
Abstract
Traditional visual SLAM algorithms run robustly under the assumption of a static environment, but always fail in dynamic scenes, since moving objects will impair camera pose tracking. Given this, this paper presents an efficient semantic dynamic SLAM (ESD-SLAM), which is suitable for dynamic scenarios. Based on the ORB-SLAM2 framework, the ESD-SLAM we proposed employs lightweight semantic segmentation network FcHarDNet to extract semantic information, and uses the region growing algorithm to optimize the semantic segmentation boundary. Then dynamic objects are removed by combining semantic information with multi-view geometry, and it further improves the localization accuracy. Combining semantic information and depth information, a dense point cloud map of static scene is constructed to serve the planning task of mobile robot. We conduct the experiments on the public TUM RGB-D dataset and in the real-world environment. Experimental results show that the proposed algorithm can improve the performance of the ORB-SLAM2 system in dynamic scenes, and significantly improve the real-time performance compared with other same type dynamic SLAM algorithms.
Introduction
Simultaneous localization and mapping (SLAM) [1] is a technique that applies sensors to estimate the current pose and build a 3-D map of the environment without any prior information about the environment. With the development of computer vision, deep learning technology, and the hardware computing ability, visual SLAM [2] has been widely used in autonomous driving, mobile robot, and unmanned autonomous vehicles (UAV). Some advanced SLAM algorithms have achieved satisfactory results, such as ORB-SLAM2 [3], ORB-SLAM3 [4], VINS-Mono [5], LSD-SLAM [6].
However, these algorithms are designed for static scenes. Dynamic objects are very common in real life. These dynamic objects cause many wrong data associations, destroy the constraint relationship of pose between frames, and finally lead to the pose estimation error of the whole system [10, 11]. The standard visual slam eliminates the influence of dynamic objects by random sampling consistency (RANSAC) [7]. However, they fail to accommodate the dynamic scenes where dynamic objects occupy a large area in the image.
This paper focuses on dynamic object feature points removal in dynamic scenes and the static dense point cloud map construction in the visual SLAM system. Major contributions of this paper are: This paper presents an efficient semantic dynamic SLAM (ESD-SLAM), which bases on ORB-SLAM2 with prior knowledge of semantic segmentation and multi-view geometry. It works satisfactorily in dynamic environment and significantly improves the localization accuracy as well as stability in high dynamic scenes. The system adopts lightweight semantic segmentation network FcHarDNet [23] for real-time semantic segmentation. Experimental results show that the system achieves a balance between calculation efficiency and localization accuracy in dynamic environment. Combining semantic segmentation information and depth information, masked depth image is constructed to remove the interference of dynamic objects and build dense point clouds in static scenes.
Related work
Currently, most of the visual SLAM system is based on the assumption of static scenes and has poor robustness in dynamic scenes [8, 9]. Dynamic objects in the scenes could cause mismatch of features, which affects the localization accuracy and the success rate of relocation. For this problem, there are mainly two solutions. Pure geometric-based [12–16] and semantic-based [17–20] methods. These geometric-based approaches rely on geometric restrictions, such as the equation of epipolar lines and the principle of triangulation, to segment static and dynamic features. They are based on the fact that dynamic features will violate standard constraints defined in the multi-view geometry for static scene. These geometric-based approaches cannot remove all dynamic objects, e.g., people who remains stationary. Features on such objects are unreliable and need to be removed from tracking and mapping.
These semantic-based methods first detect or segment objects and then remove outliers from tracking. DS-SLAM [17] used SegNet [21] network to capture semantic information and then combined it with motion consistency checking to filter dynamic features. This method improved the localization accuracy compared with ORB-SLAM2, but the deviation of the fundamental matrix calculated in the polar constraint was easy to be affected by external points, which influence the system accuracy. DynaSLAM [18], proposed by Bescos Berta was a dynamic robust SLAM algorithm which employed the semantic segmentation results of Mask R-CNN [22] and multi-view geometry to detect moving objects, and recovered the background occluded by dynamic objects. This algorithm improved the accuracy of pose estimation but cannot realize real-time operation. Jonathan proposed DOTMask [19], a highly modular pipeline that tracked and masked dynamic objects through semantic segmentation to improve both localization and mapping in visual SLAM, however, its localization accuracy was lower than DynaSLAM. SaD-SLAM Xun proposed [20] which used semantic information obtained by Mask R-CNN and depth information to discover dynamic feature points. At the same time, static feature points of moving target were detected and used to finetune the camera attitude estimation, which made the algorithm robust and accurate. However, the system operated offline semantic segmentation and could meet the requirements of real-time operation.
Inspired by these works above, the paper proposes an efficient and reliable visual SLAM method for filtering dynamic feature points from real scenes. Experimental results show that our proposed can significantly improve the localization accuracy and real-time performance in dynamic environment.
System description
Framework of ESD-SLAM
Our proposed ESD-SLAM system is built based on RGB-D model of ORB-SLAM2 by adding semantic segmentation thread to the original threads of tracking, local mapping, and loop closing.
The image processing flow chart of our proposed ESD-SLAM is shown in Fig. 1. The RGB image taken by the RGB-D camera is fed into both the tracking thread and the semantic segmentation thread. In the thread of semantic segmentation, FcHarDNet is used to segment RGB image at the pixel level to obtain the semantic label of each pixel. According to semantic label, all objects can be divided into three categories: static objects, dynamic objects, and potentially dynamic objects. Among them, the potentially dynamic objects are those which usually being static but could become dynamic under the influence of other objects (such as chairs and people). Then, the region growth algorithm is used to optimize the boundary of semantic segmentation results, and the optimized results are input into the tracking thread, where the feature points of all three categories are extracted undifferentiated. Potential dynamic feature points can be extracted based on semantic information. Dynamic feature points are removed by using semantic information and multi-view geometry, static feature points are retained to participate in pose estimation.
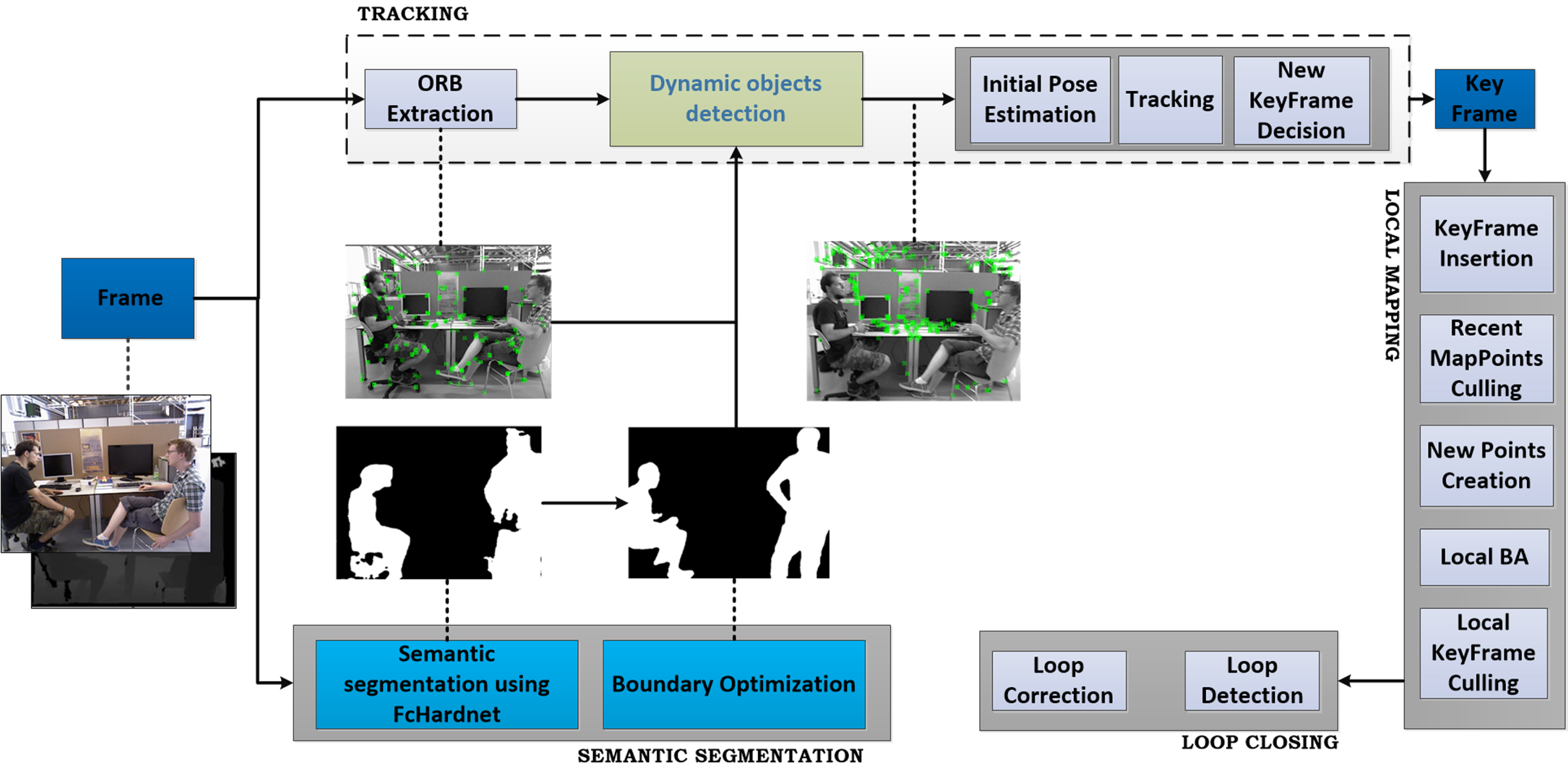
Architecture of ESD-SLAM.
To improve the efficiency of dynamic SLAM, the front-end semantic segmentation network needs to balance efficiency and accuracy. Instead of the computation-intensive Mask R-CNN used in DynaSLAM, Our ESD-SLAM system adopts FcHarDNet to get semantic segmentation results.
FcHarDNet is based on Densely Connected Network [20] and uses a sparse connection, resulting in a set of layers called harmonics dense blocks (HDB). In this block, layers with an index divided by a larger power of two have more weight in the model, which at its turn they are amplified by increasing their number of channels. This last amplification is done to balance the input/output channel ratio and avoid low MoC [23]. After each HDB, there is a conv1x1 layer as the transition layer. The block achieves back-propagation by directly passing the gradient from the output to all previous layers. FcHarDNet speeds up computation by reducing shortcuts between layers in the DenseNet architecture. FcHarDNet changes the weights of layers of DenseNet and extracts more features from more layers connected by shortcuts to maintain the model’s accuracy.
We follow the architecture proposed by the original author, and the model used in this paper is called FC-HarDNet70.As the name describes, the model contains 70 convolutional layers spread amongst 10 HDBs.
The network is based on a Pytorch implementation, trained with the PASCAL VOC 2012 dataset [26]. Objects can be divided into 21 categories, including backgrounds.
Semantic segmentation boundary optimi-zation based on region growth algorithm
To improve segmentation precision on boundaries, we use the region growth algorithm, which combines the prior information of semantic segmentation, to obtain the actual edge of dynamic objects in-depth images.
The critical problem of the region growth algorithm lies in the selection of growth seed and the determination of growth criteria. At first, in order to determine the growing seed points, we set the pixel points of the same mask as the set:
where n is the number of mask classes. In the indoor environment, only human is considered as dynamic object, so only the growing seed points in the human mask area need to be calculated. The position of the growing seed point Pt is calculated as (3), where
When the stack space for storing seed points is not empty, the seed pixel grows with a certain criterion. The calculation of the depth tolerance Th in the growth rule show in (4), where depthfactor is the scale factor of the depth map.
Algorithm 1 shows the specific steps of the algorithm for the region growth algorithm. As shown in Fig. 3, the optimized boundary contour is more refined than the original one.
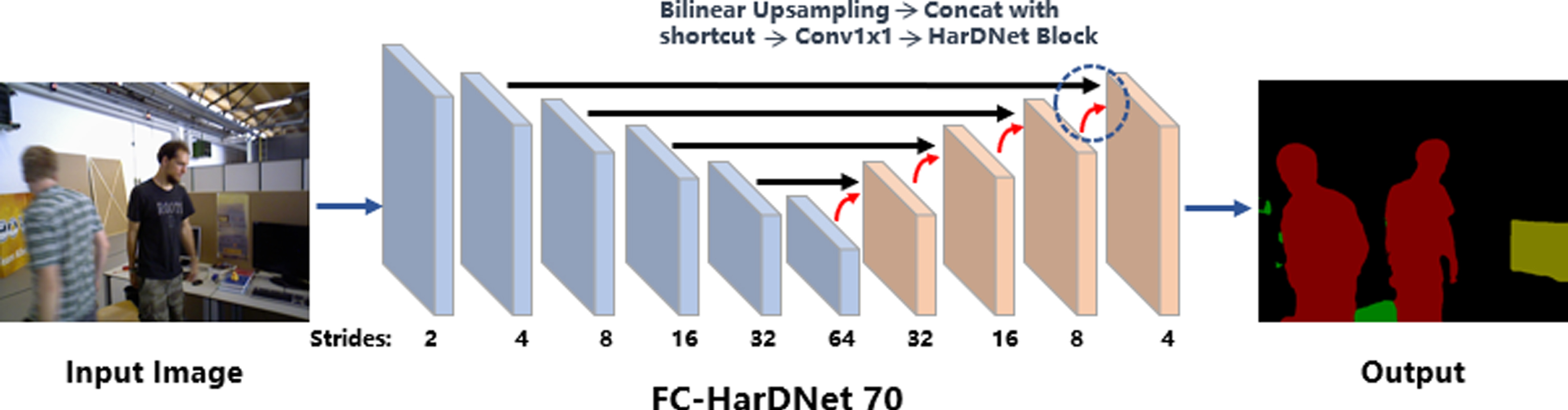
FC-HarDNet70 network structure.
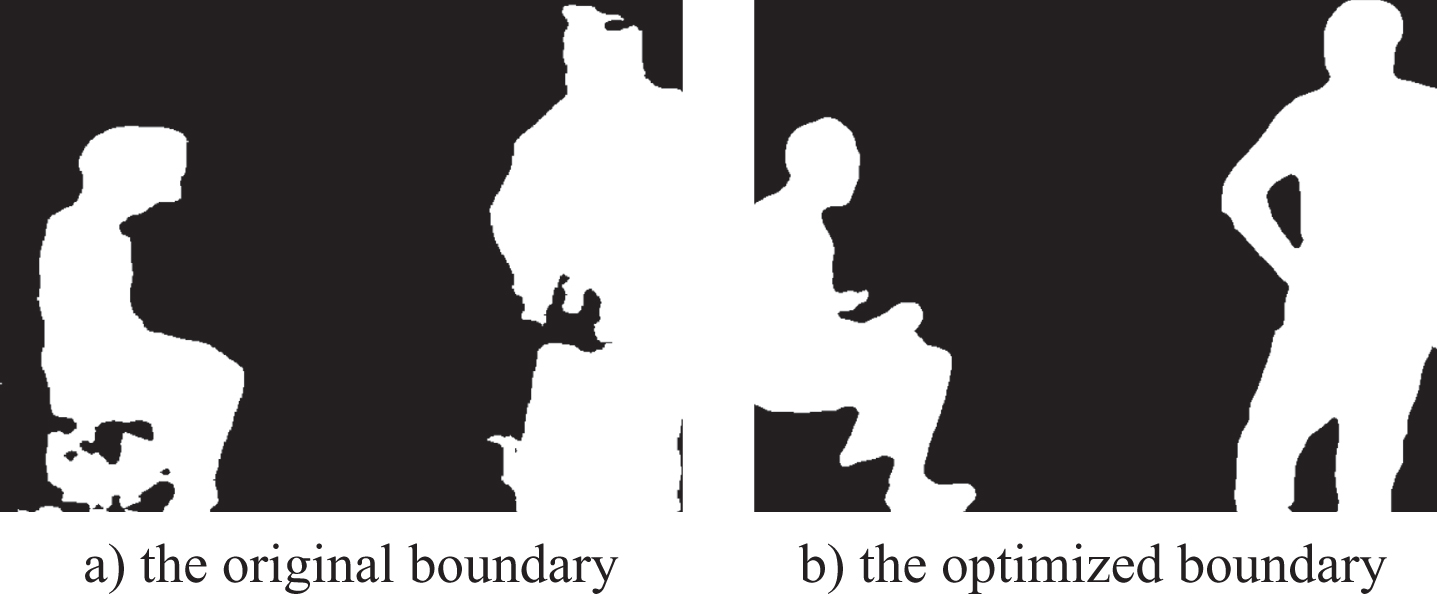
Comparison of boundary optimization.
Since the semantic segmentation only eliminate the dynamic objects, we introduce the multi-view geometry method to detect the potential dynamic objects.
The five key frames which have the highest coincidence with the current frame are selected as reference frames. the coincidence degree vs is determined by [25]:
As shown in Fig. 4, the feature points x on the previous frames are projected onto the current frame to obtain the feature points x cur and their projection depth Z cur , and the corresponding 3-D points X are generated.
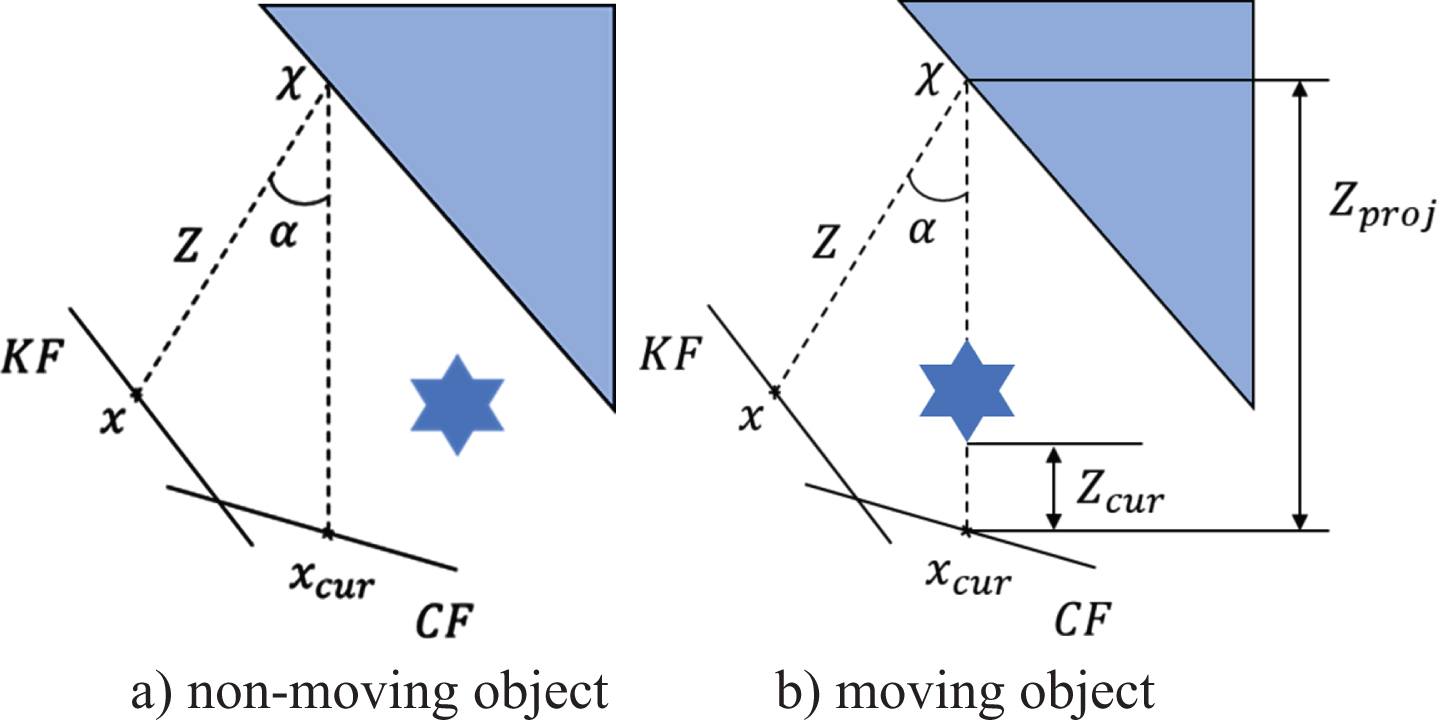
Principle of multi-view geometry.
The depth information and visual angle information are used to detect the dynamic objects. The depth difference ΔZ is calculated based on the actual depth value Z cur . The parallax angle α is calculated between the back-projections of x and x cur . Algorithm 2 shows the algorithm of multi-view geometry.
In this section, the experimental results of ESD-SLAM system illustrates its performance on TUM RGB-D dynamic scene dataset [27]. The experiments use two sets of dynamic sequences of sitting and walking. Each set of sequences contains four sequences, which are distinguished by the motion of the camera: (1) halfsphere: the camera moves around a hemisphere with a diameter of 1 m; (2) xyz: the camera moves along the x, y, z axis; (3) rpy: the camera rotates along the roll, pitch, and azimuth axes; and (4) static: the camera is stationary. Sequences in the sitting set are low dynamic sequences, in which two people sit at a table and do a small amount of exercise. While sequences in the walking set are high dynamic sequences, in which two people do a lot of movement around the table. The entire experiments are conducted on a computer with an Intel Core i7-9700k CPU, a GeForce RTX 2080Ti GPU, running on the Ubuntu 18.04 operating system.
Comparative experiment of extracting feature points
The Fig. 5 shows the comparison of ORB-SLAM2 and ESD-SLAM feature extraction on the two sets of TUM datasets (walking_xyz and walking_halfsphere). The feature extraction of ORB-SLAM2 is shown in the left figure, while the feature extraction of ESD-SLAM is shown in the right figure. It can be clearly seen that the ESD-SLAM algorithm effectively removes the feature points belonging to dynamic pedestrians.

The comparison of the ORB features extraction situation between ORB-SLAM2 and ESD-SLAM.
The proposed ESD-SLAM is developed based on ORB-SLAM2. ORB-SLAM3 is an improvement of ORB-SLAM2 by the original author. We compare the camera trajectories of three sequences (walking_xyz, walking_halfsphere, and sitting_static) produced by the three systems in X-Y axis plane. Figure 6 is the trajectories estimated by ORB-SLAM2, ORB-SLAM3, and ESD-SLAM. The estimated trajectories of the proposed ESD-SLAM are stated in the left column, while the estimated trajectories of original ORB-SLAM2 and ORB-SLAM3 are shown in the middle and right columns respectively. The relative translation error of the system is intuitively expressed by the length of the red line. The estimated trajectory of the ORB-SLAM algorithms is significantly different from the actual trajectory and its relative translation error is much larger than ESD-SLAM.
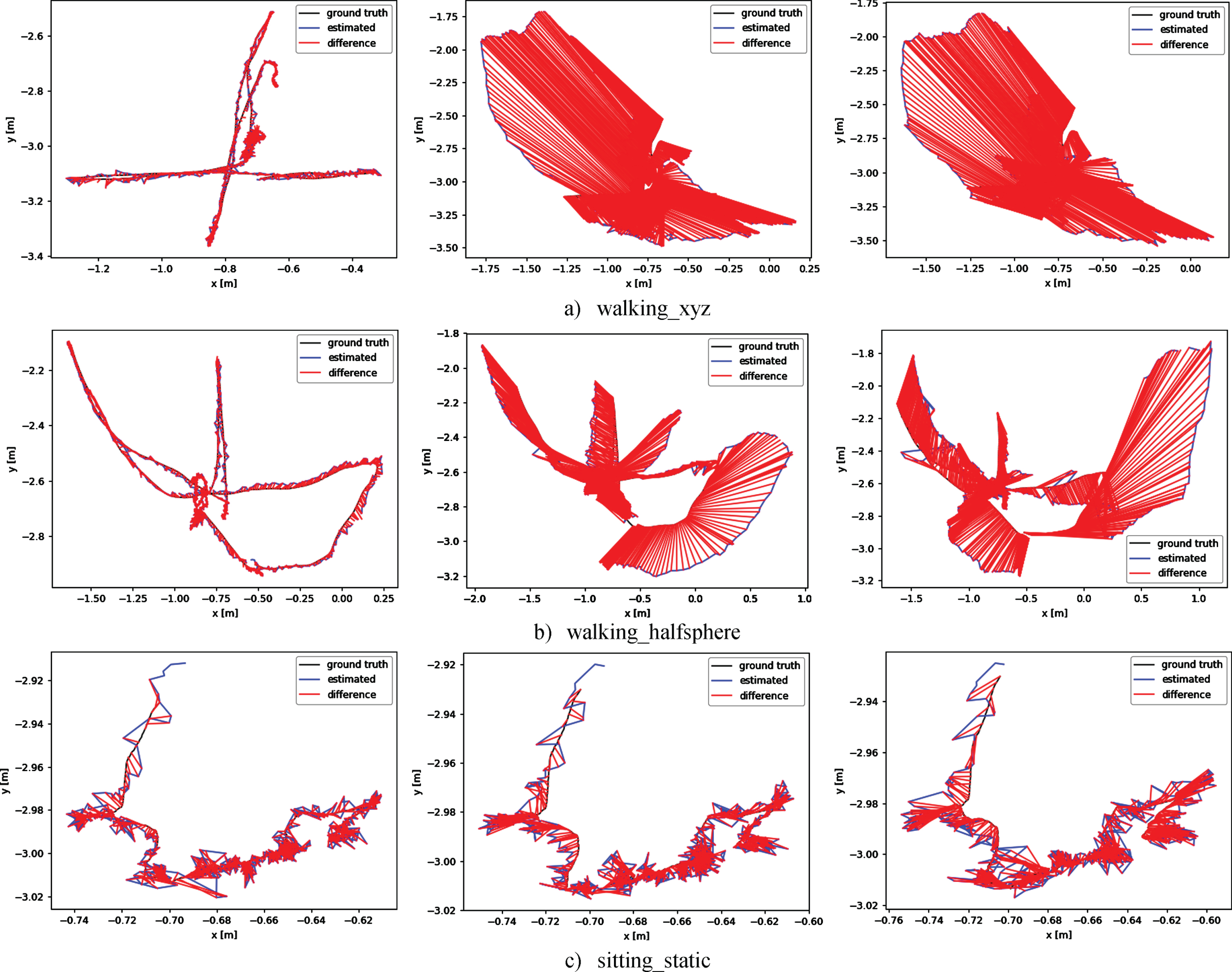
Trajectory comparison of the ESD-SLAM and ORB-SLAM algorithms.
We compare the localization accuracy of ESD-SLAM with other advanced algorithms on six sequences of the dataset (walking_halfsphere, walking_rpy, walking_static, walking_xyz, sitting_ halfsphere, and sitting_static). Absolute Trajectory Error (ATE) is used for quantitative evaluation, reflecting the gap between the estimated and the real. Root mean square error (RMSE) measures the robustness and stability of the system. Each sequence is run five times to get five RMSEs,and then the median, average, and minimum of the five RMSEs are calculated to reduce the impact of system uncertainty.
Comparison with ORB-SLAM2 and ORB-SLAM3
As shown in Tables 1 and 2, the proposed ESD-SLAM significantly reduces the absolute trajectory error in all seven sequences. In high dynamic sequences (walking_halfsphere, walking_rpy, walking_static, and walking_xyz), ORB-SLAM2 cannot deal with the feature points of moving targets effectively, which leads to large localization error. ORB-SLAM3 slightly alleviates this problem. The proposed ESD-SLAM improves the performance of the four sequences by an order of magnitude, and the overall localization error is reduced by 94% to 98%. For the low dynamic sequence (sitting_half and sitting_static), ESD-SLAM has a relatively small improvement on localization accuracy. This is because ESD-SLAM identifies people who only make gesture changes as “moving objects”, and it removes many feature points from the static part of the person. For the pure static sequence (fr1_360), the localization accuracy of the three algorithms is basically the same.
Comparisons of RMSE of ATE [m] for ESD-SLAM with ORB-SLAM2 and ORB-SLAM3
Comparisons of RMSE of ATE [m] for ESD-SLAM with ORB-SLAM2 and ORB-SLAM3
Accuracy improvement of ESD-SLAM against ORB-SLAM2 and ORB-SLAM3
Four advanced SLAM systems for dynamic environments are compared with ESD-SLAM in Table 3. The data of four existing systems are all from relevant articles, and the data of ESD-SLAM is the average value of 5 RMSEs. On walking_halfsphere, walking_rpy, walking_xyz, and sitting_static sequences, ESD-SLAM is superior to other systems in accuracy and robustness. On walking_static and sitting_halfsphere sequences, ESD-SLAM is close to the best sequence accuracy.
Comparison of RMSE of ATE [m] between this system and other dynamic SLAM system
Comparison of RMSE of ATE [m] between this system and other dynamic SLAM system
Real-time comparison of ESD-SLAM with other dynamic SLAM algorithms
Real-time comparison of ESD-SLAM with other dynamic SLAM algorithms
In this section, the dynamic objects in the environment are filtered and culled with ESD-SLAM, which finally generates the static dense point cloud maps without dynamic objects. Three sequences of the TUM dataset (sitting_static, walking_static,and walking_xyz) are tested. As Fig. 7 shows, the left images are the results without dynamic objects elimination by using ORB-SLAM2, which contains a lot of double shadows construction, while the right images are the results with dynamic objects elimination by using ESD-SLAM, where dynamic objects are successfully removed.

Dense 3-D mapping.
To demonstrate the effectiveness and the robustness of our system, we collected experimental data of the real scenes in the underground parking lot. The RGB images and corresponding depth data are captured by Intel Real-sense D435i camera.
Figure 8 shows the comparison of ORB features extraction situation between ORB-SLAM2 and ESD-SLAM in the real world. In Figure(a), there are lots of features extracted by ORB-SLAM2 lying on the walking people, while in Figure(b), the feature points on the moving people are basically removed by ESD-SLAM, and almost all feature points are extracted in the static background. Figure 9 shows the comparison of estimated camera trajectory between ORB-SLAM2 and ESD-SLAM. The blue trajectory estimated by ESD-SLAM perfectly forms a closed loop just as how the camera moves, which qualitatively reflects our accuracy. However, the dotted trajectory estimated by ORB-SLAM2 is unable to form a closed loop due to the existence of dynamic ORB features.

Comparison of the ORB features extraction situation between ORB-SLAM2 and ESD-SLAM.
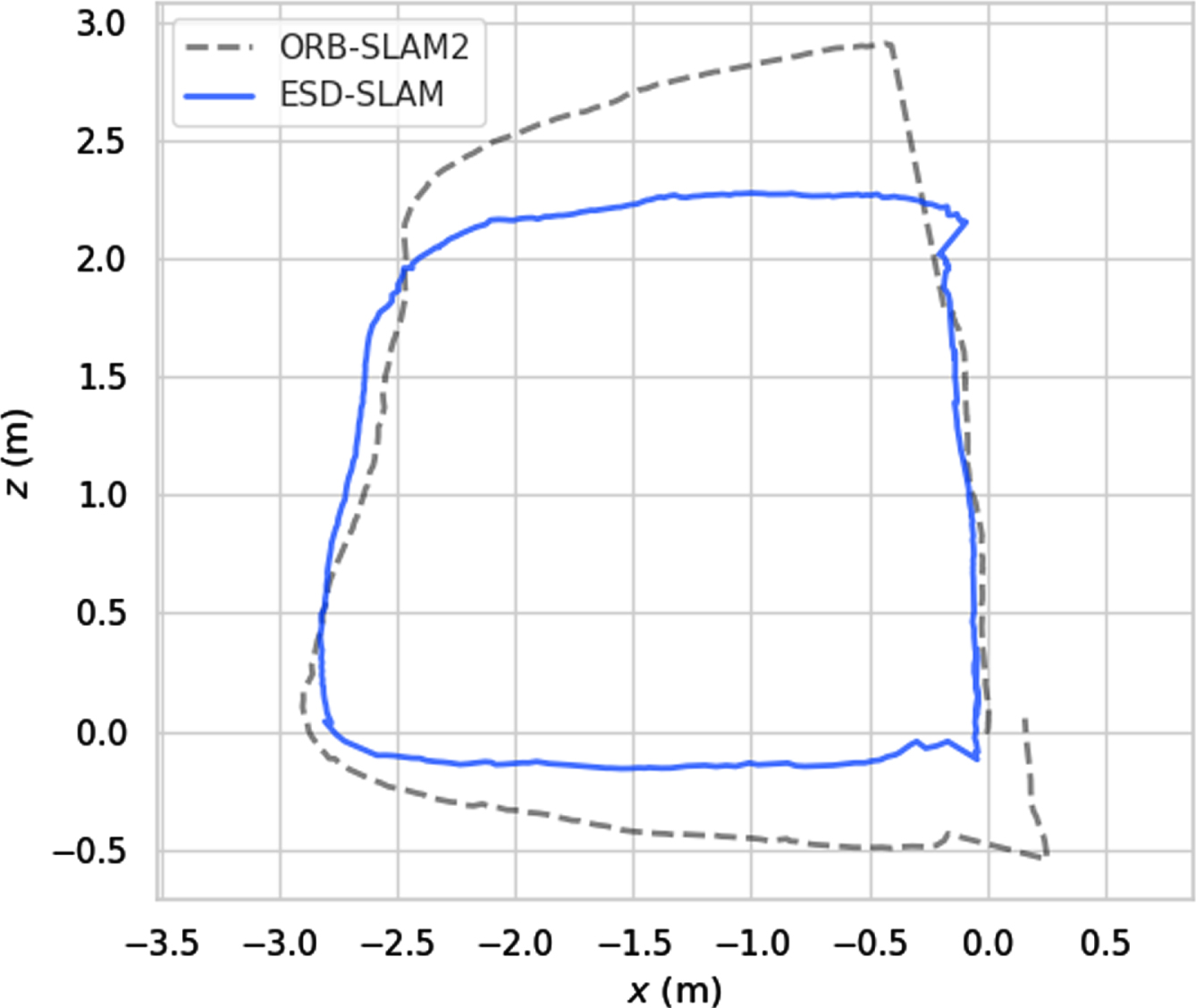
Qualitative comparison of trajectory between ORB-SLAM2 and ESD-SLAM.
This paper presents an efficient semantic dynamic SLAM (ESD-SLAM) for indoor dynamic scenes based on deep learning, which uses FcHarDNet lightweight semantic segmentation network to extract semantic information. Then region growth algorithm is used to optimize the boundary after semantic segmentation. Combined with multi-view geometry, the dynamic features in the environment are eliminated, which improves the localization accuracy and stability of the system in the dynamic environment. Finally, we carried out experiments in public TUM RGB-D dataset and in real laboratory environment. The results show that the proposed algorithm can significantly improve the localization accuracy and real-time performance in a dynamic environment.