image fusion and medical image fusion.
Footnotes
Acknowledgments
This research was funded by the National Natural Science Foundation of China (Nos. 62101481, 62002313, 62066049), Key Areas Research Program of Yunnan Province in China (202001BB050076), Key Laboratory in Software Engineering of Yunnan Province in China (2020SE408).