
Abstract
The prime focus of knowledge distillation (KD) seeks a light proxy termed student to mimic the outputs of its heavy neural networks termed teacher, and makes the student run real-time on the resource-limited devices. This paradigm requires aligning the soft logits of both teacher and student. However, few doubts whether the process of softening the logits truly give full play to the teacher-student paradigm. In this paper, we launch several analyses to delve into this issue from scratch. Subsequently, several simple yet effective functions are devised to replace the vanilla KD. The ultimate function can be an effective alternative to its original counterparts and work well with other skills like FitNets. To claim this point, we conduct several visual tasks on individual benchmarks, and experimental results verify the potential of our proposed function in terms of performance gains. For example, when the teacher and student networks are ShuffleNetV2-1.0 and ShuffleNetV2-0.5, our proposed method achieves 40.88%top-1 error rate on Tiny ImageNet.
Introduction
With the development of mobile devices at hand, the user requirement for automatic visual tasks like object recognition and verification using machine learning methods becomes essential. Many advanced deep neural networks, compared with previous shallow-layer models, however, are too large to be equipped thereon due to expensive inference time overhead. This drives the proceeding of network compression technologies. Among them, a fundamental and versatile approach – and now commonly incorporated in many visual tasks including object tracking [2], object detection [20, 32], etc.– is knowledge distillation termed KD. The early idea of KD is originally introduced by Ba and Caruana [1], but the concrete concept of KD is proposed by Hinton et al. [14], which is presented in Figure 1. Different from its siblings such as network pruning [9, 12] and layer decomposition [15], which removes the so-called redundant components in light of a predefined rule, KD searches for a light proxy as the student network to mimic the outputs of its heavy neural network termed teacher.
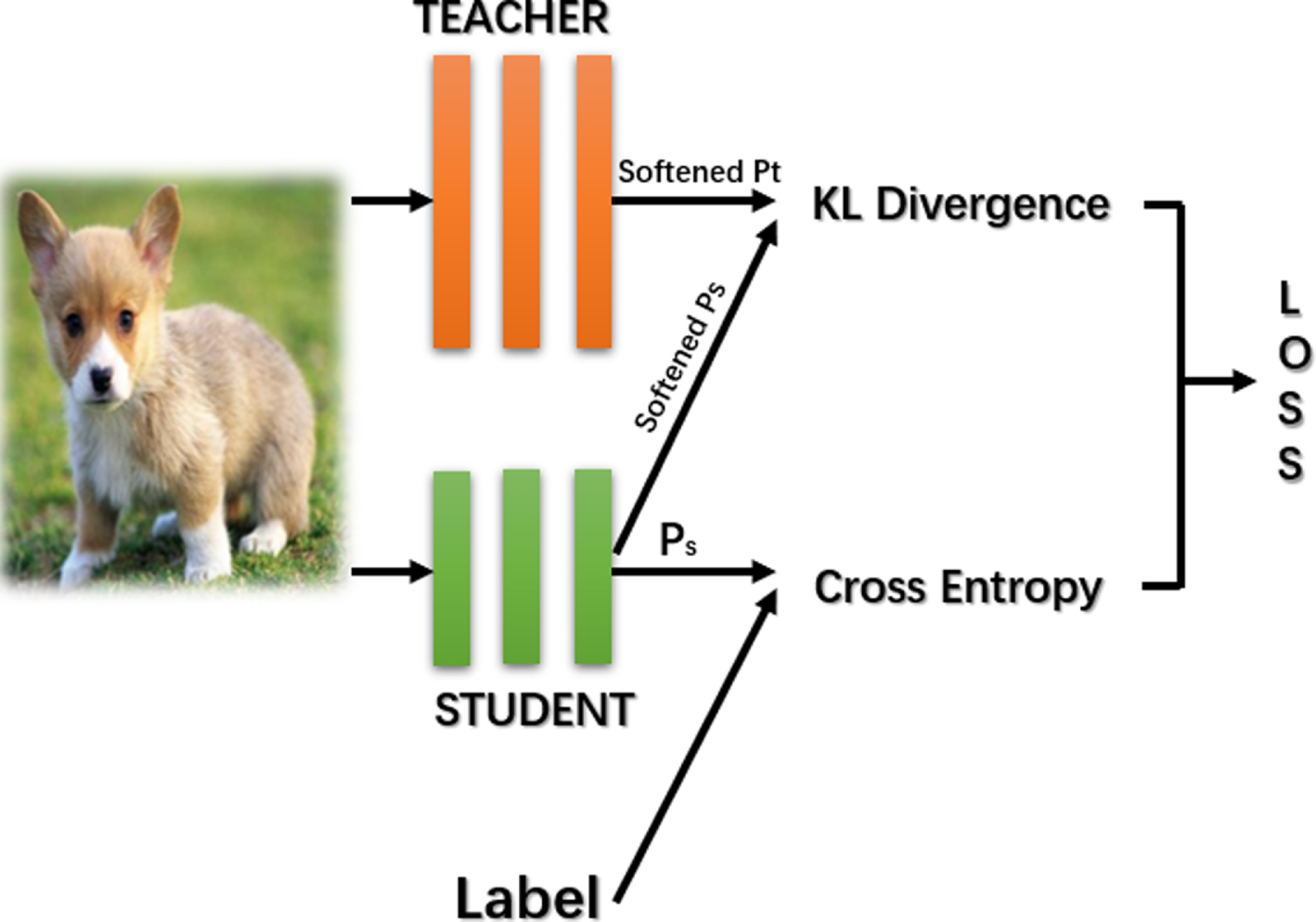
A demonstration of knowledge distillation.
As yet, softening the logits of both teacher and student has become the standard for KD, and is now widely adopted by many preceding arts. The soft logits generate final soft probabilities via the softmax function. Then, a form of sample features contained in soft probabilities could embrace more information about data structure learned by the teacher to some degree. FitNets (FN) [34], Attention Transfer (AT) [43], Similarity Preserving (SP) [38] are combined with KD to further enhance the performance of the student.
A student, in general, owns a lighter structure from its teacher, thus the learned student might not always behave like its teacher. Thus, it is natural to pose the following questions: 1) Does the process of softening logits/probabilities truly give full play to the current teacher-student paradigm? 2) Why cannot we do that, and how can this issue be addressed efficiently without extra hassle?
For this first question, we have launched several empirical studies to present the existence possibility of this issue. Before that, we illustrate whether the outputs of the student have similar data distribution or structure to that of the softened teacher. According to such intuition analyses, the incompatible case is possible to emerge. Such an issue is still fully unexplored in existing studies. In our work, we delve into the reason for this issue.
Then, we response the second question via several simple parameter decoupling strategies. In detail, we make the first change on the conventional softening process by removing the temperature parameter of student. In terms of this simple strategy, the learned student outputs softer probabilities, which are more similar to that of the softened teacher than before. Moreover, as mentioned in [42], the main hidden knowledge encapsulated in the similarity information between categories from teacher is sometimes regarded as "dark knowledge". To reveal more dark knowledge, we introduce a segmented softening function (SSF) into the softmax function to replace the traditional softening method for teacher. In this way, the more discriminative similarity information between classes can be revealed. Built off the two strategies above, we further integrate them into a unified formulation. More experiments conducted on various visual tasks show the universal applicability of this study. This implies that our work can be seamlessly coupled with current existing arts.
The rest of the paper is organized as follows. After illustrating related work (Sec. 2), we provide the background of knowledge distillation and the motivations of our proposed method (Sec. 3). Then, extensive experiments and analyses are explored (Sec. 4). At last, a conclusion is made (Sec. 5).
To the best of our knowledge, Bucilua; et al. [3] firstly explored how to use an ensemble of networks to train a single network. Furthermore, Ba and Caruana [1] aided shallow net to imitate deep net through penalizing the difference of logits between them. Inspired by [1], Hinton et al. [14] introduced the concept of knowledge distillation, which leveraging a cucumber teacher network to educate a lightweight student network by soft targets and not subject to software/hardware platforms. In this paper, this knowledge distillation framework is explored by us, which is briefly described in Section 3.1. More specifically, Phuong and Lampert [30] did a theoretical explanation and introduced three key points—data geometry, optimization bias and strong monotonicity for KD.
Recently, some approaches have been introduced to eliminate defects of KD itself. Cho and Hariharan [6] showed that small student is unable to mimic large teacher and they used an "Early-stopped" teacher to mitigate it. Mirzadeh et al. [25] bridged the gap between oversize teacher and undersize student via an intermediate size teacher assistant. Tan et al [36] defined an expressive teacher to educate the student. Wen et al. [39] amended the incorrect supervision and uncertain supervision of a teacher to improve KD.
However, the teacher cannot fulfil its function by only transferring soft targets. Therefore, numerous additive methods for KD have been proposed. Romero et al. [34] used intermediate-level hints from the teacher hidden layers to guide the student. Based on the boundary supporting sample (BBS), Heo et al. [13] aimed to transfer more accurate information about the decision boundary. In [21, 38], they consistently concentrated on transferring the instance relationship between classes from teacher to student. Afterwards, in [5, 40], contrastive learning was applied to transfer knowledge.
Besides, KD can be easily united with other model compression method for its flexibility. Polino et al. [31] and Mishra and Marr [26] combined quantization with KD to reduce the network weights and activations. Lee et al. [18] used singular value decomposition to enhance the accuracy of knowledge distillation. Lin et al. [19] pruned a transformable architecture via KD. However, only a little research discussed the combination of knowledge distillation and other model compression approaches.
Approach
Background
The key idea behind KD proposed by Hinton et al. [14] trained student not only via true labels but also the information lurked in the teacher network. We let Ft and Fs be the functions of the teacher and student networks, respectively. For an image x with true label y, the logits (the input of softmax) of teacher and student are αt = [αt0, αt1, …, αti] and αs = [αs0, αs1, …, αsi]. Then, the final probabilities of them are Pt = softmax (αt) and Ps = softmax (αs). Hinton et al. [14] used a temperature τ to produce a softer probability distillation over classes. So, knowledge distillation tries to match the soft probabilities (soft targets)
Besides, a cross-entropy loss H (Ps, y) is added to the modified soft targets. Then, the final loss function is a weighted average of two objective functions.
τ and λ are hyperparameters. τ ∈ {3, 4, 5} and λ = 0.9 are most recommended.
As mentioned above, forcing student to mimic the soft targets of teacher is aimed to help student reveal the dark knowledge that teacher has discovered above. However, we observe the probability distribution of student trained by KD is not similar to its softened teacher. To show this more visually, we first use t-SNE visualization [24] based on the following steps like [27]: (1) Choose three classes; (2) Find an orthonormal basis of the plane crossing the templates of these three classes; (3) Project the final probabilities of examples from these three classes onto this plane. The visualization shows in a 2-D to help us observe whether the student truly imitates the soft targets of the teacher or not.
Figure 2 presents the visualization results of final probabilities

t-SNE visualization of the probabilities on CIFAR-10 test set. The first column shows the soft targets of the teacher network. The second column and third column are the final probabilities
We find that adding the temperature τ for
More straightly, if the logits αt and αs are zero-meaned for each transfer case, so that
∑
i
αti = ∑
i
αsi = 0. So, the gradient of Loss-kd
Then, Equation 3 and Equation 4 can be simplified as:
As
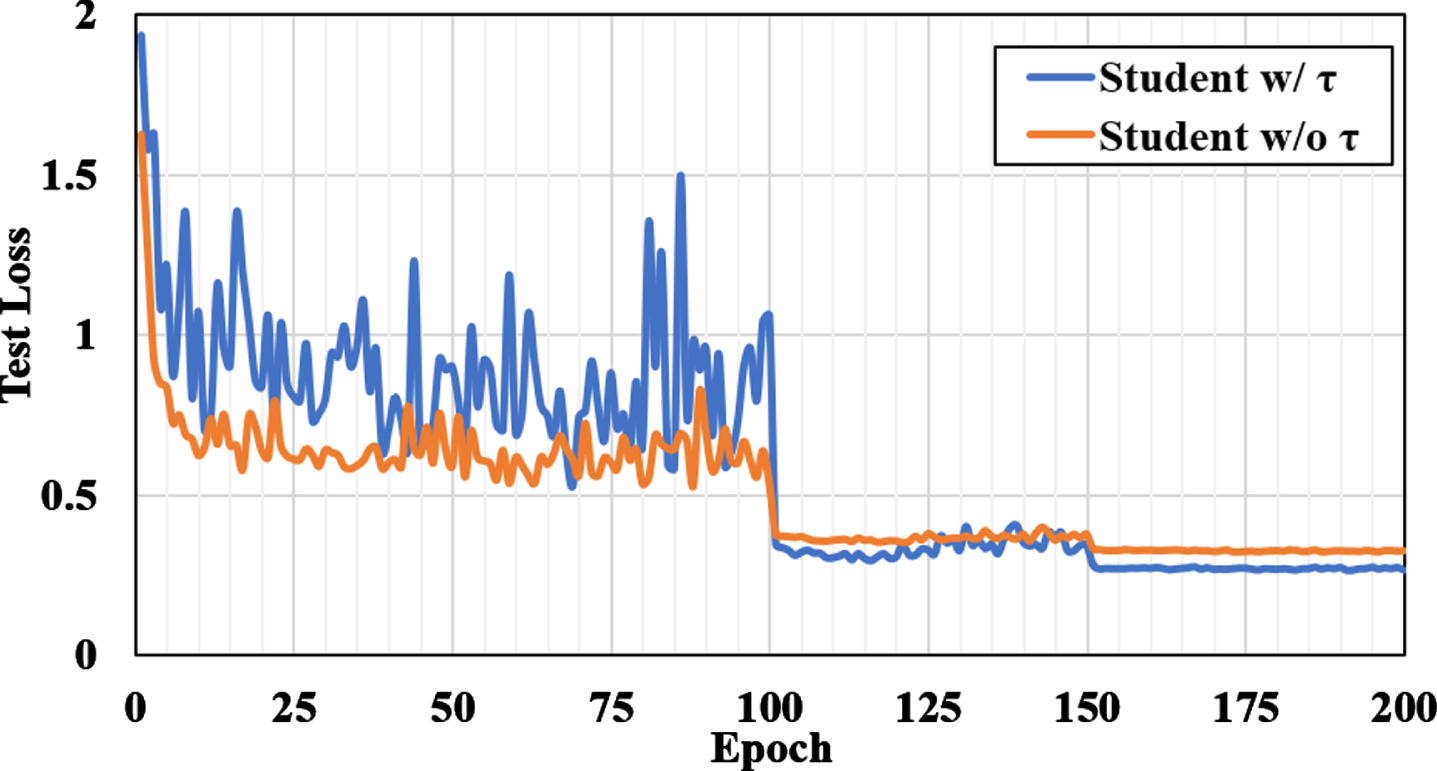
Test loss comparison between student trained by
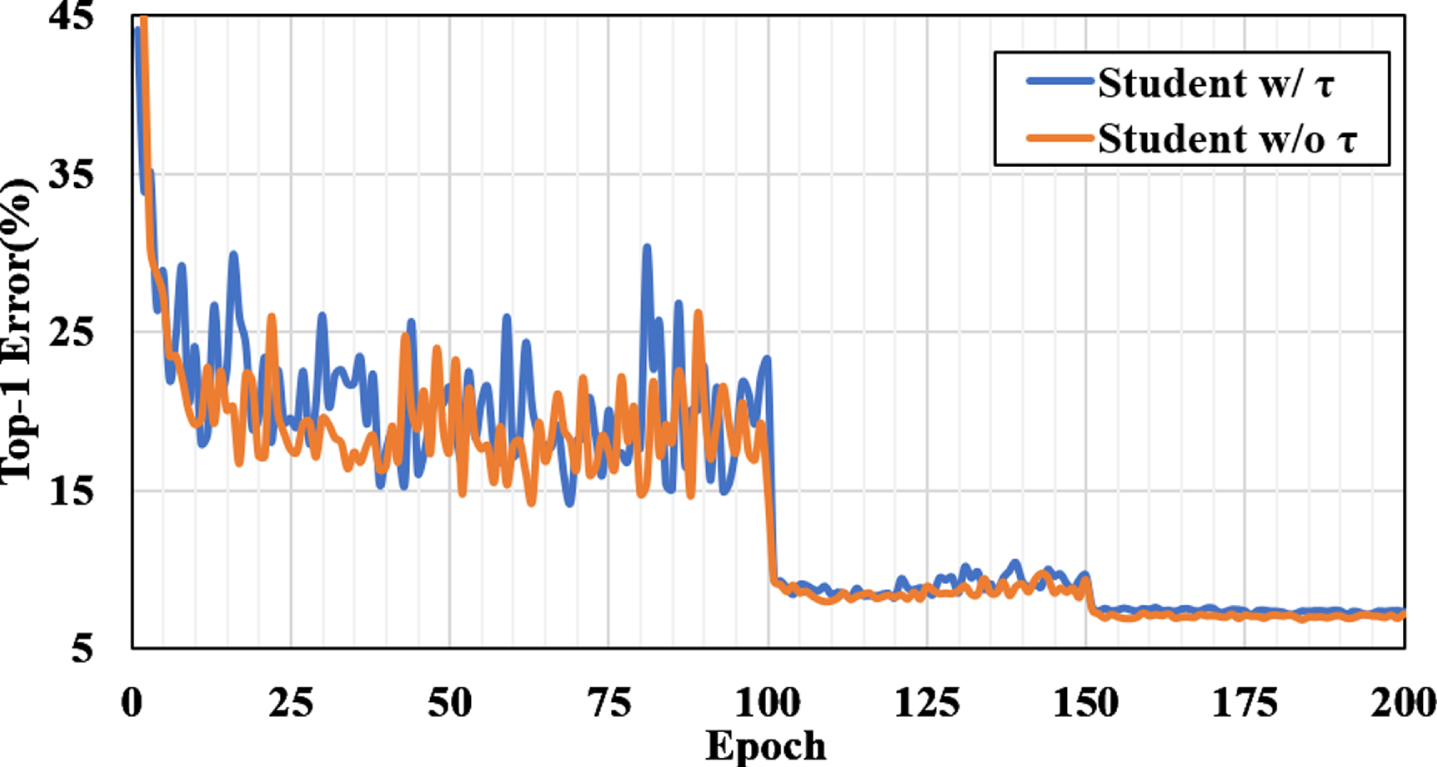
Top-1 error rate (%) comparison between student trained by
Top-1 error rate (%) comparison between student trained by
A good teacher is indispensable to a studious student. When we distill a student network, the τ for
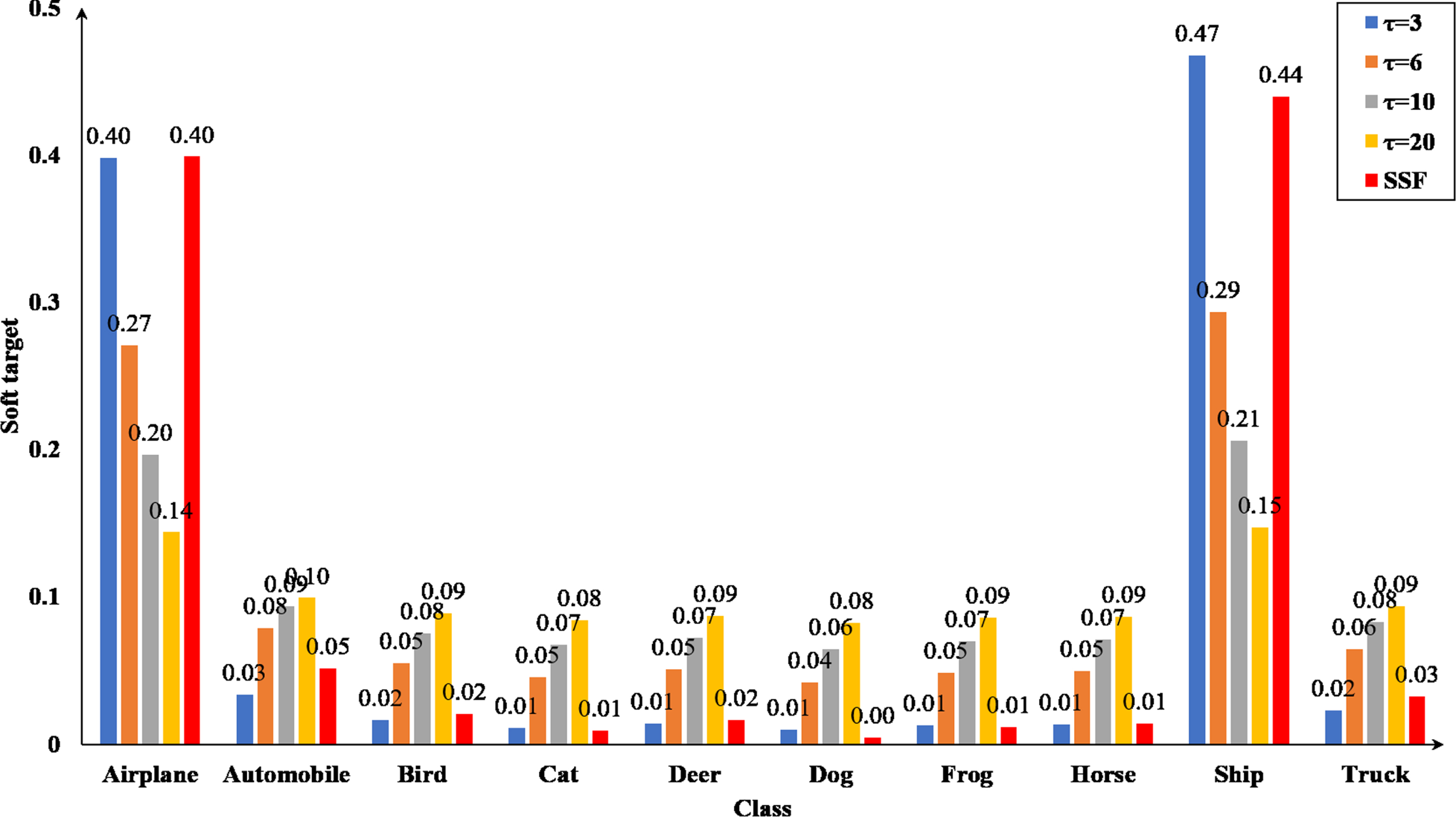
The soft probabilities of the teacher softened by τ ∈ {3, 6, 10, 20} and SSF on CIFAR-10 training set.
can just depict the relationship between the primary probability category "
Why do these happen? We observe that just leveraging single τ to soften αt may be too unadorned to extract the knowledge. To this end, we propose a new softening strategy for teacher’s logits αt. As shown in Figure 6, we divide αt = [αt0, αt1, …, αti] into three groups according to their numerical values and called these groups as the first logits, the middle logits and the last logits, respectively. We assign a larger temperature τ for the first logits and the last logits, a smaller temperature τ′ = τ - 1 for the middle logits. However, if we directly soften the logits with τ and τ′, the primary probability may be less than the secondary probability. To this end, a segmented softening function (SSF) is proposed as
The illustration of the segmented softening function of teacher.
where k0 and k1 are the anchor points to divide the groups, which are manually selected,
In the remainder of this section, we demonstrate the advantages of SSF and TCF in more detail. Above all, as shown in Figure 5, it can be observed that compared with τ = 3, the soft probabilities of "
Top-1 error rate (%) comparison between student trained by KD and TCF
According to the SCF and TCF, we further design the third modified function to form a more efficient teacher-student paradigm, which is called Teacher-Student Compatibility Function (TSCF):
Image classification on CIFAR-100
CIFAR-100 [16] contains 50K training images and 10K test images with 100 classes, both of which are at resolution 32 × 32. To better illustrate the superiority of proposed functions, we do different experimental setups. Table 3 presents the setup of each experiment such as the teacher and student architectures, model size and compression rate. Four compression styles are chosen. Because the width or depth can be flexibly modified, we choose the variants of WideResNet and ResNet [11] as teachers or students trained on CIFAR-100 (SGD with Nesterov momentum; weight decay 5e-4; batch size of 128; 200 epochs; initial learning rate of 0.1 which is divided by 10 at epoch 100s and epochs 150; pad, random flip and random crop used for data augmentation). For KD, the hyperparameters λ = 0.9 and τ = 4. For the proposed three modified functions, λ = 0.9, τ = 4 and τ′ = 3. The top-1 error rate is adopted as the performance metric.
Experimental settings with various compression styles on CIFAR-100 dataset
Experimental settings with various compression styles on CIFAR-100 dataset
The results of different experiments are shown in Table 4. From the average value of each method, the SCF, TCF and TSCF reduce the original KD error rate by 0.36%, 0.53%and 0.93%, respectively. More exactly, from the results of different experimental settings, the error of the three proposed functions are all less than those of the original KD. Especially, the accuracies of SCF, TCF and TSCF are 0.50%, 0.51%
Classification performance of various knowledge distillation methods on CIFAR-100. Top-1 error rate (%) is applied as the metric
and 0.85%higher than the teacher network in setup (a). Besides, when the teacher is too gigantic for a student like setup (g), (h) and (i), the KD cannot help the student imitate its teacher and the results are worse 0.28%, 0.63%and 0.79%than the baseline of the student. This is a typical shortcoming of KD, which has been studied in [6, 25]. Yet, the proposed TCF and TSCF are still useful to train student.
Tiny ImageNet [17] contains 200 image classes with 500 training examples, 50 validation examples and 50 test examples per class. The images of Tiny ImageNet are down-sampled to 64 × 64 for the original ImageNet [7]. However, Tiny ImageNet is large enough to be regarded as a challenging and realistic problem. Table 5 presents the different experimental settings. For the teacher and student architectures, variants of the state-of-the-art mobile architecture ShuffleNetV2 [23] are selected by us. All students are trained by SGD Nesterov momentum, weight decay 5e-4, 200 epochs with an initial learning rate of 0.01 which is divided by 10 at epochs 100, epochs 150. The data augmentation is random rotation and random flip. Three methods are added to KD and TSCF with hyperparameters β referenced by [37]. Then, the total hyperparameters are KD: {λ = 0.9, τ = 4}; the proposed three modified functions: {λ = 0.9, τ = 4, τ′ = 3}; FN [34]: {β = 100}; AT [43]: {β = 1000}; PKT [28]: {β = 30000}; SP [28]: {β = 3000}; CC [38]: {β = 0.02}. The top-1 error rate is adopted as the performance metric.
Experimental settings with the variants of ShuffleNetV2 architectures on Tiny ImageNet dataset
Experimental settings with the variants of ShuffleNetV2 architectures on Tiny ImageNet dataset
Table 6 presents the results of the experiments. Surprisingly, the KD and three proposed functions are all better than the teacher in setup (a). Compared with the vanilla KD, the average error rates of the three proposed functions reduce by 1.27%, 1.02%and 2.10%, respectively. The TSCF shows the best results among the three functions. Compared with FN, AT, PKT, SP and CC, the average error rates of TSCF are reduced by 2.03%, 1.95%, 2.12%, 1.96%and 1.98%, respectively. Moreover, it can be observed in setup (b) when the gap between teacher and student is huge, the KD loses its efficacy to train the student. Yet, our proposed functions still work and alleviate the shortcoming. Particularly, compared with KD, setup (b) improves much better via TSCF than other settings. Besides, the supplementary of other methods further enhances the results of the experiments. For setup (a) and (c), TSCF combined with AT has the best results. For setup (b), TSCF combined with SP has the best result.
Classification performance of various knowledge distillation methods on Tiny ImageNet. Top-1 error rate (%) is applied as the metric
Besides, a deep network is able to automatically learn semantically similar classes for each image individually [41]. So, we compare the probabilities assigned to the top-5 highest ranked classes outputted by the student on CIFAR-100 test set in Figure 7. The methods were added one by one to measure their effects. The setup (a) and setup (g) are chosen. It can be observed that compared with KD, the primary probabilities and secondary probabilities of the student trained by SCF and TSCF are more correlated than those of the student trained by KD, which means the student learns more semantically similar classes for each image from its teacher. Moreover, compared with SCF, TSCF (SCF+TCF) is further strengthen the correlation between the primary probabilities and secondary probabilities of the student.

(a) The top-5 highest ranked probabilities of the student for setup (a); (b) The top-5 highest ranked probabilities of the student for setup (g).
Person re-identification (ReID) is an important technique for the automatic search of a person’s in a surveillance video. Market-1501 [45] and DukeMTMC-reID [33] are chosen as the datasets to evaluate the performance of our proposed functions. The Market-1501 dataset collected from six cameras contains 197,32 images for testing and 12,936 images for training. The training set and testing set have 751 identities and 750 identities. The DukeMTMC-reID dataset includes eight 85-minute high-resolution videos from eight different cameras, which is divided into 16,522 training images for 702 identities and 19,889 test images for 702 identities. ResNet50 (26.99M) pre-trained by ImageNet and ResNet18 (12.34M) are the teacher and student. The student with a batch size of 64 is trained by SGD Nesterov momentum. Weight decay is 5e-4. The initial learning rate is 0.01 and divided by 10 at epochs 40, a totally of 60 epochs. the total hyperparameters are KD: {λ = 0.9, τ = 4}; TSCF: {λ = 0.9, τ = 4, τ′ = 3}; FN: {β = 100}; AT: {β = 1000}; PKT: {β = 30000}; SP: {β = 3000}; CC: {β = 0.02}. Rank-1, Rank-5 and mean accuracy precision (mAP) are applied as The performance metric.
Table 7 and Table 8 are results of the student pre-trained without and with ImageNet, respectively. It can be observed that the TSCF in the two tables are greater than the original KD, especially for the student pre-trained without ImageNet. For example, for DukeMTMC-reID in Table 7, the Rank-1, Rank-5 and mAP for the student trained by TSCF are 4.89%, 6.29%, 5.07 higher than the student trained by KD. For Market-1501 in Table 8, the Rank-1, Rank-5 and mAP for the student trained by TSCF are 5.52%, 4.10%, 5.13 higher than the student trained by KD. Besides, we also combine other methods with KD and TSCF. The performance is further enhanced. TSCF integrated with FN are significantly superior to other methods. For exampl, in Table 7, the Rank-1, Rank-5 and mAP are 81.41%, 91.59%and 60.65 on Market-1501. Besides, in Table 8, the Rank-1, Rank-5 and mAP are 77.65%, 88.15%and 61.26 on DukeMTMC-reID.
Person re-identification performance of various knowledge distillation methods on Market-1501 and DukeMTMC-reID when the student is not pre-trained by ImageNet. Rank-1 (%), Rank-5 (%) and mAP are applied as performance metric
Person re-identification performance of various knowledge distillation methods on Market-1501 and DukeMTMC-reID when the student is
Person re-identification performance of various knowledge distillation methods on Market-1501 and DukeMTMC-reID when the student is
Semantic segmentation aims to assign a categorical label to every pixel in an image, which plays an important role in image understanding and self-driving systems. In this section, KD and proposed functions are applied for the Semantic segmentation. DeeplabV3+ [4] is selected as the basic model to verify the performance. ResNet101 pre-trained by ImageNet is the backbone of the teacher model. ResNet50 and MobileNetV2 [35] pre-trained by ImageNet are the backbone of the student model. PASCAL VOC 2012 Aug [4] is adopted as the dataset, which is augmented from the PASCAL VOC 2012 [8] by the extra annotations [10], resulting in 10,582 training images. The student is trained by SGD Nesterov momentum with a batch size of 16 and 30K iterations. The initial learning rate is 0.01 and updates by the "poly" policy. All images are cropped to 513 × 513, which is larger than other tasks and more difficult to conduct. The loss function is the sum of Loss-distill multiply by ε = 0.1 and Loss-semantic segmentation. The total hyperparameters are KD: {λ = 1, τ = 4}; TSCF: {λ = 1, τ = 4, τ′ = 3}. The performance is measured in terms of pixel intersection-over-union averaged with 21 classes (mIOU).
The results are presented in Table 9. Compared with the baseline, the proposed TSCF can further increase the mIOU by 1.13%and 0.48%for ResNet50 and MobileNetV2, respectively. The results of TSCF are greater than those of the KD. Because of the huge gap between teacher and student, KD is invalid to transfer knowledge from teacher to student in MobileNetV2. Yet, TSCF is effective. Moreover, we also visualize the effect of different methods for MobileNetV2 in Figure 8. It can be
Semantic segmentation performance of various knowledge distillation methods on PASCLA VOC 2012 Aug. mIOU is applied as the metric
Semantic segmentation performance of various knowledge distillation methods on PASCLA VOC 2012 Aug. mIOU is applied as the metric
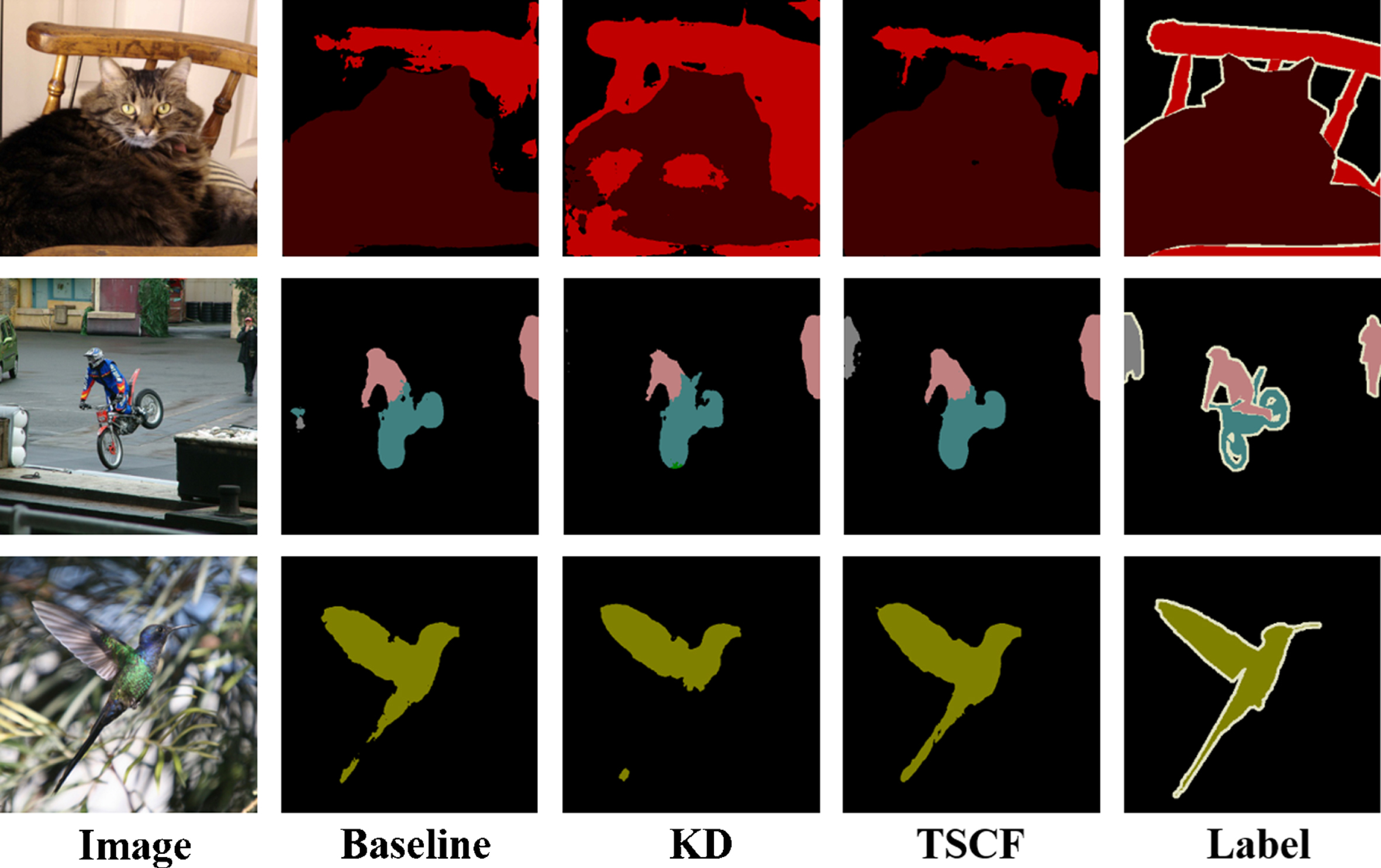
Qualitative effect of employing different methods for student MobileNetV2.
observe that the results of TSCF are more similar with the "
λ and τ are two critical hyperparameters for KD and TSCF. We have mainly set λ = 0.9 and τ = 4 in the above experiments. In this section, we vary λ and τ to analyze whether TSCF is sensitive to these two parameters. The experiments are conducted on CIFAR-100 dataset. WideResNet28-2 and WideResNet40-2 are selected as the teacher networks. WideResNet16-1 is selected as the student network.
Figure 9 and Figure 10 shows the error rates of various λ when τ = 4. It can be observed that the error rates of TSCF are consistently less than that of KD. Whether the value of λ is large (λ = 1.0) or small (λ = 0.1), the results of KD and TSCF get worse
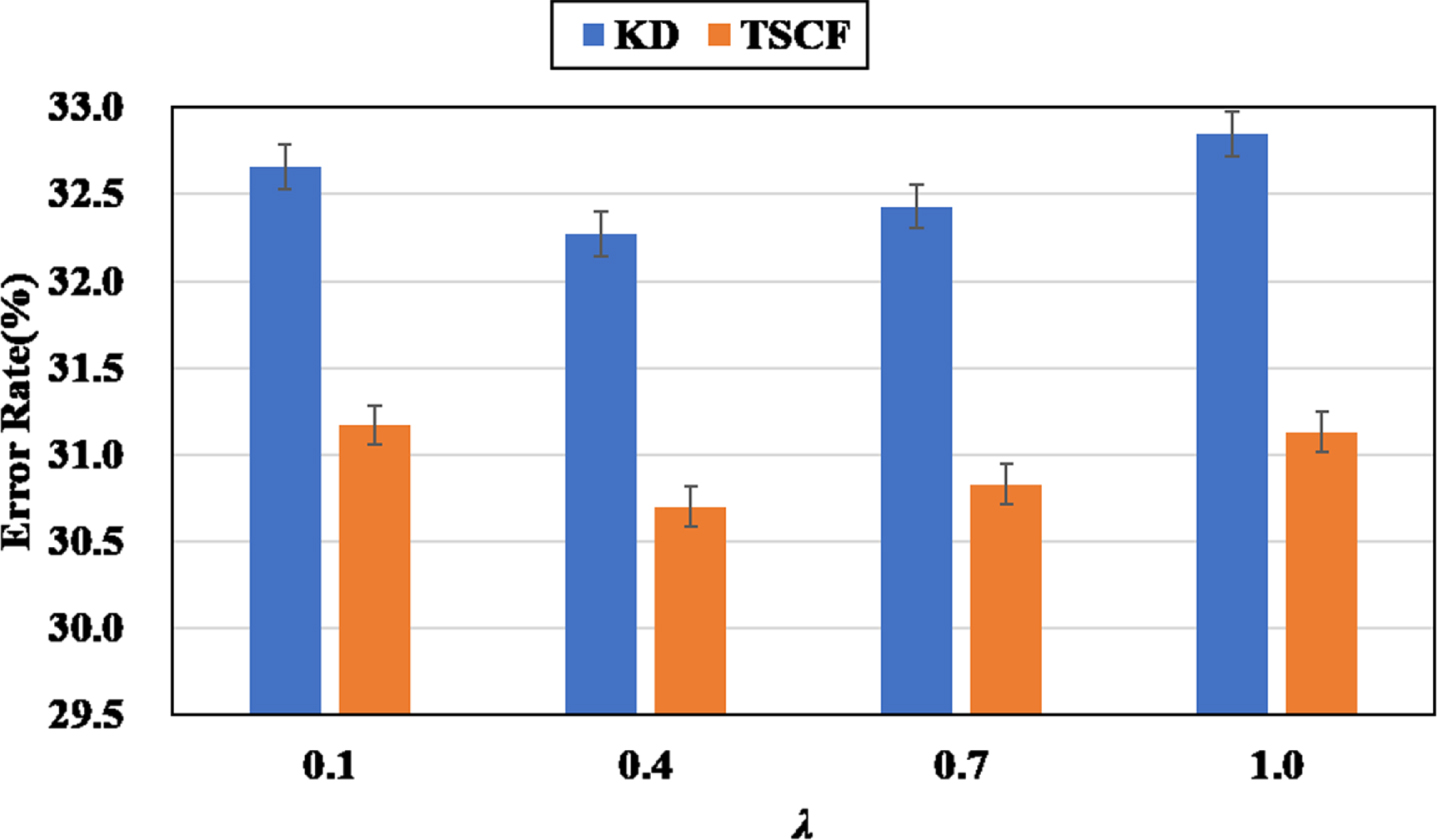
Top-1 error rate (%) of WideResNet16-1 supervised by WideResNet28-2 on CIFAR-100 when λ ∈ {0.1, 0.4, 0.7, 1.0} and τ = 4.
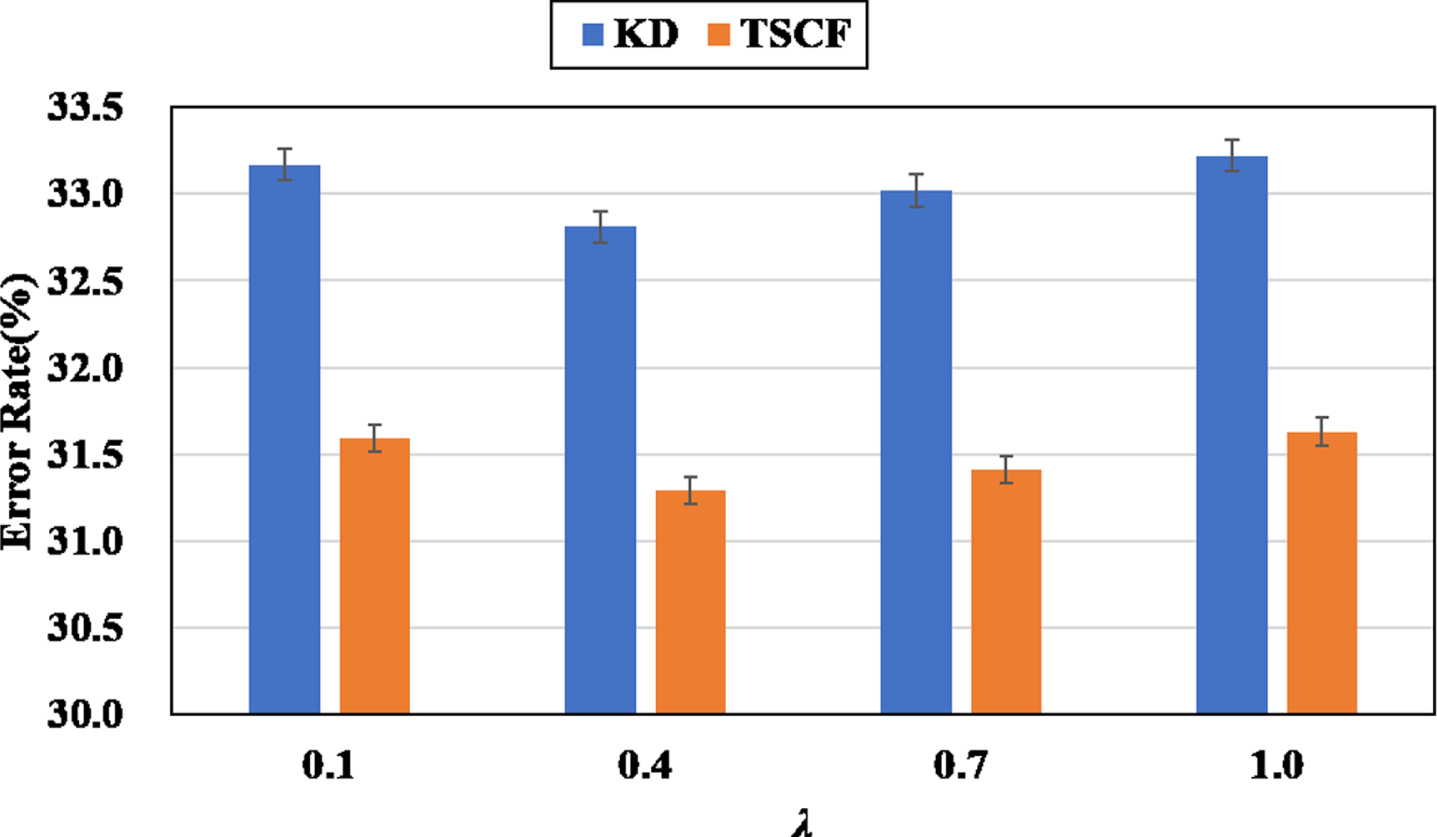
Top-1 error rate (%) of WideResNet16-1 supervised by WideResNet40-2 on CIFAR-100 when λ ∈ {0.1, 0.4, 0.7, 1.0} and τ = 4.
significantly. When λ = 1.0,
Figure 11 and Figure 12 shows the error rates of various τ when λ = 0.9. We observe that when τ = 3, the improvement of TSCP is better than the other settings. Because τ = 3 can make TSCP generate more discriminative similarity information. When τ is large,
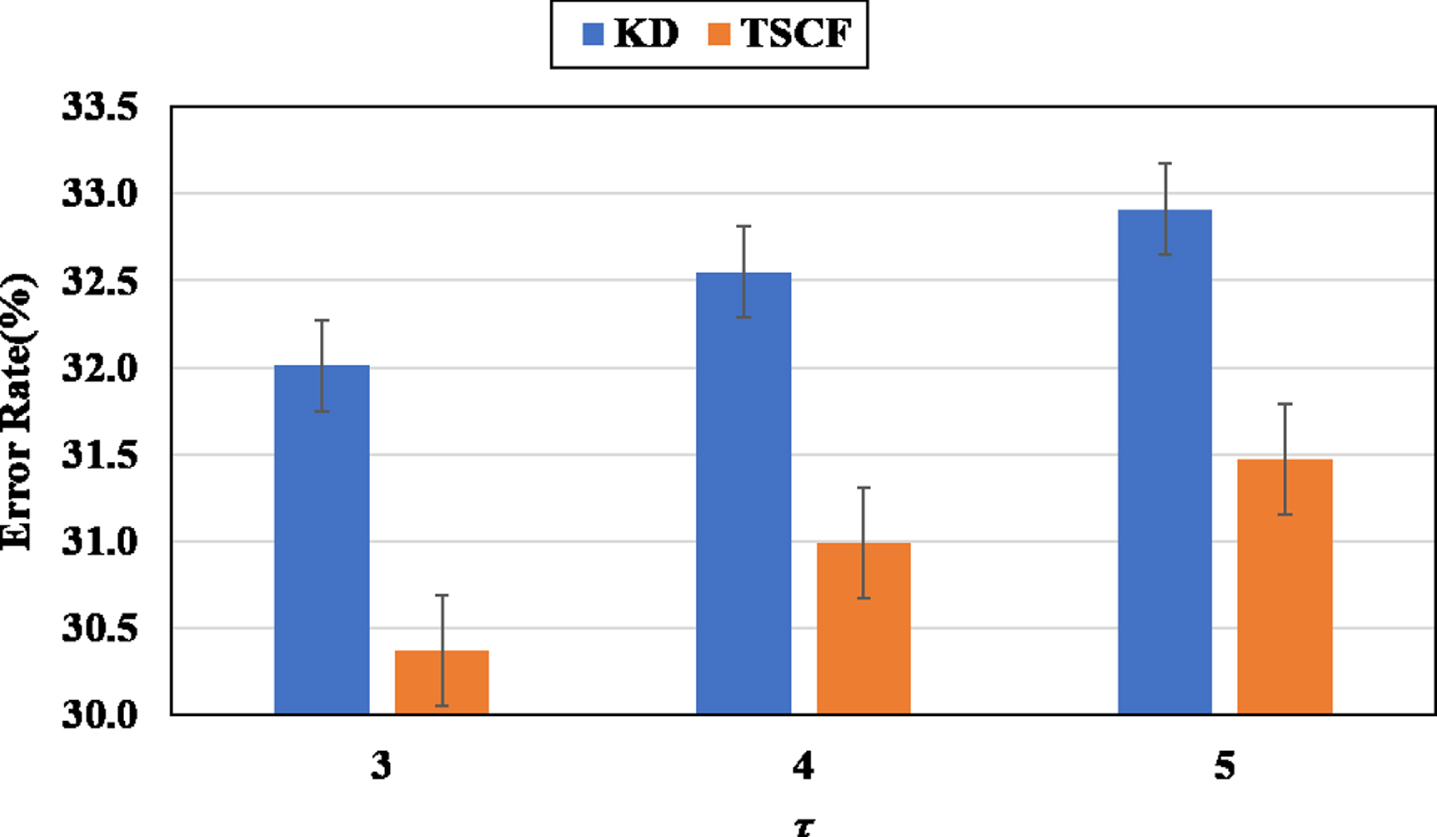
Top-1 error rate (%) of WideResNet16-1 supervised by WideResNet28-2 on CIFAR-100 when λ = 0.9 and τ ∈ {3, 4, 5}.
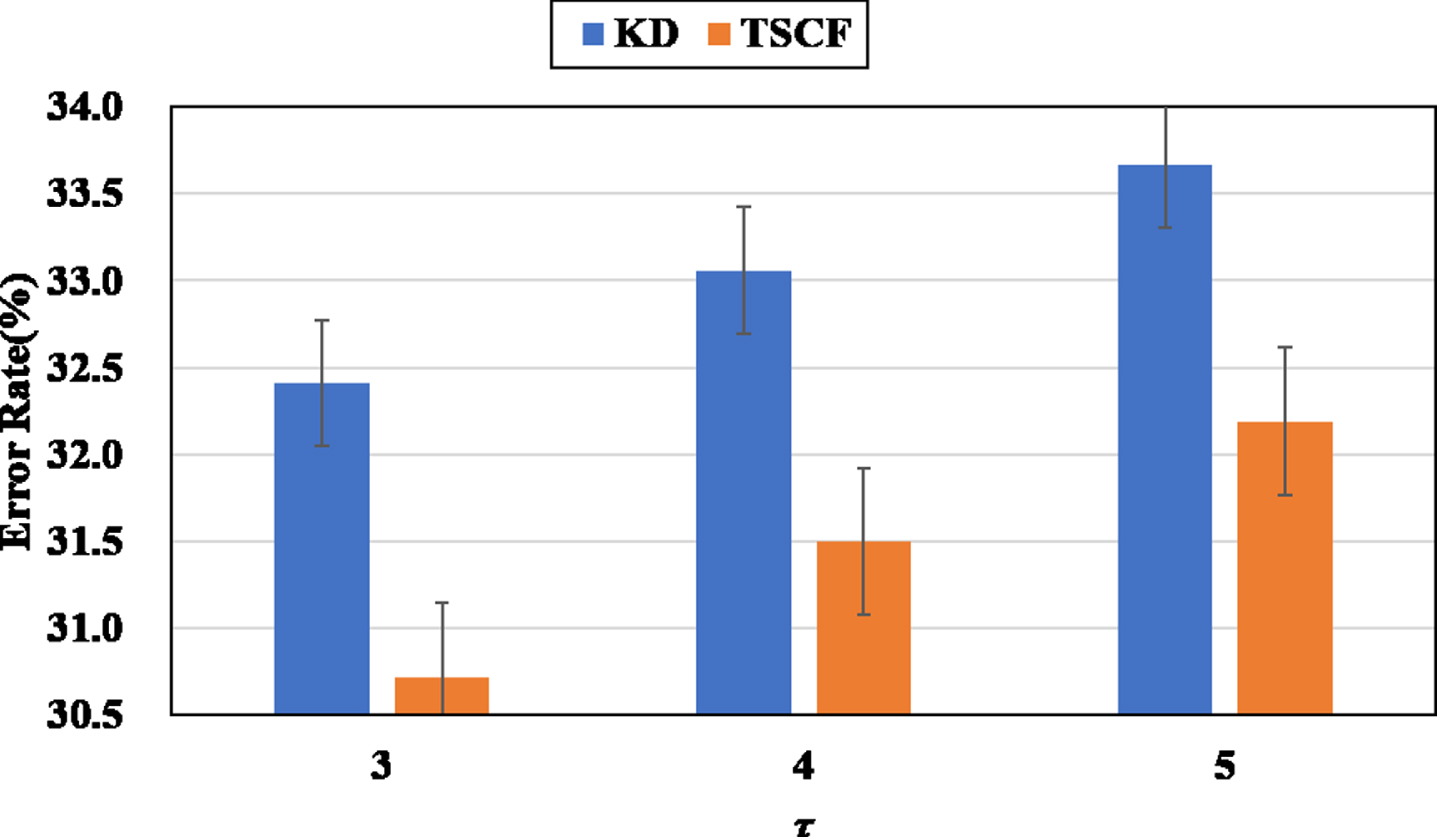
Top-1 error rate (%) of WideResNet16-1 supervised by WideResNet40-2 on CIFAR-100 when λ = 0.9 and τ ∈ {3, 4, 5}.
In this paper, we rethink knowledge distillation from its essence. In general, the teacher and the student are in different size or architecture from each other. So, softening their logits, in the same way, cannot make full use of the knowledge distillation. To find a more effective teacher-student paradigm, we propose three simple but effective strategies for knowledge distillation. In detail, we make the first change on the conventional softening process by removing the temperature parameter of student. To reveal more dark knowledge, we introduce a segmented softening function (SSF) into the softmax function to replace the traditional softening method for teacher. Built off the two strategies above, we further integrate them into a unified formulation. Extensive experiments have been conducted by us. In particular for image classification, the proposed method shows its performance superior to the vanilla knowledge distillation and even better than the teacher network. Moreover, compared with the state-of-art approaches, our method is still advanced. When the gap between teacher and student is huge, the vanilla knowledge distillation loses its efficacy to train the student. Yet, our proposed functions can efficiently alleviate this shortcoming. As for person re-identification, the proposed method can well cooperate with other methods, especially with FitNets. We also carry out experiments on semantic segmentation. The results of the vanilla knowledge distillation are further enhanced.
Acknowledgments
This work was supported by the National Key Research and Development Program: 2017YFB0202104 and the National Key Research and Development Program of China: 2018YFB0204301.
Conflict of interest
We declare that we have no financial and personal relationships with other people or organizations that can inappropriately influence our work, there is no professional or other personal interest of any nature or kind in any product, service and/or company that could be construed as influencing the position presented in, or the review of, the manuscript entitled.