
Abstract
Because multiple domain cyberspace joint attacks are becoming more widespread, establishing a multiple domain cyberspace defensive paradigm is becoming more vital. However, although some physical domain and social domain information is incorporated in present approaches, total modeling of cyberspace is absent, therefore thorough modeling of cyberspace is becoming increasingly necessary. This paper proposed a knowledge graph based multiple domain cyberspace modeling approach. A knowledge graph of multiple domain cyberspace is produced by extracting multiple domain entity information and entity relations such as physical domain, social domain, network domain, and information domain, so that semantic information of multiple domain cyberspace may be described consistently. At the same time, this paper proposed a user’s permissions reasoning method based on multiple domain cyberspace knowledge graph to address the user’s permissions reasoning that relies on artificial reasoning principles. Through the model learning knowledge graph triples characteristics and rules, and implementing automatic reasoning of user’s permissions, this proposed method can abandon the artificial model of writing reasoning rules, allowing the machine to learn the reasoning rules using machine learning and other methods. Experimental results showed that the proposed method can learn relevant reasoning rules and accomplish automated reasoning of user’s permissions, and that the method’s accuracy and recall rates are higher than those of path ranking and translating embeddings.
Keywords
Introduction
For many years, network attack detection and protection has been a hot topic in academic circles. Because of the complexity and diversity of network attacks, it has been discovered that network attack from multiple domain has gradually become the mainstream way to detect the attack. However, while the network contains the physical domain and the social domain, there is a lack of multiple domain cyberspace to complete modeling in the current method. As a result, correctly reasoning the attacker’s or user’s multiple domain action purpose is difficult.
Physical domain, digital domain, network domain, social domain, and other domains are now included in the definition of multiple domain cyberspace [1]. The physical domain is mostly used to represent three-dimensional spatial information, such as a city, region, building, room, and so on. The network domain is the typical cognition of the cyberspace; the social domain largely relates to people’s relationships, such as when an attacker and a company’s internal network administrator were classmates, the attacker may more easily get cyberspace permits than other attackers. The digital domain refers to an information entity that primarily represents digital data such as a user name, password, secret key, or information.
The main goal of the Knowledge Graph (KG) based unified description of multiple domain cyberspace is to extract semantic information from multiple domain cyberspace design and configuration, and to assess whether cyberspace events and configuration changes may have negative consequences for the overall cyberspace security state. The procedure may be broken down into three stages: To begin, the hierarchical entity characteristics are constructed using theoretical analysis in line with top-down and bottom-up methodologies, and they mostly encompass diverse entities in the physical domain, information domain, network domain, and social domain. Second, after all sorts of entities have been identified, it is required to sort out the connections between them, which may be classified as inclusion relationships, dependence relationships, domain relationships, supply relationships, and other types. After determining the entities and their relationships, the corresponding multiple domain cyberspace KG is built to establish a coherent semantic description of the multiple domain cyberspace.
Through the establishment of a good multiple domain cyberspace semantic information, which can be defined by the first-order logic corresponding reasoning rules, describes cyberspace events on the influence of the number of entities and entity relationship and attribute, and the change of entities and entity relationship influence on the relationship between user’s permissions, to find the user if he is getting more permission than he should have, in order to realize the formalization of existing reasoning methods. On the other hand, are all rule-based reasoning, with rules established by first-order logic and reasoning rules described by specialists. As a result, they are limited in their abilities and have a low degree of intelligence. As a result, it’s worthwhile to investigate how to intelligently reason user’s permissions from the KG of different domain entities.
To address this problem, this paper employs the KG construction method to describe these entities and their relationships, as well as the KG based reasoning method to implement under the multiple domain semantic cyberspace user’s permissions of intelligent reasoning, in order to discover the permissions that the user should not have, as well as to discover how multiple domain cyberspace configuration and cyberspace entity relationship affect user’s permissions, and to further optimize user’s permissions.
The main contributions of this paper are as follows: We propose a unified representation approach of multiple domain semantic cyberspace based on KG, which can describe entities and entity relations in multiple domain cyberspace in a unified description using semantic information; The KG is used to create a unified description of multiple domain cyberspace, and the existing multiple domain cyberspace security state is reasoned using the unified semantic information description to uncover the interrelationship between multiple domain assaults; As a result, to achieve the user’s permissions reasoning method based on the KG, this method abandons the traditional pattern of specialists writing reasoning rules in advance, can let the model learn automatically to the reasoning rules, realize the user’s permissions of intelligent reasoning, has a wider range of applicability and operability, and provides a new train of thought for the user’s permissions intelligent reasoning. Experimental results showed that our proposed method is superior to current reasoning methods.
This paper’s structure is as follows: We cover related works in Section 2, and we go into the unified semantic description of multiple domain cyberspace based on KG in detail in Section 3. Section 4 explains how we utilize KG to reason about our user’s permissions. Our experiment and analysis of the data are presented in Section 5. The last section is the conclusion.
Related works
KG is a knowledge representation, a semantic network that shows the relationships between things, and it falls under the semantic network category, which encompasses entities, relations, and events in the actual world.
External objective facts are referred to as information. External objective laws are inferred and summarized in knowledge. Establishing links between things based on information may be done as “knowledge”. To put it another way, the KG is made up of bits of information, each of which is represented by a Subject Predicate Object triad. This is exactly how KG operates. The top-down strategy of developing the KG, in which the ontology and data schemas for the KG were specified before entities were added to the knowledge base, was formerly popular. However, as a fundamental knowledge base, this creation approach must use an already organized knowledge base [2].
Cyberspace KG construction
Google suggested KG for the first time in 2012 [3]. Graphs, a semantic network that holds entities and relationships between items in the form of graphs, are used to store knowledge. In general, ontology creation, information extraction [4], and knowledge storage are the primary components of cyberspace KG construction [5].
Reference [6] developed an ontology to model attacks and related entities, the proposed ontology is only aimed at attack. In order to represent concepts and entities that are relevant to the cyberspace security domain, reference [7] proposed an ontology for cybersecurity derived from the ontology proposed by reference [6]. They extended the ontology to provide model relations that capture the US National Vulnerability Database schema structure and security exploit concepts. This ontology contains 11 entity types, such as vulnerability, product, means, consequence. Reference [8] extended the ontology proposed by reference [6] and added rules to the reasoning logic. Their ontology comprises three fundamental classes: means, consequences, and targets.
Information extraction is mainly oriented to open data, and the available knowledge unit is extracted through automatic technology. The knowledge unit mainly includes three knowledge elements: entity, relationship and attribute, and on this basis, a series of high-quality fact expression is formed, which lays the foundation for the construction of the upper pattern layer.
There are two main methods of information extraction [9]: the first is knowledge-based engineering, which depends significantly on extraction rules but also enables the system to deal with domain-specific data extraction challenges. The majority of early data extraction systems relied on extraction rules. The biggest disadvantage is that it necessitates the involvement of experts in the subject. As a result, the extraction system’s accuracy is excellent, and many current information extraction methods are based on knowledge engineering [10].
The second main method is the method based on machine learning [11], which has also become a mainstream method with the rise of machine learning. The fundamental processes include training an information extraction model with a significant quantity of training data and then utilizing the information extraction model to extract relevant data. This method has the benefit of not requiring professionals to set rules in advance, but it does need a big quantity of training data in order to produce superior experimental outcomes. Reference [12] proposed a system that can identify related entities from unstructured texts, and this system mainly solves network attacks and software vulnerabilities. Reference [13] established a system for identifying and collecting vulnerability and attack information from network text, and then trained a support vector machine to spot possible flaws. The single-word packet vector model is used by this classifier. Once a probable vulnerability description has been determined, the framework extracts security-related items and ideas using conventional named entity recognition methods. All of the approaches described here are machine learning methods for extracting meaningful information from unstructured text automatically. However, without sufficient training data, this technique cannot properly identify the associated entities.
At the same time, following information extraction, the link between information units is flat, devoid of hierarchy and logic, and there are many redundant or even incorrect information pieces. The act of combining information from many knowledge bases to generate a single knowledge base is known as knowledge storage [14]. The major technologies used in this procedure are reference resolution, entity disambiguation, and entity linking. Different knowledge bases collect knowledge with different emphasis for the same entity. For example, some knowledge bases may focus on their own description of some aspect, while others may focus on describing the relationship between the entity and other entities. The real purpose of knowledge storage in different knowledge bases is to describe the consolidation, in order to obtain a complete description of the entity.
Knowledge reasoning method
The process of reasoning unknown information based on current knowledge is known as knowledge reasoning. Starting with known information, then acquiring new knowledge to gain the new facts included, or concluding from a big body of existing knowledge, from individual knowledge to generic knowledge. Symbol-based reasoning and statistics-based reasoning are two types of knowledge-based reasoning [15]. Symbol-based reasoning is often based on classical logic (first-order predicate logic or propositional logic) or modifications of classical logic in the area of artificial intelligence (such as default logic). Not only can symbol-based reasoning explain the new connection between entities from the existing KG using rules, but it can also discover the KG’s logic conflict. Machine learning techniques are often used in statistics-based reasoning approaches to discover new entity associations from the KG. The goal of knowledge reasoning is to figure out how instances and connections in the KG are connected. Reference [16] proposes a SDType method that uses the statistical distribution of attributes connected by triples or predicates to predict the type of an instance. This method can be used for KG of any single data source, but it cannot be used for knowledge reasoning across datasets. Reference [17] proposes a Tipalo method as a tool for automatically typing entities, while the linked Hypernyms data set [18] uses a unique abstract data that extracts instance types through a specific schema. This method relies on structured text data and cannot be extended to other databases.
Unified semantic information description of multiple domain cyberspace based on KG
The method of various domain cyberspace unified semantic information description based on KG is mostly introduced in this section.
Most studies in the KG of conventional cyberspace building have concentrated on the network domain and digital domain, which refers to network equipment and managing network data traffic, with physical domain, social domain, and other domains receiving little attention. However, as academics and business continue to delve further into the study of cyberspace, they have found that cyberspace not only exists in the network and digital domains, but is also influenced by multiple domain behavior. To address this challenge, we proposed using KG to provide an uniform semantic information description of different domain cyberspace. According to reference [1], cyberspace is an information activity area that sends signals and information over wireless or cable channels and regulates the relevant behaviors of entities on the platform of the linked information technology infrastructure network. From the above, it may be established that cyberspace contains various domains.
The following are some of the benefits of KG: its association query is more efficient than traditional storage approaches. This is a versatile storage option that is simple to maintain. The depth and general hierarchy of knowledge must be considered while constructing knowledge for cyberspace security. As a result, the initial step in this study is to create entity information in a multiple domain cyberspace. Multiple domain cyberspace information is derived from unstructured data based on entity.
To begin, the domain and scope of cyberspace entities are identified with the goal of integrating and standardizing necessary data in multiple domain cyberspace in order to offer a top-level model for the creation of multiple domain cyberspace KG. Second, after the scope of linked entities has been determined, it is desirable to reuse existing related entities to increase development efficiency.
(1) Entity information extraction
Space entity, equipment entity, port entity, service entity, file entity, information entity, and personnel entity are the seven categories of entity information that need to be gathered in this work, as indicated in Table 1.
Entity types
Entity types
The physical domain contains space entities, which are used to describe spatial information such as a city, campus, building, room, and so on. At the same time, physical entities, or equipment entities, exist in the physical domain. Physical things include keys, access control cards, and other relevant physical entities in addition to network equipment terminals such as switches, routers, servers, and user terminals. The physical ports of all types of network equipment are represented by port entities, which are placed in the network domain. It comprises not only physical but also virtual network ports at the same time. Service entities are also found in the network domain, and they reflect the services that have been opened on the equipment, mostly the services that have been used, such as HTTP, FTP, and E-mail. The file entity is in the digital domain, and it represents digital files, which may be saved on a terminal or on a server. The information entity is a digital entity that represents digital data such as a user name, password, secret key, information, and so on. Personnel entities represent the data of persons who are participating in a network, such as attackers, users, and administrators in the social domain.
(2) Semantic information extraction and construction
KG pulls semantic information from multiple domain cyberspace configuration information to provide a unified semantic description of multiple domain cyberspace. The semantic information is the main consideration in extracting the cyberspace configuration of semantic information in this paper; a lower level of semantic information is beneficial to the clear expression of the cyberspace configuration of semantic information, but the drawback is that the model is very large and complex. The core semantic information collected in the unified description of multiple domain cyberspace based on KG essentially consists of two pieces, namely entity and relationship. The following rules are used to create the extracted data:
Rule A: Assemble entities into a domain, then into the appropriate entity type.
Rule B: Extract relationships from cyberspace;
Rule C: Use lines to link related elements and designate connections.
We may construct the multiple domain cyberspace KG illustrated in Fig. 1 based on the relevant knowledge.
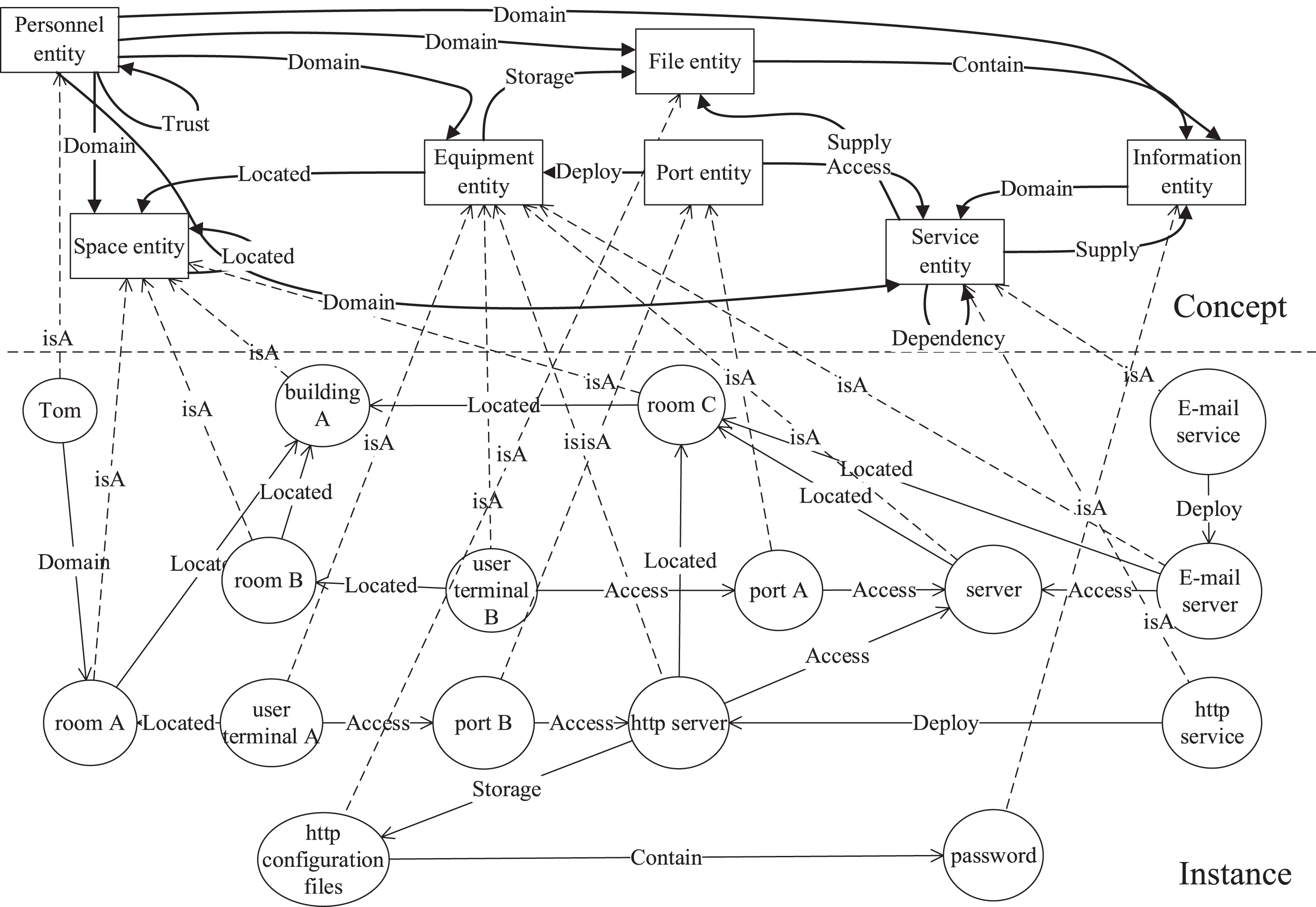
An example of multi-domain cyberspace KG.
As indicated in Fig. 1, Tom is a personnel entity; nevertheless, regular users, as well as attackers, may be able to manipulate User Terminal A, which is situated in Room A, and the server may offer network services, such as http and e-mail, if he can enter Room 1 in Building 1.
Tom, as an ordinary internal user, is unable to get important secret file information stored on the internal server, such as passwords, in the aforementioned KG. He cannot access to secret file information. However, using the multiple domain cyberspace KG and Tom’s permissions for knowledge reasoning, we discovered that he can obtain actual permissions that are higher than their deserved permissions, indicating that there are some vulnerabilities in cyberspace configuration. This serves as a foundation for further modifying cyberspace configuration and improving the multiple domain cyberspace’s overall security.
The knowledge-based user permission reasoning technique provided in this part focuses mostly on analyzing the influence of user activities on existing cyberspace security in order to identify cyberspace configuration flaws. Existing user permission inference approaches are mostly reliant on specialist-formulated user permissions reasoning rules that are neither clever or efficient. Furthermore, the particular rules of permission dependence and the relevant scope of each rule alter in the real-world multi-domain cyberspace environment. We proposed a knowledge-based user’s permissions reasoning method to overcome this challenge.
User’s permissions information
The primary problem in cyberspace security protection is user’s permissions. As stated in Table 2, there are nine different sorts of user’s permissions that must be collected in this paper.
The User’s permissions types
The User’s permissions types
The following user’s permissions are collected: space access permission, equipment use permission, equipment dominate permission, port use permission, port dominate permission, services access permission, service dominate permission, file dominate permission, and information known permission.
Physical domain permissions include space access permission, equipment use permission, and equipment dominate permission, where space access permission means the user can enter a physical space, equipment use permission means the user can use an equipment, and equipment dominate permission means the user can control an equipment. The difference between equipment use permission and equipment dominate permission is that the former allows the user to merely utilize the equipment in its present state, but the latter allows the user to alter the equipment’s configuration, such as changing the firewall setting. Port use permission, port dominate permission, and service access permission and service dominate are network domain permissions. Port use permission means the user can use this port to access services, port dominate permission means the user can change the port’s state or configuration, and service access permission and service dominate are network domain permissions. Service access permission indicates that the service request information flow will be able to access the service, but it does not imply that the service will be used in a usual manner. Users may generally pass the service’s security authentication and utilize the service normally if they have service dominion permission. Digital domain permissions include file dominate permission and information known permission, with file dominate permission implying that users can read, delete, and modify files, and information known permission implying that users are aware of digital information such as passwords, secret keys, and so on.
In reality, as evidenced by the kind of user’s permissions, the quantity of user’s permissions in cyberspace is directly tied to the connection between entities and entity relationships. Following the creation of the multiple domain cyberspace KG, we use it to perform permission reasoning for existing users in cyberspace and discover user’s all permissions under current cyberspace configuration, in order to identify vulnerabilities and provide a reference for modifying the cyberspace configuration to improve cyberspace security.
KG is composed of pieces of knowledge, and each piece of knowledge can be represented as a KG triad. It is assumed that the given KG consists of two entities
That is, when
Above that, this is traditional Translating Embeddings method (TransE) [20], and in our proposed method, we made the following improvements to it:
First, we have the entities and relationships from the multi-domain cyberspace KG; we also assume that Equation (1) holds;
Second, we train a model A that to learn the
Third, we also train a model B to learn the relationship of entity types, that means, assume that entity
Fourth, the user’s permission
Among them, α + β = 1.
At last, we compared the output
There is also a threshold w that needs to be met, that is
In a conclude, we have
The overall framework of user permission reasoning method is shown in Fig. 2.

The framework of user’s permission reasoning method based on KG.
The algorithm’s pseudo code is shown in Algorithm 1.
The experimental data
We evaluate the accuracy of the aforementioned knowledge reasoning method via experiments in this section, in order to establish that the multiple domain cyberspace can be unified defined based on the KG and the real user’s permissions can be reasoned based on the knowledge. The experimental data came from the cyberspace environments described in Chapters 2 and 5 in reference [1], which were designated as cyberspace environment A and B, respectively. At the same time, we created a conventional cyberspace simulation environment, which is shown in Fig. 3 as cyberspace environment C. We not only replicate actual equipment, physical connections, and network services in this environment, but also the physical space in which they are placed, the equipment’s location space, digital files and information kept by various equipment, as well as network administrators and users. In this cyberspace, which has a good reputation, there are not only regular users, but also network administrators and server administrators, as well as network attackers masquerading as ordinary users.

The topology of experimental cyberspace environment C.
The outermost space in this setting refers to the complete external environment, which might relate to the campus, the firm, the building, and so on. P1 is a space domain room, P2 is the room where the intrusion prevention system equipment is installed, P3 is a room, and P4 is the room where the server is installed. For five types of equipment, including computer 2 sets (T1 and T2, respectively in P1 and P3), firewall 2 sets (FW1, FW2, respectively in P3 and P4), sensor 1 (D1, stored in P2), router 1 (R, stored in P4), and switch 1 (SW, stored in P4), server 2 sets (T1 and T2, respectively in P1 and P3), firewall 2 sets (FW1, FW2, respectively in P3 and P4), sensor 1 (D1, stored in (S1, S2, stored in P4). The connections between the equipment are shown in Fig. 3.
Method A: This method based on Path Ranking Algorithm (PRA) [19]. This method leverages the route connection between entities for reasoning calculations, allowing it to directly estimate the relationship between two entity nodes. The approach begins with a single entity node, and at each entity node, you have two options: move to a randomly selected node or return to the beginning node. There is just one parameter in the algorithm: the restart probability R. After iteration, stability is established by a series of random walks. The score of all nodes in the network for the beginning node, essentially the intimacy between entity nodes, is included in the likelihood vector following stability. The entity node that can be inferred is the node with the highest score.
Method B: Based on Rules (BOR). Since there is no public data set of user’s permissions reasoning in scholarly community, we use the rule-based reasoning method based on reference [1] to carry out user’s permissions reasoning for the three existing cyberspace environments, and get their final permissions that can be obtained. Although rule-based reasoning has its limitations, but its precision rate and recall rate are both 100% after specialist make rules. In the description in reference [1], the accuracy of its rule-based user’s permission reasoning method is 100%.
Method C: TransE method: The key concept behind the TransE method is to identify a mapping function that will translate each node in the graph into a low-dimensional dense embedded representation, with related nodes in the graph having the same distance in the low-dimensional space. The representation vector that results may be utilized for tasks like node categorization, connection prediction, visualization, and so forth. It is mostly a knowledge-based method.
Method D: Knowledge Based User’s Permissions Reasoning (KR), which is the method proposed in this paper.
The accuracy and recall rates are both 100% because Method B is a rule-based reasoning method that is carried out by a professional to describe rules. The suggested method’s key benefits are its intelligence and refinement, and there is no data for user permission reasoning that has been accepted by the academic community. To compare the effects, the user’s permissions reasoning in BOR is utilized as the training data for our KR method.
Evaluation criterion
We created 5000 users in our multiple domain cyberspace system, each with varied beginning permissions. To begin, the BOR approach is used to reason about the permissions of 5000 users. This rule has 14 rules, and the particular rules may be found in reference [1]. The final permissions obtained from 5000 users are then utilized as training data to test the effectiveness of our proposed method.
There are two types of criteria for determining if the reasoning is correct: accuracy rate and recall rate. The following is the definition of formula:
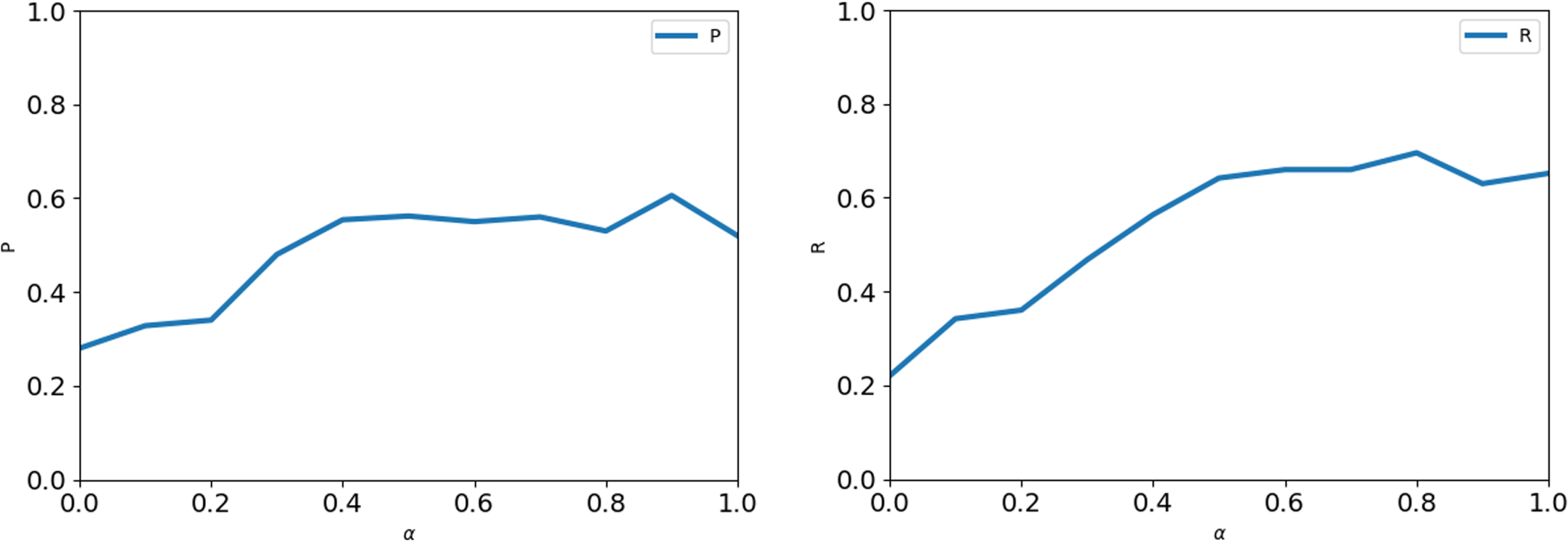
The parameter influence to P and R.

The threshold w influence to the P and R.
TP is the number of positive categories predicted to be positive categories, FP is the number of negative samples are mistakenly predicted to be positive samples, and FN is the number of positive samples predicted to be negative samples.
The hardware equipment of our experiment is Intel X power CPU, the memory is 64GB, 2 pieces of 2080Ti, the operating system is Ubuntu 18.04, and the cyberspace environment is written by Python. We first set 5000 users and give them different initial permissions respectively, and then get the corresponding final user’s permissions through Method B.
Experiment A: The relationship between parameters α and P, R in our proposed method, the experiment data is environment A. In order to obtain high precision rate and recall rate, we set the w = 0 in experiment A.
Experiment A is to see the effects of parameters α and β on the experiment. We are setting α = 0.1 ∼ 1.0, to see which parameters is best. The result is shown in Fig. 4.
From the result, we can see the different parameters is influence to the experiment. We can see α = 0 . 8 the R is best, and α = 0 . 9 the P is best. Therefore, we use the α = 0 . 85 in the following experiments.
Experiment B: And then, we also see the effects of threshold w on the experiment. The experiment results are shown in Fig. 5.
From the Fig. 5, we can see with the w increasing, the P and R is decreasing. It shows that w is the minimum the better. This is also consistent with our conventional understanding, but in our common sense, the cosine similarity had better greater than 0.5, therefore, we set the w = 0.5 in the following experiments.
Experiment C: Then, the BOR results is used as the training data of other methods, and the experimental results obtained are shown in the table below.
The experimental results are shown in Table 3, according to the experimental results, the proposed method’s accuracy rate and recall rate are not equal to zero, demonstrating that the KR method can reason out the corresponding user’s permissions, and permission to automated reasoning, without relying on specialist given rules. As a result, the KR method, when compared to BOR higher intelligent level, has a wider applicability, it can abandon the artificial model of writing reasoning rules, and let the machine with the help of machine learning and other methods reason out the corresponding user permissions.
The results of different methods in different datasets (cyberspace environment)
The results of different methods in different datasets (cyberspace environment)
At the same time, the accuracy rate and recall rate of the proposed method are better than PRA method and TransE method in other environments, with the exception of cyberspace environment C, where the recall rate is slightly lower, indicating that the proposed method has a better effect and can improve the accuracy rate of existing reasoning methods to some extent.
Simultaneously, the experimental results discovered that the bigger the network, the longer the reasoning time. Because cyberspace environment B is more complicated than cyberspace environments A and C in the experiment, it takes longer to reason about it. However, the experiments in this work were all conducted in a tiny simulated cyberspace, and reasoning verification was not performed on a huge genuine cyberspace. As a result, the next step is to test the suggested method’s practicality on a large-scale real-world internet.
The user’s permissions reasoning based on knowledge to reason out the user’s all possible permissions ability under the current cyberspace configuration was discovered through the analysis of experiment results, which means we can reason the user’s permissions he can obtain under the current cyberspace configuration. The proposed method which uses the specialist mode to discard the usual set of reasoning rules, solves the issue of its limited field of application, and considerably improves reasoning efficiency.
Based on KG, this paper proposed a unified representation method for semantic information in multiple domain cyberspace, as well as a knowledge-based reasoning method. Entities and entity relationships in multiple domain cyberspace may be represented using KG, allowing cyberspace entities from several domains to be characterized and articulated in a consistent manner. Unified semantic information description based on existing multiple domain cyberspace security status, thus effectively grasping these connections between multiple domain attack, on this basis, has realized the permissions of users based on the knowledge reasoning method, this method has abolished the traditional pattern of specialists writing reasoning rules in advance, can let the machine learn reasoning rules automatically, and intelligently realize the user’s permissions. It has been shown that this method can successfully reason the user’s ultimate obtain permissions under present cyberspace configuration, and realize the intelligent reasoning of user’s permissions, via the creation of a simulation cyberspace environment and experiments. As a result, the method proposed in this paper is both practical and efficient.
The unified semantic description and reasoning approach of multiple domain cyberspace based on KG is presented in this paper, which can describe the information of diverse domains in cyberspace, effectively describing and expressing the entire condition of cyberspace. Our experiments, on the other hand, are all based on a tiny simulation cyberspace environment that hasn’t been effectively tested in a large-scale genuine cyberspace environment. The next stage will be to test the accuracy and efficacy of our proposed method in a large-scale real-world cyberspace.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China: Research on multiple time series classification and prediction in dynamic variable environment (62076251 and 62106281), the National Key Research and Development Program of China: Research on basic theory of social engineering (2017YFB0802801). Basic frontier science and technology innovation basic research project of Army Engineering University of PLA (KYZYJQ2L2008).