
Abstract
Thirukkural, a Tamil classic literature, which was written in 300 BCE is a didactic literature. Though Thirukkural comprises 1330 couplets which are organized into three sections and 133 chapters, in order to retrieve meaningful Thirukkural for a given query in search systems, a better organization of the Thirukkural is needed. This paper lays such a foundation by classifying the Thirukkural into ten new categories called superclasses that is helpful for building a better Information Retrieval (IR) system. The classifier is trained using Multinomial Naïve Bayes algorithm. Each superclass is further classified into two subcategories based on the didactic information. The proposed classification framework is evaluated using precision, recall and F-score metrics and achieved an overall F-score of 82.33% and a comparison analysis has been done with the Support Vector Machine, Logistic Regression and Random Forest algorithms. An IR system is built on top of the proposed system and the performance comparison has been done with the Google search and a locally built keyword search. The proposed classification framework has achieved a mean average precision score of 89%, whereas the Google search and keyword search have yielded 59% and 68% respectively.
Keywords
Introduction
The Tamil language and literature have a rich and long tradition, going back in time to a little more than two thousand years. The Thirukkural, Agananooru, Purananooru and Silapathikaram are a few world-famous works. The Thirukkural, one of the most widely translated books of all time, has been published in a number of languages worldwide. The era of Tamil literature can broadly be classified into: Sangam literature, post-Sangam literature, medieval age literature and modern literature. The Sangam age, long reckoned the golden era of Tamil literature, dates back to the 1st century BC. The Thirukkural was written in the post-Sangam age. Having had such a long and glorious history, Tamil has transformed both in speech and text over the years. The current generation of Tamil speakers is largely unaware of the rich nuances characteristic of the lexical range used in ancient Tamil literature. This paper proposes a Thirukkural classification framework as an initial attempt to take ancient Tamil literature to today’s millennial.
Thirukkural focuses on morality and ethics. It offers all possible solutions for living a successful and happy life that are appropriate for any generation. It has been translated into 37 different languages around the world, necessitating computational processing of the Thirukkural.
The Thirukkural has 1330 couplets divided into 133 chapters, focusing on three major aspects of life: virtue, wealth and love [7]. The Thirukkural couplets in all the three sections provide advices to various classes of human society, as well as advice on what to do and what not to do. This paper attempts to merge the existing classification of the 3 aspects and 133 chapters into ten superclasses that denote the major classes of human society. The ten superclasses identified by the proposed framework are king, saint, scholar, friend, minister, family man, common man, husband, wife, and general. The superclasses are further classified into two subclasses: To Do (TD) and Not To Do (NTD). These specify aspects/advice to be followed, or not, by the respective superclasses. The proposed reorganization of the Thirukkural is done to make the computational classification easier. For instance, if an Information Retrieval (IR) system is built on top of the proposed classification framework, and a query, for instance, “What are the factors a king must consider while making a decision for his people?” is given, the proposed framework offers semantically closer results, given that all Thirukkural couplets related to king are grouped into a superclass and two subclasses.
The contributions of this paper are threefold: Identification of 10 superclasses, and their respective two subclasses, for the Thirukkural. Classification of the Thirukkural into superclasses using the Multinomial Naïve Bayes (MNB) Classifier. Rule-based classification of subclasses.
MNB Classifier is one of the multiclass classification algorithms and suits well for small datasets. The Thirukkural has only 1330 couplets, and these couplets need to be classified into ten superclasses in the proposed work. Hence, the proposed work uses MNB Classifier to classify the Thirukkural couplets.
The remainder of the paper is laid out as follows. The background information about the Thirukkural is presented in Section 2. The related work is described in Section 3, and the proposed work is discussed in Section 4. The section 5 explains experiments and results of the proposed methodology. The section 6 presents conclusions and future work.
Background
This section describes the Tamil language and the Thirukkural. Tamil is a language that has been spoken since 300 BC. The language has undergone a radical transformation in terms of the script, grammar and word usage, and these changes have been reflected, correspondingly, in its literature. For the current generation that is unable to understand such ancient literature but is interested in reading it, simplified versions are readily available. To make it even more convenient, if those simplified versions are made available in an IR system like Google, alongside the original classic, a lot of people today will benefit from an understanding of the ancient language, its style, and its indubitable value. The proposed work intends to lay such a foundation.
The Thirukkural is a classic work of Tamil literature which focuses on ethics and moral values. It has been translated into more than 37 Indian and international languages, including English, Latin, French, German, Russian, Spanish, Chinese, Japanese, Arabic, and so on. It comprises 1330 couplets organized into 133 chapters and divided into three sections: “ (transliteration-Arattuppāl; translation-virtue)”, “
(transliteration-Arattuppāl; translation-virtue)”, “ (transliteration-Porutpāl; translation-wealth)” and “
(transliteration-Porutpāl; translation-wealth)” and “ (transliteration-Kāmattuppāl; translation-love)”. Thirty-eight chapters are devoted to virtue, 70 to wealth, and 25 to love [7]. Each chapter has 10 couplets. Each couplet contains seven words known as “
(transliteration-Kāmattuppāl; translation-love)”. Thirty-eight chapters are devoted to virtue, 70 to wealth, and 25 to love [7]. Each chapter has 10 couplets. Each couplet contains seven words known as “ (Cīr)”, with four cirs in the first line and three in the second. A cir is a crisp way of representing many words using one word.
(Cīr)”, with four cirs in the first line and three in the second. A cir is a crisp way of representing many words using one word.
The three sections offer all classes of human society invaluable advice. The proposed work aims at reorganizing the Thirukkural by classifying all 1330 couplets from the perspective of the classes of human society that are identified as superclasses. Table 1 shows the sections, and the respective superclasses for which the said sections are meant, in the existing organization of the Thirukkural. English transliteration and its meaning in English are given within parenthesis for the Tamil words used. The transliterations are done using the Google Translation. G.U.Pope’s explanation is used in all the Thirukkural couplets given in examples.
Sections of Thirukkural and its superclasses
Sections of Thirukkural and its superclasses
It can be observed that the ten superclasses are scattered across all three sections. When Natural Language Processing (NLP) applications - such as an IR or a Summary Generation system - need to retrieve the Thirukkural specifically for a particular superclass, the Thirukkural couplets have to be grouped as per their classes for easier access by the above said NLP applications. Table 1 shows only nine superclasses. The proposed work groups the Thirukkural couplets that do not fall into these nine classes into a tenth superclass, titled general.
All advice in the Thirukkural can, generally speaking, be classified into what a person must, and must not, do. Further, the proposed framework has incorporated this classification by introducing two subclasses: TD and NTD for each superclass. Example 1 in Fig. 1 belongs to the superclass king and the subclass NTD.

Example 1.
The Thirukkural couplet in Example 1 advises a king with a sizeable army not to engage in battle with a king who has a miniscule army. If he does, his pride will take a beating on account of his being made to look small. When a query is given to the IR system, the proposed work can aid in retrieving this Thirukkural couplet.
In this section, a survey of the literature on the related work is undertaken from two perspectives. Since the proposed work is a text classification framework, the related work on text classification is discussed. Given that the proposed framework classifies Tamil literature for a computational analysis later, this section focuses on computational work done on the literature.
Works related to text classification
In [9], Nunzio (2009) used the Bernoulli and MNB models for text classification into two classes. The term frequencies of the document were used as features. Their work was tested on 94380 English documents from four datasets: Reuters, 20 Newsgroups corpus, WebKB and the 7 Sectors database. Mean average precision was used as evaluation metrics and achieved 27%.
In [8], Capdevila and Florez (2009) proposed a framework for automatic text categorization using the Gaussian probabilistic classifier and classified text into 90 categories, with the unique words in the document functioning as features. Their work was tested on 10788 English documents from two datasets, 20 Newsgroups and the Reuters 21578 collection, with accuracy as evaluation metric.
In [15], Rajan et al. (2009) classified Tamil documents into five categories using the vector space model and artificial neural networks, with the most frequent words in the documents used as features. Their work was tested on 400 Tamil documents of the Tamil CIIL corpus with precision as the evaluation metric.
In [2], Al-Salemi and Aziz (2011) used the simple Naïve Bayes, multi-variant Bernoulli Naïve Bayes and MNB models to automatically categorize Arabic documents into four classes, with the most frequent terms in the documents serving as features. In-house collections of Arabic news were used as a dataset to test their work, in all on 3172 Arabic documents. Macro average is the average of F1-measure of all categories. Precision, recall, F1-measure and macro-average were used as evaluation metrics and achieved overall Macro-F1, 0.941.
In [16], Rizzo et al. (2017) classified research articles into two classes, relevant and non-relevant papers, using the MNB classifier. The classification assists researchers retrieve relevant papers for their research. Authors’ names, names of journals, journal references, abstracts, introductions and conclusions were used as features. Their work was tested on 2215 papers from the benchmark Systematic Literature Review dataset, with recall as the evaluation metric and achieved 95%.
In [1], Al-Badarneh et al. (2017) investigated different indexing approaches for Arabic text classification using the MNB classifier and identified five categories. Word frequencies were used as features in their 1000 normalized Arabic documents dataset. Micro average accuracy was used as evaluation metric and achieved 99.36%.
In [23], Xu (2018) classified a text into 20 categories, comparing algorithms such as the classical Naïve Bayes classifier as well as the Bernoulli and Gaussian event models. Word frequencies of the document were used as features. Their work was tested on 23020 English documents from the 20 Newsgroups and WebKB datasets. Precision, recall and F-measure were used as evaluation metrics.
In [6], Bahgat et al. (2018) classified the email into two categories using semantic methods. The Principal Component Analysis and Correlation Feature Selection techniques were used for feature selection. The benchmark Enron dataset was used for evaluating their work. The comparative study was performed with different machine learning techniques and 90% accuracy was achieved.
In [12], Luo (2021) used Naïve Bayes, Support Vector Machine and Logistic Regression machine learning algorithms to classify English documents. Word frequency, question mark, full stop, initial word and final word of the documents were used as features. The author has tested the work with 1033 English documents. Precision, recall and F-measure were used as evaluation metrics.
The existing text classification work has been done on English, Arabic and Tamil expository documents. The proposed work differs from these by attempting a text classification framework for a literature-type text in Tamil, and is the first of its kind. The usage of words in expository documents is different from literature-type text. For instance, the literature word “ (Ilavē - not)” is not commonly used in expository type of Tamil text. It is one of the words in negative feature set which is used for subclass classification. Handling of literature words is one of the challenges of the proposed work. Furthermore, the proposed work has attempted to reorganize the ancient Tamil literature, Thirukkural, to make the computational analysis easier. Next section describes other computational works done on Tamil literatures.
(Ilavē - not)” is not commonly used in expository type of Tamil text. It is one of the words in negative feature set which is used for subclass classification. Handling of literature words is one of the challenges of the proposed work. Furthermore, the proposed work has attempted to reorganize the ancient Tamil literature, Thirukkural, to make the computational analysis easier. Next section describes other computational works done on Tamil literatures.
Computational work done on tamil literature
In [10], Elanchezhiyan et al. (2011) proposed the Kuralagam search engine for the Thirukkural, which retrieves couplets based on keywords, concepts and expanded query words. It retrieves couplets that are conceptually relevant to the query. Mean Average Precision was used as the evaluation metric and achieved the score of 0.83.
In [13], Madhavan et al. (2012) classified Tamil poems into four protocols called “Paa", using a rule-based approach, and context-free grammar to create the rules. Tamil poems have been parsed, an intermediate representation was created, and the poems were subsequently classified into four categories. They have achieved classification accuracy of 90%.
In [17], Sridevi and Subashini (2013) classified 11th century Tamil handwritten texts using the probabilistic neural network. Line, word, character segmentation and feature extraction were done before the classification, with structural and syntactic features. Testing involved the use of 500 characters, with accuracy as the evaluation metric. They have achieved the classification accuracy of 80.52%.
In [21], Subalalitha and Ranjani (2014) used a concept called Suthras, found in Sanskrit literature as well as in the Tamil grammar text, Nannool, for a crisp representation of texts. They attempted to merge these concepts with current text processing techniques like the rhetorical structure theory and universal networking language to identify the semantic indices of Tamil documents. The most frequently occurring words and synonyms were used as features. Their dataset comprised 1000 tourism-based Tamil documents, and was evaluated using the mean average precision metric and achieved the score of 0.7.
In [20], Subalalitha and Poovammal (2018) constructed an automatic bilingual dictionary for the Thirukkural using the Naïve Bayes machine learning algorithm. They used an English translation and commentary by G. U. Pope, alongside explanations in Tamil by Dr M. Varadharajan and Dr Solomon Pappaiya. Precision was used as an evaluation metric and achieved 70%.
In [4], Anita and Subalalitha (2019) proposed an approach to cluster Thirukkural couplets using discourse connectives as features. The K-means clustering machine learning algorithm was used. Cluster purity, the Rand index, precision, recall and F-score were used as evaluation metrics to obtain 79% purity, 92% overall Rand index, 79% precision, 80% recall and an F-score of 79%.
In [5], Anita and Subalalitha (2019) proposed a rule based approach to construct a discourse parser for the Thirukkural. They have used discourse connectives as the features. Precision and recall were used as evaluation metrics and achieved 81.5% precision and 81.86% recall.
In [19], Subalalitha (2019) proposed an information extraction scheme for the Tamil literary work, Kurunthogai. Details pertaining to food, flora, fauna, vessels, water bodies, noun unigrams, verb unigrams, adjective-noun bigrams and adverb-verb bigrams were extracted. A Tamil morphological analyzer tool was used to extract N-grams. Precision was used as the evaluation metric and obtained 88.8%.
It can be seen that substantial computational works have been done on Tamil literature. The proposed method differs from the above by attempting a yet-to-be-explored text classification of the Thirukkural.
Proposed work
The proposed system tries to combine the current classification of the three sections and 133 chapters into ten superclasses that represent the major human groups. King, saint, scholar, friend, minister, family man, common man, husband, wife, and general are the ten superclasses defined by the proposed work. To Do (TD) and Not To Do (NTD) are the two subclasses of the superclasses. These specify aspects/advice on what to do and what not to do, by the respective superclasses.
The architecture of the proposed work is shown in Fig. 2. The 1330 Thirukkural couplets are divided into a training set (80% of all couplets) and a testing set (20%). The training couplets are tagged into ten superclasses by semantically analyzing them. The testing couplets are classified into superclasses using MNB Classifier. Each superclass is further classified into two subclasses using morphological features [3] generated by the Morphological Analyzer, which is a tool developed at Anna University, Chennai.
Architecture for the proposed methodology.
The MNB classifier is one of the algorithms for multi-class text classification. Since the MNB is a supervised classification algorithm, the text documents are labeled / categorized into predefined classes. The MNB builds a probabilistic model using the training set. The testing set is classified using the probabilistic model.
Let Tr be the training set Tr = {Tr1, Tr2, ... Trm}, where m = 1064 and Ts is the testing set. Ts = {Ts1,Ts2, ... Tsn}, where n = 266. The Thirukkural couplets in the training set are labeled manually. The superclasses king, saint, scholar, friend, minister, family man, common man, husband, wife, and general are denoted as C = {C1, C2, ... Ck}, where k = 10. The couplets in the Tr are mapped semantically into one of the classes of C, Tr⟶{C1, C2, ... Ck } during the training.
The construction of the probabilistic model involves the following steps. Calculation of prior probabilities. Calculation of conditional probabilities. Calculation of posterior probabilities.
The prior probabilities are calculated for each superclass for the training set, Tr, using equation given in Equation (1).
After ascertaining the prior probability, the conditional probability is calculated. It is the probability of a word appearing in a particular superclass (Ci), using the equation given by Equation (2). Trj = w1,w2 …wx, where x = 7.
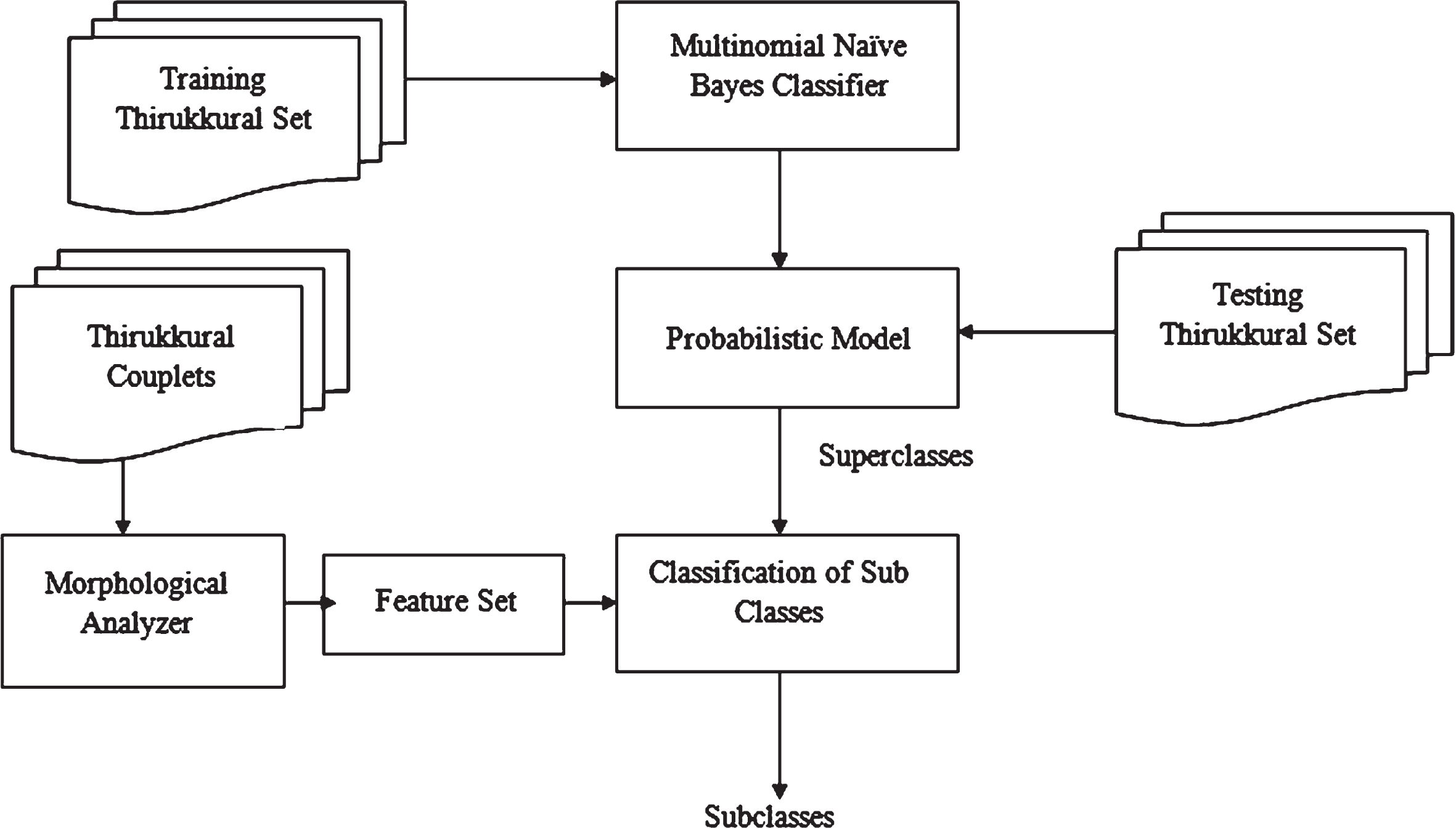
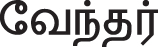 (Vēntar-King)” has a higher conditional probability for the superclass king than for other classes.
(Vēntar-King)” has a higher conditional probability for the superclass king than for other classes.
The posterior probability is calculated for the couplets in the testing set by Equation (3). Tsy = w1,w2 ... wx, where x = 7.
The couplets in the testing set are classified by Equation (4). Example 2 in Fig. 3 is categorized as superclass king, since this couplet contains terms like, “ (Ceṅkōl –Scepter) ”, “
(Ceṅkōl –Scepter) ”, “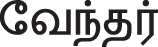 (Vēntar-King)”, and “
(Vēntar-King)”, and “ (Kotai –Donation)” have a higher probability for the superclass king than other classes.
(Kotai –Donation)” have a higher probability for the superclass king than other classes.

Example 2.
The test set has been classified into 10 superclasses. Each superclass, C, now needs to be further classified into two subclasses, TD and NTD. Since the Thirukkural literature explains what a person must do and must not do by the superclasses, the feature set is constructed with the negative words used in the Thirukkural. This feature set for subclass identification is identified using a morphological analyzer [3], which identifies both the morphemes and Parts of Speech tags. Morphological features, such as adjectives, such as “ (Ketta –Bad)”, adverbs, such as “
(Ketta –Bad)”, adverbs, such as “ (Inri –Without)”and negative finite verbs, such as “
(Inri –Without)”and negative finite verbs, such as “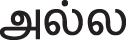 (Alla - Not)” are considered feature set for subclass identification.
(Alla - Not)” are considered feature set for subclass identification.
Algorithm 1 describes the subclass identification. The Thirukkural couplet is analyzed for the negative word by searching the Feature_set. If there is no feature from the Feature_set occurring in the couplet, the Thirukkural couplet belongs to the positive subclass, TD. If a word (Wi) of a Thirukkural couplet is matched with the word in the Feature_set, the three words preceding Wi (Wi - 1,Wi - 2,Wi - 3), and the three words succeeding Wi (Wi +1,Wi +2, Wi +3) must be analyzed for negative words, since each Thirukkural couplet contains 7 words. If there is a negative word, the couplet belongs to the positive subclass TD, otherwise it belongs to the negative subclass, NTD.
Example 3 in Fig. 4 illustrates how subclass identification is carried out. In Example 3, there is no negative word that is present in the Feature_set, so the couplet belongs to the TD subclass.

Example 3.
In Example 4 in Fig. 5, the word “ (Illai-No)” is W5 ∈ Feature_set and there is no other negative word that is present in Feature_set in surrounding, so the couplet belongs to the NTD subclass.
(Illai-No)” is W5 ∈ Feature_set and there is no other negative word that is present in Feature_set in surrounding, so the couplet belongs to the NTD subclass.

Example 4.
In Example 5 in Fig. 6, the word “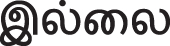 (innata - unpleasant)” is W2 ∈ Feature_set and the word “ (Illai -No)” is W3 ∈ Feature_set, so the couplet belongs to the TD subclass. The word “
(innata - unpleasant)” is W2 ∈ Feature_set and the word “ (Illai -No)” is W3 ∈ Feature_set, so the couplet belongs to the TD subclass. The word “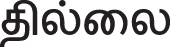 ” contains the word “’ which is separated using the morphological analyzer tool.
” contains the word “’ which is separated using the morphological analyzer tool.

Example 5.
Dataset details
The dataset is tested using the inter-rater reliability [11, 18]. The inter-rater reliability is a test validity method used to measure the score given by the human experts. In our dataset, three human experts found the Thirukkural couplets category.
Table 2 describes the percentage agreement for the superclass categories of the Thirukkural couplets. We have used 0 to 9 to represent the superclasses king, saint, scholar, friend, minister, family man, common man, husband, wife, and general respectively. All the annotators classified the couplet 1 as 9, which is general superclass, and the agreement is 100 percentage. Similarly, inter-rater reliability is calculated for all the Thirukkural couplets. The next section describes the implementation and analysis of the results.
Percentage agreement across multiple annotators
Percentage agreement across multiple annotators
The training set consists of 1064 Thirukkural couplets (80% of all couplets) and the testing set consists of 266 (20% of all couplets). The proposed approach has been evaluated using the metrics of precision, recall and F-measure, calculated as in Equations (5), (6) and (7) [14].
F-Score is given by the following formula.
The value of the variable, M, is calculated automatically, whereas the C and N values are calculated using human judgment. About three domain experts have calculated these metrics, and the average has been taken and presented in Tables 3 and 5.
Since the proposed work has attempted to merge the three sections and 133 chapters into ten superclasses, it is seen from Table 3 that the superclass common man dominates the rest of the classes and the superclass, Saint is least observed. Table 4 depicts the number of chapters in which each superclass is focused on. Table 4 shows that the proposed framework retains the integrity of the contents even after the reorganization of the existing Thirukkural.
Precision, Recall and F-Score for the Superclass classification
Chapter-Super class mappings
The prior probability and conditional probability are higher for the superclasses that are present in the most number of chapters. This is the reason for the decrease in precision, recall and F-score metrics. It can be alleviated by adding weights to words that decide the superclasses. Since a couplet has only seven words, the proposed approach has considered all words to be equal.
The Thirukkural couplet in Example 6 in Fig. 7 must be classified as superclass king. The probabilistic model is based on frequency of words. This couplet contains the word “ (Il –House)” related to the superclass family man, two times and other words are also occurring more number of times in superclass family man than superclass king. Hence this Thirukkural couplet is classified as family man instead of king.
(Il –House)” related to the superclass family man, two times and other words are also occurring more number of times in superclass family man than superclass king. Hence this Thirukkural couplet is classified as family man instead of king.

Example 6.
The superclasses are classified into two subclasses: TD and NTD. The precision, recall and F-score values are found using Equations (5), (6) and (7), and listed in Table 5. The precision, recall and F-score metrics obtained for subclass identification depends on the correctness of the morphological analyzer. During training, certain words are not correctly split into morphemes.
Precision, Recall and F-Score for the Subclass classification
Example 7 in Fig. 8 must be classified as NTD subclass. Some literature words are not correctly separated by the Morphological analyzer, for instance, it did not split the word “ (Peyarār –Not change)”from “
(Peyarār –Not change)”from “ (Tāmpeyarār –Who do not change)” and is classified as TD subclass.
(Tāmpeyarār –Who do not change)” and is classified as TD subclass.

Example 7.
The results of the machine learning algorithms, such as, MNB, Support Vector Machine (SVM), Linear Regression (LR) and Random Forest (RF) are compared. The precision, recall and F-score values of the algorithms are shown in Figs. 9, 10 and 11.
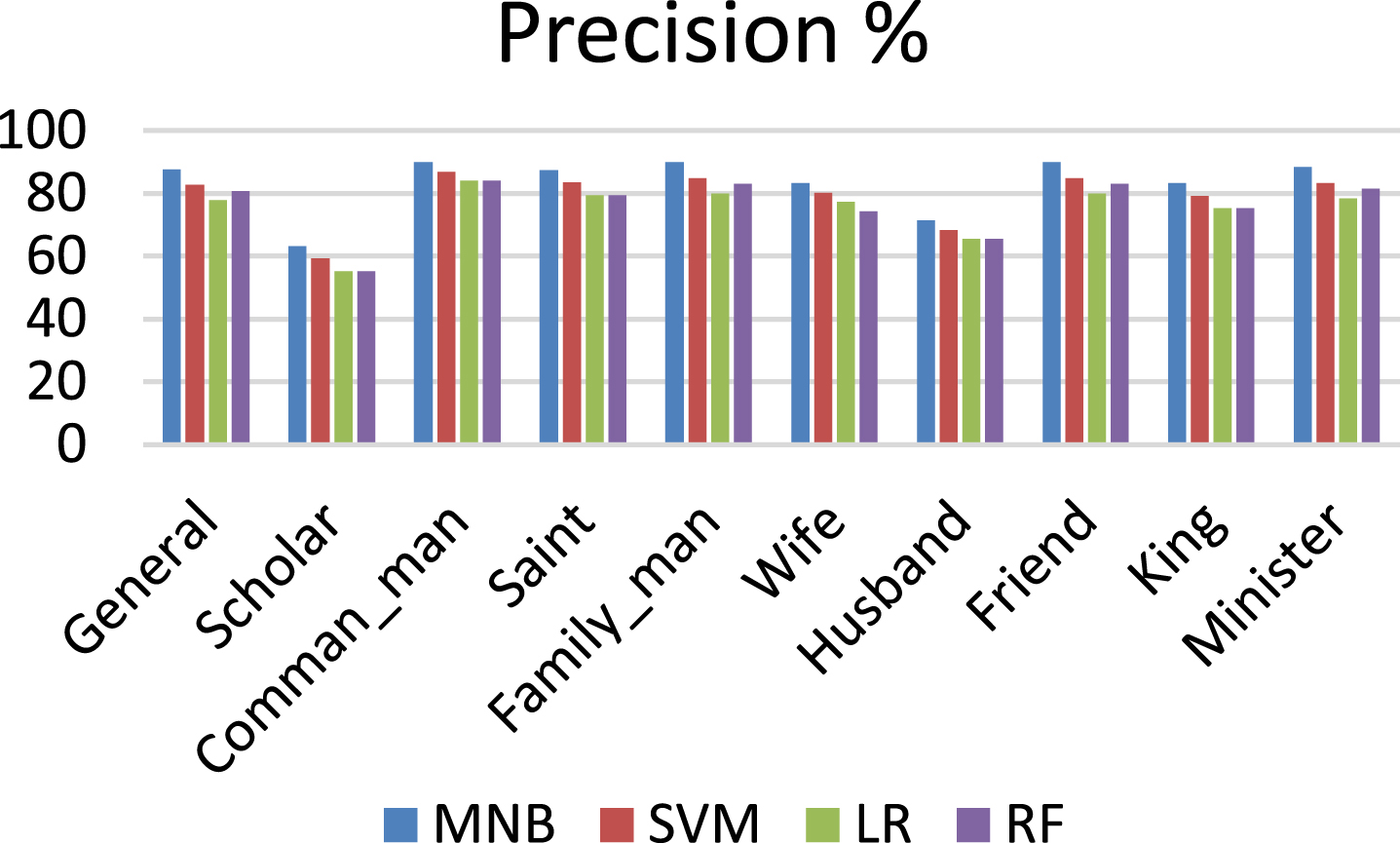
Comparison of algorithms using precision.

Comparison of algorithms using Recall.
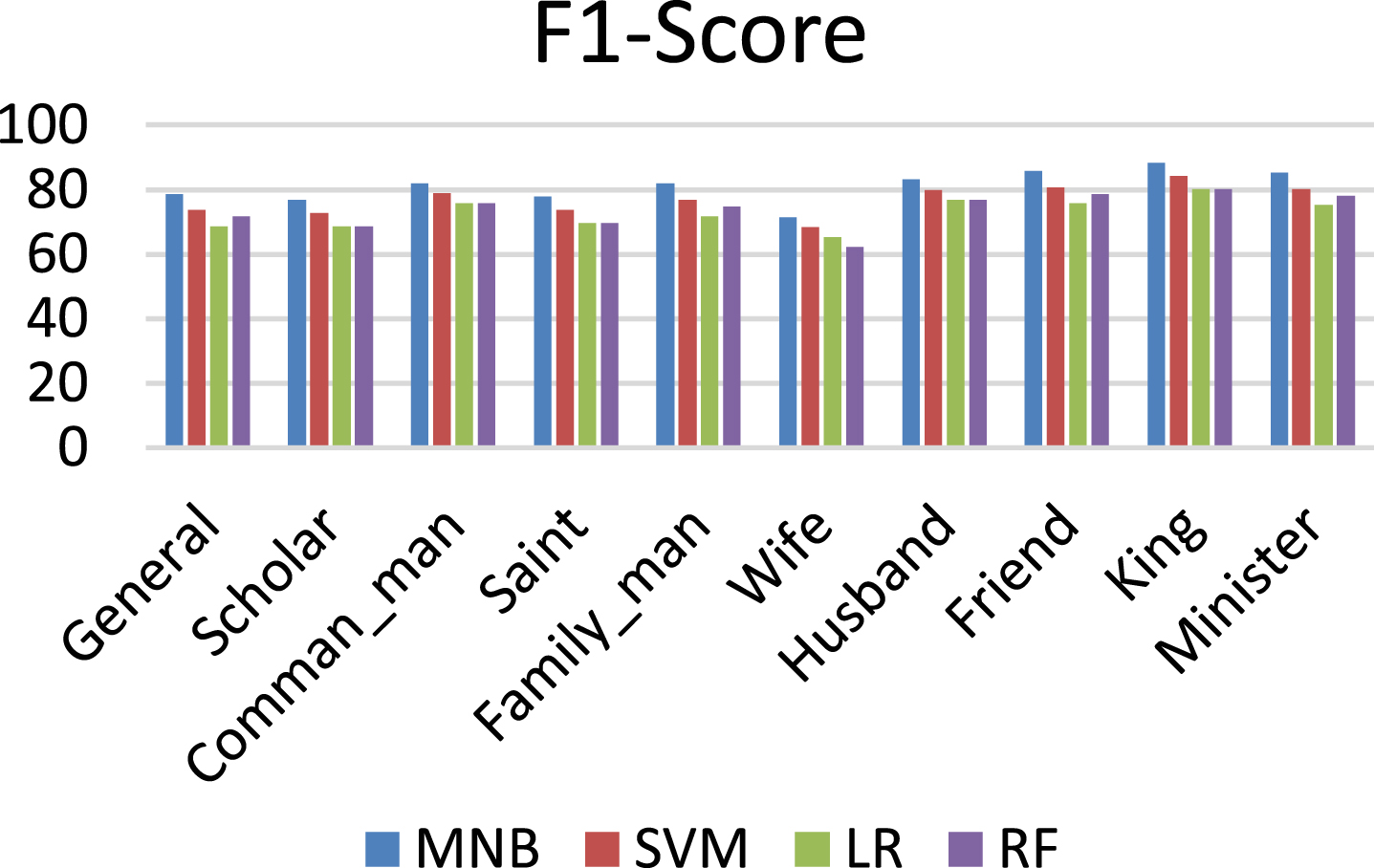
Comparison of algorithms using F-score.
It can be observed from the comparison that the MNB algorithm gives good results than the rest of the algorithms. The reason behind this is that MNB works better in small datasets and it is based on frequency of words.
An IR system has been developed on top of the proposed framework to assess its efficiency, and performance has been compared to Google search and a locally built search that does not use the proposed classification framework (Search without classification). The proposed work is evaluated using the precision (P), average precision (AP), and mean average precision (MAP) metrics computed using Equations 8, 9, and 10 [22].
Equation 8 is used to calculate the precision of the Thirukkural couplets. Equation 9 yields AP@10, which is the average precision for the top 10 retrieved results.
N is the number of queries, which in this case is 15. The proposed supervised classification-based search method has a MAP score of 0.89, compared to 0.59 for Google search and 0.68 for Search without classification.
The average precision values for Google search, Search without classification, and Classification-based search are shown in Table 6, which shows an output comparison of the proposed approach with the other two, where Qi denotes query i. Because of the use of superclass and subclass classification, the precision and MAP scores obtained by the proposed work are higher than those of Google search and Search without classification.
Performance Comparison using average precision values
Keyword matching is at the heart of both Google search and Search without classification. In most cases, Google retrieves the entire chapter of Thirukkural that matches the keywords in the query, ignoring the semantically related ones. For example, if a query contains the word “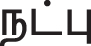 (Natpu –Friendship)”, Google will return a chapter on “ (Natpu –Friendship)”, as well as a chapter on “
(Natpu –Friendship)”, Google will return a chapter on “ (Natpu –Friendship)”, as well as a chapter on “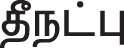 (Tīnatpu –Evil Friendship)”, from the Thirukkural, explaining why the MAP score is so poor. The Thirukkural couplets matching the keywords present in the query, as well as their synonyms, are retrieved in Search without classification, missing the relevant words. For instance, if a query contains the term “
(Tīnatpu –Evil Friendship)”, from the Thirukkural, explaining why the MAP score is so poor. The Thirukkural couplets matching the keywords present in the query, as well as their synonyms, are retrieved in Search without classification, missing the relevant words. For instance, if a query contains the term “ (Aracan - King)”, the Search without classification retrieves the Thirukkural couplets matching the keyword “” (Aracan - King)”, as well as their synonyms “
(Aracan - King)”, the Search without classification retrieves the Thirukkural couplets matching the keyword “” (Aracan - King)”, as well as their synonyms “ (Mannan - King)”, “
(Mannan - King)”, “ (Vēntaṉ - King)” and “
(Vēntaṉ - King)” and “ (Maṉṉavaṉ - King)”. It does not retrieve Thirukkural couplets matching words related to “
(Maṉṉavaṉ - King)”. It does not retrieve Thirukkural couplets matching words related to “ (Aracan - King)” such as “
(Aracan - King)” such as “ (Aran - Bulwark)”, “
(Aran - Bulwark)”, “ (Ceṅkōl –Scepter), “
(Ceṅkōl –Scepter), “ (Patai –army)”, and so on, which are retrieved in classification-based search because these words have higher probability values for the superclass king.
(Patai –army)”, and so on, which are retrieved in classification-based search because these words have higher probability values for the superclass king.
This paper has attempted to reorganize the existing Tamil classic literature, Thirukkural, by proposing new set of 10 superclasses for building an efficient search system. The proposed approach has used the MNB classifier to classify Thirukkural couplets into ten superclasses. They have been further classified into two subclasses capturing the didactic essence of Thirukkural.
The efficiency of the proposed classification framework is tested by building an IR on top of proposed classification framework. The performance of the proposed IR systems has been evaluated using the MAP score and compared with the traditional search without classification and Google search. The results (MAP score of 0.89) were better than those produced by state of the art approaches and were largely driven by the classification framework. In order to justify the choice of MNB classifier, the MNB algorithm is compared with the SVM, LR and RF algorithms.
The proposed approach can be extended to other unexplored Tamil classics such as the Kurunthogai, Purananooru, and Naladiyar by finding an apt semantic representation for these literatures.